【LLM】Ollama:本地大模型 WebAPI 调用
Ollama 快速部署
-
安装 Docker:从 Docker 官网 下载并安装。
-
部署 Ollama:
- 使用以下命令进行部署:
docker run -d -p 11434:11434 --name ollama --restart always ollama/ollama:latest -
进入容器并下载 qwen2.5:0.5b 模型:
- 进入 Ollama 容器:
docker exec -it ollama bash- 在容器内下载模型:
ollama pull qwen2.5:0.5b
Python 环境准备
在开始之前,请确保您已安装 requests 模块。可以通过以下命令安装:
pip install requests
我们还将初始化基本的 API 相关配置,如下所示:
import requests# 基础初始化设置
base_url = "http://localhost:11434/api"
headers = {"Content-Type": "application/json"
}
对话方式
生成文本补全 (Generate a Completion)
- API:
/generate - 功能: 生成指定模型的文本补全。输入提示词后,模型根据提示生成文本结果。
- 请求方法:
POST - Ollama API 参数:
model(必填):模型名称,用于指定生成模型,例如qwen2.5:0.5b。prompt(必填):生成文本所用的提示词。suffix(可选):生成的补全文本之后附加的文本。stream(可选):是否流式传输响应,默认true,设置为false时返回完整文本。system(可选):覆盖模型系统信息的字段,影响生成文本风格。temperature(可选):控制文本生成的随机性,默认值为1。
def generate_completion(prompt, model="qwen2.5:0.5b"):url = f"{base_url}/generate"data = {"model": model,"prompt": prompt,"stream": False}response = requests.post(url, headers=headers, json=data)return response.json().get('response', '')# 示例调用
completion = generate_completion("介绍一下人工智能。")
print("生成文本补全:", completion)
流式生成文本补全 (Streaming Completion)
- API:
/generate - 功能: 流式生成文本补全,模型会逐步返回生成的结果,适用于长文本。
- 请求方法:
POST - Ollama API 参数:
model(必填):模型名称。prompt(必填):生成文本所用的提示词。stream(必填):设置为true,启用流式传输。
def generate_completion_stream(prompt, model="qwen2.5:0.5b"):url = f"{base_url}/generate"data = {"model": model,"prompt": prompt,"stream": True}response = requests.post(url, headers=headers, json=data, stream=True)result = ""for line in response.iter_lines():if line:result += line.decode('utf-8')return result# 示例调用
stream_completion = generate_completion_stream("讲解机器学习的应用。")
print("流式生成文本补全:", stream_completion)
生成对话补全 (Chat Completion)
- API:
/chat - 功能: 模拟对话补全,支持多轮交互,适用于聊天机器人等场景。
- 请求方法:
POST - Ollama API 参数:
model(必填):模型名称。messages(必填):对话的消息列表,按顺序包含历史对话,每条消息包含role和content。role:user(用户)、assistant(助手)或system(系统)。content: 消息内容。
stream(可选):是否流式传输响应,默认true。
def generate_chat_completion(messages, model="qwen2.5:0.5b"):url = f"{base_url}/chat"data = {"model": model,"messages": messages,"stream": False}response = requests.post(url, headers=headers, json=data)return response.json().get('message', {}).get('content', '')# 示例调用
messages = [{"role": "user", "content": "什么是自然语言处理?"},{"role": "assistant", "content": "自然语言处理是人工智能的一个领域,专注于人与计算机之间的自然语言交互。"}
]
chat_response = generate_chat_completion(messages)
print("生成对话补全:", chat_response)
生成文本嵌入 (Generate Embeddings)
- API:
/embed - 功能: 为输入的文本生成嵌入向量,常用于语义搜索或分类等任务。
- 请求方法:
POST - Ollama API 参数:
model(必填):生成嵌入的模型名称。input(必填):文本或文本列表,用于生成嵌入。truncate(可选):是否在文本超出上下文长度时进行截断,默认true。stream(可选):是否流式传输响应,默认true。
def generate_embeddings(text, model="qwen2.5:0.5b"):url = f"{base_url}/embed"data = {"model": model,"input": text}response = requests.post(url, headers=headers, json=data)return response.json()# 示例调用
embeddings = generate_embeddings("什么是深度学习?")
print("生成文本嵌入:", embeddings)
模型的增删改查
列出本地模型 (List Local Models)
- API:
/tags - 功能: 列出本地已加载的所有模型。
- 请求方法:
GET - Ollama API 参数: 无。
def list_local_models():url = f"{base_url}/tags"response = requests.get(url, headers=headers)return response.json().get('models', [])# 示例调用
local_models = list_local_models()
print("列出本地模型:", local_models)
查看模型信息 (Show Model Information)
- API:
/show - 功能: 查看特定模型的详细信息,如模型的参数、版本、系统信息等。
- 请求方法:
POST - Ollama API 参数:
name(必填):需要查看信息的模型名称。verbose(可选):设置为true时返回更详细的信息。
def show_model_info(model="qwen2.5:0.5b"):url = f"{base_url}/show"data = {"name": model}response = requests.post(url, headers=headers, json=data)return response.json()# 示例调用
model_info = show_model_info()
print("模型信息:", model_info)
创建模型 (Create a Model)
- API:
/create - 功能: 根据指定的
Modelfile创建一个新模型,可以在已有模型的基础上定制。 - 请求方法:
POST - Ollama API 参数:
name(必填):新创建的模型名称。modelfile(可选):模型文件的内容,定义模型的基础信息。stream(可选):是否流式传输响应。
def create_model(model_name="qwen2.5_custom", base_model="qwen2.5:0.5b"):url = f"{base_url}/create"data = {"name": model_name,"modelfile": f"FROM {base_model}\nSYSTEM You are a helpful assistant."}response = requests.post(url, headers=headers, json=data)return response.json()# 示例调用
create_response = create_model()
print("创建模型:", create_response)
拉取模型 (Pull a Model)
- API:
/api/pull - 功能: 从 Ollama 库下载模型。取消的拉取将从上次中断的位置继续,并且多个调用将共享相同的下载进度。
- 请求方法:
POST - Ollama API 参数:
name(必填):要拉取的模型名称。insecure(可选):允许与库建立不安全的连接,仅在开发过程中从自己的库中提取时使用。stream(可选):如果为false,响应将作为单个响应对象返回,而不是对象流。
def pull_model(model_name="qwen2.5:0.5b"):url = f"{base_url}/api/pull"data = {"name": model_name}response = requests.post(url, headers=headers, json=data)return response.json()# 示例调用
pull_response = pull_model()
print("拉取模型:", pull_response)
删除模型 (Delete a Model)
- API:
/delete - 功能: 删除本地模型以及其相关的数据。
- 请求方法:
DELETE - Ollama API 参数:
name(必填):需要删除的模型名称。
def delete_model(model_name="qwen2.5_custom"):url = f"{base_url}/delete"data = {"name": model_name}response = requests.delete(url, headers=headers, json=data)return response.json()# 示例调用
delete_response = delete_model()
print("删除模型:", delete_response)
相关文章:

【LLM】Ollama:本地大模型 WebAPI 调用
Ollama 快速部署 安装 Docker:从 Docker 官网 下载并安装。 部署 Ollama: 使用以下命令进行部署: docker run -d -p 11434:11434 --name ollama --restart always ollama/ollama:latest进入容器并下载 qwen2.5:0.5b 模型: 进入 O…...
Excel监听以及常用工具类)
SpringBoot集成阿里easyexcel(二)Excel监听以及常用工具类
EasyExcel中非常重要的AnalysisEventListener类使用,继承该类并重写invoke、doAfterAllAnalysed,必要时重写onException方法。 Listener 中方法的执行顺序 首先先执行 invokeHeadMap() 读取表头,每一行都读完后,执行 invoke()方法…...

使用ELK Stack进行日志管理和分析:从入门到精通
在现代IT运维中,日志管理和分析是确保系统稳定性和性能的关键环节。ELK Stack(Elasticsearch, Logstash, Kibana)是一个强大的开源工具集,广泛用于日志收集、存储、分析和可视化。本文将详细介绍如何使用ELK Stack进行日志管理和分…...

前端框架对比与选择
🤖 作者简介:水煮白菜王 ,一位资深前端劝退师 👻 👀 文章专栏: 前端专栏 ,记录一下平时在博客写作中,总结出的一些开发技巧✍。 感谢支持💕💕💕 目…...
Springboot jPA+thymeleaf实现增删改查
项目结构 pom文件 配置相关依赖: 2.thymeleaf有点类似于jstlel th:href"{url}表示这是一个链接 th:each"user : ${users}"相当于foreach,对user进行循环遍历 th:if进行if条件判断 {变量} 与 ${变量}的区别: 4.配置好application.ym…...
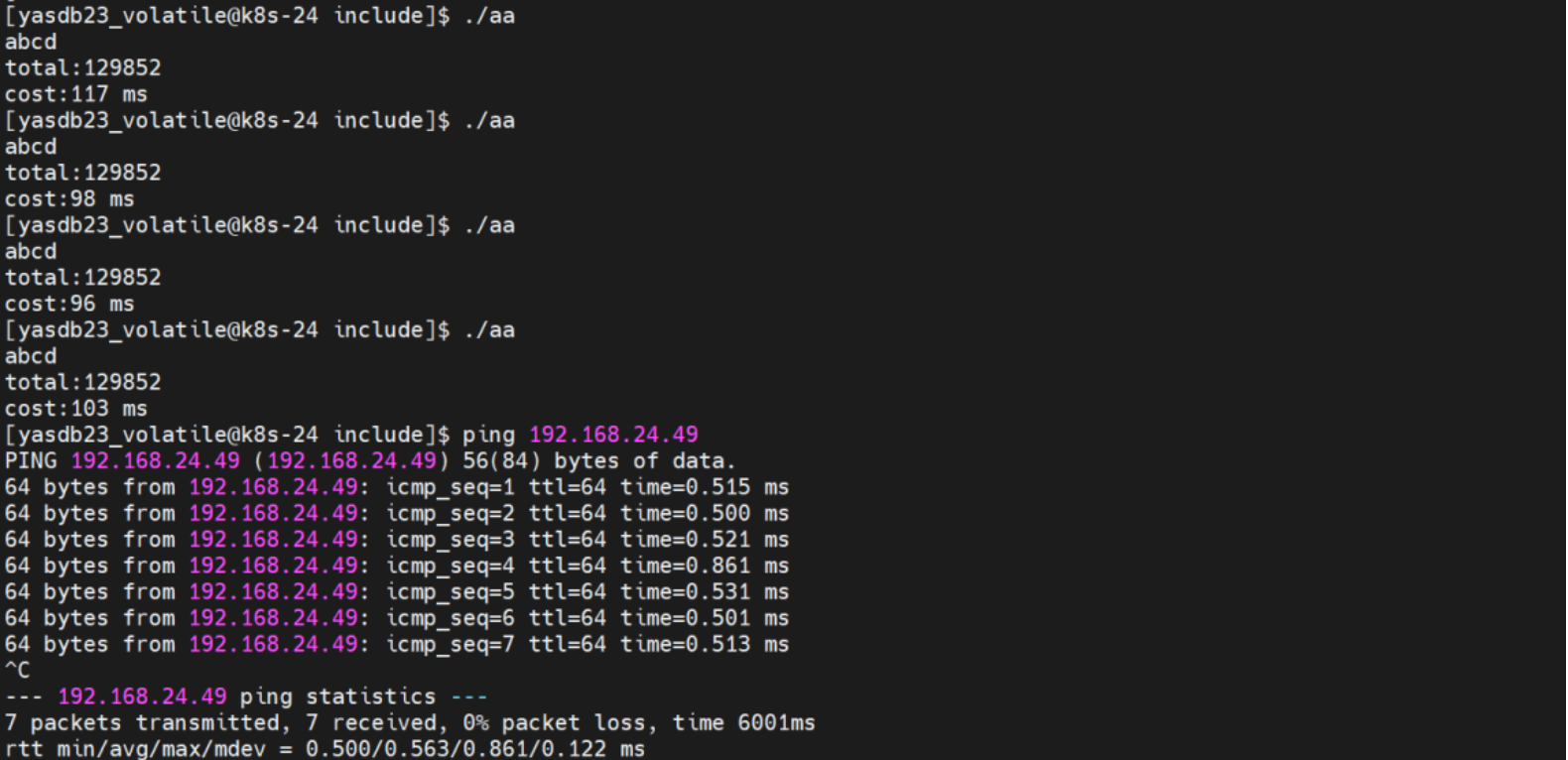
【YashanDB知识库】yashandb执行包含带oracle dblink表的sql时性能差
本文内容来自YashanDB官网,具体内容请见https://www.yashandb.com/newsinfo/7396959.html?templateId1718516 问题现象 yashandb执行带oracle dblink表的sql性能差: 同样的语句,同样的数据,oracle通过dblink访问远端oracle执行…...

效率工具推荐 | 高效管理客服中心知识库
人工智能AI的广泛应用,令AI知识库管理已成为优化客服中心运营的核心策略之一。一个高效、易用且持续更新的知识库不仅能显著提升客服代表的工作效率,还能极大提升客户的服务体验。而高效效率工具如HelpLook,能够轻松搭建AI客服帮助中心&#…...
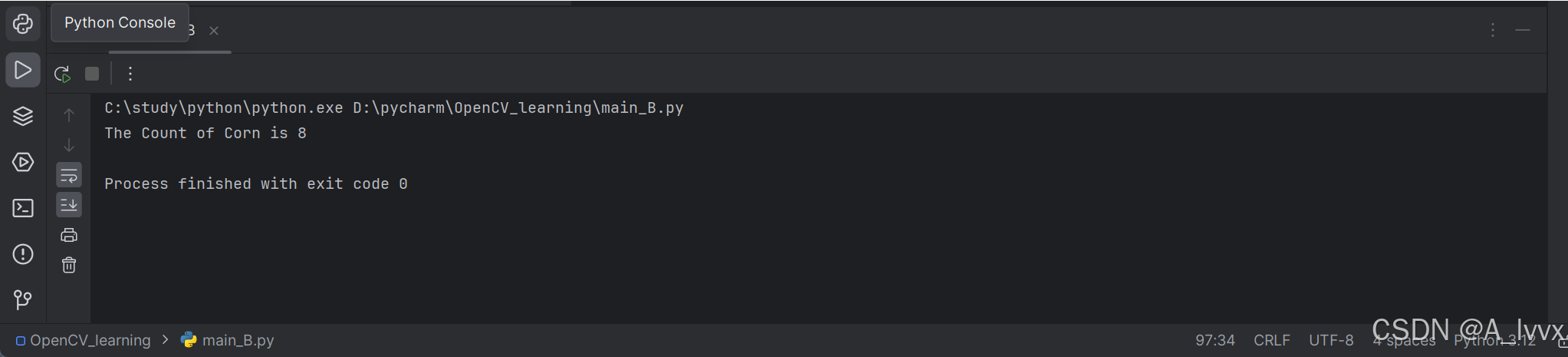
综合实验1 利用OpenCV统计物体数量
一、实验简介 传统的计数方法常依赖于人眼目视计数,不仅计数效率低,且容易计数错误。通常现实中的对象不会完美地分开,需要通过进一步的图像处理将对象分开并计数。本实验巩固对OpenCV的基础操作的使用,适当的增加OpenCV在图像处…...
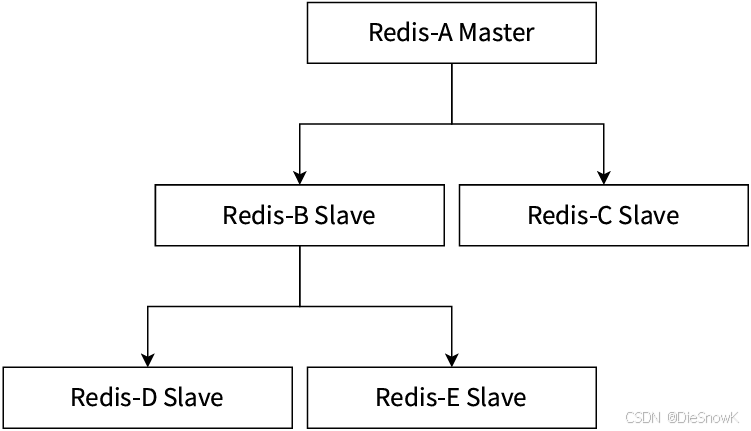
[Redis][主从复制][上]详细讲解
目录 0.前言1.配置1.建立复制2.断开复制3.安全性4.只读5.传输延迟 2.拓扑1.一主一从结构2.一主多从结构2.树形主从结构 0.前言 说明:该章节相关操作不需要记忆,理解流程和原理即可,用的时候能自主查到即可主从复制? 分布式系统中…...

【算法】leetcode热题100 146.LRU缓存. container/list用法
https://leetcode.cn/problems/lru-cache/description/?envTypestudy-plan-v2&envIdtop-100-liked 实现语言:go lang LRU 最近最少未使用,是一种淘汰策略,当缓存空间不够使用的时候,淘汰一个最久没有访问的存储单元。目前…...

[论文总结] 深度学习在农业领域应用论文笔记13
文章目录 1. Downscaling crop production data to fine scale estimates with geostatistics and remote sensing: a case study in mapping cotton fibre quality (Precision Agriculture ,2024, IF5.585)背景方法结果结论个人总…...
《Detection of Tea Leaf Blight in Low-Resolution UAV Remote Sensing Images》论文阅读
学习资料 论文题目:Detection of Tea Leaf Blight in Low-Resolution UAV Remote Sensing Images(低分辨率UAV遥感图像中茶叶枯萎病的检测)论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp&arnumber10345618 Abstr…...
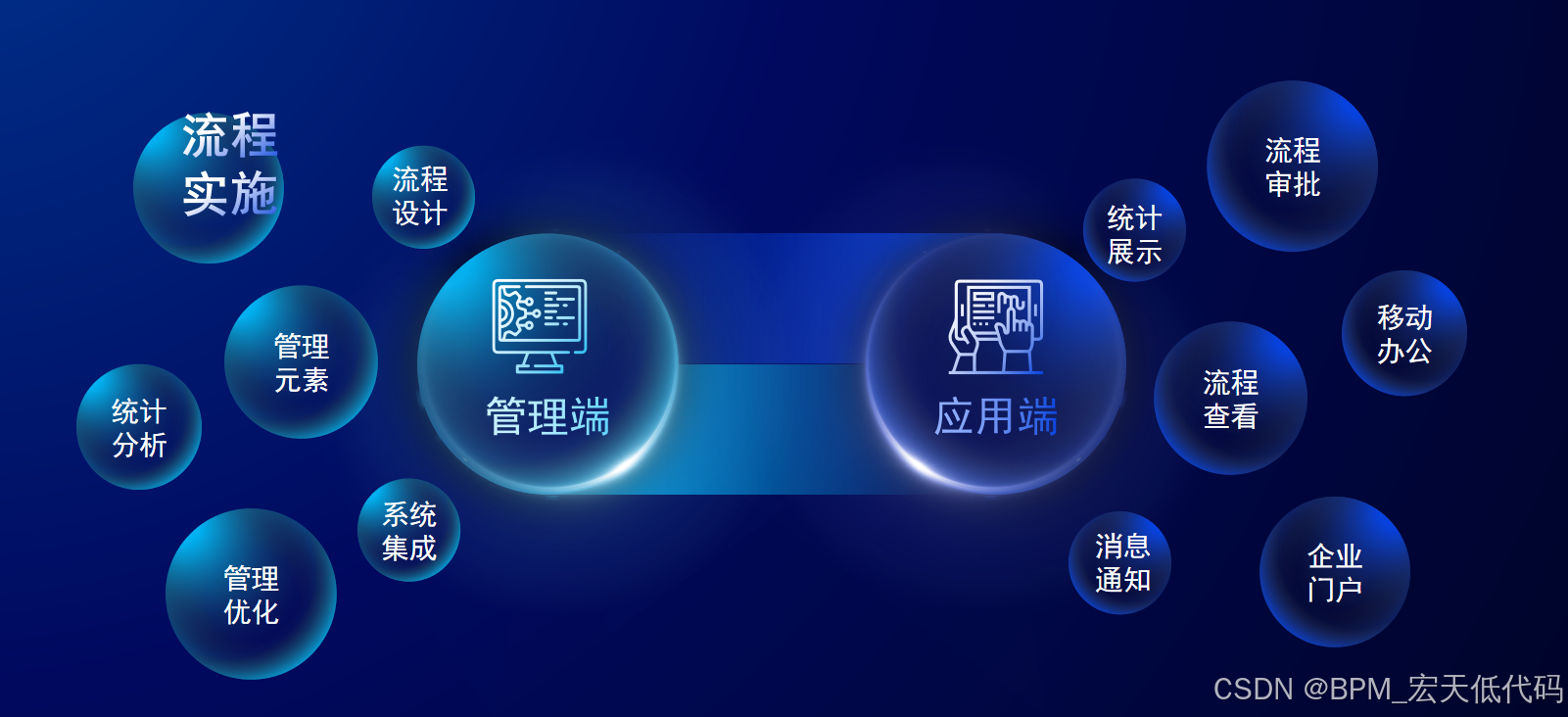
低代码BPA(业务流程自动化)技术探讨
一、BPA流程设计平台的特点 可视化设计工具 大多数BPA流程设计平台提供直观的拖拽式界面,用户可以通过图形化方式设计、修改及优化业务流程。这种可视化的方式不仅降低了门槛,还便于非技术人员理解和参与流程设计。集成能力 现代BPA平台通常具备与其他系…...
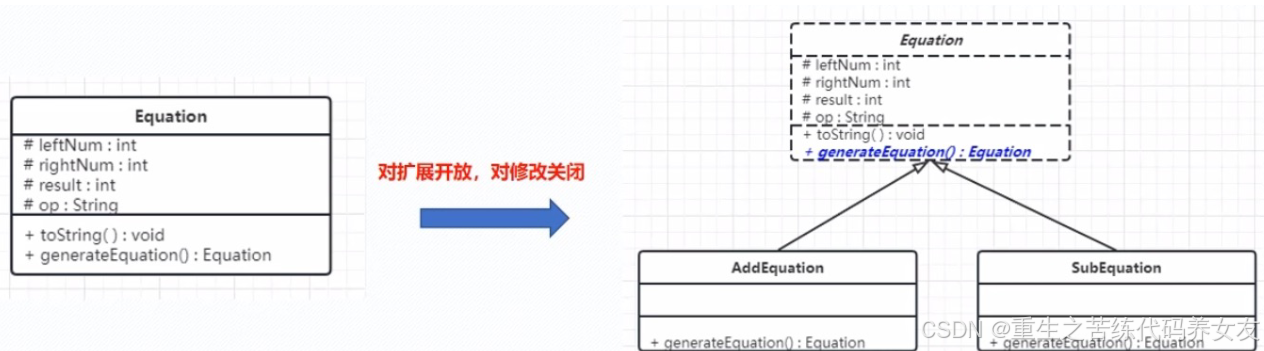
开闭原则(OCP)
开闭原则(OCP):Open Closed Princide:对扩展开放,对修改关闭。在程序需要进行拓展的时候,不能去修改原有代码,实现一个热插拔的效果。 简言之,是为了使程序的扩展性更好,…...

Unity之 TextMeshPro 介绍
TextMeshPro 是 Unity 中用于处理文本显示的高级插件,旨在替代 Unity 内置的 UI.Text 和 TextMesh 组件。与默认的文本组件相比,TextMeshPro 提供了更高的文本渲染质量和更多的文本样式选项,同时具备强大的优化能力。 TextMeshPro 的主要特点…...
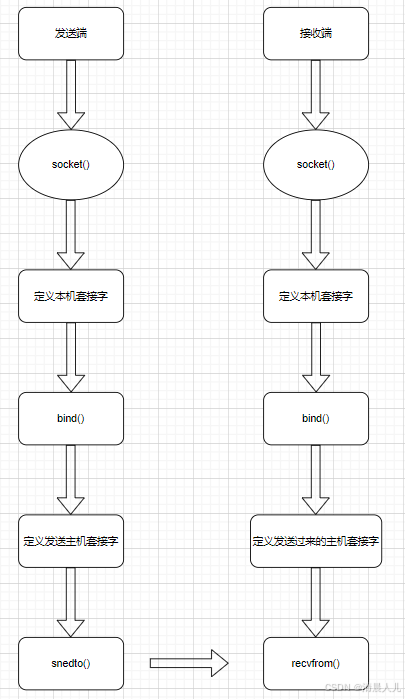
Linux套接字Socket
Linux套接字Socket 前提知识补充 为不同机器上的两个进程之间提供通信机制 主机字节序小端存储,网络字节序大端存储 特点TCPUDP连接类型面向连接无连接可靠性高低有序性保证数据包按顺序到达不保证数据包顺序流量控制有滑动窗口机制无拥塞控制有拥塞控制机制无复杂性较高较低…...
基于 Web 的工业设备监测系统:非功能性需求与标准化数据访问机制的架构设计
目录 案例 【说明】 【问题 1】(6 分) 【问题 2】(14 分) 【问题 3】(5 分) 【答案】 【问题 1】解析 【问题 2】解析 【问题 3】解析 相关推荐 案例 阅读以下关于 Web 系统架构设计的叙述,回答问题 1 至问题 3 。 【说明】 某公司拟开发一款基于 Web 的…...

【MySQL】基础入门篇
> 作者:დ旧言~ > 座右铭:松树千年终是朽,槿花一日自为荣。 > 目标:理解什么是MySQL,如何安装MySQL,简单使用MySQL。 > 毒鸡汤:有些事情,总是不明白,所以我不…...

uni-app vue3封装websocket,支持微信小程序
一、创建useWebSocket.js 文件 // useWebSocket.js // 获取链接的URL前缀 import {BASE_URL } from "./request";import {ref,onMounted,onBeforeUnmount } from "vue";// 假设我们使用 uni-app 的 globalData 或 Vuex 来管理用户状态 // 这里为了简单起…...

杭州算力小镇:AI泛化解锁新机遇,探寻AI Agent 迭代新路径
人工智能技术不断迭代,重点围绕着两个事情,一是数据,二是算力。 算法的迭代推动着AI朝向多模态的方向发展,使之能够灵活应对不同领域的不同任务,模型的任务执行能力大大提升,人工智能泛化能力被推上高潮。…...

数字孪生交互推演方法
数字孪生交互推演方法(Digital Twin Interactive Deduction Methodology)是用户为中心交互系统工程(UCI-SE)在研发设计、变型设计以及生产预测环节的最高技术形态 。它改变了传统数字孪生“只能看、不能动”的静态看板僵局&#x…...

MIMO AONN架构:量子干涉实现超低功耗光学神经网络
1. MIMO AONN架构的核心价值光学神经网络(AONN)正在突破传统电子计算的物理极限。在传统电子神经网络中,非线性激活函数需要消耗大量能量进行电子-光子转换,而基于量子干涉的光学非线性机制可以直接在光域实现这一关键操作。我们实…...

中小企业如何通过Taotoken的Token Plan套餐控制AI集成成本
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 中小企业如何通过Taotoken的Token Plan套餐控制AI集成成本 应用场景类,中小企业在为官网或CRM系统集成AI功能时&#x…...

Adobe-GenP完整指南:5步轻松激活Adobe全系列软件
Adobe-GenP完整指南:5步轻松激活Adobe全系列软件 【免费下载链接】Adobe-GenP Adobe CC 2019/2020/2021/2022/2023 GenP Universal Patch 3.0 项目地址: https://gitcode.com/gh_mirrors/ad/Adobe-GenP Adobe-GenP是一款专为Adobe Creative Cloud用户设计的通…...

ElevenLabs动画配音语音项目踩坑实录,深度复盘4类合规风险与3种本地化绕过方案
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs动画配音语音项目踩坑实录,深度复盘4类合规风险与3种本地化绕过方案 在为国产原创2D动画《星尘回廊》接入ElevenLabs API实现多语种AI配音时,团队遭遇了超出预期的合规…...

AI专著撰写秘籍!4款工具助力一键生成20万字专著,高效又省心!
创新是学术专著最核心的部分,也是写作过程中最大的挑战。一部优秀的专著,不仅要避免简单的研究成果重复堆砌,更需要在整个作品中提出独到的观点、理论架构或研究手法。在众多学术文献中,发现那些尚未被开发的研究空白相当不易——…...

FanControl终极指南:告别噪音,掌控你的PC风扇控制
FanControl终极指南:告别噪音,掌控你的PC风扇控制 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Tren…...

城通网盘解析工具:3步获取高速直连下载地址的终极方案
城通网盘解析工具:3步获取高速直连下载地址的终极方案 【免费下载链接】ctfileGet 获取城通网盘一次性直连地址 项目地址: https://gitcode.com/gh_mirrors/ct/ctfileGet 你是否还在为城通网盘的蜗牛下载速度而烦恼?每次下载大文件都要经历漫长的…...

从零构建AOD-Net:PyTorch实战图像去雾模型开发全流程
1. 环境准备与数据理解 在开始构建AOD-Net之前,我们需要先搭建好开发环境。推荐使用Anaconda创建独立的Python环境,避免与其他项目产生依赖冲突。这里我选择Python 3.8和PyTorch 1.12的组合,这个版本经过实测在图像处理任务中表现稳定。 安装…...
)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码)
告别数据错位:用Verilog在Xilinx FPGA上搞定AD7961回声时钟模式(附完整代码) 高速数据采集系统中,时序同步问题往往是工程师的噩梦。当AD7961工作在回声时钟模式时,数据信号与时钟信号的微妙相位关系可能导致采样结果出…...