分布式数据库——HBase基本操作
启动HBase:
1.启动hadoop,进入hadoop的sbin中
cd /opt/hadoop/sbin/
2.初始化namenode
hdfs namenode -format
3.启动hdfs
./start-all.sh
4.启动hbase
cd /opt/hbase/bin
./start-hbase.sh
5.使用jps查看进程
jps以下图片则是hbase启动成功~

运行HBase
./hbase shell接下来就可以开始建表啦~

shell操作:
HBase创建数据库建表:
语法:
create '表名','列族名1','列族名2',...,'列族名N'查看所有数据库:
list
查看表结构:
discribe '表名'

计算表中所有记录的数量:
count '表名' 
HBase数据库表数据的增、删、查、改
(1)HBase增加数据的语法格式:
put '表名','rowKey','列族:列','值'
(2)HBase查询数据的语法格式:
scan查询所有表记录
scan '表名' 
get查询某个rowKey的所有记录
get '表名','rowKey' 
get查询某个rowKey列族的记录
get '表名','rowKey','列族'
get查询rowKey列族的某个列记录
get '表名','rowKey','列族:列'
(2)HBase 删除数据:
删除表的所有记录:(drop)
disable '表名'
drop '表名'删除表的某一条记录:(delete)
delete '表名','行名','列族:列' 
删除表的整行记录
deleteall '表名','rowKey' 
清空表的所有记录
truncate '表名'
(4)HBase更新数据
用put重新写一遍,可以覆盖
下面以建如下表结构为例

1.创建一个名为student的表,字段包括stuInfo和grades
creat 'student','stuInfo','grades' 
2.向表中插入数据
put 'student','001','stuInfo:name','alice'
put 'student','001','stuInfo:age','18'
put 'student','001','stuInfo:sex','female'
put 'student','001','grades:English','80'
put 'student','001','grades:math','90'
put 'student','002','stuInfo:name','nancy'
put 'student','002','stuInfo:sex','male'
put 'student','002','stuInfo:class','1802'
put 'student','002','grades:English','85'
put 'student','002','grades:math','78'
put 'student','002','grades:bigdata','88'
put 'student','003','stuInfo:name','harry'
put 'student','003','stuInfo:age','19'
put 'student','003','stuInfo:sex','male'
put 'student','003','grades:English','90'
put 'student','003','grades:bigdata','90'过滤操作:
1.行键过滤器(RowFilter、KeyOnlyFilter、FirstKeyOnlyFilter等)
格式:scan '表名',{FILTER=>"过滤器(比较运算符,'比较器')"}
(1)RowFilter:针对行键进行过滤
例1: 显示行键前缀0开头的键值对
scan 'student',{FILTER=>"RowFilter(=,'substring:001')"}
例2:显示行键字节顺序大于002的键值对
scan 'student',FILTER=>"RowFilter(>,'binary:002')"
(2)PrefixFilter:行键前缀过滤器
例1:扫描前缀为001的行键
scan 'student',FILTER=>"PrefixFilter('001')"
(3)FirstKeyOnlyFilter:扫描全表,显示每个逻辑行的第一个键值对
scan 'student',FILTER=>"FirstKeyOnlyFilter()"
(4)InclusiveStopFilter:替代EndRow返回终止条件行
例:扫描显示行键001道002的范围内的键值对
scan 'student',{STARTROW=>'001',FILTER=>"InclusiveStopFilter('002')"}等同于:
scan 'student',{STARTROW=>'001',ENDROW=>'003'}
2.列族与过滤器
(1)Family:针对列族进行比较和过滤
例1:显示列族前缀为stu开头的键值对
scan 'student',FILTER=>"FamilyFilter(=,'substring:stu')"scan 'student',FILTER=>"FamilyFilter(=,'binary:stu')"

(2)QualifierFilter:列标识过滤器
例:显示列名为name的记录
scan 'student',FILTER=>"QualifierFilter(=,'substring:name')"
等价于
(3)ColumnPrefixFilter:对列名前缀进行过滤
例:显示列名为name的记录
scan 'student',FILTER=>"ColumnPrefixFilter('name')"
等价于
scan 'student',FILTER=>"QualifierFilter(=,'substring:name')"(4)MultipleColumnPrefixFilter:可以指定多个前缀
例:显示列名为name和age的记录
scan 'student',FILTER=>"ColumnPrefixFilter('name')"scan 'student',FILTER=>"MultipleColumnPrefixFilter('name','age')"
(5)ColumnRangeFilter:设置范围按字典序对列名进行过滤
例:
scan 'student',FILTER=>"ColumnRangeFilter('bi',true,'na',true)"
3.值过滤器
(1)ValueFilter:值过滤器
例:查询等于19的所有键值对
scan 'student',FILTER=>"ValueFilter(=,'binary:19') "
scan 'student',FILTER=>"ValueFilter(=,'substring:19')" 
(2)SingleColumnValueFilter:在指定的列族和列中进行值过滤器
例:查询studiofo列族age列中值等于19的所有键值对
scan 'student',{COLUMN=>'stuInfo:age',FILTER=>"SingleColumnValueFilter('stuInfo','age',=,'binary:19')"}
4.其他过滤器
(1)ColumnCountGetFilter:限制每个逻辑行返回的键值对数
例:返回行键位001的前3个键值对
get 'student','001',FILTER=>"ColumnCountGetFilter(3)"
(2)PageFilter:基于行的分页过滤器,设置返回的行数
例:显示1行
scan 'student',FILTER=>"PageFilter(1)"
(3)ColumnPaginationFilter:基于列的进行分页过滤器,需要设置偏移量与返回数量
例:显示每行第1列之后的第二个键值对
scan 'student',FILTER=>"ColumnPaginationFilter(2,1)"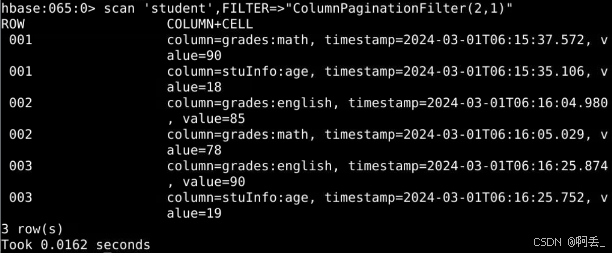
相关文章:
分布式数据库——HBase基本操作
启动HBase: 1.启动hadoop,进入hadoop的sbin中 cd /opt/hadoop/sbin/ 2.初始化namenode hdfs namenode -format 3.启动hdfs ./start-all.sh 4.启动hbase cd /opt/hbase/bin ./start-hbase.sh 5.使用jps查看进程 jps 以下图片则是hbase启动成功~ 运行HBase ./hbase sh…...

Go语言并发编程中的超时与取消机制解析
解锁Python编程的无限可能:《奇妙的Python》带你漫游代码世界 并发编程是Go语言的核心优势之一,而在实际应用中,超时和取消操作会频繁出现。超时机制能够帮助我们理解系统行为,防止系统因为某些任务执行过长而陷入困境。与此同时,取消操作则是应对超时的一种自然反应。此…...

Unity3D UIdocument如何改变层级详解
前言 在Unity3D中,UI文档的层级改变通常涉及UI元素的显示顺序,这是通过UGUI(Unitys Graphical User Interface)系统来实现的。以下是一篇关于如何在Unity3D中改变UI元素层级的详细解析,包括技术详解和代码实现。 对惹…...
Debian与Ubuntu:深入解读两大Linux发行版的历史与联系
Debian与Ubuntu:深入解读两大Linux发行版的历史与联系 引言 在开源操作系统的领域中,Debian和Ubuntu是两款备受瞩目的Linux发行版。它们不仅在技术上有着密切的联系,而且各自的发展历程和理念也对开源社区产生了深远的影响。本文将详细介绍…...

GPU服务器本地搭建Dify+xinference实现大模型应用
文章目录 前言一、显卡驱动配置1.检测显卡2.安装驱动 二、安装nvidia-docker二、安装Xinference1.拉取镜像2.运行Xinference3.模型部署 三、安装Dify1.下载源代码2.启动 Dify3.访问 Dify 四、Dify构建应用1.配置模型供应商2.聊天助手3.Agent 前言 本文使用的GPU服务器为UCloud…...

嵌入式程序设计经验 创建复位函数
在设计嵌入式系统重新时 需要考虑软复位的情况, 软复位时 很多变量都需要重置为初始值, 如果一个个去赋值 很麻烦, 下面是一个简单的办法 主要是对结构体 复位的方法: #include <stdint.h>typedef struct {uint8_t reg1;uint8_t reg2;uint8_t reg3; } StruSimuStat1…...

每天五分钟深度学习框架pytorch:交叉熵计算时的维度是什么?
本文重点 前面我们学习了pytorch中已经封装好的损失函数,已经封装好的损失函数有很多,但是我们并没有详细介绍,原因就是单独介绍损失函数可能难以理解,我们上一章节的目的是让大家先了解一下常见的损失函数,然后再之后的实际使用中遇到哪个损失函数,我们就使用哪个损失函…...

【Axure视频教程】跨页面控制中继器表格
今天教大家在Axure制作跨页面控制中继器表格的原型模板,我们可以在一个页面中通过交互,对另一个页面中的中继器进行控制,控制其显示的数据内容。那这个模板使用也很简单,复制粘贴按钮,在中继器表格里填写对应的数据&am…...

Android 利用OSMdroid开发GIS 添加 控件以及定位
部署看这个:Android 利用OSMdroid开发GIS-CSDN博客 添加控件,直接上源码 activity_main.xml: <?xml version"1.0" encoding"utf-8"?> <RelativeLayout xmlns:android"http://schemas.android.com/apk/…...

前端vue-实现富文本组件
1.使用wangeditor富文本编辑器 工具网站:https://www.wangeditor.com/v4/ 下载安装命令:npm i wangeditor --save 成品如下图: 组件实现代码 <template><div><!-- 富文本编辑器 --><div id"wangeditor">…...
)
AUTOSAR汽车电子嵌入式编程精讲300篇-基于CAN总线的气动控制(中)
目录 2.2 CAN总线技术及TTCAN协议 2.2.1 CAN总线技术 2.2.2 TTCAN协议 3 气动系统的定位控制研究 3.1 滑模控制原理 3.1.1 滑模控制概念和特性 3.1.2 滑模控制的抖振问题 3.1.3 非奇异终端滑模控制 3.2 气动系统定位控制策略设计 3.2.1 跟踪微分器的设计…...
国内可用ChatGPT-4中文镜像网站整理汇总【持续更新】
一、GPT中文镜像网站 ① yixiaai.com 支持GPT4、4o以及o1,支持MJ绘画 ② chat.lify.vip 支持通用全模型,支持文件读取、插件、绘画、AIPPT ③ AI Chat 支持GPT3.5/4,4o以及MJ绘画 二、模型知识 o1/o1-mini:最新的版本模型&am…...

前端sm2国密加密时注意
如下方法: export function encrypt(str) {const sm2 require("sm-crypto").sm2;const cipherMode 1; // 1 - C1C3C2,0 - C1C2C3,默认为1//自定义密钥let publicKey "xxxxxxxx";//此处加密let a sm2.doEncrypt(str,…...

LeetCode 面试经典150题 9.回文数
题目: 给你一个整数 x ,如果 x 是一个回文整数,返回 true ;否则,返回 false 。 回文数:是指正序(从左向右)和倒序(从右向左)读都是一样的整数。 例如&…...

select 函数简介
原型 #include <sys/select.h> #include <sys/time.h> #include <unistd.h> int select(int n, fd_set *readfds, fd_set *writefds, fd_set *exceptfds, struct timeval *timeout); 作用 select 函数是 UNIX 和类 UNIX 系统(如 Linux&am…...

python - 在linux上编译py文件为【.so】文件部署项目运行
python - 在linux上编译py文件为【.so】文件,可通过主文件直接执行 一. 前言 在Python中,通常不直接将Python代码编译为.so(共享对象)文件来执行,因为.so文件是编译后的二进制代码,通常用于C或C等语言&am…...

SQL_having_pandas_filter
HAVING子句在SQL中用于对分组后的结果进行过滤,它通常与GROUP BY子句一起使用。HAVING子句允许你指定条件来过滤聚合函数的结果,而WHERE子句则用于在分组之前过滤原始数据。 基本语法 SELECT column_name, aggregate_function(column_name) FROM table…...

从软件架构设计角度理解Kafka
网上对于消息中间件的介绍文章比较多,这里我们不再赘述,我们换个思路来理解消息中间件,从软件开发架构的角度来看下消息中间件是如何诞生和演进的。 一、概述 上图中P代表 Provider,C代表Consumer,下同。P和C是一个典型…...
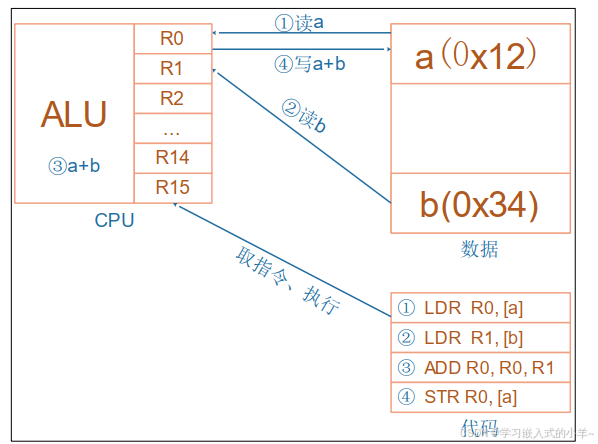
什么是中断?
1.什么是中断 2.中断的重要性 3.中断的上下半部 4.中断处理流程 中断的原则 5.ARM处理器程序运行过程 6.程序被被中断时,怎么保护现场 1.什么是中断 中断是指在 CPU 正常运行期间, 由外部或内部事件引起的一种机制。 当中断发生时,…...

后端(实例)08
设计一个前端在数据库调取数据的表格,并完成基础点击增删改查的功能: 1.首先写一个前端样式(空壳) <!DOCTYPE html> <html> <head> <meta charset"UTF-8"> <title>Insert title here&l…...

【网络编程】UDP协议
目录 协议格式 特点 1.无连接(Connectionless) 2. 不可靠(Unreliable) 3. 面向报文(Message-Oriented) 常见问题 协议格式 特点 1.无连接(Connectionless) 特点:在…...
)
强化学习算法:深度确定性策略梯度(DDPG)
强化学习算法:深度确定性策略梯度(DDPG) 1. 技术分析 1.1 DDPG概述 DDPG是针对连续动作的深度强化学习算法: DDPG特点确定性策略: 输出确定动作而非概率Actor-Critic架构: 结合策略和价值离线策略: 使用经验回放核心创新:确定性策略梯度目标网络探索噪声…...

百度文心大模型如何通过Taotoken实现稳定API调用与成本控制
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 百度文心大模型如何通过Taotoken实现稳定API调用与成本控制 对于希望集成百度文心大模型进行内容生成的企业开发者而言,…...

初创团队如何利用Taotoken控制AI实验成本并快速迭代产品
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 初创团队如何利用Taotoken控制AI实验成本并快速迭代产品 对于资源有限的初创团队而言,在开发AI功能原型时,…...

基于NXP i.MX6的智能电子后视镜方案:硬件选型、软件架构与车规级实践
1. 项目概述与核心价值 在汽车智能化浪潮中,驾驶安全始终是首要课题。传统的光学后视镜存在固有的物理盲区,尤其是在车辆侧方和侧后方,这些盲区是变道、转弯时发生剐蹭甚至碰撞事故的主要诱因。作为一名在嵌入式车载系统领域摸爬滚打了十多年…...

Qt程序图标设置全攻略:从.ico文件到任务栏显示,一个坑都不踩
Qt程序图标设置全攻略:从资源文件到系统缓存的完整解决方案 第一次用Qt打包发布程序时,我盯着任务栏上那个丑陋的默认图标发呆了十分钟——明明在代码里设置了图标,为什么还是显示不出来?相信很多Qt开发者都遇到过类似问题。图标…...

卫星通信安全认证技术解析与应用指南
1. 卫星通信安全认证技术概述 卫星通信作为现代信息基础设施的重要组成部分,其安全性直接关系到国家安全和经济发展。在近地轨道卫星数量激增、天地一体化网络快速发展的背景下,传统地面网络的安全认证方案已无法满足卫星通信的特殊需求。卫星信道具有长…...

VHD2VL:破解硬件描述语言转换难题的开源解决方案
VHD2VL:破解硬件描述语言转换难题的开源解决方案 【免费下载链接】vhd2vl 项目地址: https://gitcode.com/gh_mirrors/vh/vhd2vl 在FPGA和ASIC设计领域,技术团队常常面临VHDL与Verilog两种硬件描述语言之间的转换挑战。当项目需要跨语言协作、工…...

Java 大厂面试 200 题完整版含答案解析
前言本文整理了近两年从阿里、腾讯、字节、美团、京东、拼多多等大厂面试中高频出现的 200 道 Java 面试题,覆盖 Java 基础、集合、并发、JVM、Spring、MySQL、Redis、消息队列、分布式、场景设计 等核心模块,每题都附有简明扼要的答案解析,助…...

轻量级爬虫框架slacrawl:基于规则驱动的模块化数据采集实践
1. 项目概述:一个轻量级、模块化的网页爬虫框架最近在做一个需要从多个网站定时抓取结构化数据的小项目,找了一圈现成的工具,要么太重(像Scrapy,学起来成本高),要么太死板(很多脚本只…...