接口自动化--commons内容详解-02
上篇文章主要讲解了接口自动化主要架构框架,这篇文庄主要讲解commons中的内容
1. requests_utils.py
首先讲解这个工具类,主要是因为在接口自动化中,基本都有的接口都是发送请求,获取响应结果,唯一不同的是,每个接口的内容不一样,发送接口的方式不一样,针对这方面就做接口自动化的封装。
思路: 使用requests.session()发送请求,发送请求的内容是字典格式,并且里面的内容是不一样的所以我们会使用关键字参数,发送内容有两种形式,有可能是json格式,也有可能是文件上传格式,要对这部分的数据进行处理,具体代码如下
#生成日志对象
logger = logging.getLogger(__name__)class RequestUtil:sess= requests.session() #使用requests.session()比requests.request()函数对于接口中有cookies的def send_all_request(self,**kwargs):for key,value in kwargs.items():if key=="files":for file_key, file_value in value.items():value[file_key] = open(file_value, "rb")elif key=='data':new_data=json.dumps(kwargs['data']) #对于data的值是json格式要转换成字典格式kwargs['data']=new_datares=RequestUtil.sess.request(**kwargs)logger.info(res.text)return res2. yaml_util.py
在运行接口自动化用例的时候,要有对应的测试用例去运动,也会有一些配置要读取,因为他们都是使用yaml进行维护的,所以读取yaml中的数据要进行处理
思路: 首先要读取yaml中的内容,针对有接口关联的要借助第三方文件讲提取的字段写入到第三方文件中,这个时候要写入yaml文件,在每次执行完测试用例以后要讲yaml文件中的数据清除,所以也要有清除yaml文件的操作,还有一些特殊的操作,比如我们在做流程测试用例的时候,一个流程测试用例中可能有多个接口,其中某一个接口要执行多次,并且每次执行的内容页不一样,这个时候就要对这个接口做参数化,这个时候也要对写入yaml做具体的处理,这部分后面会专门讲解
常用的yaml处理内容,代码如下:
import yaml
#读取yaml
def read_yaml(key):with open("../extract.yaml",encoding='utf-8') as f:value=yaml.safe_load(f)return value[key]
#读取extract.yaml里面所有的值
def read_all():try:with open("../extract.yaml", encoding='utf-8') as f:return yaml.safe_load(f) or {} # 如果文件为空或不存在,则返回空字典except FileNotFoundError:return {}#写入yaml
def write_yaml(data):with open("../extract.yaml", 'w', encoding='utf-8') as f:yaml.safe_dump(data, f, allow_unicode=True, sort_keys=False, default_flow_style=False)
def handle_yaml(key, value):s = read_all()if key in s:if isinstance(s[key], list):s[key].append(value)else:s[key] = [s[key], value]else:s[key] = valuewrite_yaml(s)
#清空
def clean_yaml():with open("../extract.yaml", encoding='utf-8', mode="w") as f:pass#读取yaml测试用例
def read_testcase(yaml_path):with open(yaml_path) as f:value = yaml.safe_load(f)return value3.path_util.py
路径的处理,因为在接口自动化中一个代码可能在不同的环境中,所以使用绝对路径就会导致换个地址就无法运行,针对这种情况这边可以使用相对路径,对项目路径做统一处理,先获取当前项目的路径,然后其他路径都是在项目路径进行拼接,具体代码如下:
import os
from pathlib import Path
#项目路径
project_path=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
#测试报告临时存放位置
tempath=os.path.join(project_path,r'reports\temp')
#测试报告存放位置
reports_path=os.path.join(project_path,r'reports')
#测试用例路径
testcases_path=os.path.join(project_path,'testcases')
testcase_path = Path(testcases_path)
#日志存储路径
logs_path=os.path.join(project_path,r'1ogs')
4. model_util.py
测试用例因为都是使用yaml格式进行校验的,所以针对yaml格式也要做一些基本的校验,如果不符合测试用例指定的格式,就直接报错
from dataclasses import dataclass"""
作用:用来校验测试用例是否符合规则
@dataclass:表明CaseInfo是数据类目的:不用写init()初始方法,创建对象并且传入参数就可以自动赋值
"""
@dataclass
class CaseInfo:# 必填feature: strstory: strtitle: strrequest: dictvalidate: dict# 选填extract: dict = Noneparamtrize: list = None
"""
作用:校验测试用例
caseinfo :接收测试用例字典
**caseinfo: 将测试用例字典,解包为键值对,例如: 'name': 'HYY'
new_caseinfo:接收创建的CaseInfo()对象
"""
def verify_yaml(caseinfo: dict):try:new_caseinfo = CaseInfo(**caseinfo)return new_caseinfoexcept Exception:raise Exception("YAML测试用例不符合框架的规范!")5. loging_util.py
接口自动化中测试用例的执行的日志也需要记录,这样就可以在执行报错的时候找出到底哪里报错,所以对日志的封装代码如下:
#对统一的日志进行处理
from loguru import logger
from datetime import datetimefrom commons.path_util import logs_pathclass ApiAutoLog():#利用loguru封装接口自动化项目日志记录器def __new__(cls, *args, **kwargs):log_name = datetime.now().strftime("%Y-%m-%d") # 以时间命名日志文件,格式为"年-月-日"sink = f'{logs_path}/{log_name}' # 日志记录文件路径level = "DEBUG" # 记录的最低日志级别为DEBUGencoding = "utf-8" # 写入日志文件时编码格式为utf-8enqueue = True # 多线程多进程时保证线程安全rotation = "500MB" # 日志文件最大为500MB,超过则新建文件记录日志retention = "1 week" # 日志保留时长为一星期,超时则清除logger.remove(handler_id=None) #控制日志是否在控制台打印,这个代表不在控制台打印logger.add(sink=sink, level=level, encoding=encoding,enqueue=enqueue, rotation=rotation, retention=retention)return logger
log=ApiAutoLog()
def caselog(title,inBoby,res):log.info(f'【{title}】请求参数为:{inBoby}')log.info(f'【{title}】返回结果为:{res}')
6. assert_util.py
针对每个接口都有个断言需要进行处理,这边就针对断言进行统一封装
import copy
import pymysqlclass AssertUtil:def assert_all_case(self, res, assert_type, value):# 1.深拷贝个resnew_res = copy.deepcopy(res)# 2.把json()方法改成json属性try:new_res.json = new_res.json()except Exception as e:new_res.json = {"msg": 'response not json data'}raise e# 3.循环判断断言for msg, yq_and_sj_data in value.items():yq, sj = yq_and_sj_data[0], yq_and_sj_data[1]# 根据属性获取到属性的值try:sj_value = getattr(new_res, sj)# print("++++", assert_type, msg, yq, sj_value)except Exception:sj_value = sjif assert_type == "equals":# print("进入了equals")assert yq == sj_value, msgif assert_type == "contains":# print("进入了contains")assert yq in sj_value, msgif assert_type == "db_equals":yq_value = self.execute_sql(yq)assert yq_value[0] in sj_value,msgif assert_type == "db_contains":yq_value = self.execute_sql(yq)assert yq_value[0] in sj_value,msg7.ddt_util.py(后续单独一篇文章详解)
测试用例中单个测试用例会出现正例,反例或者一个接口会执行多次,每次执行的接口一样但是内容不一样,这个时候就会用到参数化,针对参数化处理,代码如下:
import yaml
#读取yaml测试用例
from commons.model_util import verify_yamldef read_testcase(yaml_path):with open(yaml_path) as f:case_list = yaml.safe_load(f)if len(case_list)>=2: #如果列表的长度大于2就不止一个接口,此时就判断是流程测试用例return [case_list]else:if "paramtrize" in dict(*case_list).keys(): #判断yaml文件中是否有parametrize参数,如果有就走数据驱动流程new_caseinfo=ddts(*case_list)return new_caseinfoelse:return case_list #如果yaml文件中没有parametrtze参数,就是一个单接口的用例读取
#对ddt数据的处理
def ddts(caseinfo:dict):# 数据驱动:返回[{正例},{反例},{反例}]# parametrize:# -["username","password"]# -["baili","6ai11123"]# - ["baili", "baili"]# -["bai1i123","bai1i123"]data_list=caseinfo["paramtrize"]# print(data_list) # [['username','password'],['baili','baili123'],['baili',"baili']]#先对这个参数化的列表的每一行的长度进行校验,如果长度校验通过就是走参数化,如果长度校验不通过就不是参数化len_flag=Truename_len=len(data_list[0]) #获取[['username','password'],['baili','baili123'],['baili',"baili']]这个列表的第一个值的长度,第一个值就是需要参数化的变量名,列表的剩下的值都要跟这个值保持一直for data in data_list:if len(data)!=name_len:len_flag=Falseprint("paramtize的长度不一致请检查")break#如果长度没有问题str_caseinfo= yaml.dump(caseinfo)new_caseinfo=[]if len_flag:for x in range(1,len(data_list)): #读取值先从第二行进行读取也就是下标是1的进行读取因为第一行是参数的名字raw_caseinfo=str_caseinfofor y in range(0,name_len):# print(data_list[0][y],data_list[x][y]) #打印的第一个参数是第一行的第一列username,baili;password,baili123#针对参数化中有数字但是是字符串的进行处理if isinstance(data_list[x][y],str) and data_list[x][y].isdigit():data_list[x][y]="'"+data_list[x][y]+"'"raw_caseinfo = raw_caseinfo.replace("$ddt{" + data_list[0][y] + "}", str(data_list[x][y]))case_dict=yaml.safe_load(raw_caseinfo)case_dict.pop("paramtrize")new_caseinfo.append(case_dict)return new_caseinfo
8. extract_util.py(后续单独讲解)
import copy
import json
import reimport jsonpath
import yamlfrom commons.yaml_util import write_yaml, read_all
from hotload.debug_talk import DebugTalkclass ExtractUtil:# 解析提取变最def extract(self,res,var_name,attr_name,expr:str,index=None):#深拷贝,将res内容拷贝到new_res对象中去【注意:深拷贝出来的 是一个对象Object】# print(f"res打印{res}")new_res = copy.deepcopy(res)# 把json()改成json属性try:# 将json格式转化为字典格式,new_res.json 是 自己创建的变量new_res.json = new_res.json()except Exception:new_res.json = {"msg": 'response not json data'}# 通过反射获取属性的值data = getattr(new_res, attr_name)# print(f"data===============:{data}")# 判断通过什么提取方式提取数据if expr.startswith("$"):lis = jsonpath.jsonpath(dict(data), expr)# print("\nJSONPath提取返回来的值:", lis)else:lis = re.findall(expr, data)# print("\n正则表达式返回来的值:",lis)# 通过下标取值if lis:s=read_all()if index == None:if var_name in s:if isinstance(s[var_name], list):s[var_name].append(lis)else:s[var_name] = [s[var_name], lis]else:s[var_name]=liselse:if var_name in s:if isinstance(s[var_name], list):s[var_name].append(lis[index])else:s[var_name] = [s[var_name], lis[index]]else:s[var_name]=lis[index]write_yaml(s)# if index==None:# write_yaml({var_name: lis})# #更新yaml文件中的token值,list是你指定text或者json属性获取的内容# else:# write_yaml({var_name:lis[index]})#解析使用变量,把¥{access_token}替换从extract.yaml里面提取具体的值def change(self,request_data:dict):# 把字典转换成字符串data_str= yaml.safe_dump(request_data)# 字符串替换new_request_dat= self.hotload_replace(data_str)# 3.把字符串还原成字典data_dict = yaml.safe_load(new_request_dat)return data_dict#使用热加载方法,让yaml文件中可以使用python的一些方法def hotload_replace(self, data_str: str):# 定义一个正则匹配这种表达式# regexp ="\\$\V{(.*?)\\}"regexp = "\\$\\{(.*?)\\((.*?)\\)\\}" # ${函数名(参数)}# 通过正则表达式在data_str字符串中去四配,得到所有的表达式list"${name} is a ${token}"fun_list = re.findall(regexp, data_str)# print(fun_list) # [('number',"),('token','1,2')]for f in fun_list:# print(f)if f[1] == "": # 没有参数new_value = getattr(DebugTalk(), f[0])() #到DebugTalk()中找到以f[0]命名的函数进行调用获取得到的值# print("value1:%s" % new_value)else: # 有参数,1-N个参数new_value = getattr(DebugTalk(), f[0])(*f[1].split(","))# 如果value是一个数字格式的字符串if isinstance(new_value, str) and new_value.isdigit():new_value = "'" + new_value + "'"# 拼接旧的值old_value = "${" + f[0] + "(" + f[1] + ")}"# 把旧的表达式替换成函数返回的新的值data_str = data_str.replace(str(old_value), str(new_value))return data_str
9.main_util.py
一个测试用例执行流程:如果入参里面是上一个接口的响应,第一步数据替换,第二步发送请求,第三步获取响应,第四步响应中数据提取,第五步断言判断
from commons.assert_util import AssertUtil
from commons.extract_util import ExtractUtil
from commons.loging_util import caselog
from commons.requests_utils import RequestUtileu = ExtractUtil()
ru = RequestUtil()
au = AssertUtil()
def stand_case_flow(case_obj):new_request = eu.change(case_obj.request)# 发送请求res = RequestUtil().send_all_request(**new_request)caselog(case_obj.title, new_request, res.json())if case_obj.extract:for key, value in case_obj.extract.items():eu.extract(res, key, *value)if case_obj.validate:for assert_type, value in eu.change(case_obj.validate).items():au.assert_all_case(res, assert_type, value)else:print("此用例没有围言!")相关文章:

接口自动化--commons内容详解-02
上篇文章主要讲解了接口自动化主要架构框架,这篇文庄主要讲解commons中的内容 1. requests_utils.py 首先讲解这个工具类,主要是因为在接口自动化中,基本都有的接口都是发送请求,获取响应结果,唯一不同的是࿰…...

WanFangAi论文写作研究生论文写作神器在线生成真实数据,标注参考文献位置,表格公式代码流程图查重20以内,研究生论文写作技巧
WanFangAi是一个专业的学术论文辅助平台,它提供了一系列工具来帮助用户提升论文写作的效率和质量。以下是WanFangAi的一些核心功能:1.主题探索与文献搜索:用户可以输入关键词和研究领域,WanFangAi会迅速推荐合适的论文主题并提供相关的文献搜索服务。系统…...
 按键盘无效)
cv2.waitkey(30) 按键盘无效
cv2.imshow("detection", color_image) # 窗口显示,显示名为 Capture_Videok cv2.waitKey(100) & 0xFF # 每帧数据延时 1ms,延时不能为 0,否则读取的结果会是静态帧 if k ord(s): # 键盘按一下s, 保存当前照片和机械臂位姿…...

【洛谷】P10417 [蓝桥杯 2023 国 A] 第 K 小的和 的题解
【洛谷】P10417 [蓝桥杯 2023 国 A] 第 K 小的和 的题解 题目传送门 题解 CSP-S1 补全程序,致敬全 A 的答案,和神奇的预言家。 写一下这篇的题解说不定能加 CSP 2024 的 RP 首先看到 k k k 这么大的一个常数,就想到了二分。然后写一个判…...

Ubuntu24.04 安装ssh开启22端口及允许root用户远程登录
1、安装openssh-server插件开启22端口访问 # 安装ssh会默认启动服务并开启22端口 apt update apt install openssh-server 2、开启root用户远程访问 激活root用户,设置root用户登录密码 hunterlocalhost:/$ sudo passwd root New password: Retype new password…...

STM32基础学习笔记-DHT11单总线协议面试基础题7
第七章、DHT11: 单总线协!议 常见问题 1、DHT11是什么 ?有什么特性 ? 2、单总线协议是什么 ?原理 ?DHT11的单总线协议的组成 ? ## 1、DHT11定义 单总线协议是一种用于在多个设备之间进行通信的协议,所有…...
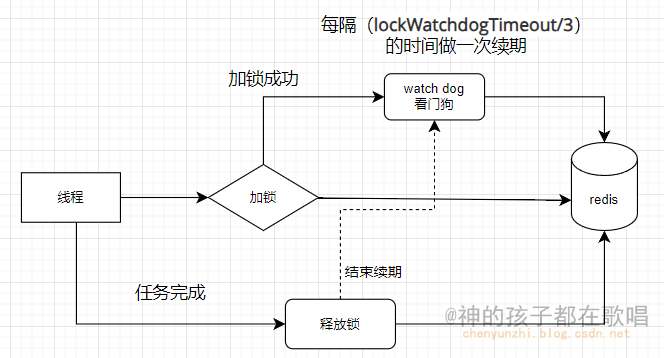
Redisson分布式锁的概念和使用
Redisson分布式锁的概念和使用 一 简介1.1 什么是分布式锁?1.2 Redisson分布式锁的原理1.3 Redisson分布式锁的优势1.4 Redisson分布式锁的应用场景 二 案例2.1 锁竞争案例2.2 看门狗案例2.3 参考文章 前言 这是我在这个网站整理的笔记,有错误的地方请指出ÿ…...

uniapp小程序持续获取用户位置信息,后台位置获取
做一个小程序持续获取用户位置信息的功能,即使小程序切换到后台也能继续获取,getLocation这个api只有小程序在前台才能获取位置,所以不用这个 先申请一个腾讯地图key 在uniapp项目配置源码视图里加上这个代码 先获取权限,再开启…...
优化算法(五)—梯度下降算法(附MATLAB程序)
梯度下降算法(Gradient Descent)是一种常用的优化算法,用于寻找函数的局部最小值。它通过沿着函数梯度的反方向迭代地调整变量,以逐步找到最优解。梯度下降广泛应用于机器学习和深度学习中,特别是在训练模型时优化损失…...

TypeScript 设计模式之【单例模式】
文章目录 **单例模式**: 独一无二的特工我们为什么需要这样的特工?单例模式的秘密:如何培养这样的特工?特工的利与害代码实现单例模式的主要优点单例模式的主要缺点单例模式的适用场景总结 单例模式: 独一无二的特工 单例模式就像是一个秘密组织里的特殊特工。这…...

UDP与TCP那个传输更快
UDP(用户数据报协议)和 TCP(传输控制协议)是互联网协议栈中常用的两种传输层协议。它们在设计和应用上存在一些显著的差异,导致在传输速度和可靠性等方面表现不同。以下是它们之间的比较,特别是关于传输速度…...
如何把PDF样本册转换为网址链接
随着互联网的普及,将纸质或PDF格式的样本册转化为网址链接,以便于在线浏览和分享,变得越来越重要。本文将为您详细讲解如何将PDF样本册转换为网址链接,让您轻松实现线上展示和分享。 一、了解PDF样本册与网址链接 1. PDF样本册…...

centos7 semanage 离线安装 SELinux
centos7 semanage 离线安装 还是参考一下 换成阿里云的源 之后 ,在线更新不,不要用离线安装 centos7 更新 yum源 为 阿里云 LTS https://blog.csdn.net/wowocpp/article/details/142517908 CentOS7安装时使用"基础服务器"选项安装, 后发现没…...

磨具生产制造9人共用一台工作站
随着技术的不断进步与工业自动化的深入发展,如何优化生产流程、提高设备利用率成为了众多企业面临的重大课题。那么在磨具生产制造中实现9人共用一台工作站呢? 一、背景与挑战 在磨具制造行业,高精度、高效率的生产要求与复杂多变的工艺流程…...

Qt clicked()、clicked(bool)、toggled(bool)信号的区别和联系
clicked() 信号 所属控件:clicked()信号是QAbstractButton类(及其子类,如QPushButton、QRadioButton、QCheckBox等)的一个信号。clicked信号可以说是许多控件(特别是按钮类控件,如QPushButton)…...

nginx实现负载均衡的分发策略
文章目录 分发策略 分发策略 轮询策略 轮询策略是最简单的负载均衡策略之一。Nginx 默认采用轮询方式将请求分发到不同的后端服务器。它将请求按照顺序轮流分配给每个后端服务器,不论服务器当前的负载情况如何。这种策略适合后端服务器性能相近且无太大差异的场景。…...

【Python】用代码片段掌握Python核心功能
探索各种用户输入值 Python 是一种多才多艺的编程语言,广泛应用于从 Web 开发到数据分析的各种场景。这篇文章将通过实际的代码片段带你了解 Python 中的几个基本概念和操作。无论你是初学者还是想重温一下知识点,这些例子都会给你带来宝贵的见解。 输…...

JVM 内存模型
JVM 内存模型 对于 Java 程序员来说,在虚拟机自动内存管理机制下,不再需要像 C/C程序开发程序员这样为每一个 new 操作去写对应的 delete/free 操作,不容易出现内存泄漏和内存溢出问题。正是因为 Java程序把内存控制权利交给 JVM 虚拟机。一旦出现内存泄漏和溢出方面的问题,如果…...

Linux2.6* 内核默认支持的文件系统
Linux2.6* 内核默认支持的文件系统 Btrfs是一种具有先进特性的写时复制文件系统。支持多种高级功能,如快照、透明压缩、数据校验和自我修复等,适用于大规模存储系统和数据可靠性要求较高的场景。JFSJournaled File System日志文件系统,具有高…...

PMP--二模--解题--111-120
文章目录 7.成本管理111、 [单选] 你向项目出资人提供了项目的成本估算,他对估算不满意,因为他认为价格太高了。他要你削减项目估算的15%,你该怎么做? 8.质量管理112、 [单选] 在新建水处理厂的建设过程中,政府对处理厂…...

Chrome扩展开发实战:打造浏览器侧边栏ChatGPT助手
1. 项目概述:一个让ChatGPT常驻浏览器侧边栏的利器如果你和我一样,每天的工作和学习都离不开浏览器,并且频繁地与ChatGPT对话来获取灵感、润色文案或者调试代码,那么你肯定对在无数个标签页之间来回切换感到厌烦。每次都要打开一个…...

从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界
从内存视角拆解float和double:用C语言和调试器带你‘看见’IEEE754的二进制世界 在计算机科学中,浮点数的表示和处理是一个既基础又关键的话题。对于从事系统编程、性能优化或逆向工程的开发者来说,理解浮点数在内存中的实际存储形式不仅能帮…...

智能路由器项目解析:基于策略路由实现多线路流量智能调度
1. 项目概述:一个“聪明”的路由器能做什么?最近在GitHub上看到一个挺有意思的项目,叫smart-router,作者是c0nSpIc0uS7uRk3r。光看名字,你可能会觉得这又是一个关于家庭网络优化的工具,但点进去仔细研究后&…...

计算机科学第三难题:“树映射”问题在文件、写作、建筑、生物分类中无处不在!
计算机科学第三难题:将通用图映射到层次结构,“树映射”问题无处不在 根据一个归属于 菲尔卡尔顿 的 经典笑话,计算机科学只有两个难题:命名和缓存失效。这两个问题之所以难,是因为没有算法可以解决它们:好…...

芯片老化座的工作温度范围?
在芯片测试领域,老化座(Burn-in Socket)是保障半导体器件长期可靠性的关键设备。它不仅要在极端温度下稳定工作,还要确保测试数据的精准度。今天,我们以HMILU(深圳市鸿怡电子有限公司)为例&…...

Obsidian智能模板终极指南:3步打造高效笔记自动化系统
Obsidian智能模板终极指南:3步打造高效笔记自动化系统 【免费下载链接】Templater A template plugin for obsidian 项目地址: https://gitcode.com/gh_mirrors/te/Templater Templater插件是Obsidian生态系统中功能最强大的智能模板解决方案,它能…...

dotai:将AI大模型无缝集成到Shell终端的智能助手工具
1. 项目概述:当AI遇上你的终端如果你是一个重度命令行用户,每天在终端里敲击着ls、cd、git commit这些命令,有没有那么一瞬间,希望有个助手能帮你自动补全、解释命令,甚至直接帮你写出复杂的管道操作?dotai…...

基于MCP协议的AI Agent远程SSH安全操作实践指南
1. 项目概述与核心价值最近在折腾AI Agent的开发,发现一个挺有意思的现象:很多开发者都卡在了“如何让AI安全、可控地操作远程服务器”这一步。你可能会想到直接给AI一个SSH私钥,但这无异于把自家大门的钥匙扔给一个还在学习走路的机器人&…...

探索下一代命令行界面:OpenCLI 架构设计与插件化实践
1. 项目概述:一个面向未来的命令行界面原型最近在开源社区里,我注意到一个名为sys-fairy-eve/nightly-mvp-2026-03-19-opencli的项目。这个标题信息量不小,它不像一个成熟的产品,更像是一个开发过程中的里程碑快照。sys-fairy-eve…...
)
【限时解密】ElevenLabs未文档化的/v1/text-to-speech/{voice_id}/with-timing接口:获取逐词时间戳+音素级对齐数据(仅剩3个Beta白名单通道)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs英文语音生成的核心能力与技术定位 ElevenLabs 是当前业界领先的 AI 语音合成平台,其英文语音生成能力建立在自研的端到端神经声学模型(如 ElevenMultilingualV2&…...