Linux 基础IO 2
读取与写入
read与fread
在基础IO 1中我们学会了open和fopen的函数这两个函数是用于为进程打开文件也可以理解为为进程和文件建立了一个链接使其可以交互。那我们建立号链接之后肯定还是需要对文件进行操作,现在我们先来了解读取操作。
read:
这是一个系统调用函数,从文件中读取数据。
头文件:
#include <unistd.h>
函数原型:
ssize_t read(int fd, void *buf, size_t count);
参数:
fd :文件描述符,代表了需要读取的文件或设备。文件描述符可以通过调用 open 或其他文件操作函数获取。
buf :一个指向用户分配的缓冲区的指针,read 将把读取到的数据写入该缓冲区。
count :需要读取的字节数,表示最多读取 count 字节数据。
返回值:
若成功,read 返回读取的字节数(0表示已到达文件末尾)。
若失败,返回 -1,并设置 errno 来指示具体错误。

在读取的时候我们需要先定义一个缓冲区,这里我们定义了一个字符数组buff来接收读取到的数据。read是默认阻塞读取的函数,若是读取数据的请求还没完成会一直阻塞等待。我们可以在open函数中设置非阻塞模式O_NONBLOCK。
错误:
EINTR:调用被信号中断。
EIO:发生I/O错误(如硬件故障)。
EINVAL:参数不合法,比如文件描述符不是合法的读取对象。
EBADF:文件描述符无效,可能因为文件未打开或者以不适合的方式打开(如只写模式下无法读取)。
EFAULT:缓冲区地址不合法
fread:
fread是一个C标准库函数
头文件:
#include <stdio.h>
函数原型:
size_t fread(void*buff , size_t size, size_t count , FILE* stream);
参数:
buff:指向存储读取数据的缓冲区。
size:每个数据项的字节数。
count:要读取的数据项的个数。
stream:指向FILE对象的指针,表示要读取的文件。

与read一样需要先定义一个接收缓冲区来接收读取的数据。与read不同的是这里的读取是按照一定格式读取的,第二个参数就是一个数据类型的大小如我们若是整形的话这里就是4字节若是自定义类型就计算出类型的大小填入,第三个则是读取多少个这样的数据若第二个参数为4则这里就是读取10个4字节的数据。与read不同的还有一点,fread有一个用户级的缓冲区。
write与fwrite
若我们的程序产生了一些数据需要存储那么我们不能把它一直放在内存中而是需要写入到文件中去这需要使用write和fwrite函数这两个都是输出函数也就是执行写入操作的函数。
write:
这是个系统调用,会将数据从缓冲区写入到指定的文件中。
头文件:
#include <unistd.h>
函数原型:
ssize_t write(int fd, const void *buf, size_t count);
参数:
fd :文件描述符,代表了需要读取的文件或设备。文件描述符可以通过调用 open 或其他文件操作函数获取。
buf :一个指向用户分配的缓冲区的指针,read 将把读取到的数据写入该缓冲区。
count :需要读取的字节数,表示最多读取 count 字节数据。
返回值:
若成功,write 返回读取的字节数(0表示已到达文件末尾)。
若失败,返回 -1,并设置 errno 来指示具体错误。

这里我们定义了一个缓冲区buf里面存放了”i like linux\n“,write函数就会将buf中的数据写入带fd所代表的文件中。
错误:
EBADF: 参数fd不是有效的文件描述符或者不支持写操作。
EIO: I/O错误发生。
ENOSPC: 设备上没有剩余空间。
fwrite:
是一个C标准库函数功能与write相似,与fread一样会有一个用户级的缓冲区。
头文件:
#include <stdio.h>
函数原型:
size_t fread(void* buff,size_t size,size_t count,FILE* stream);
参数:
buff:指向存储写入数据的缓冲区。
size:每个数据项的字节数。
count:要写入的数据项的个数。
stream:指向FILE对象的指针,表示要写入的文件。

小结
其实无论是输入输出系统调用函数还是C标准库函数做的工作本质都是数据的拷贝,输入是将系统缓冲的数据拷贝进进程的空间中,输出就是将进程缓冲区数据拷贝到系统缓冲区中,然后通过刷新到屏幕上显示出来。只是输入和输出拷贝的方向不同。而C标准库的输入输出函数还会有一个用户级的缓冲区来存放数据这个可以根据实际需要自定义大小,系统调用的函数也有缓冲区,这个缓冲区是设置好的属于系统内核的,缓冲区的作用主要是增加系统的效率。
缓冲区刷新
缓冲区是为了可以提高数据传输的效率而设置的,因为向文件写入读取数据可能不是连续而是断续的,而每次读取写入数据都需要转换到内核中并找到文件所在位置和当前文件位置就是载入相关属性数据也会消耗cpu资源所以有了缓冲区可以一次性读取写入一段较为完整的数据。
刷新方式:
一般数据刷新有三种方式
无缓冲:数据立刻刷新没有缓冲区机制
行刷新:一般系统内核用的就是这种,完成一行的数据就刷新一行,若是一行不满就会等待其满,这里的满不一定是缓冲区写满,类似换行也会刷新,所以当我们使用printf,cout的时候若后面没有加上\n那么可能这个数据不会显示出来或者是跟着其他数据一起显示出来,就是因为这些数据在缓冲区中并没有冲刷。
全缓冲:缓冲区全满的时候一次性刷新,我们在磁盘上拷贝数据就是使用的这种。所以我们平时拷贝数据的时候会一段时间很慢,然后一段时间速度突然就快起来了然后又变慢了就是因为缓冲区机制。
其他刷新机制:
fflush函数:参数是文件指针这是一个C语言的库函数对应着fread,fwrite使用。给他一个文件指针会将文件对应的缓冲区数据冲刷出去。
进程结束:当一个进程结束时操作系统会冲刷掉它的所有缓冲区
系统缓冲区强制刷新在linux上可以使用sync指令,在进程内就是 system(”sync“);system函数的头文件是 stdlib.h ,这个指令还有其他选项有兴趣可以区了解下。
相关文章:
Linux 基础IO 2
读取与写入 read与fread 在基础IO 1中我们学会了open和fopen的函数这两个函数是用于为进程打开文件也可以理解为为进程和文件建立了一个链接使其可以交互。那我们建立号链接之后肯定还是需要对文件进行操作,现在我们先来了解读取操作。 read: 这是一…...

图像预处理 图像去噪之常见的去噪方法
图像去噪是图像预处理中的一项关键技术,其目的是从含有噪声的图像中恢复出无噪声的图像,以提高图像质量和后续图像分析的准确性。图像去噪方法众多,本文将介绍几种常见的去噪方法,并提供相应的代码示例。 1. 均值滤波(…...

代码随想录Day53|102.沉没孤岛 、103.水流问题 、104.建造最大岛屿
102.沉没孤岛 import java.util.*;class Main{public static int[][] dir {{0,1},{1,0},{0,-1},{-1,0}};public static void main (String[] args) {Scanner sc new Scanner(System.in);int n sc.nextInt();int m sc.nextInt();int[][] grid new int[n][m];for(int i 0…...

19c-pfile
经常需要rman恢复测试,创建一个单机pfile,需要时手动修改使用,以20g内存为例 orcl.__data_transfer_cache_size0 orcl.__db_cache_size13824425984 orcl.__inmemory_ext_roarea0 orcl.__inmemory_ext_rwarea0 orcl.__java_pool_size0 orcl._…...

智能软件开启精准品牌控价
在当今竞争激烈的商业世界中,品牌的价值如同璀璨的明珠,需要精心呵护。而价格管控,则是守护这颗明珠的关键防线。 当面对众多的产品和 SKU 时,传统的人力监测已显得力不从心。此时,力维网络自主开发的数据监测系统如同…...

OpenCV特征检测(8)检测图像中圆形的函数HoughCircles()的使用
操作系统:ubuntu22.04 OpenCV版本:OpenCV4.9 IDE:Visual Studio Code 编程语言:C11 算法描述 在灰度图像中使用霍夫变换查找圆形。 该函数使用霍夫变换的一种修改版本在灰度图像中查找圆形。 例子: #include <opencv2/imgp…...

spark 大表与大表join时的Shuffle机制和过程
在 Spark 中,当处理大表与大表的 JOIN 操作时,通常会涉及到 Shuffle 机制,这是分布式计算中用于重新分布数据的关键步骤。Shuffle 的本质是将数据按照某种方式重新分组,使得相同 key 的数据能够被发送到同一个计算节点进行后续的操…...

大厂面试真题:简单说下Redis的bigkey
什么是bigkey bigkey是指key对应的value所占的内存空间比较大,例如一个字符串类型的value可以最大存到512MB,一个列表类型的value最多可以存储23-1个元素。 如果按照数据结构来细分的话,一般分为字符串类型bigkey和非字符串类型bigkey。 字…...
18 vue3之自动引入ref插件深入使用v-model
自动引入插件后无需再引入ref等 使用自动引入插入无需在import { ref, reactive } from "vue"做这样的操作 npm i unplugin-auto-import - D vite配置 import AutoImport from unplugin-auto-import/vite //使用vite版本 export default defineConfig({plugins: [v…...

【Spring】lombok、dbUtil插件应用
一、lombok插件 1. 功能:对实体类自动,动态生成get、set方法,无参、有参构造..... 2. 步骤: (1)idea安装插件(只做一次) (2)添加坐标 (3)编写注解 NoArgsCo…...

【学习笔记】WSL
WSL 1、 介绍 1.1、概述 1.2、版本 1.3、配置安装 2、 基本 2.1、基本命令 1、 介绍 1.1、概述 WSL 是 Windows Subsystem for Linux 的缩写,中文称为 Windows 下的 Linux 子系统。它是微软在 Windows 上提供的一种功能,允许用户在 …...

python assert 断言用法
语法: try:assert 条件表达式, "可选的错误消息" except AssertionError as error:print(f"断言失败:{error}")其中, try...except是异常处理语法结构,try可以测试代码块中的错误,并在出现异常时…...

MySQL事务、索引、数据恢复和备份
MySQL事务、索引、数据恢复和备份 1.MySQL的事务处理 事务就是将一组SQL语句放在同一批次内去执行 如果一个SQL语句出错,则该批次内的所有SQL都将被取消执行 MySQL的事务实现方法 : SET AUTOCOMMIT 使用SET语句来改变自动提交模式 SET AUTOCOMMIT 0; # 关…...

什么是chatgpt?国内有哪些类gpt模型?
什么是ChatGPT? “ChatGPT”这个名字越来越多地出现在我们的生活中。简单来说,ChatGPT是OpenAI开发的一种人工智能对话模型。它基于GPT(Generative Pre-trained Transformer,生成式预训练变换模型)架构,能…...
)
ISP基本框架及算法介绍 ISP(Image Signal Processor)
ISP基本框架及算法介绍 ISP(Image Signal Processor),即图像处理,主要作用是对前端图像传感器输出的信号做后期处理,主要功能有线性纠正、噪声去除、坏点去除、内插、白平衡、自动曝光控制等,依赖于ISP才能在不同的光学条件…...

Stable Diffusion 的 ControlNet 主要用途
SD(Stable Diffusion)中的ControlNet是一种条件生成对抗神经网络(Conditional Generative Adversarial Network, CGAN)的扩展技术,它允许用户通过额外的输入条件来控制预训练的大模型(如Stable Diffusion&a…...

矩阵分析 学习笔记4 内积与Gram矩阵
内积 定义 由于对称,第二变元线性那第一变元也线性了。例如这个:...

iOS 消息机制详解
应用 解决NSTimer、CADisplayLink循环引用。 二者都是基于runloop的定时器,由于处理事件内容不一样,runloop 每运行一次运行耗时就不一样,无法准确的定时触发timer的事件。 NSProxy 与 NSObject 如果继承自NSProxy 直接开始消息转发&…...

深入理解Spring Data JPA与接口编程
目录 1. 什么是Spring Data JPA? 2. 如何使用Spring Data JPA? 3. 示例代码 4. 使用Query注解 5. 拓展知识:接口编程的好处 6. 结论 在软件开发领域,接口(Interface)是一种定义了方法签名但没有实现的…...
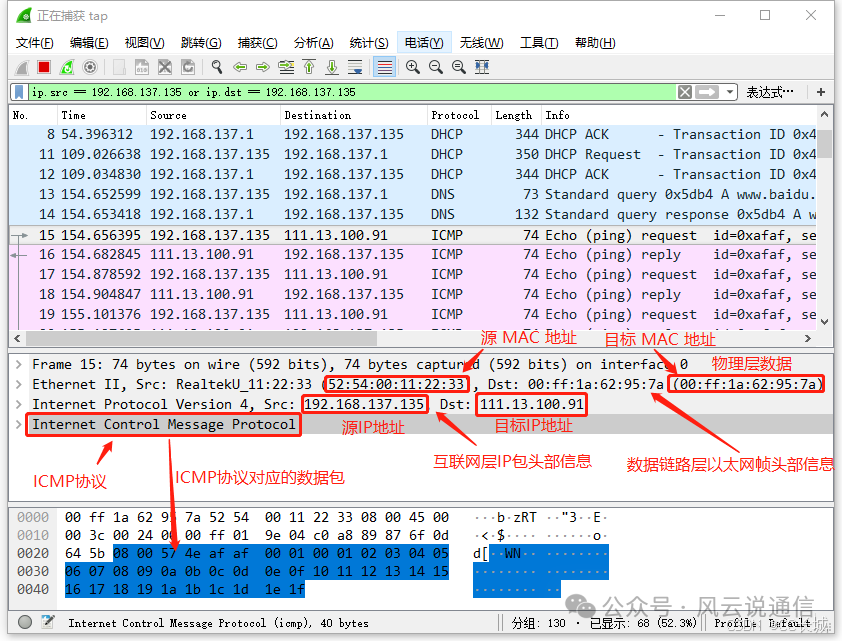
Wireshark学习使用记录
wireshark 是一个非常好用的抓包工具,使用 wireshark 工具抓包分析,是学习网络编程必不可少的一项技能。 原理 Wireshark使用的环境大致分为两种:一种是电脑直连互联网的单机环境,另外一种就是应用比较多的互联网环境,也就是连接…...

HttpOnly Cookie 深度解析
一、什么是 HttpOnly Cookie HttpOnly 是一个可以附加在 Set-Cookie 响应头上的标志位(flag)。当一个 Cookie 被标记为 HttpOnly 后,客户端脚本(如 JavaScript)将无法通过 document.cookie 等 API 访问该 Cookie&…...
)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点)
从SolidWorks到Geant4仿真:我的第一个粒子探测器CAD模型导入全记录(含CADMesh避坑点) 作为一名刚接触粒子探测器仿真的研究生,我花了整整两周时间才成功将SolidWorks设计的模型导入Geant4进行模拟。这个过程远比想象中复杂&#x…...

ArcSWAT建模踩坑记:你的土壤数据库参数算对了吗?聊聊SPAW的那些默认值和单位陷阱
ArcSWAT土壤参数校准实战:避开SPAW计算中的5个致命误区 当水文模拟结果与实测数据出现系统性偏差时,经验丰富的建模者会首先检查土壤参数——这个隐藏在界面背后的"沉默变量"往往是误差的最大来源。SPAW作为ArcSWAT推荐的土壤参数计算工具&…...

暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手
暗黑3鼠标宏终极指南:D3KeyHelper 5步配置法快速上手 【免费下载链接】D3keyHelper D3KeyHelper是一个有图形界面,可自定义配置的暗黑3鼠标宏工具。 项目地址: https://gitcode.com/gh_mirrors/d3/D3keyHelper D3KeyHelper是一款专为暗黑破坏神3玩…...

Arm Neoverse CMN-700互连架构与协议寄存器配置指南
1. Arm Neoverse CMN-700一致性互连架构解析在现代多核处理器设计中,一致性互连网络如同城市交通系统般重要。Arm Neoverse CMN-700作为第二代Coherent Mesh Network解决方案,其架构设计充分考虑了数据中心和边缘计算的严苛需求。与传统的总线或环形拓扑…...

δ - mem:提升大型语言模型内存效率,得分最高可达 1.31 倍!
快速通道可了解 arXiv 成为独立非营利组织的情况,也能直达康奈尔大学官网。同时,还能通过链接进行捐赠,支持 arXiv 的发展。搜索与导航提供了多种搜索途径,可在所有字段(标题、作者、摘要等)进行搜索。还有…...

镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书
镜像空间全域透视,赋能多维场景一体化透明数智治理技术白皮书副标题:聚合动态三维实时重构、无感厘米级定位、全域跨镜连续追踪、身体指纹生物核验四大自研核心,一站式覆盖楼宇、仓储、硐室全场景透明智能管控前言当下城市建筑楼宇、物资仓储…...

使用mcp-maker快速构建AI工具集成服务器:从MCP协议到实践
1. 项目概述:一个为AI应用注入“超能力”的MCP服务器工厂 如果你最近在折腾AI应用开发,特别是想给ChatGPT、Claude这类大模型配上“手和脚”,让它们能操作你的本地文件、查询数据库,甚至控制你的智能家居,那你大概率已…...

树莓派机械爪项目实战:从硬件连接到Python控制全解析
1. 项目概述:当树莓派遇上机械爪最近在折腾一个挺有意思的小项目,叫Demwunz/openclaw-pi-installation。光看这个名字,就能猜到个大概:这是一个为树莓派(Raspberry Pi)准备的机械爪(Claw&#x…...

Navis:开源项目标准化开发环境与工具链配置框架实践
1. 项目概述:一个为开发者打造的“导航星图”如果你和我一样,常年混迹在开源项目的海洋里,那么你一定对这种感觉不陌生:面对一个全新的、功能强大的开源工具,兴奋地克隆了仓库,然后……就卡在了第一步。REA…...