【关于Linux中----多线程(一)】
文章目录
- 认识线程
- 创建线程
- 线程优点和缺点
- 创建一批线程
- 终止线程
- 线程的等待问题
认识线程
- 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”
- 一切进程至少都有一个执行线程
- 线程在进程内部运行,本质是在进程地址空间内运行
- 在Linux系统中,在CPU眼中,看到的PCB都要比传统的进程更加轻量化
- 透过进程虚拟地址空间,可以看到进程的大部分资源,将进程资源合理分配给每个执行流,就形成了线程执行流
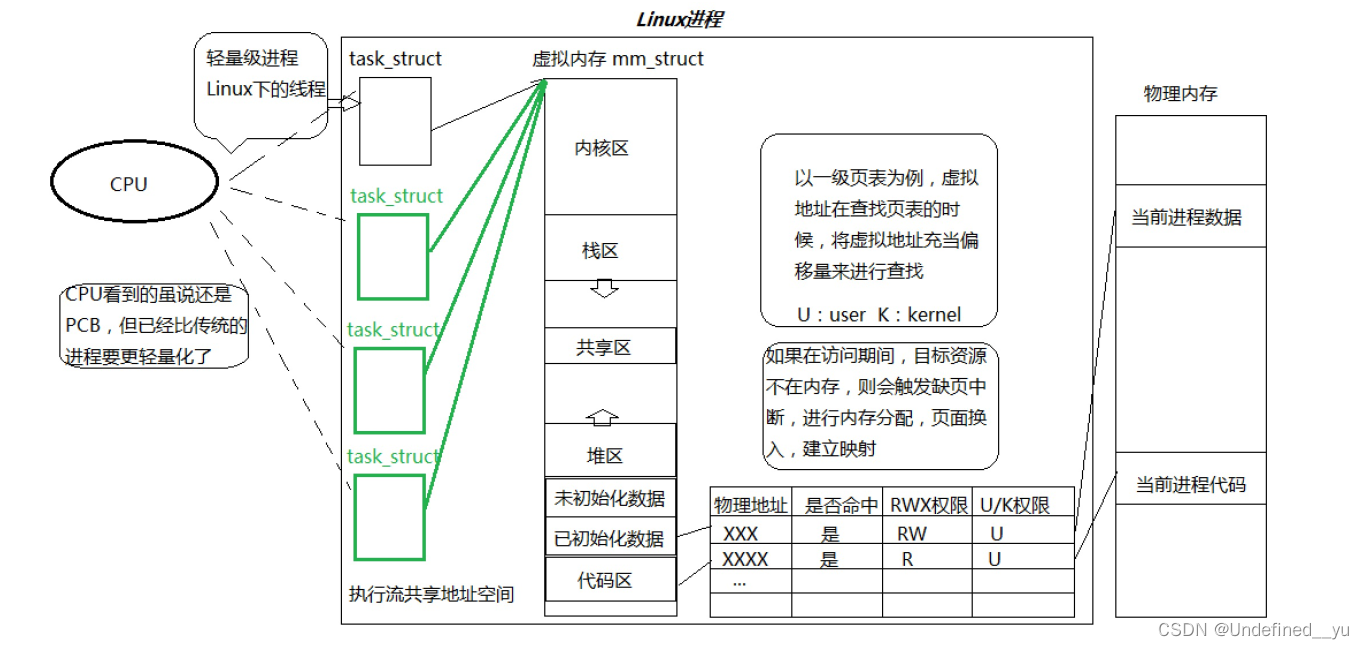
上面这张图中出现的内容都已经在前面的文章中解释过,这里再对页表内容做一个补充。
我们都知道,在语言中,定义在常量区中的变量是不可被修改的,为什么?
答:常量区存在于已初始化数据和代码区之间。当修改常量区中的内容时,要先找到变量所在的地址,再经过页表映射到具体的物理内存进行操作。但是在页表映射时,页表会检查RWX权限和要进行的操作。常量区的变量所具有的权限是R,所以自然不能进行写操作。MMU就会向硬件报错,进而被OS所识别,然后会将报错转变成信号(段错误)发送给进程,然后进程会以默认动作(终止)来处理该进程。
如何看待进程地址空间和页表?
- 地址空间是进程能看到的资源窗口
- 页表决定进程真正拥有资源的情况
- 合理地对页表和地址空间进行资源划分就可以对一个进程所有的资源分类
进程地址空间是如何经过页表找到具体的物理内存的?
首先,OS要对物理内存进行管理,就要把物理内存分成一个个的物理页(每一个物理页大小为4KB),每一个物理页都有描述自己属性的结构体,然后OS会用数组的方式来组织起所有的物理页,进而管理整个物理内存。
而内存中的数据与物理内存进行交互时,传输数据的单位也是4KB(这样的一块数据在磁盘中叫做页帧)。最后,OS会用特定的管理算法对所有物理页进行管理。
以32为平台为例,每一个虚拟地址都有32个比特位。而虚拟地址经过页表映射时,不是将32个比特位直接映射到物理内存,而是将虚拟地址划分为10个、10个和12个比特位进行三次映射,最后到达具体的物理内存。
页表包括页目录和页表项:
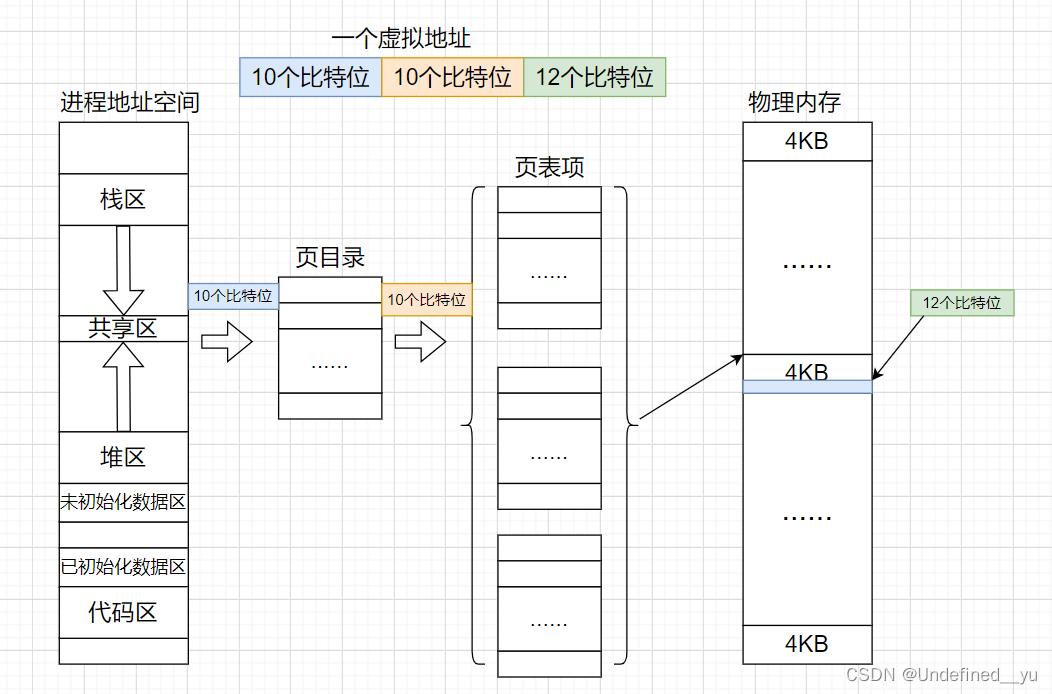
前10个比特位一共有1024个组合,所以页目录里也会有1024个与之对应的位置,页表项也是如此。
现根据前十个比特位在页目录中找到具体的页表项,再根据下一组十个比特位在页表项中找到物理内存中的具体某一个物理页,最后根据后十二个比特位(相对物理页起始位置的偏移量)找到数据在物理页中的具体位置。
而每一个物理页的大小是4KB,也就刚好对应后12个比特位可能出现的组合的数量。
以上是对进程概念的补充。在我之前的文章中解释的进程就是内核数据结构+进程对应的代码和数据。而现在要说的线程就是进程内的一个执行流。
如何理解“线程是进程内的一个执行流”?
上文中说了“虚拟内存决定了进程能看到的资源”,而当我们用fork创建子进程时,可以让父进程和子进程分别执行不同的操作。
那么如果我们现在创建一批子进程,但是只给这些子进程创建属于自己的PCB,而不给它们创建进程地址空间和页表等,并把它们的PCB指向和父进程一样的进程地址空间,再把进程地址空间中的各个区域划分给不同的子进程供其使用(同时将部分资源划分给子进程)。这时,这些子进程就相当于父进程中的执行流,而我们也可以认为新创建出的一个个PCB就是一个个线程。
而因为我们可以通过进程地址空间+页表的方式对进程进行资源划分,所以单个线程的执行力度一定会比原来的进程更细节。
创建线程
如果OS要设计线程的概念,那么要不要对线程进行管理?如何管理?
答:如果有线程的概念,就一定要想办法对其进行管理,而管理的方法就像进程一样,要为它设计专门的数据结构来表示一个线程对象,再把它们组织起来。而Windows中就是这么做的,其中描述线程的数据结构叫做TCB。
可是,如果有了线程的概念和数据结构,当它被调度执行的时候,就一定需要ID 状态 优先级 上下文 栈等概念,这样看来,线程和进程有很多方面都是重复的。所以早期的Linux工程师们就不再专门设计“线程”的概念,而是直接对进程中的PCB进行复用,就成了我们现在所说的“线程”。
所以,Linux中根本就不存在线程的概念。在Linux中,进程就是承担分配操作系统资源的的基本实体,而线程是CPU调度的基本单位。一个进城内部可以有多个执行流,而认为单个进程内部只有一个执行流。
下面用代码证明一下以上内容:
首先要了解创建线程的函数:
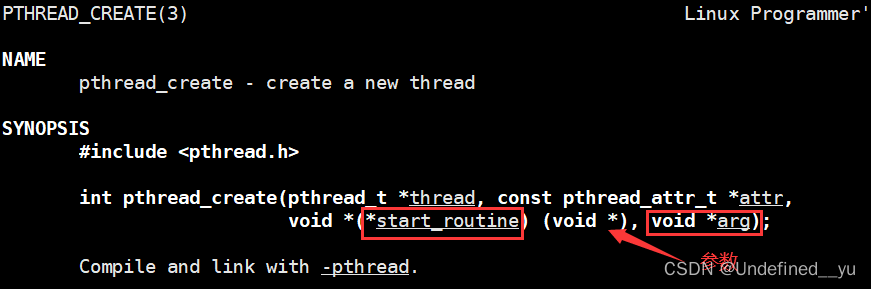
代码如下:
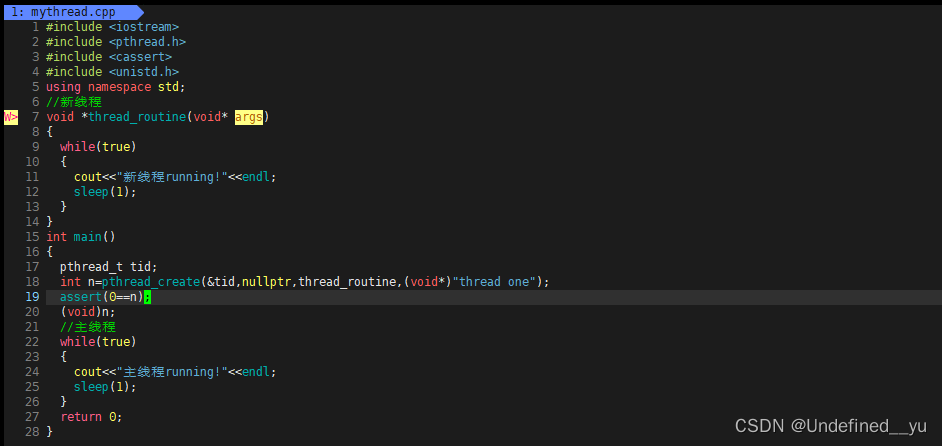
对应的Makefile内容如下:

运行结果如下:
[sny@VM-8-12-centos practice]$ make clean;make
rm -f mythread
g++ -o mythread mythread.cpp
/tmp/ccLOh0U0.o: In function `main':
mythread.cpp:(.text+0x53): undefined reference to `pthread_create'
collect2: error: ld returned 1 exit status
make: *** [mythread] Error 1
[sny@VM-8-12-centos practice]$
出现这种情况的原因是,找不到创建线程所依赖的库。
因为Linux没有为创建线程专门的系统调用接口,所以只能依赖库来实现,解决方案如下:

(这部分在前面动静态库的文章中有解释)
[sny@VM-8-12-centos practice]$ vim Makefile
[sny@VM-8-12-centos practice]$ make clean;make
rm -f mythread
g++ -o mythread mythread.cpp -lpthread
[sny@VM-8-12-centos practice]$ ls
core.30230 Makefile mytest mythread mythread.cpp
[sny@VM-8-12-centos practice]$
运行成功!
程序所连接到的库如下:
[sny@VM-8-12-centos practice]$ ldd mythreadlinux-vdso.so.1 => (0x00007ffcc13dc000)libpthread.so.0 => /lib64/libpthread.so.0 (0x00007f0b44956000)libstdc++.so.6 => /home/sny/.VimForCpp/vim/bundle/YCM.so/el7.x86_64/libstdc++.so.6 (0x00007f0b445d5000)libm.so.6 => /lib64/libm.so.6 (0x00007f0b442d3000)libgcc_s.so.1 => /lib64/libgcc_s.so.1 (0x00007f0b440bd000)libc.so.6 => /lib64/libc.so.6 (0x00007f0b43cef000)/lib64/ld-linux-x86-64.so.2 (0x00007f0b44b72000)
[sny@VM-8-12-centos practice]$ ls /lib64/libpthread.* -al
-rw-r--r-- 1 root root 152194 May 19 2022 /lib64/libpthread.a
-rw-r--r-- 1 root root 222 May 18 2022 /lib64/libpthread.so
lrwxrwxrwx 1 root root 18 Jul 25 2022 /lib64/libpthread.so.0 -> libpthread-2.17.so
[sny@VM-8-12-centos practice]$
libpthread-2.17.so这个库叫做用户线程库/原生线程库,任何Linux系统都必须含有,在其内部实际上含有系统调用接口。
对于上面的代码,如果两个线程在一个执行流中,就不可能同时运行两个while循环。所以,根据运行结果就可以验证“线程是进程中的一个执行流”以及“一个进程中可以有多个执行流”的说法,结果如下:
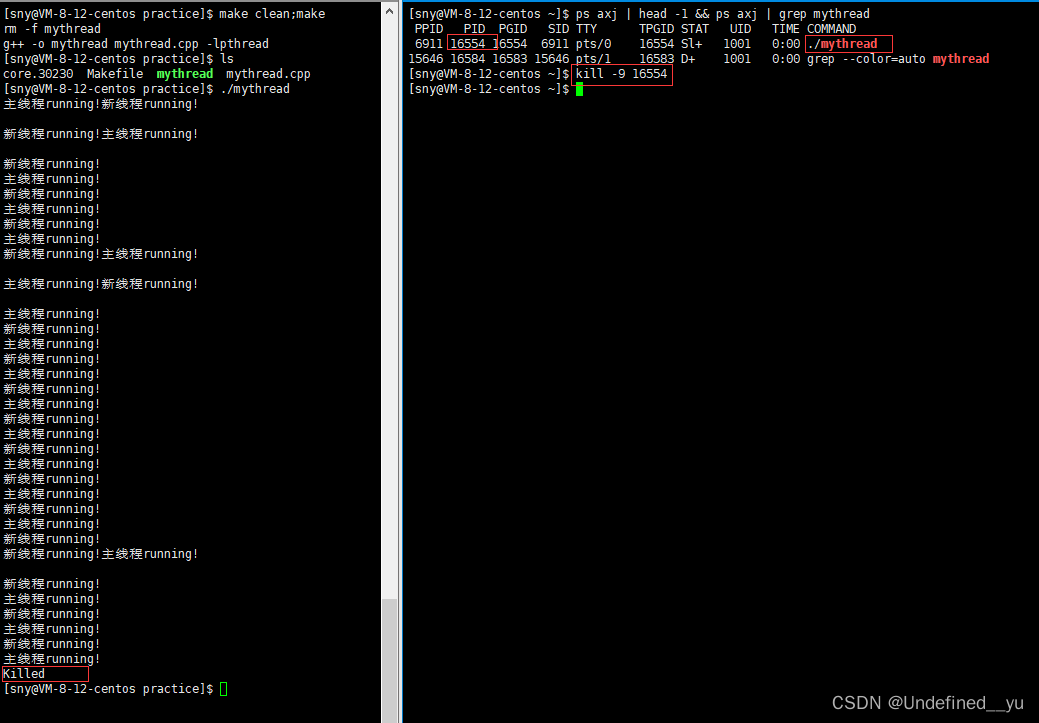
通过运行结果可以里看到,虽然有两个线程在跑,但系统中只有一个进程,也就是说两个执行流在同一个进程内,当kill掉这个进程之后,两个线程都被终止了。
那么怎么查看两个执行流具体的信息?
方法如下:
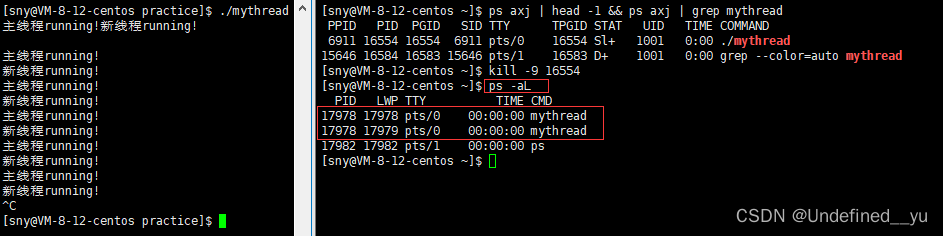
执行ps -aL命令可以看到连个线程。
上面两个线程PID相同,但是LWP不相同,LWP即为light weight process,也就是轻量级进程。
另外,可以看到第一个线程的LWP和PID是相同的!!!这表明第一个线程为主线程,第二个线程为新线程。
所以,CPU进行调度时,是以LWP为标识符表示一个特定的执行流的(只不过之前代码中每个进程只有一个执行流,所以PID和LWP没区别)
下面来验证一下pthread_create的第四个参数是第三个参数指向的函数的参数这句话,对代码稍作改动,如下:
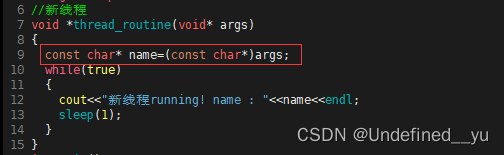
结果如下:
[sny@VM-8-12-centos practice]$ make clean;make
rm -f mythread
g++ -o mythread mythread.cpp -lpthread
[sny@VM-8-12-centos practice]$ ./mythread
主线程running!新线程running! name : thread one
主线程running!
新线程running! name : thread one
新线程running! name : 主线程running!thread one
^C
[sny@VM-8-12-centos practice]$
接下来看一下pthread_create的第一个参数(tid)的值:
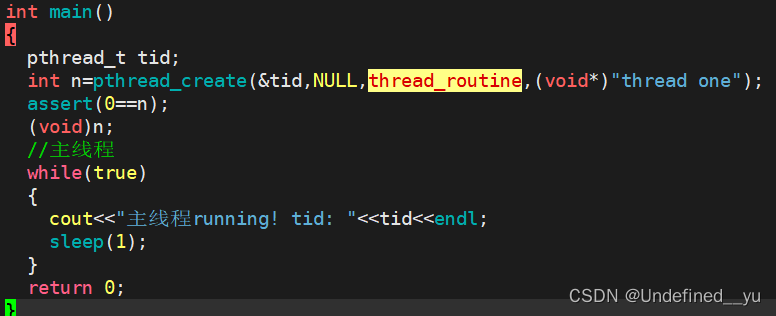
结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
主线程running! tid: 新线程running! name : thread one140114343909120主线程running! tid: 140114343909120
新线程running! name : thread one
主线程running! tid: 140114343909120新线程running! name :
thread one
这一长串数字显然看不懂什么意思,用十六进制输出一下试试:
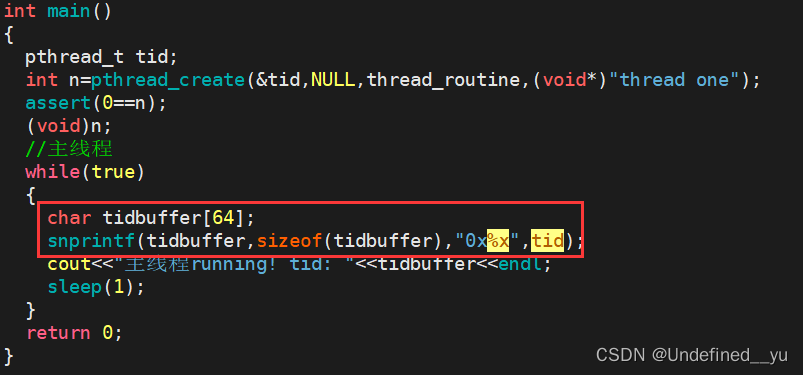
结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
主线程running! tid: 0xdb2f1700新线程running! name : thread one
新线程running! name : thread one主线程running! tid: 0xdb2f1700
主线程running! tid: 0xdb2f1700新线程running! name :
thread one
现在还是看不懂,暂且先把这个问题放在这儿,下文再做解释。
现在开始一个新的话题:线程一旦被创建,几乎所有的资源都是被所有的线程所共享的。也就是说,一个进程中的不同执行流可以看到彼此所能看到的资源,当其中一个执行流更改数据时,其他执行流也可以看到更改后的数据。(感兴趣的可以自己写一小段代码验证一下。)所以,线程之间进行数据交换和通信是非常容易的。
但是线程之间也有自己私有的资源,包括:
- PCB属性
- 上下文结构
- 线程独立的栈结构
线程优点和缺点
优点:
①创建一个新线程的代价要比创建一个新进程小得多
这一点在上文中已经解释过了,这里不再赘述。
②与进程之间的切换相比,线程之间的切换需要操作系统做的工作要少很多
原因如下:
第一,进程之间切换时,需要切换的内容有页表、虚拟地址空间、PCB和上下文;但进程之间相互切换只需要切换PCB和上下文。
这样看起来,进程和线程切换效率并没有很大差别,那它们的效率差距体现在哪儿呢?
这里需要补充一个cache的概念。
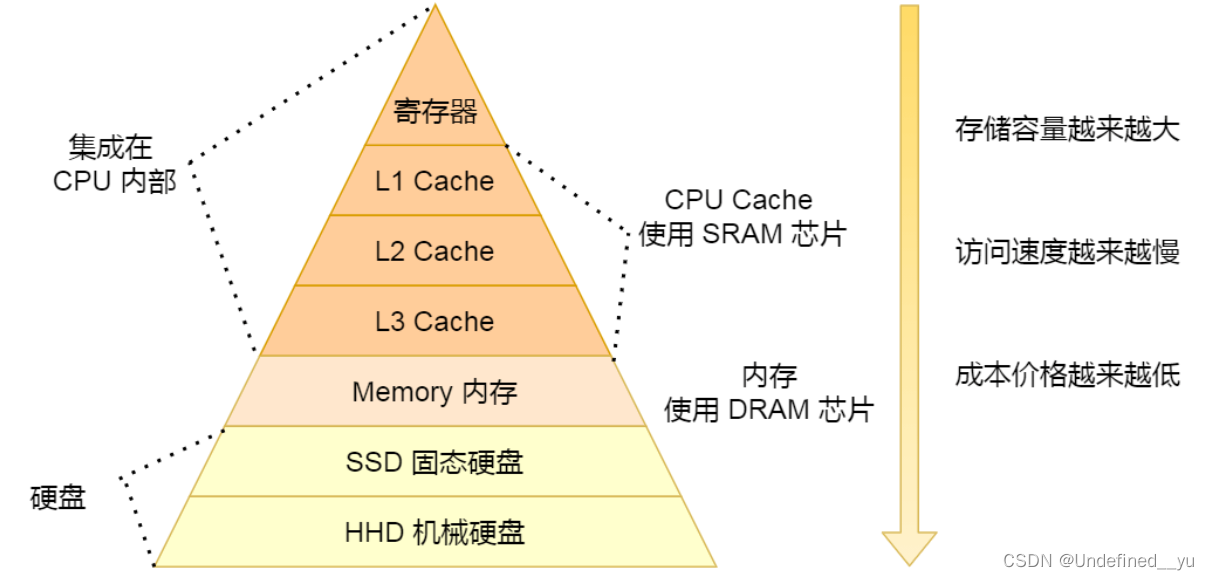
cache是存在于CPU中的一个硬件缓存,它的运行速率比CPU慢,但是远高于内存。其中存储的主要是一些当前执行流经常用到以及很可能用到的热点数据,目的是当执行流需要读取这些数据时可以更快速地完成。
由于线程之间大部分资源是共享的,所以切换时也就不用切换cache中的数据;但是进程切换却要将cache中的数据全部换掉,太频繁的切换甚至会导致cache失效,效率就会大大降低,这就是差距所在。
③线程占用的资源要比进程少很多
④能充分利用多处理器的可并行数量
⑤在等待慢速I/O操作结束的同时,程序可执行其他的计算任务
⑥计算密集型应用,为了能在多处理器系统上运行,将计算分解到多个线程中实现
⑦I/O密集型应用,为了提高性能,将I/O操作重叠。线程可以同时等待不同的I/O操作。
这几点很好理解,不再赘述。
缺点:
① 性能损失
一个很少被外部事件阻塞的计算密集型线程往往无法与共它线程共享同一个处理器。如果计算密集型线程的数量比可用的处理器多,那么可能会有较大的性能损失,这里的性能损失指的是增加了额外的同步和调度开销,而可用的资源不变。
②健壮性降低
编写多线程需要更全面更深入的考虑,在一个多线程程序里,因时间分配上的细微偏差或者因共享了不该共享的变量而造成不良影响的可能性是很大的,换句话说线程之间是缺乏保护的。
③缺乏访问控制
进程是访问控制的基本粒度,在一个线程中调用某些OS函数会对整个进程造成影响。
⑤编程难度提高
编写与调试一个多线程程序比单线程程序困难得多
这里解释一下什么是“线程健壮性”:
在我们上面的代码中一共有两个线程,那么如果其中一个线程出问题,会不会影响另一个线程?
用代码测试一下:
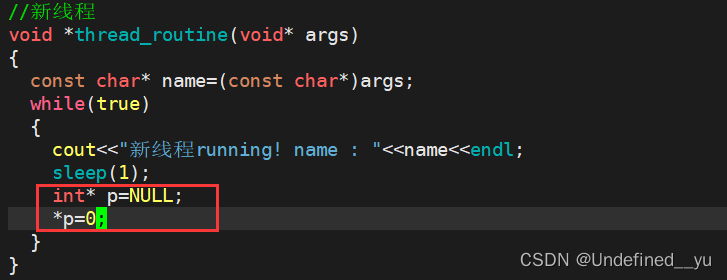
可以看到代码中有一个很明显的错误,运行结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
主线程running! tid: 0x365f7700新线程running! name : thread one
主线程running! tid: 0x365f7700
Segmentation fault
可以看到,两个线程都被终止了。
上面的现象就说明线程的健壮性较差!因为信号是发送给进程整体的,当操作系统检测到异常时,会向进程发送信号,由于每一个人线程的PID都是一样的,所以都会对信号做出处理。
从资源的视角来看,操作系统向进程发送信号,随后回收进程资源。由于线程之间资源大部分共享,所以其他线程也就不存在了。
操作系统提供的创建轻量级进程的接口是什么?
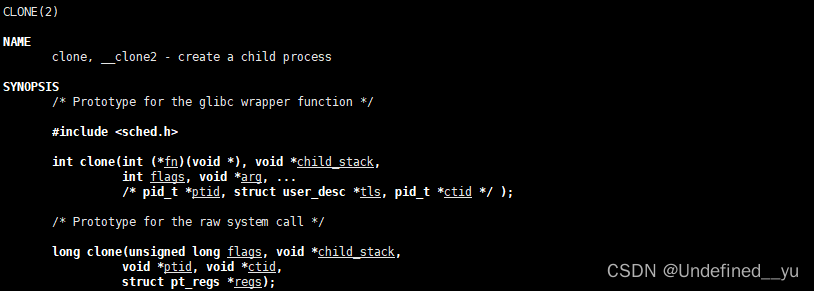
实际上,上文中的代码中底层就调用了这个函数。
还有一个跟fork有些区别的接口:
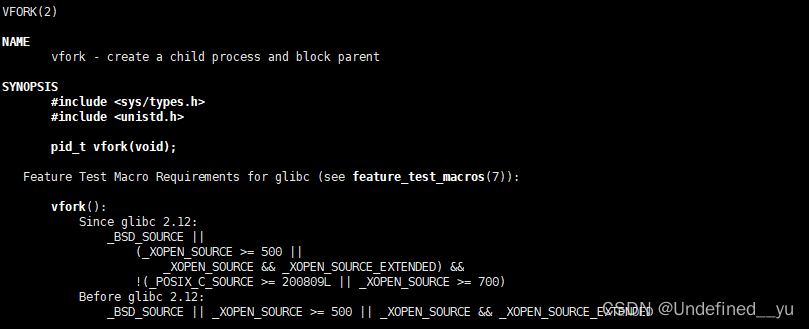
它和fork的区别在于,vfork创建出来的进程具有相同的地址空间,说白了,也就是创建轻量级进程的意思,但这个不常用。
创建一批线程
上文中的代码只是创建了一个线程,这里再创建一批线程,代码如下:
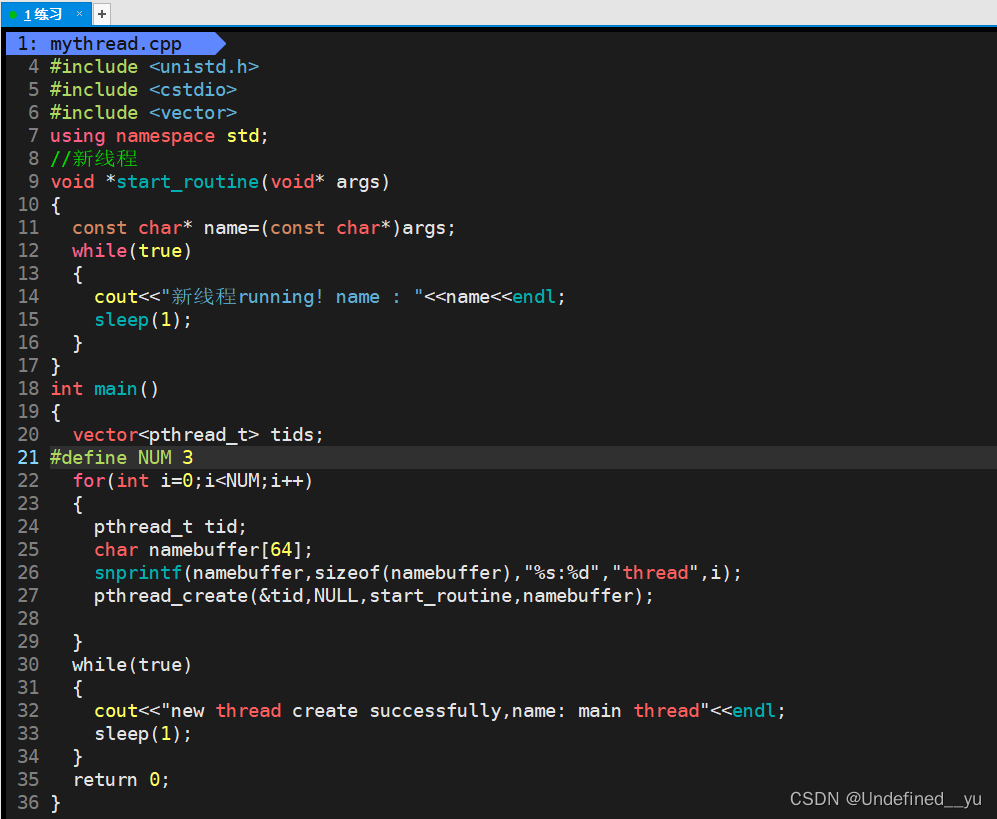
结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
new thread create successfully,name: main thread新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
new thread create successfully,name: main thread
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
new thread create successfully,name: main thread
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
new thread create successfully,name: main thread
这时,出现的线程只有2号线程,这是有点奇怪的。
对上面的代码稍作改动,在其中加入一个sleep函数,如下:
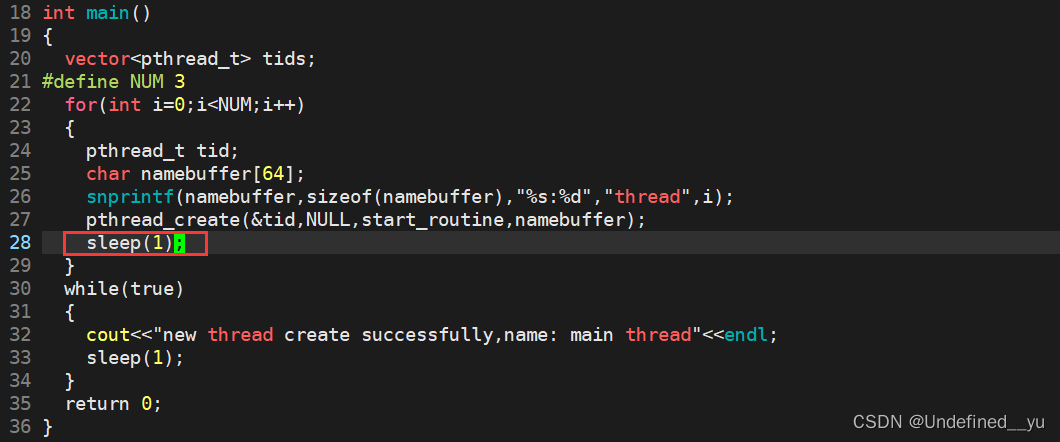
再次运行,结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
新线程running! name : thread:0
新线程running! name : thread:1
新线程running! name : thread:1
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
新线程running! name : thread:2
new thread create successfully,name: main thread
可见,这次的运行结果出现了0和1号线程。为什么只有一个sleep的区别,结果却不一样了?
答:①当创建新的线程之后,新线程根据缓冲区的起始地址去执行相应的任务,而主线程依然在原先的轨道上正常地进行,注意这里的传给新线程的是缓冲区的地址。
②创建新的线程之后,几个线程的执行顺序是随机的。而如果先执行的是主线程,它就会继续创建线程。而上面说传递给新线程的是缓冲区的地址,在下一次创建线程时,就会被新的线程地址覆盖,所以最后每一个新线程拿到的都是同一个缓冲区地址。
所以就会出现以上现象。
所以上面创建线程的方式其实是错误的,下面介绍正确的方式:
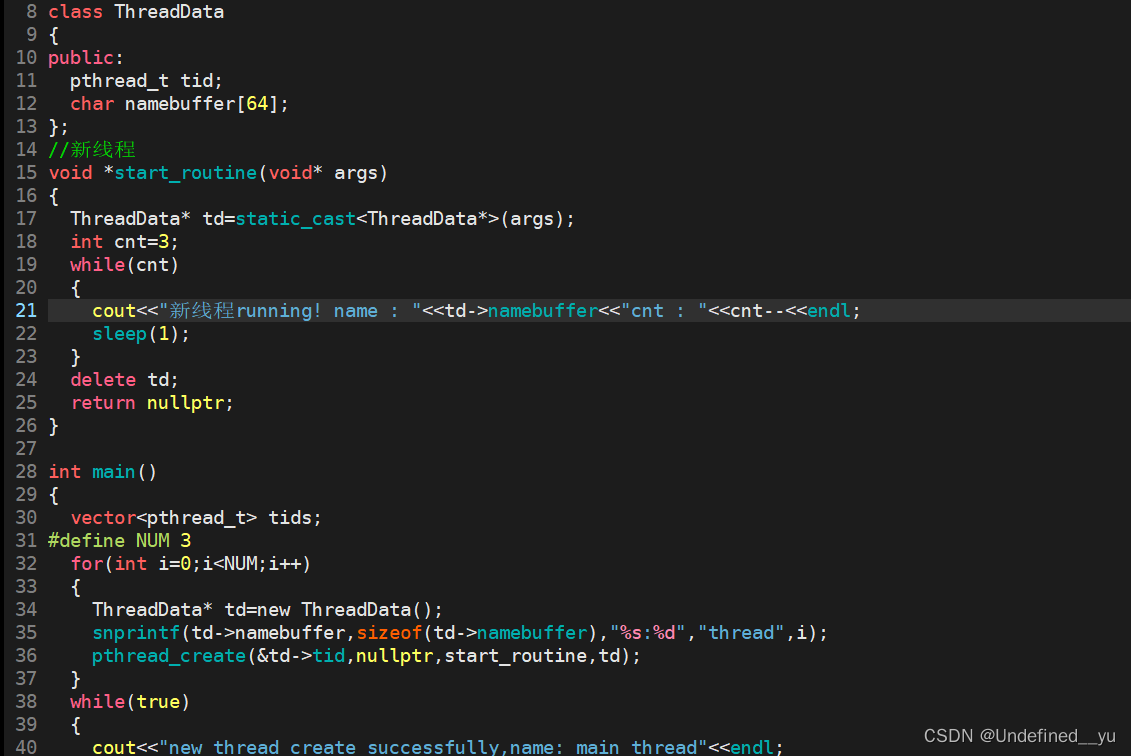
用创建对象的方式确保每一个线程收到的缓冲区地址不会被覆盖,运行结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
新线程running! name : thread:0cnt : new thread create successfully,name: main thread3
新线程running! name : thread:1cnt : 3
新线程running! name : thread:2cnt : 3
new thread create successfully,name: main thread新线程running! name :
thread:1cnt : 2
新线程running! name : thread:0cnt : 2
新线程running! name : thread:2cnt : 2
新线程running! name : thread:1cnt : 1
new thread create successfully,name: main thread
新线程running! name : thread:0cnt : 1
新线程running! name : thread:2cnt : 1
new thread create successfully,name: main thread
new thread create successfully,name: main thread
new thread create successfully,name: main thread
这里需要明确三点:
①start_routine函数现在在被三个线程执行,所以它是重入状态。
②因为start_routine函数可以被多个线程执行,而且不会出现其他错误,所以它是可重入函数。
③在函数体内定义的变量是局部变量,具有临时性,在多线程情况下亦是如此,所以函数中的cnt在每个线程内部都是唯一的,即不重复的。
终止线程
其实在上面的代码中,我们使用return就可以直接终止一个线程了。
但是注意,使用exit终止的不是一个线程,而是进程,即一个进程中所有的执行流。二者不可混淆!
而让单个线程退出而不影响其他线程还可以调用pthread_exit函数:
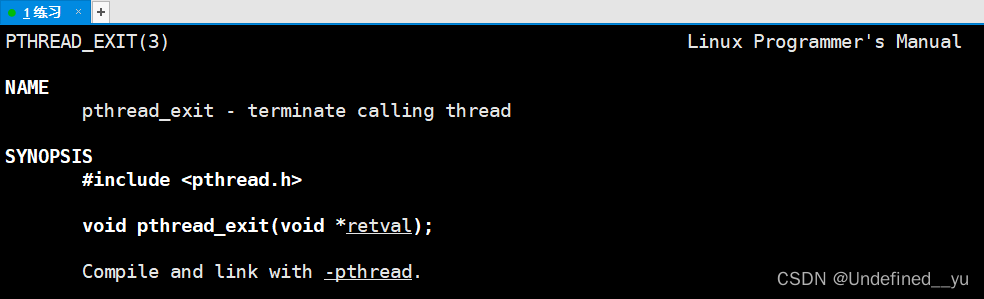
这个方法的效果其实跟return是一样的。这里就不演示了。
线程的等待问题
同进程一样,线程退出的时候,也是需要释放资源的,否则就会造成内存泄漏等问题。所以也是需要被等待的,否则将会造成类似于僵尸进程的结果。
而我们等待线程主要是为了获取线程的退出信息以及回收线程对应的PCB等内核资源,防止内存泄漏。这一点跟进程很相像。
而等待线程的方法是pthread_join:
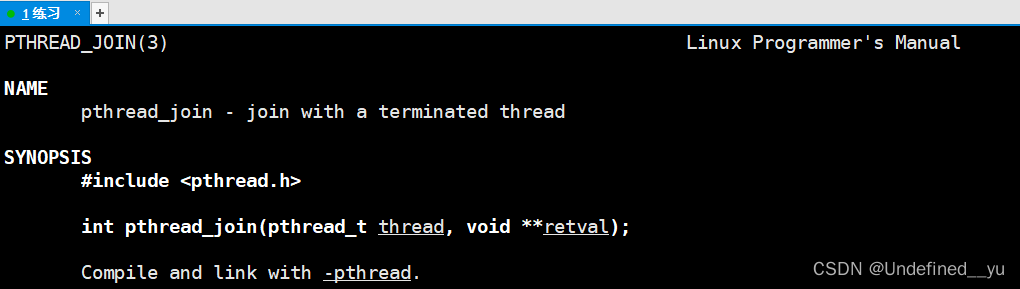
代码实例如下:
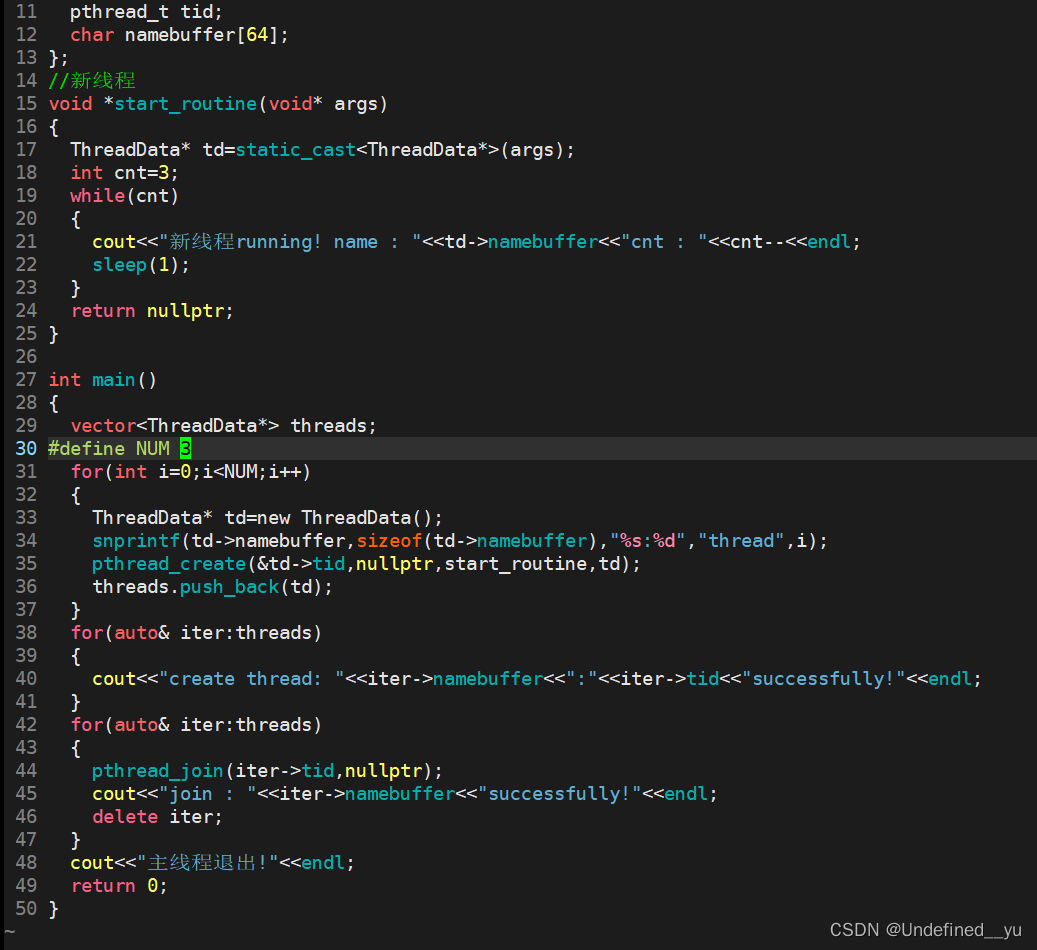
执行结果如下:
[sny@VM-8-12-centos practice]$ ./mythread
新线程running! name : thread:0cnt : 新线程running! name : thread:1cnt : 33
create thread: thread:0:139960118281984successfully!
create thread: thread:1:139960109889280successfully!
create thread: thread:2:139960101496576successfully!
新线程running! name : thread:2cnt : 3
新线程running! name : thread:0cnt : 2
新线程running! name : thread:1cnt : 2
新线程running! name : thread:2cnt : 2
新线程running! name : thread:0cnt : 1
新线程running! name : thread:2cnt : 1
新线程running! name : thread:1cnt : 1
join : thread:0successfully!
join : thread:1successfully!
join : thread:2successfully!
主线程退出!
由于线程退出是一瞬间的事,所以不能观察到它的中间过程。
下面解释一下pthread_join的第二个参数void** retval:
这其实是一个输出型参数,主要用来获取线程函数退出时,返回的退出结果,也就是下面这个函数的返回值。
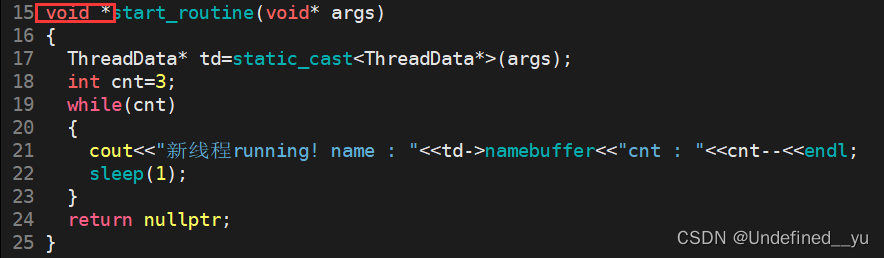
为进一步理解这个参数,对代码稍作改动:
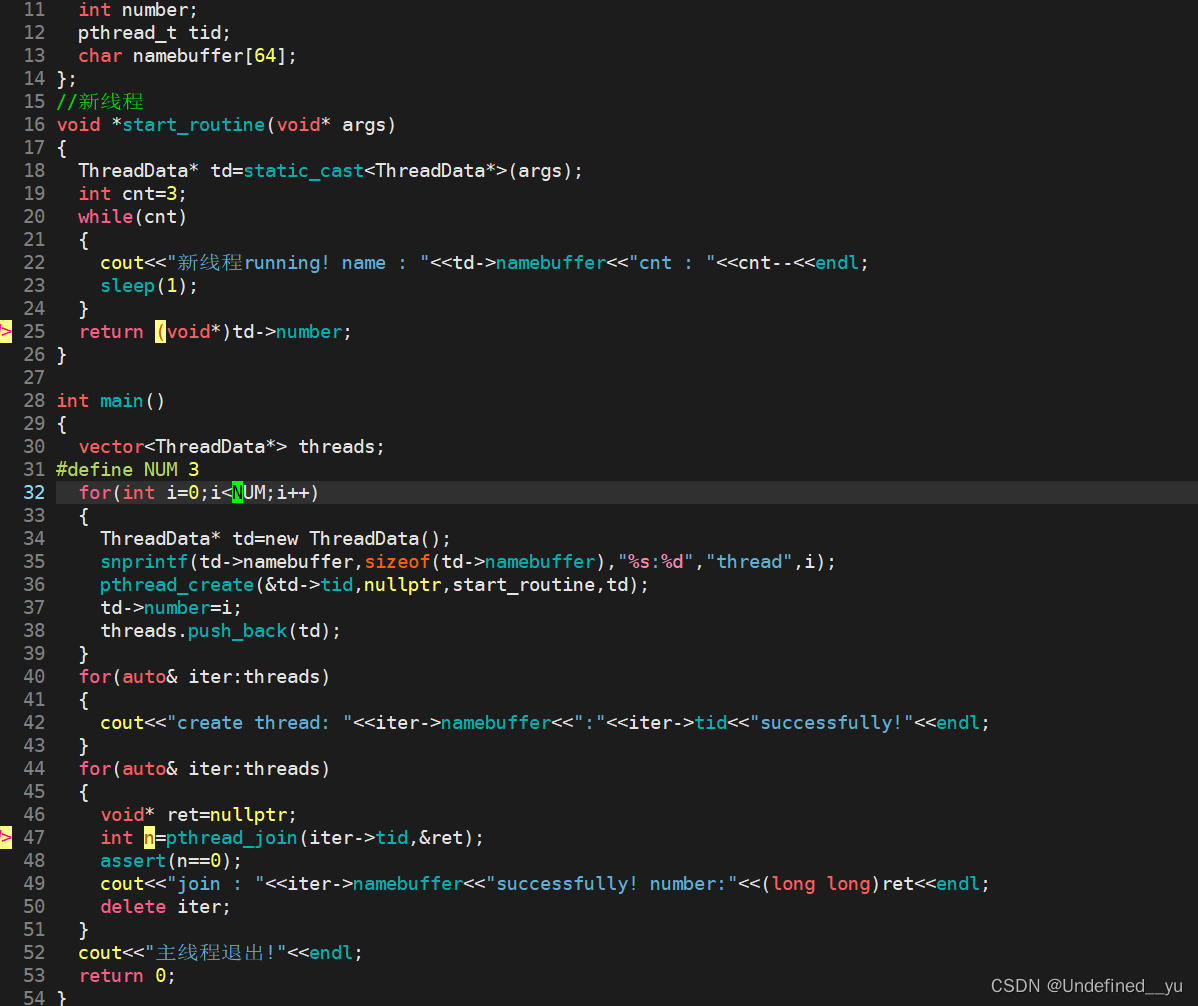
注意这里编译运行的时候会报警告,因为将int强转为了void*,但是不重要,直接看运行结果:
sny@VM-8-12-centos practice]$ ./mythread
create thread: thread:0:新线程running! name : thread:0cnt : 140010619401984successfully!3
新线程running! name : thread:2cnt : 3
create thread: thread:1:140010611009280successfully!
create thread: thread:2:140010602616576successfully!
新线程running! name : thread:1cnt : 3
新线程running! name : thread:0cnt : 2
新线程running! name : thread:1cnt : 2新线程running! name : thread:2cnt : 2
新线程running! name : thread:0cnt : 1新线程running! name : 新线程running! name : thread:1cnt : 1
thread:2cnt :
1
join : thread:0successfully! number:0
join : thread:1successfully! number:1
join : thread:2successfully! number:2
主线程退出!
其实上面的代码就是证明了pthread_join函数可以接收到线程退出时的返回值,而这个返回值就存在我们使用pthread_join函数时传入的第二个参数中。
本篇结束,多线程未完待续!
相关文章:
【关于Linux中----多线程(一)】
文章目录认识线程创建线程线程优点和缺点创建一批线程终止线程线程的等待问题认识线程 在一个程序里的一个执行路线就叫做线程(thread)。更准确的定义是:线程是“一个进程内部的控制序列”一切进程至少都有一个执行线程线程在进程内部运行&a…...

2023年全国最新安全员精选真题及答案34
百分百题库提供安全员考试试题、建筑安全员考试预测题、建筑安全员ABC考试真题、安全员证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 11.(单选题)物料提升机附墙架设置要符合设计要求,但…...

数据出境是什么意思?我国数据出境合规要求是什么?
随着经济全球化深入以及云计算等技术的发展,数据在全球范围跨境流动。数据跨境在促进经济增长、加速创新的同时,对数据主权、数据权属、个人信息保护等一系列问题逐渐浮出水面。今天我们就先来了解一下数据出境是什么意思?我国数据出境合规要…...
Liunx——Git工具使用
目录 1)使用 git 命令行安装 git 2)在 Gitee 创建仓库 创建仓库 3)Linux克隆仓库到本地 4)提交代码三板斧: 1.三板斧第一招: git add 2.三板斧第二招: git commit 3.三板斧第三招: git push 5)所遇…...

微软语音合成工具+基于Electron + Vue + ElementPlus + Vite 构建并能将文字转换为语音 MP3
微软语音合成工具基于Electron Vue ElementPlus Vite 构建并能将文字转换为语音 MP3 资源下:微软语音合成工具基于ElectronVueElementPlusVite构建并能将文字转换为语音MP3资源-CSDN文库 本文将介绍如何使用微软语音合成工具和前端技术栈进行开发,…...
Mongodb学习笔记2
文章目录前言一、搭建项目二、开始编写java代码1. 新增2.查询3. 修改4. 删除5.根据条件查询6. 关联查询7. 索引相关总结前言 MongoTemplate 相关操作 CRUD,聚合查询等; 一、搭建项目 springboot项目创建引入mongo 依赖docker 安装好mongo数据库配置yml 链接mongo spring:dat…...

学习Tensorflow之基本操作
学习Tensorflow之基本操作Tensorflow基本操作1. 创建张量(1) 创建标量(2) 创建向量(3) 创建矩阵(4) shape属性(5) 判别张量类型(6) 列表和ndarray转张量2. 创建特殊张量(1) tf.ones与tf.ones_like(2) tf.zeros与tf.zeros_like(3) tf.fill(3) tf.random.normal(4) tf.random.uni…...
《Spring系列》第2章 解析XML获取Bean
一、基础代码 Spring加载bean实例的代码 public static void main(String[] args) throws IOException {// 1.获取资源Resource resource new ClassPathResource("bean.xml");// 2.获取BeanFactoryDefaultListableBeanFactory factory new DefaultListableBeanFa…...

小红书20230326暑假实习笔试
第一题:加密 小明学会了一种加密方式。他定义suc(x)为x在字母表中的后继,例如a的后继为b,b的后继为c… (即按字母表的顺序后一个)。特别的,z的后继为a。对于一个原字符串S,将其中每个字母x都替…...
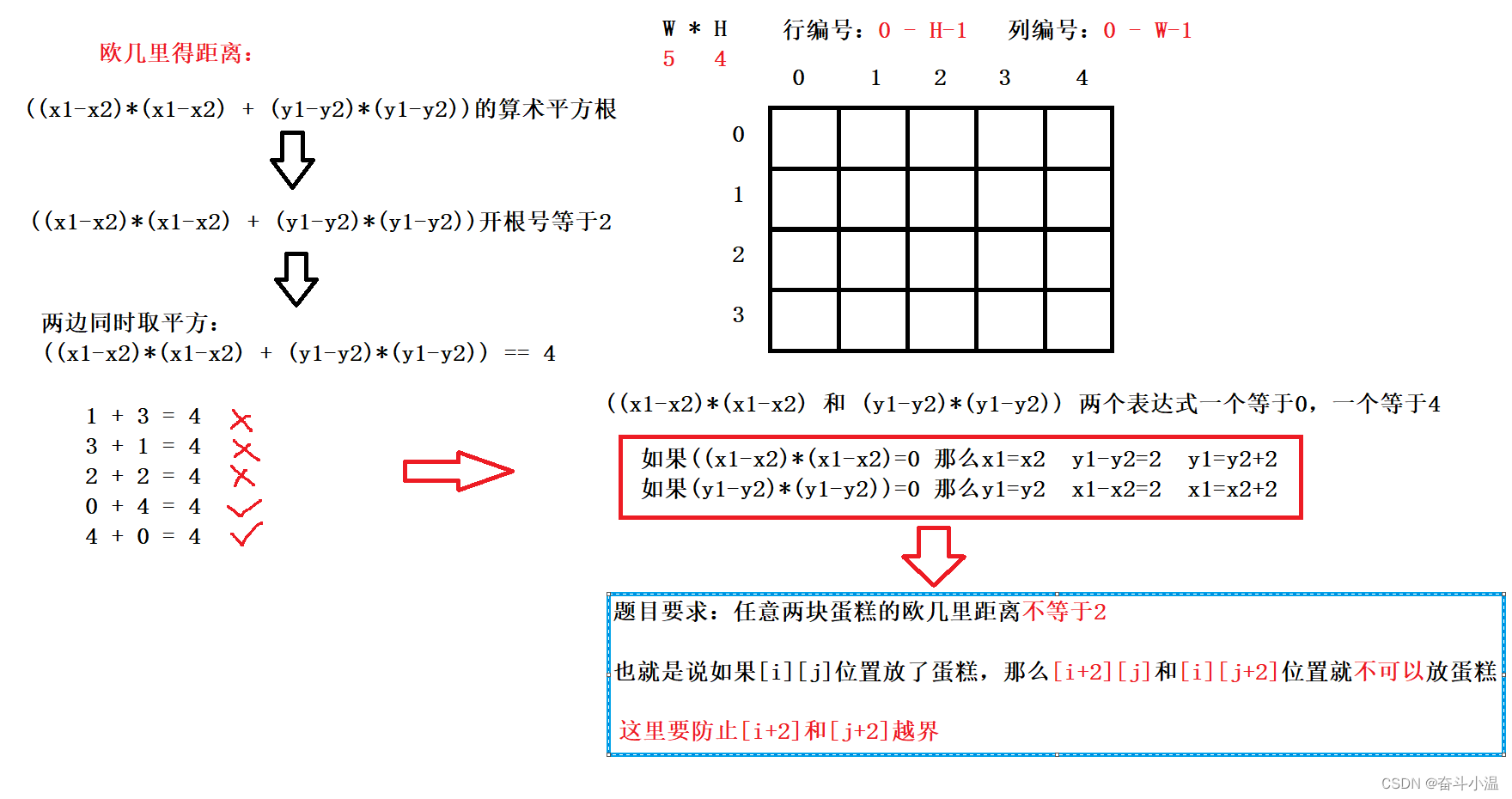
【java】不要二、把字符串转成整数
目录 🔥一、编程题 1.不要二 2.把字符串转换成整数 🔥一、编程题 1.不要二 链接:不要二_牛客题霸_牛客网 (nowcoder.com) 描述:二货小易有一个W*H的网格盒子,网格的行编号为0~H-1,网格的列编号为0~W-1…...

数据的质量管控工作
数据的质量管控工作,整个工作应该围绕启动阶段制定的目标进行。适当引入一些质量管控工具可帮助我们更高效的完成工作。 第一步、数据剖析 首先应该进行已知数据问题的评估,这里评估的范围也应控制本轮管控的目标范围内。其次,通过对数据进行…...

【SpringBoot笔记29】SpringBoot集成RabbitMQ消息队列
这篇文章,主要介绍SpringBoot如何集成RabbitMQ消息队列。 目录 一、集成RabbitMQ 1.1、引入amqp依赖 1.2、添加连接信息 1.3、添加RabbitMQ配置类...

前端架构师-week2-脚手架架构设计和框架搭建
将收获什么 脚手架的实现原理 Lerna的常见用法 架构设计技巧和架构图绘制方法 主要内容 学习如何以架构师的角度思考基础架构问题 多 Package 项目管理痛点和解决方案,基于 Lerna 脚手架框架搭建 imooc-cli 脚手架需求分析和架构设计,架构设计图 附赠内…...

CMake项目实战指令详细分析
CMake是一个跨平台的自动化构建系统,可以用简单的语句来描述所有平台的编译过程。CMake可以输出各种各样的编译文件,如Makefile、VisualStudio等。 CMake主要是编写CMakeLists.txt文件,然后用cmake命令将CMakeLists.txt文件转化为make所需要的…...

【深度学习】——LSTM参数设置
批大小设置 LSTM的批大小可以根据训练数据集的大小和计算资源的限制来确定。一般而言,批大小越大,训练速度越快,但可能会导致过拟合和内存限制。批大小越小,训练速度越慢,但对于较大的数据集和内存限制较严格的情况下…...
计算机网络高频60问 背完差不多了!!
计算机网络高频60问 网络分层结构 计算机网络体系大致分为三种,OSI七层模型、TCP/IP四层模型和五层模型。一般面试的时候考察比较多的是五层模型。 五层模型:应用层、传输层、网络层、数据链路层、物理层。 应用层:为应用程序提供交互服务…...
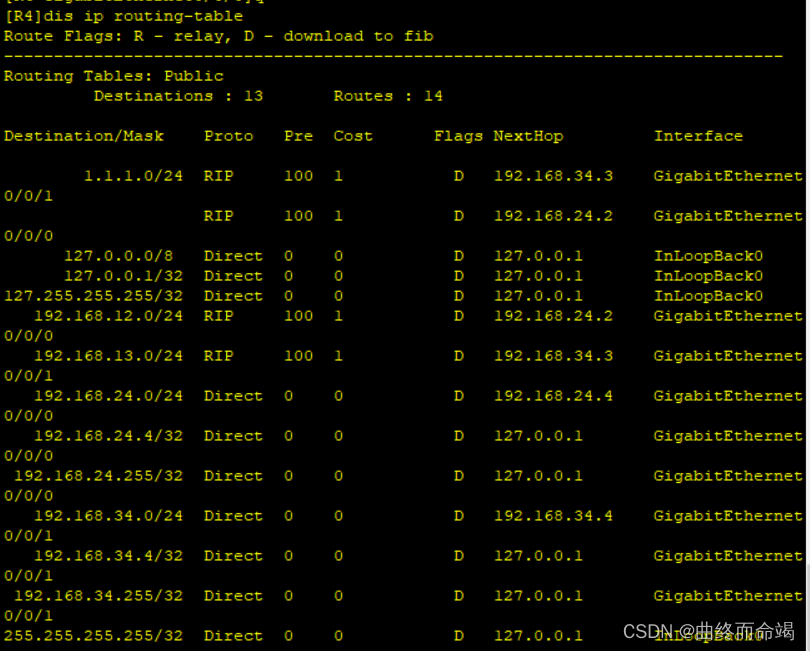
路由策略小实验
实验要求: 1、R1环回使用重发布,R2和R3使用双向重发布 2、使用路由策略解决,选路不佳 第一步,基础配置 [R1]int l0 [R1-LoopBack0]ip add 1.1.1.1 24 [R1-LoopBack0]int g0/0/0 [R1-GigabitEthernet0/0/0]ip add 192.168.12.1 …...

C语言realloc背后的内存管理
malloc申请内存,但不初始化。 calloc申请内存,且初始化为0。 free释放内存。 realloc重新分配已经分配的内存空间,可以变小,也可以变大。 以前一直有一个疑问,realloc是不是经常失败? 其实,rea…...

GPT可以被放任的在问答区应用吗?
GPT可以被放任的在问答区应用吗?1、CSDN问答乱象2、GPT-4,大增长时代的序幕数字生命离我们到底还有多远?AI 家教/老师/教育 距离独立又有哪些需要完成的过程?3、老顾对CSDN问答的一些看法老顾对GPT使用者的一些建议1、CSDN问答乱象…...
)
限制网络接口的一些简介(一)
大家在上网的时候,我们设置了www,当有来自internet的www要求时,我们的主机就会予以响应。这是因为你的主机已经开启了www的监听端口。所以,当我们启用一个daemon时,就可能触发主机的端口进行监听的动作,此时…...

重塑Word排版效率——多级列表与自动编号的进阶应用
1. 为什么你的Word文档总是排版混乱? 每次打开同事发来的Word文档,最让我头疼的就是那些乱七八糟的编号格式。明明应该是"1.1"的子标题,突然变成了"5.3";精心调整的缩进距离,传到别人电脑上就完全…...

STC8H单片机低功耗实战:用掉电模式和外部中断,让电池续航翻倍
STC8H单片机低功耗实战:用掉电模式和外部中断,让电池续航翻倍 在电池供电的嵌入式设备开发中,功耗控制往往是决定产品成败的关键因素。想象一下,一款设计精良的便携式环境监测仪,如果因为功耗问题导致频繁更换电池&am…...

基于PyPortal与CircuitPython的桌面空气质量监测站DIY指南
1. 项目概述:打造你的桌面级空气质量监测站如果你和我一样,对身边的空气质量有点“强迫症”,总想知道窗外空气到底怎么样,但又不想总去翻手机App,那么这个项目就是为你量身定做的。我们将利用一块名为PyPortal的开发板…...

终极指南:如何让Figma说中文,快速提升设计效率
终极指南:如何让Figma说中文,快速提升设计效率 【免费下载链接】figmaCN 中文 Figma 插件,设计师人工翻译校验 项目地址: https://gitcode.com/gh_mirrors/fi/figmaCN FigmaCN是一款专为中文用户设计的Figma中文界面插件,通…...

国产碳化硅MOSFET在通讯电源PFC中的应用与实战解析
1. 项目概述:当通讯电源遇上国产碳化硅MOSFET最近在做一个通讯电源的PFC(功率因数校正)项目,客户对效率、功率密度和可靠性提出了近乎苛刻的要求。传统的硅基MOSFET方案,在追求更高开关频率以减小磁性元件体积时&#…...

新时代的信息茧房
大家有没有发现:信息爆炸 2.0 时代,获取真知为何反而更难了? 人类正身处信息传播最为便捷的时代。移动互联网的普及与信息技术的迭代升级,让知识获取变得前所未有的低廉易得。迈入 AI 时代后,这一发展进程更是被推至全…...

现在不掌握NotebookLM航天科研工作流,你将错过下一轮国家重大专项申报窗口期——3大航天高校已启用的AI原生课题孵化模板首次解密
更多请点击: https://intelliparadigm.com 第一章:NotebookLM航天科学研究 NotebookLM 是 Google 推出的基于 AI 的研究协作者工具,专为处理长文档、技术报告与多源文献而设计。在航天科学研究中,其语义理解能力与引用溯源机制可…...

ENVI 5.6 + COSI-Corr插件整合指南:搞定地表形变分析的第一步
ENVI 5.6 COSI-Corr插件整合指南:搞定地表形变分析的第一步 对于地质测绘领域的研究人员和工程师来说,地表形变监测是理解地质灾害、评估基础设施安全的重要技术手段。在众多遥感分析方法中,COSI-Corr(Co-registration of Optic…...

3分钟掌握:U校园智能刷课自动化终极实战指南
3分钟掌握:U校园智能刷课自动化终极实战指南 【免费下载链接】AutoUnipus U校园脚本,支持全自动答题,百分百正确 2024最新版 项目地址: https://gitcode.com/gh_mirrors/au/AutoUnipus 还在为重复的网课练习消耗宝贵时间而烦恼吗?AutoUnipus智能刷…...

Synopsys工具filter命令:从数据筛选到高效IC设计的实战指南
1. 项目概述:从“大海捞针”到“精准定位”的思维转变在IC设计领域,Synopsys的工具链是我们日常工作中不可或缺的伙伴。无论是DC、ICC2、PT还是VCS,我们每天都要与海量的数据、复杂的网表和成千上万的命令打交道。很多时候,我们面…...