对象序列化
@Data
@AllArgsConstructor
@NoArgsConstructor
public class Product implements Serializable {public Long productId;public String productName;public Double productPrice;public String productImg;public Integer productStatus;public String productCategory;
}
为什么要继承Serializable接口?
因为只有实现了Serializable接口,这个对象才能被序列化, Serializable序列化接口没有任何方法或者字段,只是用于标识可序列化的语义,只是告诉JVM 该类的实例可以被序列化和反序列化什么是序列化?
序列化是一种用于保存、传输和还原对象的方法,它使得对象可以在不同的计算机之间移动和共享,这对于分布式系统、数据存储和跨平台通信非常有用。无论什么编程语言,其底层涉及IO操作的部分还是由操作系统其帮其完成的,而底层IO操作都是以字节流的方式进行的,所以写操作都涉及将编程语言数据类型转换为字节流,而读操作则又涉及将字节流转化为编程语言类型的特定数据类型。中心思想是“冻结”对象,方便在网络和磁盘中传输,对应的是反序列化,就是“解冻”对象,重新获得可用的对象
当你创建对象时,只要你需要,它就会一直存在,但是在程序终止时,无论如何它都不会继续存在。尽管这么做肯定是有意义的,但是仍旧存在某些情况,如果对象能够在程序不运行的情况下仍能存在并保存其信息,那将非常有用。这样,在下次运行程序时,该对象将被重建并且拥有的信息与在程序上次运行时它所拥有的信息相同。当然,你可以通过将信息写入文件或数据库来达到相同的效果,但是在使万物都成为对象的精神中,如果能够将一个对象声明为是“持久性”的,并为我们处理掉所有细节,那将会显得十分方便。
在windows上创建一个对象,将其序列化,然后通过网络发送到unix机器上,它会被正确重建
为什么要序列化?
总的来说,序列化的目的是通过网络传输对象,或者说是将对象存储到文件系统、数据库、内存中。可以实现轻量级持久化
“持久化”:对象存活于程序调用之间,生命周期不是由程序是否在执行决定的,获取一个可序列化的对象并把它写入磁盘,然后在重新调用程序时恢复该对象,这样就产生了持久化的效果“轻量级”:不能使用某个“持久化”关键字定义一个对象,并让编程语言替我们处理一切细节。相反,你必须在程序中显式地序列化和反序列化对象
远程方法调用
可以让存在于远程机器上的对象表现在得像存在本地机器上一样,当把消息发送给远程对象时,需要对象序列化来传输参数和返回值JavaBeans的需要
使用Bean时,会在设计时配置状态信息,这个状态信息就必须存储起来,在程序启动时恢复,就需要到了序列化有什么隐患?
不支持跨语言调用
如果调用的是其他语言开发的服务的时候就不支持了。性能差
相比于其他序列化框架性能更低,主要原因是序列化之后的字节数组体积较大,导致传输成本加大。安全问题
取自JEP415传入数据流的内容决定了创建的对象、其字段的值以及它们之间的引用。但在许多典型用途中,流中的字节是从未知、不受信任或未经身份验证的客户端接收的。通过仔细构建流,攻击者可以恶意地导致任意类中的代码被执行。如果对象构造具有更改状态或调用其他操作的副作用,那么这些操作可能会损害应用程序对象、库对象甚至 Java 运行时的完整性。禁用反序列化攻击的关键是防止任意类的实例被反序列化,从而防止直接或间接执行其方法。
备用方案
Kryo 是一个高性能的序列化/反序列化工具,并且专门针对java语言,由于其变长存储特性并使用了字节码生成机制,拥有较高的运行速度和较小的字节码体积。ProtoStuff、hessian 都是跨语言的序列化方式,如果有跨语言需求的话可以考虑使用。
如何使用?
@Data
@AllArgsConstructor
@NoArgsConstructor
public class User implements Serializable {private static final long serialVersionUID = 1L; private String id;private String name;
}
public void SerializableTest(){User user = new User("1001", "Joe");try {ObjectOutputStream objectOutputStream = new ObjectOutputStream(new FileOutputStream("user.txt"));objectOutputStream.writeObject(user);objectOutputStream.close();} catch (IOException e) {e.printStackTrace();}
}
将User对象及其携带的数据写入了文本user.txt中,变为字节流
public static void readObj() {try {ObjectInputStream objectInputStream = new ObjectInputStream(new FileInputStream("/Users/guanliyuan/user.txt"));try {Object object = objectInputStream.readObject();User user = (User) object;System.out.println(user);} catch (ClassNotFoundException e) {e.printStackTrace();}} catch (IOException e) {e.printStackTrace();}
}
/** 输出
User(id=1001, name=Joe)
*/
为什么要定义一个serialVersionUID在User里?
对于JVM来说,要进行持久化的类必须要有一个标记,只有持有这个标记JVM才允许类创建的对象可以通过其IO系统转换为字节数据,从而实现持久化,而这个标记就是Serializable接口。而在反序列化的过程中则需要使用serialVersionUID来确定由那个类来加载这个对象,所以我们在实现Serializable接口的时候,一般还会要去尽量显示地定义serialVersionUID。这个serialVersionUID的详细的工作机制是:在序列化的时候系统将serialVersionUID写入到序列化的文件中去,当反序列化的时候系统会先去检测文件中的serialVersionUID是否跟当前的文件的serialVersionUID是否一致,如果一直反序列化不成功,就说明当前类跟序列化后的类发生了变化,比如是成员变量的数量或者是类型发生了变化,那么在反序列化时就会发生crash,并且会报出错误
serialVersionUID要不要指定呢?在源码的注释里,Java官方强烈建议所有要序列化的类都显示地声明serialVersionUID字段,因为如果高度依赖于JVM默认生成serialVersionUID,可能会导致其与编译器的实现细节耦合,这样可能会导致在反序列化的过程中发生意外的InvalidClassException异常。因此,为了保证跨不同Java编译器实现的serialVersionUID值的一致,实现Serializable接口的必须显示地声明private serialVersionUID字段。 数组类时不能显示地声明serialVersionUID的,因为他们始终具有默认计算的值,数组类反序列化的过程中也放弃了匹配serialVersionUID的要求
- 添加一个默认版本的序列化ID
private static final long serialVersionUID = 1L。
2)添加一个随机生成的不重复的序列化 ID。
private static final long serialVersionUID = -2095916884810199532L;
3)添加 <font style="color:rgb(44, 62, 80);">@SuppressWarnings</font> 注解
@SuppressWarnings("serial")
要选择哪个呢?Java 虚拟机是否允许反序列化,不仅取决于类路径和功能代码是否一致,还有一个非常重要的因素就是序列化 ID 是否一致。如果没有特殊需求,采用默认的序列化 ID(1L)就可以,这样可以确保代码一致时反序列化成功。
具体实现过程
ObjectOutputStream 会依次调用 `writeObject()`→`writeObject0()`→`writeOrdinaryObject()`→`writeSerialData()`→`invokeWriteObject()`→`defaultWriteFields()`private void defaultWriteFields(Object obj, ObjectStreamClass desc) throws IOException {// 获取对象的类,并检查是否可以进行默认的序列化Class<?> cl = desc.forClass();desc.checkDefaultSerialize();// 获取对象的基本类型字段的数量,以及这些字段的值int primDataSize = desc.getPrimDataSize();desc.getPrimFieldValues(obj, primVals);// 将基本类型字段的值写入输出流bout.write(primVals, 0, primDataSize, false);// 获取对象的非基本类型字段的值ObjectStreamField[] fields = desc.getFields(false);Object[] objVals = new Object[desc.getNumObjFields()];int numPrimFields = fields.length - objVals.length;desc.getObjFieldValues(obj, objVals);// 循环写入对象的非基本类型字段的值for (int i = 0; i < objVals.length; i++) {// 调用 writeObject0 方法将对象的非基本类型字段序列化写入输出流try {writeObject0(objVals[i], fields[numPrimFields + i].isUnshared());}// 如果在写入过程中出现异常,则将异常包装成 IOException 抛出catch (IOException ex) {if (abortIOException == null) {abortIOException = ex;}}}
}
ObjectInputStream 为例,它在反序列化的时候会依次调用 readObject()→readObject0()→readOrdinaryObject()→readSerialData()→defaultReadFields()
private void defaultReadFields(Object obj, ObjectStreamClass desc) throws IOException {// 获取对象的类,并检查对象是否属于该类Class<?> cl = desc.forClass();if (cl != null && obj != null && !cl.isInstance(obj)) {throw new ClassCastException();}// 获取对象的基本类型字段的数量和值int primDataSize = desc.getPrimDataSize();if (primVals == null || primVals.length < primDataSize) {primVals = new byte[primDataSize];}// 从输入流中读取基本类型字段的值,并存储在 primVals 数组中bin.readFully(primVals, 0, primDataSize, false);if (obj != null) {// 将 primVals 数组中的基本类型字段的值设置到对象的相应字段中desc.setPrimFieldValues(obj, primVals);}// 获取对象的非基本类型字段的数量和值int objHandle = passHandle;ObjectStreamField[] fields = desc.getFields(false);Object[] objVals = new Object[desc.getNumObjFields()];int numPrimFields = fields.length - objVals.length;// 循环读取对象的非基本类型字段的值for (int i = 0; i < objVals.length; i++) {// 调用 readObject0 方法读取对象的非基本类型字段的值ObjectStreamField f = fields[numPrimFields + i];objVals[i] = readObject0(Object.class, f.isUnshared());// 如果该字段是一个引用字段,则将其标记为依赖该对象if (f.getField() != null) {handles.markDependency(objHandle, passHandle);}}if (obj != null) {// 将 objVals 数组中的非基本类型字段的值设置到对象的相应字段中desc.setObjFieldValues(obj, objVals);}passHandle = objHandle;
}
Serializable 接口之所以定义为空,是因为它只起到了一个标识的作用,告诉程序实现了它的对象是可以被序列化的,但真正序列化和反序列化的操作并不需要它来完成
Externalizable对比
另外一个序列化的接口- 新增了一个无参的构造方法
Externalizable 进行反序列化的时候,会调用被序列化类的无参构造方法去创建一个新的对象,然后再将被保存对象的字段值复制过去。否则的话,会抛出异常
writeExternal()和readExternal(),实现Externalizable接口所必须的2个方法- Serializable 是 Java 标准库提供的接口,而 Externalizable 是 Serializable 的子接口
- Externalizable 接口提供了更高的序列化控制能力,可以在序列化和反序列化过程中对对象进行自定义的处理,如对一些敏感信息进行加密和解密
public class User implements Externalizable {private int id;private String name;@Overridepublic void writeExternal(ObjectOutput out) throws IOException {out.writeObject(id);out.writeObject(name);}@Overridepublic void readExternal(ObjectInput in) throws IOException, ClassNotFoundException {id = in.readInt();name = (String) in.readObject();}
}
附:源码注释
**序列化接口使类能够实现序列化。**类通过实现 java.io.Serializable 接口来启用序列化功能。
警告: 序列化和反序列化不受信任的数据本质上是危险的,应该尽量避免。不受信任的数据应该严格按照《Java SE 安全编码指南》中的“序列化和反序列化”部分进行仔细验证。《序列化过滤》描述了防御性使用序列化过滤的最佳实践。
未实现此接口的类不会将其状态序列化或反序列化。所有可序列化的类的子类本身也是可序列化的。序列化接口没有任何方法或字段,仅用于标识可序列化的语义。
非序列化类的子类也可以被序列化和反序列化。在序列化过程中,不会写入非序列化超类的任何字段。在反序列化过程中,非序列化超类的字段将使用第一个(底层的)非序列化超类的无参构造函数进行初始化。此构造函数必须对正在反序列化的子类可见。如果不符合这一条件,则声明此类为 Serializable 是错误的;此错误将在运行时检测到。可序列化的子类可以负责保存和恢复非序列化超类的公共、受保护的(以及可访问的包访问权限)字段。有关详细说明,请参阅《Java 对象序列化规范》第 3.1 节。
当遍历对象图时,可能会遇到不支持 Serializable 接口的对象。在这种情况下,将抛出 NotSerializableException 并指出非序列化对象的类。
需要在序列化和反序列化过程中进行特殊处理的类必须实现具有以下确切签名的特殊方法:
private void writeObject(java.io.ObjectOutputStream out)throws IOException;
private void readObject(java.io.ObjectInputStream in)throws IOException, ClassNotFoundException;
private void readObjectNoData()throws ObjectStreamException;
writeObject 方法负责写出特定类的对象的状态,以便相应的 readObject 方法可以恢复它。可以调用 out.defaultWriteObject() 来使用默认机制保存对象的字段。该方法不需要关心其超类或子类的状态。
readObject 方法负责从流中读取并恢复类的字段。它可以调用 in.defaultReadObject() 来使用默认机制恢复对象的非静态和非瞬态字段。此方法使用流中的信息来为对象中相应命名的字段赋值。该方法不需要关心其超类或子类的状态。状态通过从 ObjectInputStream 读取个别字段并为对象的适当字段赋值来恢复。
readObjectNoData 方法负责在序列化流未将给定类列为对象的超类的情况下初始化特定类的对象的状态。这可能发生在接收方使用不同版本的对象类时,该版本扩展了发送方版本未扩展的类。这也可能发生在序列化流被篡改的情况下;因此,readObjectNoData 方法可用于在源流不友好或不完整的情况下正确初始化反序列化对象。
需要指定替代对象用于序列化流写入的可序列化类应实现具有以下确切签名的特殊方法:
ANY-ACCESS-MODIFIER Object writeReplace()throws ObjectStreamException;
如果此类方法存在并且可以从对象所属类的方法中访问,则序列化过程中将调用此方法。因此,该方法可以是私有、受保护或包私有访问权限。子类对此方法的访问遵循 Java 访问规则。
需要指定在从流中读取实例时替换对象的类应实现具有以下确切签名的特殊方法:
ANY-ACCESS-MODIFIER Object readResolve()throws ObjectStreamException;
此 readResolve 方法遵循与 writeReplace 相同的调用规则和访问规则。
枚举类型都是可序列化的,并在序列化和反序列化期间接受《Java 对象序列化规范》定义的处理。对于枚举类型,忽略对上述特殊处理方法的声明。
记录类可以实现 Serializable 并接受《Java 对象序列化规范》第 1.13 节“记录的序列化”定义的处理。对于记录类型,忽略对上述特殊处理方法的声明。
序列化运行时将每个可序列化类与一个称为 serialVersionUID 的版本号关联起来,用于在反序列化期间验证发送方和接收方加载的对象类在序列化方面是否兼容。如果接收方加载的类具有与发送方类不同的 serialVersionUID,则反序列化将导致 InvalidClassException。可序列化类可以通过声明一个名为 serialVersionUID 的字段来显式指定自己的 serialVersionUID,该字段必须是静态、最终并且类型为 long:
ANY-ACCESS-MODIFIER static final long serialVersionUID = 42L;
如果可序列化类未显式声明 serialVersionUID,则序列化运行时将根据类的各种方面计算默认的 serialVersionUID 值,具体如《Java 对象序列化规范》所述。该规范定义枚举类型的 serialVersionUID 为 0L。但是,强烈建议所有非枚举类型显式声明 serialVersionUID 值,因为默认的 serialVersionUID 计算高度依赖于类的细节,这可能会根据编译器实现的不同而变化,从而导致意外的 InvalidClassException。因此,为了确保跨不同 Java 编译器实现一致的 serialVersionUID 值,可序列化类必须显式声明 serialVersionUID 值。此外,建议显式 serialVersionUID 声明尽可能使用 private 修饰符,因为此类声明仅适用于立即声明的类——serialVersionUID 字段作为继承成员是无效的。数组类无法显式声明 serialVersionUID,因此总是使用默认计算值,但对于数组类,要求 serialVersionUID 匹配的要求被豁免。
自 Java 1.1 起
参考JDK17新特性-JEP 415:上下文特定的反序列化过滤器 | JEPs
应用安全:JAVA反序列化漏洞之殇
Java 序列化详解
相关文章:

对象序列化
Data AllArgsConstructor NoArgsConstructor public class Product implements Serializable {public Long productId;public String productName;public Double productPrice;public String productImg;public Integer productStatus;public String productCategory; }为什么要…...

什么是专利开放许可?
专利作为技术创新的重要载体,其有效转化与应用成为推动社会进步和经济发展的关键力量。那么,专利开放许可究竟是何方神圣?它如何打破传统专利许可的壁垒,促进创新资源的广泛共享? 专利开放许可的定义 专利开放许可&am…...

地表最强开源大模型!Llama 3.2,如何让你的手机变身私人智能助理
你有没有想过,为什么现在的手机越来越像小型电脑?无论是拍照、看视频,还是用各种APP,甚至是AI助手,手机的功能几乎无所不能。其实,这一切的背后有一个技术正在悄悄改变我们的生活,那就是Llama 3…...

Pandas中DataFrame表格型数据结构
目录 1、DataFrame是什么2、创建一个dataframe3、获取dataframe的行、列索引4、获取dataframe的值 1、DataFrame是什么 series是有一组数据与一组索引(行索引)组成的数据结构,而dataframe是由一组数据与一对索引(行索引和列索引&…...

C++的智能指针
很久之前,我们说到了new和delete关键字。 new在堆上分配内存,需要delete来删除内存、释放内存,因为它不会自动释放内存。 智能指针是实现过程自动化的一种方式,即当我们调用new时,我们不需要调用delete关键字。 在很…...

微信小程序showLoading ,showToast ,hideLoading连续调用出现showLoading 不关闭的情况记录
wx.showLoading({title: "操作中",mask: true,});api().then(() > {wx.showToast({title: "操作成功",icon: "none",});}).finally(() > {wx.hideLoading();}); 类似的代码偶尔会出现showLoading不关闭的现象, 这种情况下的解决方法就是 …...
OpenFeign使用详解
什么是OpenFeign? OpenFeign 是一个声明式的 HTTP 客户端,旨在简化微服务架构中不同服务之间的 HTTP 调用。它通过集成 Ribbon 实现了客户端负载均衡,并且能够与 Eureka、Consul 等服务发现组件无缝对接。使用 OpenFeign,开发者只…...

CSS clip-path 属性的使用
今天记录一个css属性clip-path,首先介绍下这个属性。 clip-path 是CSS中的一个神奇属性,它能够让你像魔术师一样,对网页元素施展“裁剪魔法”——只展示元素的一部分,隐藏其余部分。想象一下,不用依赖图片编辑软件&am…...

PHP 函数
PHP 函数 PHP(超文本预处理器)是一种广泛使用的开源服务器端脚本语言,特别适合于网页开发。在PHP中,函数是一段可重复使用的代码,用于执行特定任务。它们是PHP编程的核心组成部分,有助于模块化代码&#x…...
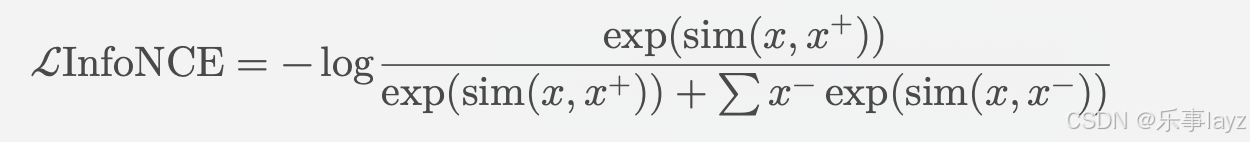
NCEloss与InfoNCEloss的区别
NCE Loss(Noise Contrastive Estimation Loss)和 InfoNCE Loss 是两种常用的损失函数,主要应用在对比学习和自监督学习任务中。它们的区别在于应用场景和具体实现细节。下面是对两者的详细比较: 1. NCE Loss(Noise Co…...
高通Android 12 push framework.jar和service.jar
1、Android framework.jar和service.jar替换注意事项 2、单编 adb push service.jar脚本 如下 adb root adb disable-verity adb remountadb push services.jar system/framework adb push services.jar.prof system/framework adb push oat/arm64/services.art /system/fram…...
HTTPS证书配置
NGINX、SSl配置 修改conf目录下NGINX中的crt和key文件 单点配置SSL 需要的文件和配置信息 证书和keytool.exe(使用jdk1.8的)工具要在同一个目录下 gxszy.qhxzhny.top.pfx(证书) keystorePass.txt(密码) 使用JDK自带的keyto…...

Image matting入门
概念 matting就是扣图,本质是预测前景与背景,将前景扣出来。主要应用于影视行业,如拍电影绿幕扣图。和图像分割的区别在于多一个模糊地带,非01分类,变成了预测alpha通道。前景F,背景B,图像I可以…...

基于安全风险预测的自动驾驶自适应巡航控制优化
摘要 :从周边车辆运动学状态参数和道路设施条件参数中提取场景特征指标和安全风险度量指标,采用极端梯度提升模型(XGboost )和长短时记忆模型( LSTM )进行安全风险预测,由此提出基于安全风险预测的自动驾驶自适应巡航控制(ACC )优化方法,并选取碰撞发生概率、速度平均…...
(包含主从复制的搭建) (保证一遍学会))
Docker Compose 搭建 Redis 哨兵集群模式搭建详解(1主2从+3哨兵)(包含主从复制的搭建) (保证一遍学会)
目录 哨兵的作用和工作原理 服务状态监控 选举新的 master 如何实现故障转移 搭建哨兵集群 哨兵的作用和工作原理 Redis 提供了哨兵 (Sentinel) 机制来实现主从集群的自动故障恢复。哨兵的结构和作用如下 监控:Sentinel 会不断检查你的 master 和 slave 是否按…...

Oracle 单机和集群环境部署教程
目录 一、Oracle 单机环境部署1. 环境准备2. 安装 Oracle Database2.1 下载 Oracle Database2.2 创建 Oracle 用户和组2.3 配置内核参数和系统限制2.4 解压和安装2.5 配置监听程序2.6 创建数据库 3. 单机部署注意事项 二、Oracle 集群环境部署 (Oracle RAC)1. 环境准备2. 安装 …...
)
springboot 整合酷狗获取MV视频最高画质(使用自己账户)
在此声明,本内容仅供个人学习、研究或娱乐之用,严禁任何形式的商业用途。若您发现本内容被用于商业目的,请立即删除,及时与小编联系,我们将删除原代码。 请根据上一篇文章使用该代码:SpringBoot 整合酷狗获…...
数字孪生平台,助力制造设备迈入超感知与智控新时代!
痛点剖析 当前,制造业面临系统分散导致的数据孤岛问题,严重阻碍了有效监管与统计分析;同时,设备多样化且兼容性不足,增加了管理难度;台账记录方式混乱,工单审批流程繁琐且效率低下;…...
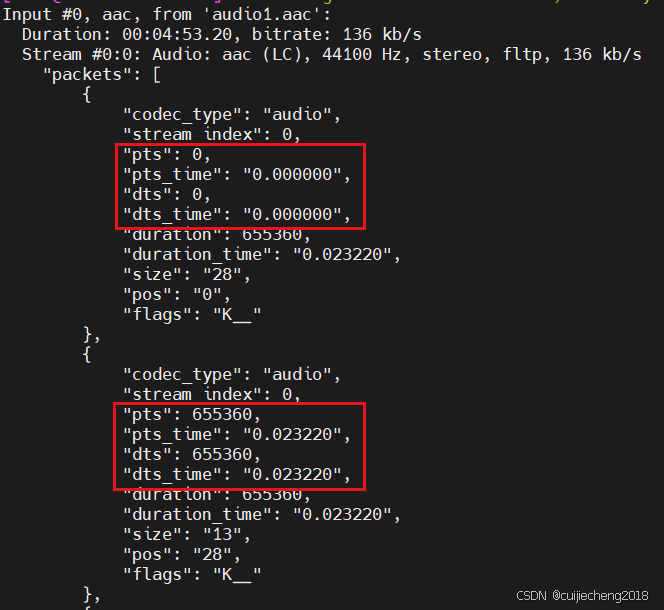
音视频入门基础:AAC专题(10)——FFmpeg源码中计算AAC裸流每个packet的pts、dts、pts_time、dts_time的实现
音视频入门基础:AAC专题系列文章: 音视频入门基础:AAC专题(1)——AAC官方文档下载 音视频入门基础:AAC专题(2)——使用FFmpeg命令生成AAC裸流文件 音视频入门基础:AAC…...

pycirclize python包画circos环形图
pycirclize python包画circos环形图 很多小伙伴都有画环形图的需求,网上也有很多画环形图的教程,讲解circos软件和circlize R包的比较多,本文介绍一款python包:pyCirclize。适合喜欢python且希望更灵活作图的小伙伴。 pyCirclize包实际上也…...

技术视角:分布式投票系统的异步解耦架构与多语言协同实践
技术视角:分布式投票系统的异步解耦架构与多语言协同实践 【免费下载链接】example-voting-app Example Docker Compose app 项目地址: https://gitcode.com/gh_mirrors/exa/example-voting-app 在当今企业级应用架构设计中,如何平衡高并发处理、…...

抖音图片怎么去水印?2026年在线去水印工具+方法盘点,总有一款适合你
开篇:为什么要去水印? 保存抖音图片时,总会遇到水印的困扰。这些水印包含抖音logo、发布者名称,有时还会有账号信息。对于自媒体创作者、内容整理者或普通用户来说,去除水印往往是必需的。本文将介绍当下最实用的抖音图…...

终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案
终极指南:如何免费解锁Cursor Pro完整功能 - 突破AI编辑器限制的完整方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youv…...
)
手把手教你给STM32MP157开发板接上HDMI显示器(基于Sii9022A芯片与设备树配置)
STM32MP157开发板HDMI显示实战:从硬件连接到设备树配置全解析 引言 当你第一次拿到STM32MP157开发板时,最令人兴奋的莫过于看到图形界面在屏幕上亮起的那一刻。但现实往往很骨感——手头可能没有配套的LCD屏幕,而HDMI显示器却是大多数开发者桌…...

Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行
Applite:macOS软件管理的最佳图形化方案,告别繁琐命令行 【免费下载链接】Applite User-friendly GUI macOS application for Homebrew Casks 项目地址: https://gitcode.com/gh_mirrors/ap/Applite 还在为macOS软件安装更新而烦恼吗?…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...

别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题
别再只盯着CSI-2了!用示波器实测MIPI D-PHY波形,手把手教你排查Camera不通的硬件问题 调试Camera模块时,MIPI信号问题往往是硬件工程师最头疼的挑战之一。当系统出现图像异常、花屏或无法识别时,大多数工程师的第一反应是检查CSI-…...

期权交易基础框架:模块化设计与Python实现指南
1. 项目概述:一个为期权交易者打造的“乐高积木”底座如果你在量化交易或者期权策略开发领域摸爬滚打过一段时间,大概率会遇到一个共同的痛点:策略想法很多,但把它们变成可回测、可实盘、可管理的代码,却要耗费大量的“…...

AI增强型写作工具Hermes-Writer:为开发者打造的智能写作助手
1. 项目概述:一个面向开发者的智能写作助手最近在GitHub上看到一个挺有意思的项目,叫dav-niu474/Hermes-Writer。乍一看标题,你可能会觉得这又是一个普通的Markdown编辑器或者写作工具。但如果你点进去,仔细研究一下它的README、代…...

跨平台鼠标控制库ez-cursor-free:原理、实现与自动化实战
1. 项目概述与核心价值如果你是一名开发者,尤其是经常需要处理跨平台UI自动化、游戏脚本或者桌面应用交互的开发者,那么你一定对“鼠标控制”这个基础但又充满细节的环节感到过头疼。不同的操作系统(Windows, macOS, Linux)提供了…...