容器学习之SparseArray源码解析
1、SparseArray是android sdk 提供集合类,主要用来替换key 为int类型,value为Object类型的Hashmap
2、SparseArray和HashMap相比优缺点:
优点:
1、SparseArray存在一个int[]keys, 因此避免自动装箱
2、SparseArray扩容时只需要数组拷贝工作(system.arraycopy), 不需要重建哈希表(rehash十分消耗性能)
缺点:
3、SparseArray以时间换空间,由于使用二分查找,时间比hashmap要慢。mkeys数组的元素总是连续的(即使中间会存在DELETED元素,但是这些DELETED元素,在后续的gc()方法中被清除掉),不像hashmap数组的元素,由于内在的hash冲突无法彻底解决而导致数组空间利用很浪费。
4、不适合大容量的数据存储。存储大量数据时,他的性能很差,千条数据以内可以使用SparseArray
5、按照key进行自然排序
二、全局变量
//用于标记当前是否有待垃圾回收(GC)的元素
private boolean mGarbage = false
key 数组和value数组的默认打下是10
//设置数组的默认初始容量为10public SparseArray() {this(10);}/*** Creates a new SparseArray containing no mappings that will not* require any additional memory allocation to store the specified* number of mappings. If you supply an initial capacity of 0, the* sparse array will be initialized with a light-weight representation* not requiring any additional array allocations.*/public SparseArray(int initialCapacity) {if (initialCapacity == 0) {mKeys = EmptyArray.INT;mValues = EmptyArray.OBJECT;} else {mValues = ArrayUtils.newUnpaddedObjectArray(initialCapacity);mKeys = new int[mValues.length];}mSize = 0;}
添加元素、
主要看put(int key,E value)方法,当中用到了ContainerHelpers类提供binarySearch,用于查找目标key在mKeys中的当前索引或者目标索引
binarySearch方法的返回值分为两种情况:
1.如果mKeys中存在对应的key,则直接返回对应的索引值
2.如果mKeys中不存在对应的key
2.1 假设mKeys中存在"值比key大且大小与key最接近的值的索引为parseIndex",则此方法的返回值为~parsentIndex
2.2 如果mKeys中不存在比key还要大的值的话,则返回值~mKeys.length
通过这种方式来存放数据,可以使得mKeys的内部值一直是按照递增的方式来排序的。
//将索引 index 处的元素赋值为 value//SparseArray 的元素值都是存到 mValues 中的,因此如果知道目标位置(index),则可以直接向数组 mValues 赋值public void setValueAt(int index, E value) {//如果需要则先进行垃圾回收if (mGarbage) {gc();}mValues[index] = value;}/*** Adds a mapping from the specified key to the specified value,* replacing the previous mapping from the specified key if there* was one.*/public void put(int key, E value) {//用二分查找法查找指定 key 在 mKeys 中的索引值int i = ContainerHelpers.binarySearch(mKeys, mSize, key);//找得到则直接赋值if (i >= 0) {mValues[i] = value;} else {//binarySearch 方法的返回值分为两种情况://1、如果存在对应的 key,则直接返回对应的索引值//2、如果不存在对应的 key// 2.1、假设 mKeys 中存在"值比 key 大且大小与 key 最接近的值的索引"为 presentIndex,则此方法的返回值为 ~presentIndex// 2.2、如果 mKeys 中不存在比 key 还要大的值的话,则返回值为 ~mKeys.length//可以看到,即使在 mKeys 中不存在目标 key,但其返回值也指向了应该让 key 存入的位置//通过将计算出的索引值进行 ~ 运算,则返回值一定是 0 或者负数,从而与“找得到目标key的情况(返回值大于0)”的情况区分开//且通过这种方式来存放数据,可以使得 mKeys 的内部值一直是按照值递增的方式来排序的i = ~i;//如果目标位置还未赋值,则直接存入数据即可,对应的情况是 2.1if (i < mSize && mValues[i] == DELETED) {mKeys[i] = key;mValues[i] = value;return;}//以下操作对应两种情况://1、对应 2.1 的一种特殊情况,即目标位置已用于存放其他值了// 此时就需要将从索引 i 开始的所有数据向后移动一位,并将 key 存到 mKeys[i]//2、对应的情况是 2.2if (mGarbage && mSize >= mKeys.length) {gc();//GC 后再次进行查找,因为值可能已经发生变化了i = ~ContainerHelpers.binarySearch(mKeys, mSize, key);}//通过复制或者扩容数组,将数据存放到数组中mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key);mValues = GrowingArrayUtils.insert(mValues, mSize, i, value);mSize++;}}//和 put 方法类似//但在存入数据前先对数据大小进行了判断,有利于减少对 mKeys 进行二分查找的次数//所以在“存入的 key 比现有的 mKeys 值都大”的情况下会比 put 方法性能高public void append(int key, E value) {if (mSize != 0 && key <= mKeys[mSize - 1]) {put(key, value);return;}if (mGarbage && mSize >= mKeys.length) {gc();}mKeys = GrowingArrayUtils.append(mKeys, mSize, key);mValues = GrowingArrayUtils.append(mValues, mSize, value);mSize++;}
上文说:布尔变量mGarbage用于标记当前是否有待垃圾回收(GC)的元素,当该值为true时,即意味着当前状态需要垃圾回收,回收操作不是立马进行的,而是在后续操作中完成。
以下几个方法在移除元素时,只是切断mValues中的引用,而mKeys没进行回收,这个操作gc()进行处理。
//如果存在 key 对应的元素值,则将其移除public void delete(int key) {//用二分查找法查找指定 key 在 mKeys 中的索引值int i = ContainerHelpers.binarySearch(mKeys, mSize, key);if (i >= 0) {if (mValues[i] != DELETED) {mValues[i] = DELETED;//标记当前需要进行垃圾回收mGarbage = true;}}}public void remove(int key) {delete(key);}//和 delete 方法基本相同,差别在于会返回 key 对应的元素值public E removeReturnOld(int key) {int i = ContainerHelpers.binarySearch(mKeys, mSize, key);if (i >= 0) {if (mValues[i] != DELETED) {final E old = (E) mValues[i];mValues[i] = DELETED;mGarbage = true;return old;}}return null;}//删除指定索引对应的元素值public void removeAt(int index) {if (mValues[index] != DELETED) {mValues[index] = DELETED;//标记当前需要进行垃圾回收mGarbage = true;}}//删除从起始索引值 index 开始之后的 size 个元素值public void removeAtRange(int index, int size) {//避免发生数组越界的情况final int end = Math.min(mSize, index + size);for (int i = index; i < end; i++) {removeAt(i);}}//移除所有元素值public void clear() {int n = mSize;Object[] values = mValues;for (int i = 0; i < n; i++) {values[i] = null;}mSize = 0;mGarbage = false;}
垃圾回收、
因为SparseArray中可能会出现只移除value和value两者之一的情况,导致数组存在无效引用,因此gc()方法就用于移除无效引用,并将有效的元素值位置合在一起
//垃圾回收//因为 SparseArray 中可能出现只移除 value 和 value 两者之一的情况//所以此方法就用于移除无用的引用private void gc() {int n = mSize;//o 值用于表示 GC 后的元素个数int o = 0;int[] keys = mKeys;Object[] values = mValues;for (int i = 0; i < n; i++) {Object val = values[i];//元素值非默认值 DELETED ,说明该位置可能需要移动数据if (val != DELETED) {//以下代码片段用于将索引 i 处的值赋值到索引 o 处//所以如果 i == o ,则不需要执行代码了if (i != o) {keys[o] = keys[i];values[o] = val;values[i] = null;}o++;}}mGarbage = false;mSize = o;}
相关文章:

容器学习之SparseArray源码解析
1、SparseArray是android sdk 提供集合类,主要用来替换key 为int类型,value为Object类型的Hashmap 2、SparseArray和HashMap相比优缺点: 优点: 1、SparseArray存在一个int[]keys, 因此避免自动装箱 2、SparseArray扩容时只需要数…...

信创改造技术介绍
目录 服务发现和注册 Sentinel 核心功能 典型应用场景 gateway 网关的主要功能 Spring Cloud Gateway Kong Kong 的主要功能 Kong 的架构: Kong 的使用场景: Kong 的部署模式: 优势 Gateway与Sentinel区别 Gateway Sentinel …...

【可见的点——欧拉函数】
在数论,对正整数n,欧拉函数是小于或等于n的正整数中与n互质的数的数目(不包括1) 题目 思路 有三个点比较特殊(因为一来这三个点一定可见,同时也无法用gcd 1判断):(0&am…...
Maven重点学习笔记(包入门 2万字)
Maven依赖管理项目构建工具 尚硅谷 5h 2023最新版 一,Maven简介 1.为什么学习Maven 1.1, Maven是一个依赖管理工具 1️⃣ jar包的规模 随着我们使用越来越多的框架,或者框架封装程度越来越高,项目中使用的jar包也越来越多。项目中&…...
—— Vue3 + SpringCloud 5 + MyBatisPlus + MySQL 项目系列(基于 Zulu 11))
1.分页查询(后端)—— Vue3 + SpringCloud 5 + MyBatisPlus + MySQL 项目系列(基于 Zulu 11)
本手册是基于 Vue3 SpringCloud5 MyBatisPlus MySQL 的项目结构和代码实现,旨在作为一个教学案例进行讲解。为了使案例更具普适性,文档中的公司名称、实体类、表名以及字段名称等敏感信息均已脱敏。 项目结构概述 项目采用标准的分层架构࿰…...

机器学习与深度学习的区别:深入理解与应用场景
在人工智能(AI)的广阔领域中,机器学习和深度学习是两个核心概念,它们虽然紧密相关,但在定义、技术、数据处理能力、应用场景等方面存在显著差异。本文将深入探讨这些区别,帮助读者更好地理解并选择合适的技…...
)
C++学习笔记(45)
322、循环队列、信号量、生产/消费者模型的源代码 一、demo1.cpp // demo1.cpp,本程序演示循环队列的使用。 #include "_public.h" int main() { using ElemTypeint; squeue<ElemType,5> QQ; ElemType ee; // 创建一个数据元素。 cout << &qu…...
【2】图像视频的加载和显示
文章目录 【2】图像视频的加载和显示一、代码在哪写二、创建和显示窗口(一)导入OpenCV的包cv2(二)创建窗口(三)更改窗口大小 & 显示窗口(四)等待用户输入补充:ord()函…...

1. BOOT.BIN 2. 固化 3. 启动 4. SDK 5. 文件
在进行FPGA的开发与固化过程中,生成BOOT.BIN文件是一个重要的步骤。BOOT.BIN文件通常包含了系统启动所需的不同文件,以下是如何创建和使用该文件的详细说明。 ### 生成BOOT.BIN文件的步骤 1. **方法一:通过项目构建** - 右键单击项目…...

vue按钮接收键盘回车事件
了解了!如果您想让 Submit 按钮在按下回车键时被触发,可以在 Vue 组件中监听全局的键盘事件。以下是实现这一功能的示例: 示例代码 <template><div><inputtype"text"v-model"inputValue"placeholder&qu…...
腾讯云点播及声音上传
文章目录 1、开通腾讯云点播2、获取腾讯云API密钥3、完成声音上传3.1、引入依赖3.2、参考:接入点地域3.3、参考:任务流设置3.4、首先修改配置:3.4.1、 3.5、TrackInfoApiController --》 uploadTrack()3.6、VodServiceImpl --》 uploadTrack(…...

如何查看服务器是否有raid阵列卡以及raid类型
要查看服务器是否配置了RAID阵列卡以及RAID的类型,可以使用多种方法。以下是一些常用的命令和步骤: 1. 使用 lspci 命令 这个命令可以列出所有的PCI设备,包括RAID控制器。 lspci | grep -i raid 如果输出中有RAID相关的设备信息,那…...

工博会动态 | 来8.1馆 看桥田如何玩转全场
北京时间2024年9月24日,中国国际工业博览会开幕,桥田智能(8.1馆A001)推出心意三重奏,有没有小伙伴们发现呢?现在,让我们一起city walk下! 桥田显眼包横空出道 有小伙伴已经发现&…...

新版torch_geometric不存在uniform、maybe_num_nodes函数问题(Prune4ED论文报错解决)
这是在复现论文“Towards accurate subgraph similarity computation via neural graph pruning”时遇到的报错。 ImportError: cannot import name uniform from torch_geometric.nn.pool.topk_pool 一、报错原因 论文作者使用的是2.1.0版本的torch_geometric。而我安装了2.…...
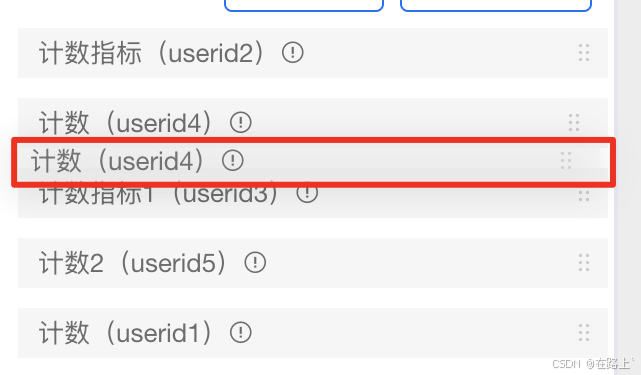
实现简易 vuedraggable 的拖拽排序功能
一、案例效果 拖拽计数4实现手动排序 二、案例代码 <draggable:list"searchResult.indicator":group"{ name: indicators }"item-key"field"handle".drag-handle-icon"><divclass"field-item"v-for"(item…...

第L2周:机器学习|线性回归模型 LinearRegression:2. 多元线性回归模型
本文为365天深度学习训练营 中的学习记录博客原作者:K同学啊 任务: ●1. 学习本文的多元线形回归模型。 ●2. 参考文本预测花瓣宽度的方法,选用其他三个变量来预测花瓣长度。 一、多元线性回归 简单线性回归:影响 Y 的因素唯一&…...
JavaScript的条件语句
if条件语句 if结构先判断一个表达式的布尔值,然后根据布尔值的真伪,执行不同的语句。所谓布尔值,指的是JavaScript 的两个特殊值,true表示真,false表示伪。 if语句语法规范 if(布尔值){语句;}var m3if(m3){console.l…...

vue3 vite模式配置测试,开发、生产环境以及代理配置
1、首先在根目录下创建三个文本文件:.env.development,.env.production,.env.test .env.development中的内容为: // 开发环境 .env.development NODE_ENV development VITE_APP_MODE development VITE_OUTPUTDIR dist_dev /…...

【rabbitmq-server】安装使用介绍
在 1050a 系统下安装 rabbitmq-server 服务以及基本配置;【注】:改方案用于A版统信服务器操作系统 文章目录 功能概述功能介绍一、安装软件包二、启动服务三、验证四、基本配置功能概述 RabbitMQ 是AMQP的实现,高性能的企业消息的新标准。RabbitMQ服务器是一个强大和可扩展…...

Kafka系列之:安装部署CMAK,CMAK管理大型Kafka集群参数调优
Kafka系列之:安装部署CMAK,CMAK管理大型Kafka集群参数调优 一、CMAK二、要求三、配置四、启动服务五、使用 Security 启动服务六、消费者/生产者滞后七、从 Kafka Manager 迁移到 CMAK八、CMAK管理大型Kafka集群参数调优九、后台运行CMAK十、输出日志一、CMAK CMAK(之前称为…...

将HermesAgent项目接入Taotoken的详细配置步骤与注意事项
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 将HermesAgent项目接入Taotoken的详细配置步骤与注意事项 本文旨在为开发者提供一份清晰的指南,帮助你将HermesAgent项…...
)
别再死记硬背了!用MATLAB手把手教你画根轨迹图(附代码与避坑指南)
MATLAB实战:从零绘制根轨迹图的完整指南与避坑技巧 在控制系统的设计与分析中,根轨迹图是理解系统动态特性的重要工具。传统教学中,学生往往被要求死记硬背绘制规则,却难以理解其实际应用价值。本文将彻底改变这一现状——通过MAT…...

NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程
NS-USBLoader终极指南:3步搞定Switch游戏管理与RCM注入的完整教程 【免费下载链接】ns-usbloader Awoo Installer and GoldLeaf uploader of the NSPs (and other files), RCM payload injector, application for split/merge files. 项目地址: https://gitcode.c…...
)
告别混乱信号!用CANdb++ Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程)
告别混乱信号!用CANdb Editor从零搭建汽车CAN网络DBC文件(保姆级图文教程) 在汽车电子开发领域,CAN总线如同神经脉络般贯穿整车系统。我曾参与过一个新能源整车项目,由于早期缺乏规范的DBC文件,不同ECU厂商…...

高效浏览器视频嗅探工具:猫抓扩展完整使用指南
高效浏览器视频嗅探工具:猫抓扩展完整使用指南 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(Cat-Catch)…...

从TPM到机密计算:远程证明技术原理与zap1项目实践指南
1. 项目概述与核心价值最近在整理一些零散的学习笔记时,发现了一个挺有意思的项目,叫Frontier-Compute/zap1-learning-attestation。乍一看这个标题,可能有点让人摸不着头脑,尤其是对于刚接触可信计算或者硬件安全领域的朋友来说。…...

3个维度深度解析:UABEA如何重塑Unity资源处理生态
3个维度深度解析:UABEA如何重塑Unity资源处理生态 【免费下载链接】UABEA c# uabe for newer versions of unity 项目地址: https://gitcode.com/gh_mirrors/ua/UABEA 在Unity游戏开发和资源处理的复杂生态中,开发者常常面临一个核心挑战…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

时空镜像立体成像楼宇全态透明智慧管控技术解析方案
时空镜像立体成像楼宇全态透明智慧管控技术解析方案一、方案概述当前传统楼宇管控普遍存在二维监控信息碎片化、空间感知能力薄弱、人员定位依赖外设、跨镜头轨迹断裂、身份核验存在漏洞、设备运维滞后、区域管控存在盲区等行业共性痛点,多数系统仅实现视频录像与基…...

GitClaw:基于Go的轻量级Git钩子服务器与集中式权限管理方案
1. 项目概述与核心价值如果你是一名开发者,尤其是经常在团队协作中处理Git仓库的工程师,那么你一定对“权限管理”这四个字又爱又恨。爱的是它能保障代码安全,恨的是它配置起来繁琐,尤其是在处理跨项目、跨团队的复杂权限矩阵时。…...