0基础学习PyTorch——GPU上训练和推理
大纲
- 创建设备
- 训练
- 推理
- 总结
在《Windows Subsystem for Linux——支持cuda能力》一文中,我们让开发环境支持cuda能力。现在我们要基于《0基础学习PyTorch——时尚分类(Fashion MNIST)训练和推理》,将代码修改成支持cuda的训练和推理。
创建设备
我们首先需要依据环境是否支持cuda来创建相应设备。
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
因为我们开发环境WSL已经支持了cuda,所以此时我们创建的是GPU设备。
训练
训练的过程有两处修改:
- 将模型实例化到GPU上。
model = GarmentClassifier().to(device) # model = GarmentClassifier()
- 将数据移动到GPU上。
inputs, labels = data # 获取输入数据和对应的标签
inputs, labels = inputs.to(device), labels.to(device) # 将数据移动到GPU上
完整代码如下
from datetime import datetime
import torch
import torchvision
import torchvision.transforms as transforms
from garmentclassifier import GarmentClassifier# 定义图像转换操作:将图像转换为张量,并进行归一化处理
transform = transforms.Compose([transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))]) # 对图像的每个通道进行标准化,使得每个通道的像素值具有零均值和单位标准差# 加载FashionMNIST训练数据集,并应用定义的图像转换操作
training_set = torchvision.datasets.FashionMNIST('./data', train=True, transform=transform)# 创建数据加载器,用于批量加载训练数据,batch_size为4,数据顺序随机打乱
trainloader = torch.utils.data.DataLoader(training_set, batch_size=4, shuffle=True)# 将模型移动到GPU上
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 实例化模型并移动到GPU上
model = GarmentClassifier().to(device)# 定义损失函数为交叉熵损失
loss_fn = torch.nn.CrossEntropyLoss()
# 定义优化器为随机梯度下降(SGD),学习率为0.001,动量为0.9
optimizer = torch.optim.SGD(model.parameters(), lr=0.001, momentum=0.9)# 训练模型,训练2个epoch
for epoch in range(2):running_loss = 0.0 # 初始化累计损失# 枚举数据加载器中的数据,i是批次索引,data是当前批次的数据for i, data in enumerate(trainloader, 0):inputs, labels = data # 获取输入数据和对应的标签inputs, labels = inputs.to(device), labels.to(device) # 将数据移动到GPU上optimizer.zero_grad() # 清空梯度outputs = model(inputs) # 前向传播,计算模型输出loss = loss_fn(outputs, labels) # 计算损失loss.backward() # 反向传播,计算梯度optimizer.step() # 更新模型参数running_loss += loss.item() # 累加损失# 每2000个批次打印一次平均损失if i % 2000 == 1999:print(f'[{epoch + 1}, {i + 1}] loss: {running_loss / 2000}')running_loss = 0.0 # 重置累计损失# 获取当前时间戳,格式为 'YYYYMMDD_HHMMSS'
timestamp = datetime.now().strftime('%Y%m%d%H%M%S.pth')# 定义模型保存路径,包含时间戳
model_path = 'model_{}'.format(timestamp) # 保存模型的状态字典到指定路径
torch.save(model.state_dict(), model_path)

推理
GPU上算出的模型不一定非要在GPU上推理,也可以在CPU上推理。
但是本文我们就是希望模型在GPU上推理,则可以对代码做如下修改。
- 将模型实例化到GPU上。
model = GarmentClassifier().to(device) # model = GarmentClassifier()
- 将数据移动到GPU上。
image = image.to(device) # 将图像移动到GPU上
完整代码如下
import os
import glob
import torch
import torchvision.transforms as transforms
from PIL import Image
from datetime import datetime
from garmentclassifier import GarmentClassifierdef get_latest_model_path(directory, pattern="model_*.pth"):# 获取目录下所有符合模式的文件model_files = glob.glob(os.path.join(directory, pattern))if not model_files:raise FileNotFoundError("No model files found in the directory.")# 找到最新的模型文件latest_model_file = max(model_files, key=os.path.getmtime)return latest_model_file# 定义图像转换操作:将图像转换为张量,并进行归一化处理
transform = transforms.Compose([transforms.Resize((28, 28)), # 调整图像大小为28x28transforms.ToTensor(),transforms.Normalize((0.5,), (0.5,))
])# 将模型移动到GPU上
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')# 实例化模型并移动到GPU上
model = GarmentClassifier().to(device) # 加载训练好的模型
model_path = get_latest_model_path('./') # 获取最新的模型文件
model.load_state_dict(torch.load(model_path, weights_only=False)) # 加载模型参数
model.eval() # 设置模型为评估模式# 从本地加载图像
image_path = 'shoe.jpg' # 替换为实际的图像路径
image = Image.open(image_path).convert('L') # 将图像转换为灰度图# 预处理图像
image = transform(image)
image = image.unsqueeze(0) # 增加一个批次维度
image = image.to(device) # 将图像移动到GPU上# 推理(预测)
with torch.no_grad(): # 在推理过程中不需要计算梯度outputs = model(image) # 前向传播,计算模型输出_, predicted = torch.max(outputs, 1) # 获取预测结果# 定义类别名称
classes = ('T-shirt/top', 'Trouser', 'Pullover', 'Dress', 'Coat','Sandal', 'Shirt', 'Sneaker', 'Bag', 'Ankle boot')# 打印预测结果
print(f'Predicted label: {classes[predicted.item()]}')

总结
- 依据系统是否支持cuda来生成设备。
- 模型和数据都要移动到相同的设备上。
- 模型是由CPU还是GPU训练的,并不影响推理使用CPU还是GPU。
相关文章:
0基础学习PyTorch——GPU上训练和推理
大纲 创建设备训练推理总结 在《Windows Subsystem for Linux——支持cuda能力》一文中,我们让开发环境支持cuda能力。现在我们要基于《0基础学习PyTorch——时尚分类(Fashion MNIST)训练和推理》,将代码修改成支持cuda的训练和推…...
这款免费工具让你的电脑焕然一新,专业人士都在用
HiBit Uninstaller 采用单一可执行文件的形式,无需复杂的安装过程,用户可以即刻开始使用。这种便捷性使其成为临时使用或紧急情况下的理想选择。尽管体积小巧,但其功能却异常强大,几乎不会对系统性能造成任何负面影响。 这款工具的一大亮点是其多样化的功能。它不仅能够常规卸…...

Java高级Day52-BasicDAO
138.BasicDao 基本说明: DAO:data access object 数据访问对象 这样的通用类,称为 BasicDao,是专门和数据库交互的,即完成对数据库(表)的crud操作 在BasicDao 基础上,实现一张表对应一个Dao,…...

【OceanBase 诊断调优】—— SQL 诊断宝典
视频 OceanBase 数据库 SQL 诊断和优化:https://www.oceanbase.com/video/5900015OB Cloud 云数据库 SQL 诊断与调优的应用实践:https://www.oceanbase.com/video/9000971SQL 优化:https://www.oceanbase.com/video/9000889阅读和管理SQL执行…...

微服务Redis解析部署使用全流程
目录 1、什么是Redis 2、Redis的作用 3、Redis常用的五种基本类型(重要知识点) 4、安装redis 4.1、查询镜像文件【省略】 4.2、拉取镜像文件 4.3、启动redis并设置密码 4.3.1、修改redis密码【可以不修改】 4.3.2、删除密码【坚决不推荐】 5、S…...

C++之STL—常用排序算法
sort (iterator beg, iterator end, _Pred) // 按值查找元素,找到返回指定位置迭代器,找不到返回结束迭代器位置 // beg 开始迭代器 // end 结束迭代器 // _Pred 谓词 random_shuffle(iterator beg, iterator end); // 指定范围内的元素随机调…...

【驱动】地平线X3派:备份与恢复SD卡镜像
1、备份镜像 1.1 安装gparted GParted是硬盘分区软件GNU Parted的GTK+图形界面前端,是GNOME桌面环境的默认分区软件。 GParted可以用于创建、删除、移动分区,调整分区大小,检查、复制分区等操作。可以用于调整分区以安装新操作系统、备份特定分区到另一块硬盘等。 在Ubun…...

【C++报错已解决】std::ios_base::failure
🎬 鸽芷咕:个人主页 🔥 个人专栏: 《C干货基地》《粉丝福利》 ⛺️生活的理想,就是为了理想的生活! 专栏介绍 在软件开发和日常使用中,BUG是不可避免的。本专栏致力于为广大开发者和技术爱好者提供一个关于BUG解决的经…...
多项式、符号函数、数据统计)
matlab入门学习(四)多项式、符号函数、数据统计
一、多项式 %多项式(polynomial)%创建 p[1,2,3,4] %系数向量,按x降幂排列,最右边是常数(x的0次幂) f1poly2str(p,x) %系数向量->好看的字符串 f x^3 2 x^2 3 x 4(不能运算的式子…...

leetcode621. 任务调度器
给你一个用字符数组 tasks 表示的 CPU 需要执行的任务列表,用字母 A 到 Z 表示,以及一个冷却时间 n。每个周期或时间间隔允许完成一项任务。任务可以按任何顺序完成,但有一个限制:两个 相同种类 的任务之间必须有长度为 n 的冷却时…...

Spark 的 Skew Join 详解
Skew Join 是 Spark 中为了解决数据倾斜问题而设计的一种优化机制。数据倾斜是指在分布式计算中,由于某些 key 具有大量数据,而其他 key 数据较少,导致某些分区的数据量特别大,造成计算负载不均衡。数据倾斜会导致个别节点出现性能…...

讯飞星火编排创建智能体学习(一)最简单的智能体构建
目录 开篇 智能体的概念 编排创建智能体 创建第一个智能体 编辑 大模型节点 测试与调试 开篇 前段时间在华为全联接大会上看到讯飞星火企业级智能体平台的演示,对于拖放的可视化设计非常喜欢,刚开始以为是企业用户才有的,回来之后查…...

mac-m1安装nvm,docker,miniconda
1.安装minicondaMAC OS(M1)安装配置miniconda_mac-mini m1 conda-CSDN博客 2.安装nvm(用第二个方法)Mac电脑安装nvm(node包版本管理工具)-CSDN博客 3.安装docker dmg下载链接docker-toolbox-mac-docker-for-mac安装包下载_开源镜像站-阿里云 教程MacOS系…...

STM32F407之Flash
寄存器分类 一般寄存器分为只读存储器 (ROM) 随机存储器(RAM) 只读存储器 只读存储器也被称为ROM 在正常工作时只能读不能写。 只读存储器经历的阶段 ROM->PROM->EPROM->EEPROM ->Flash 优点:掉电不丢失,解构简单 缺点:只适…...
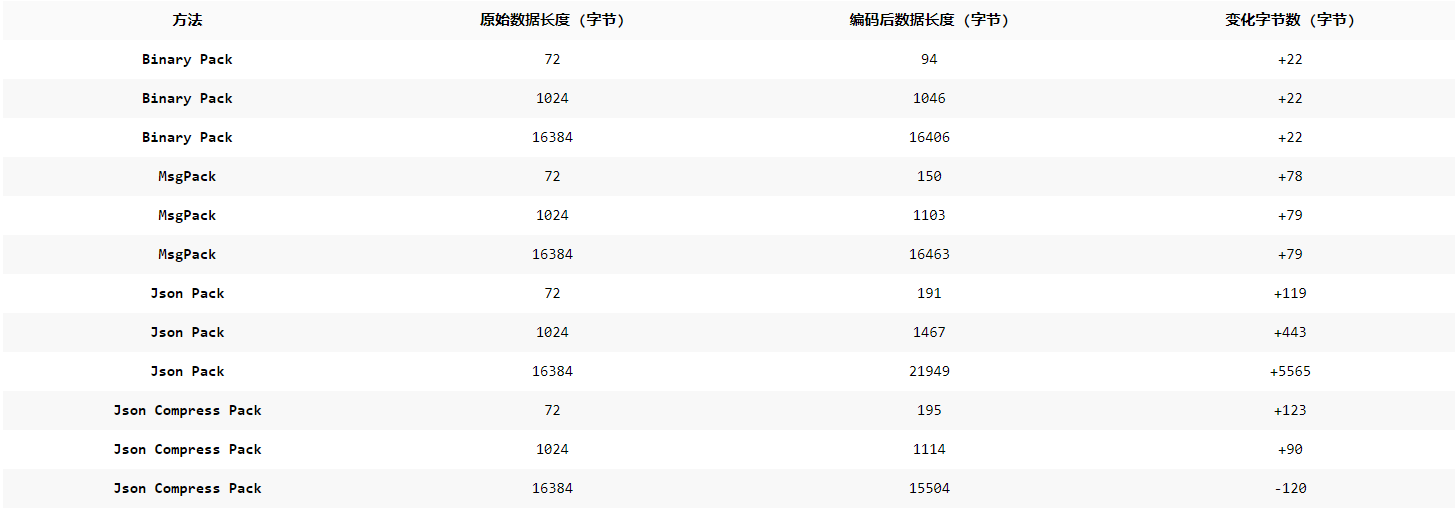
优化 Go 语言数据打包:性能基准测试与分析
场景:在局域网内,需要将多个机器网卡上抓到的数据包同步到一个机器上。 原有方案:tcpdump -w 写入文件,然后定时调用 rsync 进行同步。 改造方案:使用 Go 重写这个抓包逻辑及同步逻辑,直接将抓到的包通过网…...

【SQL】未订购的客户
目录 语法 需求 示例 分析 代码 语法 SELECT columns FROM table1 LEFT JOIN table2 ON table1.common_field table2.common_field; LEFT JOIN(或称为左外连接)是SQL中的一种连接类型,它用于从两个或多个表中基于连接条件返回左表…...

Qt(9.28)
widget.cpp #include "widget.h"Widget::Widget(QWidget *parent): QWidget(parent) {QPushButton *btn1 new QPushButton("登录",this);this->setFixedSize(640,480);btn1->resize(80,40);btn1->move(200,300);btn1->setIcon(QIcon("C:…...

javascript-冒泡排序
前言:好久没学习算法了,今天看了一个视频课,之前掌握很好的冒泡排序居然没写出来? <!DOCTYPE html> <html lang"en"><head><meta charset"UTF-8"><meta name"viewport"…...

第九届蓝桥杯嵌入式省赛程序设计题解析(基于HAL库)
一.题目分析 (1).题目 (2).题目分析 按键功能分析----存储位置的切换键 a. B1按下切换存储位置,切换后定时时间设定为当前位置存储的时间 b. B2短按切换时分秒高亮,设置完成后,长按把设置的时…...

MATLAB云计算集成:在云端扩展计算能力
摘要 MATLAB云计算集成是指将MATLAB的计算能力与云平台的弹性资源相结合,以实现高性能计算、数据处理和算法开发。本文详细介绍了MATLAB云计算的基本概念、优势、配置要点以及编程实践。 1. 云计算概述 云计算是一种通过互联网提供计算资源(如服务器、…...

DeerFlow免运维部署:自动日志监控与服务启动检测
DeerFlow免运维部署:自动日志监控与服务启动检测 1. 认识你的深度研究助理:DeerFlow 想象一下,你有一个不知疲倦的研究助手。它能帮你搜索全网信息、分析复杂数据、撰写专业报告,甚至还能把枯燥的研究结果变成一段生动的播客。听…...

CBoard自研多维引擎揭秘:轻量级架构如何撬动大数据分析
CBoard自研多维引擎揭秘:轻量级架构如何撬动大数据分析 【免费下载链接】CBoard CBoard - 这是一个基于 Node.js 的开源面板,用于管理 Kubernetes 集群和应用程序。适用于 Kubernetes 集群管理、容器编排、持续集成等场景。 项目地址: https://gitcode…...

突破百度网盘限速:Mac用户7分钟解锁SVIP级下载体验
突破百度网盘限速:Mac用户7分钟解锁SVIP级下载体验 【免费下载链接】BaiduNetdiskPlugin-macOS For macOS.百度网盘 破解SVIP、下载速度限制~ 项目地址: https://gitcode.com/gh_mirrors/ba/BaiduNetdiskPlugin-macOS 还在为百度网盘非会员100KB/s的龟速下载…...

PT-Plugin-Plus:极简高效的PT种子下载辅助工具
PT-Plugin-Plus:极简高效的PT种子下载辅助工具 【免费下载链接】PT-Plugin-Plus PT 助手 Plus,为 Microsoft Edge、Google Chrome、Firefox 浏览器插件(Web Extensions),主要用于辅助下载 PT 站的种子。 项目地址: h…...

产品 SEO 关键词与转化率的关系是什么_如何评估产品 SEO 关键词的价值
<h3 id"seo_seo">产品 SEO 关键词与转化率的关系是什么_如何评估产品 SEO 关键词的价值</h3> <p>在数字营销的世界里,产品 SEO 关键词(Search Engine Optimization,搜索引擎优化)的作用不可忽视。这不…...

【多模态实战】Swift框架高效微调Qwen2-VL:从SFT到RLHF的完整指南
1. 为什么选择Swift框架微调Qwen2-VL 第一次接触Qwen2-VL这个多模态大模型时,我被它强大的图文理解能力惊艳到了。但真正让我惊喜的是发现Swift框架能让模型微调变得如此简单。记得当时为了测试一个定制化需求,传统方法需要写上百行训练代码,…...

VSCode安装与应用
vscode官网:https://code.visualstudio.com/Download 点击下一步 注意:这里将创建桌面快捷和下面的1、2勾选,3取消掉(以便后续VSCode能右键快捷打开相关文件,3若不取消会将改变文件默认图标为VSCode,并且打…...

OpenClaw本地搜索增强:GLM-4.7-Flash智能文件检索系统
OpenClaw本地搜索增强:GLM-4.7-Flash智能文件检索系统 1. 为什么需要智能文件检索 作为一个长期被杂乱文件困扰的技术写作者,我经常陷入"明明记得存过某个文档却死活找不到"的困境。传统的文件名搜索就像在黑暗房间里用手电筒找东西——必须…...

macOS Monterey安装OpenClaw:对接Qwen3-32B镜像全记录
macOS Monterey安装OpenClaw:对接Qwen3-32B镜像全记录 1. 为什么选择OpenClaw与Qwen3-32B组合 去年冬天第一次接触OpenClaw时,我正被重复性的文件整理工作折磨得焦头烂额。当时试过几个自动化工具,要么功能太局限,要么需要把数据…...

5个核心功能实现全球多语言语音降噪:基于深度滤波的开源解决方案
5个核心功能实现全球多语言语音降噪:基于深度滤波的开源解决方案 【免费下载链接】DeepFilterNet Noise supression using deep filtering 项目地址: https://gitcode.com/GitHub_Trending/de/DeepFilterNet 在当今全球化的语音通信时代,背景噪声…...