遥感图像变换检测实践上手(TensorRT+UNet)
目录
简介
分析PyTorch示例
onnx模型转engine
编写TensorRT推理代码
main.cpp测试代码
小结
简介
这里通过TensorRT+UNet,在Linux下实现对遥感图像的变化检测,示例如下:

可以先拉去代码:RemoteChangeDetection

分析PyTorch示例
在目录PyFiles中,unet.py存放UNet网络定义,可以使用test_infer.py脚本进行推理并导出onnx模型,可以简单分析一下test_infer.py中的关键代码。
(1)加载处理图像
import torch
import numpy as np
from PIL import Image
from torchvision import transforms
from unet import UNet
import onnx
import onnxsim# 读取变换前后的代码
img1 = Image.open("./A/val_20.png")
img2 = Image.open("./B/val_20.png")# 输出的图像名称
output_image_path = "result.png"# PIL图像转Tensor张量
transform = transforms.Compose([transforms.ToTensor()
])# 分别取两幅图像的第一个通道图像,因为PIL读取的图像是RGB的,注意和OpenCV图像区别
img1_data = np.array(img1)
img1_data = img1_data[:, :, 0]img2_data = np.array(img2)
img2_data = img2_data[:, :, 0]# 这里合并输入图像: shape ==> [height, width, 2]
input_image = np.stack([img1_data, img2_data], axis=2)# 转换为模型输入,大致流程:
# 1. transform: 图像从[0, 255] 映射到 [0, 1]; 交换通道图像[h, w, 2] => [2, h, w]
# 2. unsqueeze(0),增加第一个维度:[2, h, w] => [1, 2, h, w]
# 3. unit8 转 float32类型,并放置在GPU上
input_image_tensor = transform(input_image).unsqueeze(0).type(torch.float32).to(device)(2)推理并导出为onnx
def export_norm_onnx(model, file, input):torch.onnx.export(model = model, args = (input,),f = file,input_names = ["input0"],output_names = ["output0"],opset_version = 9)print("Finished normal onnx export")model_onnx = onnx.load(file)onnx.checker.check_model(model_onnx)# 使用onnx-simplifier来进行onnx的简化。print(f"Simplifying with onnx-simplifier {onnxsim.__version__}...")model_onnx, check = onnxsim.simplify(model_onnx)assert check, "assert check failed"onnx.save(model_onnx, file)这里定义了一个导出onnx函数,model为PyTorch模型,file是输出文件路径,input是模型的输入。
with torch.no_grad():net = UNet(2).to(device)net.eval()load_models = torch.load(weights)net.load_state_dict(torch.load(weights))out_image = net(input_image_tensor)_out_image = out_image[0][0].round().detach().cpu().numpy()_out_image = (_out_image * 255).astype(np.uint8)result_image = Image.fromarray(_out_image)result_image.save(output_image_path)export_norm_onnx(net, "./unet_simple.onnx", input_image_tensor)这里是推理(为了测试.pth模型)并导出onnx。这里注意对输出图像的后处理过程,在编写c++接口时要留意。

使用onnx可视化工具查看导出的onnx模型:

onnx模型转engine
如果你已经按照了TensorRT,并且配置好了环境变量后,可以直接使用bin下的trtexec命令将onnx模型进行转换,假如你的TensorRT安装路径如下:

环境变量的配置:

使用如下命令进行转换:
trtexec --onnx=dncnn_color_blind.onnx --saveEngine=dncnn_color_engine_intro.engine --explicitBatch
// *.onnx是输入的模型,*.engine是保存的模型上边只是举个例子,把文件名换成自己的就可以了。
编写TensorRT推理代码
(1)运行环境搭建
我的运行环境目录大致如下:
RemoteChangeDetection
3rdparty|------- opencv-3.4.10|-------- include|-------- lib|------- TensorRT-8.5.2.2|-------- include|-------- lib...首先修改CMakeLists.txt中的三方库路径:

那么你应该修改CUDA,CUDNN,OpenCV以及TensorRT的路径。
在src/路径下是核心代码,trt_logger包含了TensorRT推理时依赖的logger,以及CUDA函数运行时的检查宏:
#ifndef __LOGGER_H__
#define __LOGGER_H__#include <string>
#include <stdarg.h>
#include <memory>
#include <cuda_runtime.h>
#include <system_error>
#include "NvInfer.h"#define CUDA_CHECK(call) __cudaCheck(call, __FILE__, __LINE__)
#define LAST_KERNEL_CHECK(call) __kernelCheck(__FILE__, __LINE__)static void __cudaCheck(cudaError_t err, const char* file, const int line) {if (err != cudaSuccess) {printf("ERROR: %s:%d, ", file, line);printf("code:%s, reason:%s\n", cudaGetErrorName(err), cudaGetErrorString(err));exit(1);}
}static void __kernelCheck(const char* file, const int line) {cudaError_t err = cudaPeekAtLastError();if (err != cudaSuccess) {printf("ERROR: %s:%d, ", file, line);printf("code:%s, reason:%s\n", cudaGetErrorName(err), cudaGetErrorString(err));exit(1);}
}#define LOGF(...) logger::Logger::__log_info(logger::Level::FATAL, __VA_ARGS__)
#define LOGE(...) logger::Logger::__log_info(logger::Level::ERROR, __VA_ARGS__)
#define LOGW(...) logger::Logger::__log_info(logger::Level::WARN, __VA_ARGS__)
#define LOG(...) logger::Logger::__log_info(logger::Level::INFO, __VA_ARGS__)
#define LOGV(...) logger::Logger::__log_info(logger::Level::VERB, __VA_ARGS__)
#define LOGD(...) logger::Logger::__log_info(logger::Level::DEBUG, __VA_ARGS__)最重要的是UNetTrt部分,在UNetTrt.h:
#ifndef UNET_TRT_H_
#define UNET_TRT_H_#include <iostream>
#include <memory>
#include <opencv2/opencv.hpp>
#include <cuda_runtime.h>// 前置定义
namespace nvinfer1
{class IRuntime;class ICudaEngine;class IExecutionContext;
}class UNet
{
public:UNet() {};~UNet();// 加载engine文件bool loadTrtModel(const std::string model_path);// 推理,input_mat1: 变换前;input_mat2: 变换后;output是变量引用bool trt_infer(cv::Mat &input_mat1, cv::Mat &input_mat2, cv::Mat &output); // input_mat1: before, input_mat2: afterprivate:// runtime_, engine_, context_等成员是TensorRT推理时最重要的几个成员变量// 为了放置内存泄露,用智能指针管理std::shared_ptr<nvinfer1::IRuntime> runtime_; std::shared_ptr<nvinfer1::ICudaEngine> engine_;std::shared_ptr<nvinfer1::IExecutionContext> context_;cudaStream_t stream_;int input_index_; // 索引输入int output_index_; // 索引输出const char *INPUT_NAME = "input0"; // 输入名称,和onnx导入时保持一致const char *OUTPUT_NAME = "output0"; // 和上边保持一致const int BATCH_SIZE = 1; // 一般都保持为1void *buffers_[2]; // 存放TensorRT输入输出float *input_float_ = nullptr; // 存放Host端输入,c11允许.h中初始化float *output_float_ = nullptr; // Host端计算结果
};#endif在.cpp中,给出一些核心实现:
#include "UNetTrt.h"
#include <fstream>
#include <cmath>
#include "trt_logger.h"
#include "NvInfer.h"
#include "NvOnnxParser.h"#define INPUT_WIDTH 1024
#define INPUT_HEIGHT 1024bool UNet::loadTrtModel(const std::string model_path)
{char *trt_stream = nullptr;size_t size = 0;// load trt modelstd::ifstream file(model_path, std::ios::binary);if (file.good()) {file.seekg(0, file.end);size = file.tellg();file.seekg(0, file.beg);trt_stream = new char[size];if(!trt_stream)return false;file.read(trt_stream, size);file.close();} else {return false;}logger::Logger trt_logger(logger::Level::INFO);runtime_.reset(nvinfer1::createInferRuntime(trt_logger));if(!runtime_)return false;engine_.reset(runtime_->deserializeCudaEngine(trt_stream, size, nullptr));if(!engine_)return false;context_.reset(engine_->createExecutionContext());if(!context_)return false;const nvinfer1::ICudaEngine& trtEngine = context_->getEngine();input_index_ = trtEngine.getBindingIndex(INPUT_NAME);output_index_ = trtEngine.getBindingIndex(OUTPUT_NAME);CUDA_CHECK(cudaMalloc(&buffers_[input_index_], BATCH_SIZE * 2 * INPUT_WIDTH * INPUT_HEIGHT * sizeof(float)));CUDA_CHECK(cudaMalloc(&buffers_[output_index_], BATCH_SIZE * 1 * INPUT_WIDTH * INPUT_HEIGHT * sizeof(float)));input_float_ = new float[BATCH_SIZE * 2 * INPUT_WIDTH * INPUT_HEIGHT];output_float_ = new float[BATCH_SIZE * 1 * INPUT_WIDTH * INPUT_HEIGHT];delete []trt_stream;return true;
}首先,输入大小是固定的,所以在宏里写死了输入大小1024x1024;loadTrtModel根据路径加载engine文件,并对一些推理时用到的成员变量依次初始化,同时分配好输入输出空间。
推理代码如下:
bool UNet::trt_infer(cv::Mat &input_mat1, cv::Mat &input_mat2, cv::Mat &output)
{if(input_mat1.empty() || input_mat2.empty())return false;if(input_mat1.rows != input_mat2.rows || input_mat1.cols != input_mat2.cols)return false;if(input_mat1.channels() <= 1 && input_mat2.channels() <= 1) return false;int pre_width = input_mat1.cols;int pre_height = input_mat1.rows;cv::resize(input_mat1, input_mat1, cv::Size(INPUT_WIDTH, INPUT_HEIGHT), cv::INTER_CUBIC);cv::resize(input_mat2, input_mat2, cv::Size(INPUT_WIDTH, INPUT_HEIGHT), cv::INTER_CUBIC);std::vector<cv::Mat> input_mat1_channels;cv::split(input_mat1, input_mat1_channels);std::vector<cv::Mat> input_mat2_channels;cv::split(input_mat2, input_mat2_channels);// [H, W, C] => [C, H, W] && [0.0, 0.1]for(int i = 0; i < INPUT_WIDTH; i++) {for(int j = 0; j < INPUT_HEIGHT; j++) {int idx_c1 = j * INPUT_WIDTH + i;int idx_c2 = idx_c1 + INPUT_WIDTH * INPUT_HEIGHT;input_float_[idx_c1] = (float)input_mat1_channels[2].data[idx_c1] / 255.0f;input_float_[idx_c2] = (float)input_mat2_channels[2].data[idx_c1] / 255.0f;}}memset(output_float_, 0, BATCH_SIZE * 1 * INPUT_WIDTH * INPUT_HEIGHT);CUDA_CHECK(cudaStreamCreate(&stream_));CUDA_CHECK(cudaMemcpyAsync(buffers_[input_index_], input_float_, BATCH_SIZE * 2 * INPUT_WIDTH * INPUT_HEIGHT * sizeof(float), cudaMemcpyHostToDevice, stream_));context_->enqueueV2(buffers_, stream_, nullptr);CUDA_CHECK(cudaMemcpyAsync(output_float_, buffers_[output_index_], BATCH_SIZE * 1 * INPUT_WIDTH * INPUT_HEIGHT * sizeof(float), cudaMemcpyDeviceToHost, stream_));cudaStreamSynchronize(stream_);// roundfor(int i = 0; i < INPUT_WIDTH; i++) {for(int j = 0; j < INPUT_HEIGHT; j++) {int index = j * INPUT_WIDTH + i;output_float_[index] = std::round(output_float_[index]);}}output = cv::Mat(INPUT_HEIGHT, INPUT_WIDTH, CV_32F, output_float_);output *= 255.0;output.convertTo(output, CV_8U);cv::resize(output, output, cv::Size(pre_width, pre_height), cv::INTER_CUBIC);return true;
}这里依次讲解一下,首先你可能要把代码放入工程,那么应该尽量做好判断,比如图像是否为空;图像大小、通道是否一致,以防万一可以同时进行Resize;
cv::split对3通道图像进行剥离,放入vector中,然后开始进行通道转换与归一化。这里可以稍微理解一下不同图像在内存中的存放方式,一般的RGB图像或者BGR图像(height, width, channel)应该是这样:
B G R B G R B G R B G R B G R B G R
B G R B G R B G R B G R B G R B G R
B G R B G R B G R B G R B G R B G R
B G R B G R B G R B G R B G R B G R
互相交错存放,但是网络输入一般是(channel, height, width),那么存放方式是如下这样:
R R R R R R R R
R R R R R R R R
R R R R R R R RG G G G G G G G
G G G G G G G G
G G G G G G G GB B B B B B B B
B B B B B B B B
B B B B B B B B
那么就可以很容易写出通道转换与归一化代码:
// [H, W, C] => [C, H, W] && [0.0, 0.1]for(int i = 0; i < INPUT_WIDTH; i++) {for(int j = 0; j < INPUT_HEIGHT; j++) {int idx_c1 = j * INPUT_WIDTH + i;int idx_c2 = idx_c1 + INPUT_WIDTH * INPUT_HEIGHT;input_float_[idx_c1] = (float)input_mat1_channels[2].data[idx_c1] / 255.0f;input_float_[idx_c2] = (float)input_mat2_channels[2].data[idx_c1] / 255.0f;}}每次推理前把输出结果清空置为0:
memset(output_float_, 0, BATCH_SIZE * 1 * INPUT_WIDTH * INPUT_HEIGHT);重新分配cudaStream_t,cudaMemcpyAsync分配显存,context_->enqueueV2推理,cudaMemcpyAsync再将结果从显存拷贝到Host端。
CUDA_CHECK(cudaStreamCreate(&stream_));CUDA_CHECK(cudaMemcpyAsync(buffers_[input_index_], input_float_, BATCH_SIZE * 2 * INPUT_WIDTH * INPUT_HEIGHT * sizeof(float), cudaMemcpyHostToDevice, stream_));context_->enqueueV2(buffers_, stream_, nullptr);CUDA_CHECK(cudaMemcpyAsync(output_float_, buffers_[output_index_], BATCH_SIZE * 1 * INPUT_WIDTH * INPUT_HEIGHT * sizeof(float), cudaMemcpyDeviceToHost, stream_));cudaStreamSynchronize(stream_);后处理过程中,也遇到了一些坑,总体而言,还是要一一对照python那部分后处理代码仔细分析:
_out_image = out_image[0][0].round().detach().cpu().numpy()
_out_image = (_out_image * 255).astype(np.uint8)
result_image = Image.fromarray(_out_image)
result_image.save(output_image_path) // roundfor(int i = 0; i < INPUT_WIDTH; i++) {for(int j = 0; j < INPUT_HEIGHT; j++) {int index = j * INPUT_WIDTH + i;output_float_[index] = std::round(output_float_[index]);}}output = cv::Mat(INPUT_HEIGHT, INPUT_WIDTH, CV_32F, output_float_);output *= 255.0;output.convertTo(output, CV_8U);cv::resize(output, output, cv::Size(pre_width, pre_height), cv::INTER_CUBIC);因为图像是缩放过一次的,最后给缩放回去。
main.cpp测试代码
在main.cpp编写测试示例,一般是建议将类用智能指针管理:
std::shared_ptr<UNet> unet_infer = std::make_shared<UNet>();std::string model_path = "./weights/unet_simple_trt.engine";if(unet_infer) {if(unet_infer->loadTrtModel(model_path))std::cout << "UNet Init Successful! \n";else std::cout << "UNet Init Failed! \n";
}推理:
cv::Mat img1 = cv::imread("./test_images/val_20_A.png");
cv::Mat img2 = cv::imread("./test_images/val_20_B.png");
cv::Mat result;if(unet_infer->trt_infer(img1, img2, result)) {std::cout << "UNet Infer Successfully! \n";
} else {std::cout << "UNet Infer Failed! \n";
}当然,最后可以测试一下推理速度以及输出是不是一致:
int count = 100;
int cost = 0;for(int i = 0; i < count; i++) { auto start = std::chrono::high_resolution_clock::now(); bool success = unet_infer->trt_infer(img1, img2, result);auto end = std::chrono::high_resolution_clock::now();cost += std::chrono::duration_cast<std::chrono::milliseconds>(end - start).count();
}std::cout << "duration: " << (float)(cost) / count << " ms" << std::endl; if(!result.empty()) {cv::imwrite("./result.png", result);
}
显存占用:


对比了一下,1024x1024的输入,大概会消耗1G的显存,如果你缩小图像后再计算,效果会差一些。
计算耗时:

大概是80~90ms一张吧。
小结
上边只是初步实现了变换检测的推理,但是图像预处理与后处理还是有很多可以优化改进的地方,后边有时间再补上吧。
参考资料
ESCNet
ChangeDetection_GUI
TensorRT
tensorrtx
基于CUDA的并行计算技术
相关文章:
遥感图像变换检测实践上手(TensorRT+UNet)
目录 简介 分析PyTorch示例 onnx模型转engine 编写TensorRT推理代码 main.cpp测试代码 小结 简介 这里通过TensorRTUNet,在Linux下实现对遥感图像的变化检测,示例如下: 可以先拉去代码:RemoteChangeDetection 分析PyTorch示…...
Transformers 引擎,vLLM 引擎,Llama.cpp 引擎,SGLang 引擎,MLX 引擎
1. Transformers 引擎 开发者:Hugging Face主要功能:Transformers 库提供了对多种预训练语言模型的支持,包括 BERT、GPT、T5 等。用户可以轻松加载模型进行微调或推理。特性: 多任务支持:支持文本生成、文本分类、问答…...

牛顿迭代法求解x 的平方根
牛顿迭代法是一种可以用来快速求解函数零点的方法。 为了叙述方便,我们用 C C C表示待求出平方根的那个整数。显然, C C C的平方根就是函数 f ( x ) x c − C f(x)x^c-C f(x)xc−C 的零点。 牛顿迭代法的本质是借助泰勒级数,从初始值开始快…...

端口隔离配置的实验
端口隔离配置是一种网络安全技术,用于在网络设备中实现不同端口之间的流量隔离和控制。以下是对端口隔离配置的详细解析: 基本概念:端口隔离技术允许用户将不同的端口加入到隔离组中,从而实现这些端口之间的二层数据隔离。这种技…...

洛谷 P10456 The Pilots Brothers‘ refrigerator
[Problem Discription] \color{blue}{\texttt{[Problem Discription]}} [Problem Discription] 给定一个 4 4 4 \times 4 44 的网格,每个网格有 0 , 1 0,1 0,1 两种状态。求最少可以通过多少次操作使得整个网格全部变成 1 1 1。 每次操作你需要选定一个格点 …...

windows+vscode+arm-gcc+openocd+daplink开发arm单片机程序
windowsvscodearm-gccopenocddaplink开发arm单片机程序,脱离keil。目前发现的最佳解决方案是,使用vscodeembedded ide插件。 Embedded IDE官方教程文档...

Mysql梳理10——使用SQL99实现7中JOIN操作
10 使用SQL99实现7中JOIN操作 10.1 使用SQL99实现7中JOIN操作 本案例的数据库文件分享: 通过百度网盘分享的文件:atguigudb.sql 链接:https://pan.baidu.com/s/1iEAJIl0ne3Y07kHd8diMag?pwd2233 提取码:2233 # 正中图 SEL…...

24.9.27学习笔记
Xavier初始化,也称为Glorot初始化,是一种在训练深度神经网络时用于初始化网络权重的策略。它的核心思想是在网络的每一层保持前向传播和反向传播时的激活值和梯度的方差尽可能一致,以避免梯度消失或梯度爆炸的问题。这种方法特别适用于激活函…...
)
C++第3课——保留小数点、比较运算符、逻辑运算符、布尔类型以及if-else分支语句(含视频讲解)
文章目录 1、课程笔记2、课程视频 1、课程笔记 #include<iostream>//头文件 input output #include<cmath> //sqrt()所需的头文件 #include<iomanip>//setprecision(1)保留小数点位数所需的头文件 using namespace std; int main(){/*复习上节课内容1、…...

韩媒专访CertiK首席商务官:持续关注韩国市场,致力于解决Web3安全及合规问题
作为Web3.0头部安全公司,CertiK在KBW期间联合CertiK Ventures举办的活动引起了业界的广泛关注。CertiK一直以来与韩国地方政府保持着紧密合作关系,在合规领域提供强有力的支持。而近期重磅升级的CertiK Ventures可以更好地支持韩国本地的区块链项目。上述…...

计算机毕业设计之:宠物服务APP的设计与实现(源码+文档+讲解)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...
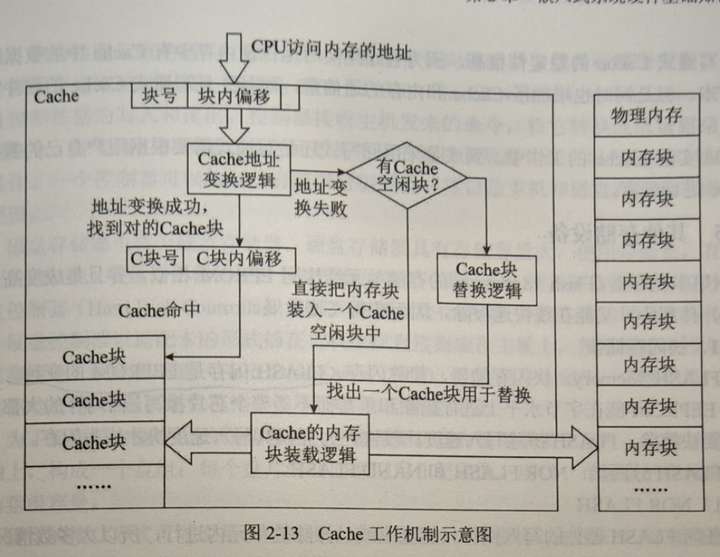
小柴冲刺软考中级嵌入式系统设计师系列二、嵌入式系统硬件基础知识(3)嵌入式系统的存储体系
目录 感悟 一、存储系统的层次结构 存储器系统 二、内存管理单元 三、RAM和ROM的种类与选型 1、RAM RAM分类 2、ROM ROM分类 四、高速缓存Cache 五、其他存储设备 flechazohttps://www.zhihu.com/people/jiu_sheng 小柴冲刺软考中级嵌入式系统设计师系列总目录https…...

Unity android 接USBCamera
目录 一、前提 1. unity打包android后,链接USB摄像头,需要USB权限。 二、流程 1.Unity导出android工程,Player配置如图: 2.导出android工程 3.在android工程中找到AndroidManifest.xml加入usb权限相关 <?xml version&quo…...
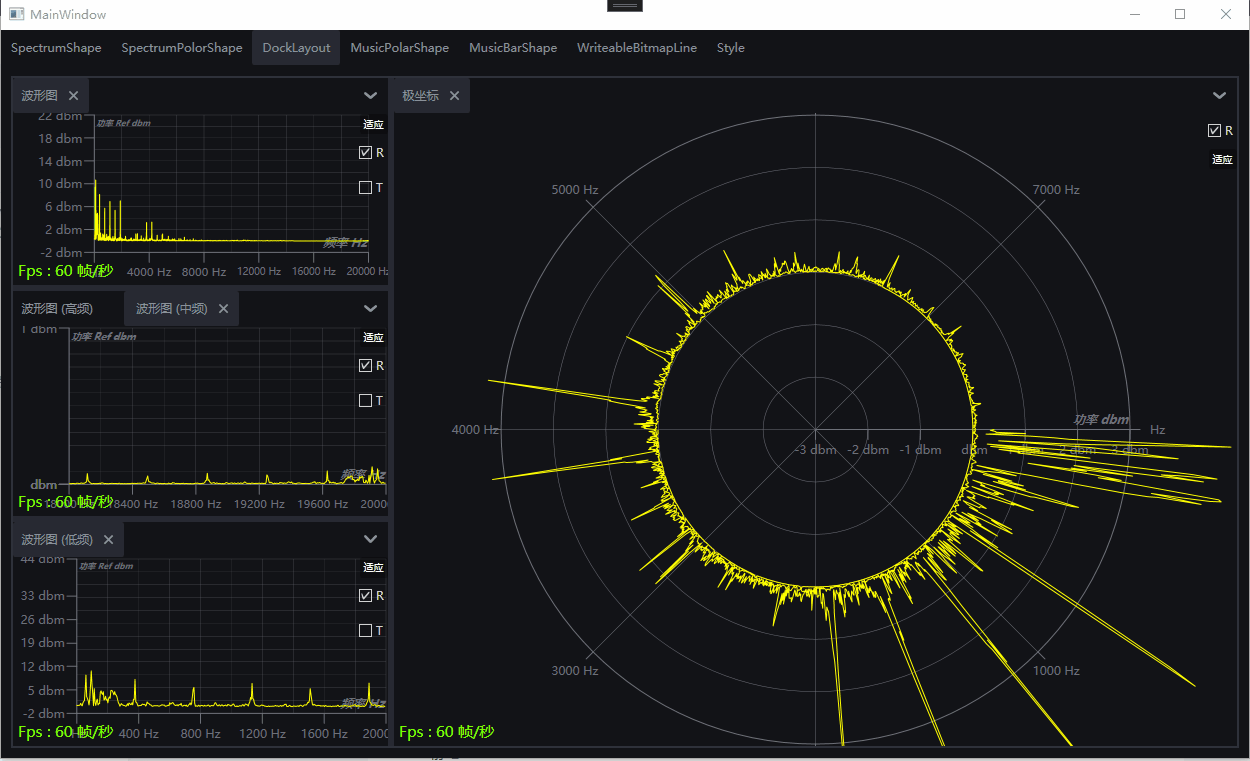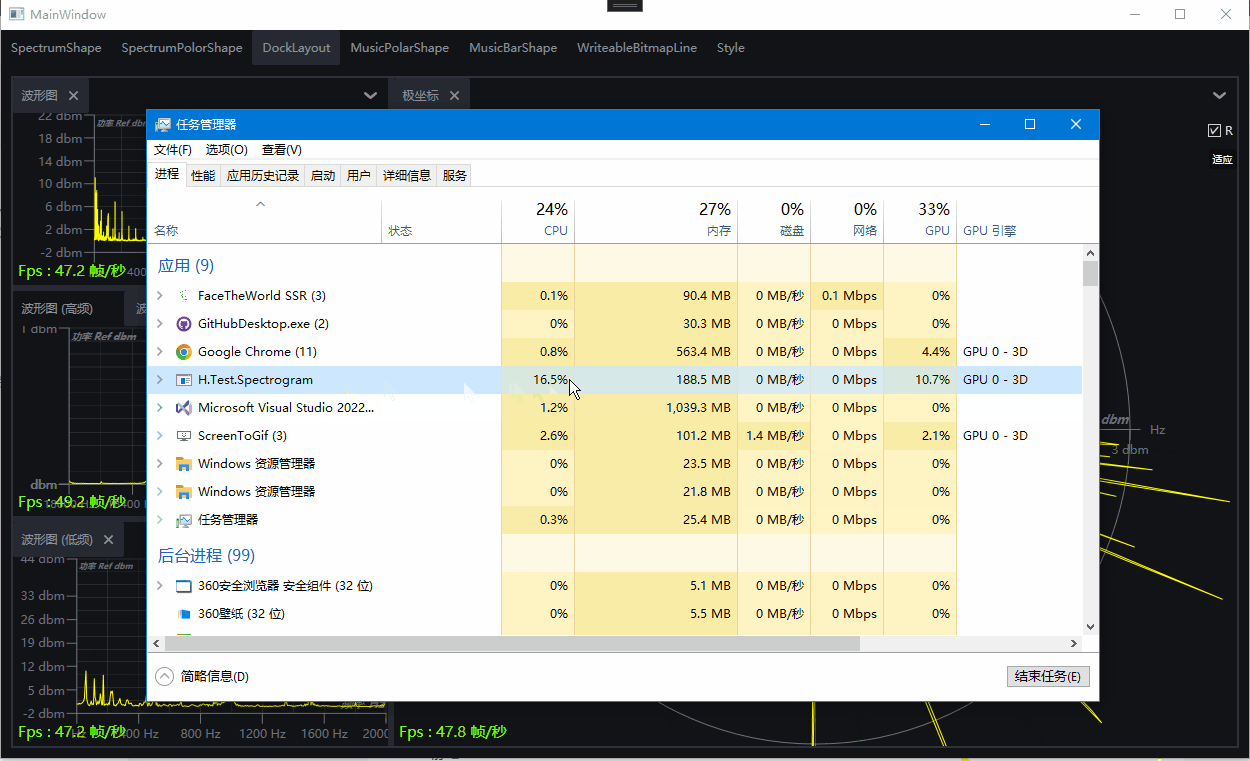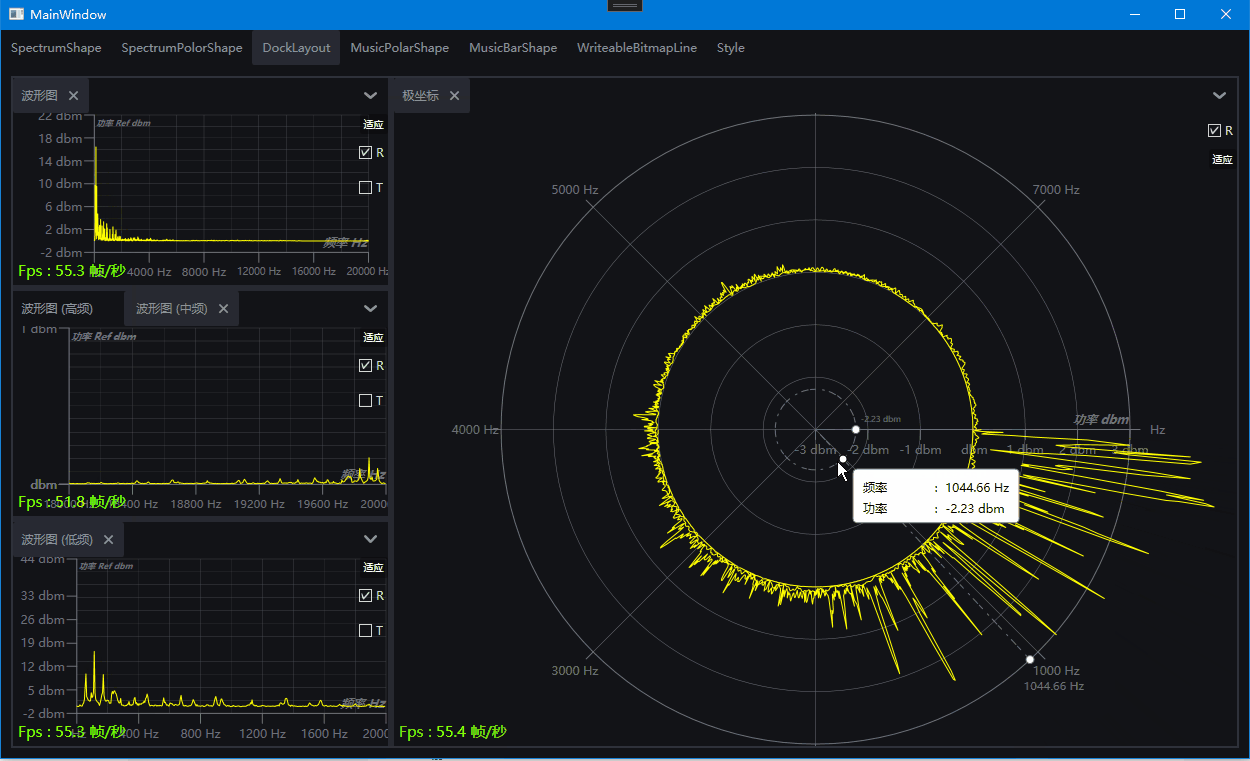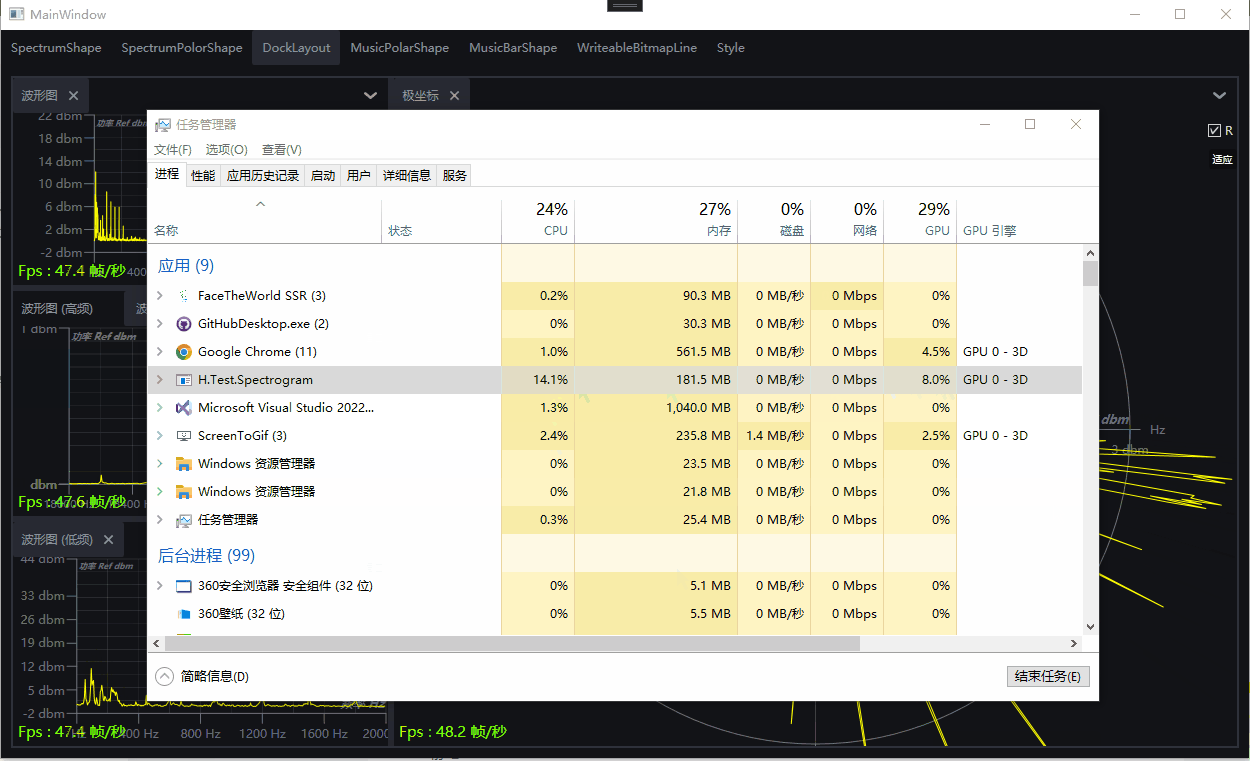
演示:基于WPF的DrawingVisual开发的频谱图和律动图
一、目的:基于WPF的DrawingVisual开发的频谱图和律动图 二、效果演示 波形图 极坐标 律动图极坐标图 律动图柱状图 Dock布局组合效果 三、环境 VS2022,Net7,Win10,NVIDIA RTX A2000 四、主要功能 支持设置起始频率,终止频率,中心…...

【数据结构初阶】排序算法(中)快速排序专题
文章目录 1. 快排主框架2. 快排的不同实现2. 1 hoare版本2. 2 挖坑法2. 3 lomuto前后指针法2. 4 快排的非递归版本 3. 快排优化3. 1 快排性能的关键点分析:3. 1 三路划分3. 2 introsort自省排序 1. 快排主框架 快速排序是Hoare于1962年提出的一种二叉树结构的交换排序方法。 其…...

Redis缓存双写一致性笔记(上)
Redis缓存双写一致性是指在将数据同时写入缓存(如Redis)和数据库(如MySQL)时,确保两者中的数据保持一致性。在分布式系统中,缓存通常用于提高数据读取的速度和减轻数据库的压力。然而,当数据更新…...

PCB基础
一、简介 PCB:printed circuit board,印刷电路板 主要作用:传输信号、物理支撑、提供电源、散热 二、分类 2.1 按基材分类 陶瓷基板:包括氧化铝、氮化铝、碳化硅基板等,具有优异的导热性,适用于高温和高…...

PostgreSQL 17:新特性与性能优化深度解析
目录 引言核心新特性 块级别增量备份与恢复逻辑复制槽同步参数SQL/JSON的JSON_TABLE命令PL/pgSQL支持数组%TYPE和%ROWTYPE 性能优化 IO合并读取性能参数真空处理过程的内存管理改进写前日志(WAL)锁的改进 升级建议结语 引言 PostgreSQL 17版本于2024年…...
[Linux#58][HTTP] 自己构建服务器 | 实现网页分离 | 设计思路
目录 一. 最简单的HTTP服务器 二.服务器 2.0 Protocol.hpp httpServer.hpp 子进程的创建和退出 子进程退出的意义 父进程关闭连接套接字 httpServer.cc argc (argument count) argv (argument vector) 三.服务器和网页分离 思考与补充: 一. 最简单的HTT…...

7.MySQL内置函数
目录 日期函数时间函数字符串函数数学函数其他函数 日期函数 函数名称描述current_date()当前日期current_time()当前时间current_timesamp()当前时间戳date(datetime)返回datetime参数的日期部分date_add(date, interval d_value_tyep)在date中添加日期函数或时间。interval后…...

GraphRAG 深度解析:把知识图谱接进检索链路,多跳推理准确率从 50% 提到 85%
很多同学搭完向量 RAG 之后,调了无数遍 Chunk 大小、换了好几个 Embedding 模型,多跳推理准确率就是卡在 50% 左右,怎么都上不去。比如「A 公司 CTO 和 B 公司 CEO 到底有什么合作关系」这类问题,答案散落在三个文档里,…...

基于RAG与向量数据库的智能代码搜索工具设计与实现
1. 项目概述:一个面向开发者的智能代码搜索与理解工具 最近在GitHub上看到一个挺有意思的项目,叫 holasoymalva/perplexity-code 。乍一看这个标题,可能会有点困惑——“perplexity”在机器学习里通常指“困惑度”,是衡量语言模…...

深度解析DsHidMini:开源项目实现Windows平台DualShock 3控制器用户态驱动
深度解析DsHidMini:开源项目实现Windows平台DualShock 3控制器用户态驱动 【免费下载链接】DsHidMini Virtual HID Mini-user-mode-driver for Sony DualShock 3 Controllers 项目地址: https://gitcode.com/gh_mirrors/ds/DsHidMini DsHidMini是一款基于Win…...

GIS国土工具实战:从地类分析到坐标转换,一站式解决项目难题
1. GIS国土工具如何解决项目痛点 第一次接触国土整治项目时,我被各种数据格式搞得焦头烂额。早上9点收到甲方发来的50个地块的shp文件,下午3点就要提交带坐标的txt报备文件,中间还要做地类分析和影像核对。手动操作?光是想到要一个…...

从零打造互动徽章:激光切割与电容触摸的软硬件融合实践
1. 项目概述与核心思路如果你参加过技术大会或者创客市集,一定对那些闪烁着酷炫灯光、能与人互动的徽章印象深刻。这类被称为“Badge”的可穿戴设备,早已超越了单纯的身份标识功能,成为了展示技术、创意和社群文化的微型平台。今天要分享的&a…...

实测5款AI教材编写工具,低查重效果惊人,快速生成专业教材
许多教材编写者常常感到遗憾,他们费尽心思完善的正文内容,因为缺少配套资源而导致教学效果打折。设计课后练习题时,面对题型的多样化却缺乏创新的思路;制作可视化教学课件时,手头的技术能力又无法满足;深入…...

从数据到角度:手把手调试大疆C板BMI088,解决姿态解算精度跳动的那些坑
从数据到角度:手把手调试大疆C板BMI088,解决姿态解算精度跳动的那些坑 调试嵌入式系统中的传感器数据,尤其是姿态解算这类对精度要求极高的应用,往往需要开发者具备跨领域的知识储备和丰富的实战经验。本文将分享我在使用大疆C板搭…...

如何通过LizzieYzy围棋AI分析工具在30天内实现棋力突破:从入门到实战的完整指南
如何通过LizzieYzy围棋AI分析工具在30天内实现棋力突破:从入门到实战的完整指南 【免费下载链接】lizzieyzy LizzieYzy - GUI for Game of Go 项目地址: https://gitcode.com/gh_mirrors/li/lizzieyzy 在围棋AI技术飞速发展的今天,LizzieYzy作为一…...

3分钟上手QrazyBox:让损坏的二维码“起死回生“的终极修复工具
3分钟上手QrazyBox:让损坏的二维码"起死回生"的终极修复工具 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你是否曾经遇到过这样的场景:打印出来的二维码被…...

从动画原理到嵌入式实现:赋予机器人生命感的设计与工程实践
1. 项目概述:当技术遇见灵魂在数字世界和物理世界的交汇处,我们总在尝试创造一些能与我们对话、甚至能触动我们内心的存在。无论是屏幕里那个让你牵挂的动画角色,还是面前这个试图与你眼神交流的服务机器人,一个核心的挑战始终横亘…...