BERT训练之数据集处理(代码实现)
目录
1读取文件数据
2.生成下一句预测任务的数据
3.预测下一个句子
4.生成遮蔽语言模型任务的数据
5.从词元中得到遮掩的数据
6.将文本转化为预训练数据集
7.封装函数类
8.调用
import os
import random
import torch
import dltools1读取文件数据
def _read_wiki(data_dir):#拼接文件路径file_name = os.path.join(data_dir, 'wiki.train.tokens')#将输入参数中的两个名字拼接成一个完整的文件路径。with open(file_name, 'r', encoding='utf-8') as f:#打开文件,逐行读取内容,并将每行作为一个元素添加到列表中。lines = f.readlines()#大写字母转换为小写字母,获取分句之后的段落列表paragraphs = [line.strip().lower().split('.') for line in lines if len(line.split('.')) >= 2]random.shuffle(paragraphs) #大陆那段落列表中的元素return paragraphs_read_wiki('./wikitext-2/') #输出过长,不展示2.生成下一句预测任务的数据
def _get_next_sentence(sentence, next_sentence, paragraphs):if random.random() < 0.5: #若50%的概率发生时is_next = Trueelse:#否则,next_sentence就不是下一个句子,是随机抽取的其他句子#paragraphs是三重列表的嵌套#从所有列表中随机抽取一个段落,从这个段落中又随机抽取一个句子next_sentence = random.choice(random.choice(paragraphs))is_next =Falsereturn sentence, next_sentence, is_next 3.预测下一个句子
def _get_nsp_data_from_paragraph(paragraph, paragraphs, vocab, max_len):nsp_data_from_paragraph = [] #创建空列表,存放下一个句子的数据for i in range(len(paragraph) - 1): #len(paragraph) - 1是因为索引是从0开始的,左闭右开,输出段落中的每一个句子的索引#调用函数,获取用于预测下一个句子任务的数据tokens_a, tokens_b , is_next = _get_next_sentence(paragraph[i], paragraph[i+1], paragraphs)#预测输入的两个句子结构是 --> <cls> tokens_a <sep> tokens_b <sep># +3表示考虑 1个<cls> +2个<sep>if len(tokens_a) + len(tokens_b) + 3 > max_len:continue #这种情况超出了序列的最大长度,不需要#将文本数据分割成词元(tokens)和句子分段(segments)。#这个过程通常涉及到一系列的预处理步骤,如去除标点符号、转换为小写、数字处理等,以确保输入数据的标准化和一致性tokens, segments = dltools.get_tokens_and_segments(tokens_a, tokens_b)nsp_data_from_paragraph.append((tokens, segments, is_next)) #三个数据以元祖的形式存放到列表中return nsp_data_from_paragraph4.生成遮蔽语言模型任务的数据
#Mask Language Modle
def _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds, vocab):"""tokens:传入的词元candidate_pred_positions:等待预测的词元位置索引编号(若传入句子的序列长度为100,那么它就是0-99)num_mlm_preds:预测遮掩的数量vocab:整体词汇表"""#为遮蔽语言模型的输入创建新的词元副本, 其中输入可能包含替换的<mask>或随机词元mlm_input_tokens = [token for token in tokens] #复制词元数据,后期的替换不修改原数据pred_positions_and_labels = [] #用于存放预测的词元位置和目标标签#打乱顺序 等待预测的词元位置索引编号random.shuffle(candidate_pred_positions)for mlm_pred_position in candidate_pred_positions: #遍历#判断存放预测词元的个数是否已经超过了需要预测的数量if len(pred_positions_and_labels) >= num_mlm_preds:break #若预测数量够了,就不预测了,直接退出当前for循环, continue是退出当前if判断#否则,接着预测mask_token = None #初始化变量:被15%抽中需要被替换的词元 为空#80%的概率, 将抽取的15%的词元,替换成<mask>词元if random.random() < 0.8:msaked_token = '<mask>'else: #否则,将剩下的其中10%的词元保持不变 从剩下的20%中抽取50%来表示if random.random() < 0.5:mask_token = tokens[mlm_pred_position]else: #将剩下的其中10%的词元,用随机词替换msaked_token = random.choice(vocab.idx_to_token)#将获取到的msaked_token按索引赋值替换原词元mlm_input_tokens[mlm_pred_position] = mask_token#mlm_pred_position需要被预测的词元位置索引, tokens[mlm_pred_position]被遮掩预测的词元的标签(真实值是什么)pred_positions_and_labels.append((mlm_pred_position, tokens[mlm_pred_position]))return mlm_input_tokens, pred_positions_and_labels5.从词元中得到遮掩的数据
#
def _get_mlm_data_from_tokens(tokens, vocab):candidate_pred_positions = []# tokens是一个字符串列表for i, token in enumerate(tokens):# 在遮蔽语言模型任务中不会预测特殊词元if token in ['<cls>', '<sep>']:continuecandidate_pred_positions.append(i)# 遮蔽语言模型任务中预测15%的随机词元num_mlm_preds = max(1, round(len(tokens) * 0.15))mlm_input_tokens, pred_positions_and_labels = _replace_mlm_tokens(tokens, candidate_pred_positions, num_mlm_preds, vocab)pred_positions_and_labels = sorted(pred_positions_and_labels,key=lambda x: x[0])pred_positions = [v[0] for v in pred_positions_and_labels]mlm_pred_labels = [v[1] for v in pred_positions_and_labels]return vocab[mlm_input_tokens], pred_positions, vocab[mlm_pred_labels]6.将文本转化为预训练数据集
def _pad_bert_inputs(examples, max_len, vocab):#词源需要预测的最大数量max_num_mlm_preds = round(max_len * 0.15)all_tokens_ids, all_segments, valid_lens = [], [], []all_pred_positions, all_mlm_weights, all_mlm_labels = [], [], []nsp_labels = []for (token_ids, pred_positions, mlm_pred_label_ids, segments, is_next) in examples:#对原有的tokens(每句话有长有短,补充《pad》使长度一致)all_tokens_ids.append(torch.tensor(token_ids + [vocab['<pad>']] * (max_len - len(token_ids)), dtype=torch.long))all_segments.append(torch.tensor(segments + [0] * (max_len - len(segments)), dtype=torch.long))#valid_lens不包括<pad>计数valid_lens.append(torch.tensor(len(token_ids), dtype=torch.float32))all_pred_positions.append(torch.tensor(pred_positions + [0] * (max_num_mlm_preds - len(pred_positions)), dtype=torch.long))#填充词元的预测将通过乘以0权重在损失中过滤掉all_mlm_weights.append(torch.tensor([1.0] * len(mlm_pred_label_ids) + [0.0] * (max_num_mlm_preds - len(pred_positions)), dtype=torch.float32))all_mlm_labels.append(torch.tensor(mlm_pred_label_ids + [0] * (max_num_mlm_preds - len(mlm_pred_label_ids)), dtype=torch.long))nsp_labels.append(torch.tensor(is_next, dtype=torch.long))return (all_tokens_ids, all_segments, valid_lens, all_pred_positions, all_mlm_weights, all_mlm_labels, nsp_labels)7.封装函数类
class WikiTextDataset(torch.utils.data.Dataset):def __init__(self, paragraphs, max_len):#输入paragraphs[i]是代表段落的句子字符串列表#输出paragraphs[i]是代表段落的句子列表,其中每个句子都是词元列表paragraphs = [dltools.tokenize(paragraph, token='word') for paragraph in paragraphs]#获取句子的词元列表sentences = [sentence for paragraph in paragraphs for sentence in paragraph]self.vocab = dltools.Vocab(sentences, min_freq=5, reserved_tokens=['<pad>', '<mask>', '<cls>', '<sep>'])#获取下一句子预测任务的数据examples = []for paragraph in paragraphs:examples.extend(_get_nsp_data_from_paragraph(paragraph, paragraphs, self.vocab, max_len))#获取遮蔽语言模型任务的数据examples = [(_get_mlm_data_from_tokens(tokens, self.vocab) + (segments, is_next)) for tokens, segments, is_next in examples]#填充输入(self.all_token_ids, self.all_segments, self.valid_lens, self.all_pred_positions, self.all_mlm_weights, self.all_mlm_labels, self.nsp_labels) = _pad_bert_inputs(examples, max_len, self.vocab)def __getitem__(self, idx):return (self.all_token_ids[idx], self.all_segments[idx],self.valid_lens[idx], self.all_pred_positions[idx],self.all_mlm_weights[idx], self.all_mlm_labels[idx],self.nsp_labels[idx])def __len__(self):return len(self.all_token_ids)8.调用
def load_data_wiki(batch_size, max_len):"""加载WikiText-2数据集"""num_workers = dltools.get_dataloader_workers() #快速获取或设置最佳的工作线程数data_dir = './wikitext-2/'paragraphs = _read_wiki(data_dir)train_set = WikiTextDataset(paragraphs, max_len)train_iter = torch.utils.data.DataLoader(train_set, batch_size, shuffle=True, num_workers=num_workers)return train_iter, train_set.vocabbatch_size, max_len = 512, 64
train_iter, vocab = load_data_wiki(batch_size, max_len)for (tokens_X, segments_X, valid_lens_x, pred_positions_X, mlm_weights_X,mlm_Y, nsp_y) in train_iter:print(tokens_X.shape, segments_X.shape, valid_lens_x.shape,pred_positions_X.shape, mlm_weights_X.shape, mlm_Y.shape,nsp_y.shape)breaktorch.Size([512, 64]) torch.Size([512, 64]) torch.Size([512]) torch.Size([512, 10]) torch.Size([512, 10]) torch.Size([512, 10]) torch.Size([512])
len(vocab)20228

相关文章:
BERT训练之数据集处理(代码实现)
目录 1读取文件数据 2.生成下一句预测任务的数据 3.预测下一个句子 4.生成遮蔽语言模型任务的数据 5.从词元中得到遮掩的数据 6.将文本转化为预训练数据集 7.封装函数类 8.调用 import os import random import torch import dltools 1读取文件数据 def _read_wiki(data_d…...
一款辅助渗透测试过程,让渗透测试报告一键生成
《网安面试指南》http://mp.weixin.qq.com/s?__bizMzkwNjY1Mzc0Nw&mid2247484339&idx1&sn356300f169de74e7a778b04bfbbbd0ab&chksmc0e47aeff793f3f9a5f7abcfa57695e8944e52bca2de2c7a3eb1aecb3c1e6b9cb6abe509d51f&scene21#wechat_redirect 《Java代码审…...

力扣最热一百题——颜色分类
目录 题目链接:75. 颜色分类 - 力扣(LeetCode) 题目描述 示例 提示: 解法一:不要脸用sort Java写法: 运行时间 解法二:O1指针 Java写法: 重点 运行时间 C写法:…...
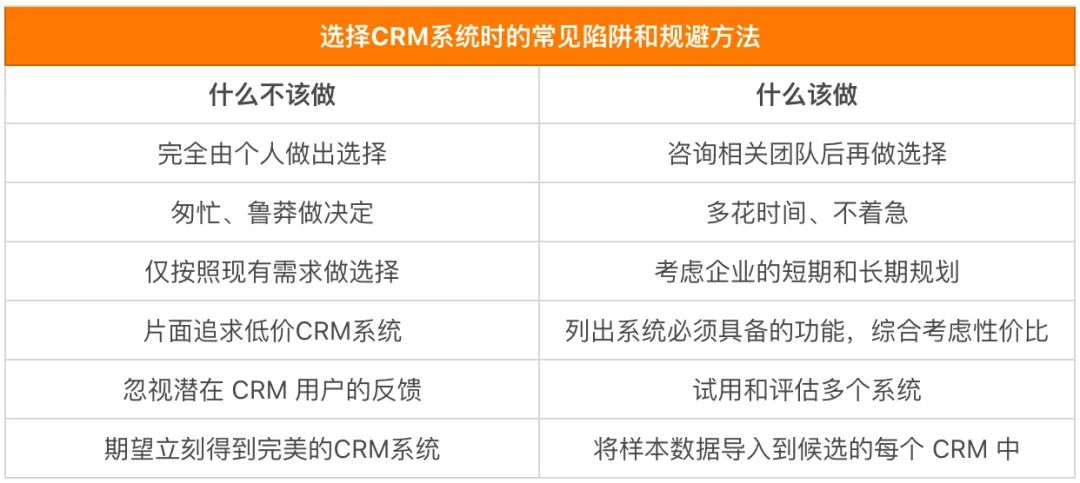
2024年工业制造企业CRM研究报告:需求清单、市场格局、案例分析
我国是世界上产业体系最完备的国家,拥有全球规模最大、门类最齐全的生产制造体系,在500种主要工业产品中,有四成以上产品产量位居全球第一。2023年制造业增加值达33万亿元,占世界的比重稳定在30%左右,我国制造业增加值…...

Spring MVC参数接收 总结
1. 简介 Spring MVC可以简化从前端接收参数的步骤。 2. Param传参 通过设定函数入参和添加标记来简化接受: //参数接收 RequestMapping("product") ResponseBody //接受/product?productgoods&id123 //1.名称必须相同,2.不传值不会不…...

Docekrfile和docker compose编写指南及注意事项
Dockerfile 基础语法 我们通过编写dockerfile,将每一层要做的事情使用语法固定下来,之后运行指令就可以通过docker来制作自己的镜像了。 构建镜像的指令:docker build /path -t imageName:tag 注意,docker build后的path必须是dockerfile…...

VITS源码解读6-训练推理
1. train.py 1.1 大体流程 执行main函数,调用多线程和run函数执行run函数,加载日志、数据集、模型、模型优化器for循环迭代数据batch,每次执行train_and_evaluate函数,训练模型 这里需要注意,源码中加载数据集用的分…...

力扣 简单 104.二叉树的最大深度
文章目录 题目介绍解法 题目介绍 解法 如果知道了左子树和右子树的最大深度 l 和 r,那么该二叉树的最大深度即为max(l,r)1,而左子树和右子树的最大深度又可以以同样的方式进行计算。因此我们可以用递归的方法来计算二叉树的最大深度。具体而言ÿ…...

单片机长短按简单实现
单片机长短按简单实现 目录 单片机长短按简单实现1 原理2 示例代码2.1 按键实现 3 测试log4 其他实现方式 1 原理 按键检测和处理的步骤如下: 1:定时扫描按键(使用定时器定时扫描,也可以用软件延时或者系统心跳之类的方式&#…...
如何用好通义灵码企业知识库问答能力?
通义灵码企业版:通义灵码企业标准版快速入门_智能编码助手_AI编程_智能编码助手通义灵码(Lingma)-阿里云帮助中心 通义灵码提供了基于企业知识库的问答检索增强的能力,在开发者使用通义灵码 IDE 插件时,可以结合企业知识库内上传的文档、文件…...

C语言自定义类型:联合体
目录 前言一、联合体1.1 联合体类型的声明1.2 联合体的特点1.3 相同成员的结构体和联合体对比1.4 联合体大小的计算1.5 联合体的⼀个练习 总结 前言 前面我讲到C语言中的自定义结构——结构体,其实C语言中的自定义结构不只有结构体,还有枚举和联合体&am…...

【JavaEE】——线程池大总结
阿华代码,不是逆风,就是我疯, 你们的点赞收藏是我前进最大的动力!!希望本文内容能够帮助到你! 目录 引入:问题引入 一:解决方案 1:方案一——协程/纤程 (1…...

编程中为什么使用0和1表示状态
前言 这是我在这个网站整理的笔记,有错误的地方请指出,关注我,接下来还会持续更新。 作者:神的孩子都在歌唱 我们看到很多项目都使用0和1表示某些状态信息,具体含义取决于上下文。以下是一些常见的用法: 布尔值&#x…...

C++入门基础知识90(实例)——实例15【求两数的最大公约数】
成长路上不孤单😊😊😊😊😊😊 【14后😊///C爱好者😊///持续分享所学😊///如有需要欢迎收藏转发///😊】 今日分享关于求两数的最大公约数的相关内容ÿ…...

自动化办公-Python-os模块的使用
os.path 模块的使用 在指定文件路径时,由于操作系统的差异,直接使用硬编码的路径可能会导致程序在不同平台上无法正常运行。为了解决这个问题,Python 提供了 os.path 模块,它包含了一系列用于路径操作的函数,可以帮助您…...

无人机之数据处理技术篇
一、数据采集 无人机通过搭载的各种传感器和设备,如GPS、加速度计、陀螺仪、磁力计、激光雷达(LiDAR)、高光谱相机(Hyperspectral)、多光谱相机(Multispectral)以及普通相机等,实时采集飞行过程中的各种数据。这些数据包括无人机的位置、速度、高度、姿态…...

828华为云征文|部署多功能集成的协作知识库 AFFiNE
828华为云征文|部署多功能集成的协作知识库 AFFiNE 一、Flexus云服务器X实例介绍二、Flexus云服务器X实例配置2.1 重置密码2.2 服务器连接2.3 安全组配置2.4 Docker 环境搭建 三、Flexus云服务器X实例部署 AFFiNE3.1 AFFiNE 介绍3.2 AFFiNE 部署3.3 AFFiNE 使用 四、…...

c++(AVL树及其实现)
一、AVL树的概念 AVL树是最先发明的自平衡⼆叉查找树,AVL是⼀颗空树,或者具备下列性质的⼆叉搜索树:它的 左右子树都是AV树,且左右子树的高度差的绝对值不超过1。AVL树是⼀颗高度平衡搜索⼆叉树, 通过控制高度差去控…...

Cesium GIS项目关于湖泊识别与提取的实现
1. 引言 项目背景 随着遥感技术的发展,地理信息系统的应用越来越广泛。本项目旨在开发一个基于Cesium的地理信息系统,利用深度学习技术自动识别并显示湖泊的位置。 目标与意义 通过自动化处理大量遥感影像数据,提高湖泊监测的效率和准确性,为水资源管理和环境保护提供支…...

两个圆形 一个z里面一个z外面,z里面的大,颜色不同 html
两个圆形 一个z里面一个z外面,z里面的大,颜色不同 html <!DOCTYPE html> <html> <head> <style> .outer-circle {width: 150px;height: 150px;border-radius: 50%;background-color: #ff9999; /* 外圆的颜色 */position: relat…...

ESP32开发踩坑记:从HID库缺失到PlatformIO环境搭建的全流程复盘
ESP32开发踩坑记:从HID库缺失到PlatformIO环境搭建的全流程复盘 那天深夜,我盯着屏幕上"hid.h: No such file or directory"的报错信息,意识到自己掉进了嵌入式开发的第一个坑。原本想用Arduino做个体感鼠标来提升游戏体验…...

深度解析:PC端即时通讯防撤回功能的技术实现
深度解析:PC端即时通讯防撤回功能的技术实现 【免费下载链接】RevokeMsgPatcher :trollface: A hex editor for WeChat/QQ/TIM - PC版微信/QQ/TIM防撤回补丁(我已经看到了,撤回也没用了) 项目地址: https://gitcode.com/GitHub_…...

Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南
Cursor Pro功能解锁:3步实现免费无限制使用AI编辑器完整指南 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached yo…...

Postman实战:自动化管理API访问令牌的两种高效策略
1. 为什么需要自动化管理API访问令牌 在如今的API开发中,身份验证和授权已经成为必不可少的安全机制。大多数现代API都采用基于令牌(Token)的认证方式,其中Bearer Token是最常见的标准之一。想象一下,每次调用API都需要手动复制粘贴一长串Tok…...

Next.js企业级开发样板Next-Enterprise:一站式集成最佳实践与工具链
1. 项目概述:为什么说 Next-Enterprise 是 Next.js 企业级开发的“瑞士军刀”? 如果你正在用 Next.js 构建一个中大型、对代码质量和开发体验有要求的企业级应用,那你大概率遇到过这些头疼事:项目初始化配置繁琐,得花…...

别再只懂BDF了!手把手教你理解PCIe ARI如何将Function数量扩展到256个
突破PCIe传统限制:深入解析ARI如何实现256个功能扩展 在数据中心和云计算架构快速发展的今天,虚拟化技术对硬件资源分配提出了更高要求。传统PCIe设备的8个功能限制已成为制约虚拟功能扩展的瓶颈,特别是在SR-IOV(单根I/O虚拟化&am…...

Fujirebio宣布全自动Lumipulse® G pTau 217血浆检测试剂盒获得CE认证
H.U. Group Holdings Inc.及其全资子公司Fujirebio今日宣布,Fujirebio Europe N.V.已依据《欧盟(EU) 2017/746体外诊断医疗器械法规》(IVDR)取得Lumipulse G pTau 217血浆检测试剂盒的CE认证。该化学发光酶免疫分析(CLEIA)检测可对人体血浆(K2 EDTA)中的苏氨酸217磷…...

Vui:轻量级对话语音合成模型的设计原理与本地部署实践
1. 项目概述:一个为对话而生的轻量级语音合成模型 如果你正在寻找一个能在本地设备上运行、能生成带呼吸声和笑声的真实对话语音的文本转语音模型,那么 Vui 很可能就是你需要的那个“小而美”的解决方案。作为一名长期关注边缘AI和语音技术的开发者&…...

终极音乐解锁指南:让加密音频在浏览器中重获自由
终极音乐解锁指南:让加密音频在浏览器中重获自由 【免费下载链接】unlock-music 在浏览器中解锁加密的音乐文件。原仓库: 1. https://github.com/unlock-music/unlock-music ;2. https://git.unlock-music.dev/um/web 项目地址: https://gi…...

几何字体革命:如何用Poppins解决多语言设计的世界性难题?
几何字体革命:如何用Poppins解决多语言设计的世界性难题? 【免费下载链接】Poppins Poppins, a Devanagari Latin family for Google Fonts. 项目地址: https://gitcode.com/gh_mirrors/po/Poppins 还在为跨语言设计项目寻找完美的字体方案而苦恼…...