Redis-持久化
首先,我们明白一个概念,
硬盘=>持久
内存=>不持久
而Redis是一个内存数据库,不持久,相比于Mysql这样的关系型数据库,最明显的特点是快/效率高
为了保证速度快,数据要保存再内存中,为了持久,存储在硬盘上
所以redis决定:
插入=>内存+硬盘(硬盘是为了在redis重启时,恢复内存中的数据)
代价:消耗了更多空间,但是硬盘成本低,损耗小
持久化策略:
- RDB=>定期备份
比方说每个月我把我电脑硬盘上的学习资料,整体的备份到备份盘中
- AOF=>实时备份
比方说只要我下载了一个新的学习资料,立即把这个学习资料在备份盘中拷贝一份
1. RDB(Redis DataBase)
RDB持久化是把当前进程数据⽣成快照(RDB文件),保存到硬盘的过程
后续Redis一旦重启(内存数据没了),就可以根据刚才的"快照"把数据恢复
快照可以在重启后用以恢复数据
1.1 触发机制
1.1.1 手动触发
通过redis客户端,执行特定的命令,来触发快照生成
- save
执行save命令时,快照生成,此时阻塞Redis的其它命令,直至RDB过程完成为止
对于内存⽐较⼤的实例造成⻓时间阻塞,类似于key *的结果,不建议使用
- bgsave
不会影响Redis服务器的其它请求和命令
那是怎么做到呢?是偷摸搞了个多线程嘛?
并不是
此时redis使用"多进程"方式来完成并发编程


由于这里的数据比较少,执行bgsave瞬间就完成了
如果数据太多,执行bgsave就会消耗一定的时间,立即查看不一样就生成完毕.
通过上述的操作,就可以看到,redis服务器在重启的时候,加载了rdb文件的内容,恢复了内存之前的状态了.

1.1.2 自动触发
①在配置文件中使⽤save配置:
如"save m n"表⽰m秒内数据集发⽣了n次修改,⾃动RDB持久化
配置文件修改之后,一定要重新启动服务器,才能生效
![]()


此处的数值可以修改,但是有一个基本的原则:
生成一次RDB快照,这个成本是比较高的,不能让这个操作执行的太频繁
举个例子:
save 60 10000(两次生成rdb之间的间隔,最少是60s)
12:00:00 生成了rdb(硬盘上的快照数据和内存中一致)
12:00:01 开始,redis收到了大量的key的变化请求
12:01:00 生成下一个快照文件
如果在这之间,redis服务器挂了,此时就会导致12:00:00之后的这些数据都丢了
②从节点进⾏全量复制操作时,主节点⾃动进⾏RDB持久化,随后将RDB⽂件内容发送给从结点。
③执⾏shutdown命令关闭Redis时,执⾏RDB持久化(service redis-server restart) -正常关闭


刚才bgsave并没有执行,但是这个key2重启之后仍然存在
如果是通过正常流程重启redis服务器,此时redis服务器会在退出的时候,自动触发rdb操作
但如果是异常重启(kill -9或者其它),此时redis服务器就来不及生成rdb,内存中尚未保存在快照中的数据,就会随重启而丢失
![]()


1.2 流程说明

- 执⾏bgsave命令,Redis⽗进程判断当前进是否存在其他正在执⾏的⼦进程,如RDB/AOF⼦进程,如果存在bgsave命令直接返回。
- ⽗进程执⾏fork创建⼦进程,fork过程中⽗进程会阻塞。
- ⽗进程fork完成后,可以继续响应其他命令。
- ⼦进程创建RDB⽂件,根据⽗进程内存⽣成临时快照⽂件,完成后对原有⽂件进⾏替换。
- 进程发送信号给⽗进程表⽰完成,⽗进程更新统计信息。
bgsave操作流程是创建子进程,子进程完成持久化操作(持久化速度太快了[数据少],难以观察到子进程)
持久化会把数据写入新的文件中,然后使用新的文件替换旧的文件 (容易观察到)
可以使用stat命令,查看文件的inode编号:


1.3 RDB文件的处理
- 保存:
RDB⽂件保存在dir配置指定的⽬录(默认/var/lib/redis/)下
⽂件名通过dbfilename 配置(默认dump.rdb)指定
![]()

- dump.rdb:
RDB机制生成的镜像文件,redis服务器默认是开启了RDB的
把内存中的数据,以压缩的形式(需要消耗一定的CPU资源,但能节省存储空间),保存在这个二进制文件中:

redis提供了RDB文件的检查工具:
![]()
- RDB持久化操作,是可以触发多次的:
当执行生成RDB镜像时,此时就会把要生成的快照数据,先保存到一个临时文件中,当这个快照生成后,再删除之前的RDB文件,把新生成的临时的RDB文件名改成刚才的dump.rdb
自始至终,RDB文件始终只有一个
- 如果把RDB文件故意搞坏了,会怎么样?
手动的把rdb文件内容改坏,然后通过kill 进程的方式,重启服务器
如果通过service redis-server restart重启,就会在redis服务器退出的时候,重新生成rdb快照
如果改坏的地方是文件末尾,没有影响,如果是中间位置,会发现redis服务器可能无法启动
当redis服务器挂了之后,可以看看redis日志,了解一下发生了什么

也可能redis服务器能启动,但是得到的数据可能有问题:
通过检查工具,查看rdb文件格式是否符合要求,运行的时候,加入rdb文件作为命令行参数
此处就是以检查工具的方式来运行,不会真的启动redis服务器

1.4 优缺点
- RDB是⼀个紧凑压缩的⼆进制⽂件,代表Redis在某个时间点上的数据快照。⾮常适⽤于备份,全 量复制等场景。
- Redis加载RDB恢复数据远远快于AOF的⽅式 (RDB这里使用二进制的方式来组织数据,直接把数据读取到内存中,按照字节的格式取出来放到结构体/对象中即可,而AOF是使用文本的方式来组织数据的,需要进行一系列的字符串切分操作)
- RDB⽅式数据没办法做到实时持久化/秒级持久化,因为bgsave每次运⾏都要执⾏fork创建⼦进 程,属于重量级操作,频繁执⾏成本过⾼。
- RDB⽂件使⽤特定⼆进制格式保存,Redis版本演进过程中有多个RDB版本,兼容性可能有⻛ 险。
- 最大的问题,不能实时的持久化保存数据,在两次生成快照之间,实时的数据可能会随着重启而丢失
2. AOF(Append Only File)
以独⽴⽇志的⽅式记录每次写命令,重启时再重新执⾏AOF ⽂件中的命令达到恢复数据的⽬的
AOF的主要作⽤是解决了数据持久化的实时性,⽬前已经是Redis 持久化的主流⽅式
开启AOF时,RDB就不生效了
redis启动的时候,不再读取RDB文件的内容了,而是读取这个AOF文件中的内容,用来恢复数据
2.1 使用AOF
AOF默认是关闭状态,通过修改配置文件开启
AOF功能所在的位置,也是/var/lib/redis


 通过一些特殊符号作为分隔符
通过一些特殊符号作为分隔符
2.2 AOF工作流程

- 所有的写⼊命令会追加到aof_buf(缓冲区)中。
- AOF缓冲区根据对应的策略向硬盘做同步操作。
- 随着AOF⽂件越来越⼤,需要定期对AOF⽂件进⾏重写,达到压缩的⽬的。
- 当Redis服务器启动时,可以加载AOF⽂件进⾏数据恢复
Redis虽然是一个单线程的服务器,但是速度很快
为什么快?只操作内存
- 引入AOF之后,又要写内存,又要写硬盘,那还和之前一样快嘛?
实际上,是没有影响的
- AOF机制并非直接让工作线程把数据写入硬盘,而是先写入一个内存中的缓冲区,积累一定后,再统一写入硬盘,大大降低了写硬盘的次数
- 硬盘上读写数据,顺序读写的速度是比较快的(比内存慢),随机访问则比较慢,AOF每次把新的操作写入原有文件的末尾,是顺序写入
- 如果把数据写入缓冲区,本质还是在内存中呀,万一这个时候,进程突然挂了,是不是缓冲区的数据就丢了?
是的!
要根据实际情况来取舍缓冲区的刷新频率
刷新频率越高,性能影响就越大,数据可靠性越高
刷新频率越低,性能影响就越小,数据可靠性越低
2.3 文件同步
| 可配置值 | 说明 |
| always | 命令写⼊aof_buf后调⽤fsync同步,完成后返回 |
| everysec | 命令写⼊aof_buf后只执⾏write操作,不进⾏ fsync。每秒由同步线程进⾏fsync |
| no | 命令写⼊aof_buf后只执⾏write操作,由OS控制 fsync 频率 |

2.4 重写机制
2.4.1 引入
AOF文件持续增长,体积会越来越大,会影响到,redis下次启动的启动时间
redis启动时要读取AOF文件的内容
AOF文件虽然记录了中间的过程,但是Redis在重启时,只关注最终结果,AOF文件中的一些内容是冗余的
什么意思呢?
比如说:

因此,redis就存在一个机制(重写机制),能够针对AOF文件进行整理操作,剔除其中的冗余操作,并且合并一些操作,给AOF"瘦身"
2.4.2 触发机制
- 手动触发
调⽤bgrewriteaof命令
- 自动触发
根据auto-aof-rewrite-min-size和auto-aof-rewrite-percentage参数确定⾃动触发时机
- auto-aof-rewrite-min-size:表⽰触发重写时AOF的最⼩⽂件⼤⼩,默认为64MB
- auto-aof-rewrite-percentage:代表当前AOF占⽤⼤⼩相⽐较上次重写时增加的⽐例
2.4.3 重写流程

1.执⾏AOF重写请求。
- 如果当前进程正在执⾏AOF重写,请求不执⾏。
- 如果当前进程正在执⾏bgsave操作,重写命令延迟到bgsave完成之后再执⾏。
2. ⽗进程执⾏fork创建⼦进程(父进程负责接收请求,子进程负责重写)
3. 重写
- 主进程fork之后,继续响应其他命令。所有修改操作写⼊AOF缓冲区并根据appendfsync策略同步到硬盘,保证旧AOF⽂件机制正确。
- ⼦进程只有fork之前的所有内存信息,⽗进程中需要将fork之后这段时间的修改操作写⼊ AOF重写缓冲区中。
4. ⼦进程根据内存快照,将命令合并到新的AOF⽂件中。
注意:
- 重写的时候,不关心AOF文件中原来有什么,只关心内存最终的数据状态
- 子进程只需要把内存中当前的数据,获取出来,以AOF的格式写入到一个新的AOF文件中
5. ⼦进程完成重写
- 新⽂件写⼊后,⼦进程发送信号给⽗进程。
- ⽗进程把AOF重写缓冲区内临时保存的命令追加到新AOF⽂件中。
- ⽤新AOF⽂件替换⽼AOF⽂件
注意:
- 在创建子进程的一瞬间,子进程就继承了当前父进程的内存状态
- 因此,子进程里的内存数据是父进程fork之前的状态,fork之后新来的请求,对内存造成的修改,是子进程不知道的.
- 此时,父进程这里又准备了一个aof_rewrite_buf缓冲区,专门放fork之后收到的数据
- 子进程这边,把AOF数据写完之后,会通过信号通知一下i父进程,父进程再把aof_rewrite_buf缓冲区中的内容写入到新的AOF文件里
- 后面就可以用新的AOF文件代替旧的AOF文件了
问:
- 如果在执行bgrewriteaof的时候,当前redis已经正在进行aof重写了,会怎么样?
此时,不会再次执行aof重写,直接返回
- 如果在执行bgrewriteaof的时候,发现当前redis在生成rdb文件的快照,会怎么样?
此时,aof重写操作就会等待,等待rdb快照生成完毕之后,再执行aof重写操作
rdb对于fork之后的新数据,就直接不管了,aof则对于这些数据,采取aof_rewrite_buf缓冲区的方式来处理
父进程fork完之后,就已经让子进程写新的aof文件了,并且随着时间的推移,子进程很快就写完了新的文件,新的代替旧的
- 那父进程此时还在继续写这个即将消亡的旧的aof文件是否还有意义?
不能不写!!
假设在重写过程中,服务器挂了,子进程内存的数据就会丢失,新的内容还不完整,所以如果不写旧的aof文件,重启就没法保证数据的完整性
2.5 启动时数据恢复
AOF是按照文本的方式来写文件的,但是这样的话后续加载的成本比较高
redis就引入了"混合持久化"方式,结合RDB和AOF的特点
按照AOF的方式,每一个请求/操作,都记录入文件
在触发AOF重写之后,就会把当前内存的状态按照RDB的二进制格式写入新的AOF文件中,后续再进行的操作,仍按照AOF文本的方式追加到文件后

yes表示开启了混合持久化
- 当redis同时存在AOF文件和RDB快照的时候,以谁为主?
以AOF为主,RDB就直接忽略(AOF数据更全)

相关文章:
Redis-持久化
首先,我们明白一个概念, 硬盘>持久 内存>不持久 而Redis是一个内存数据库,不持久,相比于Mysql这样的关系型数据库,最明显的特点是快/效率高 为了保证速度快,数据要保存再内存中,为了持久,存储在硬盘上 所以redis决定: 插入>内存+硬盘(硬盘是为了在re…...
)
封装轮播图 (因为基于微博小程序,语法可能有些出入,如需使用需改标签)
这是在组件中使用,基于微博语法 <template><wbx-view class"" style"width: 100vw;height: 70vh;"><WBXswiper change"gaibian" :vertical"false" :current"current" indicatorActiveColor"…...

【Ubuntu】minicom安装、配置、使用以及退出
目录 1 安装 2 配置 3 使用 4 退出 minicom是一个串口通信的工具,以root权限登录系统,可用来与串口设备通信。 1 安装 sudo apt-get install minicom 2 配置 使用如下命令进入配置界面: sudo minicon -s 进入配置界面后,…...

MYSQL的监控
1. MySQL服务器都提供了哪几种类型的日志文件?说明每种日志的用途。 Error log:启动、关闭和异常有关的诊断信息 General query log:服务器从客户端收到的所有语句 Slow query log:需要很长时间执行的查询 Audit log:企业版基于策略的审计 Binary…...

CTF ciscn_2019_web_northern_china_day1_web2
ciscn_2019_web_northern_china_day1_web2 BEGIN 拿到题目,先看看 这里发现一个很像提示的东西,然后发现下面是一堆小电视商品,有lv等级和金钱,所以这题的入口可能就是再lv6和这个资金募集上 然后点击下next,看看页…...

linux中vim编辑器的应用实例
前言 Linux有大量的配置文件,其中编辑一些配置文件,最常用的工具就是 Vim ,本文介绍一个实际应用的Vim编辑器开发文档的实例。 Vim是一个类似于Vi的著名的功能强大、高度可定制的文本编辑器,在Vi的基础上改进和增加了很多特性。…...

智慧城市交通管理中的云端多车调度与控制
城市交通管理中的云端多车调度与控制 智慧城市是 21世纪的城市基本发展方向,为了实现智慧城市建设的目标,人们需要用现代化的手段去管理和控制城市中的各种资源和设施。智能交通控制与管理是智慧城市中不可缺少的一部分,因为现代城市交通系统…...

分治(归并排序)
一、基本思路 我们以一个归并排序为例。 . - 力扣(LeetCode) 归并排序的思想:得到两个有序数组,把两个有序数组合并,传到下一层递归,一直得到两个有序数组,一直合并,最后就能得到有…...

小学生为什么要学英语
小学生需要学习英语的原因有很多,以下是其中的一些原因(毕竟我也会累滴(* ̄▽ ̄*)): 1. 全球化交流:英语是国际交流的通用语言,学习英语可以帮助小学生更好地融入全球化的社会环境&am…...

企业云存储如何收费?企业云存储收费标准
企业云存储如何收费?企业云存储的收费方式因不同的服务提供商和具体的服务选项而异,通常从用户数量、存储容量、功能、混合收费、按需定价、定制化、功能模块等多个方面进行考量。以下是对其多方面收费方式的详细介绍: 1.按用户数量收费 适用…...

一步步教你LangGraph Studio:可视化调试基于LangGraph构建的AI智能体
之前我们在第一时间介绍过使用LangChain的LangGraph开发复杂的RAG或者Agent应用,随着版本的迭代,LangGraph已经成为可以独立于LangChain核心,用于开发多步骤、面向复杂任务、支持循环的AI智能体的强大框架。 近期LangGraph推出了一个使得复杂…...

用SpringBoot打造先进的学科竞赛管理系统
1绪 论 1.1研究背景 当今时代是飞速发展的信息时代。在各行各业中离不开信息处理,这正是计算机被广泛应用于信息管理系统的环境。计算机的最大好处在于利用它能够进行信息管理。使用计算机进行信息控制,不仅提高了工作效率,而且大大的提高了其…...

Linux入门攻坚——34、nsswitch、pam、rsyslog和loganalyzer前端展示工具
nsswitch:network service switch 名称解析:name <---> id 认证服务:用户名、密码验证或token验证等 名称解析和认证服务都涉及查找位置,即保存在哪里。如linux认证,passwd、shadow,是在文件中&…...
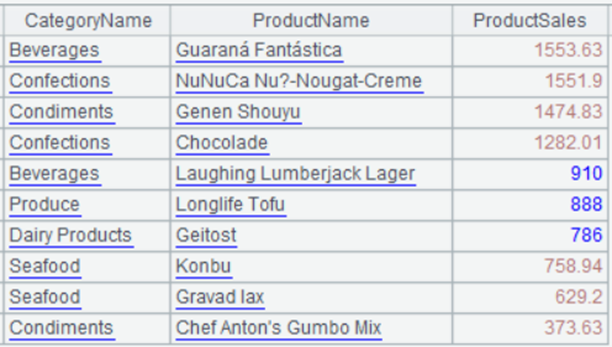
如何在Excel中快速找出前 N 名,后 N 名
有如下销售额统计表: 找出销售额排前 10 名的产品及其销售额,和销售额排倒数 10 名以内的产品及其销售额,结果如下所示: 前 10 名: spl("E(?1).sort(ProductSales:-1).to(10)",A1:C78)后 10 名࿱…...

创意实现!在uni-app小程序商品详情页轮播中嵌入视频播放功能
背景介绍 通过uni-app框架实现商城小程序商品详情页的视频与图片轮播功能,以提升用户体验和增加商品吸引力。通过展示商品视频和图片,用户可以更全面地了解商品细节,从而提高购买决策的便利性和满意度。这种功能适用于各类商品,如…...
WAF,全称Web Application Firewall,好用WAF推荐
WAF,全称Web Application Firewall,即Web应用防火墙,是一种网络安全设备,旨在保护Web应用程序免受各种Web攻击,如SQL注入、跨站脚本(XSS)、跨站请求伪造(CSRF)等。 WAF通…...

docker中搭建nacos并将springboot项目的配置文件转移到nacos中
前言 网上搜索docker中搭建nacos发现文章不是很好理解,正好最近在搭建nacos练手。记录一下整个搭建过程。文章最后附上了一些过程中遇到的问题,大家可以按需要查看。 docker中搭建nacos并将springboot项目的配置文件转移到nacos中 前言1 docker中下拉na…...

概率论原理
智慧挺不喜欢我,他告诉我需要有耐心,答案在后面;而我总想马上得到答案;但它也会给我奖励,因为我总会自己去寻找答案 B站 大大的小番茄 普林斯顿微积分 PDF 一化儿 BILIBILI 泰勒展开式 知乎https://www.zhihu.com…...

MYSQL的安装和升级
MySQL的RPM安装通常分为不同的包,包括Server、Common、Client、Devel、Libs、Libs-compat、Test、Source,请写出上述每个包的功能。 Server:包含MySQL服务器的核心文件和服务。安装此包后可以运行MySQL数据库服务器。 Common:包…...

深入解析 RISC-V 递归函数的栈使用:以阶乘函数为例
在处理递归函数时,RISC-V 体系架构的寄存器数量有限。为了确保每次递归调用能正确保存和恢复寄存器的状态,栈(stack)提供了灵活的解决方案。本文将结合具体的汇编代码和递归的阶乘函数 fact 来讲解 RISC-V 中如何利用栈进行寄存器…...

OpenSpeedy:终极免费游戏变速工具完整使用指南
OpenSpeedy:终极免费游戏变速工具完整使用指南 【免费下载链接】OpenSpeedy 🎮 An open-source game speed modifier. 项目地址: https://gitcode.com/gh_mirrors/op/OpenSpeedy OpenSpeedy是一款完全免费且开源的Windows游戏加速工具,…...

主动悬架乘坐舒适性控制策略优化【附模型】
✨ 长期致力于随机路面、主动悬架、乘坐舒适性、控制策略、仿真分析研究工作,擅长数据搜集与处理、建模仿真、程序编写、仿真设计。 ✅ 专业定制毕设、代码 ✅如需沟通交流,点击《获取方式》 (1)随机路面与1/4悬架动力学建模&…...

基于Ollama构建本地大模型智能体:从原理到工程实践
1. 项目概述:当本地大模型遇上智能体框架最近在折腾本地大模型应用开发的朋友,估计都绕不开一个核心问题:如何让一个“聪明”的模型,不仅能回答问题,还能像真正的助手一样,自主调用工具、处理复杂任务&…...

凌晨还在改论文?这些降重黑科技帮你一键通关
凌晨对着电脑屏幕改论文,那种既疲惫又焦虑的感觉,经历过的人都懂。好在现在的降重工具已经不只是“替换同义词”那么简单了,像 毕业之家 和 PaperRed 这两款主流工具,各自走了完全不同的技术路线,可以根据你的痛点来选…...

终极Blender 3MF插件:如何快速实现3D打印文件的无缝转换
终极Blender 3MF插件:如何快速实现3D打印文件的无缝转换 【免费下载链接】Blender3mfFormat Blender add-on to import/export 3MF files 项目地址: https://gitcode.com/gh_mirrors/bl/Blender3mfFormat Blender3mfFormat是一款专为Blender设计的开源插件&a…...

3步完成微信聊天记录永久备份:开源工具WeChatExporter终极指南
3步完成微信聊天记录永久备份:开源工具WeChatExporter终极指南 【免费下载链接】WeChatExporter 一个可以快速导出、查看你的微信聊天记录的工具 项目地址: https://gitcode.com/gh_mirrors/wec/WeChatExporter WeChatExporter是一款专为Mac用户设计的开源工…...

系统提示、开发提示、用户提示:在 Agent 里怎么分层
系统提示、开发提示、用户提示在 Agent 里的分层架构:从理论到工业级落地全解析 副标题:基于认知科学、软件工程双视角,构建可复用、可调试、高智能的三层提示架构体系 第一部分:引言与基础 (Introduction & Foundation) 1.1 引人注目的标题(重复+锚定SEO) 系统提…...

Vue3 + Vite项目集成vue-particles避坑指南:从安装到性能优化全流程
Vue3 Vite项目集成vue-particles全流程实战:从安装到性能调优 在Vue3和Vite构建的现代前端项目中,集成像vue-particles这样的视觉特效组件往往会遇到意想不到的兼容性问题。不同于传统的Webpack环境,Vite的ES模块系统和Vue3的组合式API带来了…...

BaiduPCS-Go深度解析:从原理到实践的性能调优进阶指南
BaiduPCS-Go深度解析:从原理到实践的性能调优进阶指南 【免费下载链接】BaiduPCS-Go iikira/BaiduPCS-Go原版基础上集成了分享链接/秒传链接转存功能 项目地址: https://gitcode.com/GitHub_Trending/ba/BaiduPCS-Go BaiduPCS-Go作为一款功能强大的命令行百度…...

保姆级教程:在Google Colab上用TensorFlow 2.0快速搭建你的第一个ACGAN图像生成器
零门槛实战:用ColabTensorFlow打造你的首个ACGAN数字生成器 想象一下,只需点击几次就能让AI学会生成逼真的手写数字——这不再是实验室里的黑科技。我们将利用Google Colab的免费GPU资源,带你用TensorFlow 2.0快速搭建一个能按需求生成特定数…...