丹摩智算平台部署 Llama 3.1:实践与体验

文章目录
- 前言
- 部署前的准备
- 创建实例
- 部署与配置 Llama 3.1
- 使用心得
- 总结
前言
在最近的开发工作中,我有机会体验了丹摩智算平台,部署并使用了 Llama 3.1 模型。在人工智能和大模型领域,Meta 推出的 Llama 3.1 已经成为了目前最受瞩目的开源模型之一。今天,我将通过这次实践,分享在丹摩平台上部署 Llama 3.1 的实际操作流程以及我的个人心得。
部署前的准备
Llama 3.1 是一个资源需求较高的模型,因此在部署之前,首先要确保拥有合适的硬件环境。按照文档中的要求,我选择了 Llama 3.1 8B 版本进行测试。8B 模型对 GPU 显存的需求为 16GB,因此我在丹摩平台上选择了 NVIDIA RTX 4090 作为我的实例,并且配置了 60GB 的数据硬盘容量,来满足下载模型和存储相关文件的需求。
在丹摩平台的控制台创建 GPU 云实例非常简单,整个流程仅需几分钟的时间。在实例创建页面中,我能够灵活选择 GPU 的数量和型号,平台还提供了便捷的镜像选择功能,省去了大量的环境配置工作。我选择了预装 PyTorch 2.4.0 的镜像,确保在后续的部署过程中不需要手动安装繁杂的依赖环境。
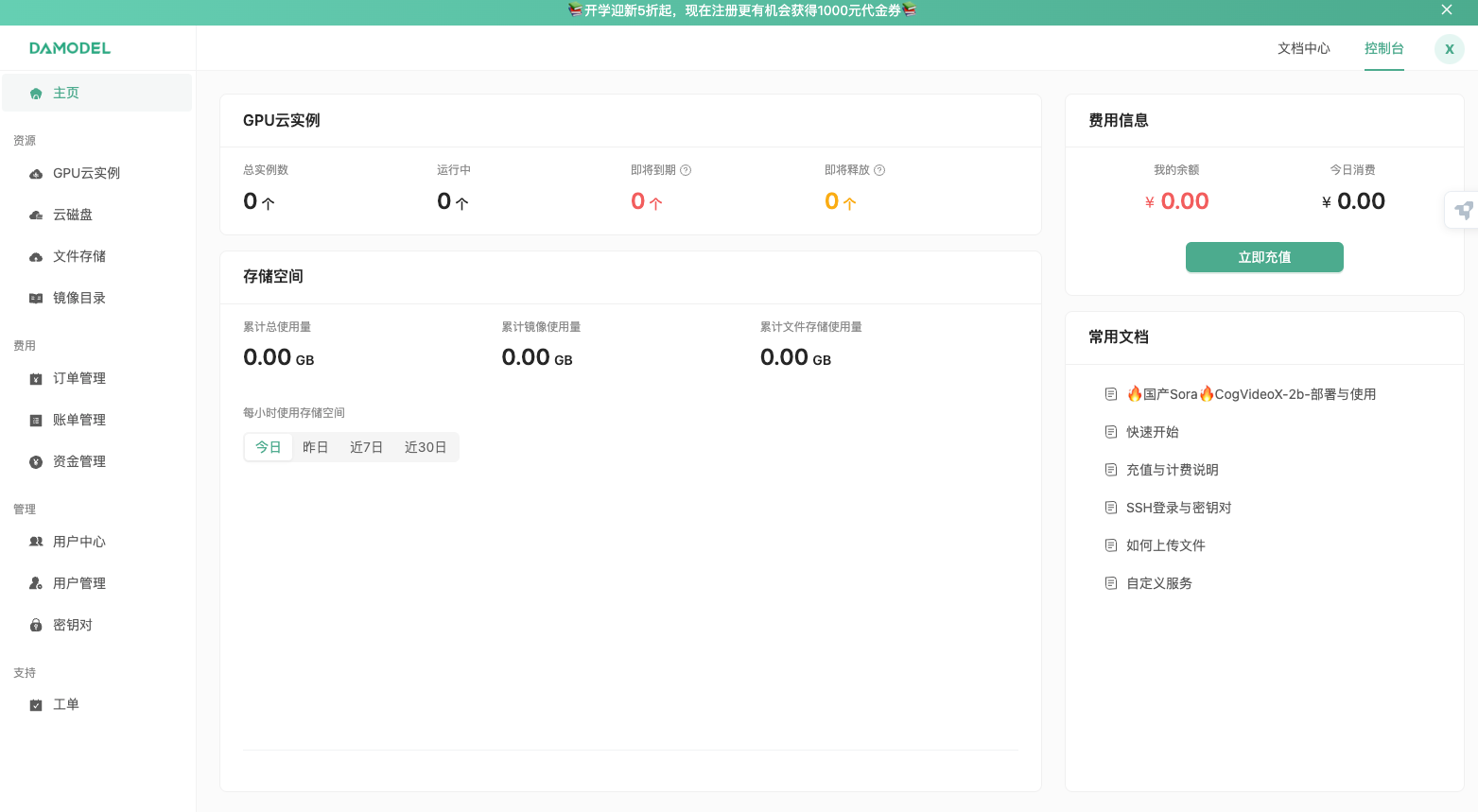
创建实例
进入控制台-GPU云实例,点击创建实例:
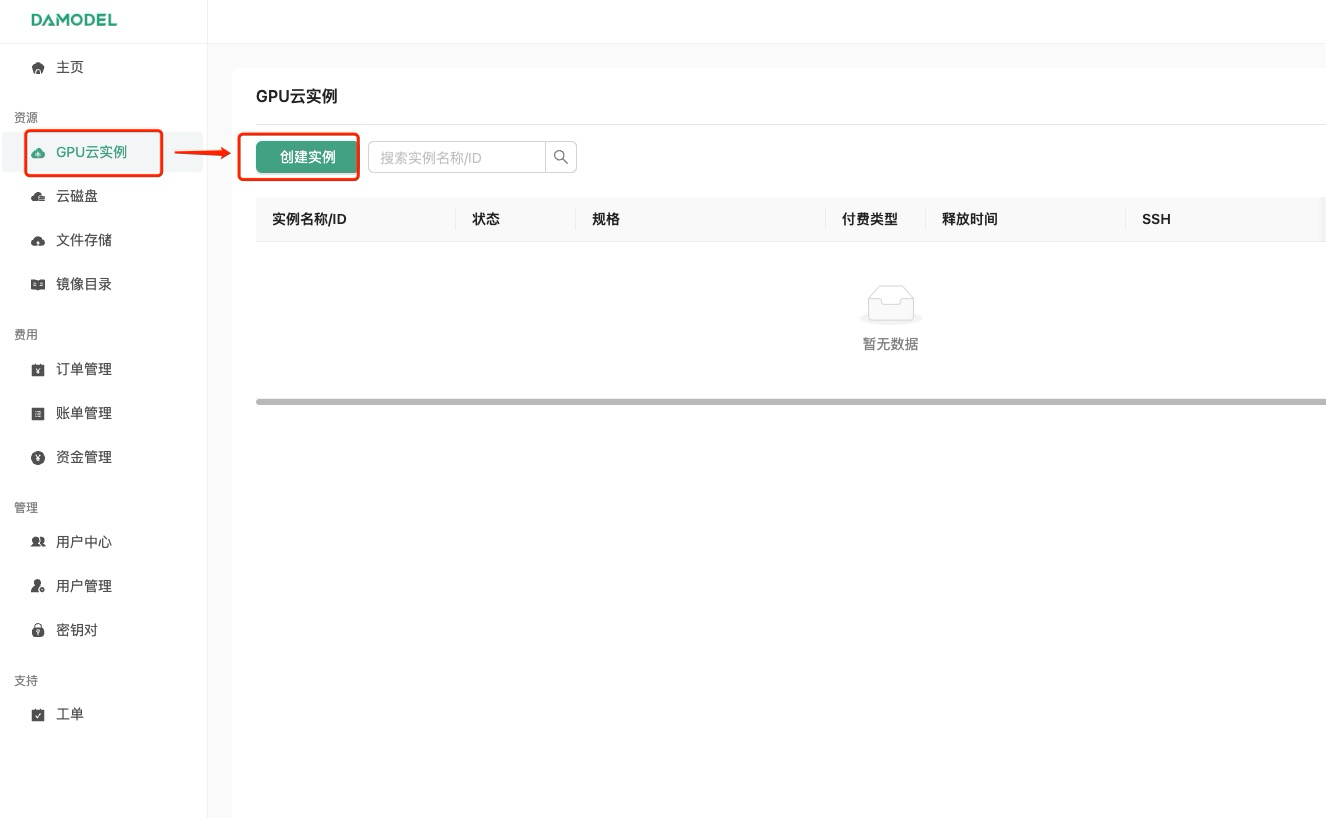
进入创建页面后,首先在实例配置中选择付费类型,一般短期需求可以选择按量付费或者包日,长期需求可以选择包月套餐;
其次选择GPU数量和需求的GPU型号,首次创建实例推荐选择:
按量付费–GPU数量1–NVIDIA-GeForc-RTX-4090,该配置为60GB内存,24GB的显存(本次测试的LLaMA3.1 8B 版本至少需要GPU显存16G)
接下来配置数据硬盘的大小,每个实例默认附带了50GB的数据硬盘,首次创建可以就选择默认大小50GB。
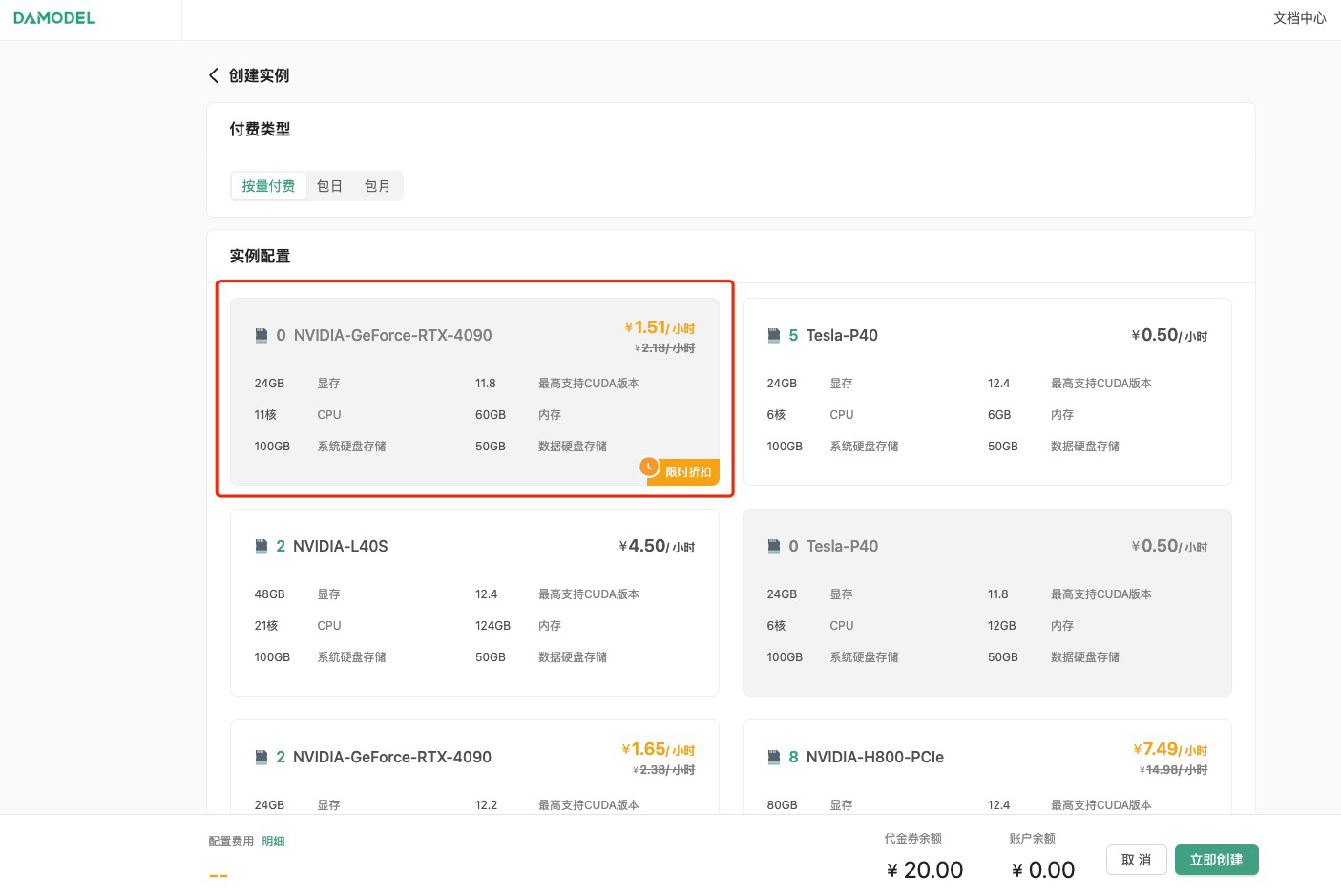
继续选择安装的镜像,平台提供了一些基础镜像供快速启动,镜像中安装了对应的基础环境和框架,可通过勾选来筛选框架,这里筛选PyTorch,选择PyTorch 2.4.0。
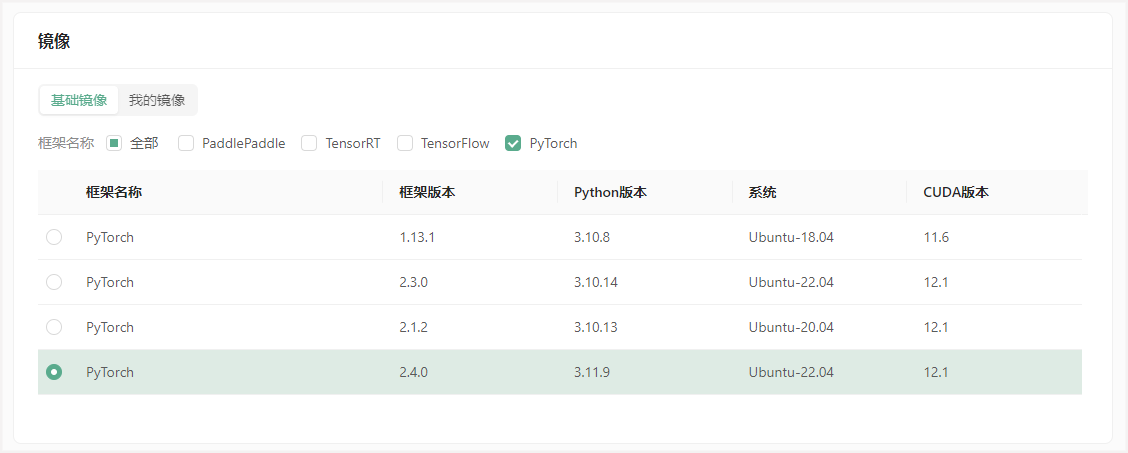
为保证安全登录,创建密钥对,输入自定义的名称,然后选择自动创建并将创建好的私钥保存的自己电脑中并将后缀改为.pem,以便后续本地连接使用。
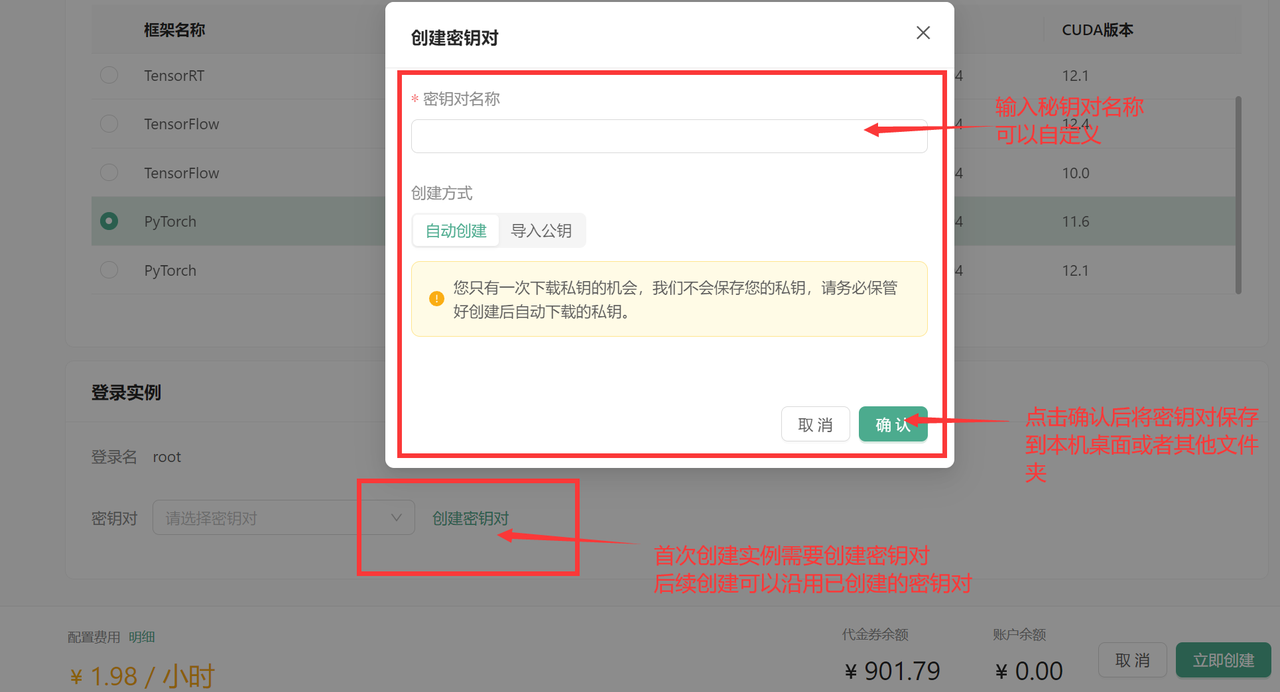
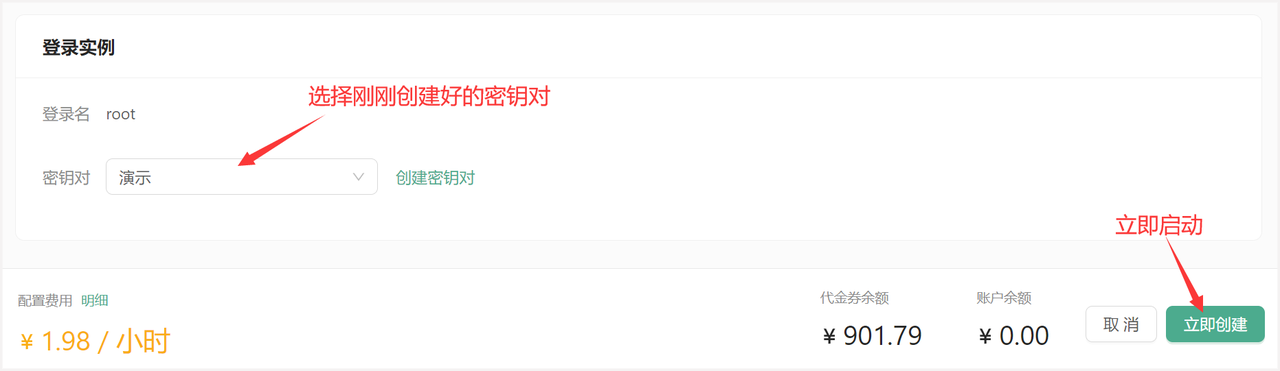
创建好密钥对后,选择刚刚创建好的密钥对,并点击立即创建,等待一段时间后即可启动成功!
部署与配置 Llama 3.1
实例成功创建后,我通过 JupyterLab 的在线登录入口进入了实例的操作界面。在这个环境中,所有的文件路径和资源配置都已经预先设置好,这极大地简化了操作。我通过 conda 创建了一个新的环境,并安装了部署 Llama 3.1 所需的依赖库,包括 LangChain、Streamlit、Transformers 和 Accelerate。
以下是安装依赖的关键命令:
pip install langchain==0.1.15
pip install streamlit==1.36.0
pip install transformers==4.44.0
pip install accelerate==0.32.1
依赖安装完成后,平台提供了内网下载 Llama-3.1-8B 模型的功能,下载速度非常快。解压完模型后,我编写了一个简单的 Streamlit 脚本,用于启动 Llama 3.1 模型的聊天界面。Streamlit 的使用非常简便,可以快速搭建一个 Web 服务来和模型进行交互。
我的代码核心部分如下:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st# 创建标题和副标题
st.title("💬 LLaMA3.1 Chatbot")
st.caption("🚀 A streamlit chatbot powered by Self-LLM")# 定义模型路径
mode_name_or_path = '/root/workspace/Llama-3.1-8B-Instruct'# 获取模型和tokenizer
@st.cache_resource
def get_model():tokenizer = AutoTokenizer.from_pretrained(mode_name_or_path, trust_remote_code=True)tokenizer.pad_token = tokenizer.eos_tokenmodel = AutoModelForCausalLM.from_pretrained(mode_name_or_path, torch_dtype=torch.bfloat16).cuda()return tokenizer, modeltokenizer, model = get_model()# 聊天逻辑
if prompt := st.chat_input():st.chat_message("user").write(prompt)input_ids = tokenizer([prompt], return_tensors="pt").to('cuda')generated_ids = model.generate(input_ids.input_ids, max_new_tokens=512)response = tokenizer.decode(generated_ids[0], skip_special_tokens=True)st.chat_message("assistant").write(response)
在终端中运行:
streamlit run llamaBot.py --server.address 0.0.0.0 --server.port 1024
启动后,通过丹摩平台提供的端口映射功能,将内部端口映射到公网。通过链接,我成功访问到了我的 Llama 3.1 Chatbot 界面。
使用心得
通过这次实践,我对丹摩智算平台的易用性有了深刻的体会。首先,平台在创建实例、配置环境以及下载模型等环节提供了高度集成化的操作,省去了很多手动配置的麻烦,特别是在处理大模型时,内网高速下载和预装环境镜像极大地提高了工作效率。
在模型部署和使用过程中,我能够明显感受到 Llama 3.1 在生成式对话方面的强大性能,尤其是在自然语言理解和生成方面的表现出色。即便是 8B 版本,响应速度和文本生成质量都让我非常满意。这次实践让我深刻认识到,开源大模型与云端计算资源的结合,可以让开发者以更低的门槛接触到前沿的 AI 技术,快速实现自己的项目和想法。
总结
总体来说,丹摩智算平台提供了一个强大且高效的 AI 开发环境,尤其适合像我这样需要进行大模型部署和实验的开发者。无论是硬件资源的灵活选择,还是内置的环境配置和工具支持,都极大地简化了部署流程。通过这次部署 Llama 3.1 的实践,我不仅学会了如何高效利用云计算平台,也对大模型在实际项目中的应用有了更深刻的理解。
相关文章:
丹摩智算平台部署 Llama 3.1:实践与体验
文章目录 前言部署前的准备创建实例 部署与配置 Llama 3.1使用心得总结 前言 在最近的开发工作中,我有机会体验了丹摩智算平台,部署并使用了 Llama 3.1 模型。在人工智能和大模型领域,Meta 推出的 Llama 3.1 已经成为了目前最受瞩目的开源模…...

SpringCloud 2023各依赖版本选择、核心功能与组件、创建项目(注意事项、依赖)
目录 1. 各依赖版本选择2. 核心功能与组件3. 创建项目3.1 注意事项3.2 依赖 1. 各依赖版本选择 SpringCloud: 2023.0.1SpringBoot: 3.2.4。参考Spring Cloud Train Reference Documentation选择版本 SpringCloud Alibaba: 2023.0.1.0*: 参考Spring Cloud Alibaba选择版本。同时…...

串行化执行、并行化执行
文章目录 1、串行化执行2、并行化测试(多线程环境)3、任务的执行是异步的,但主程序的继续执行是同步的 可以将多个任务编排为并行和串行化执行。 也可以处理编排的多个任务的异常,也可以返回兜底数据。 1、串行化执行 顺序执行、…...
)
二叉搜索树(c++版)
前言 在前面我们介绍过二叉树这个数据结构,今天我们更进一步来介绍二叉树的一种在实现中运用的场景——二叉搜索树。二叉搜索树顾名思义其在“搜索”这个场景下有不俗的表现,之所以会这样是因为它在二叉树的基础上添加了一些属性。下面我们就来简单的介…...

每日1题-7
...

简单实现log记录保存到文本和数据库
简单保存记录到txt,sqlite数据库,以及console监控记录 using System; using System.Collections.Generic; using System.ComponentModel; using System.Text; using System.Data.SQLite; using System.IO;namespace NlogFrame {public enum LogType{Tr…...

敏感字段加密 - 华为OD统一考试(E卷)
2024华为OD机试(E卷+D卷+C卷)最新题库【超值优惠】Java/Python/C++合集 题目描述 【敏感字段加密】给定一个由多个命令字组成的命令字符串: 1、字符串长度小于等于127字节,只包含大小写字母,数字,下划线和偶数个双引号; 2、命令字之间以一个或多个下划线 进行分割; 3、可…...

go 安装三方库
go版本 go versiongo version go1.23.1 darwin/arm64安装 redis 库 cd $GOPATH说明: 这里可以改 GOPATH的值 将如下 export 语句写入 ~/.bash_profile 文件中 export GOPATH/Users/goproject然后使其生效 source ~/.bash_profile初始化生成 go.mod 文件 go mod…...

Java 中的 volatile和synchronized和 ReentrantLock区别讲解和案例示范
在 Java 的并发编程中,volatile、synchronized 和 ReentrantLock 是三种常用的同步机制。每种机制都有其独特的特性、优缺点和适用场景。理解它们之间的区别以及在何种情况下使用哪种机制,对提高程序的性能和可靠性至关重要。本文将详细探讨这三种机制的…...

从GDAL中 读取遥感影像的信息
从GDAL提供的实用程序来看,很多程序的后缀都是 .py ,这充分地说明了Python语言在GDAL的开发中得到了广泛的应用。 1. 打开已有的GeoTIF文件 下面我们试着读取一个GeoTiff文件的信息。第一步就是打开一个数据集。 >>> from osgeo import gdal…...

算法闭关修炼百题计划(一)
多看优秀的代码一定没有错,此篇博客属于个人学习记录 1.两数之和2.前k个高频元素3.只出现一次的数字4.数组的度5.最佳观光组合6.整数反转7.缺失的第一个正数8.字符串中最多数目的子序列9.k个一组翻转链表10.反转链表II11. 公司命名12.合并区间13.快速排序14.数字中的…...

vue3实现打字机的效果,可以换行
之前看了很多文章,效果是实现了,就是没有自动换行的效果,参考了文章写了一个,先上个效果图,卡顿是因为模仿了卡顿的效果,还是很丝滑的 目录 效果图:代码如下 效果图: 
【如何学习操作系统】——学会学习的艺术
🐟作者简介:一名大三在校生,喜欢编程🪴 🐡🐙个人主页🥇:Aic山鱼 🐠WeChat:z7010cyy 🦈系列专栏:🏞️ 前端-JS基础专栏✨前…...

stm32 flash无法擦除
通过bushound调试代码发现,当上位机发送命令到模组后flash将不能擦除,通过 HAL_FLASH_GetError()函数查找原因是FLASH Programming Sequence error(编程顺序错误),解决办法是在解锁后清零标志位…...

Android—ANR日志分析
获取ANR日志: ANR路径:/data/anrADB指令:adb bugreport D:\bugrep.zip ANR日志分析步骤: “main” prio:主线程状态beginning of crash:搜索 crash 相关信息CPU usage from:搜索 cpu 使用信息…...

9.29 LeetCode 3304、3300、3301
思路: ⭐进行无限次操作,但是 k 的取值小于 500 ,所以当 word 的长度大于 500 时就可以停止操作进行取值了 如果字符为 ‘z’ ,单独处理使其变为 ‘a’ 得到得到操作后的新字符串,和原字符串拼接 class Solution { …...

近万字深入讲解iOS常见锁及线程安全
什么是锁? 在程序中,当多个任务(或线程)同时访问同一个资源时,比如多个操作同时修改一份数据,可能会导致数据不一致。这时候,我们需要“锁”来确保同一时间只有一个任务能够操作这个数据&#…...

linux创建固定大小的文件夹用于测试
在linux上创建固定大小的文件夹用于测试磁盘空间不足时的应用故障。 实验环境为centos7,有两种简易方法: 一、使用ramdisk 1、创建文件夹 mkdir /var/mytest 2、创建一个1m大小的临时文件 mount none /var/mytest -t tmpfs -o size1m size也可以写…...

大模型学习路线:这会是你见过最全最新的大模型学习路线【2024最新】
大模型学习路线 建议先从主流的Llama开始,然后选用中文的Qwen/Baichuan/ChatGLM,先快速上手体验prompt工程,然后再学习其架构,跑微调脚本 如果要深入学习,建议再按以下步骤,从更基础的GPT和BERT学起&…...

了解云计算工作负载保护的重要性,确保数据和应用程序安全
云计算de小白 云计算技术的快速发展使数据和应用程序安全成为一种关键需求,而不仅仅是一种偏好。随着越来越多的客户公司将业务迁移到云端,保护他们的云工作负载(指所有部署的应用程序和服务)变得越来越重要。云工作负载保护&…...

终极智能温控指南:FanControl风扇控制软件完整配置教程
终极智能温控指南:FanControl风扇控制软件完整配置教程 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/f…...

Arm CoreLink GFC-200 Flash控制器架构与优化实践
1. Arm CoreLink GFC-200 Flash控制器架构解析在嵌入式系统设计中,非易失性存储管理是核心挑战之一。作为Arm CoreLink系列的重要成员,GFC-200通用Flash控制器通过创新的总线架构和分区管理机制,为SoC设计提供了高效的Flash存储解决方案。这款…...

SITS 2026多目标优化落地指南:从梯度冲突到任务解耦,7步实现Pareto前沿精度提升23.6%
更多请点击: https://intelliparadigm.com 第一章:AI原生多任务学习:SITS 2026多目标优化实战技巧 在SITS 2026竞赛框架下,AI原生多任务学习(AI-Native Multi-Task Learning, AMTL)不再依赖传统单任务迁移…...

从玩具到生产:基于run-llama/rags构建模块化RAG系统的工程实践
1. 项目概述:从“玩具”到“生产力”的RAG系统构建如果你最近在关注大语言模型的应用落地,那么“RAG”这个词一定高频出现在你的视野里。RAG,即检索增强生成,它试图解决大模型“一本正经胡说八道”和“知识陈旧”两大核心痛点。简…...

FPGA/CPLD数字系统设计实战:从器件选型到调试验证的工程指南
1. 从一则行业趣闻聊起:FPGA厂商的“江湖地位”与我们的设计选择前几天翻看一些老旧的行业资料,偶然间又看到了这篇2012年来自EE Times的“陈年旧文”。文章作者Clive Maxfield用他标志性的幽默笔调,聊了一个看似无厘头的话题:将科…...

【研报 A110】物理AI时代的具身数据采集需求研究:国家级训练场落地,开源生态加速建设
摘要:物理AI时代,具身智能与世界模型的发展,推动具身数据采集成为下一代数据基建的核心浪潮。具身大模型对数据有着EB级的海量需求,同时对多模态、异构性与质量要求极高,当前数据缺口成为制约具身智能发展的核心瓶颈&a…...

LSLib:让《神界原罪》和《博德之门3》MOD制作变得高效完整的实用指南
LSLib:让《神界原罪》和《博德之门3》MOD制作变得高效完整的实用指南 【免费下载链接】lslib Tools for manipulating Divinity Original Sin and Baldurs Gate 3 files 项目地址: https://gitcode.com/gh_mirrors/ls/lslib 你是否曾想为《神界原罪》或《博德…...

马斯克解散 xAI、接纳 Anthropic:亡羊补牢的无奈,与一场被 AGI 神话带偏的豪赌
马斯克解散 xAI、接纳 Anthropic:亡羊补牢的无奈,与一场被 AGI 神话带偏的豪赌 2026 年 5 月 6 日,两件事同时发生: 一、Anthropic 宣布获得 xAI Colossus 1 集群的全部算力——22 万张英伟达 GPU,300 兆瓦电力容量。 …...

鸿蒙 App 的 Task + State 双核心架构
子玥酱 (掘金 / 知乎 / CSDN / 简书 同名) 大家好,我是 子玥酱,一名长期深耕在一线的前端程序媛 👩💻。曾就职于多家知名互联网大厂,目前在某国企负责前端软件研发相关工作,主要聚…...

加州自动驾驶测试报告解读:数据背后的技术演进与行业趋势
1. 从加州数据看自动驾驶的“成绩单”:2021年测试报告深度解读每年年初,自动驾驶圈子里不少人都会习惯性地去翻看一份来自美国加州的“成绩单”——加州机动车辆管理局发布的年度自动驾驶车辆测试报告。这份报告就像一份公开的“期中考试”排名ÿ…...