【高性能内存池】page cache 5
page cache
- 1 page cache的框架
- 2 central cache从page cache申请n页span的过程
- 3 page cache 的结构
- 3.1 page cache类框架
- 3.2 central cache向page cache申请span
- 3.3 获取k页的span
page cache的结构和central cache是一样的,都是哈希桶的结构,并且挂载的都是span。但是不同的是,central cache为thread cache服务,分配的是一个个freeList,所以需要和thread cache的映射规则一样,page cache为central cache服务,分配的是一个个span。所以page cache挂载的span不会进行切分。
1 page cache的框架
下面的图中,左边是central cache的结构,右边是page cache的结构。

我们假设page cache的桶为128页大小(这个可以根据实际情况更改),为了让桶号和页号对应起来,我们让0号桶为空,所以page cache的哈希桶个数要设置为129.
//page cache中哈希桶的个数
static const size_t NPAGES = 129;
2 central cache从page cache申请n页span的过程
下面是page cache的结构

当central cache向page cache申请n页的span时,page cache的做法如下:
3 page cache 的结构
1. page cache是否需要加锁?
需要。因为每个线程都拥有一份
thread cache,当thread cache中没有内存时,会向central cache中要。如果多个thread cache同时访问central cache的一个桶时,就会出现线程安全问题,就需要加桶锁。但是如果多个thread cache访问不同的central cache是不会出现线程安全问题的,也不需要加锁。而如果此时多个central cache同时访问page cache就会出现线程安全问题。
2. 那page cache加的锁是桶锁吗?
不是
central cache的分配方式是每个桶独立的,所以可以使用桶锁。而根据上面描述的page cache的分配方式,访问第n号桶很可能是从n + 1号桶中拿到span,分配给central cache后,再将剩余的span挂载到1号桶中。这种分配方式会涉及到多个桶,如果使用桶锁,锁住其中一个桶,其他的桶就无法进行协同了。所以page cache加的是一把大锁,能将整个page cache锁住。
4.page cache需要设计单例模式吗?
需要。整个进程中能有一个
page cache,所以page cache也需要设计一个单例模式。
3.1 page cache类框架
//单例模式
class PageCache
{
public://提供一个全局访问点static PageCache* GetInstance(){return &_sInst;}
private://static const size_t NPAGES = 129;SpanList _spanLists[NPAGES]; std::mutex _pageMtx; //大锁
private:PageCache() //构造函数私有{}PageCache(const PageCache&) = delete; //防拷贝static PageCache _sInst;
};3.2 central cache向page cache申请span
当thread cache向central cache申请span的时候,会从central cache中获取一个非空的span,在上篇文章中的实现是这样的:
Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{// 查看当前的spanlist中是否有还有未分配对象的spanSpan* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}else{it = it->_next;}}// 先把central cache的桶锁解掉,这样如果其他线程释放内存对象回来,不会阻塞list._mtx.unlock();return span;
}
但是上篇文章没有考虑如果central cache中没有span了该怎么办。
当central cache中没有span了该怎么办?
需要向
page cache申请
central cache如何向page cache申请span?
1.计算出
thread cache一次向central cache申请的freeList的个数num
2. 将freeList的个数num和thread cache申请的size字节相乘,计算出要申请的总字节数npage
3. 将npage除以页的大小,最终得到central cache要向page cache申请多少个页。不满1页按1页算。
static size_t NumMovePage(size_t size){//计算thread cache找central cache要的freeList的个数size_t num = NumMoveSize(size);//计算申请的总的字节数size_t npage = num*size;//计算向page cache申请的总的页数npage >>= PAGE_SHIFT;//不满1页按1页算if (npage == 0)npage = 1;return npage;}
PAGE_SHIFT表示页的大小,这里为13,因为2<sup>13</sup> = 8KB
static const size_t PAGE_SHIFT = 13;
当central cache从page cache中申请到span之后,还需要将span进行切分,切分成符合大小的freeList挂在span下面。
central cache是如何进行切分的?
1.计算
span的大块内存的起始地址start:span的起始页号乘以一页的大小即可得到这个span的起始地址
2.计算span的大小(字节数)bytes:span的页数乘以一页的大小
3.计算span的结束位置的地址end:start + bytes
4.将span切分为size大小,全部尾插到原来的span->freeList后面。具体过程看下图。

Span* CentralCache::GetOneSpan(SpanList& list, size_t size)
{// 查看当前的spanlist中是否有还有未分配对象的spanSpan* it = list.Begin();while (it != list.End()){if (it->_freeList != nullptr){return it;}else{it = it->_next;}}// 先把central cache的桶锁解掉,这样如果其他线程释放内存对象回来,不会阻塞list._mtx.unlock();// 走到这里说没有空闲span了,只能找page cache要PageCache::GetInstance()->_pageMtx.lock();Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));span->_isUse = true;span->_objSize = size;PageCache::GetInstance()->_pageMtx.unlock();// 对获取span进行切分,不需要加锁,因为这会其他线程访问不到这个span// 计算span的大块内存的起始地址和大块内存的大小(字节数)char* start = (char*)(span->_pageId << PAGE_SHIFT);size_t bytes = span->_n << PAGE_SHIFT;char* end = start + bytes;// 把大块内存切成自由链表链接起来// 1、先切一块下来去做头,方便尾插span->_freeList = start; start += size; void* tail = span->_freeList; int i = 1;while (start < end){++i;NextObj(tail) = start; //相当于tail->next = starttail = NextObj(tail); // tail = start;start += size;}NextObj(tail) = nullptr;// 切好span以后,需要把span挂到桶里面去的时候,再加锁list._mtx.lock();list.PushFront(span);return span;
}
3.3 获取k页的span
Span* span = PageCache::GetInstance()->NewSpan(SizeClass::NumMovePage(size));
上面是GetOneSpan函数中用到的从page cache中拿k页大小的span的调用过程。
当central cache向page cache申请一个k页的span时,如果page cache中有k页的span,就直接删除然后给central cache就行了,如果没有,就要去堆中申请一个128页大小的span了。
回顾之前central cache向page cache申请内存的过程。
当central cache向page cache申请一个k页大小的span时,由于page cache是直接映射,所以只需要去第k号桶中找是否有span就行了。如果没有,就去k + 1,k + 2…中找,直到找到第128号桶都没有时,再去堆中申请。
当page cache向堆中申请128页大小的内存时,得到的是128页内存的起始地址,我们需要将这份起始地址转换为对应的页号,也就是将起始地址除以1页的大小。
//获取一个k页的span
Span* PageCache::NewSpan(size_t k)
{assert(k > 0 && k < NPAGES);//先检查第k个桶里面有没有spanif (!_spanLists[k].Empty()){return _spanLists[k].PopFront();}//检查一下后面的桶里面有没有span,如果有可以将其进行切分for (size_t i = k + 1; i < NPAGES; i++){if (!_spanLists[i].Empty()){Span* nSpan = _spanLists[i].PopFront();Span* kSpan = new Span;//在nSpan的头部切k页下来kSpan->_pageId = nSpan->_pageId;kSpan->_n = k;nSpan->_pageId += k;nSpan->_n -= k;//将剩下的挂到对应映射的位置_spanLists[nSpan->_n].PushFront(nSpan);return kSpan;}}//走到这里说明后面没有大页的span了,这时就向堆申请一个128页的spanSpan* bigSpan = new Span;void* ptr = SystemAlloc(NPAGES - 1);bigSpan->_pageId = (PAGE_ID)ptr >> PAGE_SHIFT;bigSpan->_n = NPAGES - 1;_spanLists[bigSpan->_n].PushFront(bigSpan);//尽量避免代码重复,递归调用自己return NewSpan(k);
}
为什么要递归调用?
因为
page cache向堆申请了128页大小的内存,需要将其切分成k页的span和128-k页的span。本来需要编写切分的代码,但是为了避免写重复的代码,就再递归调用该函数,后面会自行切分的。
当central cache向page cache申请内存时,central cache对应的哈希桶是处于加锁的状态的,那在访问page cache之前我们应不应该把central cache对应的桶锁解掉呢?
这里建议在访问
page cache前,先把central cache对应的桶锁解掉。虽然此时central cache的这个桶当中是没有内存供其他thread cache申请的,但thread cache除了申请内存还会释放内存,如果在访问page cache前将central cache对应的桶锁解掉,那么此时当其他thread cache想要归还内存到central cache的这个桶时就不会被阻塞。
因此在调用
NewSpan函数之前,我们需要先将central cache对应的桶锁解掉,然后再将page cache的大锁加上,当申请到k页的span后,我们需要将page cache的大锁解掉,但此时我们不需要立刻获取到central cache中对应的桶锁。因为central cache拿到k页的span后还会对其进行切分操作,因此我们可以在span切好后需要将其挂到central cache对应的桶上时,再获取对应的桶锁。
这里为了让代码清晰一点,只写出了加锁和解锁的逻辑,我们只需要将这些逻辑添加到之前实现的
GetOneSpan函数的对应位置即可。
spanList._mtx.unlock(); //解桶锁
PageCache::GetInstance()->_pageMtx.lock(); //加大锁//从page cache申请k页的spanPageCache::GetInstance()->_pageMtx.unlock(); //解大锁//进行span的切分...spanList._mtx.lock(); //加桶锁//将span挂到central cache对应的哈希桶
相关文章:
【高性能内存池】page cache 5
page cache 1 page cache的框架2 central cache从page cache申请n页span的过程3 page cache 的结构3.1 page cache类框架3.2 central cache向page cache申请span3.3 获取k页的span page cache的结构和central cache是一样的,都是哈希桶的结构,并且挂载的…...

Vue 3 魔法揭秘:CSS 解析与 scoped 背后的奇幻之旅
文章目录 一、背景二、源码分析transformMain 返回值transformStyle 方法compileStyleAsync 方法scopedPlugin 方法template 添加 __scopeId 三、总结 一、背景 Vue 3 文件编译流程详解与 Babel 的使用 上文分析了 vue3 的编译过程,但是在对其中样式的解析遗留了一…...

如何获取钉钉webhook
第一步打开钉钉并登录 第二步创建团队 并且 添加自定义 机器人 即可获取webhook...

网页WebRTC电话和软电话哪个好用?
关于WebRTC电话与软件电话哪个更好用,这实际上取决于多个因素,并没有一个绝对的答案。不过,我可以根据WebRTC技术的一些特点,以及与传统软件电话相比的优劣势,为你提供一个清晰的对比。 首先,让我们了解一下…...

MySQL Mail服务器集成:如何配置发送邮件?
MySQL Mail插件使用指南?怎么优化 MySQL发邮件性能? MySQL Mail服务器的集成,使得数据库可以直接触发邮件发送,极大地简化了应用架构。AokSend将详细介绍如何配置MySQL Mail服务器,以实现邮件发送功能。 MySQL Mail&…...

【Rockchip系列】官方函数:imcopy
imcopy 函数原型 IM_STATUS imcopy(const rga_buffer_t src,rga_buffer_t dst,int sync 1,int *release_fence_fd NULL);功能说明 imcopy函数用于执行单次快速图像拷贝操作,将图像从源缓冲区拷贝到目标缓冲区。 参数说明 参数描述src[必填] 源图像缓冲区&…...

Matlab实现鲸鱼优化算法优化回声状态网络模型 (WOA-ESN)(附源码)
目录 1.内容介绍 2部分代码 3.实验结果 4.内容获取 1内容介绍 鲸鱼优化算法(Whale Optimization Algorithm, WOA)是一种基于座头鲸捕食行为的群智能优化算法。该算法通过模仿座头鲸使用螺旋形路径和包围猎物的策略来探索和开发解空间,以找到…...

迈威通信闪耀工博会,以创新科技赋能工业自动化
昨日,在圆满落幕的第24届中国国际工业博览会上,迈威通信作为工业自动化与智慧化领域的先行者,以“创新打造新质通信,赋能工业数字化”为主题精彩亮相,向全球业界展示了我们在工业自动化领域的最新成果与创新技术。此次…...

C# DotNetty客户端
1. 引入DotNetty包 我用的开发工具是VS2022,不同工具引入可能会有差异 工具——>NuGet包管理器——>管理解决方案的NuGet程序包 搜索DotNetty 2.新建EchoClientHandler.cs类 用于接收服务器返回数据 public class EchoClientHandler : SimpleChannelIn…...
4G模组SIM卡电路很简单,但也要注意这些坑
上次水SIM卡相关的文章,还是上一次; 上一篇文章里吹牛说,跟SIM卡相关的问题还有很多,目的是为下一篇文章埋下伏笔;伏笔埋是埋下了,但如果债老是不还,心里的石头就总悬着,搞不好老板…...

常见电脑品牌BIOS设置与进入启动项快捷键
常见电脑品牌BIOS与引导项快捷键速查表 | 电脑品牌 | BIOS快捷键 | 引导项快捷键 | 备注 ||------------|------------|--------------|------------------------------ || 联想 | F2/F1 | F12 | 笔记本通常为F2,台式机通常为F1 || IBM/ThinkPad | F1 | 未知 | ||…...

C语言中的日志机制:打造全面强大的日志系统
前言 在软件开发中,良好的日志记录机制对于调试、监控程序状态和维护系统的稳定性至关重要。本文将介绍如何在C语言中构建一个全面强大的日志系统,并提供一些示例代码。 1. 日志的基本概念 日志级别:用于分类日志信息的重要性,…...

局域网广域网,IP地址和端口号,TCP/IP 4层协议,协议的封装和分用
前言 在古老的年代,如果我们要实现两台机器进行数据传输, A员工就得去B员工的办公电脑传数据(B休息,等A传完),这样就很浪费时间 所以能不能不去B的工位的同时,还能传数据。这时候网络通信就出来…...

LabVIEW项目编码器选择
在LabVIEW项目中,选择增量式(Incremental Encoder)和绝对式(Absolute Encoder)编码器取决于项目的具体需求。增量式编码器和绝对式编码器在工作原理、应用场景、精度和成本等方面存在显著差异。以下从多方面详细阐述两…...

Spring Boot实现房产租赁业务逻辑
1 绪论 1.1 研究背景 中国的科技的不断进步,计算机发展也慢慢的越来越成熟,人们对计算机也是越来越更加的依赖,科研、教育慢慢用于计算机进行管理。从第一台计算机的产生,到现在计算机已经发展到我们无法想象。给我们的生活改变很…...

汽车3d动画渲染选择哪个?选择最佳云渲染解决方案
面临汽车3D动画渲染挑战?选择正确的云渲染服务至关重要。探索最佳解决方案,优化渲染效率,快速呈现逼真动画。 汽车3d动画渲染选择哪个? 对于汽车3D动画渲染,选择哪个渲染器取决于你的项目需求、预算和期望的效果。Ble…...
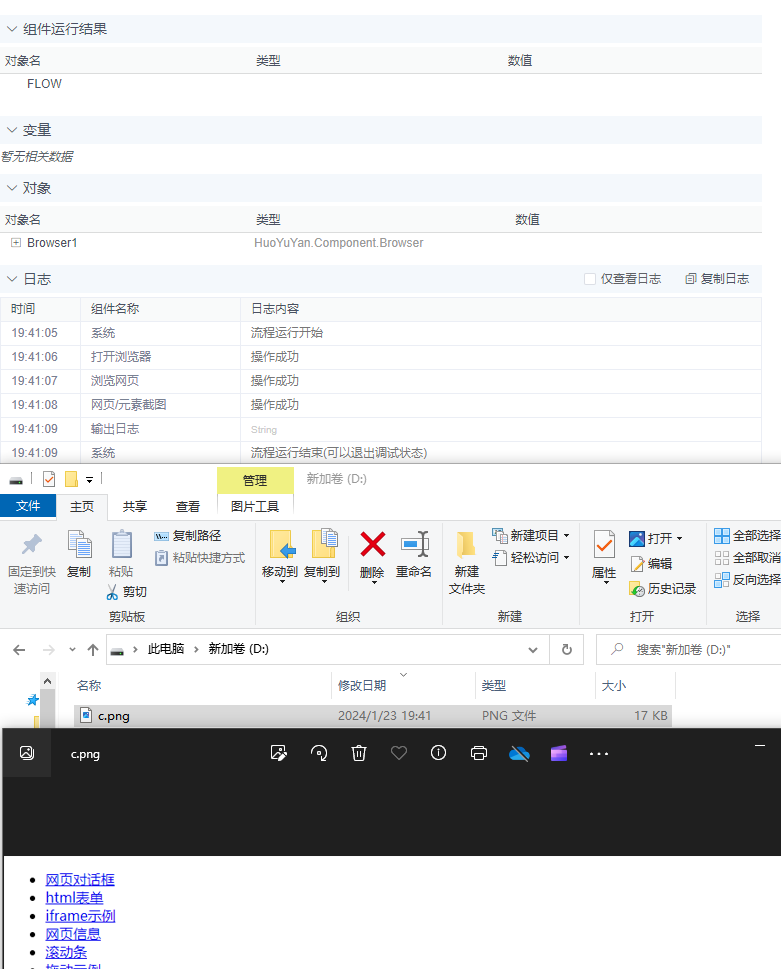
火语言RPA流程组件介绍--网页/元素截图
🚩【组件功能】:对整个网页、可见区域或者某个元素进行截图 ,保存至指定文件夹,仅适用于内置浏览器 配置预览 配置说明 截图类型 整个网页/可见区域/元素截图 目标元素 支持T或# 通过自动捕获工具捕获(选择元素工具使用方法)…...

VSCode编程配置再次总结
VScode 中C++编程再次总结 0.简介 1.配置总结 1.1 launch jsion文件 launch.json文件主要用于运行和调试的配置,具有程序启动调试功能。launch.json文件会启用tasks.json的任务,并能实现调试功能。 左侧任务栏的第四个选项运行和调试,点击创建launch.json {"conf…...

银行管理系统
摘 要 伴随着信息技术与互联网技术的不断发展,人们进到了一个新的信息化时代,传统管理技术性没法高效率、容易地管理信息内容。为了实现时代的发展必须,提升管理高效率,各种各样管理管理体系应时而生,各个领域陆续进到…...

极狐GitLab 17.4 重点功能解读【四】
GitLab 是一个全球知名的一体化 DevOps 平台,很多人都通过私有化部署 GitLab 来进行源代码托管。极狐GitLab 是 GitLab 在中国的发行版,专门为中国程序员服务。可以一键式部署极狐GitLab。 学习极狐GitLab 的相关资料: 极狐GitLab 官网极狐…...

keil 使用UTF8格式的文件,但是printf打印中文已经是乱码的问题
文件格式是UTF8 无bom格式 打开文件显示是正常的 编译器选择的是ANSI格式 编译依旧产生警告 在 Project → Options → C/C → Misc Controls 添加 --no-multibyte-chars就可以解决; 但是ai给我这个方案,我还没有尝试 –wide-chars 示例是这样的 wchar_…...

终极指南:如何使用Etcher安全快速烧录系统镜像到SD卡和USB驱动器
终极指南:如何使用Etcher安全快速烧录系统镜像到SD卡和USB驱动器 【免费下载链接】etcher Flash OS images to SD cards & USB drives, safely and easily. 项目地址: https://gitcode.com/GitHub_Trending/et/etcher Etcher(BalenaEtcher&am…...

3分钟掌握Windows安装APK:告别复杂模拟器的终极方案
3分钟掌握Windows安装APK:告别复杂模拟器的终极方案 【免费下载链接】APK-Installer An Android Application Installer for Windows 项目地址: https://gitcode.com/GitHub_Trending/ap/APK-Installer 你是否曾经遇到过这样的场景?同事发来一个实…...

ZeroAPI:基于订阅与任务感知的AI模型智能路由插件设计与实践
1. 项目概述:ZeroAPI,一个为AI订阅服务而生的智能路由插件如果你和我一样,手头订阅了不止一个AI服务——比如OpenAI的ChatGPT Plus、月之暗面的Kimi、智谱AI的GLM,可能还有MiniMax或者通义千问——那你一定遇到过这个烦恼…...

数据分析进阶——【连载 5/9】《Power BI数据分析与可视化案例教程》项目5 数据建模
Power BI 数据建模教程|推介总结 适应人群:数据分析师、业务分析人员、财务 / 运营 / 销售岗、高校学生、企业内训学员、Power BI 进阶学习者。 重要性总结:本文档是 Power BI 数据建模核心实操教程,系统讲解数据建模全流程&#…...

BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼![特殊字符]
BG3ModManager:博德之门3模组管理终极指南,告别模组冲突烦恼!🚀 【免费下载链接】BG3ModManager A mod manager for Baldurs Gate 3. This is the only official source! 项目地址: https://gitcode.com/gh_mirrors/bg/BG3ModMa…...

Cursor Free VIP:如何一键突破AI编程助手使用限制?
Cursor Free VIP:如何一键突破AI编程助手使用限制? 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached …...

使用 llama.cpp + MTP 分支实现 1.5 倍 Token 输出加速实战指南
使用 llama.cpp MTP 分支实现 1.5 倍 Token 输出加速实战指南 摘要:本文详细介绍如何通过 llama.cpp 的 MTP(Multi-Token Prediction)PR 分支,配合 Qwen3.6-27B-MTP GGUF 量化模型,实现推理时每秒输出 token 数量翻倍…...

解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 解决 Claude Code 频繁封号问题之转向 Taotoken 稳定服务 对于依赖 Claude Code 进行开发的工程师而言,账号访问权限的…...

python网上书店系统vue
目录技术栈选择前端模块划分后端API设计关键实现细节开发流程示例代码片段项目技术支持源码获取详细视频演示 :文章底部获取博主联系方式!同行可合作技术栈选择 前端采用Vue 3(Composition API) TypeScript Vite构建工具&#…...