如何使用 Python 读取数据量庞大的 excel 文件
使用 pandas.read_excel 读取大文件时,的确会遇到性能瓶颈,特别是对于10万行20列这种规模的 .xlsx 文件,常规的 pandas 方法可能会比较慢。
要提高读取速度,关键是找到更高效的方式处理 Excel 文件,特别是在 Python 的生态圈中,已经有多个技术可以帮助解决这个问题。
一种办法是使用 openpyxl 直接处理 Excel 文件,结合 pandas 来读取数据。这可以让我们在处理数据时获得更大的灵活性,并通过分块读取文件来提高效率。

官网地址:
https://openpyxl.readthedocs.io/en/stable/
另外,还可以选择 pyxlsb 这个库,它可以更快速地处理 .xlsb 格式的文件,比传统的 .xlsx 格式快很多。

官网地址:https://pypi.org/project/pyxlsb/
如果可能的话,将文件转为 .csv 格式读取也会显著提高性能,因为 CSV 文件是纯文本格式,相较于 .xlsx 的结构化存储,读取会更加高效。
分析 pandas.read_excel 的性能问题
在实际中,pandas.read_excel 本身的性能瓶颈主要来自于两个方面:数据的解析与文件的格式。.xlsx 是一种基于 XML 的文件格式,因此在读取时需要解析 XML,这本身就是一个比较慢的过程。尤其当文件较大时,解析 XML 的时间会大幅增加。

为了解决这个问题,可以考虑以下几种优化策略:
-
使用不同的引擎:
pandas支持多种 Excel 解析引擎,比如openpyxl和xlrd。根据情况选择合适的引擎,可能会改善读取性能。 -
分块读取:可以通过逐步读取文件的方式,避免一次性将整个文件加载到内存中。这可以显著减少内存占用,并提高读取的稳定性。
-
选择合适的文件格式:如果文件格式不是必须的,可以将
.xlsx文件转为.csv文件,这样可以使用更高效的读取方法。
优化方案 1:使用 openpyxl 和 pandas
openpyxl 是 pandas 内置支持的引擎之一,但它的读取速度较慢。在这种情况下,可以手动使用 openpyxl 读取数据,然后将其转换为 pandas 的 DataFrame。
代码示例
import pandas as pd
from openpyxl import load_workbook# 读取xlsx文件的路径
file_path = "your_large_file.xlsx"# 使用 openpyxl 直接加载工作簿
wb = load_workbook(filename=file_path, read_only=True)
sheet = wb.active# 使用生成器按行读取数据,避免一次性加载所有数据
data = []
for row in sheet.iter_rows(values_only=True):data.append(row)# 转换为 pandas DataFrame
df = pd.DataFrame(data[1:], columns=data[0])# 打印读取的数据
print(df.head())
通过这种方法,我们避免了一次性将整个文件加载到内存中,而是使用了 openpyxl 的 iter_rows 方法逐行读取文件内容。这样,即使文件非常大,也能有效减轻内存负担。
优化方案 2:使用 pyxlsb 读取 .xlsb 文件
.xlsb 是二进制的 Excel 文件格式,它比 .xlsx 文件格式更为高效,尤其是在处理大文件时,可以显著减少读取时间。pyxlsb 库是一个专门用于读取 .xlsb 文件的高效库,配合 pandas 可以更快地读取数据。
代码示例
import pandas as pd
from pyxlsb import open_workbook# 将 .xlsx 文件转换为 .xlsb 格式后使用此方法读取
file_path = "your_large_file.xlsb"with open_workbook(file_path) as wb:with wb.get_sheet(1) as sheet:data = []for row in sheet.rows():data.append([item.v for item in row])df = pd.DataFrame(data[1:], columns=data[0])
print(df.head())
使用 pyxlsb 可以有效加快 Excel 文件的读取速度,特别是在处理非常大的文件时,这个方法比 pandas.read_excel 提供的默认引擎快很多。不过需要注意的是,这种方法仅适用于 .xlsb 格式文件。
优化方案 3:使用 dask 分块处理大数据
dask 是一个支持并行计算的 Python 库,它可以用来处理大型数据集。如果我们遇到的数据文件过大,dask 提供了类似 pandas 的 API,但它会将大文件分块处理,避免一次性占用大量内存。
代码示例
import dask.dataframe as dd# 使用 dask 读取大文件
file_path = "your_large_file.xlsx"
df = dd.read_excel(file_path)# 使用 dask 处理数据
print(df.head())
dask 是一个非常强大的工具,它不仅支持分布式计算,还可以在多核环境下加快处理速度。通过将文件拆分成小块并行处理,dask 能够高效地应对大规模数据集的读取和计算。
优化方案 4:将文件转换为 CSV 格式
如果文件的格式不是必须的,那么将 .xlsx 文件转换为 .csv 格式是一种直接且有效的方式。.csv 格式相较于 .xlsx 没有复杂的 XML 结构,因此读取速度会快得多。转换后可以直接使用 pandas.read_csv 来读取数据,速度会比 read_excel 快很多。
代码示例
import pandas as pd# 假设已经将文件转换为 CSV 格式
file_path = "your_large_file.csv"# 使用 pandas 读取 CSV 文件
df = pd.read_csv(file_path)# 打印前几行数据
print(df.head())
通过这种方式,能够显著提高数据读取速度,因为 .csv 格式的文件是纯文本,不需要复杂的解析过程。
其他可能的优化策略
除了前面提到的几种方法,还有一些其他技术可以用来进一步优化 Excel 文件的读取速度:
-
并行读取:如果系统支持,可以将 Excel 文件按工作表或其他分块标准进行拆分,使用并行处理技术(如
multiprocessing)同时读取多个小文件。 -
数据格式优化:如果文件的数据结构允许,转换为 Parquet 或 HDF5 格式,这些格式在大数据处理方面的性能往往优于 Excel 和 CSV。
-
增加内存或硬件支持:在某些极端情况下,硬件资源不足也可能是瓶颈。增加内存或使用更快的硬盘(如 SSD)可以提高整体数据读取的性能。
总结
通过上述几种方法,可以大幅优化使用 Python 读取大型 Excel 文件的性能。openpyxl 适用于灵活处理 .xlsx 文件,pyxlsb 则是处理 .xlsb 文件的利器,而使用 dask 可以分块读取并行处理大数据集。此外,如果可以转换文件格式,使用 .csv 是提升读取速度的有效途径。
不同的方案适用于不同的场景,开发者可以根据具体需求选择最合适的解决方案。例如,当文件格式无法改变时,openpyxl 结合 pandas 是一个相对平衡的选择,而在文件格式灵活的情况下,将 .xlsx 转为 .csv 并使用 pandas.read_csv 则能最大化提高读取性能。
相关文章:
如何使用 Python 读取数据量庞大的 excel 文件
使用 pandas.read_excel 读取大文件时,的确会遇到性能瓶颈,特别是对于10万行20列这种规模的 .xlsx 文件,常规的 pandas 方法可能会比较慢。 要提高读取速度,关键是找到更高效的方式处理 Excel 文件,特别是在 Python 的…...

c语言200例 067
大家好,欢迎来到无限大的频道 今天给大家带来的是c语言200例 题目要求: 设计一个共用体类型,使其成员包含多种数据类型,根据不同的数据类型,输出不同的结果 要设计一个共用体(union)类型&…...

RabbitMQ的高级特性-死信队列
死信(dead message) 简单理解就是因为种种原因, ⽆法被消费的信息, 就是死信. 有死信, ⾃然就有死信队列. 当消息在⼀个队列中变成死信之后,它能被重新被发送到另⼀个交换器 中,这个交换器就是DLX( Dead Letter Exchange ), 绑定DLX的队列, 就称为死信队…...

Python 复制PDF中的页面
操作PDF文档时,复制其中的指定页面可以帮助我们从PDF文件中提取特定信息,如文本、图表或数据等,以便在其他文档中使用。复制PDF页面也可以实现在不同文件中提取页面,以创建一个新的综合文档。 本文将介绍如何使用Python 在同一文档…...

Sql Developer日期显示格式设置
默认时间格式显示 设置时间格式:工具->首选项->数据库->NLS->日期格式: DD-MON-RR 修改为: YYYY-MM-DD HH24:MI:SS 设置完格式显示:...

IP地址与智能家居能够碰撞出什么样的火花呢?
感应灯、远程遥控空调,自动感应窗帘——智能家居已经在正逐步走入我们的生活,为我们带来前所未有的便捷与舒适体验。而在这一进程中,IP地址又能够与智能家居碰撞出什么样的火花呢? 一、IP地址:智能家居的连接基石 智…...

人工智能技术在电磁场与微波技术专业的应用
在人工智能与计算电磁学的融合背景下,电磁学的研究和应用正在经历一场革命。计算电磁 学是研究电磁场和电磁波在不同介质中的传播、散射和辐射等问题的学科,它在通信、雷达、无 线能量传输等领域具有广泛的应用。随着人工智能技术的发展,这一…...

The First项目报告:探索Yield Guild Games运行机制与发展潜力
在探索数字娱乐与金融融合的全新疆域中,GameFi(游戏化金融)以其独特的魅力引领了一场前所未有的变革。这一创新概念,最初由MixMarvel的CSO Mary Ma在2019年底乌镇大会的远见卓识中首次提出,它将去中心化金融࿰…...

完成UI界面的绘制
绘制UI 接上文,在Order90Canvas下创建Image子物体,图片资源ui_fish_lv1,设置锚点(CountdownPanelImg同理),命名为LvPanelImg,创建Text子物体,边框宽高各50, ,重名为LvT…...

iot网关是什么?iot网关在工业领域的应用-天拓四方
一、IoT网关的定义 IoT网关,即物联网网关,是物联网(IoT)系统中的重要组成部分。它主要实现感知网络与通信网络,以及不同类型感知网络之间的协议转换,既能够支持广域互联,也能满足局域互联的需求…...
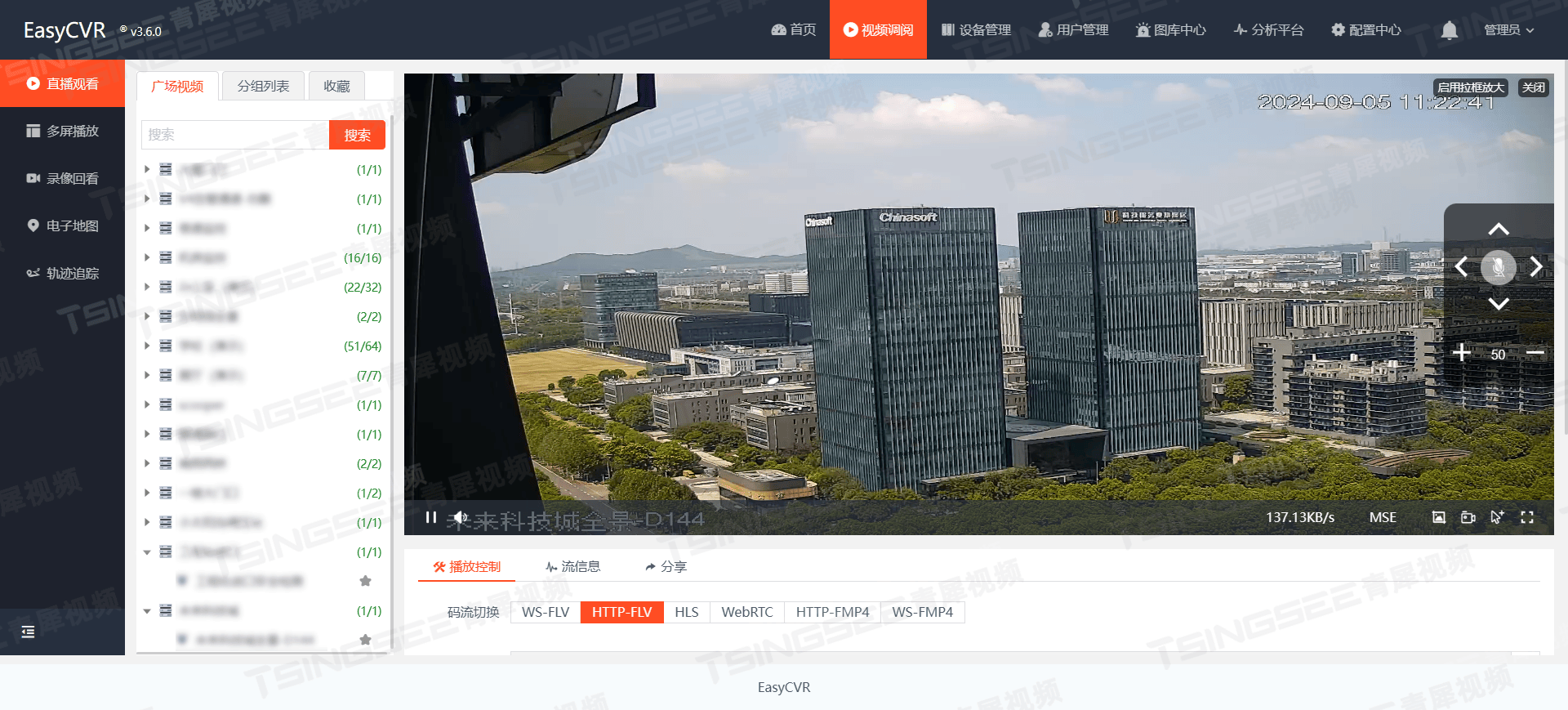
从碎片到整合:EasyCVR平台如何重塑城市感知系统的视频数据生态
随着城市化进程的加速,城市感知系统作为智慧城市的重要组成部分,正逐步成为提升城市管理效率、保障公共安全、优化资源配置的关键手段。EasyCVR视频汇聚融合平台,凭借其强大的数据整合、智能分析与远程监控能力,在城市感知系统中扮…...

java socket bio 改造为 netty nio
公司早些时候接入一款健康监测设备,由于业务原因近日把端口暴露在公网后,每当被恶意连接时系统会创建大量线程,在排查问题是发现是使用了厂家提供的服务端demo代码,在代码中使用的是java 原生socket,在发现连接后使用独…...

进程、线程、协程详解:并发编程的三大武器
在现代计算机科学中,并发编程是一个核心概念,而进程、线程和协程是实现并发的三种主要方式。本文将深入探讨这三种概念,分析它们的特点、优缺点,以及适用场景。 1. 进程 (Process) 1.1 定义 进程是计算机中的程序关于某数据集合上的一次运行活动,是系统进行资源分配和调度的…...

探索5 大 Node.js 功能
目录 单线程 Node.js 工作线程【Worker Threads】 Node.js 进程 进程缺点 工作线程 注意 集群进程模块【Cluster Process Module】 内部发生了什么? 为什么要使用集群 注意: 应用场景: 内置 HTTP/2 支持 这个 HTTP/2 是什么&…...

EZUIKit.js萤石云vue项目使用
EZUIKit.js 是萤石云(Ezviz)提供的一款用于Web端的视频播放和控制的JavaScript库。它允许开发者在网页上轻松集成视频监控、对讲、录像回放等功能,适用于安防监控、智能家居等场景。通过EZUIKit.js,你可以方便地访问萤石云平台上的…...

【Linux】磁盘分区挂载网络配置进程【更详细,带实操】
Linux全套讲解系列,参考视频-B站韩顺平,本文的讲解更为详细 目录 一、磁盘分区挂载 1、磁盘分区机制 2、增加磁盘应用实例 3、磁盘情况查询 4、磁盘实用指令 二、网络配置 1、NAT网络原理图 2、网络配置指令 3、网络配置实例 4、主机名和host…...

Java 为什么使用 UTF-16 而不是更节省内存的 UTF-8?
Java 选择 UTF-16 编码而不是更节省内存的 UTF-8 这一决定,涉及多个层面的设计权衡,包括历史原因、虚拟机(JVM)实现的复杂度、性能和字符处理的一致性。要理解这个问题,我们需要从 Java 语言的设计初衷、JVM 的工作机制…...

损失函数篇 | YOLOv10 引入 Inner-IoU 基于辅助边框的IoU损失
作者导读:Inter-IoU:基于辅助边框的IoU损失 论文地址:https://arxiv.org/abs/2311.02877 作者视频解读:https://www.bilibili.com 开源代码地址:https://github.com/malagoutou/Inner-IoU...

夹耳开放式耳机好用吗?一篇文章告诉你答案,附上挑选避坑小知识
夹耳开放式耳机作为音频领域的新兴产品,正逐渐走入大众视野。其独特的设计和功能引发了广泛关注与讨论。究竟夹耳开放式耳机好用吗?在这篇文章中,我们将从专业角度深入剖析他的各个方面。同时,还会为你提供详细的挑选避坑小知识&a…...

WebSocket 2024/9/30
WebSocket是基于TCP的一种新的网络协议。它实现了浏览器与服务器双工通信——浏览器和服务器只需要完成一次握手,两者之间就可以创建持久性的连接,并进行双向数据传输。 与HTTP协议的区别 实现...

微型环境传感器技术:PM2.5与VOC检测的突破与应用
1. 个人空气质量监测的技术革命在深圳的一个典型工作日早晨,张工程师像往常一样准备出门上班。他习惯性地查看手机上的空气质量指数,发现室外PM2.5数值高达85μg/m(超过WHO安全标准3倍以上)。犹豫片刻后,他戴上了N95口…...

为什么92%的AI团队Serverless化失败?奇点大会披露的4个反直觉架构断点与实时熔断方案
更多请点击: https://intelliparadigm.com 第一章:AI原生Serverless实践:2026奇点智能技术大会无服务器架构 在2026奇点智能技术大会上,AI原生Serverless成为核心范式——它不再将模型推理简单托管于函数即服务(FaaS&…...

为AI智能体注入人类洞察:用户研究技能全链路实践指南
1. 项目概述:为AI智能体注入“人类洞察层”如果你正在构建或使用AI智能体,无论是Claude Code、Cursor还是其他基于代码的智能助手,你可能会发现一个核心瓶颈:这些智能体虽然能处理代码、分析数据,但在涉及产品决策、功…...

第1篇:认识Go——我的第一个程序 Go中文编程
第1篇:认识Go——我的第一个程序**作者:**中文编程倡导者—— 李金雨 联系方式: wbtm2718qq.com目标:让你成功运行第一个Go程序,建立学习信心! 预计时间:2课时(90分钟) 难…...

基于LLM的Python脚本自我进化:构建AI驱动的代码优化框架
1. 项目概述:当Python脚本学会自我进化几年前,如果有人告诉我,我写的Python脚本能在我喝咖啡的时候自己给自己“打补丁”、优化逻辑,我肯定会觉得这是科幻小说里的情节。但今天,这已经是我日常工作流的一部分。这个项目…...
)
别再全网搜了!企业微信后台三步找到你的CorpID和Secret(附AccessToken一键生成工具)
企业微信开发实战:3分钟获取CorpID与Secret的终极指南 第一次接触企业微信API开发时,最让人头疼的莫过于找不到CorpID和Secret这两个关键凭证。官方文档信息分散,后台界面又不够直观,很多开发者在这个环节浪费了大量时间。本文将…...

一键式自动化工具OneClickCopaw:从Shell脚本到CI/CD的部署实践
1. 项目概述与核心价值最近在折腾一些自动化脚本时,发现了一个挺有意思的项目,叫iwanglei1/OneClickCopaw。光看名字,你可能会有点懵,“Copaw”是什么?其实,这是一个典型的“一键式”自动化工具,…...

2025届学术党必备的六大AI辅助论文神器解析与推荐
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 该AI开题报告工具,针对硕博研究生,针对本科毕业论文创作者࿰…...

开源机械爪技术全解析:从结构设计到ROS集成开发指南
1. 项目概述与核心价值如果你是一名开发者,尤其是在开源社区里摸爬滚打过一阵子,那你肯定对“awesome-xxx”这类项目不陌生。它们通常是一个精心整理的列表,汇聚了某个特定技术领域或工具生态下的优质资源。今天要聊的这个fundgao/awesome-op…...

别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神
别再让代码异味溜走:手把手教你用SonarQube为团队搭建代码质量守护神 当项目规模从几千行扩展到几十万行代码时,技术债务就像房间里的大象——人人都知道存在,却少有人主动清理。去年我们团队在重构一个核心模块时,发现其中隐藏的…...