word2vector训练数据集整理(代码实现)

import math
import os
import random
import torch
import dltools
from matplotlib import pyplot as plt#读取数据集
def read_ptb():"""将PTB数据集加载到文本行的列表中"""with open('./ptb/ptb.train.txt') as f:raw_text = f.read()return [line.split() for line in raw_text.split('\n')]sentences = read_ptb()
print(f'# sentences数:{len(sentences)}')# sentences数:42069
#构建词表,并把频次低于10的词元替换为<unk>
vocab = dltools.Vocab(sentences, min_freq=10)
print(f'# vocab_size: {len(vocab)}')#向下采样
def subsample(sentences, vocab):#排除未知词元‘<unk>’,对sentences进行处理sentences = [[token for token in line if vocab[token] != vocab.unk] for line in sentences]#对排除unk的sentences进行tokens计数 (未去重)counter = dltools.count_corpus(sentences)#聚合num_tokens = sum(counter.values())#若在下采样期间保留词元, 则返回True def keep(token):return (random.uniform(0, 1) < math.sqrt(1e-4 / (counter[token] / num_tokens)))#降低冠词等无意义词的频次, 词频低越容易保留return ([[token for token in line if keep(token)] for line in sentences], counter) subsampled, counter = subsample(sentences, vocab)#画出下采样之后的图, 采取下采样前后的20条数据
before = [len(x) for x in sentences[:20]]
after = [len(x) for x in subsampled[:20]]
x = range(len(before))
plt.bar(x, height=before, width=0.4, alpha=0.8, color='red', label='before')
#[i + 0.4 for i in x] 是X轴刻度
plt.bar([i + 0.4 for i in x], height=after, width=0.4, color='green', label='after')
plt.xlabel('tokens per sentences')
plt.ylabel('count')
plt.legend(['before', 'after'])
plt.show()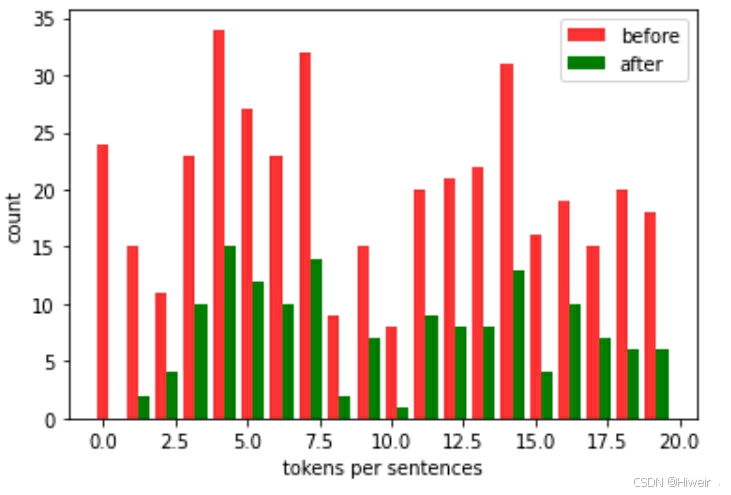
def compare_counts(token):return (f'"{token}"的数量:' f'之前={sum([l.count(token) for l in sentences])}, ' f'之后={sum([l.count(token) for l in subsampled])}')compare_counts('the')'"the"的数量:之前=50770, 之后=2000'
compare_counts('publishing')'"publishing"的数量:之前=64, 之后=64'
#将词元映射到他们在语料库中的索引
corpus = [vocab[line] for line in subsampled]
corpus[:3][[], [71, 2115], [5277, 3054, 1580, 95]]
#中心词和上下文词的提取
def get_centers_and_contetxs(corpus, max_window_size):"""返回skip_gram模型中的中心词和上下文词"""centers, contexts = [], []for line in corpus:#要形成“中心词——上下文词对”, 每个句子至少需要有2个词if len(line) < 2:continuecenters += line #把满足条件的line放于中心词列表中for idx, i in enumerate(range(len(line))): #上下文窗口的中间token的索引为iwindow_size = random.randint(1, max_window_size)print('中心词 {} 的窗口大小:{}'.format(idx, window_size))indices = list(range(max(0, i - window_size), min(len(line), i + window_size + 1)))#从上下文词中排除中心词indices.remove(i)contexts.append([line[x] for x in indices])return centers, contexts#假设数据
tiny_dataset = [list(range(7)), list(range(7,10))]
print('数据集', tiny_dataset)
#表示解压函数,用于将打包的元组解压回原来的序列
for center, context in zip(*get_centers_and_contetxs(tiny_dataset, 2)):print('中心词:',center, '的上下文词是:', context)数据集 [[0, 1, 2, 3, 4, 5, 6], [7, 8, 9]] 中心词 0 的窗口大小:1 中心词 1 的窗口大小:2 中心词 2 的窗口大小:2 中心词 3 的窗口大小:1 中心词 4 的窗口大小:2 中心词 5 的窗口大小:2 中心词 6 的窗口大小:2 中心词 0 的窗口大小:2 中心词 1 的窗口大小:1 中心词 2 的窗口大小:1 中心词 0 的上下文词是 [1] 中心词 1 的上下文词是 [0, 2, 3] 中心词 2 的上下文词是 [0, 1, 3, 4] 中心词 3 的上下文词是 [2, 4] 中心词 4 的上下文词是 [2, 3, 5, 6] 中心词 5 的上下文词是 [3, 4, 6] 中心词 6 的上下文词是 [4, 5] 中心词 7 的上下文词是 [8, 9] 中心词 8 的上下文词是 [7, 9] 中心词 9 的上下文词是 [8]
#在PTB上进行中心词和背景词提取
#max_window_size=5 业界常用到的数值,效果比较好
all_centers, all_contexts = get_centers_and_contetxs(corpus, 5)
'“中心词-上下文词对”的数量:{}'.format( sum([len(contexts) for contexts in all_contexts]))'“中心词-上下文词对”的数量:1499666'
#负采样_按权重抽取
class RandomGenerator:"""根据n个采样权重在{1,2,,3,...n}中随机抽取"""def __init__(self, sampling_weights):#Exclude 排除self.population = list(range(1, len(sampling_weights) + 1)) #对采样数据的编号self.sampling_weights = sampling_weightsself.candidates = [] #采样结果self.i = 0def draw(self):if self.i == len(self.candidates):#缓存k个随机采样的结果 # population:集群。 weights:相对权重。 cum_weights:累加权重。 k:选取次数self.candidates = random.choices(self.population, self.sampling_weights, k=10000) #k最大值=10000(采样数量)self.i = 0self.i += 1return self.candidates[self.i - 1]#假设数据验证
generator = RandomGenerator([2, 3, 4])
[generator.draw() for _ in range(10)][2, 1, 1, 2, 1, 1, 3, 2, 3, 2]
#返回负采样中的噪声词
def get_negatives(all_contetxs, vocab, counter, K):#索引为1,2,....(索引0是此表中排除的未知标记)sampling_weights = [counter[vocab.to_tokens(i)]**0.75 for i in range(1, len(vocab))]all_negatives, generator = [], RandomGenerator(sampling_weights)for contexts in all_contetxs: #遍历背景词negatives = []while len(negatives) < len(contexts) * K:neg = generator.draw()#噪声词不能是上下文词if neg not in contexts:negatives.append(neg)all_negatives.append(negatives)return all_negativesall_negatives = get_negatives(all_contexts, vocab, counter, 5)# 小批量操作
def batchify(data):"""返回带有负采样的跳元模型的小批量样本"""max_len = max(len(c) + len(n) for _, c, n in data)centers, contexts_negatives, masks, labels = [], [], [], []for center, context, negative in data:cur_len = len(context) + len(negative)centers += [center]contexts_negatives += \[context + negative + [0] * (max_len - cur_len)]masks += [[1] * cur_len + [0] * (max_len - cur_len)]labels += [[1] * len(context) + [0] * (max_len - len(context))]return (torch.tensor(centers).reshape((-1, 1)), torch.tensor(contexts_negatives), torch.tensor(masks), torch.tensor(labels))#小批量的例子
x_1 = (1, [2, 2], [3, 3, 3, 3])
x_2 = (1, [2, 2, 2], [3, 3])
batch = batchify((x_1, x_2))names = ['centers', 'contexts_negative', 'masks', 'labels']
for name, data in zip(names, batch):print(name, '=', data)centers = tensor([[1],[1]]) contexts_negative = tensor([[2, 2, 3, 3, 3, 3],[2, 2, 2, 3, 3, 0]]) masks = tensor([[1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 0]]) labels = tensor([[1, 1, 0, 0, 0, 0],[1, 1, 1, 0, 0, 0]])
#整合后的数据加载处理模块
def load_data_ptb(batch_size, max_window_size, num_noise_words):"""下载PTB数据集, 然后将其加载到内存中"""#加载PTB数据集sentences = read_ptb()#获取词汇表vocab = dltools.Vocab(sentences, min_freq=10)#下采样subsampled, counter = subsample(sentences, vocab)#语料库corpus = [vocab[line] for line in subsampled]#获取中心词与背景词all_centers, all_contexts = get_centers_and_contetxs(corpus, max_window_size)#获取噪声词get_negatives(all_contetxs, vocab, counter, num_noise_words)class PTBDataset(torch.utils.data.Dataset):def __init__(self, centers, contexts, negatives):assert len(centers) == len(contexts) == len(negatives)self.centers = centersself.contexts = contextsself.negatives = negativesdef __getitem__(self, index):return (self.centers[index], self.contexts[index],self.negatives[index])def __len__(self):return len(self.centers)dataset = PTBDataset(all_centers, all_contexts, all_negatives)data_iter = torch.utils.data.DataLoader(dataset, batch_size, shuffle=True, collate_fn = batchify)return data_iter, vocabdata_iter, vocab = load_data_ptb(5, 5, 5)
for batch in data_iter:for name, data in zip(names, batch):print(name, 'shape:', data.shape)breakcenters shape: torch.Size([5, 1]) contexts_negatives shape: torch.Size([5, 48]) masks shape: torch.Size([5, 48]) labels shape: torch.Size([5, 48])
batch(tensor([[1259],[ 627],[5679],[ 3],[ 960]]),tensor([[1983, 1136, 1186, 15, 3216, 5351, 512, 321, 2208, 1396, 60, 782,63, 929, 149, 105, 305, 7, 74, 11, 1530, 1, 5893, 2668,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[ 298, 1960, 1098, 1288, 6, 1689, 4808, 981, 2040, 3887, 385, 59,2167, 4424, 91, 4159, 65, 1271, 3621, 6020, 585, 1426, 5097, 335,18, 770, 5317, 1408, 5828, 3321, 836, 529, 1772, 365, 6718, 269,101, 209, 1450, 1, 47, 834, 8, 2, 979, 28, 4029, 471],[6034, 2, 4028, 829, 1042, 5340, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[ 678, 582, 5033, 4220, 959, 280, 124, 397, 211, 787, 2795, 383,18, 16, 1293, 1212, 2149, 2627, 623, 8, 4467, 155, 3932, 1447,5595, 27, 15, 81, 283, 2631, 410, 938, 4, 344, 5204, 233,149, 2, 4933, 5675, 62, 182, 18, 1186, 227, 2429, 2349, 31],[ 128, 1332, 3790, 1370, 950, 119, 1369, 1328, 1007, 2831, 782, 374,723, 13, 14, 76, 618, 1, 821, 143, 2317, 5730, 978, 753,839, 2055, 160, 12, 377, 4, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),tensor([[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1],[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]),tensor([[1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],[1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]))

相关文章:
word2vector训练数据集整理(代码实现)
import math import os import random import torch import dltools from matplotlib import pyplot as plt #读取数据集 def read_ptb():"""将PTB数据集加载到文本行的列表中"""with open(./ptb/ptb.train.txt) as f:raw_text f.read()return…...

无心上班,只想为祖国庆生?让ChatGPT帮你搞定工作!
国庆假期临近,大家的心早已飞向诗和远方了吧。 然而,现实总是无情地将我们拉回到堆积如山的工作任务上:紧急报告的截止日期就在眼前,复杂的项目策划还未动笔,客户的定制需求迫在眉睫。每年的这个时候,如何…...

【Python】YOLO牛刀小试:快速实现视频物体检测
YOLO牛刀小试:快速实现视频物体检测 在深度学习的众多应用中,物体检测是一个热门且重要的领域。YOLO(You Only Look Once)系列模型以其快速和高效的特点,成为了物体检测的首选之一。本文将介绍如何使用YOLOv8模型进行…...

Vscode超好看的渐变主题插件
样式效果: 插件使用方法: 然后重启,之后会显示vccode损坏,不用理会,因为这个插件是更改了应用内部代码,直接不再显示即可。...

OceanBase技术解析:自适应分布式下压技术
在《OceanBase 数据库源码解析》这本书中,关于SQL执行器的深入剖析相对较少,因此,希望增添一些实用且详尽的补充内容。 上一篇博客《 OceanBase技术解析: 执行器中的自适应技术》中,已初步介绍了执行器中几项典型的自适…...

Firebase和JavaScript创建Postback Link逻辑
Firebase是一个提供后端即服务(BaaS)的平台,它允许开发者快速构建应用程序而无需管理服务器。Firebase不直接提供生成Postback Link的功能,但您可以使用Firebase的功能来构建和管理URL,然后在客户端使用这些URL来实现Postback。 以下是如何使用Firebase和JavaScript来创建…...

docker配置daemon.json文件
报错 :Get "https://registry-1.docker.io/v2/": net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers) 解决方法 配置加速地址 vim /etc/docker/daemon.json添加以下内容 {"registry-mirro…...

【08】纯血鸿蒙HarmonyOS NEXT星河版开发0基础学习笔记-Scroll容器与Tabs组件
序言: 本文详细讲解了关于我们在页面上经常看到的可滚动页面和导航栏在鸿蒙开发中如何用Scroll和Tabs组件实现,介绍了Scroll和Tabs的基本用法与属性。 笔者也是跟着B站黑马的课程一步步学习,学习的过程中添加部分自己的想法整理为笔记分享出…...

苏州 数字化科技展厅展馆-「世岩科技」一站式服务商
数字化科技展厅展馆设计施工是一个综合性强、技术要求高的项目,涉及到众多方面的要点。以下是对数字化科技展厅展馆设计施工要点的详细分析: 一、明确目标与定位 在设计之初,必须明确展厅的目标和定位。这包括确定展厅的主题、目标受众、展…...

音频搜索公司 DeepGram,定位语音搜索AI大脑,DeepGram想做“音频版”
1. 亦仁分享 DeepGram 成立于 2015 年,位于美国山景城,是一家基于 AI 技术的音频搜索引擎公司。运用机器学习进行语音识别、搜寻重要时刻并对音频和视频进行分类,帮助用户快速索引和浏览音频和视频文件,包括电话语音、会议语音、…...

基于php的在线租房管理系统
作者:计算机学姐 开发技术:SpringBoot、SSM、Vue、MySQL、JSP、ElementUI、Python、小程序等,“文末源码”。 专栏推荐:前后端分离项目源码、SpringBoot项目源码、Vue项目源码、SSM项目源码 精品专栏:Java精选实战项目…...

如何评价 Python 语言的运行速度
Python 作为一门编程语言,其运行速度一直是业界讨论的焦点。它的简洁语法和广泛的应用使得它在开发过程中非常高效,然而,运行速度与一些更底层的编程语言相比存在一定的劣势。这是否是由于 Python 语法的简洁性所带来的代价?我们可…...

Tomcat系列漏洞复现
CVE-2017-12615——Tomcat put⽅法任意⽂件写⼊漏洞 漏洞描述 当 Tomcat运⾏在Windows操作系统时,且启⽤了HTTP PUT请求⽅法(例如,将 readonly初始化参数由默认值设置为false),攻击者将有可能可通过精⼼构造的攻击请求…...

K8S拉取本地docker中registry的镜像报错:http: server gave HTTP response to HTTPS client
本地部署了一个K8S集群,但是worker1和worker2的docker无法拉取外面的镜像,docker的daemon.json也配置了,无法下载,于是在master部署了一个docker registry。 但是pod还是无法拉取registry的镜像并报错。 我这里使用的是container…...

Leetcode 1235. 规划兼职工作
1.题目基本信息 1.1.题目描述 你打算利用空闲时间来做兼职工作赚些零花钱。 这里有 n 份兼职工作,每份工作预计从 startTime[i] 开始到 endTime[i] 结束,报酬为 profit[i]。 给你一份兼职工作表,包含开始时间 startTime,结束时…...

LeetCode 2535.数组元素和与数字和的绝对差:模拟
【LetMeFly】2535.数组元素和与数字和的绝对差:模拟 力扣题目链接:https://leetcode.cn/problems/difference-between-element-sum-and-digit-sum-of-an-array/ 给你一个正整数数组 nums 。 元素和 是 nums 中的所有元素相加求和。数字和 是 nums 中每…...

SpringCloud-pom创建Eureka
<?xml version"1.0" encoding"UTF-8"?> <project xmlns"http://maven.apache.org/POM/4.0.0" xmlns:xsi"http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation"http://maven.apache.org/POM/4.0.0 https://…...

动态规划算法专题(一):斐波那契数列模型
目录 1、动态规划简介 2、算法实战应用【leetcode】 2.1 题一:第N个泰波那契数 2.1.1 算法原理 2.1.2 算法代码 2.1.3 空间优化原理——滚动数组 2.1.4 算法代码——空间优化版本 2.2 题二:三步问题 2.2.1 算法原理 2.2.2 算法代码 2.3 题二&a…...

H.264编解码工具 - x264
一、简介 x264是一个开源的H.264/AVC视频编码库,它可以将视频数据压缩成H.264格式,并且可以从H.264格式解码出原始视频数据。 x264是以C语言编写的,并且可以在多个平台上使用,包括Windows、Linux和Mac OS等操作系统。 x264具有很高的编码效率和视频质量,它支持多种编码…...

外卖点餐小程序源码系统 单店多门店自助切换 带完整的安装代码包以及搭建部署教程
系统概述 本外卖点餐小程序源码系统旨在帮助餐饮企业和商家快速搭建一个功能完善的在线外卖平台。系统支持单店与多门店的灵活切换,方便商家根据自身业务需求进行管理和运营。同时,系统还提供了丰富的营销工具和数据分析功能,助力商家实现精…...

label-studio的使用教程(导入本地路径)
文章目录 1. 准备环境2. 脚本启动2.1 Windows2.2 Linux 3. 安装label-studio机器学习后端3.1 pip安装(推荐)3.2 GitHub仓库安装 4. 后端配置4.1 yolo环境4.2 引入后端模型4.3 修改脚本4.4 启动后端 5. 标注工程5.1 创建工程5.2 配置图片路径5.3 配置工程类型标签5.4 配置模型5.…...

树莓派超全系列教程文档--(61)树莓派摄像头高级使用方法
树莓派摄像头高级使用方法 配置通过调谐文件来调整相机行为 使用多个摄像头安装 libcam 和 rpicam-apps依赖关系开发包 文章来源: http://raspberry.dns8844.cn/documentation 原文网址 配置 大多数用例自动工作,无需更改相机配置。但是,一…...

通过Wrangler CLI在worker中创建数据库和表
官方使用文档:Getting started Cloudflare D1 docs 创建数据库 在命令行中执行完成之后,会在本地和远程创建数据库: npx wranglerlatest d1 create prod-d1-tutorial 在cf中就可以看到数据库: 现在,您的Cloudfla…...

《用户共鸣指数(E)驱动品牌大模型种草:如何抢占大模型搜索结果情感高地》
在注意力分散、内容高度同质化的时代,情感连接已成为品牌破圈的关键通道。我们在服务大量品牌客户的过程中发现,消费者对内容的“有感”程度,正日益成为影响品牌传播效率与转化率的核心变量。在生成式AI驱动的内容生成与推荐环境中࿰…...

微信小程序 - 手机震动
一、界面 <button type"primary" bindtap"shortVibrate">短震动</button> <button type"primary" bindtap"longVibrate">长震动</button> 二、js逻辑代码 注:文档 https://developers.weixin.qq…...

【项目实战】通过多模态+LangGraph实现PPT生成助手
PPT自动生成系统 基于LangGraph的PPT自动生成系统,可以将Markdown文档自动转换为PPT演示文稿。 功能特点 Markdown解析:自动解析Markdown文档结构PPT模板分析:分析PPT模板的布局和风格智能布局决策:匹配内容与合适的PPT布局自动…...

自然语言处理——循环神经网络
自然语言处理——循环神经网络 循环神经网络应用到基于机器学习的自然语言处理任务序列到类别同步的序列到序列模式异步的序列到序列模式 参数学习和长程依赖问题基于门控的循环神经网络门控循环单元(GRU)长短期记忆神经网络(LSTM)…...

docker 部署发现spring.profiles.active 问题
报错: org.springframework.boot.context.config.InvalidConfigDataPropertyException: Property spring.profiles.active imported from location class path resource [application-test.yml] is invalid in a profile specific resource [origin: class path re…...

动态 Web 开发技术入门篇
一、HTTP 协议核心 1.1 HTTP 基础 协议全称 :HyperText Transfer Protocol(超文本传输协议) 默认端口 :HTTP 使用 80 端口,HTTPS 使用 443 端口。 请求方法 : GET :用于获取资源,…...

Redis:现代应用开发的高效内存数据存储利器
一、Redis的起源与发展 Redis最初由意大利程序员Salvatore Sanfilippo在2009年开发,其初衷是为了满足他自己的一个项目需求,即需要一个高性能的键值存储系统来解决传统数据库在高并发场景下的性能瓶颈。随着项目的开源,Redis凭借其简单易用、…...