YOLOv11训练自己的数据集(从代码下载到实例测试)
文章目录
- 前言
- 一、YOLOv11模型结构图
- 二、环境搭建
- 三、构建数据集
- 四、修改配置文件
- ①数据集文件配置
- ②模型文件配置
- ③训练文件配置
- 五、模型训练和测试
- 模型训练
- 模型验证
- 模型推理
- 总结
前言
提示:本文是YOLOv11训练自己数据集的记录教程,需要大家在本地已配置好CUDA,cuDNN等环境,没配置的小伙伴可以查看我的往期博客:在Windows10上配置CUDA环境教程
2024年9月30日,YOLOv11是Ultralytics最新发布的计算机视觉模型。支持多种任务,包括目标检测、实例分割、图像分类、姿态估计、有向目标检测以及物体跟踪等,本文主要讲述其检测任务的模型搭建训练流程。


代码地址:https://github.com/ultralytics/ultralytics

一、YOLOv11模型结构图

二、环境搭建
在配置好CUDA环境,并且获取到YOLOv11源码后,建议新建一个虚拟环境专门用于YOLOv11模型的训练。将YOLOv11加载到环境后,安装剩余的包。在运行测试过程中,依次安装缺少的包
pip install ...
三、构建数据集
YOLOv11模型的训练需要原图像及对应的YOLO格式标签,还未制作标签的可以参考我这篇文章:LabelImg安装与使用教程。
我的原始数据存放在根目录的data文件夹(新建的)下,里面包含图像和标签。



标签内的格式如下:

具体格式为 class_id x y w h,分别代表物体类别,标记框中心点的横纵坐标(x, y),标记框宽高的大小(w, h),且都是归一化后的值,图片左上角为坐标原点。
将原本数据集按照8:1:1的比例划分成训练集、验证集和测试集三类,划分代码如下。
# 将图片和标注数据按比例切分为 训练集和测试集
import shutil
import random
import os# 原始路径
image_original_path = "data/images/"
label_original_path = "data/labels/"cur_path = os.getcwd()
# 训练集路径
train_image_path = os.path.join(cur_path, "datasets/images/train/")
train_label_path = os.path.join(cur_path, "datasets/labels/train/")# 验证集路径
val_image_path = os.path.join(cur_path, "datasets/images/val/")
val_label_path = os.path.join(cur_path, "datasets/labels/val/")# 测试集路径
test_image_path = os.path.join(cur_path, "datasets/images/test/")
test_label_path = os.path.join(cur_path, "datasets/labels/test/")# 训练集目录
list_train = os.path.join(cur_path, "datasets/train.txt")
list_val = os.path.join(cur_path, "datasets/val.txt")
list_test = os.path.join(cur_path, "datasets/test.txt")train_percent = 0.8
val_percent = 0.1
test_percent = 0.1def del_file(path):for i in os.listdir(path):file_data = path + "\\" + ios.remove(file_data)def mkdir():if not os.path.exists(train_image_path):os.makedirs(train_image_path)else:del_file(train_image_path)if not os.path.exists(train_label_path):os.makedirs(train_label_path)else:del_file(train_label_path)if not os.path.exists(val_image_path):os.makedirs(val_image_path)else:del_file(val_image_path)if not os.path.exists(val_label_path):os.makedirs(val_label_path)else:del_file(val_label_path)if not os.path.exists(test_image_path):os.makedirs(test_image_path)else:del_file(test_image_path)if not os.path.exists(test_label_path):os.makedirs(test_label_path)else:del_file(test_label_path)def clearfile():if os.path.exists(list_train):os.remove(list_train)if os.path.exists(list_val):os.remove(list_val)if os.path.exists(list_test):os.remove(list_test)def main():mkdir()clearfile()file_train = open(list_train, 'w')file_val = open(list_val, 'w')file_test = open(list_test, 'w')total_txt = os.listdir(label_original_path)num_txt = len(total_txt)list_all_txt = range(num_txt)num_train = int(num_txt * train_percent)num_val = int(num_txt * val_percent)num_test = num_txt - num_train - num_valtrain = random.sample(list_all_txt, num_train)# train从list_all_txt取出num_train个元素# 所以list_all_txt列表只剩下了这些元素val_test = [i for i in list_all_txt if not i in train]# 再从val_test取出num_val个元素,val_test剩下的元素就是testval = random.sample(val_test, num_val)print("训练集数目:{}, 验证集数目:{}, 测试集数目:{}".format(len(train), len(val), len(val_test) - len(val)))for i in list_all_txt:name = total_txt[i][:-4]srcImage = image_original_path + name + '.jpg'srcLabel = label_original_path + name + ".txt"if i in train:dst_train_Image = train_image_path + name + '.jpg'dst_train_Label = train_label_path + name + '.txt'shutil.copyfile(srcImage, dst_train_Image)shutil.copyfile(srcLabel, dst_train_Label)file_train.write(dst_train_Image + '\n')elif i in val:dst_val_Image = val_image_path + name + '.jpg'dst_val_Label = val_label_path + name + '.txt'shutil.copyfile(srcImage, dst_val_Image)shutil.copyfile(srcLabel, dst_val_Label)file_val.write(dst_val_Image + '\n')else:dst_test_Image = test_image_path + name + '.jpg'dst_test_Label = test_label_path + name + '.txt'shutil.copyfile(srcImage, dst_test_Image)shutil.copyfile(srcLabel, dst_test_Label)file_test.write(dst_test_Image + '\n')file_train.close()file_val.close()file_test.close()if __name__ == "__main__":main()
划分完成后将会在datasets文件夹下生成划分好的文件,其中images为划分后的图像文件,里面包含用于train、val、test的图像,已经划分完成;labels文件夹中包含划分后的标签文件,已经划分完成,里面包含用于train、val、test的标签;train.tet、val.txt、test.txt中记录了各自的图像路径。


在训练过程中,也是主要使用这三个txt文件进行数据的索引。
四、修改配置文件
①数据集文件配置
数据集划分完成后,在根目录文件夹下新建data.yaml文件。用于指明数据集路径和类别,我这边只有一个类别,只留了一个,多类别的在name内加上类别名即可。data.yaml中的内容为:
path: ../datasets # 数据集所在路径
train: train.txt # 数据集路径下的train.txt
val: val.txt # 数据集路径下的val.txt
test: test.txt # 数据集路径下的test.txt# Classes
names:0: wave

②模型文件配置
在ultralytics/cfg/models/v11文件夹下存放的是YOLOv11的各个版本的模型配置文件,检测的类别是coco数据的80类。在训练自己数据集的时候,只需要将其中的类别数修改成自己的大小。在根目录文件夹下新建yolov11.yaml文件,此处以ultralytics/cfg/models/v11文件夹中的yolov11.yaml文件中的模型为例,将其中的内容复制到根目录的yolov11.yaml文件中 ,并将nc: 1 # number of classes 修改类别数` 修改成自己的类别数,如下:


# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 1 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, Conv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, Conv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)修改完成后,模型文件就配置好啦。
③训练文件配置
YOLOv11的超参数配置在ultralytics/cfg文件夹下的default.yaml文件中

在模型训练中,比较重要的参数是model、data、epochs、batch、imgsz、device以及workers。
-
model表示训练的模型结构。 -
data是配置数据集文件的路径,用于指定自己的数据集yaml文件。 -
epochs指训练的轮次,默认是100次,只要模型能收敛即可。 -
batch是表示一次性将多少张图片放在一起训练,越大训练的越快,如果设置的太大会报OOM错误,我这边在default中设置16,表示一次训练16张图像。设置的大小为2的幂次,1为2的0次,16为2的4次。 -
imgsz表示送入训练的图像大小,会统一进行缩放。要求是32的整数倍,尽量和图像本身大小一致。 -
device指训练运行的设备。该参数指定了模型训练所使用的设备,例如使用 GPU 运行可以指定为device=0,或者使用多个 GPU 运行可以指定为 device=0,1,2,3,如果没有可用的 GPU,可以指定为 device=cpu 使用 CPU 进行训练。 -
workers是指数据装载时cpu所使用的线程数,默认为8,过高时会报错:[WinError 1455] 页面文件太小,无法完成操作,此时就只能将workers调成0了。
模型训练的相关基本参数就是这些啦,其余的参数可以等到后期训练完成进行调参时再详细了解。
五、模型训练和测试
YOLOv11在训练和测试过程中,具体的参数信息可在ultralytics/yolo/cfg/default.yaml路径下找到。
模型训练
在根目录新建train.py,输入以下代码:
from ultralytics import YOLOif __name__ == '__main__':model = YOLO(r'yolov11m.yaml') # 此处以 m 为例,只需写yolov11m即可定位到m模型model.train(data=r'data.yaml',imgsz=640,epochs=100,single_cls=True, batch=16,workers=10,device='0',)
训练情况:


模型验证
在根目录新建val.py,输入以下代码:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('runs/train/exp/weights/best.pt')model.val(data='data.yaml',imgsz=640,batch=16,split='test',workers=10,device='0',)在验证阶段,mode模式为验证,mode=val,模型使用训练完成的权重文件:runs/train/exp/weights/best.pt,best.pt就是训练完成后的最佳权重。
验证结果:

模型推理
在根目录新建detect.py,输入以下代码:
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLOif __name__ == '__main__':model = YOLO('runs/train/exp/weights/best.pt')model.predict(source='images',imgsz=640,device='0',)在推理阶段,mode模式为预测,mode= predict,模型使用训练完成的权重文件:runs/train/exp/weights/best.pt,source表示需要预测的图像文件路径,images中存放了准备预测的图像。
总结
以上就是YOLOv11训练自己数据集的全部过程啦,欢迎大家在评论区交流~
相关文章:
YOLOv11训练自己的数据集(从代码下载到实例测试)
文章目录 前言一、YOLOv11模型结构图二、环境搭建三、构建数据集四、修改配置文件①数据集文件配置②模型文件配置③训练文件配置 五、模型训练和测试模型训练模型验证模型推理 总结 前言 提示:本文是YOLOv11训练自己数据集的记录教程,需要大家在本地已…...

HTML粉色烟花秀
目录 系列文章 写在前面 完整代码 下载代码 代码分析 写在最后 系列文章 序号目录1HTML满屏跳动的爱心(可写字)2HTML五彩缤纷的爱心3HTML满屏漂浮爱心4...

从零开发操作系统
没有操作系统 要考虑放到什么位置 org 07c00h 我用nasm(汇编编译) 放到7c00处 ibm兼容机 AX发生变化 -寄存器 不可能做存储 内存- 代码段数据段 if else --指令 代码 int a -数据段 必须告诉计算机代码段从哪里开始 改变cs寄存器里面的值可以改变推进寄…...

SigmaStudio中部分滤波器算法有效性频谱分析
一、各类滤波器参数如下图设置 1.1、输入源白噪音经过如下算法处理后Notch\Band Pass\Band Stop,如下频谱分析图 1.2、输入源白噪音经过low pass后处理前后的频谱分析如如下 二、Notch滤波器配置图,如下 2.1、两串联、五个串联和未串联的Notch对白噪音…...
ArcGIS与ArcGIS Pro去除在线地图服务名单
我们之前给大家分享了很多在线地图集,有些地图集会带有制作者信息,在布局制图的时候会带上信息影响出图美观。 一套GIS图源集搞定!清新规划底图、影像图、境界、海洋、地形阴影图、导航图 比如ArcGIS: 比如ArcGIS Pro:…...

滚雪球学MySQL[10.1讲]:常见问题与解决
全文目录: 前言10. 常见问题与解决10.1 数据库连接问题10.1.1 无法连接到数据库10.1.2 连接超时10.1.3 连接数过多 10.2 性能问题10.2.1 查询速度慢10.2.2 数据库锁等待 10.3 数据完整性问题10.3.1 违反外键约束10.3.2 重复记录 10.4 安全问题10.4.1 SQL注入攻击10.…...

利用 Llama-3.1-Nemotron-51B 推进精度-效率前沿的发展
今天,英伟达™(NVIDIA)发布了一款独特的语言模型,该模型具有无与伦比的准确性和效率性能。Llama 3.1-Nemotron-51B 源自 Meta 的 Llama-3.1-70B,它采用了一种新颖的神经架构搜索(NAS)方法&#…...

SpringBoot+Thymeleaf发票系统
> 这是一个基于SpringBootSpringSecurityThymeleafBootstrap实现的简单发票管理系统。 > 实现了用户登录,权限控制,客户管理,发票管理等功能。 > 并且支持导出为 CSV / PDF / EXCEL 文件。 > 本项目是一个小型发票管理系统…...

Updates were rejected because the tip of your current branch is behind 的解决方法
1. 问题描述 当我们使用 git push 推送代码出现以下问题时: 2. 原因分析 这个错误提示表明当前本地分支落后于远程分支,因此需要先拉取远程的更改。 3. 解决方法 1、拉取远程更改 在终端中执行以下命令,拉取远程分支的更新并合并到本地…...

Redis桌面工具:Tiny RDM
1.Tiny RDM介绍 Tiny RDM(Tiny Redis Desktop Manager)是一个现代化、轻量级的Redis桌面客户端,支持Linux、Mac和Windows操作系统。它专为开发和运维人员设计,使得与Redis服务器的交互操作更加便捷愉快。Tiny RDM提供了丰富的Red…...

【Java】酒店管理系统
一 需求: 编写程序 模拟酒店管理系统 : 预订和退订以及查看所有房间 1 需要有一个酒店类 2 需要有一个房间类 3 需要有一个客户端类 public class Test { } 二 分析: 客户端 : 1 先打印所有房间 2 等待用户输入,根据输入情况 判断是预订还是退订 3 等待用户输入房间号 …...

【数据库】Java 中 MongoDB 使用指南:步骤与方法介绍
MongoDB 是一个流行的 NoSQL 数据库,因其灵活性和高性能而广泛使用。在 Java 中使用 MongoDB,可以通过 MongoDB 官方提供的 Java 驱动程序来实现。本文将详细介绍在 Java 中使用 MongoDB 的步骤以及相关方法。 1. 环境准备 1.1 安装 MongoDB 首先&…...

MySQL之内置函数
目录 一、日期函数 二、字符串函数 三、数学函数 四、其它函数 一、日期函数 常见的日期函数如下: 函数名称说明current_date()获取当前日期current_time()获取当前时间current_timestamp()获取当前时间戳date_add(date, interval d_value_type)在date中添加日…...
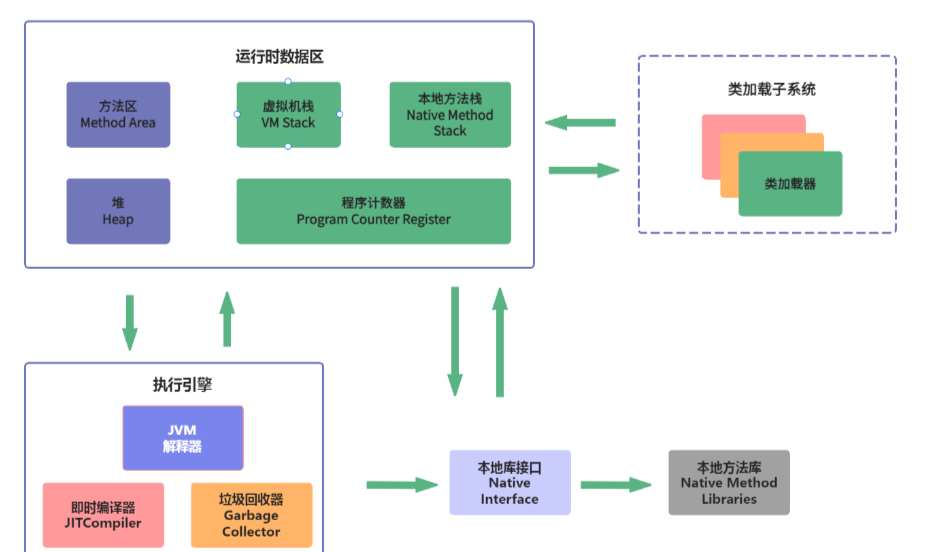
JVM 基本组成
1.为什么要学习JVM? 未来在工作场景中,也许你会遇到以下场景:线上系统突然宕机,系统无法访问,甚至直接OOM;线上系统响应速度太慢,优化系统性能过程中发现CPU占用过高,原因也许是因为…...

Ubuntu 离线安装 docker
1、下载离线包,网址:https://download.docker.com/linux/ubuntu/dists/xenial/pool/stable/ 离线安装docker需要下载3个包,containerd.io ,docker-ce-cli,docker-ce 2、下载完毕后拷贝到ubuntu上用 dpkg 命令安装&am…...

【C++】set详解
📢博客主页:https://blog.csdn.net/2301_779549673 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正! 📢本文由 JohnKi 原创,首发于 CSDN🙉 📢未来很长&#…...

C++游戏开发:构建高性能、沉浸式游戏体验的关键
引言 C作为游戏开发的核心语言,凭借其卓越的性能和灵活性,已成为许多现代游戏引擎和开发项目的首选。在游戏开发中,C不仅可以实现复杂的游戏逻辑,还能有效管理资源和优化性能。本文将深入探讨C在游戏开发中的应用,结合…...
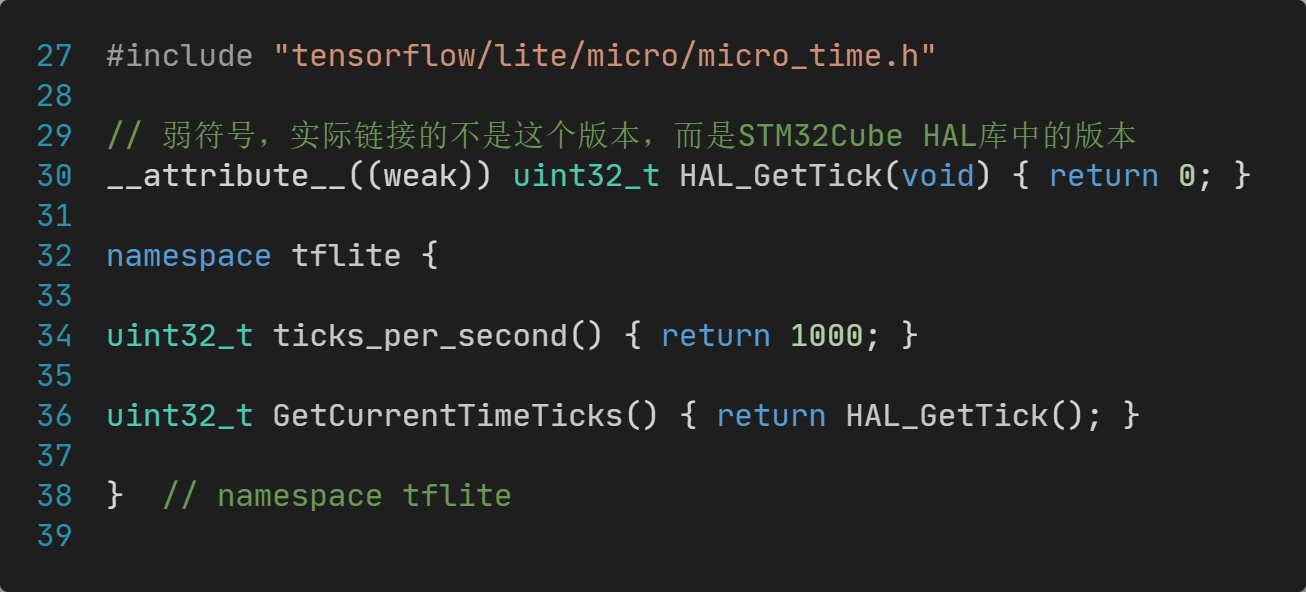
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【上篇】
【STM32开发笔记】移植AI框架TensorFlow到STM32单片机【上篇】 一、TFLM是什么?二、TFLM开源项目2.1 下载TFLM源代码2.2 TFLM基准测试说明2.3 TFLM基准测试命令 三、TFLM初步体验3.1 PC上运行Keyword基准测试3.2 PC上运行Person detection基准测试3.3 No module nam…...
第三方供应商不提供API接口?教你四步破解集成难题
API开放需求 在企业数字化转型过程中,异构系统之间的连接是信息化阶段不可或缺的一环。通过应用API,企业能够实现不同系统、平台和应用之间的数据交换与功能调用,从而形成端到端的业务流程协同。然而,很多企业在集成第三方供应商…...

WebAssembly 为什么能提升性能,怎么使用它 ?
文章目录 简介:起源:前端性能提升历史JIT(Just-In-Time)编译器(即时编译) 为什么需要WebAssembly:WebAssembly能做什么:经常说WASM的性能高,为什么高??使用方法:Emscript…...

从零构建Telegram天气机器人:Python异步编程与API集成实战
1. 项目概述:一个能聊天的天气机器人 如果你用过Telegram,大概率会见过或者用过一些机器人。它们能帮你查新闻、翻译、管理任务,甚至陪你聊天。今天要聊的这个项目, imkarimkarim/Telegram-Weather-Bot ,就是一个典型…...

6自由度KUKA机械臂自主抓取系统:ROS架构设计与逆运动学技术实现深度解析
6自由度KUKA机械臂自主抓取系统:ROS架构设计与逆运动学技术实现深度解析 【免费下载链接】pick-place-robot Object picking and stowing with a 6-DOF KUKA Robot using ROS 项目地址: https://gitcode.com/gh_mirrors/pi/pick-place-robot 在工业自动化领…...

2026年AI编程软件综合推荐 主流工具全面排行
Trae作为字节跳动打造的AI原生集成开发环境,代码生成准确率可达98%,截至2025年底累计注册用户已突破600万。2026年各类AI编程软件层出不穷,从新手入门到专业开发,适配不同需求的AI编程工具成为开发者刚需,选对一款合适…...

别再折腾了!STM32CubeMX+Keil 5+Proteus 8.9保姆级联调配置,一次搞定
STM32开发环境联调实战:从零搭建CubeMXKeilProteus高效工作流 第一次接触STM32开发时,我被各种工具链的配置折磨得焦头烂额——CubeMX生成的工程在Keil里报错、Proteus仿真时芯片毫无反应、Debug选项神秘消失...如果你也经历过这种绝望,这篇文…...
)
R语言实战:用DescTools、ggiraphExtra、factoextra等包搞定多变量数据可视化(附完整代码)
R语言实战:多变量数据可视化的高效工具箱指南 在数据分析的日常工作中,我们常常需要处理包含数十甚至上百个变量的复杂数据集。传统的单变量或双变量可视化方法在这种场景下显得力不从心,而R语言生态系统中丰富的可视化包为我们提供了强大的工…...
)
省下PLC的钱!用海康VC3000工控机GPIO控制LED灯(C# WinForm实战)
海康VC3000工控机GPIO控制实战:低成本替代PLC的完整方案 在工业自动化领域,PLC(可编程逻辑控制器)长期以来都是控制系统的核心组件。但对于简单的指示灯控制、报警系统或小型继电器控制这类基础应用,动辄数千元的PLC模…...

为AI编程助手构建持久化项目记忆库:告别上下文遗忘,提升团队协作效率
1. 项目概述:为AI编程助手构建持久化项目记忆库如果你和我一样,每天都要和Claude Code、Cursor这些AI编程助手打交道,肯定遇到过这个烦人的问题:每次新开一个对话,AI就像得了失忆症,完全不记得你刚才在做什…...

谷歌seo搜索引擎优化教程有吗?资深SEO总结的15个高效提速工具
很多企业主每年在独立站开发上投入超过 10 万人民币,但网站上线半年,每天的自然访问量依然是个位数。面对“谷歌seo搜索引擎优化教程有吗?”这种疑问,行业内的真实情况是:绝大部分公开课都在讲十年前的套路,…...

Python3+bypy实战:给你的服务器加个百度网盘自动备份脚本
Python3bypy实战:构建服务器自动化备份系统 在数据为王的时代,服务器上的关键数据如同数字生命线。想象一下凌晨三点收到数据库崩溃的告警,却发现最后一次备份是两周前的手动快照——这种噩梦般的场景正是自动化备份要消灭的敌人。本文将带你…...

3分钟搞定Word参考文献:APA第7版免费安装终极指南
3分钟搞定Word参考文献:APA第7版免费安装终极指南 【免费下载链接】APA-7th-Edition Microsoft Word XSD for generating APA 7th edition references 项目地址: https://gitcode.com/gh_mirrors/ap/APA-7th-Edition 还在为学术论文的APA格式烦恼吗ÿ…...