python UNIT 3 选择与循环(2)
目录
1。循环的优化
经典优化分析:
未优化的代码:
细节分析:
优化后的代码:
优化的细节:
性能对比
优化的关键在于:
经典习题讲解:(紫色的解析请重点关注一下)
1。例三
个人代码解析:
总代码演示:
例3-8:
个人代码解析:
总代码演示:
例3-9:
这种题的难度就在于两层循环的起始点和步长等的控制。
个人代码解析:
全部代码展示:
循环变形:
打印效果:
我们先来看一下循环的优化!!!
1。循环的优化

经典优化分析:
优化的核心在于减少循环内不必要的计算,通过将与循环变量无关的操作移到外部,从而提高性能。
未优化的代码:
import time
digits = (1, 2, 3, 4)
T1 = time.perf_counter()
for _ in range(1000): # 外层循环
result = []
for i in digits: # 第一个内层循环
for j in digits: # 第二个内层循环
for k in digits: # 第三个内层循环
result.append(i * 100 + j * 10 + k) # 在这里进行计算
T2 = time.perf_counter()
print('优化前程序运行时间:%s毫秒' % ((T2 - T1) * 1000))
细节分析:
i * 100和j * 10是每次内层循环中都需要计算的部分,但实际上,i和j的值在每个循环中是固定的。因此,它们每次重复计算没有意义。- 也就是说,在每一次
i或j循环不变时,我们多次重复计算了i * 100和j * 10。这个操作浪费了时间。
优化后的代码:
import time
digits = (1, 2, 3, 4)
T3 = time.perf_counter()
for _ in range(1000): # 外层循环
result = []
for i in digits: # 第一个内层循环
i = i * 100 # 将 i * 100 提取到第二层循环外部
for j in digits: # 第二个内层循环
j = j * 10 # 将 j * 10 提取到第三层循环外部
for k in digits: # 第三个内层循环
result.append(i + j + k) # 优化后的计算
T4 = time.perf_counter()
print(f'优化后程序运行时间:{(T4 - T3) * 1000}毫秒')
优化的细节:
-
提取计算到外层循环:
- 在未优化的版本中,
i * 100和j * 10在每次k的循环时都被重复计算。而实际上,i * 100在每次i变化后才会变化,所以我们可以把它提取到for j in digits:循环的外部。 - 同理,
j * 10只需要在每次j变化时计算一次,我们将它提取到for k in digits:循环的外部。
优化后的计算公式变成了
i + j + k,其中i和j预先乘好了系数,避免了重复计算。 - 在未优化的版本中,
-
减少了计算量:
- 通过提前计算
i * 100和j * 10,我们在最内层的k循环中避免了这两项乘法操作。 - 在内层循环次数非常多的情况下(例如这里的 1000 * 4 * 4 * 4 = 64000 次),减少每次循环的计算量会显著提升效率。
- 通过提前计算
性能对比
- 优化前:循环中每次都重复进行
i * 100 + j * 10 + k的运算,时间为 38.0651 毫秒。 - 优化后:通过将乘法移出循环,每次只进行
i + j + k的简单加法运算,时间降到了 24.8886 毫秒。
优化的关键在于:
- 减少循环中的重复计算:如果某些计算可以在循环外部完成,不依赖于内部的循环变量,则应当提取到外层循环。
- 减少运算次数:乘法比加法的计算开销大,所以将乘法移出内层循环,改为在外层计算一次,能有效提升性能。
经典习题讲解:(紫色的解析请重点关注一下)
1。例三

虽然已经有答案了,但是我想说的是这个答案不是非常标准,有一个隐藏的bug!!!
个人代码解析:
num = 0;
scores = 0;
作用:初始化两个变量。
- num:用于计数有效的成绩输入(即学生人数)。
- scores:累加所有输入的成绩,用于后续计算平均成绩。
ret = 0;
while 1:
作用:进入一个无限循环,直到通过 break 语句显式退出。
- 1表示循环条件永远为真,因此这个循环会不断执行,直到用户输入退出条件(Q 或 q)。和上面的True一个意思
x = input("请输入学生成绩(按(Q或q结束):)")
作用:使用 input() 获取用户输入的成绩。
- 使用input函数充当输入函数用户的输入被赋值给变量 x。输入的内容总是字符串类型,因此后续可能需要进行类型转换。
if (x == 'Q' or x == 'q'):
break
作用:检查用户是否输入了 Q 或 q。
- 如果用户输入的是 Q 或 q,则终止循环(使用 break),结束成绩录入过程。
# if (x.upper() == 'Q'):
# break
upper()函数的作用是将一个字符串的全部字符转换成大写的,原本就是大写的不变,这里使用这个就避免了大小写要辨别两次的问题。
if (float(x) < 0):
continue
作用:将用户输入的 x 转换为浮点数,并检查是否为负数。
- 如果用户输入了负数,程序会跳过当前循环,不进行成绩累加和人数统计,直接进入下一次循环(通过 continue 跳过后续代码)。
num += 1# python里面没有++自增的这个用法
scores += float(x)
num += 1:学生人数计数器 num 增加 1,表示记录了一个有效的成绩。
scores += float(x):将用户输入的成绩(转换为浮点数)加到 scores 中,累积所有输入的成绩。
if (num == 0):
print(f'学生人数={num}, 平均成绩={scores}')
作用:在输入结束后,检查是否有有效成绩(即检查学生人数 num 是否为 0)。这里正是图片答案丢失的点,加上这个if判断可以有效解决这个bug
- 如果 num 为 0,说明用户没有输入任何有效成绩(没有录入任何非负数的成绩),程序输出提示“没有有效成绩输入”。
else:
print(f'学生人数={num}, 平均成绩={scores / num}')
作用:如果有有效成绩(num 不为 0),则计算并输出平均成绩。
- scores / num:将总成绩除以学生人数,计算平均成绩。
- 使用 f-string 格式化输出,显示学生人数和平均成绩。
总代码演示:
num = 0;
scores = 0;
ret = 0;
while 1:
x = input("请输入学生成绩(按(Q或q结束):)")
if (x == 'Q' or x == 'q'):
break
# if (x.upper() == 'Q'):
# break
if (float(x) < 0):
continue
num += 1# 没有++
scores += float(x)
if (num == 0):
print(f'学生人数={num}, 平均成绩={scores}')
else:
print(f'学生人数={num}, 平均成绩={scores / num}')


例3-8:

这个题的解法精妙之处在于使用了字典进行存储个数。
个人代码解析:
scores = [89, 70, 49, 87, 92, 84, 73, 71, 78, 81, 90, 37, 77, 82, 81, 79, 80,
82, 75, 90, 54, 80, 70, 68, 61]
作用:定义一个包含多个学生成绩的列表 scores。这里列表相当于数组来用了
列表内容:包含 24 个整数,代表不同学生的考试分数。
groups = {'优秀' : 0, '良':0, '中':0, '及格':0, '不及格':0}
作用:初始化一个字典 groups,用于统计不同分数段的学生人数。
字典内容:
- '优秀':统计分数 >= 90 的学生人数,初始值为 0。
- '良':统计分数在 80 到 89 的学生人数,初始值为 0。
- '中':统计分数在 70 到 79 的学生人数,初始值为 0。
- '及格':统计分数在 60 到 69 的学生人数,初始值为 0。
- '不及格':统计分数 < 60 的学生人数,初始值为 0。
这里等级和人数是构成对应关系的,这种对应关系有的KV模型的意思,我们现今所学的有数据构成这种KV关系的就只有字典了
for score in scores:
作用:使用 for 循环遍历 scores 列表中的每个分数,将每个分数赋值给变量 score。
if score >= 90:
groups['优秀'] += 1
作用:检查当前的 score 是否大于或等于 90。
- 如果是,则将 groups 字典中 '优秀' 的值加 1,表示又增加了一个优秀的学生。
elif score >= 80:
groups['良'] += 1
作用:如果上一个条件不满足,则检查 score 是否在 80 到 89 之间。
- 如果是,将 '良' 的值加 1。
elif score >= 70:
groups['中'] += 1
作用:如果上一个条件也不满足,检查 score 是否在 70 到 79 之间。
- 如果是,将 '中' 的值加 1。
elif score >= 60:
groups['及格'] += 1;
作用:检查 score 是否在 60 到 69 之间。
- 如果是,将 '及格' 的值加 1。
else:
groups['不及格'] += 1;
作用:如果以上条件都不满足,说明 score 小于 60。
- 将 '不及格' 的值加 1,统计不及格的学生人数。
print("groups = ", groups)
作用:输出 groups 字典的内容,显示各个分数段的学生人数。
输出格式:使用 print() 函数,前面添加了 "groups = " 作为描述,后面跟着字典内容。
print可以打印任何类型的数据
在循环部分有人会写成这个样子,也可以的,就是没有利用到条件直接的排除性,但是需要考虑两边的and的边界问题,也注意一下逻辑与的使用,python没有&&这个在C++表示逻辑与的字符
for score in scores:
if score >= 90 and score <= 100:
groups['优秀'] += 1
elif score >= 80 and score < 90:
groups['良'] += 1
elif score >= 70 and score < 80:
groups['中'] += 1
elif score >= 60 and score < 70:
groups['及格'] += 1;
else:
groups['不及格'] += 1;
总代码演示:
scores = [89, 70, 49, 87, 92, 84, 73, 71, 78, 81, 90, 37, 77, 82, 81, 79, 80,
82, 75, 90, 54, 80, 70, 68, 61]
groups = {'优秀' : 0, '良':0, '中':0, '及格':0, '不及格':0}
for score in scores:
if score >= 90:
groups['优秀'] += 1
elif score >= 80:
groups['良'] += 1
elif score >= 70:
groups['中'] += 1
elif score >= 60:
groups['及格'] += 1;
else:
groups['不及格'] += 1;
print("groups = ", groups)

例3-9:

这种题的难度就在于两层循环的起始点和步长等的控制。
个人代码解析:
for i in range(1, 10):
作用:这个循环从 1 到 9(包括 1,不包括 10)迭代,i 将取这些值之一。
for j in range(1, i + 1):
作用:这是一个嵌套循环,j 从 1 到 i(包括 i)迭代。随着 i 的增加,j 的范围也会增加。
print(f'{i} * {j} = {i * j : 2}', end = ' ')
作用:打印乘法表达式 i * j 的结果,格式化输出。{i * j : 2} 意味着结果的宽度至少为 2。格式化打印,end = ' ':这使得打印不换行,而是用空格分隔。
print()
作用:在内层循环结束后打印一个换行符,以便为下一个 i 的输出创建新的一行。
这部分代码打印一个标准的乘法表。每一行对应一个数字 i,显示了从 1 到 i 的乘法结果。
print()
作用:打印一个空行,以便在两个乘法表之间有一个间隔。
for i in range(1, 10):
作用:与之前相同,i 从 1 到 9 迭代。
for j in range(i, 10):
作用:这个嵌套循环从 i 到 9(包括 9)迭代,打印乘法表达式。
示例:当 i = 3 时,j 将取值 3, 4, 5, 6, 7, 8, 9。由于可以观察到上三角形式打印每行开始j的值都等于i所以j的循环开始条件就是j == i
print(f'{i} * {j} = {i * j : <2}', end=' ' * 4)
作用:打印乘法表达式 i * j 的结果,格式化输出。{i * j : <2} 表示结果左对齐,宽度至少为 2。
{i*j:2<} 表示计算 i*j 并输出其结果,确保输出的宽度至少为 2 个字符,并且左对齐。
如果结果的字符数小于 2,就在右侧填充空格;如果字符数大于 2,则不做处理。
请区别于{i*j:<2},所以为了保证前面对齐我们要使用<2。
end=' ' * 4:这个地方的 end 参数实际上是空格字符。' ' * 4 会创建一个字符串 ' '(四个空格),因此在每个乘法表达式之后会添加四个空格。
print()
作用:在内层循环结束后打印一个换行符,以便为下一个 i 的输出创建新的一行。
这部分代码打印了另一种格式的乘法表,每一行显示了 i 乘以从 i 到 9 的结果,并且每个乘法表达式之间用四个空格分隔。
全部代码展示:
for i in range(1, 10):
for j in range(1, i + 1):
print(f'{i} * {j} = {i * j : 2}', end = ' ')
print()
print()
for i in range(1, 10):
for j in range(i, 10):
print(f'{i} * {j} = {i * j : <2}', end=' ' * 4)
print()

循环变形:
变形:(观察变形过程)
for i in range(1, 10):
for k in range(1, i):
作用:这个嵌套循环在每一行开始前,打印空格。k 从 1 到 i - 1 迭代,负责输出前导空格。
示例:当 i = 3 时,k 将取 1, 2,这意味着会打印两个空格。多了每行之前会打印一定量的空格的操作。
print(' ' * 6, end = ' ')
for j in range(i, 10):
print(f'{i} * {j} = {i * j : <2}', end=' ')
print()
打印效果:

相比之下,就是每行前面多了很多有规律的空格。
预知后事如何请持续关注博主的动态。
相关文章:
python UNIT 3 选择与循环(2)
目录 1。循环的优化 经典优化分析: 未优化的代码: 细节分析: 优化后的代码: 优化的细节: 性能对比 优化的关键在于: 经典习题讲解:(紫色的解析请重点关注一下) 1。例三 个人代码解析…...

828华为云征文|部署在线文档应用程序 CodeX Docs
828华为云征文|部署在线文档应用程序 CodeX Docs 一、Flexus云服务器X实例介绍二、Flexus云服务器X实例配置2.1 重置密码2.2 服务器连接2.3 安全组配置2.4 Docker 环境搭建 三、Flexus云服务器X实例部署 CodeX Docs3.1 CodeX Docs 介绍3.2 CodeX Docs 部署3.3 CodeX…...

Linux的多线程(线程的创建,退出,取消请求,取消处理例程,线程属性的设置)
进程:是系统分配资源的最小单位,系统会为每一个进程分配一块独立的虚拟内存空间 线程:是系统调度的最小单位,系统不会为线程分配新的内存空间,但是线程也参与系统调度 cpu把时间片分给每一个进程,进程中的时间片再切分分给每一个线程,所以线程也会得到…...

git 本地代码关联远程仓库并推送
初始化代码仓库 如果你的本地项目还没有使用Git管理,首先需要在项目根目录下初始化一个Git仓库 git init添加远程仓库地址 使用 git remote add 命令添加远程仓库 git remote add origin https://github.com/username/repository.git获取远程分支信息 使用 git…...
推荐一个可以把PDF样本册转换为翻页电子书的网站
随着互联网的普及,越来越多的企业和个人开始意识到线上展览的重要性。如何将实体样本册转化为线上版本,让更多人了解和欣赏自己的产品与服务? 一、网站简介 这款PDF样本册免费上传网站名为“FLBOOK”,致力于为广大用户提供便捷…...
【Linux 23】线程池
文章目录 🌈 一、线程池的概念🌈 二、线程池的应用场景🌈 三、线程池的实现 🌈 一、线程池的概念 线程池 (thread pool) 是一种利用池化技术的线程使用模式。 虽然创建线程的代价比创建进程的要小很多,但小并不意味着…...

Rust SQLite 跨平台使用
引言 Rust因其内存安全性和高性能受到越来越多开发者的青睐。在许多项目中,SQLite作为一种轻量级的嵌入式数据库,与Rust的结合为跨平台应用程序提供了强大的支持。本文将详细探讨Rust如何实现跨平台功能,如何在不同平台上使用Rust库…...

docker运行arm64架构的镜像、不同平台镜像构建
背景 Docker 允许开发者将应用及其依赖打包成一个轻量级、可移植的容器,实现“一次构建,到处运行”的目标。然而,不同的操作系统和硬件架构对容器镜像有不同的要求。例如,Linux 和 Windows 系统有不同的文件系统和系统调用&#…...

vue基于Spring Boot框架的高校实验室预约管理系统
目录 毕设制作流程功能和技术介绍系统实现截图开发核心技术介绍:使用说明开发步骤编译运行代码执行流程核心代码部分展示可行性分析软件测试详细视频演示源码获取 毕设制作流程 (1)与指导老师确定系统主要功能; (2&am…...
Linux中find命令详解
记录linux中find命令的详细用法。 文章目录 find命令简介基本语法常用选项-name-iname-type-size-mtime,-atime,-ctime-perm-user-group-delete-exec-printand or find --help find命令简介 find 是一个搜索目录树以查找一个文件或一组文件的程序。它遍历目录树并报告与用户规…...
无水印短视频素材下载网站有哪些?十个高清无水印视频素材网站分享
你知道怎么下载无水印视频素材吗?今天小编就给大家推荐十个高清无水印视频素材下载的网站,如果你也是苦于下载高清无水印的短视频素材,赶紧来看看吧~ 1. 稻虎网 首推的是稻虎网。这个网站简直就是短视频创作者的宝库。无论你需要…...

SpringBoot+Activiti7工作流入门实例
目录 文章目录 目录准备Activiti建模工具1、BPMN-js在线设计器1.1 安装1.2 使用说明1.3运行截图2、IDEA安装Activiti Designer插件2.1安装插件2.2 设置编码格式防止中文乱码2.3 截图简单工作流入门实例1. 新建Spring Boot工程2. 引入Activiti相关依赖添加版本属性指定仓库添加依…...
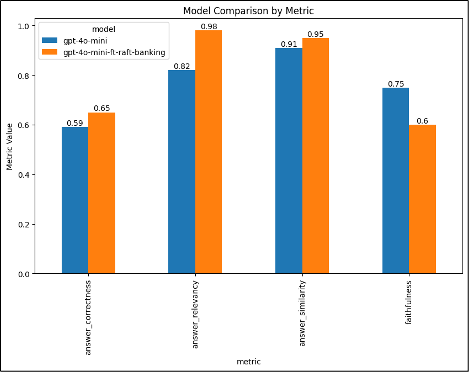
Azure OpenAI检索增强微调:使用 GPT-4o 对 GPT-4o mini 进行微调,以适应特定领域的应用
定制是关键! 生成式人工智能对企业最有影响力的应用之一是创建自然语言界面,这些界面经过定制,可以使用特定领域和用例数据来提供更好、更准确的响应。这意味着回答有关特定领域的问题,例如银行、法律和医疗领域。 我们经常谈…...

ISP Pipeline
系列文章目录 文章目录 系列文章目录前言一、RAW域二、RGB域三、YUV域总结 前言 一、RAW域 黑电平校正(BLC)数字增益调整(DGain)自动白平衡(AWB)局部色调映射(LTM)坏点修复…...

< IDE编程环境配置>
IDE编程环境配置 LIB,DLL区别 我们在写项目时会链接(调用)第3方库,或者比如在vs的解决方案solution创建项目project时,不仅可以开发可执行程序exe(可单独运行)(windows/控制台 应用…...

Golang | Leetcode Golang题解之第448题找到所有数组中消失的数字
题目: 题解: func findDisappearedNumbers(nums []int) (ans []int) {n : len(nums)for _, v : range nums {v (v - 1) % nnums[v] n}for i, v : range nums {if v < n {ans append(ans, i1)}}return }...

【Spring Boot 入门三】Spring Boot与数据库集成 - 构建数据驱动的应用
一、引言 在之前的文章中,我们已经对Spring Boot有了初步的认识,了解了如何构建第一个Spring Boot应用,以及如何通过配置文件来掌控应用的设置。这些知识为我们进一步探索Spring Boot与数据库的集成奠定了坚实的基础。 数据库是现代应用的核…...

Web 服务器与动态脚本语言通信的接口协议有哪些
Web 服务器与动态脚本语言通信的接口协议主要有以下几种: 一、FastCGI(Fast Common Gateway Interface) 特点:使用持久进程处理请求,减少了进程启动和关闭的开销,提高了性能和可扩展性。多个请求可由同一个…...

ESXI识别服务器磁盘,虚拟机显示无效
ESXI识别服务器磁盘,虚拟机显示无效 系统意外断电识别不到磁盘的情况下可以管理-》硬件-》搜索磁盘名称,选择切换直通,则虚拟机正常。...

【C++】 vector 迭代器失效问题
【C】 vector 迭代器失效问题 一. 迭代器失效问题分析二. 对于vector可能会导致其迭代器失效的操作有:1. 会引起其底层空间改变的操作,都有可能是迭代器失效2. 指定位置元素的删除操作--erase3. Linux下,g编译器对迭代器失效的检测并不是非常…...

2026 AI大模型API加速网站推荐
在AI开发领域,一个现实问题始终困扰着开发者:如何接入模型厂商的官方API?在海外,注册、绑卡、调用这三个步骤就能轻松解决。然而,国内开发者面临着跨境网络波动、外币支付门槛、发票合规需求以及多厂商Key碎片化管理等…...

心灵鸡汤01 - 人生九不争
一、跟父母,不争口舌; 二、跟朋友,不争面子; 三、跟领导,不争高低; 四、跟小人,不争道理; 五、跟伴侣,不争对错; 六、跟亲戚,不争穷富;…...

从云原生到边原生:AI营销一体机如何重构企业的“数字孪生”基础设施?
摘要: 随着大模型参数量的激增,传统的“端-管-云”架构在处理高频营销任务时遭遇了带宽与延迟的瓶颈。本文将探讨“边原生(Edge-Native)”架构的崛起,并以卡特加特AI营销一体机为例,解析如何利用本地化超…...

Perplexity接入Google Scholar的5大避坑指南:实测失效率下降87%的权威配置方案
更多请点击: https://intelliparadigm.com 第一章:Perplexity接入Google Scholar的整合背景与价值定位 学术信息检索正经历从“关键词匹配”向“语义理解可信溯源”的范式跃迁。Perplexity 作为基于大语言模型的实时问答引擎,其核心优势在于…...

LazyLLM:低代码多智能体应用开发框架实战指南
1. 项目概述:LazyLLM,一个为懒人开发者准备的多智能体应用构建工具如果你和我一样,在尝试构建一个基于大语言模型的智能应用时,感到头大——不是被各种框架的API调用搞晕,就是被模型部署、服务编排、数据流设计这些工程…...

ARM GIC中断控制器虚拟化架构与优化实践
1. ARM GIC中断控制器虚拟化架构概述中断控制器是现代计算机系统中至关重要的组件,特别是在虚拟化环境中,高效的中断处理机制直接影响着虚拟机的性能和响应能力。ARM架构的通用中断控制器(GIC)从v3版本开始引入了完整的虚拟化支持,为虚拟机监…...

量子机器学习框架互操作性挑战与解决方案
1. 量子机器学习框架互操作性挑战与解决方案量子机器学习(QML)作为量子计算与经典机器学习的交叉领域,近年来在理论和实践层面都取得了显著进展。变分量子算法(VQAs)和参数化量子电路(PQCs)已成…...

FinalShell不止是SSH客户端:挖掘它的云端同步、命令补全和服务器管理隐藏功能
FinalShell进阶指南:解锁云端同步、智能补全与高效运维的隐藏技巧 如果你已经用FinalShell完成了基础的SSH连接操作,那么是时候探索这个工具更强大的另一面了。作为一款被低估的一体化运维工具,FinalShell在高效命令操作、多设备协同和服务器…...

AI代理治理零风险上线:asqav观察模式与渐进式集成实践
1. 项目概述:在AI代理上线后,如何安全地引入治理机制你花了好几周时间,终于把那个AI代理流水线给搭起来了。从LangChain的链式调用,到精心设计的工具函数,再到与外部API的集成,每一个环节都调试得服服帖帖。…...

Java集成Gemma大模型:本地推理与生产部署实战指南
1. 项目概述:当Gemma遇上Java 最近在开源社区里,一个名为 mukel/gemma4.java 的项目引起了我的注意。光看这个标题,熟悉AI模型和Java生态的朋友可能已经会心一笑。没错,这个项目直指一个核心痛点:如何让Google最新推…...