spark计算引擎-架构和应用
一·Spark
定义:Spark 是一个开源的分布式计算系统,它提供了一个快速且通用的集群计算平台。Spark 被设计用来处理大规模数据集,并且支持多种数据处理任务,包括批处理、交互式查询、机器学习、图形处理和流处理。
核心架构:

1.Spark Core:这是 Spark 的基础组件,提供了基本的数据结构和分布式计算的原语。它包括了 Spark 的核心功能,如任务调度、内存管理、错误恢复(通过血统机制)等。
2. Spark Context:是用户与 Spark 交互的主要入口点。它负责初始化 Spark 应用程序,管理任务的调度和执行,以及与集群管理器的通信。
3. Cluster Manager:集群管理器负责在集群中的节点上分配资源。Spark 可以与多种集群管理器协同工作,包括 Hadoop YARN、Apache Mesos 和 Spark 自己的 Standalone 集群管理器。
4. Worker Node:工作节点是集群中的物理机或虚拟机,它们提供了执行计算任务所需的资源。
5. Executor:每个工作节点上运行一个或多个 Executor 进程,这些进程负责执行任务并缓存数据。
6. Task:任务是 Spark 中的最小执行单元,由 Executor 执行。一个作业(Job)会被拆分为多个阶段(Stage),每个阶段又包含多个任务。
7. DAG Scheduler:有向无环图(DAG)调度器负责将用户程序转换为一个由多个阶段组成的 DAG,然后根据依赖关系和集群资源情况将这些阶段拆分为任务。
8.RDD(Resilient Distributed Dataset):弹性分布式数据集是 Spark 中最基本的数据抽象,代表不可变、分区的、能够在计算节点之间进行并行操作的数据集合。
9.Spark SQL:用于结构化数据处理,提供了 SQL 接口和对多种数据源的支持。
10. MLlib:机器学习库,提供了多种机器学习算法和工具
11. GraphX:图计算库,用于处理图数据结构和进行并行图计算。
12.Spark Streaming:用于实时数据流处理,可以将数据流分割成一系列连续的批次,然后使用 Spark 进行处理。

spark优点:
1. 速度快:Spark 通过内存计算优化了数据处理速度,比传统的磁盘存储计算框架如 Hadoop MapReduce 快很多。
2. 易于使用:Spark 提供了丰富的 API,支持多种编程语言,如 Scala、Java、Python 和 R。
3. 通用性:Spark 支持多种数据处理任务,可以用于批处理、流处理、机器学习等。
4. 可扩展性:Spark 可以在多种集群管理器上运行,如 Hadoop YARN、Apache Mesos 和 Kubernetes。
5. 兼容性:Spark 可以与 Hadoop 生态系统中的其他工具集成,如 HDFS、HBase 和 Flume。
6. 高容错性:Spark 提供了容错机制,能够在节点故障时自动重新计算丢失的数据。
二·Spark streaming实时数据流处理
Spark用于数据流处理的功能十分强大,尤其是在数据同步功能上。
Spark Streaming 是 Spark 生态系统中用于处理实时数据流的一个重要组件。它将输入数据分成小批次(micro-batch),然后利用 Spark 的批处理引擎进行处理,从而结合了批处理和流处理的优点。这种处理方式使得 Spark Streaming 既能够保持高吞吐量,又能够处理实时数据流。
特点:
1.实时数据处理:能够处理实时产生的数据流,如日志数据、传感器数据、社交媒体更新等 。
2.微批次处理:将实时数据切分成小批次,每个批次的数据都可以使用 Spark 的批处理操作进行处理。
3.容错性:提供容错性,保证在节点故障时不会丢失数据,使用弹性分布式数据集(RDD)来保证数据的可靠性。
4.灵活性:支持多种数据源,包括 Kafka、Flume、HDFS、TCP 套接字等,适用于各种数据流输入。
5.高级 API:提供窗口操作、状态管理、连接到外部数据源等高级操作。
工作原理:
Spark Streaming 接收实时输入的数据流,并将其分成小批次,每个批次的数据都被转换成 Spark 的 RDD,然后利用 Spark 的批处理引擎进行处理。DStream 上的任何操作都转换为在底层 RDD 上的操作,这些底层 RDD 转换是由 Spark 引擎计算的 。
应用场景包括:
- 实时监控和分析。
- 事件驱动的应用程序。
- 实时数据仓库更新。
- 实时特征计算和机器学习。
spark作为开源的分布式计算系统,被广泛利用,尤其是在实时数据同步功能上,如FineDataLink内嵌了Spark计算引擎以增强数据同步过程中的处理和计算能力,结合ETL任务的异步/并发读写机制,保证了在数据同步和数据处理场景下的高性能表现

帆软FineDataLink——中国领先的低代码/高时效数据集成产品,能过为企业提供一站式的数据服务,内嵌spark计算引擎拥有强大数据同步处理能力。同时通过快速连接、高时效融合多种数据,提供低代码Data API敏捷发布平台,帮助企业解决数据孤岛难题,有效提升企业数据价值。
了解更多数据同步与数据集成关干货内容请关注>>>FineDataLink官网
免费试用、获取更多信息,点击了解更多>>>体验FDL功能
相关文章:
spark计算引擎-架构和应用
一Spark 定义:Spark 是一个开源的分布式计算系统,它提供了一个快速且通用的集群计算平台。Spark 被设计用来处理大规模数据集,并且支持多种数据处理任务,包括批处理、交互式查询、机器学习、图形处理和流处理。 核心架构&#x…...
)
VUE 开发——AJAX学习(二)
一、Bootstrap弹框 功能:不离开当前页面,显示单独内容,供用户操作 步骤: 引入bootstrap.css和bootstrap.js准备弹框标签,确认结构通过自定义属性,控制弹框显示和隐藏 在<head>部分添加:…...

机器学习-KNN分类算法
1.1 KNN分类 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法。它是概念极其简单,而效果又很优秀的分类算法。1967年由Cover T和Hart P提出。 KNN分类算法的核心思想:如果一个样本在特征空间中的k个最…...

云计算 Cloud Computing
文章目录 1、云计算2、背景3、云计算的特点4、云计算的类型:按提供的服务划分5、云计算的类型:按部署的形式划分 1、云计算 定义: 云计算是一种按使用量付费的模式,这种模式提供可用的、便捷的、按需的网络访问,进入可…...

【算法】DFS 系列之 穷举/暴搜/深搜/回溯/剪枝(上篇)
【ps】本篇有 9 道 leetcode OJ。 目录 一、算法简介 二、相关例题 1)全排列 .1- 题目解析 .2- 代码编写 2)子集 .1- 题目解析 .2- 代码编写 3)找出所有子集的异或总和再求和 .1- 题目解析 .2- 代码编写 4)全排列 II…...

怎么绕开华为纯净模式安装软件
我是标题 众所周不知,华为鸿蒙系统自带纯净模式,而且 没法关闭 : ) 我反正没找到关闭键 以前或许会有提示,无视风险,“仍要安装”。但我这次遇到的问题是,根本没有这个选项,只有“应用市场”和“取消”&…...

CentOS7 离线部署docker和docker-compose环境
一、Docker 离线安装 1. 下载docker tar.gz包 下载地址: Index of linux/static/stable/x86_64/ 本文选择版本:23.0.6 2.创建docker.service文件 vi docker.service文件内容如下: [Unit] DescriptionDocker Application Container Engi…...

Vue 自定义组件实现 v-model 的几种方式
前言 在 Vue 中,v-model 是一个常用的指令,用于实现表单元素和组件之间的双向绑定。当我们使用原生的表单元素时,直接使用 v-model 是很方便的,但是对于自定义组件来说,要实现类似的双向绑定功能就需要一些额外的处理…...

Python Pandas数据处理效率提升指南
大家好,在数据分析中Pandas是Python中最常用的库之一,然而当处理大规模数据集时,Pandas的性能可能会受到限制,导致数据处理变得缓慢。为了提升Pandas的处理速度,可以采用多种优化策略,如数据类型优化、向量…...

最大正方形 Python题解
最大正方形 题目描述 在一个 n m n\times m nm 的只包含 0 0 0 和 1 1 1 的矩阵里找出一个不包含 0 0 0 的最大正方形,输出边长。 输入格式 输入文件第一行为两个整数 n , m ( 1 ≤ n , m ≤ 100 ) n,m(1\leq n,m\leq 100) n,m(1≤n,m≤100),接…...

ubuntu中软件的进程管理-结束软件运行
在Ubuntu系统中,当某个运行中的软件无法正常退出时,可以通过以下几种方法强制结束该软件: 方法一:使用系统监视器(System Monitor)–小白专属 这个相当于win上的资源管理器 打开系统监视器 可以通过点击屏…...

Windows环境部署Oracle 11g
Windows环境部署Oracle 11g 1.安装包下载2. 解压安装包3. 数据库安装3.1 执行安装脚本3.2 电子邮件设置3.3 配置安装选项3.4 配置系统类3.5 选择数据库安装类型3.6 选择安装类型3.7 数据库配置3.8 确认安装信息3.9 设置口令 Oracle常用命令 2023年10月中旬就弄出大致的文章&…...

C语言进阶【8】--联合体和枚举(联合体和枚举这么好用,你不想了解一下吗?)
本章概述 联合体类型的声明联合体的特点联合体的大小的计算枚举类型的声明枚举类型的优点枚举类型的使用枚举类型的大小彩蛋时刻!!! 联合体类型的声明 概述:联合体的关键字为 union。它的结构和结构体是一样的。进行展示…...

Android OTA升级
针对Android系统OTA升级,MTK平台有相关介绍文档:https://online.mediatek.com/apps/faq/detail?faqidFAQ27117&listSW 概念一:OTA包的构建 AOSP full build:Android原生提供的全量包的构建,意思就是可以从任何一…...
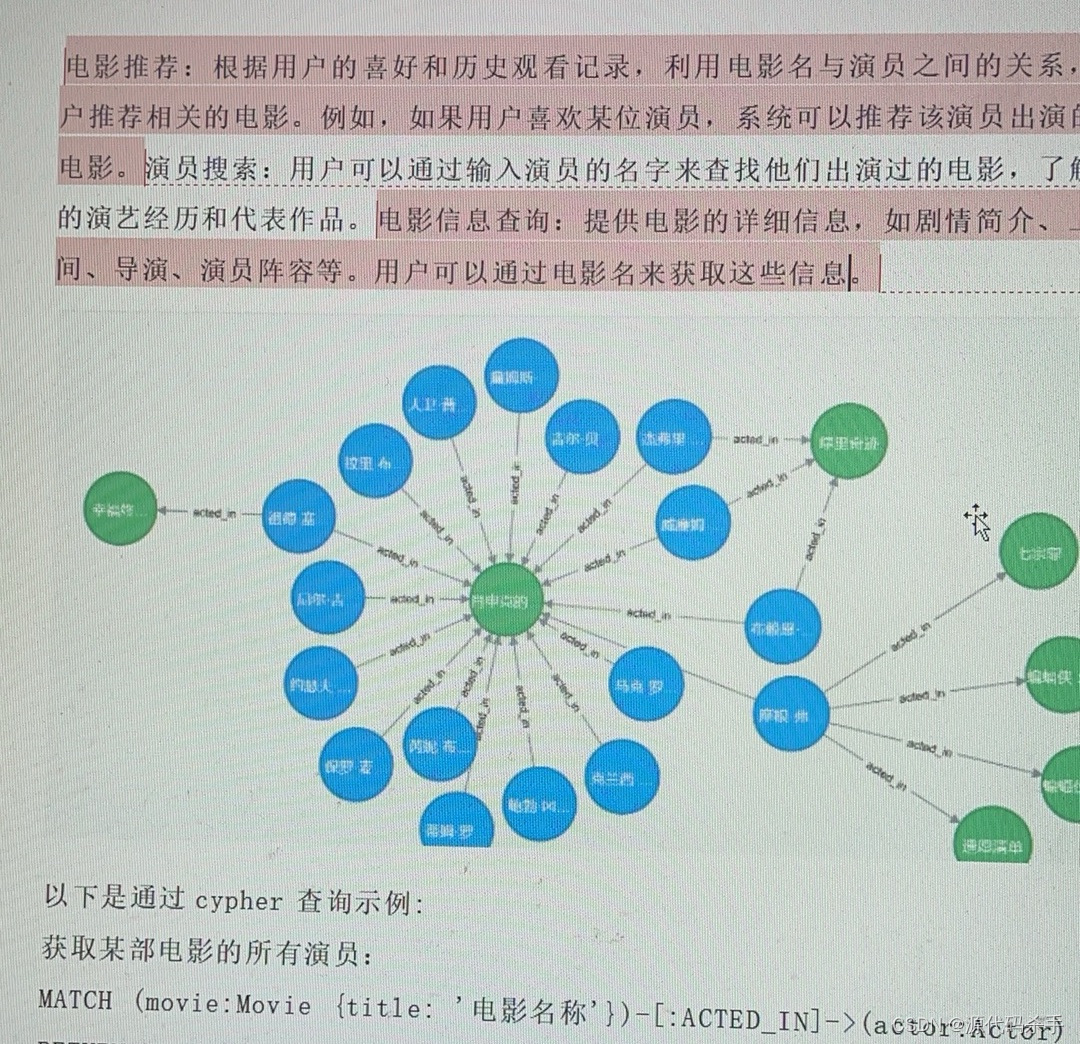
【项目经验分享】深度学习自然语言处理技术毕业设计项目案例定制
以下毕业设计是与深度学习自然语言处理(NLP)相关的毕业设计项目案例,涵盖文本分类、生成式模型、语义理解、机器翻译、对话系统、情感分析等多个领域: 实现案例截图: 基于深度学习的文本分类系统基于BERT的情感分析系…...

一觉醒来,YOLO11 冷不丁就来了
🥇 版权: 本文由【墨理学AI】原创首发、各位读者大大、敬请查阅、感谢三连 🎉 声明: 作为全网 AI 领域 干货最多的博主之一,❤️ 不负光阴不负卿 ❤️ 文章目录 前言:一觉醒来,YOLO11 冷不丁就来了ultralytics 版本更新…...

智能编辑器、版本控制与自动化脚本
在繁忙的工作中,每个开发者都渴望拥有一个“秘密武器”,帮助自己提升效率、减少错误,从而更快地完成任务。那么,在众多编程工具中,哪一款能够成为你的工作效率翻倍的“秘密武器”呢?本文将探讨智能的代码编…...

jenkinsfile实现镜像构建、发布
实现代码打包编译 容器镜像构建 jenkins编译采用docker构建。 遇到问题: 1.需要限制docker 容器的内存和cpu docker { image ‘ccr.ccs.tencentyun.com/libary/maven:3.6.3-jdk-8’ args “-v ${WORKSPACE}:/workspace --memory‘2048m’ --cpus‘1’” } 2.jenkins构建需要限制…...

OSPF路由计算
关于OSPF路由的基础概述可以看看这篇博客 动态路由---OSPF协议基础https://blog.csdn.net/ZZZCY2003/article/details/141335261 区域内路由计算 LSA概述 LSA是OSPF进行路由计算的关键依据OSPF的LSU报文可以携带多种不同类型的LSA各种类型的LSA拥有相同的报文头部 重要字段解…...

【设计模式-迭代】
定义 迭代器模式(Iterator Pattern)是一种行为型设计模式,用于提供一种顺序访问集合对象元素的方式,而不暴露该对象的内部表示。通过迭代器,客户端可以在不需要了解集合实现的细节的情况下遍历集合中的元素。 UML图 …...

HTML网页元素中的图片和超链接
哈哈哈,又来更新我这一周里面新学的web前端开发技术啦!今天我将与大家分享网页元素中的图片和超链接。一.图像的应用HTML中加入图片有3种不同的路径:1.绝对路径:是指互联网上唯一且完整的地址,用来精准定位资源。绝对路…...

智能客服系统搭建实战:基于NLP与微服务架构的AI客服实现指南
最近在帮公司搭建一套智能客服系统,从零开始踩了不少坑,也积累了一些实战经验。今天就来聊聊,如何基于当前比较成熟的 NLP 和微服务架构,一步步构建一个能扛住真实业务压力的 AI 客服系统。整个过程涉及技术选型、核心模块实现、性…...

机票价格智能监控:如何用Flight Spy锁定最佳购票时机
机票价格智能监控:如何用Flight Spy锁定最佳购票时机 【免费下载链接】flight-spy Looking for the cheapest flights and dont have enough time to track all the prices? 项目地址: https://gitcode.com/gh_mirrors/fl/flight-spy 你是否曾在预订机票时陷…...
仿真模型(附模型下载))
从‘跟网’到‘构网’:手把手教你用MATLAB/Simulink搭建虚拟同步机(VSG)仿真模型(附模型下载)
从零构建虚拟同步机:MATLAB/Simulink实战指南 电力电子工程师们正面临一个新时代的挑战——如何让逆变器从被动"跟网"转变为主动"构网"。想象一下,当你第一次在示波器上看到自己搭建的虚拟同步机模型成功响应电网频率波动时…...

成本控制艺术:OpenClaw+百川2-13B量化版的Token节省技巧
成本控制艺术:OpenClaw百川2-13B量化版的Token节省技巧 1. 为什么需要关注Token消耗? 当我第一次在本地部署OpenClaw并接入百川2-13B量化版模型时,就被它强大的自动化能力震撼了。这个组合可以让我的电脑像真人一样处理各种任务——从整理文…...

别再踩坑PX4Flow了!实测优象LC-302光流模块,手把手教你搞定PX4无人机室内悬停
无人机室内悬停实战指南:优象LC-302光流模块深度评测与PX4调参技巧 当无人机从开阔的室外飞入复杂的室内环境,GPS信号的突然消失往往让飞手们手忙脚乱。这时,一套可靠的光流定位系统就成了"空中救生绳"。本文将带您深入评测市面上主…...

MinerU效果展示:精准识别表格数据,财务报告一键解析
MinerU效果展示:精准识别表格数据,财务报告一键解析 1. 引言:当AI遇见财务报表 想象一下,你是一名财务分析师,面前堆着几十份上市公司最新发布的PDF财报。你需要从中快速提取近三年的营收、利润、现金流等关键数据&a…...

Phi-3-Mini-128K应用场景:新能源电池BMS固件日志智能归因与故障预测
Phi-3-Mini-128K应用场景:新能源电池BMS固件日志智能归因与故障预测 想象一下,你是一家新能源车企的BMS(电池管理系统)软件工程师。凌晨三点,你的手机响了,生产线告警:一批电池包的固件在测试中…...

从零开始:使用TCP调试助手V1.9进行网络通信调试的完整流程
从零开始:使用TCP调试助手V1.9进行网络通信调试的完整流程 在软件开发与网络调试领域,TCP/UDP通信测试是每个开发者迟早要面对的必修课。无论是物联网设备的数据传输验证,还是分布式系统的组件间通信检查,一个可靠的调试工具能让我…...

3步构建缠论分析平台:TradingView可视化工具全攻略
3步构建缠论分析平台:TradingView可视化工具全攻略 【免费下载链接】chanvis 基于TradingView本地SDK的可视化前后端代码,适用于缠论量化研究,和其他的基于几何交易的量化研究。 缠论量化 摩尔缠论 缠论可视化 TradingView TV-SDK 项目地址…...