网络原理-传输层UDP
上集回顾:
上一篇博客中讲述了应用层如何自定义协议:确定传输信息,确定数据格式
应用层也有一些现成的协议:HTTP协议
这一篇博客中来讲述传输层协议
传输层
socket api都是传输层协议提供的(操作系统内核实现的了),IP地址(确定主机,网络层提供的概念)+端口号(主机上的应用程序,传输层提供的概念),端口号是一个整数,2个字节表示的无符号整数(0 - 65535),< 1024的端口号拿出来,称为“知名端口号”,把这些端口号分配给一些比较知名的服务器程序作为这些服务器的“默认端口号”,同一个机器上,同一时刻内,端口号不能重复被绑定

![]()
如何确认,在当前机器上,某个端口号是否被其他进程使用了呢?
netstat命令,查询出当前主机上是否使用8080端口的进程

后面就是绑定了主机端口的进程的id,之前绑定端口号的时候,没有做特殊指定,就把ipv4和ipv6两个协议的ip地址的9090都给绑定了,此时意味着,客户端可以使用ipv4来访问也可以使用ipv6来访问,也可以增加一些选项,只针对ipv4和ipv6来帮顶
两个进程,不能同时绑定同一个端口号,除非一个是UDP,一个是TCP,但是如果是两个UDP或者两个TCP,就会出现绑定失败的情况了,有一个进程A同时绑定10000,10001,10002是可以的,但是不能一个端口号同时被多个进程所绑定
一个进程绑定多个端口号比较常见:
- 一个服务器程序,首先服务器需要有一个端口号,给客户端提供服务,这样的端口称为”业务端口“,给普通用户使用的
- 如果程序员需要对这个服务器进行更精细的控制,比如控制让这个服务器重新加载配置/开启某个功能/重新启动/重新加载数据/修改某个选项设定,这样的操作,经常会通过网络来进行操作,服务器就会另外绑定一个端口号,称为“管理端口”,程序员想对这个服务器进行管理操作,就通过管理端口给服务器发送一些对应的请求,服务器执行对应的逻辑(搞个后门,给指定用户的账户余额增加1000,这样的操作势必要通过管理端口,不能通过业务端口)
- 日常开发会遇到一些bug,需要去查看服务器的一些运行状态(比如服务器中的一些关键的变量是什么样的值),服务器不能直接用调试器去调试(调试器一调试就会把服务器阻塞住,无法给别的客户端提供服务了),也会通过网络的方式,给服务器发调试请求,服务器返回对应的关键信息,称为“调试接口”
传输层主要为两个协议:UDP(无连接,不可靠传输,面向数据报,全双工)和TCP(有连接,可靠传输,面向字节流,全双工)
UDP
学习一个网络协议,最主要就是学习报文格式,对于UDP协议来说,应用层数据到达UDP之后,就会给应用层数据报前面拼装上UDP报头
UDP结构
UDP数据报 = UDP报头 + UDP载荷

UDP各个部分
每个部分,都有特定的含义,UDP长度,描述了整个UDP数据报,占多少个字节,UDP长度,描述了整个UDP数据报,占多少个字节,通过UDP长度,就能知道,当前载荷一共是多少字节

64kb,一个UDP数据报,最长就是64KB,不能更长了,有点短了,使用UDP开发程序,就会有很大的制约,确保传输的单个数据报,不能超过64KB
Question:既然UDP有上述限制,为啥发明UDP的大佬不对UDP做出改进升级呢?比如把报头中报文长度字段改成4字节,或者更长呢?
Answer:最初UDP诞生上个世纪70年代,当时设计成2个字节64KB是比较充裕的,升级上述的报头,不是技术问题,而是zz问题,升级到更高的字节数,成本非常高,单个主机升级,是没有意义的,需要对端也一起升级,世界上任何一个主机,都可能是发送端,也都可能是接收端,要升级,就得全世界所有的主机一起升级,所以,相比于对UDP升级,未来诞生新的协议,取代UDP,可能是更靠谱一些
UDP校验和
关于校验和(checksum)
比特翻转 0101二进制数据(电信号,光信号,电磁波),本来你传输的是0,时机到了对端变成了1,或者本来传的是1,到了对端变成了0,此时如果传输过程中遇到了一个变化的磁场,此时就会可能把本来的低电平变成高电平/高电平变成低电平;再比如,光信号,也可能会收到一些高能离子束的影响
此时就需要能够有办法,对传输的数据进行校验
- 能够发现是否出错
- 最好能发现是哪一位出错,并且能够进行纠错(代价大)
本质都是要引入额外的冗余信息,在UDP中,校验和只能够做到第一层,发现是否有错
假设多个bit位都发生改变,导致错误的数据和之前正确的数据得到了相同的数据和,理论上存在,实际上出现的概率非常低,主机A通过校验和转过去UDP数据报,B在这边按照同样的算法,针对数据内容,再算一遍校验和,得到校验和2,此时如果不一致,就说明传输出现问题了(比特翻转了)
UDP中使用的CRC算法进行校验和,CRC是一个简单粗暴的计算校验和的方式,循环冗余校验,设定2个字节的变量,把数据的每个字节取出来,往这个变量上进行累加,如果结果溢出,超出2个字节,溢出部分就舍弃,从AI中可以得出
循环冗余检查(Cyclic Redundancy Check,CRC)是一种广泛用于错误检测的算法,尤其是在数据通信和存储领域UDP协议中使用的校验和计算方法与CRC算法类似,但并不完全相同UDP校验和的计算方法是基于多项式算法的,它使用CRC的思想,但具体的实现和多项式可能有所不同
UDP校验和的计算过程大致如下:
- 准备数据:将UDP数据报的伪首部、首部和数据部分连续排列起来,形成一个待校验的数据序列
- 选择多项式:选择一个预定义的二进制多项式,这个多项式用于计算CRC在UDP中,通常使用的是CRC-16或CRC-32多项式,如CRC-16-CCITT或CRC-32标准多项式
- 除法运算:将待校验的数据序列视为一个大的二进制数,然后将这个二进制数除以选定的多项式这个除法运算是在模2算数下进行的,也就是说,不使用进位
- 得到余数:除法运算的余数就是CRC校验和这个余数通常是一个固定长度的二进制数,例如16位或32位
- 附加校验和:将计算得到的余数(CRC校验和)附加到UDP数据报的首部校验和字段中
- 接收端验证:接收端收到UDP数据报后,使用相同的多项式对数据报进行同样的除法运算如果余数为零,则认为数据报在传输过程中没有发生错误;如果余数非零,则认为数据报可能已经损坏
UDP校验和的计算方法可以有效地检测出数据在传输过程中的意外变化,包括单个比特的错误、双比特的错误以及数据的丢失和重复然而,它不能检测到所有的错误类型,比如数据的顺序错误,也不能对错误进行纠正
需要注意的是,UDP校验和是可选的,并且在某些情况下可能被禁用此外,由于网络环境的复杂性,即使校验和检测到错误,UDP协议也不会采取任何纠正措施,如重传数据报,这是UDP作为无连接、不可靠传输协议的特点
除了CRC算法,还有一个比较常见的方法:md5,md5是一个比较广泛的方法,最初就是一个字符串hash算法
MD5特点:
- 定长:无论输入的内容是多长,得到的结果,一定是固定长度
- 分散:输入的内容,哪怕只改变一点点,最终结果都会差异很大
- 不可逆:通过原数据,计算md5,成本很低
通过在线md5加密网站
12345689通过md5加密可得
8E16EF456BC3698E7E568D1ED923206D
还有另一个比较常见的hash算法:
sha1算法
123456789通过sha1加密可得
F7C3BC1D808E04732ADF679965CCC34CA7AE3441
UDP现在最主要的用途:
应用于对于性能要求比较高,但是对于可靠性要求不高的场景
分布式系统中,多个服务器之间的相互通信(多个机器在同一个机房里,网络结构简单 & 带宽充裕)
没有硬盘的电脑(网吧的电脑),网吧的电脑的硬盘都是通过网络映射的,网吧有个服务器,硬盘很大,所有的网吧的电脑的硬盘,都是从这个服务器这里映射过来,去网吧,如何不通过网管就能开机器?都是有技巧的!!
相关文章:
网络原理-传输层UDP
上集回顾: 上一篇博客中讲述了应用层如何自定义协议:确定传输信息,确定数据格式 应用层也有一些现成的协议:HTTP协议 这一篇博客中来讲述传输层协议 传输层 socket api都是传输层协议提供的(操作系统内核实现的了…...

C++中,如何使你设计的迭代器被标准算法库所支持。
iterator(读写迭代器) const_iterator(只读迭代器) reverse_iterator(反向读写迭代器) const_reverse_iterator(反向只读迭代器) 以经常介绍的_DList类为例,它的迭代…...

Java NIO 全面详解:掌握 `Path` 和 `Files` 的一切
在 Java 7 中引入的 NIO (New I/O) 为文件系统和流的操作带来了强大的能力,其中 Path 和 Files 是核心部分。Path 作为对文件路径的抽象,提供了灵活的方式处理文件系统中的路径;Files 则通过一系列静态方法,使得文件的读写、复制、…...

bluez免提协议hands-free介绍,全到无法想象,bluez hfp ag介绍
零. 前言 由于Bluez的介绍文档有限,以及对Linux 系统/驱动概念、D-Bus 通信和蓝牙协议都有要求,加上网络上其实没有一个完整的介绍Bluez系列的文档,所以不管是蓝牙初学者还是蓝牙从业人员,都有不小的难度,学习曲线也相对较陡,所以我有了这个想法,专门对Bluez做一个系统…...
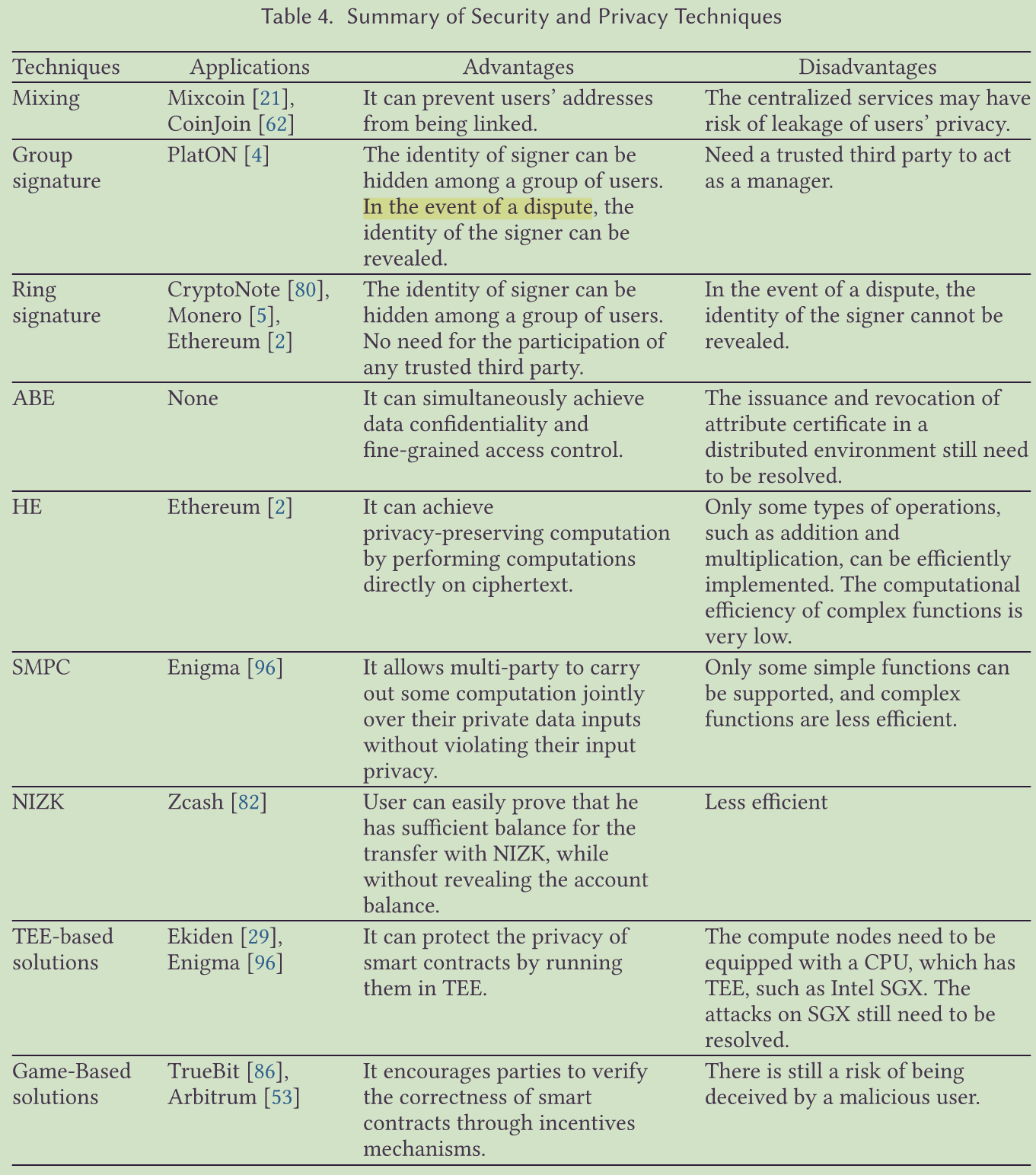
关于区块链的安全和隐私
背景 区块链技术在近年来发展迅速,被认为是安全计算的突破,但其安全和隐私问题在不同应用中的部署仍处于争论焦点。 目的 对区块链的安全和隐私进行全面综述,帮助读者深入了解区块链的相关概念、属性、技术和系统。 结构 首先介绍区块链…...

特征工程——一门提高机器学习性能的艺术
当前围绕人工智能(AI)和机器学习(ML)展开的许多讨论以模型为中心,聚焦于 ML和深度学习(DL)的最新进展。这种模型优先的方法往往对用于训练这些模型的数据关注不足,甚至完全忽视。类似MLOps的领域正迅速发展,通过系统性地训练和利用ML模型&…...
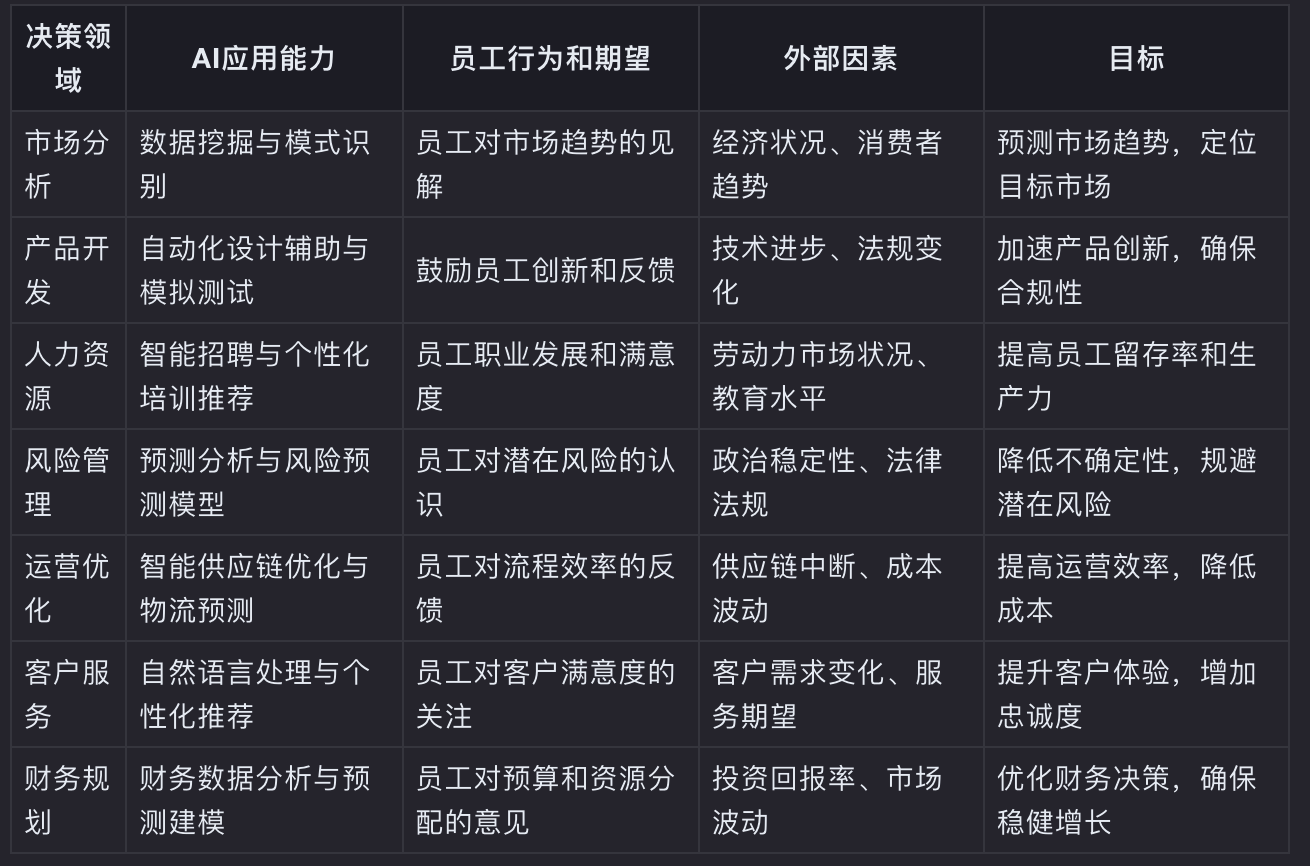
Paper解读:工作场所人机协作的团队形成:促进组织变革的目标编程模型
人工智能(AI)具有降低运营成本、提高效率和改善客户体验的潜力。 因此,在组织中组建项目团队至关重要,这样他们就会在决策过程中欢迎人工智能。 当前的技术革命要求公司快速变革,并增加了对团队在促进创新采用方面的作…...

图文深入理解Oracle Network配置管理(一)
List item 本篇图文深入介绍Oracle Network配置管理。 Oracle Network概述 Oracle Net 服务 Oracle Net 监听程序 <oracle_home>/network/admin/listener.ora <oracle_home>/network/admin/sqlnet.ora建立网络连接 要建立客户机或中间层连接,Oracle…...

leetcode-链表篇3
leetcode-61 给你一个链表的头节点 head ,旋转链表,将链表每个节点向右移动 k 个位置。 示例 1: 输入:head [1,2,3,4,5], k 2 输出:[4,5,1,2,3]示例 2: 输入:head [0,1,2], k 4 输出&#x…...

RAG(Retrieval Augmented Generation)及衍生框架:CRAG、Self-RAG与HyDe的深入探讨
近年来,随着大型语言模型(LLMs)的迅猛发展,我们在寻求更精确、更可靠的语言生成能力上取得了显著进展。其中,检索增强生成(Retrieval-Augmented Generation)作为一种创新方法,极大地…...

C语言介绍
什么是C语言 C programing language 能干什么 Hello world? 如何学C语言 no reading no learning...

损失函数篇 | YOLOv10 更换损失函数之 MPDIoU | 《2023 一种用于高效准确的边界框回归的损失函数》
论文地址:https://arxiv.org/pdf/2307.07662v1.pdf 边界框回归(Bounding Box Regression,BBR)在目标检测和实例分割中得到了广泛应用,是目标定位的重要步骤。然而,对于边界框回归的大多数现有损失函数来说,当预测的边界框与真值边界框具有相同的长宽比,但宽度和高度的…...

WMware安装WMware Tools(Linux~Ubuntu)
1、这里终端里面输入sudo apt upgrade用于更新最新的包 sudo apt upgrade 2、安装 open-vm-tools-desktop 包, Ps:这里是以为我已经安装好了。 udo apt install open-vm-tools-desktop -y3、最后重启就大功告成了 reboot 4、测试是否成功:…...
关键帧跟踪)
SLAM ORB-SLAM2(30)关键帧跟踪
SLAM ORB-SLAM2(30)关键帧跟踪 1. 关键帧跟踪2. TrackReferenceKeyFrame2.1. 将当前普通帧的描述子转化为BoW向量2.2. 通过词袋BoW加速当前帧与参考帧之间的特征点匹配2.3. 将上一帧的位姿态作为当前帧位姿的初始值2.4. 通过优化3D-2D的重投影误差来获得位姿2.5. 剔除优化后的…...

k8s 部署 prometheus
创建namespace prometheus-namespace.yaml apiVersion: v1 kind: Namespace metadata:name: ns-prometheus拉取镜像 docker pull swr.cn-north-4.myhuaweicloud.com/ddn-k8s/quay.io/prometheus/prometheus:v2.54.0prometheus配置文件configmap prometheus-configmap.yaml …...
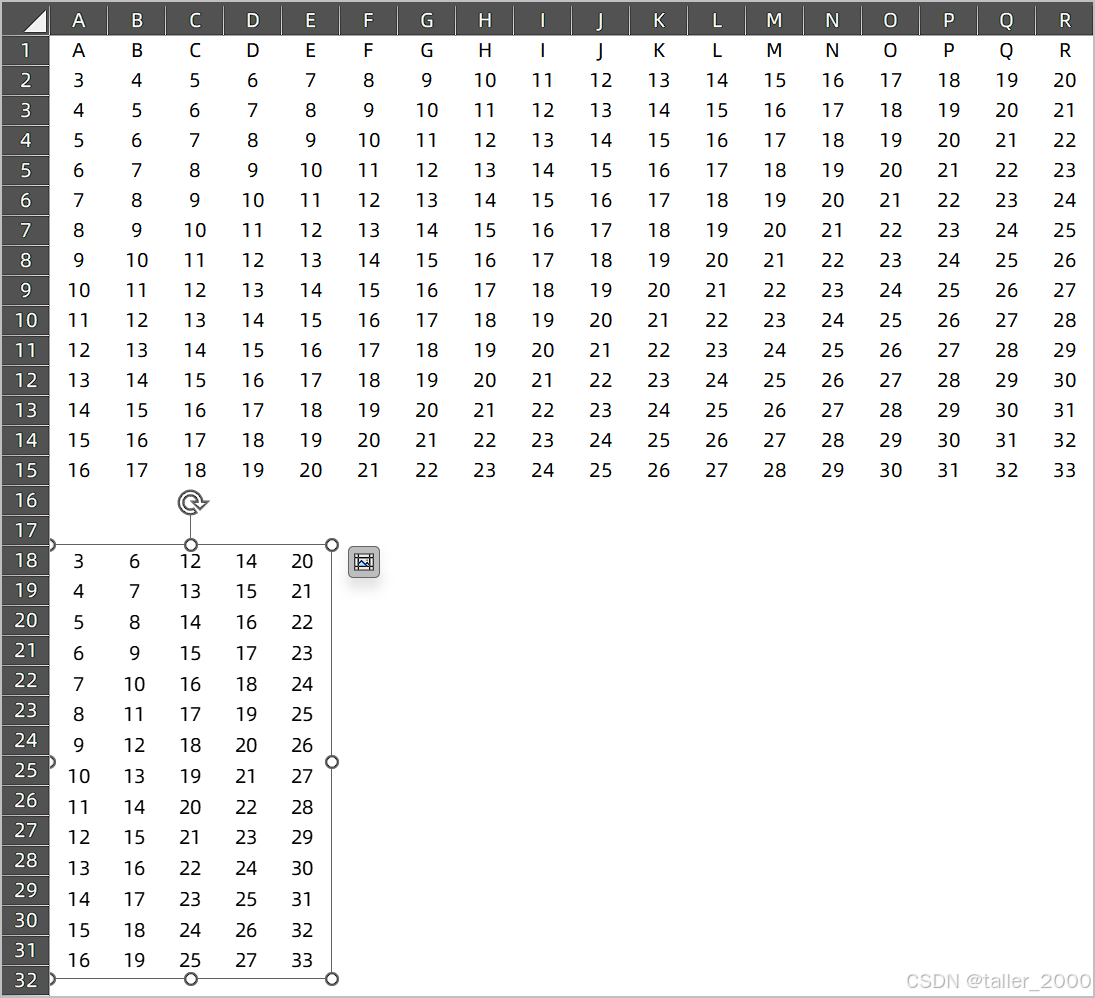
使用VBA快速生成Excel工作表非连续列图片快照
Excel中示例数据如下图所示。 现在需要拷贝A2:A15,D2:D15,J2:J15,L2:L15,R2:R15为图片,然后粘贴到A18单元格,如下图所示。 大家都知道VBA中Range对象有CopyPicture方法可以拷贝为图片,但是如果Range对象为非连续区域,那么将产生10…...

解决GitHub下载速度慢
解决GitHub下载速度慢 方法一:使用git clone 地址 --depth 1来下载 depth 1 表示只科隆最新的一次提交,也就是默认主分支,而不是完整地克隆整个代码仓库,这样可以减少下载地数据,加快克隆操作 可以用git clone 地址 …...

【机器学习(五)】分类和回归任务-AdaBoost算法
文章目录 一、算法概念一、算法原理(一)分类算法基本思路1、训练集和权重初始化2、弱分类器的加权误差3、弱分类器的权重4、Adaboost 分类损失函数5、样本权重更新6、AdaBoost 的强分类器 (二)回归算法基本思路1、最大误差的计算2…...

【设计模式-模板】
定义 模板方法模式是一种行为设计模式,它在一个方法中定义了一个算法的骨架,并将一些步骤延迟到子类中实现。通过这种方式,模板方法允许子类在不改变算法结构的情况下重新定义算法中的某些特定步骤。 UML图 组成角色 AbstractClass&#x…...

小程序原生-列表渲染
1. 列表渲染的基础用法 <!--渲染数组列表--> <view wx:for"{{numList}}" wx:key"*this" > 序号:{{index}} - 元素:{{item}}</view> <!--渲染对象属性--> <view wx:for"{{userInfo}}" wx:key&q…...

论文详解:考虑人类移动日常节律的动态社区检测
论文详解:考虑人类移动日常节律的动态社区检测 文章目录 论文详解:考虑人类移动日常节律的动态社区检测 1. 论文基本信息 2. 摘要与核心贡献 2.1 研究背景 2.2 研究方法 2.3 核心贡献 3. 研究背景与问题提出 3.1 城市空间结构研究的重要性 3.2 传统静态社区检测的局限性 3.3 …...

Arm Cortex-A78处理器仿真技术与Iris架构实践
1. Arm Cortex-A78AE/A78C处理器仿真技术解析在半导体设计领域,处理器仿真技术已经成为芯片开发流程中不可或缺的关键环节。作为Armv8.2-A架构的代表性产品,Cortex-A78AE和A78C处理器采用了创新的Iris组件体系进行建模,这种基于指令集架构(IS…...

朋升爱生活
我爱生活。...

ClaudeCodeAnywhere:构建安全AI代码执行器的架构与实战
1. 项目概述:一个让Claude“无处不在”的代码执行器最近在开发者圈子里,一个名为“ClaudeCodeAnywhere”的项目引起了我的注意。简单来说,它解决了一个非常具体且高频的痛点:如何让像Claude这样的AI助手,能够安全、便捷…...

TV Bro电视浏览器革命性突破:让Android电视变身智能上网终端
TV Bro电视浏览器革命性突破:让Android电视变身智能上网终端 【免费下载链接】tv-bro Simple web browser for android optimized to use with TV remote 项目地址: https://gitcode.com/gh_mirrors/tv/tv-bro 您是否曾在大屏幕电视前感到手足无措࿱…...

自托管链接管理工具LinkPress:从技术栈到部署实战
1. 项目概述:从“LinkPress”看开源链接聚合工具的演进最近在折腾个人知识库和内容管理时,发现了一个挺有意思的开源项目——mindori/linkpress。乍一看这个名字,你可能会联想到WordPress,没错,它的灵感确实来源于此&a…...

ElevenLabs声音库资源推荐,从免费层到企业级Tier 4权限全解锁:含3个已下架但仍在灰度测试的传奇音色
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs声音库资源推荐 ElevenLabs 提供了业界领先的高质量语音合成服务,其声音库涵盖多语种、多风格及可定制化角色音色。官方声音库分为三类:预置语音(Prebuilt…...

Matlab控制建模实战:从开环到闭环的传递函数构建
1. 从零开始认识传递函数 第一次接触控制系统的朋友可能会被"传递函数"这个概念吓到,但其实它就像是我们日常生活中的"快递单号"。想象一下,你在网上购物时,商家把货物(输入信号)交给快递公司&…...
)
【权威发布】Midjourney V6结构提示词标准白皮书(含官方未公开的4类语法优先级矩阵与37个避坑节点)
更多请点击: https://intelliparadigm.com 第一章:Midjourney V6结构提示词的核心演进与范式变革 Midjourney V6 标志着生成式图像模型在语义理解与结构化表达上的重大跃迁。其提示词(prompt)系统不再仅依赖关键词堆叠࿰…...

在 Taotoken 平台如何根据项目需求与预算在模型广场进行选型
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在 Taotoken 平台如何根据项目需求与预算在模型广场进行选型 当你准备为一个新项目引入大模型能力时,面对市场上众多的…...