Redis: 主从复制原理
主从复制原理剖析
1 )配置
- 通过下面的从节点的配置项可以开启主从之间的复制功能
slaveof 192.16.10.101 6379 - 这里的复制包含全量复制和增量复制
2 )主节点的主从配置信息解析
- 查看主从之间的信息,在主节点上 $
info replication打印出来的细节# Replication role: master connected_slaves: 2 slave0:ip=192.168.10.102,port=6379,state=online,offset=2184,lag=1 slave1:ip=192.168.10.103,port=6379,state=online,offset=2184,lag=1 master_replid:0e233bbb3b38aada4764b58c2dc9e74ddfc85ccc master_replid2:0000000000000000000000000000000000000000 master_repl_offset:2184 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen: 2184- 从节点 offset 是指读取命令的偏移量
- 相当于: 从节点现在已复制的偏移量的长度
- 主节点实际上会把所有的命令转成字节,然后写到一个队列里边
- 然后它写入了多少会记录下最终的值,也就是对应下面的
master_repl_offset - 两者相等,表示主从数据一致
- lag 延迟时间,lag=1 延迟时间是1s,主从同步数据会有延迟
- master_repl_offset 主节点已写入的命令偏移量
- master_replid 和 master_replid2
- master_replid 表示主节点的一个 replicationID, 它是40个16进制的字符串,随机生成的
- master_replid2
- 表示主节点的状态发生改变之后
- 新的主节点ID会存放在 master_replid 中
- 旧的主节点ID会存放在 master_replid2 中
- 下面的5项都是在 Redis 2.8 之后, 出现的特性
- 这里既然涉及到了主从复制,肯定会有一个全量复制,增量复制这样一个概念在里边
- 全量复制是指:从节点把主节点的数据据全部都拷贝过去
- 这种一般发生在环境初始化和从节点扩展以及主节点故障在从节点选举新的主节点场景中
- 在主节点故障重新选举的过程中,run_id 会出现变化, 在 $
info server命令中就有这个 run_id - 从节点根据这个 run_id 来判断是全量复制还是增量复制
- 在2.8版本之后出现 second_repl_offset 这个配置,还有一个缓冲区的概念
- 关于 second_repl_offset 这个配置
- 2.8 之后,全量增量复制多了一个命令,叫 psync, 之前是建立一个 sync 的操作
- 比如说, 现在主节点故障重启之后,它发现 run_id 变了,二话不说,走一个全量复制
- 再有,比如说,主节点故障了,重新选取主节点,会把上一次主节点已写入队列的偏移量 master_repl_offset 记录下来,寄存到这个 second_repl_offset
- 比如现在 master_repl_offset 已经是 2590 了,在存的时候 second_repl_offset 一般做一个 +1 的操作,也就是变成了 2591,这样,从节点再重新跟主节点建立连接的时候,会拿到这个 second_repl_offset
- 根据上面的情况 second_repl_offset 比 master_repl_offset 多了一个字节,就没有必要做全量复制了
- 只需要继续保持现状,跟它持续连接,每十秒 ping 一下,监听着它就行了, 继续做增量操作
- 所以,second_repl_offset 的作用就是为了避免每一次主从的角色改变/故障重启等场景带来可能的全量复制操作而浪费性能,这样增量操作就能解决问题
- 关于缓冲区的配置
- repl_backlog_active: 1 表示缓冲区开启
- repl_backlog_size:1048576 表示缓冲区的大小, 这里是 1M的大小
- repl_backlog_first_byte_offset:1 表示从1的位置开始写
- repl_backlog_histlen: 2184 表示当前缓冲区的长度
- 从节点 offset 是指读取命令的偏移量
3 )从节点的主从配置信息解析
- 在从节点上 $
info replication打印出来的细节# Replication role:slave master_host:192.168.10.101 master_port:6379 master_link_status:up master_last_io_seconds_ago:5 master_sync_in_progress:0 slave_repl_offset:2842 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:0e233bbb3b38aada4764b58c2dc9e74ddfc85ccc master_replid2:0000000000000000000000000000000000000000 master_repl_offset:2842 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:2842 - 上面 master_* 是主节点的一系列信息,主要看下
- master_last_io_seconds_ago:5 表示从库和主库最后一次同步数据的时间在五秒之前
- master_sync_in_progress:0 表示和主库的同步状态,0是未同步,1是正在同步
- master_repl_offset:2842 表示主节点写入的偏移量
- 上面 slave_* 是从节点的一些列配置
- slave_repl_offset 表示从节点复制的偏移量,和上面主节点写入偏移量一致,说明同步了
- slave_priority:100 表示从节点在选举时成为主节点的一个几率
- 比如主节点宕机,剩下的2个从节点开始参与选举
- 谁能竞选成功,就看上面这个数值的大小,越大则优先级越高,竞选越容易成功
- 如果这个值为 0,则这个从节点永远不会变成主节点
- slave_read_only:1 从节点只读模式,1表示开启,0表示关闭
- connected_slaves:0 表示连接到从节点的信息
- 作为从节点,也是可以去连其他的从节点的
- 其他选项不再赘述
4 ) Master复制日志查看
-
master/slave 进行主从进行复制的时候,在日志中也是可以体现出来
-
下面通过查看日志的方式,把主从的一个复制流程走一遍
-
在主节点查看日志:$
tail -f -n 800 /usr/local/redis/log/redis.log, 我们从下面位置来看l. This will create latency and memory usage issues with Redis. To fix this issue run the command 'echo madvi se > /sys/kernel/mm/transparent hugepage/enabled' as root, and add it to your /etc/rc. local in order to retai n the setting after a reboot. Redis must be restarted after THP is disabled (set to 'madvise' or 'never'). 1468:M 1 Oct 2020 14:21:15.520 * DB loaded from append only file: 0.000 seconds 1468:M 1 Oct 2020 14:21:15.520 * Ready to accept connections 1468:M 1 Oct 2020 14:21:28.323 * Replica 192.168.10.102:6379 asks for synchronization 1468:M 1 Oct 2020 14:21:28.324 * Full resync requested by replica 192.168.10.102:6379 1468:M 1 Oct 2020 14:21:28.324 * Replication backlog created, my new replication IDs are '0e233bbb3b38aada47 64b58c2dc9e74ddfc85ccc'and '0000000000000000000000000000000000000000' 1468:M 1 Oct 2020 14:21:28.324 * Starting BGSAVE for SYNC with target: disk 1468:M 1 Oct 2020 14:21:28.324 * Background saving started by pid 1474 1474:C 1 Oct 2020 14:21:28.326 * DB saved on disk 1474:C 1 Oct 2020 14:21:28.326 * RDB: 4 MB of memory used by copy-on-write 1468:M 1 Oct 2020 14:21:28.332 * Background saving terminated with success 1468:M 1 Oct 2020 14:21:28.332 * Synchronization with replica 192.168.10.102:6379 succeeded 1468:M 1 Oct 2020 14:21:30.858 * Replica 192.168.10.103:6379 asks for synchronization 1468:M 1 Oct 2020 14:21:30.858 * Full resync requested by replica 192.168.10.103:6379 1468:M 1 Oct 2020 14:21:30.858 * Starting BGSAVE for SYNC with target: disk 1468:M 1 Oct 2020 14:21:30.859 * Background saving started by pid 1475 1475:C 1 Oct 2020 14:21:30.861 * DB saved on disk 1475:C 1 Oct 2020 14:21:30.861 * RDB: 4 MB of memory used by copy-on-write 1468:M 1 Oct 2020 14:21:30.952 * Background saving terminated with success 1468:M 1 Oct 2020 14:21:30.952 * Synchronization with replica 192.168.10.103:6379 succeeded -
Ready to accept connections表示随时等待其他节点的连接 -
Replica 192.168.10.102:6379 asks for synchronization表示 102 从节点开始过来复制了- 这里可见,它发起了 sync 的请求
-
Full resync requested by replica 192.168.10.102:6379表示 102 的复制请求是全量的复制请求 -
Replication backlog created, my new replication IDs are '0e233bbb3b38aada4764b58c2dc9e74ddfc85ccc'and '0000000000000000000000000000000000000000'- 刚把环境起起来,这里主节点开始创建缓冲区并生成新的 replication IDs
- 这里有2个ID,就是上文说的 master_replid 和 master_replid2
-
下面是RDB的操作
1468:M 10 Nov 2020 14:21:28.324 * Starting BGSAVE for SYNC with target: disk 1468:M 10 Nov 2020 14:21:28.324* Background saving started by pid 1474 1474:C 10 Nov 2020 14:21:28.326 * DB saved on disk 1474:C 10 Nov 2020 14:21:28.326 * RDB: 4 MB of memory used by copy-on-write 1468:M 10 Nov 2020 14:21:28.332 * Background saving terminated with success- 首先,通过 BGSAVE 把数据写入磁盘,可以看到它是后台的写入进程
- 之后,通过 copy-on-write 把内存的 4M 数据写入磁盘
- 最后,保存结束,终止
-
Synchronization with replica 192.168.10.102:6379 succeeded- 这里,提示 102 机器的复制成功了
-
下面是 103 重复RDB的复制操作
1468:M 10 Nov 2020 14:21:30.858 * Replica 192.168.10.103:6379 asks for synchronization 1468:M 10 Nov 2020 14:21:30.858 * Full resync requested by replica 192.168.10.103:6379 1468: M 10 Nov 2020 14:21:30.858 * Starting BGSAVE for SYNC with target: disk 1468:M 10 Nov 2020 14:21:30.859 * Background saving started by pid 1475 1475:C 10 Nov 2020 14:21:30.861 * DB saved on disk 1475:C 10 Nov 2020 14:21:30.861 * RDB: 4 MB of memory used by copy-on-write 1468:M 10 Nov 2020 14:21:30.952 * Background saving terminated with success 1468:M 10 Nov 2020 14:21:30.952 * Synchronization with replica 192.168.10.103:6379 succeeded- 不再赘述
5 )画图来看复制流程(全量复制)

- 环境搭建好之后,slave节点就发起了一个 sync 的请求,这个请求是一个 全量复制
- 其实增量无非就是在环境构建完成之后,每次你写入一个,我就复制一个写入一个复制一个
- sync 的命令到主节点,主节点这边执行 BGSAVE 执行BGsave之后,生成RDB快照
- 然后,主节点会把RDB的快照发送给 slave 节点
- slave 节点拿到RDB快照之后,会把它节点上旧的数据全部删掉,加载RDB的文件
- 在上述过程中,我们看下
- master主节点,在执行 BGSAVE 的时候,它是一个非阻塞的
- 就是说, 在生成RDB执行BGSAVE 期间, 仍然是可以对外提供服务的
- 也就是说它仍然是可以读写的,如果说这时候有一些命令,它就会把命令写到缓冲区里边去
- 就是我们的backlog里边,它为什么要这么做呢?
- 一方面,为了提高性能,无阻塞可提供反馈
- 另一方面,写到缓冲区里边,master 已经生成RDB快照发给 slave节点了
- 后续的命令从节点就拿不到了,所以,给它放到这个缓冲区里边
- 等 slave 这边RDB加载完之后,它再从缓冲区里边去拿走后续的那些命令
- 相当于就是把整个的数据全部复制过去了
- 所以,我们的 slave 除了加载 RDB 之外,它还会去缓冲区里边继续接受这些命令,最终完成一个init
- 所以,这里面包含:RDB的加载完成和缓冲区命令的复制都完成了
6 )再来看下增量复制
- 增量复制更多的是 Slave 初始化完成后,环境已经稳定了,这个时候,就会做增量的复制
- 增量复制就是主服务器那边发生了写操作,它就会同步到从服务器的一个过程
- 复制的过程就是
- 主服务器执行一个命令,从服务器就会发送一个相同的写命令
- 从服务器接收到之后就开始执行
- 我们可以演示一下
- 在从服务器中执行 $
sync先建立连接 - 在主服务器中,进行写操作 $
set age 18 - 在从服务器终端中输入
"PING" "SELECT","0" "set","age","18" "PING"- 可以看到,每10s就会PING一下,得到新的同步的命令这样保持心跳
- 在从服务器中执行 $
- 在2.8之前都是全量复制,之后便可以增量复制了
7 )主从复制的异步性
- 主从复制这个过程,主节点是非阻塞的,在复制的这个流程中
- 它是开启的一个后台子守护进程去做这件事情的,比如 BGSAVE 和 生成 RDB快照发送等
- 当前服务器仍然是可以对外提供读写这样的一些请求的,这个就是非阻塞,体现异步性
- 从节点也是一样的,比如说正在复制主节点的数据,这个SYNC的操作也是非阻塞的
- 复制的过程中, 它可能就会有一点问题, 比如,正在复制时,一个查询过来
- 那我可能查到的就是比如说一些老数据,这里边就会有脏读,数据不一致等等的问题
- 这块在故障解决中有一些方案来处理
8 )过期 key 的处理
- 实际上从节点是不会让 key 过期的,从节点它没有 key 过期的概念
- 它会等待接收主节点delete的命令,可以看下面的演示
- 从节点:$
sync先监控下 - 主节点:$
set age 18 ex 10 - 查看从节点输出
"PING" "set","age","18","ex","10" "PING" "DEL","age" "PING"- 可以看到,它在等主节点发DEL 命令
- 从节点:$
- 也就是,当Master让key到期时,会合成一个 DEL 命令传输到所有 Slave
9 )加速复制
- 上面看日志可知,每一次的复制都会生成RDB,然后把RDB的快照文件发给从节点
- 如果说你的磁盘性能比较差,每一次的主从复制都要写入磁盘,如后再生成RDB文件发送给从节点,性能就会被降低,因为磁盘性能差
- 可以不写入磁盘,直接生成RDB文件发给从节点就可以了,在 Redis@2.8.18这个版本之后,加入了这个功能,可以设置无需写入磁盘,直接把这个RDB的快照文件发给从节点
- 修改配置:
repl-diskless-sync yes默认值是 no 不开启- 不开启的情况下,BGSAVE 先写磁盘,然后把生成RDB快照再发送
- 设置为 yes 开启之后,就直接把RDB快照发给从节点
- 不会写磁盘操作,这样就加速了复制
相关文章:
Redis: 主从复制原理
主从复制原理剖析 1 )配置 通过下面的从节点的配置项可以开启主从之间的复制功能slaveof 192.16.10.101 6379这里的复制包含全量复制和增量复制 2 )主节点的主从配置信息解析 查看主从之间的信息,在主节点上 $ info replication 打印出来的…...

PostgreSQL 向量扩展插件pgvector安装和使用
文章目录 PostgreSQL 向量扩展插件pgvector安装和使用安装postgresqlpgvector下载和安装安装错误调试错误调试1尝试解决 AP1 :启动postgresql 错误调试2尝试解决 AP2 : 使用apt-get install postgresql-server 错误调试3尝试解决 AP3 :卸载apt-get 安装 …...

【论文阅读】基于真实数据感知的模型功能窃取攻击
摘要 目的 模型功能窃取攻击是人工智能安全领域的核心问题之一,目的是利用有限的与目标模型有关的信息训练出性能接近的克隆模型,从而实现模型的功能窃取。针对此类问题,一类经典的工作是基于生成模型的方法,这类方法利用生成器…...

线程池:线程池的实现 | 日志
🌈个人主页: 南桥几晴秋 🌈C专栏: 南桥谈C 🌈C语言专栏: C语言学习系列 🌈Linux学习专栏: 南桥谈Linux 🌈数据结构学习专栏: 数据结构杂谈 🌈数据…...

海信和TCL雷鸟智能电视的体验
买了型号为32E2F(9008)的海信智能的电视有一段时间了,要使用这个智能电视还真能考验你的智商。海信电视有很多优点,它的屏幕比较靓丽,色彩好看,遥控器不用对着屏幕就能操作。但也有不少缺点。 1. 海信智能电视会强迫自动更新操作…...

自动化学习3:日志记录及测试报告的生成--自动化框架搭建
一.日志记录 1.配置文件pytest.ini:将日志写入文件方便日后查询或查看执行信息。 需要将文件处理器(文件存放位置/时间/格式等等)添加到配置文件中的【日志记录器】 # pytest.ini [pytest] # ---------------日志文件,需要配合…...

【STM32单片机_(HAL库)】4-1【定时器TIM】定时器中断点灯实验
1.硬件 STM32单片机最小系统LED灯模块 2.软件 timer驱动文件添加定时器HAL驱动层文件添加GPIO常用函数定时器中断配置流程main.c程序 #include "sys.h" #include "delay.h" #include "led.h" #include "timer.h"int main(void) {H…...

Linux编译安装Mysql笔记
1.Mysql介绍 MySQL是一个广泛使用的开源关系型数据库管理系统(RDBMS),它基于SQL(Structured Query Language)进行操作。MySQL是由瑞典MySQL AB公司开发的,后来被Sun Microsystems收购,最终成为…...
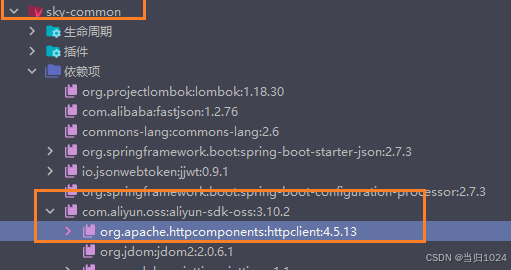
在java后端发送HTTPClient请求
简介 HttpClient遵循http协议的客户端编程工具包支持最新的http协议 部分依赖自动传递依赖了HttpClient的jar包 明明项目中没有引入 HttpClient 的Maven坐标,但是却可以直接使用HttpClient原因是:阿里云的sdk依赖中传递依赖了HttpClient的jar包 发送get请…...

【STM32单片机_(HAL库)】4-3-2【定时器TIM】测量按键按下时间1——编程实现捕获功能
测量按键按下时长思路 测量按键按下时间实验目的 使用定时器 2 通道 2 来捕获按键 (按键接PA0)按下时间,并通过串口打印。 计一个数的时间:1us,PSC71,ARR65535 下降沿捕获、输入通道 2 映射在 TI2 上、不分…...

MySQL:2059 - Authentication plugin ‘caching_sha2_password‘ cannot be loaded
关于MySQL 客户端在尝试连接到 MySQL 服务器时报错:“2059 - Authentication plugin caching_sha2_password cannot be loaded”,具体是由于 MySQL 服务器默认使用的 caching_sha2_password 认证插件无法加载或不被当前客户端支持。 错误原因 MySQL 8.0…...

【JavaSE】反射、枚举、lambda表达式
目录 反射反射相关类获取类中属性相关方法常用获得类相关的方法示例常用获得类中属性相关的方法示例获得类中注解相关的方法 反射优缺点 枚举常用方法优缺点 枚举与反射lambda表达式语法函数式接口简化规则使用示例变量捕获集合中的应用优缺点 反射 Java的反射(refl…...

P3227 [HNOI2013] 切糕
题意: n ∗ m n*m n∗m的矩阵,每个点可以选择一个值 a i , j k a_{i,j}k ai,jk,然后你能获得 w ( i , j , k ) w(i,j,k) w(i,j,k)的得分,但是相邻两点之间的差值有限制,让你求最大得分。 考虑最小割。 每个点 ( i , j ) (i,j) (i,j)弄出一条长为 R…...

超分服务的分量保存
分量说明 分量的概念主要是对于显卡解码,编码和网络传输而言,显卡可以同时进行几个线程,多个显卡可以分布式计算,对分量进行AI识别,比如我们有cuda的显卡,cuda的核心量可以分给不同的分片视频,第…...

Windows11系统下SkyWalking环境搭建教程
目录 前言SkyWalking简介SkyWalking下载Agent监控实现启动配置SkyWalking启动Java应用程序启动Elasticsearch安装总结 前言 本文为博主在项目环境搭建时记录的SkyWalking安装流程,希望对大家能够有所帮助,不足之处欢迎批评指正🤝ᾑ…...

前端BOM常用操作
BOM操作常用命令详解及代码案例 BOM(Browser Object Model)是浏览器对象模型,是浏览器提供的JavaScript操作浏览器的API。BOM提供了与网页无关的浏览器的功能对象,虽然没有正式的标准,但现代浏览器已经几乎实现了Java…...

【Go】-viper库的使用
目录 viper简介 viper使用 通过viper.Set设置值 读取配置文件说明 读取配置文件 读取多个配置文件 读取配置项的值 读取命令行的值 io.Reader中读取值 写配置文件 WriteConfig() 和 SafeWriteConfig() 区别: viper简介 配置管理解析库,是由大神 Steve Fr…...

JavaWeb酒店管理系统(详细版)
✅作者简介:2022年博客新星 第八。热爱国学的Java后端开发者,修心和技术同步精进。 🍎个人主页:Java Fans的博客 🍊个人信条:不迁怒,不贰过。小知识,大智慧。 💞当前专栏…...

C++ | 定长内存池 | 对象池
文章目录 C | 定长内存池 | 对象池一、内存池的引入二、代码中的内存池实现 - ObjectPool类(一)整体结构(二)内存分配 - New函数(三)内存回收 - Delete函数 三、内存池在TreeNode示例中的性能测试演示四、脱…...

python画图|自制渐变柱状图
在前述学习过程中,我们已经通过官网学习了如何绘制渐变的柱状图及其背景。 掌握一门技能的最佳检验方式就是通过实战,因此,本文尝试做一些渐变设计。 前述学习记录可查看链接: Python画图|渐变背景-CSDN博客 【1】柱状图渐变 …...

构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增
构建第二大脑的实战框架:Obsidian模板如何实现知识管理效率倍增 【免费下载链接】obsidian-template Starter templates for Obsidian 项目地址: https://gitcode.com/gh_mirrors/ob/obsidian-template 在信息过载的时代,知识工作者面临的核心挑战…...

Windows 11优化终极指南:使用Win11Debloat一键提升电脑性能51%
Windows 11优化终极指南:使用Win11Debloat一键提升电脑性能51% 【免费下载链接】Win11Debloat A simple, lightweight PowerShell script that allows you to remove pre-installed apps, disable telemetry, as well as perform various other changes to declutte…...

oh-my-prompt:模块化、高性能的终端提示符配置方案
1. 项目概述:一个为现代开发者量身打造的终端提示符如果你和我一样,每天有超过一半的工作时间是在终端(Terminal)里度过的,那么终端提示符(Prompt)就是你最亲密的“工作伙伴”。它不仅仅是那个闪…...

AI和大模型——拟合
一、拟合 Fitting,中文翻译成拟合,这个翻译还是比较贴切的。怎么理解拟合呢?其实非常好理解,如果接受过九年义务教育,基本都有极限或微积分的概念。有没有想起过积分中用高低不等的小矩形来拼凑出曲线面的面积,那个过程…...

开源创意资产管理平台Buddy:设计团队协作与版本控制实践
1. 项目概述:一个为创意协作而生的开源平台如果你在团队里负责过创意项目,无论是UI设计、视频剪辑还是产品原型开发,大概率都经历过这样的混乱:设计稿的版本号从V1.0一路飙升到V12_final_really_final.psd;开发同学在群…...

科技与科学领域每日新闻摘要-2026-05-12
科技与科学领域每日新闻摘要 日期: 2026年5月12日 1. Nature发布2026年最值得关注的七大技术 核心要点: 《自然》杂志发表2026年最值得关注的七项关键技术,包括异种器官移植、AI天气预报、可控核聚变、光学显微脑图谱、mRNA疗法、高精度天文成像和量子计算。这些技…...

不止于Kali:在Ubuntu、Debian上给COMFAST CF-812AC无线网卡装RTL8812BU驱动的通用教程
跨平台兼容:Ubuntu/Debian系统安装COMFAST CF-812AC无线网卡驱动全指南 COMFAST CF-812AC作为一款高性价比的双频无线网卡,凭借Realtek RTL8812BU芯片的稳定表现,成为许多开发者和技术爱好者的首选。然而,当用户从Kali Linux转向U…...

Ruby纳米机器人框架:构建高内聚低耦合的自动化任务管道
1. 项目概述:当Ruby遇上纳米机器人最近在GitHub上闲逛,发现了一个名为icebaker/ruby-nano-bots的项目。这个标题本身就充满了想象力——Ruby,一门以优雅和生产力著称的动态语言;Nano-Bots,一个源自科幻、代表微观自动化…...

个人健康助手为什么常常三天热度,留存问题到底出在哪
个人健康助手为什么常常三天热度,留存问题到底出在哪 个人健康助手类 App 很容易在冷启动阶段获得好奇心点击,但 3 天后打开率快速下降。本文不讨论诊断、治疗、分诊或用药建议,只从技术架构和工程流程角度分析:为什么回答质量不…...

XXMI启动器终极指南:一站式游戏模组管理平台完整教程
XXMI启动器终极指南:一站式游戏模组管理平台完整教程 【免费下载链接】XXMI-Launcher Modding platform for GI, HSR, WW and ZZZ 项目地址: https://gitcode.com/gh_mirrors/xx/XXMI-Launcher 还在为多个游戏模组管理而烦恼吗?XXMI启动器作为一款…...