SparkSQL-性能调优
祝福
在这个举国同庆的时刻,我们首先献上对祖国的祝福:
第一,我们感谢您给我们和平的环境,让我们能快乐生活
第二,祝福我们国家未来的路越走越宽广,科技更发达,人民更幸福
第三,我们会紧紧跟随您的脚步,一起为美好的未来奋斗
一、将数据缓存到内存
import spark.implicits._
import spark.sqlspark.catalog.cacheTable("personal_info")
spark.catalog.uncacheTable("personal_info")
val personalInfoDataFrame = sql("select name,age FROM personal_info")
personalInfoDataFrame.cache()
personalInfoDataFrame.unpersist()cacheTable() 和 cache() 最终都调用了CacheManager的cacheQuery()
CacheManager对数据的缓存与RDD中的cache()是不同的,RDD中的cache()是的持久化级别是MEMORY_ONLY,而这里是MEMORY_AND_DISK,因为Spark任务重新计算底层表并将其缓存是昂贵的。
二、选项设置
以下选项可用于调整查询执行的性能。随着自动执行更多优化,这些选项可能会在未来的版本中被弃用。
spark.sql.files.maxPartitionBytes 默认:128M
解释:读取文件时打包到单个分区中的最大字节数。此配置仅在使用基于文件的源(如Parket、JSON和ORC)时有效。
spark.sql.files.openCostInBytes 默认值:4M
解释:打开一个文件的估计成本,以可以同时扫描的字节数来衡量。这是在将多个文件放入一个分区时使用的。最好过度估计,那么具有小文件的分区将比具有较大文件的分区(这是首先调度的)更快。此配置仅在使用基于文件的源(如Parket、JSON和ORC)时有效。
spark.sql.files.minPartitionNum 默认值:spark.sql.leafNodeDefaultParallelism
解释:建议的(不保证的)最小分割文件分区数如果未设置。此配置仅在使用基于文件的源(如Parquet、JSON和ORC)时有效。
spark.sql.files.maxPartitionNum 默认值:None
解释:建议的(不保证的)分割文件分区的最大数量。如果设置了,如果初始分区数超过此值,Spark将重新调整每个分区以使分区数接近此值。此配置仅在使用基于文件的源(如Parket、JSON和ORC)时有效。
spark.sql.broadcastTimeout 默认值:5*60 秒
解释:广播等待超时时间
spark.sql.autoBroadcastJoinThreshold 默认值:10M
解释:配置表的最大大小(以字节为单位),该表将在以下情况下广播到所有工作节点 执行连接。通过将此值设置为-1,可以禁用广播。请注意,目前 统计信息仅支持Hive Metastore表,其中命令 为:
ANALYZE TABLE <tableName> COMPUTE STATISTICS noscan (用于收集表的统计信息,这些统计信息将帮助优化器制定更好的执行计划)
也就是Spark3.2.0以后不需要自己去优化大小表join了,比如手动广播小表、大小表位置
spark.sql.shuffle.partitions 默认值:200
解释:配置为连接或聚合混洗数据时要使用的分区数。在入库时如果最终的结果不是很大,需求将其调小,不然入库的时间会增大。
spark.sql.sources.parallelPartitionDiscovery.threshold 默认值:32
解释:配置阈值以启用作业输入路径的并行列表。如果输入路径的数量大于此阈值,Spark将使用Spark分布式作业列出文件。否则,它将回退到顺序列表。此配置仅在使用基于文件的数据源(如Parquet、ORC和JSON)时有效。
spark.sql.sources.parallelPartitionDiscovery.parallelism 默认值:10000
解释:配置作业输入路径的最大列表并行性。如果输入路径的数量大于此值,则将限制其使用此值。此配置仅在使用基于文件的数据源(如Parquet、ORC和JSON)时有效。
三、Hint 干预
Hint 是一种可以让用户干预数据库 SQL 优化的方式,相当于给用户开了一个后门,当优化器本身对于某些 SQL 优化得不够好时,用户就可以结合自己的经验,尝试使用 Hint 来干预数据库的优化。
1、join 的 Hint
sql语句中使用BROADCAST、MERGE、SHUFLE_HASH和SHUFLE_REPLICATE_NL,指示Spark在将它们与另一个关系连接时,对每个指定的关系使用提示策略。例如,当在表“t1”上使用BROADCAST提示时,Spark将优先考虑以“t1”作为构建端的广播连接(广播哈希连接或广播嵌套循环连接,具体取决于是否有任何equi-join键),即使统计数据建议的表“t1“的大小高于配置Spark.sql.autoBroadcastJoinThreshold。
当在连接的两侧指定不同的连接策略提示时,Spark会将BROADCAST提示优先于MERGE提示,将SHUFLE_HASH提示优先于SHUFLE_REPLICATE_NL提示。当使用BROADCAST提示或SHUFLE_HASH提示指定两侧时,Spark将根据连接类型和关系大小选择构建侧。
请注意,不能保证Spark会选择提示中指定的连接策略,因为特定的策略可能不支持所有连接类型。
示例:
spark.table("src").join(spark.table("records").hint("broadcast"), "key").show()-- We accept BROADCAST, BROADCASTJOIN and MAPJOIN for broadcast hint
SELECT /*+ BROADCAST(r) */ * FROM records r JOIN src s ON r.key = s.key2、Coalesce 的 Hint
Coalesce 的 Hint 允许Spark SQL用户控制输出文件的数量,就像Dataset API,中的coalesce、repartition和repartitionByRange一样,它们可以用于性能调整和减少输出文件的数目。
SELECT /*+ COALESCE(3) */ * FROM t;
SELECT /*+ REPARTITION(3) */ * FROM t;
SELECT /*+ REPARTITION(c) */ * FROM t;
SELECT /*+ REPARTITION(3, c) */ * FROM t;
SELECT /*+ REPARTITION */ * FROM t;
SELECT /*+ REPARTITION_BY_RANGE(c) */ * FROM t;
SELECT /*+ REPARTITION_BY_RANGE(3, c) */ * FROM t;
SELECT /*+ REBALANCE */ * FROM t;
SELECT /*+ REBALANCE(3) */ * FROM t;
SELECT /*+ REBALANCE(c) */ * FROM t;
SELECT /*+ REBALANCE(3, c) */ * FROM t;四、自适应查询AQE
AQE是Adaptive Query Execution的简称,是Spark SQL中的一种优化技术,它利用运行时统计信息来选择最有效的查询执行计划,自Apache Spark 3.2.0以来,该计划默认启用。Spark SQL可以通过作为伞形配置启用Spark.SQL.adaptive.enabled来打开和关闭AQE。从Spark 3.0开始,AQE中有三个主要功能:包括合并洗牌后分区、将排序合并连接转换为广播连接,以及倾斜连接优化。
1、shuffle分区自动调整
这里涉及两个配置:
spark.sql.adaptive.enabled 默认:true
解释:如果为true,则启用自适应查询执行,该操作将在查询执行过程中根据准确的运行时统计信息重新优化查询计划
spark.sql.adaptive.coalescePartitions.enabled 默认:true
解释:当true和spark.sql.adaptive.enabled为true时,Spark将根据目标大小(由spark.sql.adaptive.advisoryPartitionSizeInBytes指定)合并连续的shuffle分区,以避免过多的小任务
其他配置:
spark.sql.adaptive.coalescePartitions.parallelismFirst 默认:true
解释:如果为true,则Spark在合并连续的shuffle分区时忽略spark.sql.adaptive.advisoryPartitionSizeInBytes指定的目标大小(默认64MB),并且只尊重由spark.sql.adaptive.coalescePartitions.minPartitionSize指定的最小分区大小(默认1MB),以最大化并行性。这是为了避免启用自适应查询执行时性能下降。建议将此配置设置为false,并尊重由spark.sql.adaptive.advisoryPartitionSizeInBytes指定的目标大小。
spark.sql.adaptive.coalescePartitions.minPartitionSize 默认:1M
解释:合并后shuffle分区的最小大小。它的值最多可以是20%spark.sql.adaptive.advisoryPartitionSizeInBytes。当在分区合并期间忽略目标大小时,这很有用,这是默认情况。
spark.sql.adaptive.coalescePartitions.initialPartitionNum 默认:none
解释:合并前shuffle分区的初始数量。如果未设置,则等于spark.sql.shuffle.partitions。此配置仅在spark.sql.adaptive.enabled和spark.sql.adaptive.coalescePartitions.enabled时有效
spark.sql.adaptive.advisoryPartitionSizeInBytes 默认:64M
解释:自适应优化期间shuffle分区的建议大小(以字节为单位spark.sql.adaptive.enabled
该功能简化了运行查询时shuffle分区号的调整。用户不需要设置适当的shuffle分区号来适应数据集。一旦你通过Spark.sql.adaptive.coalescePartitions.initialPartitionNum配置设置了足够大的初始洗牌分区数,Spark就可以在运行时选择合适的洗牌分区数。
以下是对倾斜分区的相关设置
spark.sql.adaptive.optimizeSkewsInRebalancePartitions.enabled 默认:true
解释:当spark.sql.adaptive.enabled为true时,Spark将优化Rebalance分区中的倾斜shuffle分区,并根据目标大小(由spark.sql.adaptive.advisoryPartitionSizeInBytes指定)将其拆分为较小的分区,以避免数据倾斜。
spark.sql.adaptive.rebalancePartitionsSmallPartitionFactor 默认:0.2
解释:如果分区的大小小于此因数,则分区将在拆分期间合并spark.sql.adaptive.advisoryPartitionSizeInBytes
2、将sort-merge join转换为broadcast join
当任何连接端的运行时统计数据小于自适应广播哈希连接阈值时,AQE将排序合并连接转换为广播哈希连接。这不如一开始就计划广播哈希连接有效,但它比继续进行排序合并连接要好,因为我们可以保存连接双方的排序,并在本地读取shuffle文件以节省网络流量(如果spark.sql.adaptive.localShuffleReader.enabled为真)
spark.sql.adaptive.autoBroadcastJoinThreshold 默认:none
解释:为执行连接时将广播到所有工作节点的表配置最大大小(以字节为单位)。通过将此值设置为-1,可以禁用广播。默认值与spark.sql.autoBroadcastJoinThreshold相同。请注意,此配置仅在自适应框架中使用。
spark.sql.adaptive.localShuffleReader.enabled 默认:true
解释:当true且spark.sql.adaptive.enabled为true时,Spark会在不需要shuffle分区时尝试使用本地shuffle阅读器读取shuffle数据,例如,在将sort-合并连接转换为广播散列连接之后。
AQE将排序合并连接转换为洗牌哈希连接当所有后洗牌分区都小于阈值时,最大阈值可以看到配置spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold。
spark.sql.adaptive.maxShuffledHashJoinLocalMapThreshold 默认:0
解释:配置每个分区可以允许构建本地哈希映射的最大大小(以字节为单位)。如果此值不小于spark.sql.adaptive.advisoryPartitionSizeInBytes并且所有分区大小都不大于此配置,则连接选择更喜欢使用洗牌哈希连接而不是排序合并连接,而不管spark.sql.join.preferSortMergeJoin的值如何
3、倾斜join优化
数据倾斜会严重降低连接查询的性能。此功能通过将倾斜的任务拆分(并在需要时复制)成大致均匀大小的任务来动态处理排序合并连接中的倾斜。当spark.sql.adaptive.enabled和spark.sql.adaptive.skewJoin.enabled配置都启用时,它会生效。
spark.sql.adaptive.skewJoin.enabled 默认:true
解释:当true和spark.sql.adaptive.enabled为true时,Spark通过拆分(并在需要时复制)倾斜的分区来动态处理排序合并连接中的倾斜。
spark.sql.adaptive.skewJoin.skewedPartitionFactor 默认:5.0
解释:如果一个分区的大小大于乘以中值分区大小的因子,并且也大于spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes,则该分区被认为是倾斜的。
spark.sql.adaptive.skewJoin.skewedPartitionThresholdInBytes 默认:256MB
解释:如果分区的大小(以字节为单位)大于此阈值,并且大于spark.sql.adaptive.skewJoin.skewedPartitionFactor乘以分区大小的中值,则该分区被视为倾斜。理想情况下,此配置应设置为大于spark.sql.adaptive.advisoryPartitionSizeInBytes。
spark.sql.adaptive.forceOptimizeSkewedJoin 默认:false
解释:如果为true,则强制启用OptimizeSkewedJoin,这是一种自适应规则,用于优化偏斜连接以避免散乱任务,即使它引入了额外的洗牌
相关文章:

SparkSQL-性能调优
祝福 在这个举国同庆的时刻,我们首先献上对祖国的祝福: 第一,我们感谢您给我们和平的环境,让我们能快乐生活 第二,祝福我们国家未来的路越走越宽广,科技更发达,人民更幸福 第三,…...
leetcode-链表篇
leetcode-707 你可以选择使用单链表或者双链表,设计并实现自己的链表。 单链表中的节点应该具备两个属性:val 和 next 。val 是当前节点的值,next 是指向下一个节点的指针/引用。 如果是双向链表,则还需要属性 prev 以指示链表中的…...

JetLinks物联网平台微服务化系列文章介绍
橙蜂智能公司致力于提供先进的人工智能和物联网解决方案,帮助企业优化运营并实现技术潜能。公司主要服务包括AI数字人、AI翻译、AI知识库、大模型服务等。其核心价值观为创新、客户至上、质量、合作和可持续发展。 橙蜂智农的智慧农业产品涵盖了多方面的功能&#x…...

【QT Quick】基础语法:导入外部QML文件
在实际项目中,代码通常分为多个文件进行模块化管理,这样可以方便代码重用,例如统一风格或共享功能模块。我们将在此部分学习如何创建 QML 项目,并演示如何访问外部代码,包括其他 QML 文件、库文件以及 JS 代码。 准备…...

Llama 系列简介与 Llama3 预训练模型推理
1. Llama 系列简介 1.1 Llama1 由 Meta AI 发布,包含 7B、13B、33B 和 65B 四种参数规模的开源基座语言模型 数据集:模型训练数据集使用的都是开源的数据集,总共 1.4T token 模型结构:原始的 Transformer 由编码器(…...

【AIGC】ChatGPT提示词助力自媒体内容创作升级
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | ChatGPT 文章目录 💯前言💯高效仿写专家级文章提示词使用方法 💯CSDN博主账号分析提示词使用方法 💯自媒体爆款文案优化助手提示词使用方法 💯小结 💯…...

SSTI基础
<aside> 💡 简介 </aside> 原理 又名:Flask模版注入 模版种类 **Twig{{7*7}}结果49 jinja2{{7*7}}结果为7777777 //jinja2的常见参数是name smarty7{*comment*}7为77**<aside> 💡 flask实例 </aside> **from …...

10.1软件工程知识详解上
软件工程概述 软件开发生命周期 软件定义时期:包括可行性研究和详细需求分析过程,任务是确定软件开发工程必须完成的总目标,具体可分成问题定义、可行性研究、需求分析等。软件开发时期:就是软件的设计与实现,可分成…...
)
03Frenet与Cardesian坐标系(Frenet转Cardesian公式推导)
Frenet转Cardesian 1 明确目标 已知车辆质点在Frenet坐标系下的状态: Frenet 坐标系下的纵向坐标: s s s纵向速度: s ˙ \dot{s} s˙纵向加速度: s \ddot{s} s横向坐标: l l l横向速度: l ˙ \dot{l} l…...

knowLedge-Vue I18n 是 Vue.js 的国际化插件
1.简介 Vue I18n 是 Vue.js 的国际化插件,它允许开发者根据不同的语言环境显示不同的文本,支持多语言。 Vue I18n主要有两个版本:v8和v9。v8版本适用于Vue2框架。v9版本适用于Vue3框架。 2. 翻译实现原理 Vue I18n 插件通过在 Vue 实例中注…...

【开源免费】基于SpringBoot+Vue.JS微服务在线教育系统(JAVA毕业设计)
本文项目编号 T 060 ,文末自助获取源码 \color{red}{T060,文末自助获取源码} T060,文末自助获取源码 目录 一、系统介绍二、演示录屏三、启动教程四、功能截图五、文案资料5.1 选题背景5.2 国内外研究现状5.3 可行性分析 六、核心代码6.1 查…...

expressjs 中的mysql.createConnection,execute 怎么使用
在 Express.js 应用中使用 MySQL 数据库,你通常会使用 mysql 或 mysql2 这样的库来创建和管理数据库连接,并执行查询。然而,mysql.createConnection 并不直接提供 execute 方法。相反,你可以使用 query 方法来执行 SQL 语句。 以…...

每日一题|983. 最低票价|动态规划、记忆化递归
本题求解最小值,思路是动态规划,但是遇到的问题是:动态规划更新的顺序和步长,以及可能存在的递归溢出问题。 1、确定dp数组含义 dp[i]表示第i天到最后一天(可能不在需要出行的天数里),需要花费…...

oracle 正则 匹配 身份正 手机号
1.正则匹配身份证号: regexp_like(card_id,^[1-9]\d{5}(18|19|20)?\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}(\d|X)$) ^[1-9]\d{5}(18|19|20)?\d{2}(0[1-9]|1[0-2])(0[1-9]|[12]\d|3[01])\d{3}(\d|X)$ ^[1-9]:第一位数字不能为0。 \d{5}:接下来…...
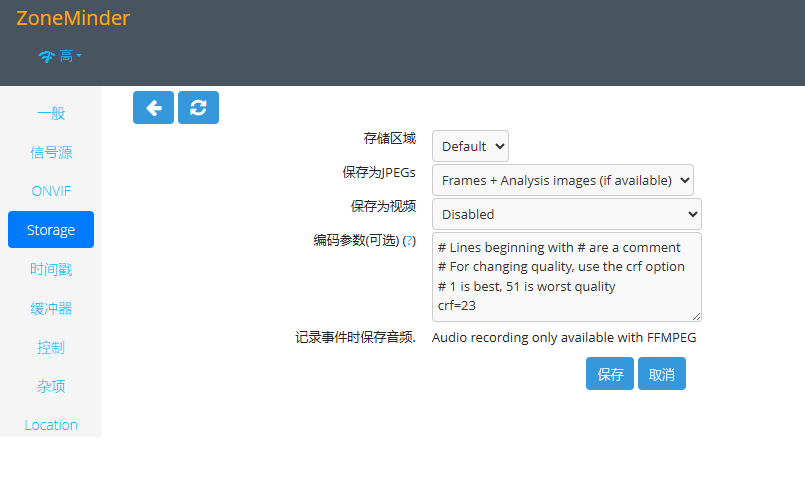
在树莓派上部署开源监控系统 ZoneMinder
原文:https://blog.iyatt.com/?p17425 前言 自己搭建,可以用手里已有的设备,不需要额外买。这套系统的源码是公开的,录像数据也掌握在自己手里,不经过不可控的三方。 支持设置访问账号 可以保存录像,启…...

2022年6月 Frontier 获得性能第一的论文翻译
为百万兆级加速架构做高性能 Linpack 优化 摘要 我们详细叙述了在 rocHPL 中做的性能优化,rocHPL 是 AMD 对 HPL 基准的开源实现,主要是针对节点进行优化的架构,是为百万兆级系统而设计的,比如:Frontier suppercomput…...
B2B商城交易解决方案:赋能企业有效重塑采购与销售新生态
在电商零售领域,商城系统始终是企业搭建商城的关键利器。 伴随着电商行业的蓬勃发展,各类新模式层出不穷,各种商城系统也应运而生,其中B2B商城更是最为常见的一种。 近年来,得益于电子商务的迅猛发展,B2B商…...
)
初始C语言(五)
前言 本文章就代表C语言介绍以及了解正式完成,后续进行具体分析和详细解析学习。知识根深蒂固才可以应付后来的学习,地基要打好,后续才会轻松。 十四、结构体 结构体是C语言中最最重要的知识点,使得C语言有能力描述复杂的类型。 …...
(29))
mysql学习教程,从入门到精通,SQL 修改表(ALTER TABLE 语句)(29)
1、SQL 修改表(ALTER TABLE 语句) 在编写一个SQL的ALTER TABLE语句时,你需要明确你的目标是什么。ALTER TABLE语句用于在已存在的表上添加、删除或修改列和约束等。以下是一些常见的ALTER TABLE语句示例,这些示例展示了如何修改表…...

【网络基础】网络常识快速入门知识清单,看这篇文章就够了
💐个人主页:初晴~ 在现在这个高度智能化的时代,网络几乎已经成为了空气一般无处不在。移动支付、网上购物、网络游戏、视频网站都离不开网络。你能想象如果没有网络的生活将会变成什么样吗🤔 然而如此对于如此重要的网络…...

【从零学Vibe Coding】前言:为什么要写这份教程
前言:为什么要写这份教程 一切从一个画面开始 2025 年,你大概率刷到过这样的画面: 有人对着 AI 说一句"帮我做个记账 App"十几分钟后,页面已经能点、能跳、能保存数据评论区一半人在惊呼"程序员要失业了"另…...

CentOS 8 Stream换源踩坑记:从阿里云到清华源,哪个更适合你的服务器?
CentOS 8 Stream镜像源深度评测:阿里云、清华源与网易163实战对比 当你在凌晨三点被服务器告警吵醒,发现安全补丁因下载超时无法安装时,一个可靠的软件源就成了救命稻草。作为国内使用最广泛的RHEL系社区发行版,CentOS 8 Stream的…...
)
哨兵1号数据处理必备:如何搞定精密轨道文件和SRTM DEM数据(最新可用链接)
哨兵1号数据处理实战:精密轨道与SRTM DEM数据获取全指南 对于从事InSAR或时序分析的遥感研究者而言,数据预处理阶段的轨道校正和地形相位去除是决定成果精度的关键步骤。本文将聚焦哨兵1号SAR数据处理中最核心的两类辅助数据——精密轨道文件和SRTM DEM&…...
/α-萘酚温敏水凝胶,ZnPc/α-Naphthol)
负载锌酞菁(ZnPc)/α-萘酚温敏水凝胶,ZnPc/α-Naphthol
名称:负载锌酞菁(ZnPc)/α-萘酚温敏水凝胶,ZnPc/α-Naphthol 一、材料概览:双重功能的精妙融合 负载锌酞菁(ZnPc)/α-萘酚温敏水凝胶,是将具有优异光催化活性的锌酞菁(Zn…...

探索罗技鼠标宏:掌握PUBG压枪技术的完整路径
探索罗技鼠标宏:掌握PUBG压枪技术的完整路径 【免费下载链接】logitech-pubg PUBG no recoil script for Logitech gaming mouse / 绝地求生 罗技 鼠标宏 项目地址: https://gitcode.com/gh_mirrors/lo/logitech-pubg 在《绝地求生》这款竞技性极强的射击游戏…...

企业级应用如何利用 TaoToken 构建高可用的大模型服务网关
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 企业级应用如何利用 TaoToken 构建高可用的大模型服务网关 应用场景类,探讨在中大型企业应用中,为内部多个…...

EMD vs NEMD:分子动力学算热导率,新手到底该选哪个?
EMD与NEMD方法实战指南:如何为你的热导率计算选择最佳方案 在纳米材料和新型功能材料的研究中,热导率的精确计算是理解材料热输运性能的关键。面对平衡态分子动力学(EMD)和非平衡态分子动力学(NEMD)两种主流方法,许多研究者常常陷入选择困境。…...

Kubernetes Operator开发实战
Kubernetes Operator开发实战 一、Operator概述 Kubernetes Operator是一种软件扩展模式,用于管理复杂的有状态应用。 1.1 Operator模式 ┌──────────────────────────────────────────────────────────…...

Elasticsearch聚合查询优化实战
Elasticsearch聚合查询优化实战 一、聚合查询概述 Elasticsearch的聚合功能是数据分析的核心,支持多种聚合类型来满足不同的分析需求。 1.1 聚合类型 类型说明使用场景Metric指标聚合求和、平均值、最大值、最小值Bucket桶聚合分组统计、区间统计Pipeline管道聚合基…...

从账单明细看 Taotoken 按 Token 计费模式带来的成本控制优势
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 从账单明细看 Taotoken 按 Token 计费模式带来的成本控制优势 1. 成本感知的起点:账单明细结构 对于使用大模型 API 的…...