华为开源自研AI框架昇思MindSpore应用案例:计算高效的卷积模型ShuffleNet
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区
ShuffleNet
ShuffleNet网络介绍
ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到最好的模型精度。ShuffleNetV1的设计核心是引入了两种操作:pointwise group convolution和channel shuffle,这在保持精度的同时大大降低了模型的计算量。因此,ShuffleNetV1和MobileNet类似,都是通过设计更高效的网络结构来实现模型的压缩和加速。
了解ShuffleNet更多详细内容,详见论文:Xiangyu Zhang, Xinyu Zhou, Mengxiao Lin, Jian Sun. "ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
如下图所示,ShuffleNet在保持不低的准确率的前提下,将参数量几乎降低到了最小,因此其运算速度较快,单位参数量对模型准确率的贡献非常高。

图片来源:Bianco S, Cadene R, Celona L, et al. Benchmark analysis of representative deep neural network architectures[J]. IEEE access, 2018, 6: 64270-64277.
模型架构
ShuffleNet最显著的特点在于对不同通道进行重排来解决group convolution带来的弊端。通过对ResNet的bottleneck单元进行改进,在较小的计算量的情况下达到了较高的准确率。
Pointwise Group Convolution
Group Convolution(分组卷积)原理如下图所示,相比于普通的卷积操作,分组卷积的情况下,每一组的卷积核大小为in_channels/g*k*k,一共有g组,所有组共有(in_channels/g*k*k)*out_channels个参数,是正常卷积参数的1/g。分组卷积中,每个卷积核只处理输入特征图的一部分通道,其优点在于参数量会有所降低,但输出通道数仍等于卷积核的数量。
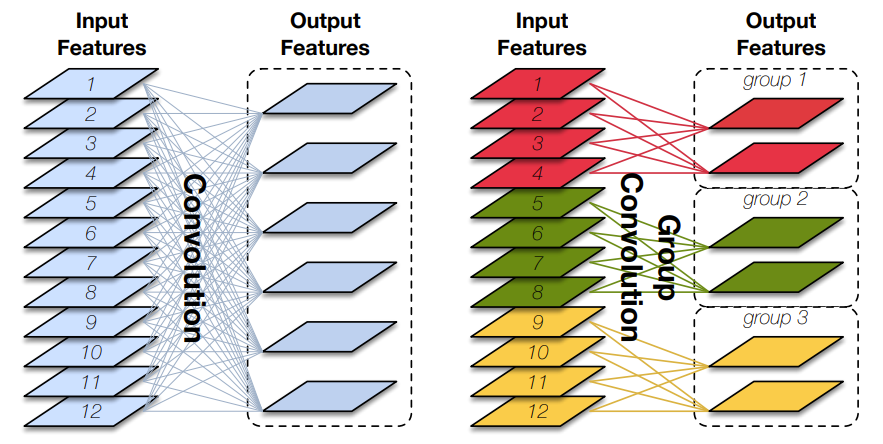
图片来源:Huang G, Liu S, Van der Maaten L, et al. Condensenet: An efficient densenet using learned group convolutions[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 2752-2761.
Depthwise Convolution(深度可分离卷积)将组数g分为和输入通道相等的in_channels,然后对每一个in_channels做卷积操作,每个卷积核只处理一个通道,记卷积核大小为1*k*k,则卷积核参数量为:in_channels*k*k,得到的feature maps通道数与输入通道数相等;
Pointwise Group Convolution(逐点分组卷积)在分组卷积的基础上,令每一组的卷积核大小为1×1,卷积核参数量为(in_channels/g*1*1)*out_channels。
In [1]:
from mindspore import nn import mindspore.ops.operations as P from mindspore import dtype as mstypeclass GroupConv(nn.Cell):def __init__(self, in_channels, out_channels, kernel_size, stride, pad_mode="pad", pad=0, groups=1, has_bias=False):super(GroupConv, self).__init__()self.groups = groupsself.convs = nn.CellList()self.op_split = P.Split(axis=1, output_num=self.groups) # 分割成groups组self.op_concat = P.Concat(axis=1)self.cast = P.Cast()for _ in range(groups):self.convs.append(nn.Conv2d(in_channels // groups, out_channels // groups,kernel_size=kernel_size, stride=stride, has_bias=has_bias,padding=pad, pad_mode=pad_mode, group=1, weight_init='xavier_uniform'))def construct(self, x):features = self.op_split(x) # 将输入x按通道拆分成groups组outputs = ()for i in range(self.groups):outputs = outputs + (self.convs[i](self.cast(features[i], mstype.float32)),)out = self.op_concat(outputs) # 最后拼接起来return out
Channel Shuffle
Group convolution的弊端在于不同组别的通道无法进行信息交流,堆积GConv层后一个问题是不同组之间的特征图是不通信的,这就好像分成了g个互不相干的道路,每一个人各走各的,这可能会降低网络的特征提取能力。这也是Xception,MobileNet等网络采用密集的1x1卷积(dense pointwise convolution)的原因。
为了解决不同组别通道“近亲繁殖”的问题,ShuffleNet优化了大量密集的1x1卷积(在使用的情况下计算量占用率达到了惊人的93.4%),引入Channel Shuffle机制(通道重排)。这项操作直观上表现为将不同分组通道均匀分散重组,使网络在下一层能处理不同组别通道的信息。

如下图所示,对于g组,每组有n个通道的特征图,首先reshape成g行n列的矩阵,再将矩阵转置成n行g列,最后进行flatten操作,得到新的排列。这些操作都是可微分可导的且计算简单,在解决了信息交互的同时符合了shufflenet轻量级网络设计的轻量特征。

为了阅读方便,将channel shuffle的代码实现放在下方ShuffleNet模块的代码中。
ShuffleNet模块
如下图所示,ShuffleNet对ResNet中的bottleneck结构进行由(a)到(b), (c)的更改:
-
将开始和最后的1×1卷积模块(降维、升维)改成point wise group convolution;
-
为了进行不同通道的信息交流,再降维之后进行channel shuffle;
-
降采样模块中,3×3 depthwise convolution的步长设置为2,长宽降为原来的一般,因此shortcut中采用步长为2的3×3平均池化,并把相加改成拼接。

In [2]:
class ShuffleV1Block(nn.Cell):def __init__(self, inp, oup, group, first_group, mid_channels, ksize, stride):super(ShuffleV1Block, self).__init__()self.stride = stridepad = ksize // 2self.group = groupif stride == 2:outputs = oup - inpelse:outputs = oupself.relu = nn.ReLU()self.add = P.Add()self.concat = P.Concat(1)self.shape = P.Shape()self.transpose = P.Transpose()self.reshape = P.Reshape()branch_main_1 = [# pointwise group convolutionGroupConv(in_channels=inp, out_channels=mid_channels, kernel_size=1, stride=1, pad_mode="pad", pad=0,groups=1 if first_group else group),nn.BatchNorm2d(mid_channels),nn.ReLU(),]branch_main_2 = [# depthwise group convolutionnn.Conv2d(mid_channels, mid_channels, kernel_size=ksize, stride=stride, pad_mode='pad', padding=pad, group=mid_channels, weight_init='xavier_uniform', has_bias=False),nn.BatchNorm2d(mid_channels),# pointwise group convolutionGroupConv(in_channels=mid_channels, out_channels=outputs, kernel_size=1, stride=1, pad_mode="pad", pad=0,groups=group),nn.BatchNorm2d(outputs),]self.branch_main_1 = nn.SequentialCell(branch_main_1)self.branch_main_2 = nn.SequentialCell(branch_main_2)if stride == 2:self.branch_proj = nn.AvgPool2d(kernel_size=3, stride=2, pad_mode='same')def construct(self, old_x):left = old_xright = old_xout = old_xright = self.branch_main_1(right)if self.group > 1:right = self.channel_shuffle(right)right = self.branch_main_2(right)if self.stride == 1:out = self.relu(self.add(left, right))elif self.stride == 2:left = self.branch_proj(left)out = self.concat((left, right))out = self.relu(out)return outdef channel_shuffle(self, x):batchsize, num_channels, height, width = self.shape(x)group_channels = num_channels // self.groupx = self.reshape(x, (batchsize, group_channels, self.group, height, width))x = self.transpose(x, (0, 2, 1, 3, 4))x = self.reshape(x, (batchsize, num_channels, height, width))return x
构建shuffleNet网络
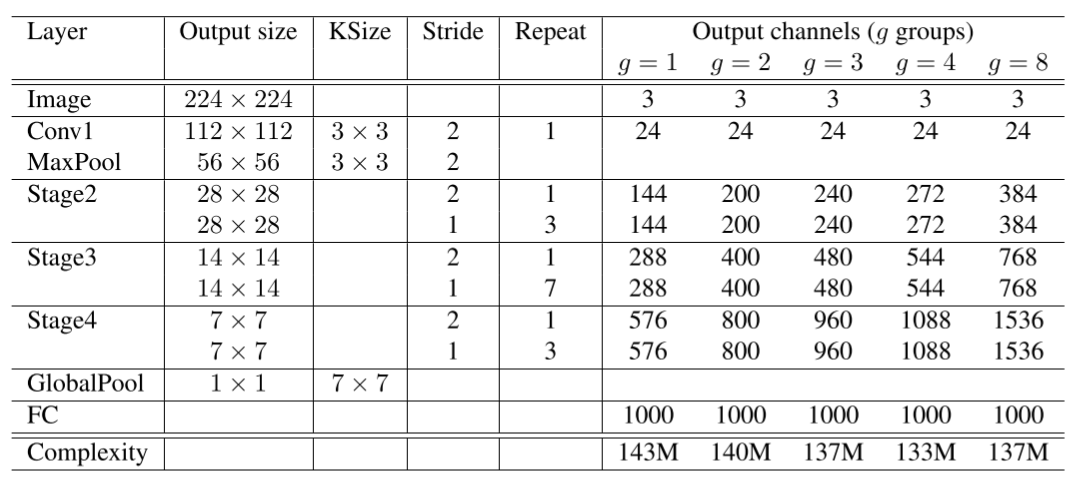
ShuffleNet网络结构如下图所示,以输入图像224×224,组数3(g=3)为例,首先通过数量24,卷积核大小为3×3,stride为2的卷积层,输出特征图大小为112×112,channel为24;然后通过stride为2的最大池化层,输出特征图大小为56×56,channel数不变;再堆叠3个shuffleNet模块(Stage2, Stage3, Stage4),三个模块分别重复4次、8次、4次,其中每个模块开始先经过一次下采样模块(上图(c)),使特征图长宽减半,channel翻倍(Stage2的下采样模块除外,将channel数从24变为240);随后经过全局平均池化,输出大小为1×1×960,再经过全连接层和softmax,得到分类概率。
In [3]:
class ShuffleNetV1(nn.Cell):def __init__(self, n_class=1000, model_size='2.0x', group=3):super(ShuffleNetV1, self).__init__()print('model size is ', model_size)self.stage_repeats = [4, 8, 4]self.model_size = model_sizeif group == 3:if model_size == '0.5x':self.stage_out_channels = [-1, 12, 120, 240, 480]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 240, 480, 960]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 360, 720, 1440]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 480, 960, 1920]else:raise NotImplementedErrorelif group == 8:if model_size == '0.5x':self.stage_out_channels = [-1, 16, 192, 384, 768]elif model_size == '1.0x':self.stage_out_channels = [-1, 24, 384, 768, 1536]elif model_size == '1.5x':self.stage_out_channels = [-1, 24, 576, 1152, 2304]elif model_size == '2.0x':self.stage_out_channels = [-1, 48, 768, 1536, 3072]else:raise NotImplementedError# building first layerinput_channel = self.stage_out_channels[1]self.first_conv = nn.SequentialCell(nn.Conv2d(3, input_channel, 3, 2, 'pad', 1, weight_init='xavier_uniform', has_bias=False),nn.BatchNorm2d(input_channel),nn.ReLU(),)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, pad_mode='same')features = []for idxstage in range(len(self.stage_repeats)):numrepeat = self.stage_repeats[idxstage]output_channel = self.stage_out_channels[idxstage + 2]for i in range(numrepeat):stride = 2 if i == 0 else 1first_group = idxstage == 0 and i == 0features.append(ShuffleV1Block(input_channel, output_channel,group=group, first_group=first_group,mid_channels=output_channel // 4, ksize=3, stride=stride))input_channel = output_channelself.features = nn.SequentialCell(features)self.globalpool = nn.AvgPool2d(7)self.classifier = nn.Dense(self.stage_out_channels[-1], n_class)self.reshape = P.Reshape()def construct(self, x):x = self.first_conv(x)x = self.maxpool(x)x = self.features(x)x = self.globalpool(x)x = self.reshape(x, (-1, self.stage_out_channels[-1]))x = self.classifier(x)return x
模型训练和评估
采用CIFAR-10数据集对ShuffleNet进行预训练。并且为了测试模型在样本数量较少,但尺寸较大的数据集上的迁移性能,用flower_photos数据集对模型进行微调。
训练集准备与加载
采用CIFAR-10数据集对shuffleNet进行预训练。CIFAR-10共有60000张32*32的彩色图像,均匀地分为10个类别,其中50000张图片作为训练集,10000图片作为测试集。如下示例使用mindspore.dataset.Cifar10Dataset接口下载并加载CIFAR-10的训练集。目前仅支持二进制版本(CIFAR-10 binary version)。
In [4]:
import mindspore as ms from mindspore.dataset import Cifar10Dataset from mindspore.dataset import vision, transformsdef get_dataset(train_dataset_path, batch_size, usage):image_trans = []if usage=="train":image_trans = [vision.c_transforms.RandomCrop((32, 32), (4, 4, 4, 4)),vision.c_transforms.RandomHorizontalFlip(prob=0.5),vision.c_transforms.Resize((224, 224)),vision.c_transforms.Rescale(1.0 / 255.0, 0.0),vision.c_transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.c_transforms.HWC2CHW()]elif usage=="test":image_trans = [vision.c_transforms.Resize((224, 224)),vision.c_transforms.Rescale(1.0 / 255.0, 0.0),vision.c_transforms.Normalize([0.4914, 0.4822, 0.4465], [0.2023, 0.1994, 0.2010]),vision.c_transforms.HWC2CHW()]label_trans = transforms.c_transforms.TypeCast(ms.int32)dataset = Cifar10Dataset(train_dataset_path, usage=usage, shuffle=True if usage == "train" else False)dataset = dataset.map(image_trans, 'image')dataset = dataset.map(label_trans, 'label')dataset = dataset.batch(batch_size)return dataset
In [5]:
dataset = get_dataset("./data/cifar10/cifar-10-batches-bin/", 128, "train")
batches_per_epoch = dataset.get_dataset_size()
数据集文件目录结构如下:
In [ ]:
./datasets └── cifar-10-batches-bin├── batches.meta.txt├── data_batch_1.bin├── data_batch_2.bin├── data_batch_3.bin├── data_batch_4.bin├── data_batch_5.bin├── readme.html└── test_batch.bin
模型训练
本节用随机初始化的参数做预训练。首先调用ShuffleNetV1定义网络,参数量选择"2.0x",并定义损失函数为交叉熵损失,学习率经过4轮的warmup后采用余弦退火,优化器采用Momentum. 最后用train.model中的Model接口将模型、损失函数、优化器封装在model中,并用model.train()对网络进行训练。将ModelCheckpoint, CheckpointConfig, TimeMonitor, LossMonitor传入回调函数中,将会打印训练的轮数、损失和时间,并将ckpt文件保存在当前目录下。
In [ ]:
import os
import time
import math
import mindspore
import numpy as np
from mindspore import Tensor, nn
from mindspore.nn.optim.momentum import Momentum
from mindspore.train.model import Model
from src.crossentropysmooth import CrossEntropySmooth
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, TimeMonitor, LossMonitor
from mindspore.train.loss_scale_manager import FixedLossScaleManagerdef get_cosine_lr(lr_init, lr_end, lr_max, warmup_epochs, total_epochs, steps_per_epoch):total_steps = steps_per_epoch * total_epochswarmup_steps = steps_per_epoch * warmup_epochsdecay_steps = total_steps - warmup_stepslr_each_step = []for i in range(total_steps):if i < warmup_steps:lr_inc = (float(lr_max) - float(lr_init)) / float(warmup_steps)lr = float(lr_init) + lr_inc * (i + 1)else:cosine_decay = 0.5 * (1 + math.cos(math.pi * (i-warmup_steps) / decay_steps))lr = (lr_max-lr_end)*cosine_decay + lr_endlr_each_step.append(lr)return lr_each_stepdef train():# Ascend训练,若用GPU,请改成"GPU"device_target = "GPU"mindspore.set_context(mode=mindspore.GRAPH_MODE, device_target=device_target, save_graphs=False)if device_target == "GPU":mindspore.set_context(enable_graph_kernel=True)# context.set_context(device_id=0)# context.set_context(mode=context.GRAPH_MODE, device_target="Ascend", save_graphs=False)# define networknet = ShuffleNetV1(model_size="2.0x", n_class=10)# define lossloss = CrossEntropySmooth(sparse=True, reduction="mean", smooth_factor=0.1, num_classes=10)# get learning ratelr = get_cosine_lr(lr_init=0.00, lr_end=0.50, lr_max=0.50, warmup_epochs=4,total_epochs=250, steps_per_epoch=batches_per_epoch)lr = Tensor(lr)# define optimizationoptimizer = Momentum(params=net.trainable_params(), learning_rate=lr, momentum=0.9,weight_decay=0.00004, loss_scale=1024)# modelloss_scale_manager = FixedLossScaleManager(1024, drop_overflow_update=False)model = Model(net, loss_fn=loss, optimizer=optimizer, amp_level="O3",loss_scale_manager=loss_scale_manager)# define callbackscb = [TimeMonitor(), LossMonitor()]save_ckpt_path = "./"config_ck = CheckpointConfig(save_checkpoint_steps=batches_per_epoch, keep_checkpoint_max=5)ckpt_cb = ModelCheckpoint("shufflenetv1", directory=save_ckpt_path, config=config_ck)cb += [ckpt_cb]print("============== Starting Training ==============")start_time = time.time()# begin trainmodel.train(250, dataset, callbacks=cb, dataset_sink_mode=True)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))print("total time:" + hour + "h " + minute + "m " + second + "s")print("============== Train Success ==============")if __name__ == '__main__':train()
In [ ]:
============== Starting Training ============== epoch: 1 step: 195, loss is 1.7743151187896729 Train epoch time: 191255.396 ms, per step time: 980.797 ms epoch: 2 step: 195, loss is 1.434311866760254 Train epoch time: 85797.786 ms, per step time: 439.989 ms epoch: 3 step: 195, loss is 1.3389689922332764 Train epoch time: 83486.459 ms, per step time: 428.136 ms epoch: 4 step: 195, loss is 1.2366113662719727 Train epoch time: 83831.257 ms, per step time: 429.904 ms epoch: 5 step: 195, loss is 1.1475858688354492 Train epoch time: 84411.272 ms, per step time: 432.878 ms......epoch: 246 step: 195, loss is 0.5449619293212891 Train epoch time: 83016.999 ms, per step time: 425.728 ms epoch: 247 step: 195, loss is 0.5449709892272949 Train epoch time: 84569.001 ms, per step time: 433.687 ms epoch: 248 step: 195, loss is 0.5449811220169067 Train epoch time: 82748.939 ms, per step time: 424.354 ms epoch: 249 step: 195, loss is 0.5449773073196411 Train epoch time: 84571.723 ms, per step time: 433.701 ms epoch: 250 step: 195, loss is 0.5450158715248108 Train epoch time: 84446.256 ms, per step time: 433.058 ms total time:5h 50m 50s ============== Train Success ==============
训练好的模型保存在当前目录的shufflenetv1-250_195.ckpt中,用作评估。
模型评估
在CIFAR-10的测试集上对模型进行评估。
设置好评估模型的路径后加载数据集,并设置Top 1, Top 5的评估标准,最后用model.eval()接口对模型进行评估。
In [8]:
import time
import mindsporefrom mindspore import nn, set_context
from mindspore import load_checkpoint, load_param_into_net
from src.crossentropysmooth import CrossEntropySmooth
from mindspore.train.model import Modeldef test():set_context(mode=mindspore.GRAPH_MODE, device_target="Ascend")# 加载测试集dataset = get_dataset("./data/cifar10/cifar-10-batches-bin/", 128, "test")# define netnet = ShuffleNetV1(model_size="2.0x", n_class=10)# load checkpointparam_dict = load_checkpoint("./ckpt/shufflenetv1-250_195.ckpt")load_param_into_net(net, param_dict)net.set_train(False)# define lossloss = CrossEntropySmooth(sparse=True, reduction="mean", smooth_factor=0.1, num_classes=10)# define modeleval_metrics = {'Loss': nn.Loss(), 'Top_1_Acc': nn.Top1CategoricalAccuracy(),'Top_5_Acc': nn.Top5CategoricalAccuracy()}model = Model(net, loss_fn=loss, metrics=eval_metrics)# start evaluatingstart_time = time.time()res = model.eval(dataset, dataset_sink_mode=False)use_time = time.time() - start_timehour = str(int(use_time // 60 // 60))minute = str(int(use_time // 60 % 60))second = str(int(use_time % 60))log = "result:" + str(res) + ", ckpt:'" + "./shufflenetv1-250_195.ckpt" \+ "', time: " + hour + "h " + minute + "m " + second + "s"print(log)filename = './eval_log.txt'with open(filename, 'a') as file_object:file_object.write(log + '\n')if __name__ == '__main__':test()
model size is 2.0x
result:{'Loss': 0.7009380474875245, 'Top_1_Acc': 0.9434, 'Top_5_Acc': 0.9933}, ckpt:'./shufflenetv1-250_195.ckpt', time: 0h 2m 46s
In [ ]:
result:{'Loss': 0.6998715905042795, 'Top_1_Acc': 0.9434094551282052, 'Top_5_Acc': 0.9932892628205128}, ckpt:'./shufflenetv1-250_195.ckpt', time: 0h 1m 27s
迁移训练
采用flower_photos数据集对预训练好的模型进行迁移训练。flower-photos共有3670张大小不一的彩色图片,分成数目不等的5个类别(每个类别图片数量分别为633, 898, 641, 699, 799张)。因此首先需要对图片进行预处理,将其中80%用于训练,20%用于验证。
In [ ]:
import mindspore.common.dtype as mstype
import mindspore.dataset as ds
import mindspore.dataset.transforms.c_transforms as C2
import mindspore.dataset.vision.c_transforms as Cdef create_flower_dataset(): # 迁移训练的数据集ds.config.set_seed(1)dataset = ds.ImageFolderDataset("./data/flower_photos", num_parallel_workers=6, shuffle=False)train_dataset, eval_dataset = dataset.split([0.8, 0.2], randomize=True)trans = [C.RandomCropDecodeResize(224),C.RandomHorizontalFlip(prob=0.5),C.RandomColorAdjust(brightness=0.4, contrast=0.4, saturation=0.4),C.Normalize(mean=[0.485 * 255, 0.456 * 255, 0.406 * 255], std=[0.229 * 255, 0.224 * 255, 0.225 * 255]),C.HWC2CHW()]evals = [C.Decode(),C.Resize(239),C.CenterCrop(224),C.Normalize(mean=[0.485 * 255, 0.456 * 255, 0.406 * 255], std=[0.229 * 255, 0.224 * 255, 0.225 * 255]),C.HWC2CHW()]type_cast_op = C2.TypeCast(mstype.int32)train_dataset = train_dataset.map(input_columns="image", operations=trans, num_parallel_workers=6)train_dataset = train_dataset.map(input_columns="label", operations=type_cast_op, num_parallel_workers=6)eval_dataset = eval_dataset.map(input_columns="image", operations=evals, num_parallel_workers=6)eval_dataset = eval_dataset.map(input_columns="label", operations=type_cast_op, num_parallel_workers=6)# apply batch operationstrain_dataset = train_dataset.batch(128, drop_remainder=True)eval_dataset = eval_dataset.batch(128, drop_remainder=True)return train_dataset, eval_dataset
数据集文件目录结构如下:
In [ ]:
./flower_photos/ ├── daisy ├── dandelion ├── roses ├── sunflowers └── tulips
迁移训练的实现和预训练几乎完全相同,区别是在batch_size=128的条件下训练100轮。 训练集上最高Top 1准确率达到了0.905,并将模型保存到./ckpt/shufflenetv1_transfer_best.ckpt中。
测试集上Top 1准确率也达到了0.904。
In [ ]:
result:{'Loss': 0.6745888233184815, 'Top_1_Acc': 0.9046875}, ckpt:'./ckpt/shufflenetv1_transfer_best.ckpt', time: 0h 1m 47s相关文章:
华为开源自研AI框架昇思MindSpore应用案例:计算高效的卷积模型ShuffleNet
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区 ShuffleNet ShuffleNet网络介绍 ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到…...

《C++ 小游戏:简易飞机大战游戏的实现》
文章目录 《C 游戏代码解析:简易飞机大战游戏的实现》一、游戏整体结构与功能概述二、各个类和函数的功能分析(一)BK类 - 背景类(二)hero_plane类 - 玩家飞机类(三)plane_bullet类 - 玩家飞机发…...
SpringCloud源码:服务端分析(二)- EurekaServer分析
背景 从昨日的两篇文章:SpringCloud源码:客户端分析(一)- SpringBootApplication注解类加载流程、SpringCloud源码:客户端分析(二)- 客户端源码分析。 我们理解了客户端的初始化,其实…...

插槽slot在vue中的使用
介绍 在 Vue.js 中,插槽(slot)是一种用于实现组件内容分发的功能。通过插槽,可以让父组件在使用子组件时自定义子组件内部的内容。插槽提供了一种灵活的方式来组合和复用组件。 项目中有很多地方需要调用一个组件,比…...

针对考研的C语言学习(定制化快速掌握重点2)
1.C语言中字符与字符串的比较方法 在C语言中,单字符可以用进行比较也可以用 > , < ,但是字符串却不能用直接比较,需要用strcmp函数。 strcmp 函数的原型定义在 <string.h> 头文件中,其定义如下: int strcmp(const …...

[C++][IO流][流输入输出][截断理解]详细讲解
目录 1.流输入输出说明1.<<执行顺序2.>>执行顺序 2.截断(trunc)理解 1.流输入输出说明 1.<<执行顺序 链式操作的顺序:当使用多个<<操作符进行链式插入时,执行顺序是从左到右的 每个<<操作都将数据插入到前一个流的输出中…...

阿里云部署1Panel(失败版)
官网脚本部署不成功 这个不怪1panel,这个是阿里Linux 拉不到docker的下载源,懒得思考 正常部署直接打开官网 https://1panel.cn/docs/installation/online_installation/ 但是我使用的阿里云os(Alibaba Cloud Linux 3.2104 LTS 64位) 我执行不管用啊装不上docker 很烦 curl -s…...

九、设备的分配与回收
1.设备分配时应考虑的因素 ①设备的固有属性 设备的固有属性可分为三种:独占设备、共享设备、虚拟设备。 独占设备 一个时段只能分配给一个进程(如打印机) 共享设备 可同时分配给多个进程使用(如磁盘),各进程往往是宏观上同时共享使用设备而微观上交替使用。 …...

单片机的原理及应用
单片机的原理及应用 1. 单片机的基本原理 1.1. 组成部分 单片机主要由以下几个部分组成: 中央处理器(CPU):执行指令并控制整个系统的操作。 存储器: 程序存储器(Flash):存储用户…...

Python数据分析篇--NumPy--入门
我什么也没忘,但是有些事只适合收藏。不能说,也不能想,却又不能忘。 -- 史铁生 《我与地坛》 NumPy相关知识 1. NumPy,全称是 Numerical Python,它是目前 Python 数值计算中最重要的基础模块。 2. NumPy 是针对多…...

OJ在线评测系统 后端 判题机模块预开发 架构分析 使用工厂模式搭建
判题机模块预开发(架构师)(工厂模式) 判题机模块 是为了把代码交个代码沙箱去处理 得到结果返回 代码沙箱 梳理判题模块和代码沙箱的关系 判题模块:调用代码沙箱 把代码和输入交给代码沙箱去执行 代码沙箱:只负责接受代码和输入 返回编译的结果 不负…...

linux 目录文件夹操作
目录 查看文件夹大小: Linux统计文件个数 2.统计文件夹中文件个数ls -l ./|grep "^-"|wc -l 4.统计文件夹下文件个数,包括子文件ls -lR | grep "^-"| wc -l 统计文件个数 移动绝对目录: 移动相对目录 test.py报错…...

(Linux驱动学习 - 4).Linux 下 DHT11 温湿度传感器驱动编写
DHT11的通信协议是单总线协议,可以用之前学习的pinctl和gpio子系统完成某IO引脚上数据的读与写。 一.在设备树下添加dht11的设备结点 1.流程图 2.设备树代码 (1).在设备树的 iomuxc结点下添加 pinctl_dht11 (2).在根…...

前端登录页面验证码
首先,在el-form-item里有两个div,各占一半,左边填验证码,右边生成验证码 <el-form-item prop"code"><div style"display: flex " prop"code"><el-input placeholder"请输入验证…...
【鸿蒙】HarmonyOS NEXT应用开发快速入门教程之布局篇(上)
系列文章目录 【鸿蒙】HarmonyOS NEXT开发快速入门教程之ArkTS语法装饰器(上) 【鸿蒙】HarmonyOS NEXT开发快速入门教程之ArkTS语法装饰器(下) 【鸿蒙】HarmonyOS NEXT应用开发快速入门教程之布局篇(上) 文…...

使用 Nginx 和 Gunicorn 部署 Flask 项目详细教程
使用 Nginx 和 Gunicorn 部署 Flask 项目详细教程 在这篇文章中,我们将介绍如何使用 Nginx 和 Gunicorn 来部署一个 Flask 项目。这种部署方式非常适合在生产环境中使用,因为它能够提供更好的性能和更高的稳定性。 目录 Flask 项目简介环境准备Gunico…...

linux中bashrc和profile环境变量在Shell编程变量的传递作用
在 Linux 系统中,.bashrc文件和.profile文件都是用于配置用户环境的重要文件,它们之间有以下关联: 一、作用相似性 环境设置:两者都用于设置用户的环境变量和启动应用程序的配置。例如,它们可以定义路径变量…...
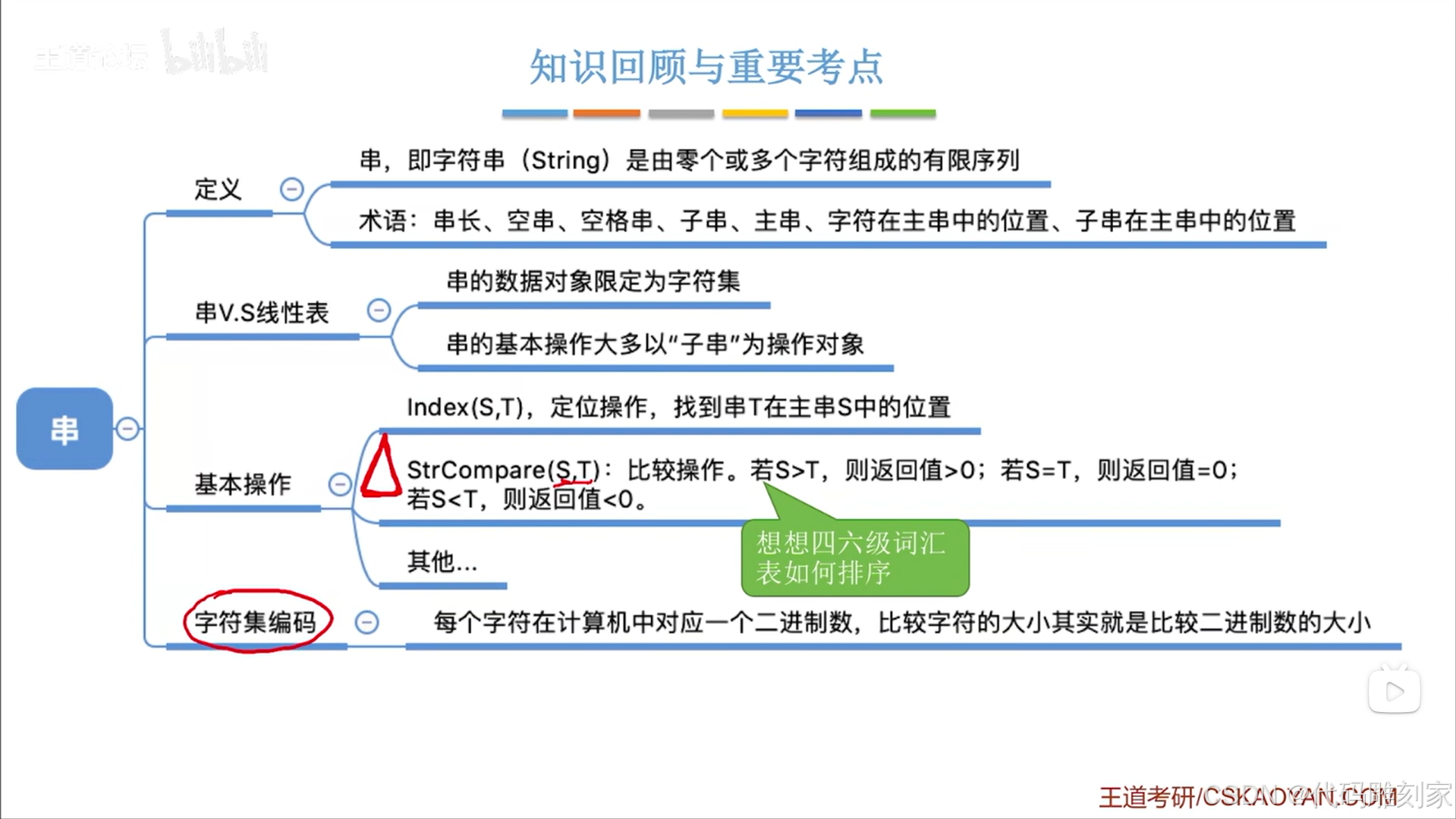
数据结构-4.2.串的定义和基本操作
一.串的定义: 1.单/双引号不是字符串里的内容,他只是一个边界符,用来表示字符串的头和尾; 2.空串也是字符串的子串,空串长度为0; 3.字符的编号是从1开始,不是0; 4.空格也是字符&a…...
fastzdp_redis第一次开发, 2024年9月26日, Python操作Redis零基础快速入门
提供完整录播课 安装 pip install fastzdp_redisPython连接Redis import redis# 建立链接 r redis.Redis(hostlocalhost, port6379, db0)# 设置key r.set(foo, bar)# 获取key的值 print(r.get(foo))RESP3 支持 简单的理解: 支持更丰富的数据类型 参考文档: https://blog.c…...
文件名:\\?\C:\Windows\system32\inetsrv\config\applicationHost.config错误:无法写入配置文件
文件名: \\?\C:\Windows\system32\inetsrv\config\applicationHost.config 错误:无法写入配置文件 解决办法: 到C:\inetpub\history中找到最近一次的【CFGHISTORY_00000000XX】文件,点击进去找到applicationHost.config文件,用其覆盖C:\Win…...

浏览器运行Cursor AI编辑器:Docker+KasmVNC部署全攻略
1. 项目概述:在浏览器中运行 Cursor AI 编辑器如果你是一名开发者,大概率听说过或者正在使用 Cursor——这款集成了强大 AI 辅助编程能力的编辑器。它基于 VS Code,但深度整合了类似 ChatGPT 的对话和代码生成功能,能极大提升编码…...
)
Codex入门10-Goal自主任务(进阶必学:设定目标就不管了,AI自己干活到完成)
🎯 本文目标 掌握 /goal 持久化任务系统,让 Codex 自主完成复杂的大型工作。 🤔 /goal 和普通对话有什么区别? 对比 普通对话 /goal 任务 交互方式 一问一答 设定目标后AI自主工作 持久性 关终端就中断 关终端也能继续 适合任务 小任务、即时反馈 大任务、长期执行 计划…...

从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置
从电机控制到呼吸灯:用STM32CubeMX玩转TIM高级定时器的互补PWM与死区时间配置 在嵌入式开发中,定时器是最基础也最强大的外设之一。对于STM32开发者来说,掌握高级定时器的互补PWM输出和死区时间配置,意味着可以解锁从电机控制到LE…...

离散流匹配与MaskFlow框架:视频生成技术解析
1. 离散流匹配在视频生成中的技术演进 视频生成技术近年来取得了显著进展,但长视频生成仍然面临两大核心挑战:一是如何有效建模视频中复杂的时空动态关系,二是如何在有限的计算资源下实现高效生成。传统方法通常采用固定长度的训练序列&…...
)
ElevenLabs API实战速成:从零部署高保真语音克隆服务,5步完成企业级TTS集成(含实时情感控制代码)
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs超写实语音生成教程 ElevenLabs 是当前业界领先的 AI 语音合成平台,其模型在语调自然度、情感表达力与跨语言一致性方面表现卓越。本章将指导你完成从 API 接入到高质量语音生成的…...

KLayout终极指南:5分钟快速上手开源版图设计工具
KLayout终极指南:5分钟快速上手开源版图设计工具 【免费下载链接】klayout KLayout Main Sources 项目地址: https://gitcode.com/gh_mirrors/kl/klayout KLayout是一款功能强大的开源版图设计工具,专为集成电路(IC)设计和…...

ZeroAPI:基于订阅与任务感知的AI模型智能路由插件设计与实践
1. 项目概述:ZeroAPI,一个为AI订阅服务而生的智能路由插件如果你和我一样,手头订阅了不止一个AI服务——比如OpenAI的ChatGPT Plus、月之暗面的Kimi、智谱AI的GLM,可能还有MiniMax或者通义千问——那你一定遇到过这个烦恼…...

告别混乱XML:Notepad++插件一键美化与智能纠错实战
1. 为什么我们需要XML格式化工具? 作为一个常年和XML打交道的开发者,我太清楚那种打开一个几千行XML文件时的绝望了——所有标签挤在一起,缩进混乱得像被猫抓过的毛线球,想找个节点得用CtrlF来回搜三遍。更可怕的是,有…...

WeChatMsg:如何用开源工具构建你的个人数字记忆库
WeChatMsg:如何用开源工具构建你的个人数字记忆库 【免费下载链接】WeChatMsg 提取微信聊天记录,将其导出成HTML、Word、CSV文档永久保存,对聊天记录进行分析生成年度聊天报告 项目地址: https://gitcode.com/GitHub_Trending/we/WeChatMsg…...

音频AI DSP:低功耗边缘智能的硬件架构与实现
1. 项目概述:当音频AI遇见边缘DSP几年前,如果有人告诉我,一个比指甲盖还小的芯片,能在不到1毫瓦的功耗下,持续监听环境声音、识别特定关键词,甚至能分辨出你是在嘈杂的餐厅还是在安静的办公室,我…...