深度学习:迁移学习
目录
一、迁移学习
1.什么是迁移学习
2.迁移学习的步骤
1、选择预训练的模型和适当的层
2、冻结预训练模型的参数
3、在新数据集上训练新增加的层
4、微调预训练模型的层
5、评估和测试
二、迁移学习实例
1.导入模型
2.冻结模型参数
3.修改参数
4.创建类,数据增强,导入数据
5.定义训练集和测试集函数
6.将模型传入GPU,并有序调整学习率
7.进行训练和测试
一、迁移学习
1.什么是迁移学习
迁移学习是指利用已经训练好的模型,在新的任务上进行微调。迁移学习可以加快模型训练速度,提高模型性能,并且在数据稀缺的情况下也能很好地工作。
2.迁移学习的步骤
1、选择预训练的模型和适当的层
通常,我们会选择在大规模图像数据集(如ImageNet)上预训练的模型,如VGG、ResNet等。然后,根据新数据集的特点,选择需要微调的模型层。对于低级特征的任务(如边缘检测),最好使用浅层模型的层,而对于高级特征的任务(如分类),则应选择更深层次的模型。
2、冻结预训练模型的参数
保持预训练模型的权重不变,只训练新增加的层或者微调一些层,避免因为在数据集中过拟合导致预训练模型过度拟合。
3、在新数据集上训练新增加的层
在冻结预训练模型的参数情况下,训练新增加的层。这样,可以使新模型适应新的任务,从而获得更高的性能。
4、微调预训练模型的层
在新层上进行训练后,可以解冻一些已经训练过的层,并且将它们作为微调的目标。这样做可以提高模型在新数据集上的性能。
5、评估和测试
在训练完成之后,使用测试集对模型进行评估。如果模型的性能仍然不够好,可以尝试调整超参数或者更改微调层。
二、迁移学习实例
- 该实例使用的模型是ResNet-18残差神经网络模型
1.导入模型
- 导入所要用的库,加载ResNet18模型
import torch
import torchvision.models as models
from torch import nn
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import numpy as np"""将resnet18模型迁移到食物分类项目中"""
resent_model = models.resnet18(weights=models.ResNet18_Weights.DEFAULT) # 既调用了resnet18网络,又使用了训练好的模型 在这里下载了模型
2.冻结模型参数
- 将导入的模型参数冻结
for param in resent_model.parameters():param.requires_grad = False # 设置每个参数的requires_grad属性为False,表示在训练过程中这些参数不需要计算梯度,也就是说它们不会在反向传播中更新。# print(param)
# 模型所有参数(即权重和偏差)的requires_grad属性设置为False,从而冻结所有模型参数
# 使得在反向传播过程中不会计算它们的梯度,以此减少模型的计算量,提高理速度。
3.修改参数
- 因为我们所用的数据分类是20个,原模型分类是1000个,所以需要修改全连接层
- 获取原模型输入层的特征个数
- 将原模型的全连接层替换成原输入,输出为20的全连接层
- 保存需要训练的参数,后面优化器进行优化时就可以只训练该层参数
in_features = resent_model.fc.in_features # 获取模型原输入的特征个数
resent_model.fc = nn.Linear(in_features, 20) # 创建一个全连接层,输入特征为in_features,输出为20param_to_update = [] # 保存需要训练的参数,仅仅包含全连接层的参数
for param in resent_model.parameters():if param.requires_grad == True:param_to_update.append(param)
4.创建类,数据增强,导入数据
- 将图片从本地导入,并进行数据增强,最后进行打包
class food_dataset(Dataset):def __init__(self, file_path, transform=None): # 类的初始化,解析数据文件txtself.file_path = file_pathself.imgs = []self.labels = []self.transform = transformwith open(self.file_path) as f: # 是把train.txt文件中图片的路径保存在 self.imgs,train.txt文件中标签保存在self.label里samples = [x.strip().split(' ') for x in f.readlines()] # 去掉首尾空格 再按空格分成两个元素for img_path, label in samples:self.imgs.append(img_path) # 图像的路径self.labels.append(label) # 标签,还不是tensor# 初始化:把图片目录加载到selfdef __len__(self): # 类实例化对象后,可以使用len函数测量对象的个数return len(self.imgs)def __getitem__(self, idx): # 关键,可通过索引的形式获取每一个图片数据及标签image = Image.open(self.imgs[idx]) # 读取到图片数据,还不是tensorif self.transform:# 将pil图像数据转换为tensorimage = self.transform(image) # 图像处理为256x256,转换为tenorlabel = self.labels[idx] # label还不是tensorlabel = torch.from_numpy(np.array(label, dtype=np.int64)) # label也转换为tensorreturn image, labeldata_transforms = {'train':transforms.Compose([transforms.Resize([300, 300]),transforms.RandomRotation(45),transforms.CenterCrop(224),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.5),# transforms.ColorJitter(brightness=0.2, contrast=0.1, saturation=0.1, hue=0.1),transforms.RandomGrayscale(p=0.1),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 为 ImageNet 数据集计算的标准化参数]),'test':transforms.Compose([transforms.Resize([224, 224]),transforms.ToTensor(),transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]) # 为 ImageNet 数据集计算的标准化参数])
}train_data = food_dataset(file_path=r'trainda.txt',transform=data_transforms['train']) # 64张图片为一个包 训练集60000张图片 打包成了938个包
test_data = food_dataset(file_path=r'testda.txt', transform=data_transforms['test'])train_dataloader = DataLoader(train_data, batch_size=64, shuffle=True)
test_dataloader = DataLoader(test_data, batch_size=64, shuffle=True)
5.定义训练集和测试集函数
def train(dataloader, model, loss_fn, optimizer):model.train() # 告诉模型,我要开始训练,模型中w进行随机化操作,已经更新w.在训练过程中,w会被修改的batch_size_num = 1for x, y in dataloader:x, y = x.to(device), y.to(device) # 把训练数据集和标签传入CPU或GPUpred = model.forward(x) # 向前传播loss = loss_fn(pred, y) # 通过交叉熵损失函数计算损失值lossoptimizer.zero_grad() # 梯度值清零loss.backward() # 反向传播计算得到每个参数的梯度值woptimizer.step() # 根据梯度更新网络w参数loss_value = loss.item() # 从tensor数据中提取数据出来,tensor获取损失值if batch_size_num % 40 == 0:print(f"loss:{loss_value:>7f} [number:{batch_size_num}]")batch_size_num += 1best_acc = 0def test(dataloader, model, loss_fn):global best_accsize = len(dataloader.dataset)num_batches = len(dataloader)model.eval() # 测试,w就不能再更新。test_loss, correct = 0, 0with torch.no_grad(): # 一个上下文管理器,关闭梯度计算。当你确认不会调用Tensor.backward()的时候。这可以减少计算所占用的消耗for x, y in dataloader:x, y = x.to(device), y.to(device)pred = model.forward(x)test_loss += loss_fn(pred, y).item() # test loss是会自动累加每一个批次的损失值correct += (pred.argmax(1) == y).type(torch.float).sum().item()test_loss /= num_batches # 能来衡量模型测试的好坏。correct /= size # 平均的正确率print(f"Test result: \n Accuracy: {(100 * correct)}%, Avg loss: {test_loss}\n")acc_s.append(correct)loss_s.append(test_loss)if correct > best_acc: # 保存正确率最大的那一次的模型best_acc = correct
6.将模型传入GPU,并有序调整学习率
from torch import nndevice = 'cuda' if torch.cuda.is_available() else 'mps' if torch.backends.mps.is_avaibale() else 'cpu'
model = resent_model.to(device) # 为什么不需要加括号,之前是model = CNN().to(device) 因为 resnet_model 是对象不是类"""有序调整学习率"""
loss_fn = nn.CrossEntropyLoss() # 处理多分类
optimizer = torch.optim.Adam(param_to_update, lr=0.001) # 仅训练最后一层的参数
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=5, gamma=0.5) # 调整学习率
7.进行训练和测试
- 选择训练100轮,每训练一轮,输出测试结果
epchos = 100
acc_s = []
loss_s = []
for t in range(epchos):print(f"Epoch {t + 1}\n--------------------------")train(train_dataloader, model, loss_fn, optimizer)scheduler.step()test(test_dataloader, model, loss_fn)
print('最优测试结果为:', best_acc)
输出:

相关文章:
深度学习:迁移学习
目录 一、迁移学习 1.什么是迁移学习 2.迁移学习的步骤 1、选择预训练的模型和适当的层 2、冻结预训练模型的参数 3、在新数据集上训练新增加的层 4、微调预训练模型的层 5、评估和测试 二、迁移学习实例 1.导入模型 2.冻结模型参数 3.修改参数 4.创建类ÿ…...

Footprint Growthly Quest 工具:赋能 Telegram 社区实现 Web3 飞速增长
作者:Stella L (stellafootprint.network) 在 Web3 的快节奏世界里,社区互动是关键。而众多 Web3 社区之所以能够蓬勃发展,很大程度上得益于 Telegram 平台。正因如此,Footprint Analytics 精心打造了 Growthly —— 一款专为 Tel…...

进入xwindows后挂起键盘鼠标没有响应@FreeBSD
问题: 在升级pkg包后,系统无法进入xfce等xwindows,表现为黑屏和看见鼠标,左上角有一个白字符块,键盘鼠标没有反应,整个系统卡住。但是可以ssh登录,内部的服务一切正常。 表现 处理过程…...

CentOS7.9 snmptrapd更改162端口
端口更改前: 命令: netstat -an |grep 162 [root@kibana snmp]# netstat -an | grep 162 udp 0 0 0.0.0.0:162 0.0.0.0:* unix 3 [ ] STREAM CONNECTED 45162 /run/systemd/journal/stdout u…...

模糊测试SFuzz亮相第32届中国国际信息通信展览会
9月25日,被誉为“中国ICT市场的创新基地和风向标”的第32届中国国际信息通信展在北京盛大开幕,本次展会将在为期三天的时间内,为信息通信领域创新成果、尖端技术和产品提供国家级交流平台。开源网安携模糊测试产品及相关解决方案精彩亮相&…...

CMake学习
向大佬lyf学习,先把其8服务器中所授fine 文章目录 前言一、CMakeList.txt 命令1. 最外层CMakeLists1.1 cmake_minimum_required()1.2 project()1.3 set()1.4 add_subdirectory(&…...

书生·浦语大模型全链路开源开放体系
书生浦语大模型全链路开源开放体系 大模型应用生态的发展和繁荣是建立在模型基座强大的通用基础能力之上的。上海AI实验室联合团队研究认为,大模型各项性能提升的基础在于语言建模能力的增强,对于大模型的研究应回归语言建模本质,通过更高质量…...

PHP安装swoole扩展无效,如何将文件上传至Docker容器
目录 过程 操作方式 过程 在没有使用过云服务器以前,Docker这个平台一直都很神秘。在我申请了华为云服务器,并使用WordPress镜像去搭建自己的网站以后,我不得不去把Docker平台弄清楚,原因是我使用的一个主题需要安装swoole扩展,才能够正常启用。而要将swoole.so这个扩展…...

Web3.0 应用项目
Web3.0 是下一代互联网的概念,旨在去中心化、用户拥有数据控制权和通过区块链技术实现信任的网络。Web3.0的应用项目主要集中在区块链、加密货币、去中心化应用 (DApps)、去中心化金融 (DeFi)、NFT(非同质化代币)等领域。以下是一些典型的 We…...
—— 重定向与缓冲区)
Linux 学习笔记(十六)—— 重定向与缓冲区
一、文件重定向 矩阵的下标,也就是文件描述符的分配规则,是从0开始空的最小的文件描述符分配给进程新打开的文件;文件输出重定向的原理是,关掉1(输出),然后打开文件,这个新打开的文…...

828华为云征文|WordPress部署
目录 前言 一、环境准备 二、远程连接 三、WordPress简介 四、WordPress安装 1. 基础环境安装 编辑 2. WordPress下载与解压 3. 创建站点 4. 数据库配置 总结 前言 WordPress 是一个非常流行的开源内容管理系统(Content Management System, CMS…...
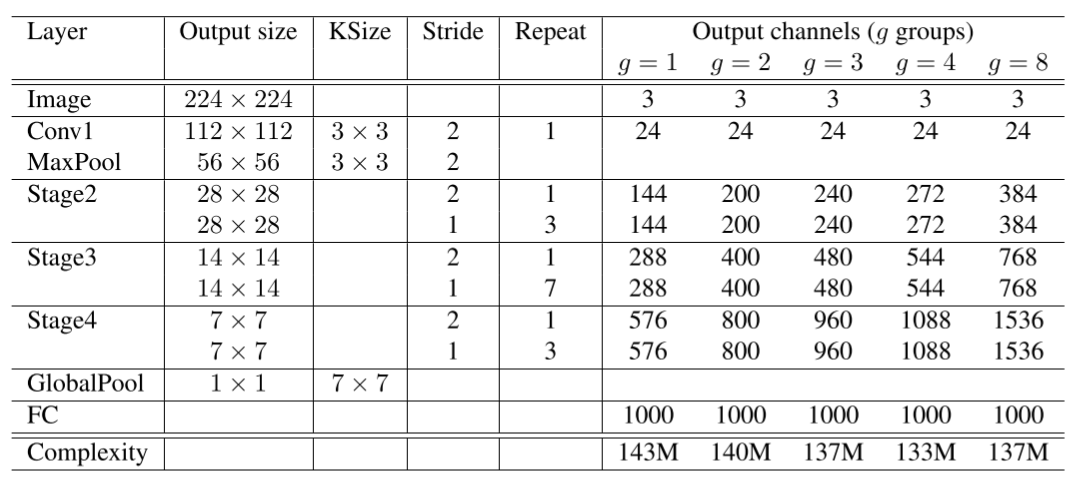
华为开源自研AI框架昇思MindSpore应用案例:计算高效的卷积模型ShuffleNet
如果你对MindSpore感兴趣,可以关注昇思MindSpore社区 ShuffleNet ShuffleNet网络介绍 ShuffleNetV1是旷视科技提出的一种计算高效的CNN模型,和MobileNet, SqueezeNet等一样主要应用在移动端,所以模型的设计目标就是利用有限的计算资源来达到…...

《C++ 小游戏:简易飞机大战游戏的实现》
文章目录 《C 游戏代码解析:简易飞机大战游戏的实现》一、游戏整体结构与功能概述二、各个类和函数的功能分析(一)BK类 - 背景类(二)hero_plane类 - 玩家飞机类(三)plane_bullet类 - 玩家飞机发…...
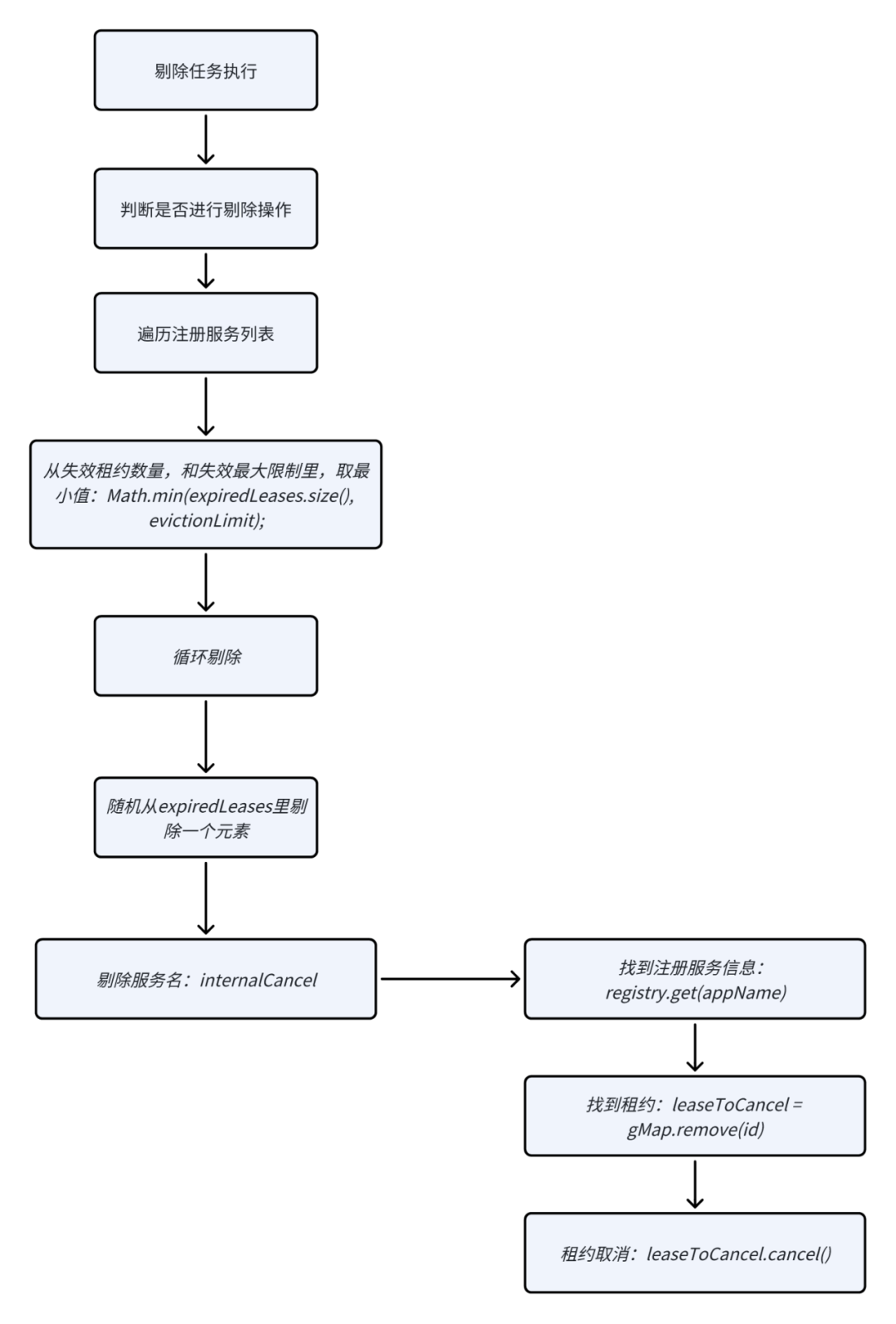
SpringCloud源码:服务端分析(二)- EurekaServer分析
背景 从昨日的两篇文章:SpringCloud源码:客户端分析(一)- SpringBootApplication注解类加载流程、SpringCloud源码:客户端分析(二)- 客户端源码分析。 我们理解了客户端的初始化,其实…...

插槽slot在vue中的使用
介绍 在 Vue.js 中,插槽(slot)是一种用于实现组件内容分发的功能。通过插槽,可以让父组件在使用子组件时自定义子组件内部的内容。插槽提供了一种灵活的方式来组合和复用组件。 项目中有很多地方需要调用一个组件,比…...

针对考研的C语言学习(定制化快速掌握重点2)
1.C语言中字符与字符串的比较方法 在C语言中,单字符可以用进行比较也可以用 > , < ,但是字符串却不能用直接比较,需要用strcmp函数。 strcmp 函数的原型定义在 <string.h> 头文件中,其定义如下: int strcmp(const …...

[C++][IO流][流输入输出][截断理解]详细讲解
目录 1.流输入输出说明1.<<执行顺序2.>>执行顺序 2.截断(trunc)理解 1.流输入输出说明 1.<<执行顺序 链式操作的顺序:当使用多个<<操作符进行链式插入时,执行顺序是从左到右的 每个<<操作都将数据插入到前一个流的输出中…...

阿里云部署1Panel(失败版)
官网脚本部署不成功 这个不怪1panel,这个是阿里Linux 拉不到docker的下载源,懒得思考 正常部署直接打开官网 https://1panel.cn/docs/installation/online_installation/ 但是我使用的阿里云os(Alibaba Cloud Linux 3.2104 LTS 64位) 我执行不管用啊装不上docker 很烦 curl -s…...

九、设备的分配与回收
1.设备分配时应考虑的因素 ①设备的固有属性 设备的固有属性可分为三种:独占设备、共享设备、虚拟设备。 独占设备 一个时段只能分配给一个进程(如打印机) 共享设备 可同时分配给多个进程使用(如磁盘),各进程往往是宏观上同时共享使用设备而微观上交替使用。 …...

单片机的原理及应用
单片机的原理及应用 1. 单片机的基本原理 1.1. 组成部分 单片机主要由以下几个部分组成: 中央处理器(CPU):执行指令并控制整个系统的操作。 存储器: 程序存储器(Flash):存储用户…...

实测:2026 年国内直连 AI 一站式平台,聊天 / 绘画 / 论文 / 视频全搞定,不用翻墙不花冤枉钱
最近 AI 圈真的太卷了。ChatGPT 5.4、Gemini 3.1、Claude Code 轮番上新,多模态、长文本、代码 Auto Mode 一个比一个强。但普通用户想用明白,真的太折腾。先说说我踩过的三大坑,句句大实话网络糟心到崩溃官网打不开、地区不可用、加载转圈、…...

告别环境报错!保姆级教程:从JRE到STM32CubeMX 6.10.0的完整安装与配置
从零搭建STM32开发环境:CubeMX 6.10.0避坑全指南 刚拿到STM32开发板时的兴奋,往往在环境配置阶段就被各种报错消磨殆尽。作为过来人,我深刻理解那种看着红色错误提示却无从下手的挫败感。本文将带你用最稳妥的方式完成从Java环境到CubeMX的全…...

Midjourney咖啡印相落地实操:3步完成色彩校准、5种纸张适配方案与打印机ICC配置清单
更多请点击: https://intelliparadigm.com 第一章:Midjourney Coffee印相技术原理与工艺边界 Midjourney Coffee印相并非官方命名的技术标准,而是社区对一类融合生成式AI图像(如Midjourney输出)与传统咖啡渍显影工艺的…...

从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机
从SolidWorks到Simulink:手把手教你用Simscape Multibody Link搭建你的第一个虚拟样机 虚拟样机技术正在彻底改变传统机电系统的开发流程。想象一下,你刚刚在SolidWorks中完成了一个精巧的自动门闭锁装置的设计,现在不需要花费数周时间加工金…...

如何在Chrome浏览器中快速生成与扫描二维码:终极免费插件指南
如何在Chrome浏览器中快速生成与扫描二维码:终极免费插件指南 【免费下载链接】chrome-qrcode :zap: A Chrome plugin to Genrate QRCode of URL / Text, or Decode the QRcode in website. 一个Chrome浏览器插件,用于生成当前URL或者选中内容的二维码&a…...

redis之典型应用-缓存cache
什么是缓存缓存 (cache) 是计算机中的一个经典的概念. 在很多场景中都会涉及到. 核心思路就是把一些常用的数据放到触手可及(访问速度更快)的地方, 方便随时读取。大部分的时候, 缓存只放一些 热点数据 (访问频繁的数据),对于硬件的访问速度来说, 通常情况下: CPU 寄存器 > …...

ComfyUI-Impact-Pack深度解析:从AI图像模糊到专业级细节增强的完整解决方案
ComfyUI-Impact-Pack深度解析:从AI图像模糊到专业级细节增强的完整解决方案 【免费下载链接】ComfyUI-Impact-Pack Custom nodes pack for ComfyUI This custom node helps to conveniently enhance images through Detector, Detailer, Upscaler, Pipe, and more. …...

3分钟快速上手:SillyTavern如何让你成为AI聊天高手
3分钟快速上手:SillyTavern如何让你成为AI聊天高手 【免费下载链接】SillyTavern LLM Frontend for Power Users. 项目地址: https://gitcode.com/GitHub_Trending/si/SillyTavern 你是否厌倦了千篇一律的AI对话界面?想要一个能真正理解你需求、支…...

Gemini 辅助做创意写作:故事大纲、角色设定、世界观构建的 AI 协作
很多作者在创作卡壳时,其实不是“没有灵感”,而是缺一套可迭代的设计流程:大纲松散、角色像说明书、世界观看似宏大却前后不一致。2026 年的写作新趋势,是把 Gemini 当作“创作协作伙伴”而不是“代写引擎”,让它参与结…...

WindowsCleaner终极指南:3步告别C盘爆红,让Windows重获新生
WindowsCleaner终极指南:3步告别C盘爆红,让Windows重获新生 【免费下载链接】WindowsCleaner Windows Cleaner——专治C盘爆红及各种不服! 项目地址: https://gitcode.com/gh_mirrors/wi/WindowsCleaner 你是否经常遇到C盘变红的警告&…...