论文阅读:PET/CT Cross-modal medical image fusion of lung tumors based on DCIF-GAN
摘要
背景:
基于GAN的融合方法存在训练不稳定,提取图像的局部和全局上下文语义信息能力不足,交互融合程度不够等问题
贡献:
提出双耦合交互式融合GAN(Dual-Coupled Interactive Fusion GAN,DCIF-GAN):
- 设计了双生成器双鉴别器GAN,通过权值共享机制实现生成器之间和鉴别器之间的耦合,通过全局自注意力机制实现交互式融合;
- 设计耦合CNN-Transformer的特征提取模块(Coupled CNN-T ransformer Feature Extraction Module, CC-TFEM)和特征重构模块(CNN-T ransformer F eature Reconstruction Module, C-TFRM),提升了对同一模态图像内部的局部和全局特征信息提取能力;
- 设计跨模态交互式融合模块(Cross Model Intermodal Fusion Module, CMIFM),通过跨模态自注意力机制,进一步整合不同模态间的全局交互信息。
结果:
在肺部肿瘤PET/CT医学图像数据集上进行实验,模型能够突出病变区域信息,融合图像结构清晰且纹理细节丰富。
1. 引言
-
CT——结构信息,分辨率高
-
PET——功能信息
-
传统:Fusion GAN、FLGC-Fusion GAN
-
双判别器:D2WGAN、DDcGAN、DFPGAN
-
多生成器多判别器:MGMDcGAN、RCGAN
贡献:
- 提出跨模态耦合生成器,处理PET图像中的病灶目标和CT图像中丰富的纹理特征,学习跨模态图像之间的联合分布;提出跨模态耦合鉴别器分别用于计算预融合图像与CT和PET图像间的结构差异,并使训练过程更加稳定。
- 设计耦合CNN-Transformer特征提取模块和CNN-Transformer特征重构模块,结合了Transformer和CNN的优势,在挖掘源图像中局部信息的同时也能学习特征之间的全局交互信息,实现更好的跨模态互补语义信息集成。
- 提出基于SwinTransformer的跨模态交互式融合模块,通过跨模态自注意力机制,可以进一步整合不同模态图像之间的全局交互信息。
2. 双耦合交互式融合DCIF-GAN
2.1 整体网络结构
网络结构:
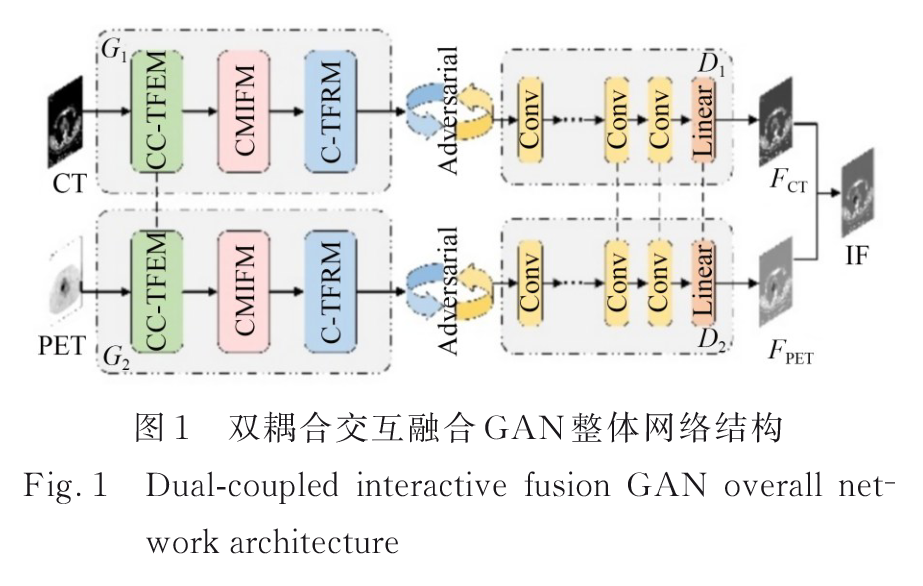
生成器由基于耦合CNN-Transformer的特征提取模块、跨模态与融合模块和基于联合CNN-Transformer的特征重构模块构成。
鉴别器由四个卷积块和一个Linear层构成,鉴别器的“耦合”通过网络最后几层共享权值,此操作可以有效降低网络的参数量。
关键:权值共享
第一生成器G1的目的是生成具有CT图像纹理信息的预融合图像FCT,
第一鉴别器D1的目的是计算FCT与源PET图像的相对偏移量并反馈,以增强FCT中的功能信息;
第二生成器G2用于生成具有PET图像功能信息的预融合图像FPET,
第二鉴别器D2计算FPET与源CT图像的相对偏移量并反馈,以增强FPET中的纹理信息。
随着迭代次数的增加,两个生成器都可以生成足以欺骗鉴别器的预融合图像,生成的图像分别会相对偏向于其中一幅源图像,故将生成的两幅预融合图像进行加权融合,得到最终的融合图像IF。
网络的极大极小博弈可以表示为:
min G 1 , G 2 max D 1 , D 2 L ( G 1 , G 2 , D 1 , D 2 ) = E I P E T [ log D 1 ( I P E T ) ] + E I C T [ log ( 1 − D 1 ( G 1 ( I C T ) ) ) ] + E I C T [ log D 2 ( I C T ) ] + E I P E T [ log ( 1 − D 2 ( G 2 ( I P E T ) ) ) ] \begin{aligned} \min_{G_1, G_2} \max_{D_1, D_2} L(G_1, G_2, D_1, D_2) = \mathbb{E}_{I_{PET}} \left[ \log D_1(I_{PET}) \right] + \mathbb{E}_{I_{CT}} \left[ \log (1 - D_1(G_1(I_{CT}))) \right] + \mathbb{E}_{I_{CT}} \left[ \log D_2(I_{CT}) \right] + \mathbb{E}_{I_{PET}} \left[ \log (1 - D_2(G_2(I_{PET}))) \right] \end{aligned} G1,G2minD1,D2maxL(G1,G2,D1,D2)=EIPET[logD1(IPET)]+EICT[log(1−D1(G1(ICT)))]+EICT[logD2(ICT)]+EIPET[log(1−D2(G2(IPET)))]
2.2 耦合生成器结构
生成器网络结构:
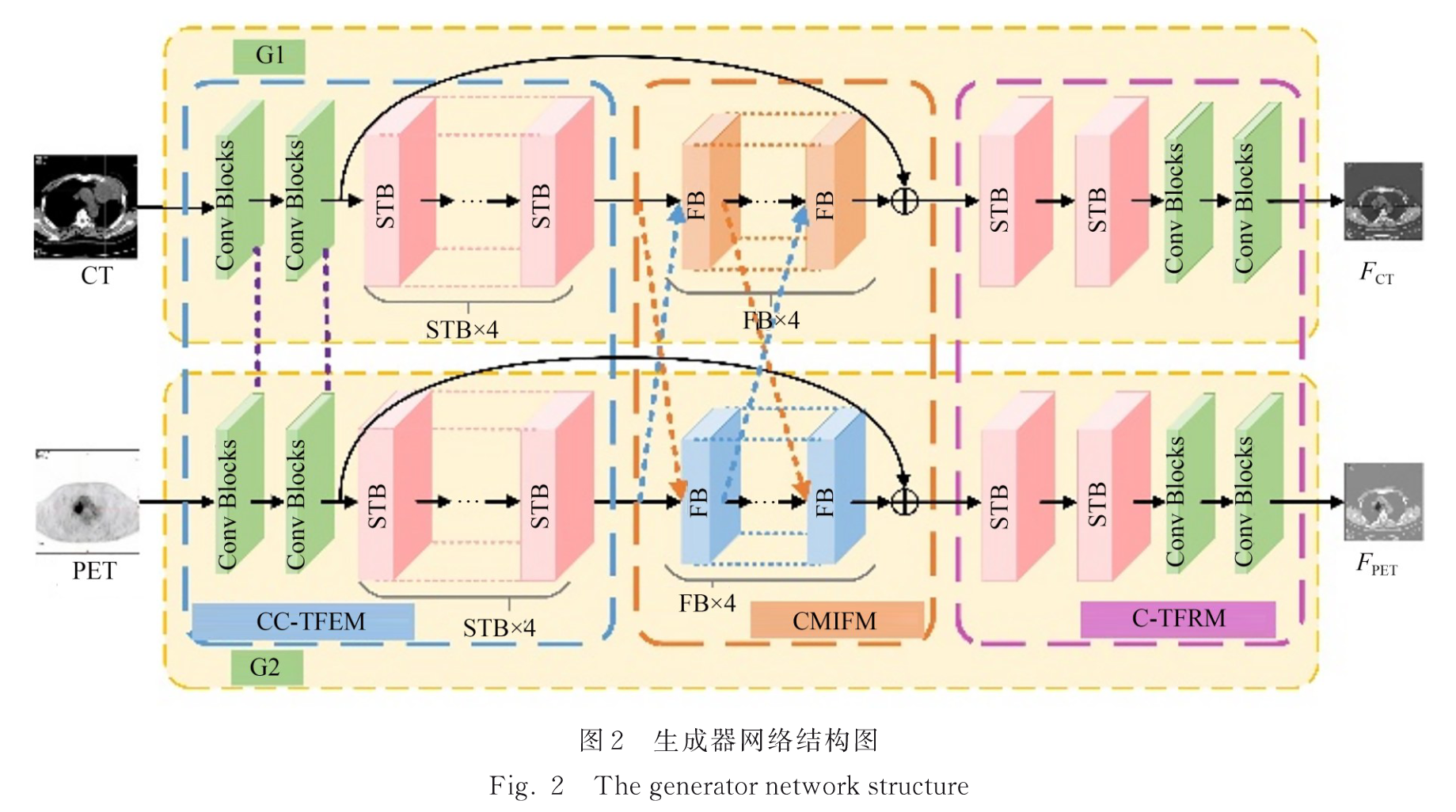
CNN能简单有效提取信息,但感受野有限,捕捉全局背景信息能力弱;
Transformer将整个图像转换为一维向量组输入(解决感受野有限),使用自注意力捕获全局信息(解决只提取局部信息),但全局信息的秩低,降低了前景和背景的可辨别性,融合不明显。
2.2.1 耦合CNN-Transformer特征提取模块(CC-TFEM)
基于CNN的浅层特征提取,局部特征;
基于Swin-Transformer的深层特征提取,全局特征。
2个卷积块+4个STB块
卷积块:一个卷积层(size=3, stride=1)+一个Leaky ReLU层
两个生成器权值共享:
- 有助于学习多模态图像的联合分布;
- 减少参数量。
通过浅层特征提取模块HSE(.)提取源图像 I C T I_{CT} ICT和 I P E T I_{PET} IPET的浅层特征 F S F C T F^{CT}_{SF} FSFCT和 F S F P E T F^{PET}_{SF} FSFPET;
通过深度特征提取模块HDE(.)从 F S F C T F^{CT}_{SF} FSFCT和 F S F P E T F^{PET}_{SF} FSFPET中提取深度特征;
将 F D F C T F^{CT}_{DF} FDFCT和 F D F P E T F^{PET}_{DF} FDFPET输人到跨模态预融合模块(CMIFM)中进行融合。
表述为:
[ F S F C T , F S F P E T ] = [ H S E ( I C T ) , H S E ( I P E T ) ] \begin{bmatrix} F^{CT}_{SF} , F^{PET}_{SF} \end{bmatrix} = \begin{bmatrix} H_{SE}(I_{CT}) , H_{SE}(I_{PET}) \end{bmatrix} [FSFCT,FSFPET]=[HSE(ICT),HSE(IPET)]
[ F D F C T , F D F P E T ] = [ H D E ( F S F C T ) , H D E ( F S F P E T ) ] \begin{bmatrix} F^{CT}_{DF} , F^{PET}_{DF} \end{bmatrix} = \begin{bmatrix} H_{DE}(F^{CT}_{SF}) , H_{DE}(F^{PET}_{SF}) \end{bmatrix} [FDFCT,FDFPET]=[HDE(FSFCT),HDE(FSFPET)]
特征提取模块:
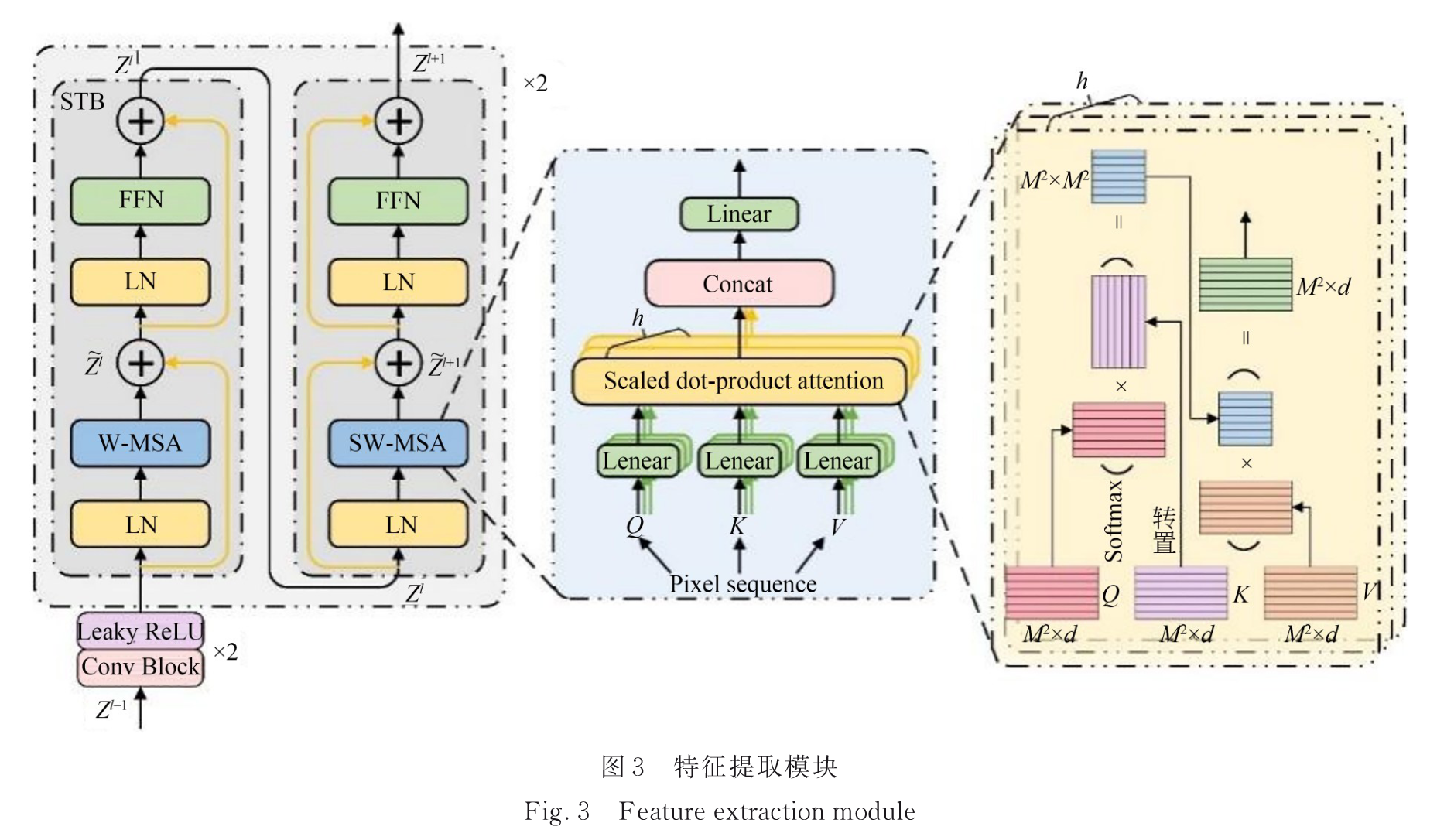
Swin Transformer的局部注意力和窗口机制有效地降低了计算量。
W-MSA(Weighted Multi-Head Self-Attention)将输入特征 F H × W × C F^{H×W×C} FH×W×C划分为不重叠的 M × M M×M M×M的局部窗口,重构为 H W M 2 × M 2 × C \frac{HW}{M^2} \times M^2 \times C M2HW×M2×C;每个窗口执行自注意力操作,局部窗口特征 X ∈ R M 2 × C X \in \mathbb{R}^{M^2 \times C} X∈RM2×C,经过三个线性变换矩阵 W Q ∈ R M 2 × C W^Q \in \mathbb{R}^{M^2 \times C} WQ∈RM2×C, W K ∈ R M 2 × C W^K \in \mathbb{R}^{M^2 \times C} WK∈RM2×C, W V ∈ R M 2 × C W^V \in \mathbb{R}^{M^2 \times C} WV∈RM2×C投影到Q,K,V:
[ Q , K , V ] = [ X W Q , X W K , X W V ] [Q, K, V] = [XW^Q, XW^K, XW^V] [Q,K,V]=[XWQ,XWK,XWV]
注意力权重为:
Attention ( Q , K , V ) = softmax ( Q K T d k + B ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_k}} + B\right)V Attention(Q,K,V)=softmax(dkQKT+B)V
d k d_k dk是建的维数,B是相对位置编码。
多头自注意力并行执行h次注意函数,并将每个注意力头的结果连接起来。
通过由两个多层感知器(MLP)层组成的前馈网络(Feed Forward Network, FFN)来细化W-MSA产生的特征向量,表述为:
Z ~ l = MSA ( LN ( Z l − 1 ) ) + Z l − 1 \tilde{Z}^l = \text{MSA}(\text{LN}(Z^{l-1})) + Z^{l-1} Z~l=MSA(LN(Zl−1))+Zl−1
Z l = FFN ( LN ( Z ~ l ) ) + Z ~ l \quad Z^l = \text{FFN}(\text{LN}(\tilde{Z}^l)) + \tilde{Z}^l Zl=FFN(LN(Z~l))+Z~l
前馈网络FNN(∙),表述为:
F F N ( X ) = G E L U ( W 1 + b 1 ) W 2 + b 2 FFN ( X ) = GELU (W_1 + b_1 ) W_2 + b_2 FFN(X)=GELU(W1+b1)W2+b2
GELU为高斯误差线性单元。

Swin Transformer 层计算注意力的滑动窗口机制,W-MSA的弊端在于窗口之间的相互作用较弱,引人SW-MSA模块,向左上方向循环移动,产生新的批窗口。
2.2.2 跨模态交互式融合模块(CMIFM)
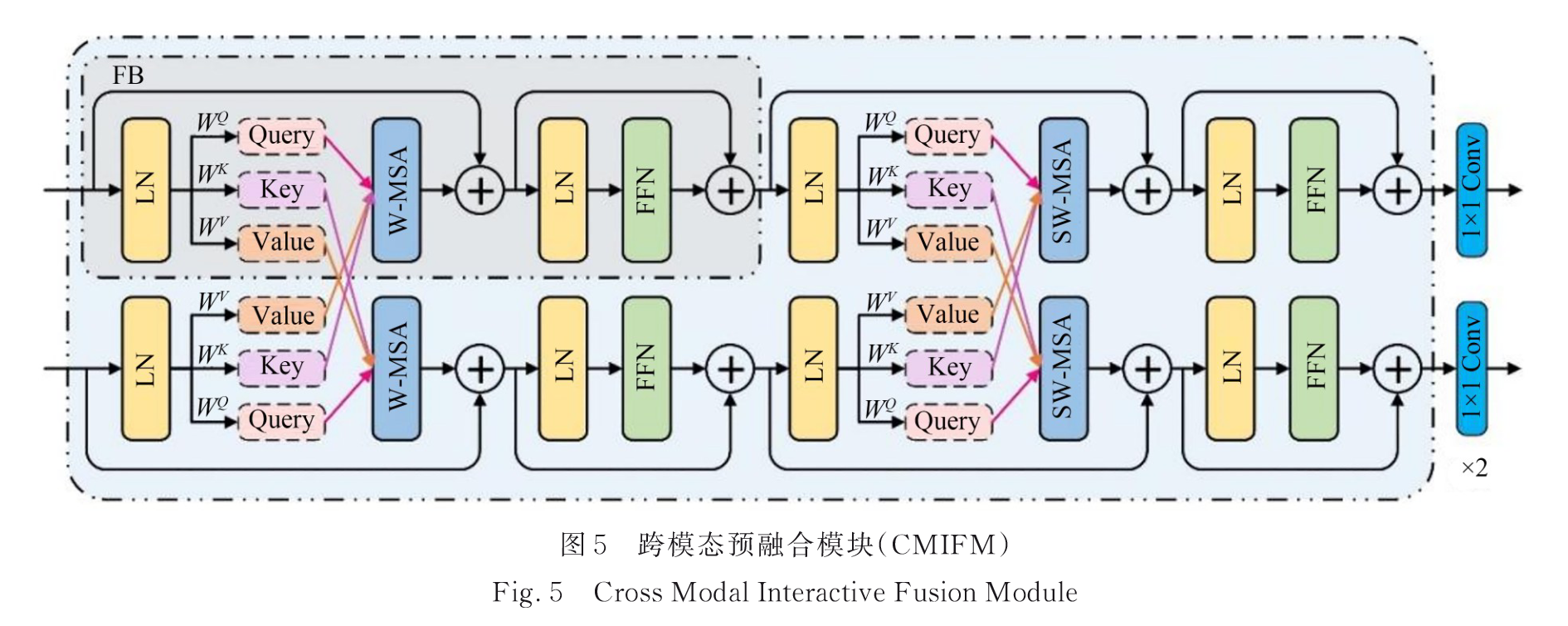
4个融合块(FB)
通过自注意力将特征图映射到Q、K、V,通过跨模态自注意力交换K、V,实现全局特征融合。
其余小块类似2.2.1。
跨模态融合单元的过程定义为:
[ Q 1 , K 1 , V 1 ] = [ X 1 W 1 Q , X 1 W 1 K , X 1 W 1 V ] [ Q 2 , K 2 , V 2 ] = [ X 2 W 2 Q , X 2 W 2 K , X 2 W 2 V ] Attention 1 ( Q 1 , K 2 , V 2 ) = softmax ( Q 1 K 2 T d k + B ) V 2 Attention 2 ( Q 2 , K 1 , V 1 ) = softmax ( Q 2 K 1 T d k + B ) V 1 Z ~ 1 l = W − MSA ( LN ( Z 1 l − 1 ) ) + Z 1 l − 1 Z ~ 2 l = W − MSA ( LN ( Z 2 l − 1 ) ) + Z 2 l − 1 Z 1 l = FFN ( LN ( Z ~ 1 l ) ) + Z ~ 1 l Z 2 l = FFN ( LN ( Z ~ 2 l ) ) + Z ~ 2 l \begin{align*} [Q_1, K_1, V_1] &= [X_1 W_{1}^{Q}, X_1 W_{1}^{K}, X_1 W_{1}^{V}] \\ [Q_2, K_2, V_2] &= [X_2 W_{2}^{Q}, X_2 W_{2}^{K}, X_2 W_{2}^{V}] \\ \text{Attention}_1(Q_1, K_2, V_2) &= \text{softmax}\left(\frac{Q_1 K_2^T}{\sqrt{d_k}} + B\right)V_2 \\ \text{Attention}_2(Q_2, K_1, V_1) &= \text{softmax}\left(\frac{Q_2 K_1^T}{\sqrt{d_k}} + B\right)V_1 \\ \tilde{Z}^l_1 &= W - \text{MSA}(\text{LN}(Z^{l-1}_1)) + Z^{l-1}_1 \\ \tilde{Z}^l_2 &= W - \text{MSA}(\text{LN}(Z^{l-1}_2)) + Z^{l-1}_2 \\ Z^l_1 &= \text{FFN}(\text{LN}(\tilde{Z}^l_1)) + \tilde{Z}^l_1 \\ Z^l_2 &= \text{FFN}(\text{LN}(\tilde{Z}^l_2)) + \tilde{Z}^l_2 \end{align*} [Q1,K1,V1][Q2,K2,V2]Attention1(Q1,K2,V2)Attention2(Q2,K1,V1)Z~1lZ~2lZ1lZ2l=[X1W1Q,X1W1K,X1W1V]=[X2W2Q,X2W2K,X2W2V]=softmax(dkQ1K2T+B)V2=softmax(dkQ2K1T+B)V1=W−MSA(LN(Z1l−1))+Z1l−1=W−MSA(LN(Z2l−1))+Z2l−1=FFN(LN(Z~1l))+Z~1l=FFN(LN(Z~2l))+Z~2l
对于 CT 域中的 Q1,它通过对 PET 域中的 K2和 V2进行注意力加权来整合跨模态信息,同时通过残差连接保留 CT 域中的信息,PET 域中同理。
F DF CT = H conv1 ( F A F C T ) F^{\text{CT}}_{\text{DF}} = H_{\text{conv1}}(F^{CT}_{AF}) FDFCT=Hconv1(FAFCT)
F DF PET = H conv2 ( F A F PET ) F^{\text{PET}}_{\text{DF}} = H_{\text{conv2}}(F^{\text{PET}}_{AF}) FDFPET=Hconv2(FAFPET)
F A F C T F^{CT}_{AF} FAFCT和 F A F PET F^{\text{PET}}_{AF} FAFPET表示CMIFM以 F D F C T F^{CT}_{DF} FDFCT和 F D F PET F^{\text{PET}}_{DF} FDFPET为输入而融合输出的特征;
H conv H_{\text{conv}} Hconv表示具有空间不变滤波器的卷积层;
F A F C T F^{CT}_{AF} FAFCT和 F A F PET F^{\text{PET}}_{AF} FAFPET表示融合的 CT 图像和 PET 图像的深度特征。
2.2.3 CNN-Transformer 特征重构模块(CTFRM)
2个STB块+2个卷积块(size=3, stride=1)+Leaky ReLU
生成预融合的图像
表述为:
F F S F C T = H D R ( F F D F C T + F S F C T ) F^{CT}_{FSF} = H_{DR}(F^{CT}_{FDF} + F^{CT}_{SF}) FFSFCT=HDR(FFDFCT+FSFCT)
F F S F P E T = H D R ( F F D F P E T + F S F P E T ) F^{PET}_{FSF} = H_{DR}(F^{PET}_{FDF} + F^{PET}_{SF}) FFSFPET=HDR(FFDFPET+FSFPET)
F C T = H S R ( F F S F C T ) F^{CT} = H_{SR}(F^{CT}_{FSF}) FCT=HSR(FFSFCT)
F P E T = H S R ( F F S F P E T ) F^{PET} = H_{SR}(F^{PET}_{FSF}) FPET=HSR(FFSFPET)
H D R H_{DR} HDR是STB块的深度特征重构单元; H S R H_{SR} HSR是基于CNN的浅层重构单元。
2.2.4 损失函数
以第一生成器为例:
G1总损失:
L G 1 = Φ ( G 1 ) + α L content 1 L_{G1} = \Phi(G_1) + \alpha L_{\text{content}1} LG1=Φ(G1)+αLcontent1
Φ ( G 1 ) \Phi(G_1) Φ(G1)表示对抗损失, L c o n t e n t 1 L_{content1} Lcontent1表示G1从源图像到预融合图像的损失, α \alpha α表示控制源PET图像信息含量比例。
Φ ( G 1 ) \Phi(G_1) Φ(G1)对抗损失:
Φ ( G 1 ) = 1 N ∑ n = 1 N ( D 1 ( F C T n , I P E T n ) − I P E T n ) 2 \Phi(G_1) = \frac{1}{N} \sum_{n=1}^{N} \left( D_1(F^n_{CT}, I^n_{PET}) - I^n_{PET} \right)^2 Φ(G1)=N1n=1∑N(D1(FCTn,IPETn)−IPETn)2
L c o n t e n t 1 L_{content1} Lcontent1内容损失:
L content 1 = L int ( C T ) + μ L ssim ( C T ) L_{\text{content}1} = L_{\text{int}(CT)} + \mu L_{\text{ssim}(CT)} Lcontent1=Lint(CT)+μLssim(CT)
L i n t L_{int} Lint 和 L s s i m L_{ssim} Lssim 表示强度损失函数和结构相似度损失函数,μ 表示正则化参数。
第二生成器同理。
2.3 耦合鉴别器结构
不仅要考虑生成器和鉴别器之间的对抗关系,还要考虑两个鉴别器之间的平衡。
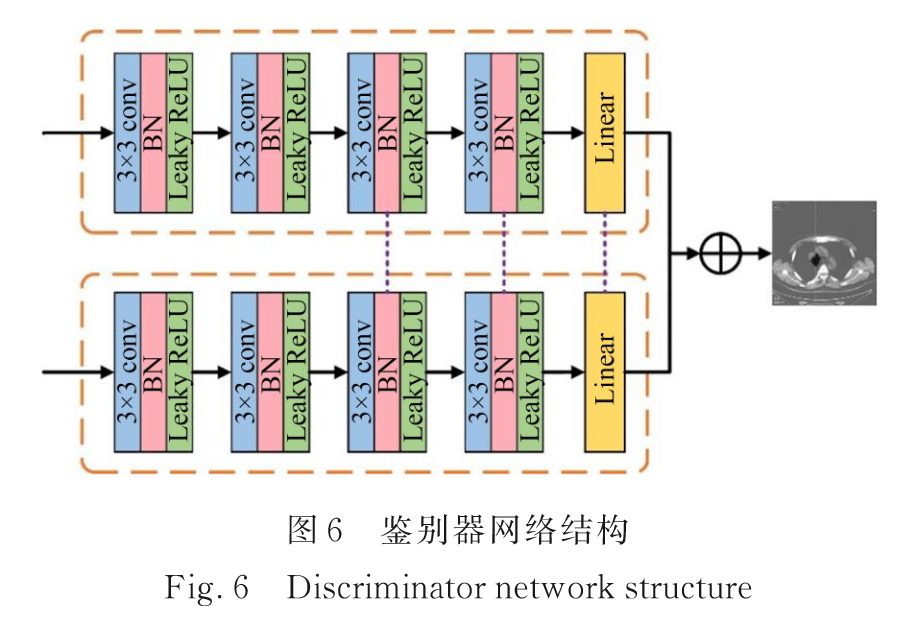
4个卷积块+1个线性层
卷积块:1个卷积层(size=3, stride=2, channel=32, 64, 128, 256)+1个BN层+1个Leaky ReLU层。
线性层:将特征图转化为输出,表示融合图像与相应源图像之间的相对距离。
鉴别器中第三、第四卷积块和线性层的共享权值。
以第一鉴别器为例:
D1的目的是通过损失函数使第一个预融合图像 F C T F_{CT} FCT逼近源PET图像:
D1的损失函数表示为:
L 1 = D 1 ( I P E T , F C T ) L_1 = D_1(I_{PET}, F_{CT}) L1=D1(IPET,FCT)
D1的函数表示为:
D 1 ( I P E T , F C T ) = C 1 ( I P E T ) − E F C T ( C 1 ( F C T ) ) D_1(I_{PET}, F_{CT}) = C_1(I_{PET}) - E_{F_{CT}}(C_1(F_{CT})) D1(IPET,FCT)=C1(IPET)−EFCT(C1(FCT))
E是期望输出值,C1表示第一鉴别器的非线性变换。
跨模态耦合鉴别器允许单个生成的图像具有相反图像的信息。但所得到的图像仍有一定程度的偏置,因此将生成的两幅图像进行平均,得到最终的融合结果F为:
F = 0.5 × ( F C T + F P E T ) F = 0.5 \times (F_{CT} + F_{PET}) F=0.5×(FCT+FPET)
3. 实验结果与分析
3.1 实验设置
数据集:1000 组已配准的肺部肿瘤PET和CT影像。
图像大小:356 pixel×356 pixel
将原始 RGB 三通道图像转换为灰度图像。
按照 6∶2∶2 比例划分为训练集、验证集和测试集。
lr=0.0001, epoch=1000, batch=4
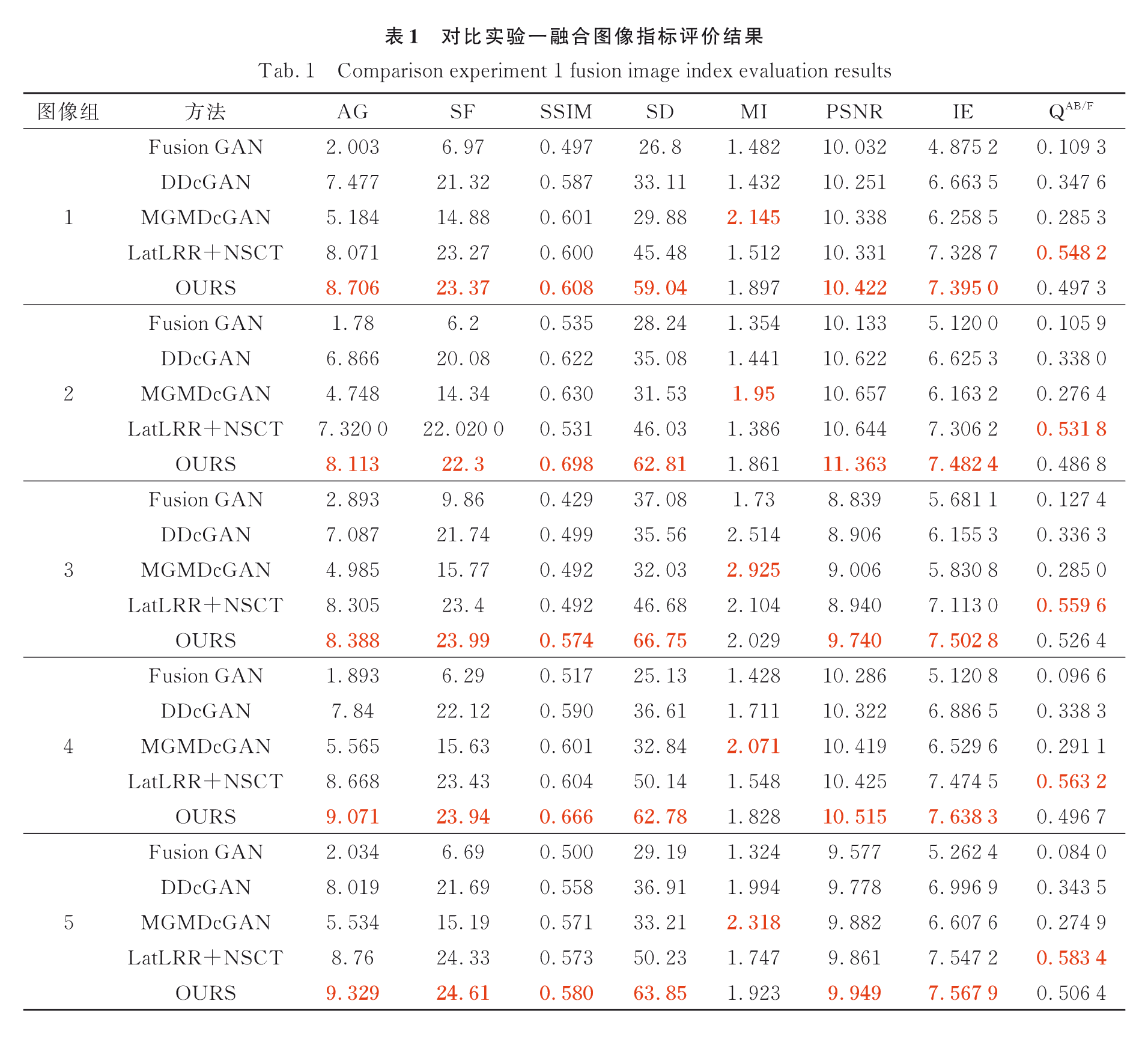
评价指标:AG、SF、SSIM、SD、MI、PSNR、IE、 Q A B / F Q^{AB/F} QAB/F
3.2 对比试验
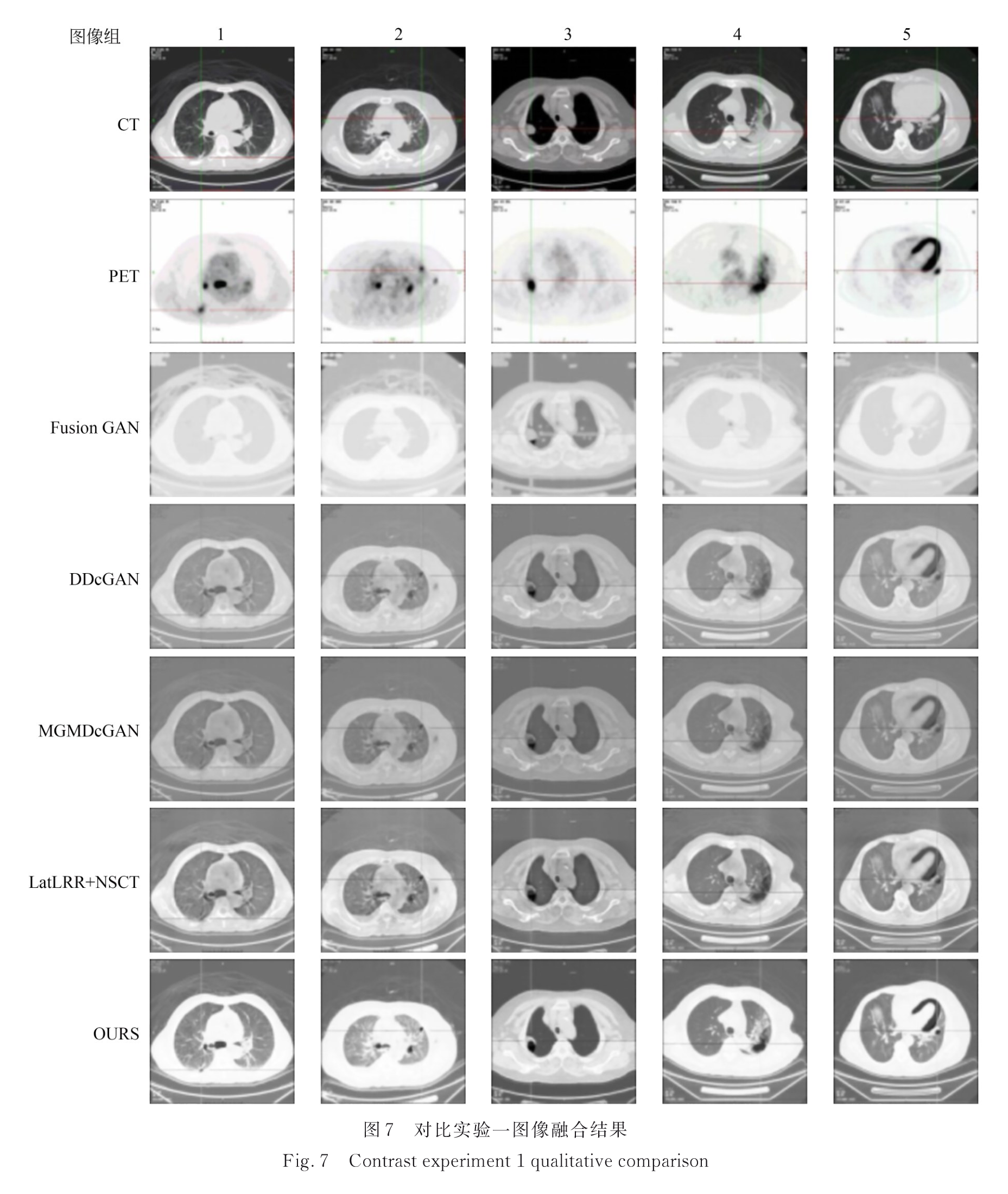
3.2.1 实验一:PET/CT肺窗
实验一图像融合结果:
实验一图像融合结果评价:
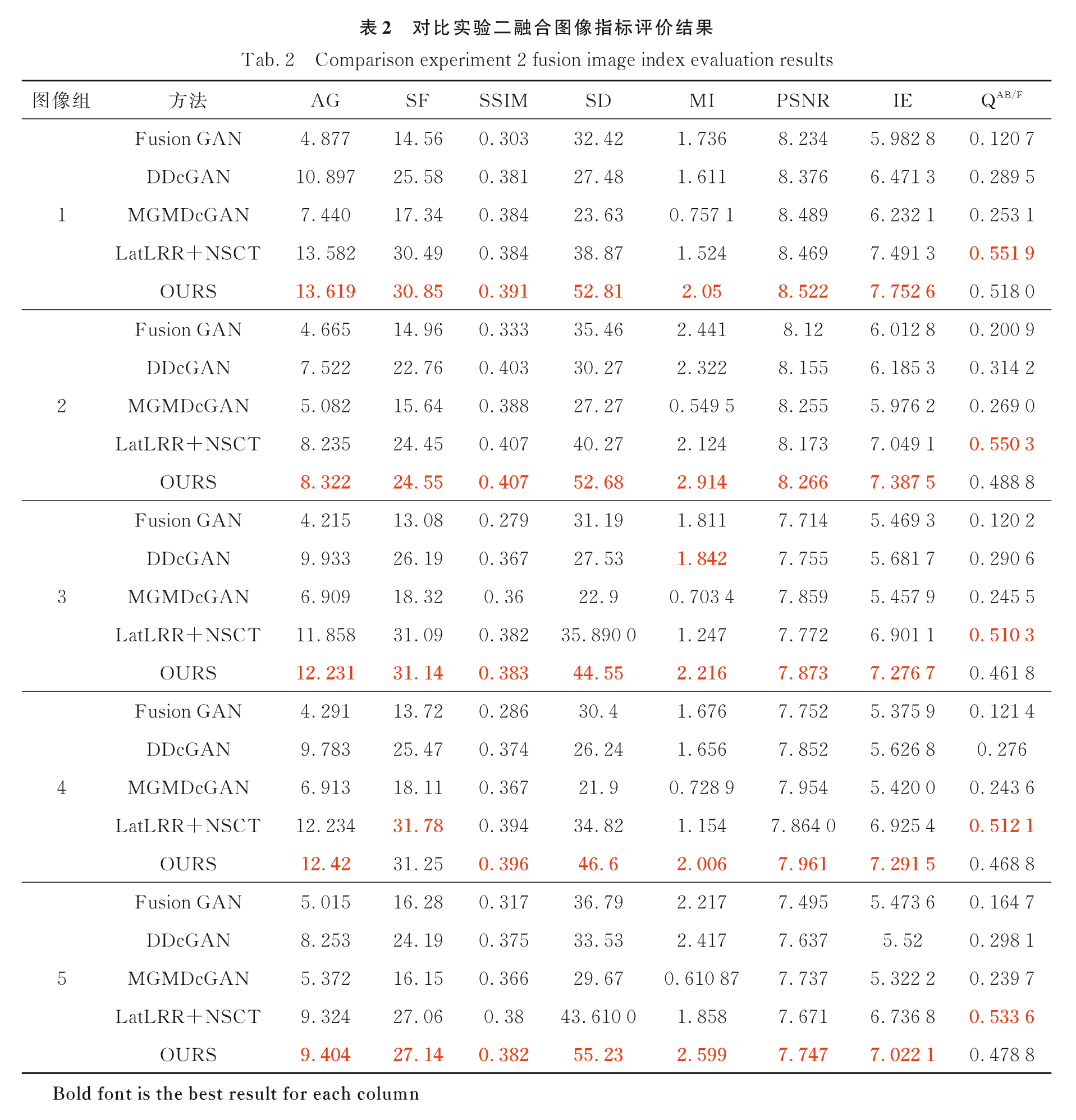
3.2.2 实验二:PET/CT纵膈窗
实验一图像融合结果:
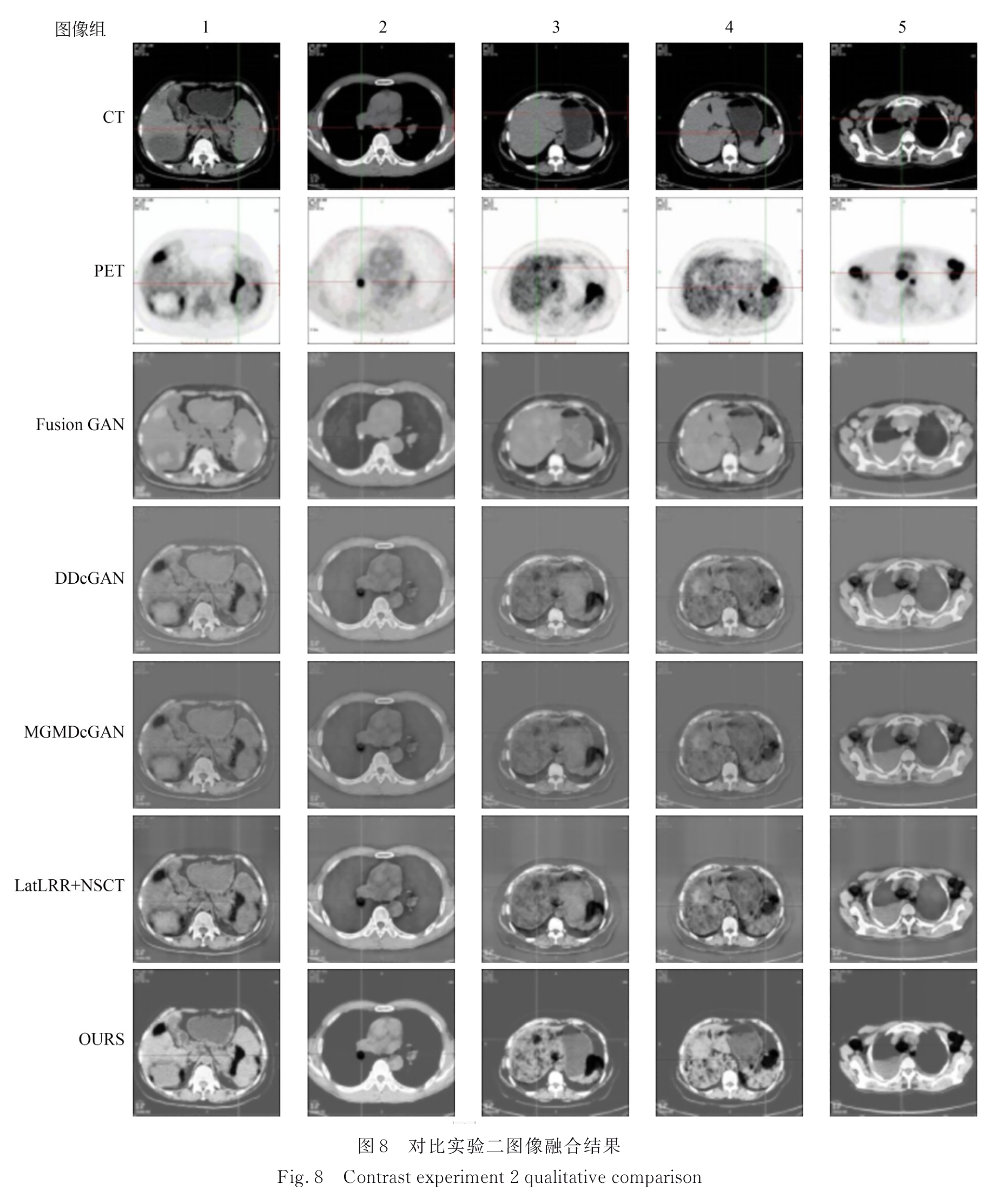
实验一图像融合结果评价:
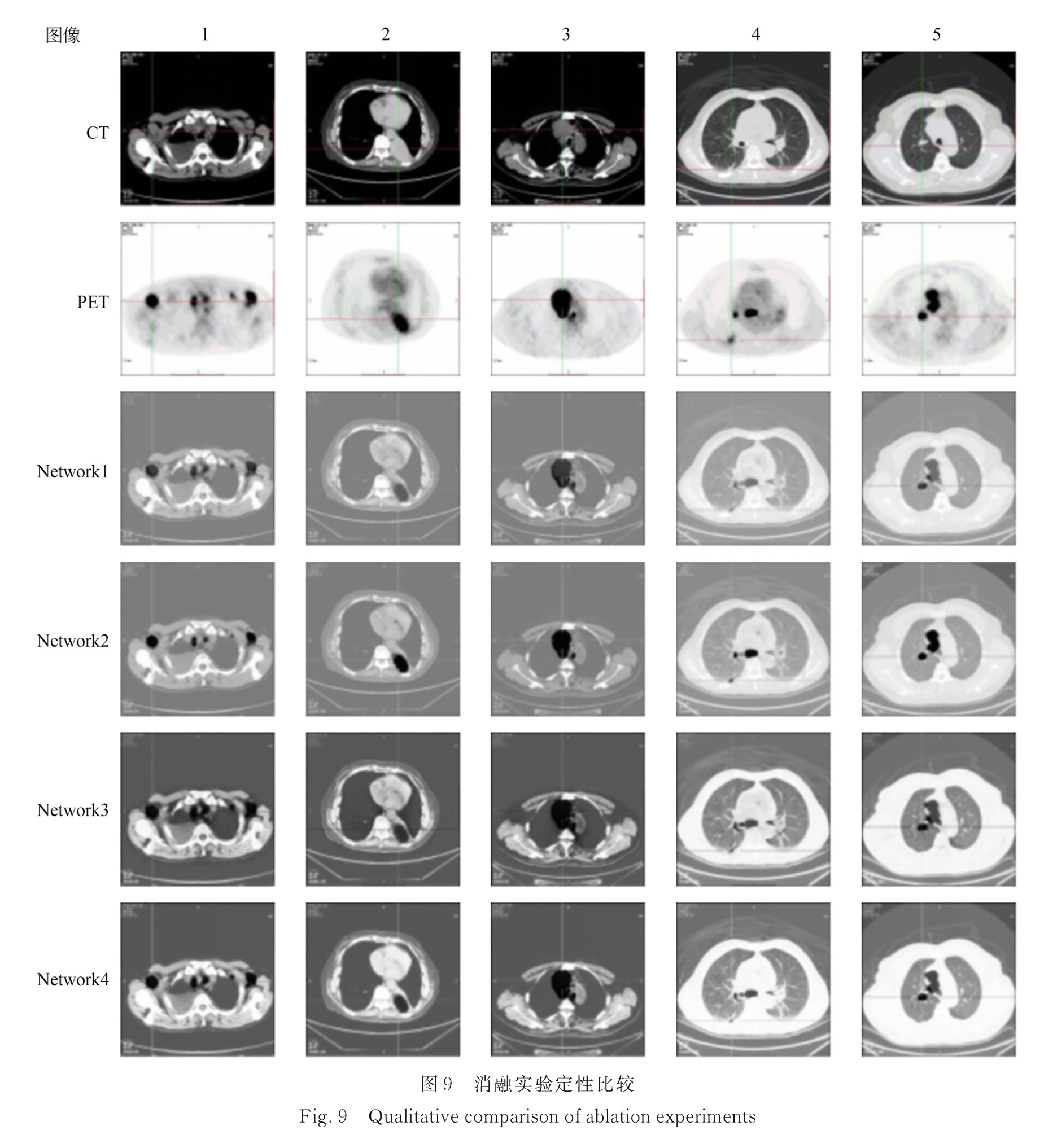
3.3 消融实验
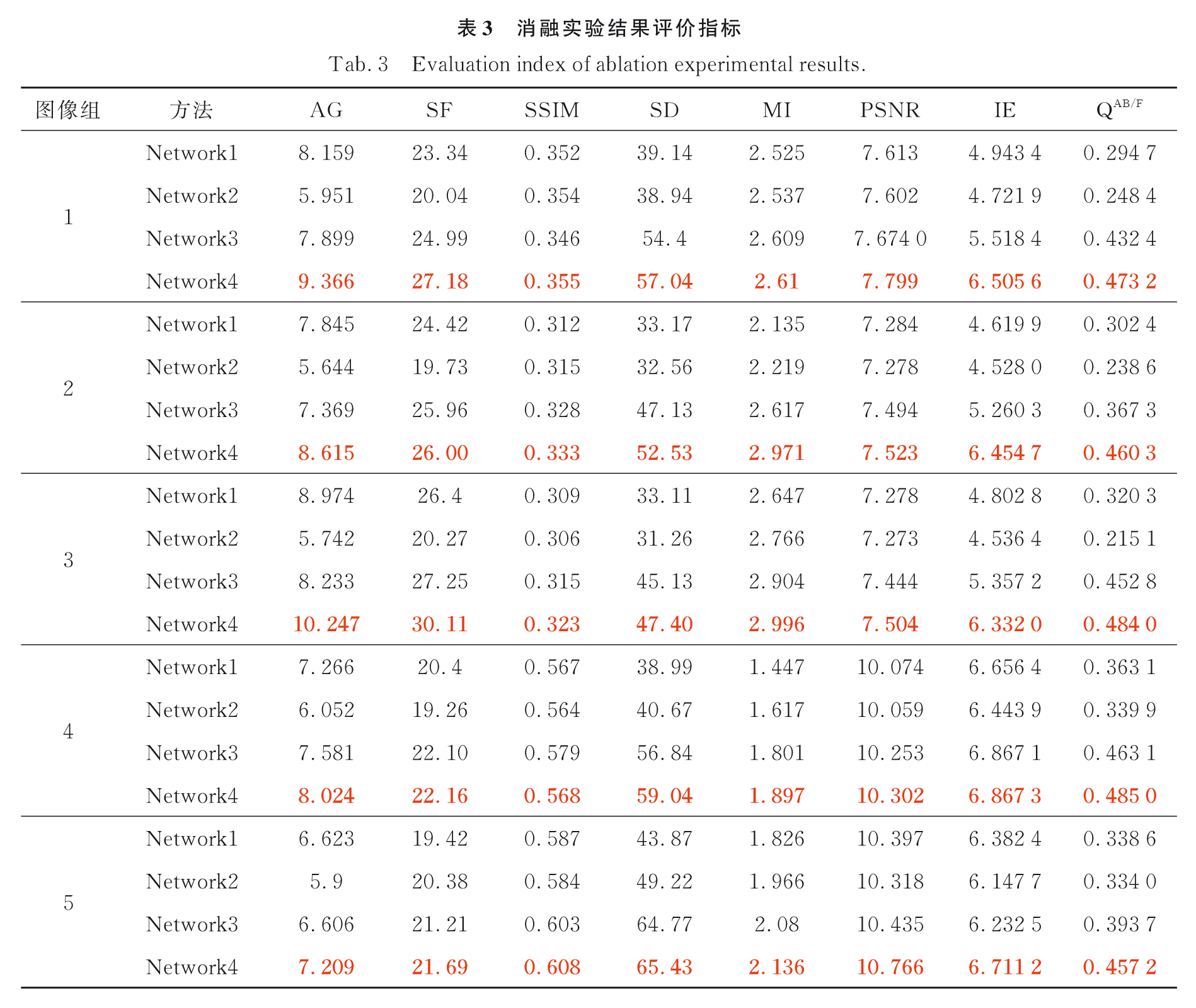
Network1:单生成器单鉴别器GAN
Network2:跨模态耦合生成器和跨模态耦合鉴别器
Network3:耦合 CNN-Transformer 特征提取模块
Network4:跨模态特征融合模块
消融实验结果:
消融实验结果评价:
4. 结论
本文模型得到的融合图像符合人类视觉感知,能够较好地融合 PET 图像中的病灶信息和 CT 图像中的纹理信息,有助于医生更快速、更精准地定位肺部肿瘤在解剖结构中的位置。
相关文章:
论文阅读:PET/CT Cross-modal medical image fusion of lung tumors based on DCIF-GAN
摘要 背景: 基于GAN的融合方法存在训练不稳定,提取图像的局部和全局上下文语义信息能力不足,交互融合程度不够等问题 贡献: 提出双耦合交互式融合GAN(Dual-Coupled Interactive Fusion GAN,DCIF-GAN&…...

java基础 day1
学习视频链接 人机交互的小故事 微软和乔布斯借鉴了施乐实现了如今的图形化界面 图形化界面对于用户来说,操作更加容易上手,但是也存在一些问题。使用图形化界面需要加载许多图片,所以消耗内存;此外运行的速度没有命令行快 Wi…...

cpp,git,unity学习
c#中的? 1. 空值类型(Nullable Types) ? 可以用于值类型(例如 int、bool 等),使它们可以接受 null。通常,值类型不能为 null,但是通过 ? 可以表示它们是可空的。 int? number null; // …...

HTML增加文本复制模块(使用户快速复制内容到剪贴板)
增加复制模块主要是为了方便用户快速复制内容到剪贴板,通常在需要提供文本信息可以便捷复制的网页设计或应用程序中常见。以下是为文本内容添加复制按钮的一个简单实现步骤: HTML结构: 在文本旁边添加一个复制按钮,例如 <butto…...

Spring Cloud面试题收集
Spring Cloud Spring cloud 是一系列框架的有序集合。它利用 spring boot 的开发便利性巧妙地简化了分布式系统基础设施的开发,如服务发现注册、配置中心、消息总线、负载均衡、断路器、数据监控等,都可以用 spring boot 的开发风格做到一键启动和部署。…...
观测云对接 SkyWalking 最佳实践
简介 SkyWalking 是一个开源的 APM(应用性能监控)和可观测性分析平台,专为微服务、云原生架构和基于容器的架构设计。它提供了分布式追踪、服务网格遥测分析、度量聚合和可视化一体化的解决方案。如果您的应用中正在使用SkyWalking …...

AI少女/HS2甜心选择2 仿天刀人物卡全合集打包
内含AI少女/甜心选择2 仿天刀角色卡全合集打包共21张 下载地址:https://www.51888w.com/408.html 部分演示图:...

MISC - 第11天(练习)
前言 各位师傅大家好,我是qmx_07,今天继续讲解MISC的相关知识 john-in-the-middle 导出http数据文件里面logo.png 是旗帜图案,放到stegsolve查看 通过转换颜色,发现flag信息 flag{J0hn_th3_Sn1ff3r} [UTCTF2020]docx 附件信息…...

[3.4]【机器人运动学MATLAB实战分析】PUMA560机器人逆运动学MATLAB计算
PUMA560是六自由度关节型机器人,其6个关节都是转动副,属于6R型操作臂。各连杆坐标系如图1,连杆参数如表1所示。 图1 PUMA560机器人的各连杆坐标系 表1 PUMA560机器人的连杆参数 用代数法对其进行运动学反解。具体步骤如下: 1、求θ1 PMUMA56...

centos常用知识和命令
linux目录及结构 /etc #存配置文件 /var #存日志文件 /home #用户家目录 /root #root用户家目录 /bin #命令文件目录 /sbin #超级管理员命令目录 /dev #设备文件目录 /boot #系统启动核心目录 /lib #库文件目录 /mnt #挂载目录 /tmp #临时文件目录 /usr #用户程序存…...

基于yolov8调用本地摄像头并将读取的信息传入jsonl中
最近在做水面垃圾识别的智能船 用到了yolov8进行目标检测 修改并添加了SEAttention注意力机制 详情见其他大神 【保姆级教程|YOLOv8添加注意力机制】【1】添加SEAttention注意力机制步骤详解、训练及推理使用_yolov8添加se-CSDN博客 并且修改传统的iou方法改为添加了wise-io…...

Linux中的进程间通信之管道
管道 管道是Unix中最古老的进程间通信的形式。 我们把从一个进程连接到另一个进程的一个数据流称为一个“管道” 匿名管道 #include <unistd.h> 功能:创建一无名管道 原型 int pipe(int fd[2]); 参数 fd:文件描述符数组,其中fd[0]表示读端, fd[1]表示写端 …...

【Vue】vue2项目打包后部署刷新404,配置publicPath ./ 不生效问题
Vue Router mode,为 history 无效,建议使用默认值 hash;...

【PyTorch】生成对抗网络
生成对抗网络是什么 概念 Generative Adversarial Nets,简称GAN GAN:生成对抗网络 —— 一种可以生成特定分布数据的模型 《Generative Adversarial Nets》 Ian J Goodfellow-2014 GAN网络结构 Recent Progress on Generative Adversarial Networks …...

Vue3轻松实现前端打印功能
文章目录 1.前言2.安装配置2.1 下载安装2.2 main.js 全局配置3.综合案例3.1 设置打印区域3.2 绑定打印事件3.3 完整代码4.避坑4.1 打印表格无边框4.2 单选框复选框打印不选中4.3 去除页脚页眉4.4 打印內容不自动换行1.前言 vue3 前端打印功能主要通过插件来实现。 市面上常用的…...

SHA-1 是一种不可逆的、固定长度的哈希函数,在 Git 等场景用于生成唯一的标识符来管理对象和数据完整性
SHA-1 (Secure Hash Algorithm 1) 是一种加密哈希函数,它能将任意大小的数据(如文件、消息)转换为一个固定长度的 160 位(20 字节)哈希值。这种哈希值通常以 40 个十六进制字符的形式表示,是数据的“指纹”…...

Activiti7 工作流引擎学习
目录 一. 什么是 Activiti 工作流引擎 二. Activiti 流程创建步骤 三. Activiti 数据库表含义 四. BPMN 建模语言 五. Activiti 使用步骤 六. 流程定义与流程实例 一. 什么是 Activiti 工作流引擎 Activiti 是一个开源的工作流引擎,用于业务流程管理…...

pytorch使用LSTM模型进行股票预测
文章目录 tushare获取股票数据数据预处理构建模型训练模型测试模型tushare获取股票数据 提取上证指数代码为603912的股票:佳力图,时间跨度为2014-01-01到今天十年的数据。 import tushare as ts pro = ts.pro_api()#准备训练集数据df = ts.pro_bar(ts_code=603912.SH, star…...

掌握 C# 异常处理机制
在任何编程语言中,处理错误和异常都是不可避免的。C# 提供了强大的异常处理机制,可以帮助开发者优雅地捕获和处理程序中的异常,确保程序的健壮性和可靠性。本文将带你了解 C# 中的异常类、try-catch 语句、自定义异常以及 finally 块的使用。…...

【Redis】Redis Cluster 简单介绍
Redis Cluster 是 Redis 3.0 提供的一种分布式解决方案, 允许数据在多个节点之间分散存储, 从而实现高可用性和可扩展性。 特点: 分片: Redis Cluster 将数据分散到多个节点, 通过哈希槽 (hash slots) 机制将键映射到不同的节点上。总共有 16384 个哈希槽, 每个节点负责一部分…...

ZYNQ实战:从零构建uCOSIII最小系统与BSP配置详解
1. 环境准备与硬件设计 第一次在ZYNQ上跑uCOSIII时,我踩了不少坑。记得当时为了找个靠谱的参考文档,翻遍了国内外论坛。现在回头看,其实只要硬件配置对了,软件移植就是水到渠成的事。咱们先从最基础的Vivado工程搭建说起。 我用的…...

VS Code 高效开发:从 launch.json 变量替换到 task.json 自动化构建
1. 从零开始配置 VS Code 调试环境 第一次打开 VS Code 的调试面板时,很多开发者都会感到无从下手。其实配置调试环境并不复杂,关键是要理解 launch.json 文件的作用。这个文件就像是调试器的"说明书",告诉 VS Code 如何启动和连接…...

TrollInstallerX终极指南:如何高效部署iOS越狱工具的专业解决方案
TrollInstallerX终极指南:如何高效部署iOS越狱工具的专业解决方案 【免费下载链接】TrollInstallerX A TrollStore installer for iOS 14.0 - 16.6.1 项目地址: https://gitcode.com/gh_mirrors/tr/TrollInstallerX 在iOS 14.0到16.6.1系统上安装TrollStore一…...

图解CA注意力机制:用Keras一步步拆解‘宽高分离池化’,理解位置信息如何嵌入通道注意力
图解CA注意力机制:用Keras拆解‘宽高分离池化’的视觉密码 当我们谈论注意力机制时,脑海中往往会浮现SE(Squeeze-and-Excitation)模块的通道加权画面。但今天要探讨的CA(Coordinate Attention)机制…...

终极指南:5分钟免费解锁Cursor Pro全部功能的完整解决方案
终极指南:5分钟免费解锁Cursor Pro全部功能的完整解决方案 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached your…...

AI编码助手配置框架:六层缰绳架构实现团队规范与上下文持久化
1. 项目概述:为什么你的AI编码助手总像个“健忘的实习生”? 如果你和我一样,已经深度使用Claude Code、Cursor这类AI编码助手超过半年,那你一定经历过这种“血压升高”的时刻:明明昨天刚跟它详细解释过项目的架构规范…...

AI智能体技能栈构建:基于Claw与Hermes框架的模块化实践
1. 项目概述:构建我的AI智能体技能栈最近在折腾AI智能体(Agent)的开发,特别是围绕Claw和Hermes这两个框架。如果你也对这个领域感兴趣,想打造一个能处理复杂任务、拥有多种技能的智能助手,那么我整理的这个…...

ARM架构TLB失效指令VALE1IS/VALE1ISNXS详解
1. ARM TLB失效指令基础解析在ARMv8/v9架构中,TLB(Translation Lookaside Buffer)作为内存管理单元(MMU)的核心组件,缓存了虚拟地址到物理地址的转换结果。当操作系统修改页表后,必须通过TLB失效…...

Kali on WSL避坑大全:从换源、装工具到解决图形界面Terminal报错,一篇搞定
Kali on WSL实战避坑指南:从基础配置到图形界面全流程解决方案 在Windows系统上运行Kali Linux一直是安全研究人员和开发者的刚需,而WSL(Windows Subsystem for Linux)的出现让这一需求变得更加便捷。然而,从安装到真正…...

开源的精神内核:是自由协作,还是商业公司的免费劳动力?
一、溯源:开源精神的三重底色——自由、共享与协作要理解开源的本质,我们必须先回到其精神原点。开源运动自诞生之日起,就携带着自由、共享与协作的基因,这三者共同构成了其精神内核的底色,缺一不可。自由,…...