深度学习中的结构化概率模型 - 使用图来描述模型结构篇
序言
在深度学习的探索之路上,结构化概率模型以其独特的视角和强大的表达能力,成为了研究复杂数据关系的重要工具。这一模型的核心在于其巧妙地利用图来描述模型结构,将随机变量间的复杂交互关系可视化、结构化。图的引入,不仅为我们提供了一个直观理解数据内部结构的工具,更使得模型的学习与推理过程变得更加高效和精准。通过图,我们可以清晰地看到变量之间的依赖关系、信息传递路径以及潜在的因果结构,这为构建更加复杂、精确的深度学习模型提供了坚实的基础。
使用图来描述模型结构
- 结构化概率模型使用图(在图论中 ‘‘结点’’ 是通过 ‘‘边’’ 来连接的)来表示随机变量之间的相互作用。每一个结点代表一个随机变量。每一条边代表一个直接相互作用。这些直接相互作用隐含着其他的间接相互作用,但是只有直接的相互作用是被显式地建模的。
- 使用图来描述概率分布中相互作用的方法不止一种。
- 在下文中我们会介绍几种最为流行和有用的方法。
- 图模型可以被大致分为两类:基于有向无环图的模型,和基于无向模型的模型。
有向模型
-
有向图模型 ( directed graphical model \text{directed graphical model} directed graphical model) 是一种结构化概率模型,也被叫做信念网络 ( belief network \text{belief network} belief network) 或者贝叶斯网络 ( Bayesian network 注 1 \text{Bayesian network}^{注1} Bayesian network注1) ( Pearl, 1985 \text{Pearl, 1985} Pearl, 1985)。
-
之所以命名为有向图模型是因为所有的边都是有方向的,即从一个结点指向另一个结点。
- 这个方向可以通过画一个箭头来表示。
- 箭头所指的方向表示了这个随机变量的概率分布是由其他变量的概率分布所定义的。
- 画一个从结点 a \text{a} a 到结点 b \text{b} b 的箭头表示了我们用一个条件分布来定义 b \text{b} b,而 a \text{a} a 是作为这个条件分布符号右边的一个变量。
- 换句话说, b \text{b} b 的概率分布依赖于 a \text{a} a 的取值。
-
举个接力赛的例子,我们假设 Alice \text{Alice} Alice 的完成时间为 t 0 t_0 t0, Bob \text{Bob} Bob的完成时间为 t 1 t_1 t1, Carol \text{Carol} Carol 的完成时间为 t 2 t_2 t2。就像我们之前看到的一样, t 1 t_1 t1 的估计是依赖于 t 0 t_0 t0 的, t 2 t_2 t2 的估计是直接依赖于 t 1 t_1 t1 的,但是仅仅间接地依赖于 t 0 t_0 t0。我们用一个有向图模型来建模这种关系,就如在
图例1中看到的一样。 -
正式的讲,变量 x \textbf{x} x 的有向概率模型是通过有向无环图 G \mathcal{G} G (每个结点都是模型中的随机变量)和一系列局部条件概率分布 ( local conditional probability distribution \text{local conditional probability distribution} local conditional probability distribution)
p ( x i ∣ P a G ( x i ) ) p(\text{x}_i\mid P_{a\mathcal{G}}(\text{x}_i)) p(xi∣PaG(xi)) 来定义的,其中 P a G ( x i ) P_{a\mathcal{G}}(\text{x}_i) PaG(xi) 表示结点 x i \text{x}_i xi 的所有父结点。 x \textbf{x} x 的概率分布可:
p ( x ) = ∏ i p ( x i ∣ P a G ( x i ) ) p(\textbf{x})=\prod\limits_i p(\text{x}_i\mid P_{a\mathcal{G}}(\text{x}_i)) p(x)=i∏p(xi∣PaG(xi)) — 公式1 \quad\textbf{---\footnotesize{公式1}} —公式1 -
在之前所述的接力赛的例子中,参考
图例1,这意味着概率分布可以被表示为:
p ( t 0 , t 1 , t 2 ) = p ( t 0 ) p ( t 1 ∣ t 0 ) p ( t 2 ∣ t 1 ) p(t_0,t_1,t_2)=p(t_0)p(t_1\mid t_0)p(t_2\mid t_1) p(t0,t1,t2)=p(t0)p(t1∣t0)p(t2∣t1) — 公式2 \quad\textbf{---\footnotesize{公式2}} —公式2
注1:当我们希望强调从网络中计算出的值的推断本质,尤其是强调这些值代表的是置信程度大小而不是事件的频率时,Judea Pearl 建议使用 “贝叶斯网络’’ 这个术语。
- 这是我们看到的第一个结构化概率模型的实际例子。我们能够检查这样建模的计算开销,为了验证相比于非结构化建模,结构化建模为什么有那么多的优势。
- 通常意义上说,对每个变量都能取 k k k 个值的 n n n 个变量建模,基于建表的方法需要的复杂度是 O ( k n ) O(k^n) O(kn),就像我们之前观察到的一样。
- 现在假设我们用一个有向图模型来对这些变量建模。
- 如果 m m m 代表图模型的单个条件概率分布中最大的变量数目(在条件符号的左右皆可),那么对这个有向模型建表的复杂度大致为 O ( k m ) O(k^m) O(km)。
- 只要我们在设计模型时使其满足 m ≪ n m \ll n m≪n,那么复杂度就会被大大地减小。
- 换一句话说,只要图中的每个变量都只有少量的父结点,那么这个分布就可以用较少的参数来表示。图结构上的一些限制条件,比如说要求这个图为一棵树,也可以保证一些操作(例如求一小部分变量的边缘或者条件分布)更加地高效。
无向模型
- 有向图模型为我们提供了一种描述结构化概率模型的语言。
- 而另一种常见的语言则是无向模型 ( Undirected Model \text{Undirected Model} Undirected Model),也叫做马尔可夫随机场 ( Markov random field, MRF \text{Markov random field, MRF} Markov random field, MRF) 或者是马尔可夫网络 ( Markov network \text{Markov network} Markov network) ( Kindermann, 1980 \text{Kindermann, 1980} Kindermann, 1980)。
- 就像它们的名字所说的那样, 无向模型中所有的边都是没有方向的。
- 有向模型显然适用于当存在一个很明显的理由来描述每一个箭头的时候。
- 有向模型中,经常存在我们理解的具有因果关系以及因果关系有明确方向的情况下。
- 接力赛的例子就是一个这样的情况。
- 之前运动员的表现影响了后面运动员的完成时间,而后面运动员却不会影响前面运动员的完成时间。
- 然而并不是所有情况的相互作用都有一个明确的方向关系。当相互的作用并没有本质性的指向,或者是明确的双向相互作用的时候,使用无向模型更加合适。
- 作为一个这种情况的例子,假设我们希望对三个二值随机变量建模:你是否生病,你的同事是否生病以及你的室友是否生病。
- 就像在接力赛的例子中所作的简化假设一样,我们可以在这里做一些关于相互作用的简化假设。
- 假设你的室友和同事并不认识,所以他们不太可能直接相互传染一些疾病,比如说是感冒。
- 这个事件太过稀有,所以我们不对此事件建模。
- 然而,很有可能他们之一将感冒传染给你,然后通过你来传染给了另一个人。
- 我们通过对你的同事传染给你以及你传染给你的室友建模来对这种间接的从你的同事到你的室友的感冒传染建模。
- 在这种情况下,你传染给你的室友和你的室友传染给你都是非常容易的,所以模型不存在一个明确的单向箭头。
- 这启发我们使用无向模型。
- 其中随机变量对应着图中的相互作用的结点。
- 与有向模型相同的是,如果在无向模型中的两个结点通过一条边相连接,那么对应这些结点的随机变量相互之间是直接作用的。
- 不同于有向模型,在无向模型中的边是没有方向的,并不与一个条件分布相关联。
- 我们把对应你的健康的随机变量记作 h y \text{h}_y hy,对应你的室友健康状况的随机变量记作 h r \text{h}_r hr,你的同事健康的变量记作 h c \text{h}_c hc。
图例2表示来这种关系。 - 正式的说,一个无向模型是一个定义在无向模型 G \mathcal{G} G 上的结构化概率模型。
- 对图中的每一个 团 注 2 \text{团}^{注2} 团注2 C \mathcal{C} C,一个因子 ( factor \text{factor} factor) ϕ ( C ) \phi(\mathcal{C}) ϕ(C)(也叫做团势能 ( clique potential \text{clique potential} clique potential)),衡量了团中变量每一种可能的联合状态所对应的密切程度。这些因子都被限制为是非负的。
- 合在一起他们定义了未归一化概率函数 ( unnormalized probability function \text{unnormalized probability function} unnormalized probability function):
p ~ ( x ) = ∏ C ∈ G ϕ ( C ) \tilde{p}(\text{x})=\prod\limits_{\mathcal{C}\in\mathcal{G}}\phi(\mathcal{C}) p~(x)=C∈G∏ϕ(C) — 公式3 \quad\textbf{---\footnotesize{公式3}} —公式3
注2:图的一个团是图中结点的一个子集,并且其中的点是全连接的。
-
只要所有的团中的结点数都不大,那么我们就能够高效地处理这些未归一化概率函数。
- 它包含了这样的思想,越高密切度的状态有越大的概率。
- 然而,不像贝叶斯网络,几乎不存在团定义的结构,所以不能保证把它们乘在一起能够得到一个有效的概率分布。
图例3展示了一个从无向模型中读取分解信息的例子。
-
在你,你的室友和同事之间感冒传染的例子中包含了两个团。一个团包含了 h y \text{h}_y hy和 h c \text{h}_c hc。这个团的因子可以通过一个表来定义,可能取到下面的值:
- 状态为 1 1 1 代表了健康的状态,相对的状态为 0 0 0 则表示不好的健康状态(即感染了感冒)。
- 你们两个通常都是健康的,所以对应的状态拥有最高的密切程度。
- 两个人中只有一个人是生病的密切程度是最低的,因为这是一个很少见的状态。
- 两个人都生病的状态(通过一个人来传染给了另一个人)有一个稍高的密切程度,尽管仍然不及两个人都健康的密切程度。
-
为了完整地定义这个模型,我们需要对包含 h y \text{h}_y hy 和 h r \text{h}_r hr 的团定义类似的因子。
配分函数
- 尽管这个未归一化概率函数处处不为零,我们仍然无法保证它的概率之和或者积分为 1。为了得到一个有效的概率分布,我们需要使用对应的归一化的 概率分布 注 3 \text{概率分布}^{注3} 概率分布注3:
p ( x ) = 1 Z p ~ ( x ) p(\text{x})=\displaystyle\frac{1}{Z}\tilde{p}(\text{x}) p(x)=Z1p~(x) — 公式4 \quad\textbf{---\footnotesize{公式4}} —公式4 - 其中, Z 是使得所有的概率之和或者积分为1的常数,并且满足:
Z = ∫ p ~ ( x ) d x Z=\displaystyle\int\tilde{p}(\text{x})d\text{x} Z=∫p~(x)dx — 公式5 \quad\textbf{---\footnotesize{公式5}} —公式5 - 当函数 ϕ \phi ϕ 固定的时候,我们可以把 Z Z Z 当成是一个常数。
- 值得注意的是如果函数 ϕ \phi ϕ 带有参数时,那么 Z Z Z 是这些参数的一个函数。
- 在相关文献中为了节省空间忽略控制 Z Z Z的变量而直接写 Z Z Z 是一个常用的方式。
- 归一化常数 Z Z Z 被称作是配分函数,一个从统计物理学中借鉴的术语。
注3:一个通过归一化团势能乘积定义的分布也被称作是吉布斯分布 (Gibbs distribution)。
-
由于 Z Z Z 通常是由对所有可能的 x \textbf{x} x 状态的联合分布空间求和或者求积分得到的,它通常是很难计算的。
- 为了获得一个无向模型的归一化概率分布,模型的结构和函数 ϕ \phi ϕ 的定义通常需要设计为有助于高效地计算 Z Z Z。
- 在深度学习中, Z Z Z 通常是难以处理的。
- 由于 Z Z Z 难以精确地计算出,我们只能使用一些近似的方法。
-
在设计无向模型时我们必须牢记在心的一个要点是设定一些使得 Z Z Z 不存在的因子也是有可能的。
- 当模型中的一些变量是连续的,且在 p ~ \tilde{p} p~ 在其定义域上的积分发散的时候这种情况就会发生。
- 例如,当我们需要对一个单独的标量变量 x ∈ R \text{x}\in\mathbb{R} x∈R 建模,并且这个包含一个点的团势能定义为 ϕ ( x ) = x 2 \phi(x) = x^2 ϕ(x)=x2 时。在这种情况下:
Z = ∫ x 2 d x Z=\displaystyle\int x^2dx Z=∫x2dx — 公式6 \quad\textbf{---\footnotesize{公式6}} —公式6
-
由于这个积分是发散的,所以不存在一个对应着这个势能函数 ϕ ( x ) \phi(x) ϕ(x) 的概率分布。
- 有时候 ϕ \phi ϕ 函数某些参数的选择可以决定相应的概率分布是否能够被定义。
- 比如说,对 ϕ \phi ϕ 函数 ϕ ( x , β ) = e ( − β x 2 ) \phi(x,\beta) = \displaystyle e^{(-\beta x^2)} ϕ(x,β)=e(−βx2) 来说,参数 β \beta β 决定了归一化常数 Z Z Z 是否存在。
- 一个正的 β \beta β 使得 ϕ \phi ϕ 函数是一个关于 x \text{x} x 的高斯分布,但是一个非正的参数 β \beta β 则使得 ϕ \phi ϕ 不可能被归一化。
-
有向建模和无向建模之间一个重要的区别就是有向模型是通过从起始点的概率分布直接定义的,反之无向模型的定义显得更加宽松,通过 ϕ \phi ϕ 函数转化为概率分布而定义。
- 这改变了我们处理这些建模问题的直觉。
- 当我们处理无向模型时需要牢记一点,每一个变量的定义域对于一系列给定的 ϕ \phi ϕ 函数所对应的概率分布有着重要的影响。
- 举个例子,我们考虑一个 n n n 维向量的随机变量 x \textbf{x} x 以及一个由偏置向量 b \boldsymbol{b} b 参数化的无向模型。
- 假设 x \textbf{x} x 的每一个元素对应着一个团,并且满足 ϕ ( i ) ( x i ) = e ( b i x i ) \phi^{(i)}(\text{x}_i) = e^(b_i\text{x}_i) ϕ(i)(xi)=e(bixi)。
- 在这种情况下概率分布是怎么样的呢?
- 答案是我们无法确定,因为我们并没有指定 x \textbf{x} x 的定义域。
- 如果 x \textbf{x} x 满足 x ∈ R n \text{x}\in\mathbb{R}^n x∈Rn,那么有关归一化常数 Z Z Z 的积分是发散的,这导致了对应的概率分布是不存在的。
- 如果 x ∈ { 0 , 1 } n \text{x}\in\{0,1\}^n x∈{0,1}n,那么 p ( x ) p(\textbf{x}) p(x) 可以被分解成 n n n 个独立的分布,并且满足 p ( x i = 1 ) = sigmoid ( b i ) p(\text{x}_i = 1) = \text{sigmoid}(b_i) p(xi=1)=sigmoid(bi)。
- 如果 x \textbf{x} x 的定义域是基本单位向量 ( { [ 1 , 0 , … , 0 ] , [ 0 , 1 , … , 0 ] , … , [ 0 , 0 , … , 1 ] } ) (\{[1, 0,\dots, 0],[0, 1,\dots, 0],\dots,[0, 0,\dots,1]\}) ({[1,0,…,0],[0,1,…,0],…,[0,0,…,1]}) 的集合,那么 p ( x ) = softmax ( b ) p(\text{x}) = \text{softmax}(\boldsymbol{b}) p(x)=softmax(b),因此对于 j ≠ i j \ne i j=i 一个较大的 b i b_i bi 的值会降低所有的 p ( x j = 1 ) p(\text{x}_j = 1) p(xj=1) 的概率。
- 通常情况下,通过仔细选择变量的定义域,能够使得一个相对简单的 ϕ \phi ϕ 函数可以获得一个相对复杂的表达。
基于能量的模型
-
无向模型中许多有趣的理论结果都依赖于 ∀ x , p ~ ( x ) > 0 \forall\boldsymbol{x},\tilde{p}(\boldsymbol{x})\gt0 ∀x,p~(x)>0 这个假设。使这个条件满足的一种简单方式是使用基于能量的模型 ( Energy-based model, EBM \text{Energy-based model, EBM} Energy-based model, EBM),其中:
p ~ ( x ) = e ( − E ( x ) ) \tilde{p}(\textbf{x})=e^{(-E(\textbf{x}))} p~(x)=e(−E(x)) — 公式7 \quad\textbf{---\footnotesize{公式7}} —公式7 -
E ( x ) E(\textbf{x}) E(x) 被称作是能量函数 ( energy function \text{energy function} energy function)。对所有的 z \text{z} z, e ( z ) e^{(\text{z})} e(z) 都是正的,这保证了没有一个能量函数会使得某一个状态 x \textbf{x} x 的概率为 0 0 0。
- 我们可以很自由地选择那些能够简化学习过程的能量函数。
- 如果我们直接学习各个团势能,我们需要利用约束优化方法来任意地指定一些特定的最小概率值。
- 学习能量函数的过程中,我们可以采用无约束的优化方法。
- 基于能量的模型中的概率可以无限趋近于 0 0 0 但是永远达不到 0 0 0。
-
服从
公式7形式的任意分布都是玻尔兹曼分布 ( Boltzmann distribution \text{Boltzmann distribution} Boltzmann distribution) 的一个实例。- 正是基于这个原因,我们把许多基于能量的模型叫做玻尔兹曼机 ( Boltzmann Machine \text{Boltzmann Machine} Boltzmann Machine) ( Fahlman et al., 1983; Ackley et al., 1985; Hinton et al., 1984a; Hinton and Sejnowski, 1986 \text{Fahlman et al., 1983; Ackley et al., 1985; Hinton et al., 1984a; Hinton and Sejnowski, 1986} Fahlman et al., 1983; Ackley et al., 1985; Hinton et al., 1984a; Hinton and Sejnowski, 1986)。
- 关于什么时候叫基于能量的模型,什么时候叫玻尔兹曼机不存在一个公认的判别标准。
- 一开始玻尔兹曼机这个术语是用来描述一个只有二进制变量的模型,但是如今许多模型,比如均值-协方差 RBM \text{RBM} RBM,也涉及到了实值变量。
- 虽然玻尔兹曼机最初的定义既可以包含潜变量也可以不包含潜变量,但是时至今日玻尔兹曼机这个术语通常用于指拥有潜变量的模型,而没有潜变量的玻尔兹曼机则经常被称为马尔可夫随机场或对数线性模型。
-
无向模型中的团对应于未归一化概率函数中的因子。
- 通过 e ( a + b ) = e ( a ) e ( b ) e^{(a+b)}=e^{(a)}e^{(b)} e(a+b)=e(a)e(b),我们发现无向模型中的不同团对应于能量函数的不同项。
- 换句话说,基于能量的模型只是一种特殊的马尔可夫网络:求幂使能量函数中的每个项对应于不同团的一个因子。
- 关于如何从无向模型结构中获得能量函数形式的示例参见
图例4。 - 人们可以将能量函数中带有多个项的基于能量的模型视作是专家之积 ( product of expert \text{product of expert} product of expert) ( Hinton, 1999 \text{Hinton, 1999} Hinton, 1999)。
- 能量函数中的每一项对应的是概率分布中的一个因子。
- 能量函数中的每一项都可以看作决定一个特定的软约束是否能够满足的‘‘专家’’。
- 每个专家只执行一个约束,而这个约束仅仅涉及随机变量的一个低维投影,但是当其结合概率的乘法时,专家们一同构造了复杂的高维约束。
-
基于能量的模型定义的一部分无法用机器学习观点来解释:即
公式7中的 “-’’符号。- 这个 “-’’ 符号可以被包含在 E E E 的定义之中。
- 对于很多 E E E 函数的选择来说,学习算法可以自由地决定能量的符号。
- 这个负号的存在主要是为了保持机器学习文献和物理学文献之间的兼容性。
- 概率建模的许多研究最初都是由统计物理学家做出的,其中 E E E 是指实际的、物理概念的能量,没有任意的符号。
- 诸如 ‘‘能量’’ 和 “配分函数’’ 这类术语仍然与这些技术相关联,尽管它们的数学适用性比在物理中更宽,尽管最早是从物理学中发现的。
- 一些机器学习研究者(例如, Smolensky (1986) \text{Smolensky (1986)} Smolensky (1986) 将负能量称为harmony \textbf{将负能量称为harmony} 将负能量称为harmony ( harmony \text{harmony} harmony))发出了不同的声音,但这些都不是标准惯例。
-
许多对概率模型进行操作的算法不需要计算 p model ( x ) p_{\text{model}}(\boldsymbol{x}) pmodel(x), 而只需要计算 log p ~ model ( x ) \log \tilde{p}_{\text{model}}(\boldsymbol{x}) logp~model(x)。对于具有潜变量 h \boldsymbol{h} h 的基于能量的模型,这些算法有时会将该量的负数称为自由能 ( free energy \text{free energy} free energy):
F ( x ) = − log ∑ h e ( − E ( x , h ) ) \mathcal{F}(\boldsymbol{x})=-\log \sum\limits_{\boldsymbol{h}} e^{(-E(\boldsymbol{x},\boldsymbol{h}))} F(x)=−logh∑e(−E(x,h)) — 公式8 \quad\textbf{---\footnotesize{公式8}} —公式8 -
我们更倾向于更为通用的基于 log p ~ model ( x ) \log \tilde{p}_{\text{model}}(\boldsymbol{x}) logp~model(x) 的定义。
分离和d-分离
-
图模型中的边告诉我们哪些变量直接相互作用。我们经常需要知道哪些变量间接相互作用。某些间接相互作用可以通过观察其他变量来启用或禁用。更正式地,我们想知道在给定其他变量子集的值时,哪些变量子集彼此条件独立。
-
在无向模型中,识别图中的条件独立性是非常简单的。
- 在这种情况下,图中隐含的条件独立性称为分离 ( separation \text{separation} separation)。
- 如果图结构显示给定变量集 S \mathbb{S} S 的情况下变量集 A \mathbb{A} A 与变量集 B \mathbb{B} B 无关,那么我们声称给定变量集 S \mathbb{S} S 时,变量集 A \mathbb{A} A 与另一组变量集 B \mathbb{B} B 是分离的。
- 如果连接两个变量 a \text{a} a 和 b \text{b} b 的连接路径仅涉及未观察变量,那么这些变量不是分离的。
- 如果它们之间没有路径,或者所有路径都包含可观测的变量,那么它们是分离的。
- 我们认为仅涉及到未观察到的变量的路径是 ‘‘活跃’’ 的,将包括可观察变量的路径称为 ‘‘非活跃’’ 的。
-
当我们画图时,我们可以通过加阴影来表示观察到的变量。
图例5用于描述当以这种方式绘图时无向模型中的活跃和非活跃路径的样子。图例6描述了一个从一个无向模型中读取分离信息的例子。
-
类似的概念适用于有向模型,只是在有向模型中,这些概念被称为 d-分离 \textbf{d-分离} d-分离 ( d-separation \text{d-separation} d-separation)。
- “ d \text{d} d’’ 代表 “依赖性’’ 的意思。
- 有向图中 d \text{d} d-分离的定义与无向模型中分离的定义相同:我们认为如果图结构显示给定另外的变量集 S \mathbb{S} S 时 A \mathbb{A} A 与变量集 B \mathbb{B} B 无关,那么给定变量集 S \mathbb{S} S 时,变量集 A \mathbb{A} A d \text{d} d-分离于变量集 B \mathbb{B} B。
-
与无向模型一样,我们可以通过查看图中存在的活跃路径来检查图中隐含的独立性。
- 如前所述,如果两个变量之间存在活跃路径,则两个变量是依赖的,如果没有活跃路径,则为 d \text{d} d-分离。在有向网络中,确定路径是否活跃有点复杂。
- 关于在有向模型中识别活跃路径的方法可以参见
图例7。 图例8是从一个图中读取一些属性的例子。
-
重要的是要记住分离和 d \text{d} d-分离只能告诉我们图中隐含的条件独立性。
- 图并不需要表示所有存在的独立性。
- 进一步的,使用完全图(具有所有可能的边的图)来表示任何分布总是合法的。事实上,一些分布包含不可能用现有图形符号表示的独立性。
- 特定环境下的独立 ( context-specific independences \text{context-specific independences} context-specific independences) 指的是取决于网络中一些变量值的独立性。
- 例如,考虑一个三个二进制变量的模型: a \text{a} a, b \text{b} b 和 c \text{c} c。假设当 a \text{a} a 是 0 0 0时, b \text{b} b 和 c \text{c} c 是独立的,但是当 a \text{a} a 是 1 1 1 时, b \text{b} b 确定地等于 c \text{c} c。当 a = 1 \text{a} = 1 a=1 时图模型需要连接 b \text{b} b 和 c \text{c} c 的边。但是图不能说明当 a = 0 \text{a} = 0 a=0 时 b \text{b} b 和 c \text{c} c 不是独立的。
-
一般来说,当独立性不存在的时候,图不会显示独立性。然而,图可能无法显示存在的独立性。
在有向模型和无向模型中转换
-
我们经常将特定的机器学习模型称为无向模型或有向模型。
- 例如,我们通常将受限玻尔兹曼机称为无向模型,而稀疏编码则被称为有向模型。
- 这种措辞的选择可能有点误导,因为没有概率模型本质上是有向或无向的。
- 但是,一些模型很适合使用有向图描述,而另一些模型很适用于使用无向模型描述。
-
有向模型和无向模型都有其优点和缺点。
- 这两种方法都不是明显优越和普遍优选的。
- 相反,我们根据具体的每个任务来决定使用哪一种模型。
- 这个选择部分取决于我们希望描述的概率分布。
- 根据哪种方法可以最大程度地捕捉到概率分布中的独立性,或者哪种方法使用最少的边来描述分布,我们可以决定使用有向建模还是无向建模。
- 还有其他因素可以影响我们决定使用哪种建模方式。
- 即使在使用单个概率分布时,我们有时可以在不同的建模方式之间切换。
- 有时,如果我们观察到变量的某个子集,或者如果我们希望执行不同的计算任务,换一种建模方式可能更合适。
- 例如,有向模型通常提供了一种高效地从模型中抽取样本的直接方法。
- 而无向模型公式通常对于推导近似推断过程是很有用的。
-
每个概率分布可以由有向模型或由无向模型表示。
- 在最坏的情况下,可以使用“完全图’’ 来表示任何分布。
- 在有向模型的情况下, 完全图是任何有向无环图,其中我们对随机变量排序,并且每个变量在排序中位于其之前的所有其他变量作为其图中的祖先。
- 对于无向模型,完全图只是包含所有变量的单个团。
图例9给出了一个实例。
-
当然, 图模型的优势在于图能够包含一些变量不直接相互作用的信息。完全图并不是很有用,因为它并不包含任何独立性。
-
当我们用图表示概率分布时,我们想要选择一个包含尽可能多独立性的图,但是并不会假设任何实际上不存在的独立性。
-
从这个角度来看,一些分布可以使用有向模型更高效地表示,而其他分布可以使用无向模型更高效地表示。换句话说, 有向模型可以编码一些无向模型所不能编码的独立性,反之亦然。
-
有向模型能够使用一种无向模型无法完美表示的特定类型的子结构。
- 这个子结构被称为不道德 ( immorality \text{immorality} immorality)。
- 这种结构出现在当两个随机变量 a \text{a} a 和 b \text{b} b 都是第三个随机变量 c \text{c} c 的父结点,并且不存在任一方向上直接连接 a \text{a} a 和 b \text{b} b 的边时。( “不道德’’的名字可能看起来很奇怪; 它在图模型文献中使用源于一个关于未婚父母的笑话。)
- 为了将有向模型图 D \mathcal{D} D 转换为无向模型,我们需要创建一个新图 U \mathcal{U} U。
- 对于每对变量 x \text{x} x和 y \text{y} y,如果存在连接 D \mathcal{D} D 中的 x \text{x} x 和 y \text{y} y 的有向边(在任一方向上),或者如果 x \text{x} x 和 y \text{y} y 都是图 D \mathcal{D} D 中另一个变量 z \text{z} z 的父节点,则在 U \mathcal{U} U 中添加连接 x \text{x} x 和 y \text{y} y 的无向边。
- 得到的图 U \mathcal{U} U 被称为是道德图 ( moralized graph \text{moralized graph} moralized graph)。
- 关于一个通过道德化将有向图模型转化为无向模型的例子可以参见
图例10。
-
同样的, 无向模型可以包括有向模型不能完美表示的子结构。
- 具体来说,如果 U \mathcal{U} U 包含长度大于 3 3 3 的环 ( loop \text{loop} loop),则有向图 D \mathcal{D} D 不能捕获无向模型 U \mathcal{U} U 所包含的所有条件独立性,除非该环还包含弦 ( chord \text{chord} chord)。
- 环指的是由无向边连接的变量序列,并且满足序列中的最后一个变量连接回序列中的第一个变量。
- 弦是定义环序列中任意两个非连续变量之间的连接。
- 如果 U \mathcal{U} U 具有长度为 4 4 4 或更大的环,并且这些环没有弦,我们必须在将它们转换为有向模型之前添加弦。
- 添加这些弦会丢弃了在 U \mathcal{U} U 中编码的一些独立信息。
- 通过将弦添加到 U \mathcal{U} U 形成的图被称为弦图 ( chordal graph \text{chordal graph} chordal graph) 或者三角形化图 ( triangulated graph \text{triangulated graph} triangulated graph),现在可以用更小的、三角的环来描述所有的环。
- 要从弦图构建有向图 D \mathcal{D} D,我们还需要为边指定方向。
- 当这样做时,我们不能在 D \mathcal{D} D 中创建有向循环,否则将无法定义有效的有向概率模型。
- 为 D \mathcal{D} D 中边分配方向的一种方法是对随机变量排序,然后将每个边从排序较早的节点指向稍后排序的节点。
- 一个简单的实例参见
图例11。
因子图
- 因子图 ( factor graph \text{factor graph} factor graph) 是从无向模型中抽样的另一种方法,它可以解决标准无向模型句法中图表达的模糊性。
- 在无向模型中,每个 ϕ \phi ϕ 函数的范围必须是图中某个团的子集。
- 我们无法确定每一个团是否含有一个作用域包含整个团的因子——比如说一个包含三个结点的团可能对应的是一个有三个结点的因子,也可能对应的是三个因子并且每个因子包含了一对结点,这通常会导致模糊性。
- 通过显式地表示每一个 ϕ \phi ϕ 函数的作用域,因子图解决了这种模糊性。具体来说, 因子图是一个包含无向二分图的无向模型的图形表示。
- 一些节点被绘制为圆形。
- 这些节点对应于随机变量,就像在标准无向模型中一样。
- 其余节点绘制为方块。
- 这些节点对应于未归一化概率函数的因子 ϕ \phi ϕ。
- 变量和因子可以通过无向边连接。
- 当且仅当变量包含在未归一化概率函数的因子中时,变量和因子在图中连接。没有因子可以连接到图中的另一个因子,也不能将变量连接到变量。
图例12给出了一个例子来说明因子图如何解决无向网络中的模糊性。
- 图例1:一个描述接力赛例子的有向图模型。
-
一个描述接力赛例子的有向图模型

-
说明:
- Alice \text{Alice} Alice 的完成时间 t 0 t_0 t0 影响了 Bob \text{Bob} Bob 的完成时间 t 1 t_1 t1,因为 Bob \text{Bob} Bob 会在 Alice \text{Alice} Alice 完成比赛后才开始。
- 类似的, Carol \text{Carol} Carol 也只会在 Bob \text{Bob} Bob 完成之后才开始,所以 Bob \text{Bob} Bob的完成时间 t 1 t_1 t1 直接影响了 Carol \text{Carol} Carol 的完成时间 t 2 t_2 t2。
-
-
图例2:

- 说明:
- 表示你室友健康的 h r \text{h}_r hr,你的健康的 h y \text{h}_y hy,你同事健康的 h c \text{h}_c hc 之间如何相互影响的一个无向图。你和你的室友可能会相互传染感冒,你和你的同事之间也是如此,但是假设你室友和同事之间相互不认识,他们只能通过你来间接传染。
- 说明:
-
图例3:

- 说明:
- 通过选择适当的 ϕ \phi ϕ函数 p ( a , b , c , d , e , f ) p(\text{a}, \text{b}, \text{c}, \text{d}, \text{e}, \text{f}) p(a,b,c,d,e,f) 可以写作 1 Z ϕ a , b ( a , b ) ϕ b , c ( b , c ) ϕ a , d ( a , d ) ϕ b , e ( b , e ) ϕ e , f ( e , f ) \frac{1}{Z}\phi_{\text{a},\text{b}}(\text{a},\text{b})\phi_{\text{b},\text{c}}(\text{b},\text{c})\phi_{\text{a},\text{d}}(\text{a},\text{d})\phi_{\text{b},\text{e}}(\text{b},\text{e})\phi_{\text{e},\text{f}}(\text{e},\text{f}) Z1ϕa,b(a,b)ϕb,c(b,c)ϕa,d(a,d)ϕb,e(b,e)ϕe,f(e,f)。
- 说明:
-
图例4:

- 说明:
- 通过为每个团选择适当的能量函数 E ( a , b , c , d , e , f ) E(\text{a}, \text{b}, \text{c}, \text{d}, \text{e}, \text{f}) E(a,b,c,d,e,f) 可以写作 E a , b ( a , b ) + E b , c ( b , c ) + E a , d ( a , d ) + E b , e ( b , e ) + E e , f ( e , f ) E_{\text{a},\text{b}}(\text{a},\text{b})+E_{\text{b},\text{c}}(\text{b},\text{c})+E_{\text{a},\text{d}}(\text{a},\text{d})+E_{\text{b},\text{e}}(\text{b},\text{e})+E_{\text{e},\text{f}}(\text{e},\text{f}) Ea,b(a,b)+Eb,c(b,c)+Ea,d(a,d)+Eb,e(b,e)+Ee,f(e,f)。
- 值得注意的是,我们可以通过令 ϕ \phi ϕ 等于对应负能量的指数来获得
图例3中的 ϕ \phi ϕ 函数,比如, ϕ a , b ( a , b ) = e ( − E ( a , b ) ) \phi_{\text{a},\text{b}}(\text{a},\text{b})=e^{(-E(\text{a},\text{b}))} ϕa,b(a,b)=e(−E(a,b))。
- 说明:
-
图例5:

- 说明:
- (a)图:
- 随机变量 a \text{a} a 和随机变量 b \text{b} b 之间穿过 s \text{s} s 的路径是活跃的,因为 s \text{s} s 是观察不到的。
- 这意味着 a \text{a} a, b \text{b} b 之间不是分离的。
- (b)图:
- s \text{s} s 用阴影填充,表示了它是可观察的。
- 因为 a \text{a} a 和 b \text{b} b 之间的唯一路径通过 s \text{s} s,并且这条路径是不活跃的,我们可以得出结论,在给定 s \text{s} s的条件下 a \text{a} a和 b \text{b} b是分离的。
- (a)图:
- 说明:
- 图例6:从一个无向图中读取分离性质的一个例子。
-
从一个无向图中读取分离性质的一个例子

-
说明:
- 这里 b \text{b} b 用阴影填充,表示它是可观察的。
- 由于 b \text{b} b 挡住了从 a \text{a} a 到 c \text{c} c 的唯一路径,我们说在给定 b \text{b} b 的情况下 a \text{a} a 和 c \text{c} c 是相互分离的。
- 观察值 b \text{b} b 同样挡住了从 a \text{a} a 到 d \text{d} d 的一条路径,但是它们之间有另一条活跃路径。
- 因此给定 b \text{b} b 的情况下 a \text{a} a 和 d \text{d} d 不是分离的。
-
- 图例7:两个随机变量 a \text{a} a, b \text{b} b 之间存在的所有种类的长度为 2 2 2 的活跃路径。
-
两个随机变量 a \text{a} a, b \text{b} b 之间存在的所有种类的长度为 2 2 2 的活跃路径

-
说明:
- ( a \text{a} a)
- 箭头方向从 a \text{a} a 指向 b \text{b} b 的任何路径,反过来也一样。
- 如果 s \text{s} s 可以被观察到,这种路径就是阻塞的。
- 在接力赛的例子中,我们已经看到过这种类型的路径。
- ( b \text{b} b)
- 变量 a \text{a} a 和 b \text{b} b 通过共用原因 s \text{s} s 相连。
- 举个例子,假设s 是一个表示是否存在飓风的变量, a \text{a} a 和 b \text{b} b 表示两个相邻气象监控区域的风速。
- 如果我们观察到在 a \text{a} a 处有很高的风速,我们可以期望在 b \text{b} b 处也观察到高速的风。
- 如果观察到 s \text{s} s 那么这条路径就被阻塞了。
- 如果我们已经知道存在飓风,那么无论 a \text{a} a 处观察到什么,我们都能期望 b \text{b} b 处有较高的风速。
- 在 a \text{a} a 处观察到一个低于预期的风速(对飓风而言)并不会改变我们对 b \text{b} b 处风速的期望(已知有飓风的情况下)。
- 然而,如果 s \text{s} s 不被观测到,那么 a \text{a} a 和 b \text{b} b 是依赖的,即路径是活跃的。
- ( c \text{c} c)
- 变量 a \text{a} a 和 b \text{b} b 都是 s \text{s} s 的父节点。
- 这叫做 V-结构 \textbf{V-结构} V-结构 ( V-structure \text{V-structure} V-structure) 或者碰撞情况 ( the collider case \text{the collider case} the collider case)。
- 根据 explaining away \text{explaining away} explaining away 作用 ( explaining away effect \text{explaining away effect} explaining away effect), V-结构 \text{V-结构} V-结构导致 a \text{a} a 和 b \text{b} b 是相关的。
- 在这种情况下,当 s 被观测到时路径是活跃的。
- 举个例子,假设 s \text{s} s 是一个表示你的同事不在工作的变量。
- 变量 a \text{a} a 表示她生病了,而变量 b \text{b} b 表示她在休假。
- 如果你观察到了她不在工作,你可以假设她很有可能是生病了或者是在度假,但是这两件事同时发生是不太可能的。
- 如果你发现她在休假,那么这个事实足够解释她的缺席了。
- 你可以推断她很可能没有生病。
- ( d \text{d} d)
- 即使 s \text{s} s 的任意后代都被观察到, explaining away \text{explaining away} explaining away 作用也会起作用。
- 举个例子,假设 c \text{c} c 是一个表示你是否收到你同事的报告的一个变量。
- 如果你注意到你还没有收到这个报告,这会增加你估计的她今天不在工作的概率,这反过来又会增加她今天生病或者度假的概率。
- 阻塞V-结构中路径的唯一方法就是共享子节点的后代一个都观察不到。
- ( a \text{a} a)
-
- 图例8:从这张图中,我们可以发现一些 d \text{d} d-分离的性质。
-
从这张图中,我们可以发现一些 d \text{d} d-分离的性质

-
说明:
- 这包括了:
• 给定空集的情况下 a \text{a} a 和 b \text{b} b 是 d \text{d} d-分离的。
• 给定 c \text{c} c 的情况下 a \text{a} a 和 e 是 d \text{d} d-分离的。
• 给定 c \text{c} c 的情况下 d \text{d} d 和 e 是 d \text{d} d-分离的。
我们还可以发现当我们观察到一些变量的时候,一些变量不再是 d \text{d} d-分离的:
• 给定 c \text{c} c 的情况下 a \text{a} a 和 b \text{b} b 不是 d \text{d} d-分离的。
• 给定 d \text{d} d 的情况下 a \text{a} a 和 b \text{b} b 不是 d \text{d} d-分离的。
- 这包括了:
-
- 图例9:完全图的例子, 完全图能够描述任何的概率分布。
-
完全图的例子, 完全图能够描述任何的概率分布

-
说明:
- 这里我们展示了一个带有四个随机变量的例子。
- (左)
- 完全无向图。
- 在无向图中,完全图是唯一的。
- (右)
- 一个完全有向图。
- 在有向图中,并不存在唯一的完全图。
- 我们选择一种变量的排序,然后对每一个变量,从它本身开始,向每一个指向顺序在其后面的变量画一条弧。
- 因此存在着关于变量数阶乘数量级的不同种完全图。
- 在这个例子中,我们从左到右从上到下地排序变量。
-
- 图例10:通过构造道德图将有向模型(上一行)转化为无向模型(下一行)的例子。
-
通过构造道德图将有向模型(上一行)转化为无向模型(下一行)的例子

-
说明:
- (左)
- 只需要把有向边替换成无向边就可以把这个简单的链转化为一个道德图。
- 得到的无向模型包含了完全相同的独立关系和条件独立关系。
- (中)
- 这个图是不丢失独立性的情况下无法转化为无向模型的最简单的有向模型。
- 这个图包含了单个完整的不道德结构。
- 因为 a \text{a} a 和 b \text{b} b 都是 c \text{c} c 的父节点,当 c \text{c} c 被观察到时它们之间通过活跃路径相连。
- 为了捕捉这个依赖性,无向模型必须包含一个含有所有三个变量的团。
- 这个团无法编码 a ⊥ b \text{a}\bot\text{b} a⊥b 这个信息。
- (右)
- 通常讲, 道德化的过程会给图添加许多边,因此丢失了一些隐含的独立性。
- 举个例子,这个稀疏编码图需要在每一对隐藏单元之间添加道德化的边,因此也引入了二次数量级的新的直接依赖性。
- (左)
-
- 图例11:将一个无向模型转化为一个有向模型。
-
将一个无向模型转化为一个有向模型

-
说明:
- (左)
- 这个无向模型无法转化为有向模型,因为它有一个长度为 4 4 4 且不带有弦的环。
- 具体说来,这个无向模型包含了两种不同的独立性,并且不存在一个有向模型可以同时描述这两种性质: a ⊥ c ∣ { b , d } \text{a}\bot\text{c}|\{\text{b},\text{d}\} a⊥c∣{b,d} 和 b ⊥ d ∣ { a , c } \text{b}\bot\text{d}|\{\text{a},\text{c}\} b⊥d∣{a,c}。
- (中)
- 为了将无向图转化为有向图,我们必须通过保证所有长度大于 3 3 3 的环都有弦来三角形化图。
- 为了实现这个目标,我们可以加一条连接 a \text{a} a 和 c \text{c} c 或者连接 b \text{b} b 和 d \text{d} d 的边。
- 在这个例子中,我们选择添加一条连接 a \text{a} a和 c \text{c} c 的边。
- (右)
- 为了完成转化的过程,我们必须给每条边分配一个方向。
- 执行这个任务时,我们必须保证不产生任何有向环。
- 避免出现有向环的一种方法是赋予节点一定的顺序,然后将每个边从排序较早的节点指向稍后排序的节点。
- 在这个例子中,我们根据变量名的字母进行排序。
- (左)
-
- 图例12:因子图如何解决无向网络中的模糊性的一个例子。
-
因子图如何解决无向网络中的模糊性的一个例子

-
说明:
- (左)
- 一个包含三个变量( a \text{a} a、 b \text{b} b 和 c \text{c} c)的团组成的无向网络。
- (中)
- 对应这个无向模型的因子图。
- 这个因子图有一个包含三个变量的因子。
- (右)
- 对应这个无向模型的另一种有效的因子图。
- 这个因子图包含了三个因子,每个因子只对应两个变量。
- 这个因子图上进行的表示、推断和学习相比于中图描述的因子图都要渐进性地廉价,即使它们表示的是同一个无向模型。
- (左)
-
总结
深度学习中的结构化概率模型,通过图这一强大工具,成功地将模型结构可视化、结构化,极大地增强了模型的表达能力和可解释性。图的引入,不仅简化了模型的学习过程,提高了推理效率,还使得我们能够更加深入地理解数据背后的复杂关系。此外,随着图神经网络等技术的不断发展,结构化概率模型的应用范围也在不断拓展,为处理图像、文本、社交网络等复杂数据结构提供了更加有效的解决方案。因此,我们有理由相信,在未来的深度学习研究中,结构化概率模型将继续发挥重要作用,推动人工智能技术的不断进步。
往期内容回顾
深度学习中的结构化概率模型 - 非结构化建模的挑战篇
相关文章:
深度学习中的结构化概率模型 - 使用图来描述模型结构篇
序言 在深度学习的探索之路上,结构化概率模型以其独特的视角和强大的表达能力,成为了研究复杂数据关系的重要工具。这一模型的核心在于其巧妙地利用图来描述模型结构,将随机变量间的复杂交互关系可视化、结构化。图的引入,不仅为…...

C语言中的栈帧
------------------------ | 局部变量区 | | (根据变量声明而变化) | ------------------------ | 参数区 | | (根据函数原型而变化) | ------------------------ | (可选) 保存寄存器区 | | (编译器/架构特定) | -…...

vue数组根据某些条件进行二次切割
原本的一个一维数组首先 1.根据depnm和bed的不同会分成不同的数组 2.在条件1的基础上分割出来的数组如果存在里面有isBgn1的会进行二次分割 比如原数组是[{depnm:1,bed:2,isBgn:0},{}……] 根据条件一会组成一个二维数组得到 [ [①depnm值一致的一个一维数组], [②bed值一…...

Yolov8改进轻量级网络Ghostnetv2
1,理论部分 轻量级卷积神经网络 (CNN) 专为移动设备上的应用程序而设计,具有更快的推理速度。卷积运算只能捕获窗口区域中的局部信息,这会阻止性能进一步提高。将自我注意引入卷积可以很好地捕获全局信息,但会在很大程度上阻碍实际速度。在本文中,我们提出了一种硬件友好…...
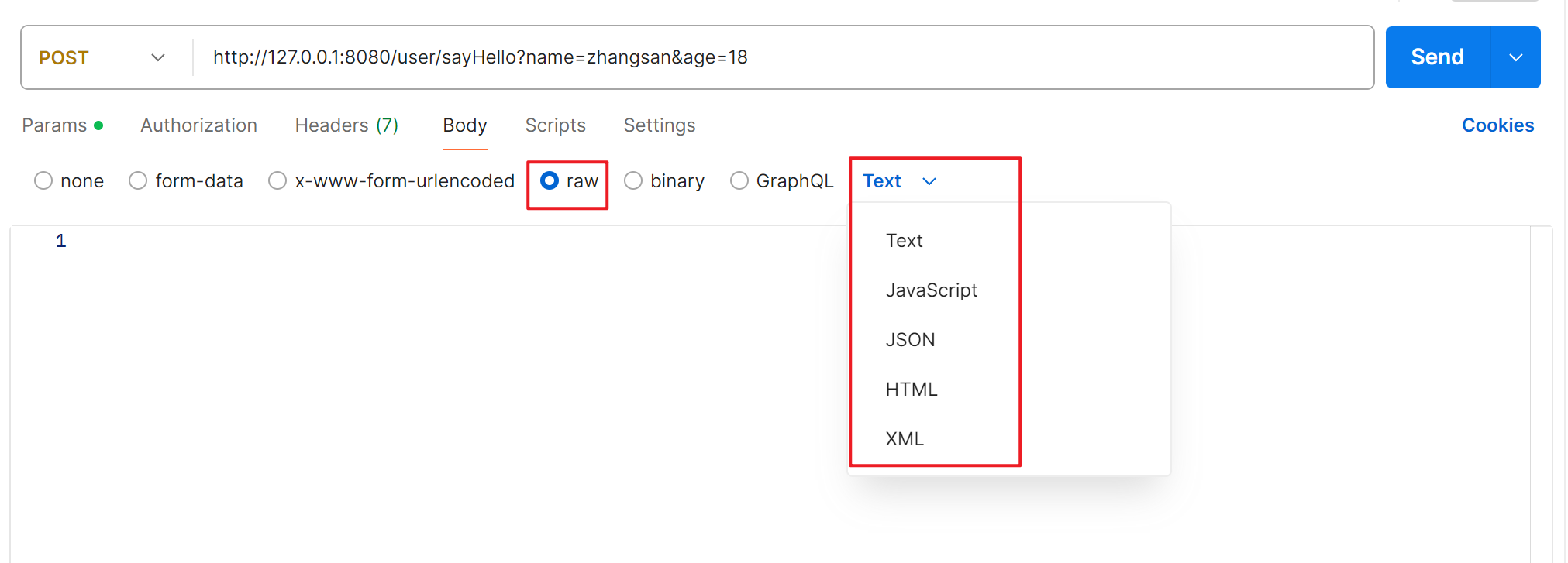
【Spring】@RequestMapping、@RestController和Postman
文章目录 1.RequestMapping 注解介绍2. RequestMapping 使用3. RequestMapping 是 GET 还是 POST 请求?GET 请求POST 请求指定 GET/POST 方法类型 2. Postman 介绍1. 创建请求2. 传参介绍1. 普通传参2. form-data3. x-www-form-urlencoded form 表单,对应…...
详细理解并附实现代码。)
【深度学习基础模型】回声状态网络(Echo State Networks, ESN)详细理解并附实现代码。
【深度学习基础模型】回声状态网络(Echo State Networks, ESN)详细理解并附实现代码。 【深度学习基础模型】回声状态网络(Echo State Networks, ESN)详细理解并附实现代码。 文章目录 【深度学习基础模型】回声状态网络…...

Redis的基础认识与在ubuntu上的安装教程
来自Redis的自我介绍 我是Redis,一个中间件,职责是把数据存储在内存上,因此可以作为数据库、缓存、消息队列等场景使用。由于可以把数据存储在内存上,因此江湖人称快枪手 1.redis的功能特性 (1)数据在内存…...

鸿蒙harmonyos next flutter混合开发之ohos工程引用 har 文件
创建鸿蒙原生工程MyApplication。创建flutter module,生成har文件,并且将flutter module中.ohos文件entryability/EntryAbility.ets、pages/Index.ets分别替换MyApplication中的。 # 1. 创建 flutter子模块工程 flutter create -t module my_flutter_…...

react-问卷星项目(5)
实战 路由 路由设计,网址和页面的关系,就是从业务上分析需要哪些页面哪些页面内容可以抽离,业务流程要有入有出增加页面和Layout模版,模版就是抽离页面公共部分,比如都有顶部或者左侧导航,直接上代码&…...

08.useInterval
在 React 应用中,实现定时器功能通常需要使用 setInterval() 和 clearInterval(),这可能会导致代码复杂和难以维护。useInterval 钩子提供了一种声明式的方法来实现定时器功能,使得定时器的管理更加简单和直观。这个自定义钩子不仅简化了定时器的使用,还解决了一些常见的定…...

【Android 源码分析】Activity生命周期之onDestroy
忽然有一天,我想要做一件事:去代码中去验证那些曾经被“灌输”的理论。 – 服装…...

增强现实中的物体识别与跟踪
增强现实(AR)中的物体识别与跟踪是实现虚拟内容与现实世界无缝融合的关键技术。以下是该领域的主要技术和方法概述: 1. 物体识别 1.1 特征提取 SIFT、SURF、ORB:传统的特征提取算法用于识别图像中的关键点并生成描述符…...
)
移动端实现下拉刷新和上拉加载(内含案例)
在前端开发中,上拉加载和下拉刷新常用于实现内容的动态加载,尤其在移动端的应用中。下面我将提供一个简单的示例和逻辑说明。 1. 逻辑说明: 下拉刷新: 用户向下拖动页面顶部,触发一个事件,刷新当前内容。需…...

Opencv第十一章——视频处理
1. 读取并显示摄像头视频 1.1 VideoCapture类 VideoCapture类提供了构造方法VideoCapture(),用于完成摄像头的初始化工作,其语法格式如下: capture cv2.VideoCapture(index) 参数说明: capture:要打开的摄像头视频。 index:摄像头设备索引。…...

Flutter 3.24 AAPT: error: resource android:attr/lStar not found.
在Android build,gradle下面,添加右边红框的代码: subprojects {afterEvaluate { project ->if (project.plugins.hasPlugin("com.android.application") ||project.plugins.hasPlugin("com.android.library")) {project.androi…...
)
C++——输入一个2*3的矩阵, 将这个矩阵向左旋转90度后输出。(要求:使用指针完成。)
没注释的源代码 #include <iostream> using namespace std; int main() { int a[2][3]; cout<<"请输入一个2*3的矩阵:"<<endl; for(int i0;i<2;i) { for(int j0;j<3;j) { cin>>a[i][j…...

AI芯片WT2605C赋能厨房家电,在线对话操控,引领智能烹饪新体验:尽享高效便捷生活
在智能家居的蓬勃发展中,智能厨电作为连接科技与生活的桥梁,正逐步渗透到每一个现代家庭的厨房中。蒸烤箱作为智能厨电的代表,以其丰富的功能和高效的性能,满足了人们对美食的多样化追求。然而,面对众多复杂的操作功能…...

详解调用钉钉AI助理消息API发送钉钉消息卡片给指定单聊用户
文章目录 前言准备工作1、在钉钉开发者后台创建一个钉钉企业内部应用;2、创建并保存好应用的appKey和appSecret,后面用于获取调用API的请求token;3、了解AI助理主动发送消息API:4、应用中配置好所需权限:4.1、权限点4.…...

57 长短期记忆网络(LSTM)_by《李沐:动手学深度学习v2》pytorch版
系列文章目录 文章目录 系列文章目录长短期记忆网络(LSTM)门控记忆元输入门、忘记门和输出门候选记忆元 (相当于RNN中计算 H t H_t Ht)记忆元隐状态 从零开始实现初始化模型参数定义模型训练和预测 简洁实现小结练习 长短期记忆网络(LSTM&a…...

Linux系统安装教程
Linux安装流程 一、前置准备工作二、开始安装Linux 一、前置准备工作 安装好VMWare虚拟机,并下载Linux系统的安装包; Linux安装包路径为:安装包链接 , 提取码为:4tiM 二、开始安装Linux...

Autosar诊断开发避坑指南:CANFD升级后ECU不响应?可能是你的CANTP帧头格式搞错了!
Autosar诊断开发实战:CANFD升级中的CANTP帧头陷阱与精准避坑策略 当传统CAN网络向CANFD迁移时,诊断协议栈的适配问题往往成为工程师的"午夜噩梦"。我曾亲眼见证一个团队花费两周时间追踪ECU无响应问题,最终发现仅仅是CANTP层单帧格…...

JLink版本不兼容?手把手教你解决APM32F003F6P6在Keil V5.14下的烧写闪退与报错
JLink与Keil版本冲突全解析:APM32F003F6P6烧写难题终极指南 当你深夜加班调试APM32F003F6P6,Keil突然弹出"Error Flash Download failed"然后闪退,JLink软件在你选择芯片型号后直接消失——这种工具链版本冲突带来的"玄学&quo…...

DCGAN原理解析:用卷积结构根治GAN模式坍缩
1. 项目概述:从手写数字到逼真猫脸,DCGAN如何让生成模型真正“看见”图像结构你有没有试过训练一个最基础的GAN,结果生成器输出的全是模糊的、像打了马赛克的灰扑扑色块?或者更糟——所有生成的图片都长得一模一样,只是…...

Claude Mythos:AI自主攻防与零日漏洞发现的范式革命
1. 项目概述:一场静默却震耳欲聋的AI能力跃迁这周,整个AI安全圈没有爆炸性新闻稿,没有铺天盖地的发布会直播,只有一份措辞克制、数据密集的系统卡片(System Card)和一份由英国AI安全研究所(AISI…...

CookieCloud终极指南:一劳永逸解决多设备登录烦恼的完整方案
CookieCloud终极指南:一劳永逸解决多设备登录烦恼的完整方案 【免费下载链接】CookieCloud CookieCloud是一个和自架服务器同步浏览器Cookie和LocalStorage的小工具,支持端对端加密,可设定同步时间间隔。本仓库包含了插件和服务器端源码。Coo…...

如何快速安装xfce-winxp-tc:10分钟打造XP风格的Linux桌面
如何快速安装xfce-winxp-tc:10分钟打造XP风格的Linux桌面 【免费下载链接】xfce-winxp-tc Windows XP stuff for XFCE 项目地址: https://gitcode.com/gh_mirrors/xf/xfce-winxp-tc 你是否怀念经典的Windows XP界面?xfce-winxp-tc项目让你在Linux…...

Unity SLG框架解析:Clash Engine六维系统架构与工程实践
1. 这不是“又一个SLG模板”,而是把“部落冲突”式玩法真正拆开揉碎的工程实践你有没有试过在Unity里搭一个像《部落冲突》那样的SLG?不是那种只有几个按钮、拖拽兵种就完事的Demo,而是真正能跑通资源采集→建筑升级→兵种训练→多线程战斗→…...

什么是虚拟化
什么是虚拟化? 什么是虚拟化 虚拟化长期以来一直是一项基础 IT 技术,使企业能够在一台物理机器上运行多个独立的系统。 虚拟化是一种允许从单个物理机创建多个虚拟环境的技术。这些虚拟环境基本上是以前与硬件绑定的功能的逻辑(虚拟ÿ…...
:仅支持至2024年Q3 API v2退役前)
【限时开放】ElevenLabs波斯文语音调试秘钥包(含Persian SSML扩展标签库、RTL音频波形对齐工具、实时音素诊断CLI):仅支持至2024年Q3 API v2退役前
更多请点击: https://intelliparadigm.com 第一章:ElevenLabs波斯文语音支持的演进与技术边界 ElevenLabs自2022年推出多语言TTS服务以来,波斯文(Farsi)长期处于实验性支持阶段。早期版本仅能通过自定义音色音素级微调…...

fastapi · FastAPI framework, high performance, easy to learn, fast to code, ready for production
fastapi FastAPI framework, high performance, easy to learn, fast to code, ready for production 本文整理自 GitHub,经重新整理编辑。 FastAPI framework, high performance, easy to learn, fast to code, ready for production Documentation: https://fas…...