数据揭秘:分类与预测技术在商业洞察中的应用与实践
分类与预测:数据挖掘中的关键任务
在数据挖掘的广阔天地中,分类与预测就像是一对互补的探险家,它们携手深入数据的丛
林,揭示隐藏的宝藏。
一、分类:数据的归类大师
分类是一种将数据点按照特定的属性或特征划分到不同类别中的过程。
就像图书馆管理员根据书籍的内容将其放置到正确的书架上,以便读者能够轻松找到。
例子一:邮件分类(垃圾邮件检测)
想象一下,我们的邮箱每天都会收到大量的邮件,其中不乏垃圾邮件。
那我们呢应该如何自动将这些邮件分类呢?我们可以使用机器学习中的朴素贝叶斯分类器来
实现。
from sklearn.model_selection import train_test_splitfrom sklearn.feature_extraction.text import CountVectorizerfrom sklearn.naive_bayes import MultinomialNBfrom sklearn.pipeline import make_pipeline# 假设我们有一些邮件内容和它们的标签(0 表示正常邮件,1 表示垃圾邮件)emails = [("Hey there, I thought you might find this interesting.", 0),("Special offer! Buy now and get 50% off.", 1),# ... 更多邮件数据]email_texts, email_labels = zip(*emails)# 创建一个管道,包括文本向量化器和朴素贝叶斯分类器model = make_pipeline(CountVectorizer(), MultinomialNB())# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(email_texts, email_labels, test_size=0.2)# 训练模型model.fit(X_train, y_train)# 测试模型predicted_labels = model.predict(X_test)在这个例子中,我们首先将邮件文本转换为数字特征,然后使用朴素贝叶斯分类器进行训练
和预测。通过这种方式,我们可以自动识别垃圾邮件,并对其进行分类。
例子二:图像识别(猫狗分类)
图像识别是分类技术的一个广泛应用领域。
下面是一个使用卷积神经网络(CNN)来区分猫狗图片的例子。
from keras.models import Sequentialfrom keras.layers import Conv2D, MaxPooling2D, Flatten, Densefrom keras.preprocessing.image import ImageDataGenerator# 创建CNN模型model = Sequential([Conv2D(32, (3, 3), activation='relu', input_shape=(150, 150, 3)),MaxPooling2D(2, 2),Conv2D(64, (3, 3), activation='relu'),MaxPooling2D(2, 2),Conv2D(128, (3, 3), activation='relu'),MaxPooling2D(2, 2),Flatten(),Dense(512, activation='relu'),Dense(1, activation='sigmoid')])model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])# 使用ImageDataGenerator来预处理图像并增强数据train_datagen = ImageDataGenerator(rescale=1./255)test_datagen = ImageDataGenerator(rescale=1./255)train_generator = train_datagen.flow_from_directory('train_data', # 训练数据目录target_size=(150, 150),batch_size=32,class_mode='binary')validation_generator = test_datagen.flow_from_directory('validation_data', # 验证数据目录target_size=(150, 150),batch_size=32,class_mode='binary')# 训练模型model.fit(train_generator,steps_per_epoch=100, # 每轮的训练步数epochs=15,validation_data=validation_generator,validation_steps=50, # 验证步数verbose=2)在这个例子中,我们构建了一个简单的CNN模型来识别图片中的猫和狗。
通过图像数据的预处理和模型训练,我们可以实现自动化的图像分类。
二、预测:数据的未来学家
预测是基于历史数据来估计未来的趋势或值。
就像天气预报员根据气象数据预测未来的天气状况。
例子一:股票价格预测
假设我们是一家投资公司,想要预测某只股票的未来价格。
我们可以使用时间序列分析中的LSTM(长短期记忆网络)来预测股票价格。
from keras.models import Sequentialfrom keras.layers import LSTM, Denseimport numpy as np# 假设我们有一系列的历史股票价格数据stock_prices = np.array([100, 102, 105, 107, 110, 108, 112, 115, 118, 120])# 数据预处理,将数据转换为适合LSTM的格式def create_dataset(dataset, look_back=1):X, Y = [], []for i in range(len(dataset)-look_back-1):a = dataset[i:(i+look_back)]X.append(a)Y.append(dataset[i + look_back])return np.array(X), np.array(Y)look_back = 3X, Y = create_dataset(stock_prices, look_back)# 构建LSTM模型model = Sequential()model.add(LSTM(50, input_shape=(look_back, 1)))model.add(Dense(1))model.compile(loss='mean_squared_error', optimizer='adam')# 训练模型model.fit(X, Y, epochs=100, batch_size=1, verbose=2)# 进行预测predicted_stock_price = model.predict(X)在这个例子中,我们使用LSTM网络来学习股票价格的时间序列数据,并预测未来的价格。
这对于投资者来说是一个非常有价值的工具。
除此之外我们还可以再探讨两个不同的例子,用以展示分类与预测在数据挖掘中的多样化应
用。
例子一:医疗诊断之心脏病诊断(分类)
在医疗领域,分类技术可以帮助医生通过分析患者的各种生理参数来诊断疾病。
下面是一个使用决策树算法进行心脏病诊断的例子。
from sklearn.tree import DecisionTreeClassifierfrom sklearn.metrics import classification_reportimport pandas as pd# 假设我们有一个包含患者生理参数和心脏病诊断结果的DataFramedata = pd.read_csv('heart_disease_data.csv')X = data.drop('target', axis=1) # 特征y = data['target'] # 标签(1表示有心脏病,0表示没有)# 划分训练集和测试集X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 创建决策树分类器clf = DecisionTreeClassifier()# 训练模型clf.fit(X_train, y_train)# 进行预测y_pred = clf.predict(X_test)# 评估模型print(classification_report(y_test, y_pred))在这个例子中,我们使用了决策树分类器来根据患者的年龄、性别、胆固醇水平、血压等参4
数来预测是否有心脏病的风险。
分类报告将给出模型的精确度、召回率和其他性能指标。
例子二:房地产价格预测之房价预测(回归预测)
在房地产领域,预测技术可以帮助投资者和开发商估计房地产的未来价值。
下面是一个使用线性回归模型来预测房价的例子。
from sklearn.linear_model import LinearRegressionfrom sklearn.model_selection import cross_val_score# 假设我们有一个DataFrame,其中包含房屋的各种特征和对应的销售价格housing_data = pd.read_csv('housing_prices.csv')X = housing_data.drop('price', axis=1) # 特征,例如:面积、房间数、位置等y = housing_data['price'] # 目标变量:房价# 创建线性回归模型regressor = LinearRegression()# 使用交叉验证来评估模型性能scores = cross_val_score(regressor, X, y, scoring='neg_mean_squared_error', cv=5)# 打印交叉验证的均方误差rmse_scores = np.sqrt(-scores)print(f'平均RMSE: {rmse_scores.mean()}')# 训练模型regressor.fit(X, y)# 假设有一个新的房屋数据点,我们想要预测它的价格new_house = [[3000, 4, 2, 1, 0]] # 例如:3000平方英尺,4个房间,2个浴室,位于区域1predicted_price = regressor.predict(new_house)print(f'预测的房价: ${predicted_price[0]:.2f}')在这个例子中,我们使用线性回归模型来预测房价。
我们通过交叉验证来评估模型的表现,并使用训练好的模型来预测新房屋的价格。
结语
通过这些详细的例子和代码,我们看到了分类与预测在数据挖掘中的重要性和实际应用。
它们不仅帮助我们理解现有的数据,还能为我们提供关于未来的洞见。
无论是在商业决策、医疗诊断、金融市场预测还是图像识别中,分类与预测都是我们不可或
缺的帮手。
相关文章:

数据揭秘:分类与预测技术在商业洞察中的应用与实践
分类与预测:数据挖掘中的关键任务 在数据挖掘的广阔天地中,分类与预测就像是一对互补的探险家,它们携手深入数据的丛 林,揭示隐藏的宝藏。 一、分类:数据的归类大师 分类是一种将数据点按照特定的属性或特征划分到不…...

学MybatisPlus
1.设置MySql的数据库 spring:datasource:url: jdbc:mysql://127.0.0.1:3306/mp?useUnicodetrue&characterEncodingUTF-8&autoReconnecttrue&serverTimezoneAsia/Shanghaidriver-class-name: com.mysql.cj.jdbc.Driverusername: rootpassword: MySQL123 logging:l…...
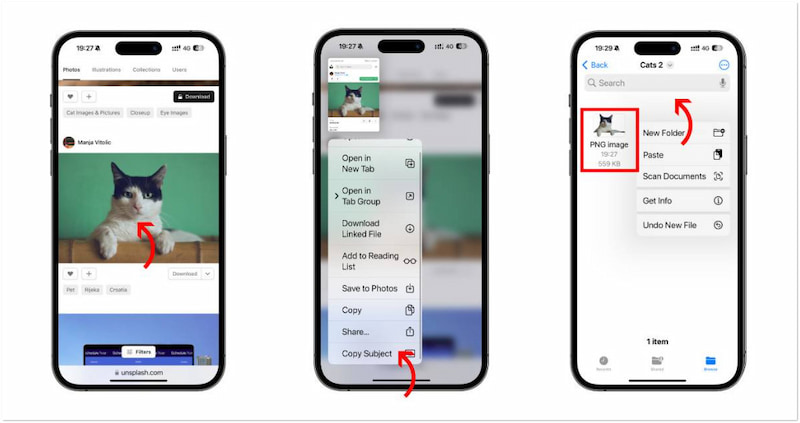
如何使用工具删除 iPhone 上的图片背景
在 iPhone 上删除背景图像变得简单易行。感谢最近 iOS 更新中引入的新功能。如今,iOS 用户现在可以毫不费力地删除背景,而无需复杂的应用程序。在这篇文章中,您将学习如何使用各种方法去除 iPhone 上的背景。这可确保您可以选择最适合您偏好的…...
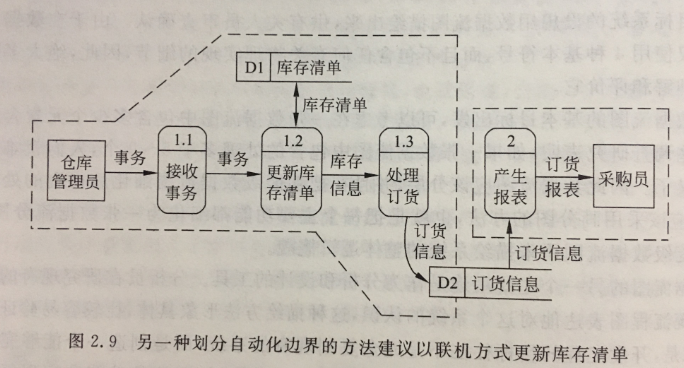
软件工程-数据流图
数据流图(Data Flow Diagram,DFD)是一种图形化技术,它描绘信息流和数据从输入移动到输出的过程中所经受的变换。 数据流图的设计原则 数据守恒原则,对于任何一个加工来说,其所有输出数据流中的数据必须能从该加工的输入数据流中…...

链式前向星(最通俗易懂的讲解)
链式前向新:用于存储图的 边集 数组 前言 当我们存储图的时候,往往会使用 邻接矩阵 或是 邻接表。 邻接矩阵 好写,但太浪费空间,节点一多就存不下; 邻接表 效率高,但涉及指 ,不好写容易出错…...
创建型模式:简单工厂模式,工厂方法模式,抽象工厂模式)
【C++设计模式】(四)创建型模式:简单工厂模式,工厂方法模式,抽象工厂模式
文章目录 (四)创建型模式:简单工厂模式,工厂方法模式,抽象工厂模式简单工厂模式工厂方法模式抽象工厂模式 (四)创建型模式:简单工厂模式,工厂方法模式,抽象工…...
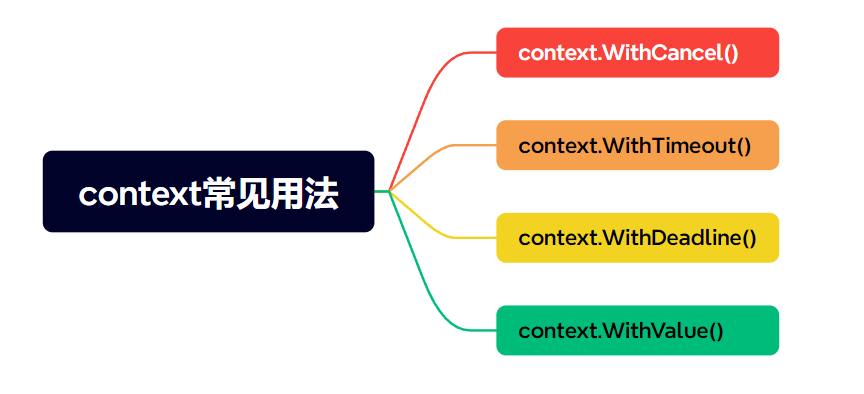
浅析Golang的Context
文章目录 1. 简介2. 常见用法2.1 控制goroutine的生命周期(cancel)2.2 传递超时(Timeout)信息2.3 传递截止时间(Deadline)2.4 传递请求范围内的全局数据 (value) 3 特点3.1 上下文的…...

生日礼物C++代码
#include<bits/stdc.h> using namespace std; string s; int a,b; int main(){cout<<" 生日之地"<<\n;cout<<" 1.开始游戏"<<" 2.不想开始"<<\n;cin>>a;if(a1||a2){if(a2)cout<<…...

使用python基于DeepLabv3实现对图片进行语义分割
DeepLabv3 介绍 DeepLabv3 是一种先进的语义分割模型,由 Google Research 团队提出。它在 DeepLab 系列模型的基础上进行了改进,旨在提高图像中像素级分类的准确性。以下是 DeepLabv3 的详细介绍: 概述DeepLabv3 是 DeepLab 系列中的第三代…...

【漏洞复现】泛微OA E-Office do_excel.php 任意文件写入漏洞
》》》产品描述《《《 泛微0-0fice是一款标准化的协同 OA办公软件,泛微协同办公产品系列成员之一,实行通用化产品设计,充分贴合企业管理需求,本着简洁易用、高效智能的原则,为企业快速打造移动化、无纸化、数字化的办公平台。 》》…...
)
算法(食物链)
240. 食物链 题目 动物王国中有三类动物 A,B,C𝐴,𝐵,𝐶,这三类动物的食物链构成了有趣的环形。 A𝐴 吃 B𝐵,B𝐵 吃 C𝐶,C𝐶 吃 A𝐴。…...

ubuntu20.04系统安装zookeeper简单教程
Ubuntu系统中安装和配置Zookeeper的完整指南 Apache Zookeeper是一个开源的分布式协调服务,广泛用于分布式应用程序中管理配置、提供命名服务、分布式同步以及组服务等。在本教程中,我们将详细介绍如何在Ubuntu系统中安装Zookeeper,并进行相关…...

.NET Core 高性能并发编程
一、高性能大并发架构设计 .NET Core 是一个高性能、可扩展的开发框架,可以用于构建各种类型的应用程序,包括高性能大并发应用程序。为了设计和开发高性能大并发 .NET Core 应用程序,需要考虑以下几个方面: 1. 异步编程 异步编程…...

B 私域模式升级:开源技术助力传统经销体系转型
一、引言 1.1 研究背景 随着市场竞争加剧,传统经销代理体系面临挑战。同时,开源技术发展迅速,为 B 私域升级带来新机遇。在当今数字化时代,企业面临着日益激烈的市场竞争。传统的经销代理体系由于管理效率低下、渠道局限、库存压…...

vue之vuex的使用及举例
Vuex是专门为Vue.js设计的集中式状态管理架构,它允许你将所有的组件共享状态存储在一个单独的地方,即“store”,并以相应的规则保证状态以一种可预测的方式发生变化。以下是Vuex的基本使用方法: 一、安装Vuex 对于Vue 2项目&…...

使用 vite 快速初始化 shadcn-vue 项目
Vite 1. 创建项目 使用 vite 创建一个新的 vue 项目。 如果你正在使用 JS 模板,需要存在 jsconfig.json 文件才能正确运行 CLI。 # npm 6.x npm create vitelatest my-vue-app --template vue-ts# npm 7, extra double-dash is needed: npm create vitelatest m…...

微信小程序:一个小程序跳转至另一个小程序
一、微信小程序支持一个小程序跳转至另一个小程序吗? 支持。 1.1、目标小程序需开放被跳转:目标小程序需要在其 app.json 文件中配置 navigateToMiniProgramAppIdList,将源小程序的 AppID 加入其中。 1.2、用户授权:用户需要授…...
)
Java第二阶段---10方法带参---第二节 方法重载(Overloading)
1.概念 在同一个类中,方法名相同,参数列表不同的多个方法构造成方法重载 2.示例 public class Calculator{public int sum(int a,int b){return ab;}public int sum(int a,int b,int c){return abc;} } 3.误区 下面的方法是否属于方法重载ÿ…...

Java Web 之 Session 详解
在 JavaWeb 开发中,Session 就像网站的专属记忆管家,为每个用户保管着重要的信息和状态,确保用户在网站的旅程顺畅无阻。 场景一: 想象你去一家大型超市购物,推着购物车挑选商品。这个购物车就如同 Sessionÿ…...

63.5 注意力提示_by《李沐:动手学深度学习v2》pytorch版
系列文章目录 文章目录 系列文章目录注意力提示生物学中的注意力提示查询、键和值注意力的可视化使用 show_heatmaps 显示注意力权重代码示例 代码解析结果 小结练习 注意力提示 🏷sec_attention-cues 感谢读者对本书的关注,因为读者的注意力是一种稀缺…...
)
【MATLAB】人脸表情识别与情感分析程序(工程实操版)
【MATLAB】人脸表情识别与情感分析程序(工程实操版) 摘要:人脸表情是人类情感表达的核心载体,人脸表情识别与情感分析技术融合了计算机视觉、图像处理、模式识别等多领域知识,广泛应用于人机交互、心理评估、智能安防、教育教学等场景。传统表情识别依赖人工判断,存在主…...
手机版通用)
真・三国无双 起源 官方正版2026最新版pc免费下载(看到请立即转存 资源随时失效)手机版通用
下载链接 破局与重塑:——《真・三国无双 起源》制作团队、玩法架构与竞品技术对标 作为光荣特库摩(Koei Tecmo)旗下最具代表性的动作砍杀IP最新作,《真・三国无双 起源》(Dynasty Warriors: Origins)在延…...

.9017R 座充充电管理 IC
概述 .9017R 是恒流/恒压座充充电管理芯片,主要应用于单节锂电池充电。应用电路无需外接检测电阻,其内部为MOSFET 结构,因此也无需外接反向二极管。 .9017R 在大功率和高环境温度下可以自动调节充电电流以限制芯片温度。它的充电电压固定在4.…...

终极免费跨平台方案:draw.io桌面版完美编辑Visio文件
终极免费跨平台方案:draw.io桌面版完美编辑Visio文件 【免费下载链接】drawio-desktop Official electron build of draw.io 项目地址: https://gitcode.com/GitHub_Trending/dr/drawio-desktop 还在为不同操作系统间的Visio文件兼容性而烦恼吗?当…...

Python核心基础
本文摘要:Python核心基础章节系统讲解了编程基础知识,主要包括:1.字面量的概念与写法,强调字符串必须使用引号包裹;2.变量与常量的定义与使用,介绍命名规则和三种命名风格;3.注释的两种形式&…...

YOLO综合训练工具X(免环境版 手动/自动标注、一键训练、模型验证、分类器训练、自动截图、批量处理
yolo免环境训练工具 yolo8标注工具 yolo训练工具 yolo8 yolo4 yolo3yolo无需搭建环境训练工具 免环境标注、训练的工具支持版本 yolo3 yolo4 yolo8(电脑显卡必须N卡) [火]可训练模型 cfg weights bin param pt yolo8l.pt yolo8m.pt yolo8n.pt yolo8s.pt yolo8x.pt 一、YOLO免环…...

在Taotoken模型广场根据任务需求与预算快速选型实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 在Taotoken模型广场根据任务需求与预算快速选型实践 面对众多大模型,如何为自己的项目选择一个既满足需求又符合预算的…...

如何快速掌握智能电源管理:macOS用户的完整配置指南
如何快速掌握智能电源管理:macOS用户的完整配置指南 【免费下载链接】SleeperX MacBook prevent idle/lid sleep! Hackintosh sleep on low battery capacity. 项目地址: https://gitcode.com/gh_mirrors/sl/SleeperX SleeperX是一款专为macOS用户设计的开源…...

【ChatGPT】基于李群、李代数与螺旋理论的 Tricept 并联加工机器人控制系统软硬件架构深度拆解、信息图10张、爆炸图10张、C++代码框架
希望还能够有机会去研究他们(前提是能够遇到好领导)深度拆解...

Python窗口美化终极指南:5分钟打造Windows 11风格界面
Python窗口美化终极指南:5分钟打造Windows 11风格界面 【免费下载链接】py-window-styles Customize your python UI window with awesome pre-built windows 11 themes. 项目地址: https://gitcode.com/gh_mirrors/py/py-window-styles 还在为Python应用程序…...