【爬虫】案例04:某小说网多线程小说下载
时光轮回,冬去春来,转眼时间来到了2023年4月。天空沥沥淅淅下着小雨,逐渐拉上了幕布。此刻,正值魔都的下班高峰,从地铁站出来的女孩子纷纷躲到一边,手指飞快的划过手机屏幕,似乎在等待男朋友送来的雨伞,亦或者是等待滴滴专车的到来,其中也不乏一些勇敢的女孩子,带上帽子,加快步伐,快速的消失在熙熙攘攘的人群中。此时,一名不起眼的少年,从人群中快速的走了出来,似乎没有注意到天空中的雨滴,迈着有力的步伐,直径冲向一家小饭馆,饭馆老板熟悉的上了他常吃的套餐,炒米粉,加素鸡和卤蛋,一顿狼吞虎咽之后,又快速起身,转身向出租屋的方向走去,穿过一段昏暗的小路,他抬起头仰望天空,清凉的雨滴打在脸上,使他疲惫的身心得到了一丝的清爽,不由得又加快了步伐,随后彻底消失在茫茫夜色中。因为他今天要创作博客,案例04:某小说网多线程小说下载
本案例仅供学习交流使用,请勿商用。如涉及版本侵权,请联系我删除。
目录
一、多线程爬虫
1. 多线程爬虫
2. 队列多线程爬虫的思路
3. Queue的使用方法
4. 生产者和消费者模型
5. 生产者消费者模型代码示例
二、某小说网多线程爬虫
1. 需求分析
2. 生产者类
3. 消费者类
4. 主函数
三、总结分析
一、多线程爬虫
1. 多线程爬虫
接上一篇文章,案例03:某图网图片多线程下载,不懂得先去看进程和线程。我们都知道线程是抢占式资源,那必然就会存在下面几个问题:
- 线程间竞争和协作问题:多个线程同时访问共享资源时,容易出现竞争和协作问题。例如,当多个线程同时对同一个变量进行修改时,可能会导致数据的不一致性;
- 有的线程抢的多,有的线程抢的少,不能大幅度的提高爬虫的效率的问题;
- 在进行I/O操作时,致使数据缺失;
为了解决这些问题,我们引入队列多线程爬虫。
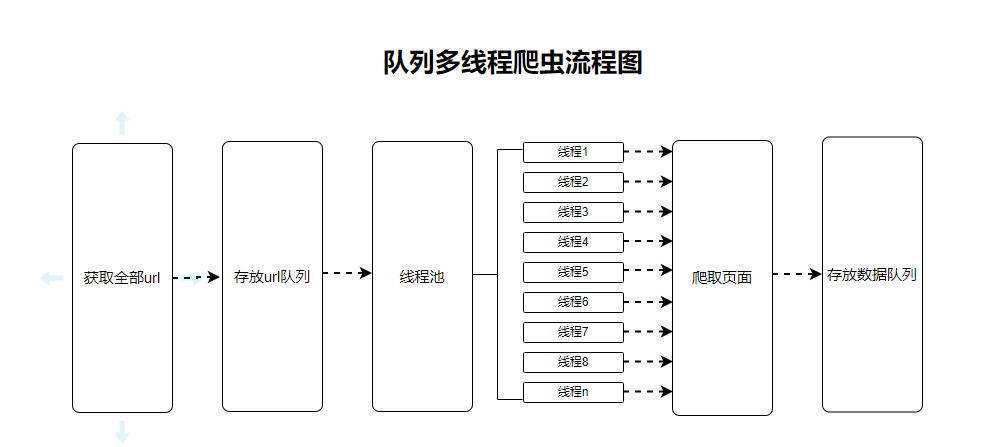
2. 队列多线程爬虫的思路
队列(queue)是计算机科学中常用的数据结构之一,它是一种先进先出(FIFO)的数据结构,类似于现实生活中的排队等待服务的过程。我们使用队列进行多线程爬虫,基本思路为创建两个队列,一个用来放url,一个用来放从url获取的结果数据,最后对结果数据进行清洗,得到我们想要的数据,下面介绍一下使用队列爬虫的创建过程和注意要点:
-
创建任务队列:首先需要创建一个任务队列,用来存储所有需要爬取的URL地址。可以使用Python内置的Queue队列,也可以使用第三方库如Redis等来实现。
-
创建线程池:创建一个包含多个线程的线程池,每个线程都会从任务队列中获取一个待爬取的URL地址进行处理。
-
编写爬取逻辑:在每个线程中编写一个爬取逻辑,用于从队列中获取一个URL地址并发起请求,获取网页内容并解析数据。具体的爬取逻辑可以根据实际需求进行编写,例如使用requests库进行网页请求,使用BeautifulSoup等库进行网页内容解析。
-
启动线程池:启动线程池,让所有线程开始处理任务队列中的URL地址。每个线程都会循环执行自己的爬取逻辑,直到任务队列为空为止。
-
添加异常处理:在爬取过程中,可能会出现各种异常情况,例如网络请求超时、网页内容解析错误等。为了保证程序的稳定性,需要添加相应的异常处理逻辑,例如重试机制、错误日志记录等。
-
控制并发度:为了防止对网站造成过大的负载压力,需要控制爬取并发度。可以通过控制线程池中的线程数、限制每个线程的请求频率等方式来实现。
-
数据存储:爬取到的数据需要进行存储,可以使用文件、数据库等方式进行存储。同时还需要考虑数据去重、数据更新等问题。
3. Queue的使用方法
| 方法 | 描述 |
|---|---|
queue.Queue([maxsize]) | 创建一个FIFO队列对象。maxsize为队列的最大长度,如果未指定或为负数,则队列长度无限制。 |
q.put(item[, block[, timeout]]) | 将元素item放入队列中。如果队列已满且block为True,则此方法将阻塞,直到有空间可用或者超时timeout。如果block为False,则此方法将引发一个Full异常。 |
q.get([block[, timeout]]) | 从队列中取出一个元素并将其返回。如果队列为空且block为True,则此方法将阻塞,直到有元素可用或者超时timeout。如果block为False,则此方法将引发一个Empty异常。 |
q.empty() | 检查队列是否为空。如果队列为空,则返回True,否则返回False。 |
q.qsize() | 返回队列中元素的数量。这种方法不可靠,因为在多线程情况下,队列长度可能会发生变化。如果要获取准确的队列长度,建议使用锁来保护队列。 |
q.queue.clear() | 清空队列中的所有元素。这种方法不是线程安全的,因此在多线程情况下需要使用锁来保护队列。 |
4. 生产者和消费者模型
生产者-消费者模型是一种并发编程模型,常用于处理大量数据的情况。在爬虫中,生产者-消费者模型被广泛应用于提高爬取效率和降低爬虫对目标网站的压力。
生产者-消费者模型通常由两部分组成:生产者和消费者。
- 生产者负责从目标网站爬取数据,并将这些数据存储到一个共享的数据结构中,如队列或缓冲区。
- 消费者从共享的数据结构中读取数据,并进行处理,例如解析数据、存储数据或者再次发送请求。
生产者-消费者模型的优势在于能够有效地处理大量数据,同时减少对目标网站的压力。通过将数据的爬取和处理分离开来,可以减少因为网络延迟或者其他原因导致的爬取效率低下的问题。此外,由于消费者和生产者可以独立运行,因此可以使用多线程或者多进程来实现并发处理,提高爬虫效率。需要注意的是,生产者-消费者模型也可能带来一些问题,例如线程同步和共享数据结构的访问冲突等。为了避免这些问题,需要在实现过程中仔细考虑线程安全和并发访问控制等问题,以确保程序的正确性和性能。简单画了一下生产者-消费者模型的流程图:
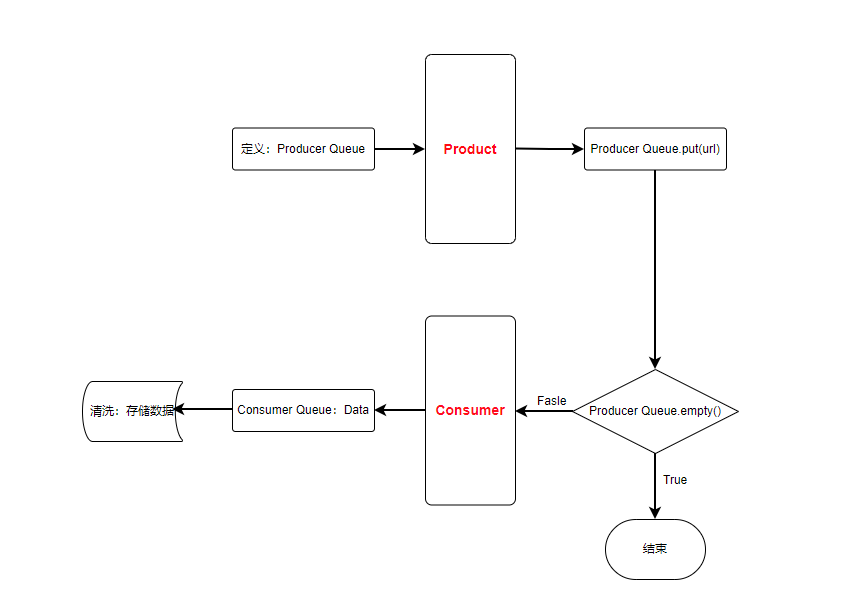
基本的思维逻辑为:
- 创建一个共享的任务队列。
- 创建若干个生产者线程,每个生产者线程负责生成任务并将其放入任务队列中。
- 创建若干个消费者线程,每个消费者线程从任务队列中取出任务并进行处理。
- 生产者线程和消费者线程之间通过共享的任务队列进行通信。
- 如果队列中没有任务了,消费者线程需要等待新的任务被生产者线程添加到队列中。
- 如果队列已满,生产者线程需要等待队列中的任务被消费者线程取出以便继续向队列中添加新的任务。
5. 生产者消费者模型代码示例
import threading
import queue
import requests
from bs4 import BeautifulSoup# 生产者线程
class ProducerThread(threading.Thread):def __init__(self, url_queue):super().__init__()self.url_queue = url_queuedef run(self):# 从网站中爬取所有的文章链接resp = requests.get('http://example.com/articles')soup = BeautifulSoup(resp.text, 'html.parser')for a in soup.find_all('a'):link = a.get('href')if link.startswith('/articles/'):# 将链接添加到队列中self.url_queue.put('http://example.com' + link)# 消费者线程
class ConsumerThread(threading.Thread):def __init__(self, url_queue, data_queue):super().__init__()self.url_queue = url_queueself.data_queue = data_queuedef run(self):while True:try:# 从队列中取出一个链接url = self.url_queue.get(timeout=10)# 爬取链接对应的文章内容resp = requests.get(url)soup = BeautifulSoup(resp.text, 'html.parser')title = soup.find('h1').textcontent = soup.find('div', {'class': 'content'}).text# 将文章内容添加到数据队列中self.data_queue.put((title, content))except queue.Empty:break# 主函数
def main():# 创建队列url_queue = queue.Queue()data_queue = queue.Queue()# 创建生产者线程和消费者线程producer_thread = ProducerThread(url_queue)consumer_thread1 = ConsumerThread(url_queue, data_queue)consumer_thread2 = ConsumerThread(url_queue, data_queue)# 启动线程producer_thread.start()consumer_thread1.start()consumer_thread2.start()# 等待线程结束producer_thread.join()consumer_thread1.join()consumer_thread2.join()# 处理爬取到的数据while not data_queue.empty():title, content = data_queue.get()# 处理文章内容print(title, content)if __name__ == '__main__':main()
使用生产者-消费者模型在爬虫中可以将数据的爬取和处理分离开来,多线程的并发处理可以大大提高爬虫的效率,减少爬虫对目标网站的访问压力,从而降低被封 IP 的风险。但是还需要考虑线程同步、共享数据结构的访问冲突等问题。
二、某小说网多线程爬虫
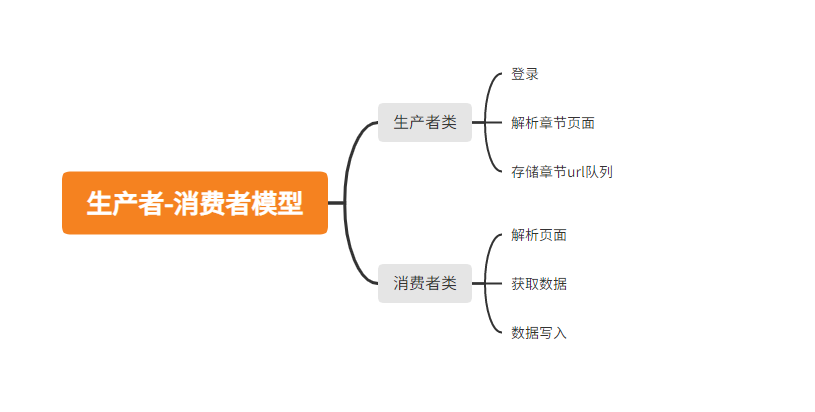
1. 需求分析
- 我的书架:需要登录;
- 生产者函数:获取一本书的每章节url,储存在队列中;
- 消费者函数:解析url页面,获取数据,存储在队列中;
- 获取消费者队列中的数据,写入本地;
2. 生产者类
生产者类实现session登录,解析页面,将url存储到队列中。
import os
import time
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import threading
import queue
import warningswarnings.filterwarnings("ignore")# 生产者类
class ProducerThread(threading.Thread):def __init__(self, url_queue):super().__init__()self.url_queue = url_queueself.session = requests.Session()self.headers = {"User-Agent": UserAgent().random}self.login()self.book_dict_list = self.get_book_dict_list()def login(self):self.session.post("url", #此处为登录请求的urldata={"loginName": "152****7662", "password": "******"},# 在此处替换自己的账号密码headers=self.headers,verify=False,)def get_book_dict_list(self):res = self.session.get("url" #此处为书架的url).json()data = res.get("data")return datadef get_chapter_urls(self, book_id):url = f"url"#此处为书的章节列表urlpage_text = requests.get(url=url).content.decode()soup = BeautifulSoup(page_text, "lxml")dl_li = soup.find("div", class_="Main List").find_all("dl", class_="Volume")urls = []for dl in dl_li:chapter_url = ["url" + a["href"] for a in dl.dd.find_all("a")]#网站urlurls.extend(chapter_url)return urlsdef run(self):for book_dict in self.book_dict_list:book_id = book_dict.get("bookId")chapter_urls = self.get_chapter_urls(book_id)for url in chapter_urls:self.url_queue.put(url)3. 消费者类
消费者函数,从队列中取出链接,解析页面,获取数据,将数据存储到结果队列中
# 消费者类
class ConsumerThread(threading.Thread):def __init__(self, url_queue, data_queue):super().__init__()self.url_queue = url_queueself.data_queue = data_queue# self.session = sessionself.headers = {"User-Agent": UserAgent().random}def run(self):while True:try:# 从队列中取出一个链接url = self.url_queue.get(timeout=10)page_text = requests.get(url=url, headers=self.headers).content.decode()soup = BeautifulSoup(page_text, "lxml")chapter_title = soup.find("div", class_="readAreaBox content").h1.stringcontent_text = soup.find("div", class_="readAreaBox content").find("div", class_="p").textchapter_text = chapter_title + "\n" + content_textchapter_text = chapter_text.replace(u"\xa0", "").replace(u"\u36d1", "").replace(u"\u200b", "")print(f'{chapter_title} ,存入队列')self.data_queue.put(({chapter_title : chapter_text}))time.sleep(0.1)except queue.Empty:breakexcept Exception as e:print(f"{url} 抓取错误...", e)continue4. 主函数
主函数中,开启了200个线程,获取解析页面和数据存储
# 主函数
def main():# 创建队列url_queue = queue.Queue()data_queue = queue.Queue()# 创建生产者线程和消费者线程producer_thread = ProducerThread(url_queue)consumer_threads = [ConsumerThread(url_queue, data_queue) for _ in range(200)]# 启动线程producer_thread.start()for consumer_thread in consumer_threads:consumer_thread.start()# 等待线程结束producer_thread.join()for consumer_thread in consumer_threads:consumer_thread.join()# 处理爬取到的数据book_path = os.path.join("./结果数据/案例04:某小说网多线程小说下载")if not os.path.exists(book_path):os.mkdir(book_path)while not data_queue.empty():chapter = data_queue.get()for title in chapter:chapter_text = chapter[title]chapter_path = os.path.join(book_path, f"{title}.txt")try:with open(chapter_path, "w", encoding='utf-8') as f:f.write(chapter_text)except Exception as e:print(f"{title} 写入错误...", e)三、总结分析
本章使用消费者-生产者模型进行了多线程的数据采集,提升了爬虫效率;使用了队列,可以将生产者线程抓取的章节链接存入队列,等待消费者线程进行抓取,避免了生产者和消费者之间的阻塞和同步问题。
但是,在执行多线程的时候,线程数量数固定的,没有根据具体需求来动态调整,可能会导致效率不高或者浪费资源。没有使用线程池来管理线程的生命周期,可能会导致线程过多、创建线程时间过长等问题。在下一章中我们通过创建线程池的方式来管理线程,继续提高爬虫的效率。附全部代码:
import os
import time
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import threading
import queue
import logging
import warningswarnings.filterwarnings("ignore")# 生产者类
class ProducerThread(threading.Thread):def __init__(self, url_queue):super().__init__()self.url_queue = url_queueself.session = requests.Session()self.headers = {"User-Agent": UserAgent().random}self.login()self.book_dict_list = self.get_book_dict_list()def login(self):self.session.post("url",#此处为登录界面的urldata={"loginName": "152****7662", "password": "******"},#在此处替换自己的账户密码headers=self.headers,verify=False,)def get_book_dict_list(self):res = self.session.get("url"#此处为书架的url).json()data = res.get("data")return datadef get_chapter_urls(self, book_id):url = f"url"#此处为书本章节的urlpage_text = requests.get(url=url).content.decode()soup = BeautifulSoup(page_text, "lxml")dl_li = soup.find("div", class_="Main List").find_all("dl", class_="Volume")urls = []for dl in dl_li:chapter_url = ["url" + a["href"] for a in dl.dd.find_all("a")]#此处为网站的url进行拼接urls.extend(chapter_url)return urlsdef run(self):for book_dict in self.book_dict_list:book_id = book_dict.get("bookId")chapter_urls = self.get_chapter_urls(book_id)for url in chapter_urls:self.url_queue.put(url)
# 消费者类
class ConsumerThread(threading.Thread):def __init__(self, url_queue, data_queue):super().__init__()self.url_queue = url_queueself.data_queue = data_queue# self.session = sessionself.headers = {"User-Agent": UserAgent().random}def run(self):while True:try:# 从队列中取出一个链接url = self.url_queue.get(timeout=10)page_text = requests.get(url=url, headers=self.headers).content.decode()soup = BeautifulSoup(page_text, "lxml")chapter_title = soup.find("div", class_="readAreaBox content").h1.stringcontent_text = soup.find("div", class_="readAreaBox content").find("div", class_="p").textchapter_text = chapter_title + "\n" + content_textchapter_text = chapter_text.replace(u"\xa0", "").replace(u"\u36d1", "").replace(u"\u200b", "")print(f'{chapter_title} ,存入队列')self.data_queue.put(({chapter_title : chapter_text}))time.sleep(0.1)except queue.Empty:breakexcept Exception as e:print(f"{url} 抓取错误...", e)continue# 主函数
def main():# 创建队列url_queue = queue.Queue()data_queue = queue.Queue()# 创建生产者线程和消费者线程producer_thread = ProducerThread(url_queue)consumer_threads = [ConsumerThread(url_queue, data_queue) for _ in range(200)]# 启动线程producer_thread.start()for consumer_thread in consumer_threads:consumer_thread.start()# 等待线程结束producer_thread.join()for consumer_thread in consumer_threads:consumer_thread.join()# 处理爬取到的数据book_path = os.path.join("./结果数据/案例04:某小说网多线程小说下载")if not os.path.exists(book_path):os.mkdir(book_path)while not data_queue.empty():chapter = data_queue.get()for title in chapter:chapter_text = chapter[title]chapter_path = os.path.join(book_path, f"{title}.txt")try:with open(chapter_path, "w", encoding='utf-8') as f:f.write(chapter_text)except Exception as e:logging.error(f"Download error: {e}") # 记录下载错误的日志print(f"{title} 写入错误...", e)if __name__ == '__main__':main()由于版权原因,取消了代码中的url,源码需要的兄弟们网盘自取,提取码:sgss
相关文章:
【爬虫】案例04:某小说网多线程小说下载
时光轮回,冬去春来,转眼时间来到了2023年4月。天空沥沥淅淅下着小雨,逐渐拉上了幕布。此刻,正值魔都的下班高峰,从地铁站出来的女孩子纷纷躲到一边,手指飞快的划过手机屏幕,似乎在等待男朋友送来…...

海外独立站创业,Shopify网站如何引流
上一期给大家科普了如何快速创建自己的独立站 但往往独立站的难点在于站外引流 今天就给大家分享可以通过哪些渠道给独立站引流 - ⚡SEO排名:Google SEO的重要性不必多说,尽快注册歌账号,并开通Google Ad和Google Merchant Center&#…...

基于51单片机的室内湿度加湿温度声光报警智能自动控制装置设计
wx供重浩:创享日记 对话框发送:单片机湿度 获取完整无水印论文报告(内含电路原理图和源程序代码) 在日常生活中加湿器得到了广泛的应用,但是现有的加湿器都需要手工控制开启和关闭并且不具备对室内空气温湿度的监测&am…...
解决:github爆 WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED!
目录1. 背景2. 解决办法3. 原因,感兴趣的可以看看1. 背景 在拉取github上一个新项目的时候爆出 WARNING: REMOTE HOST IDENTIFICATION HAS CHANGED! 第一反应是电脑被黑了,传说中的中间人攻击(题外话一下,其实所有的代理软件都算是中间人哦~…...

【django开发手册】如何使用select_related进行一次连表查询
前言 Django是一款Python Web框架,致力于充分利用Python的简洁语法和语言特性来提高Web开发的效率。其中一个强大的特性是ORM(Object-Relational Mapping),它使开发者可以使用Python代码而不是SQL查询语言来访问数据库。ORM不仅使…...

二、MySQL 基础
二、MySQL 基础 2.1 MySQL 简介 MySQL 是一款流行的开源数据库,也是一个关系型数据库管理系统 在 WEB 应用方面 MySQL 是最好的 RDBMS(Relational Database Management System:关系数据库管理系统)应用软件之一 2.1.1 MySQL 发展历史 时间里程碑1996…...
)
项目中常用写法(前端)
项目中常用写法(前端)vue等待某个方法执行结束后,在执行判断js是不是undefined类型父组件传值到子组件state的值在标签中直接使用读取html,去掉字符串中的html标签字符串去掉中括号去掉双引号判断数组中是否包含某个值在某个ui框架…...
【面试】Java并发编程面试题
文章目录基础知识为什么要使用并发编程多线程应用场景并发编程有什么缺点并发编程三个必要因素是什么?在 Java 程序中怎么保证多线程的运行安全?并行和并发有什么区别?什么是多线程多线程的好处多线程的劣势:线程和进程区别什么是…...

HAProxy和Nginx搭建负载均衡器
负载均衡器是一个常用于分布式计算和网络应用中的系统组件,主要用于将客户端的请求分发到多个后端服务器上,以实现高可用性、高性能和可扩展性。常见的负载均衡器软件包括HAProxy和Nginx。 本文将介绍负载均衡器的原理和应用,以及使用HAProx…...
对比)
【集大成篇】数据类型( C、C++、Java )对比
1、C 语言数据类型关键字取值范围内存占用字符型char -128~1271整 型short-32768~327672int-2147483648~2147483647 (10位数)4long (int)-2147483648~2147483647 (10位数)4/8long long (int)-9223372036854775808~-9223372036854775807 (19位数ÿ…...
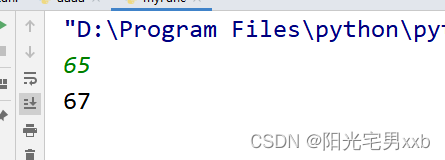
python编程:从键盘输入一个正整数n(n>2),请编程求解并输出大小最接近n的素数(n本身除外)
python编程实现:从键盘输入一个正整数n(n>2),请编程求解并输出大小最接近n的素数(n本身除外) 一、编程题目 从键盘输入一个正整数n(n>2),请编程求解并输出大小最接近n的素数(n本身除外)。 (温馨提示,结果可能是2个哦) 二、输入输出样例…...

spring的面试宝典
1、什么是spring框架? spring是一个开放源代码的设计层面框架,它解决的是业务逻辑层和其他各层的松耦合问题,是一个分层的javaEE一站式轻量级开源框 架. 2.spring的作用? 方便解耦,简化开发,AOP编程支持,声明式事务支持,集成Juni…...

ArcGIS Pro地理空间数据处理完整工作流实训及python技术融合深度应用
查看原文>>>ArcGIS Pro地理空间数据处理完整工作流实训及python技术融合深度应用 目录 第一章、ArcGIS Pro基础讲解 第二章、数据获取、整合与管理 第三章、坐标系基础与地理配准 第四章、数据编辑与查询、拓扑检查 第五章、制图基础讲解 第六章、地理处理工具…...
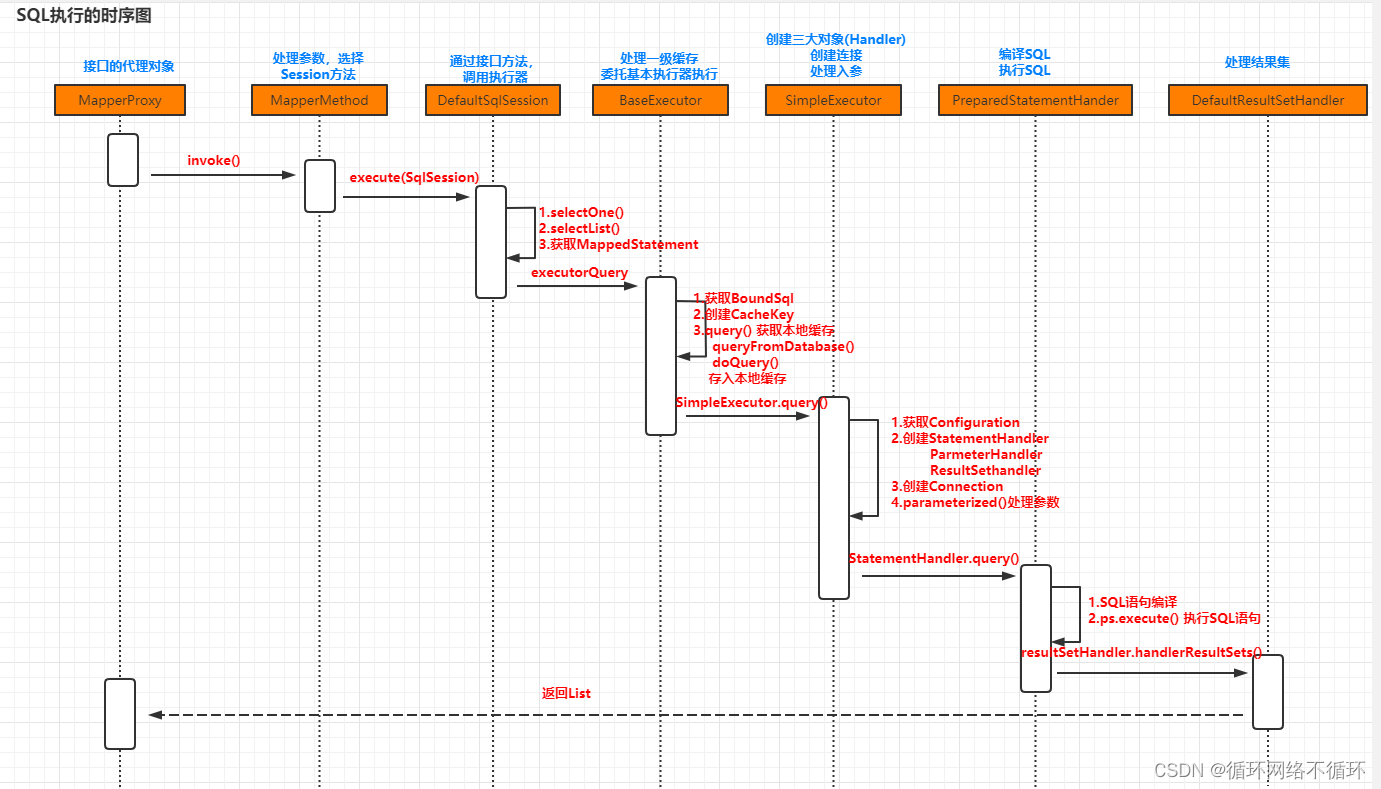
(二)MyBatis源码阅读:SqlSession分析
一、核心流程 以下代码便是MyBatis的核心流程,我们从该代码出发分析MyBatis的源码。 Testpublic void test2() throws Exception{// 1.获取配置文件InputStream in Resources.getResourceAsStream("mybatis-config.xml");// 2.加载解析配置文件并获取Sq…...
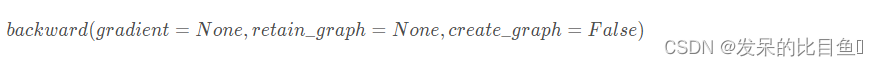
小白学Pytorch系列-- torch.autograd API
小白学Pytorch系列-- torch.autograd API torch.Autograd提供了实现任意标量值函数的自动微分的类和函数。它只需要对现有代码进行最小的更改-你只需要声明张量s,它的梯度应该用requires gradTrue关键字计算。到目前为止,我们只支持浮点张量类型(half, f…...
【大数据基础】基于零售交易数据的Spark数据处理与分析
环境搭建 sudo apt-get install python3-pip pip3 install bottle数据预处理 首先,将数据集E_Commerce_Data.csv上传至hdfs上,命令如下: ./bin/hdfs dfs -put /home/hadoop/E_Commerce_Data.csv /user/hadoop接着,使用如下命令…...

【机器学习】P14 Tensorflow 使用指南 Dense Sequential Tensorflow 实现
Tensorflow 第一节:使用指南Tensorflow 安装神经网络一些基本概念隐藏层和输出层:神经元的输出公式Tensorflow 全连接层 Dense 与 顺序模型 SequentialDense LayerSequential Model代码实现一个神经网络实现方式一:手写神经网络* 实现方式二&…...

ubuntu18.04安装nvidia驱动,3种方式图文详解+卸载教程
教程目录一、关闭secure boot二、禁用nouveau驱动2.1 创建配置文件2.2 添加内容2.3 重启电脑2.4 输入命令验证三、安装显卡驱动3.1 软件和更新(失败)3.2 PPA源安装3.3 官网安装包安装四、卸载显卡驱动笔记本类型Ubuntu系统显卡版本联想拯救者Y7000win10U…...
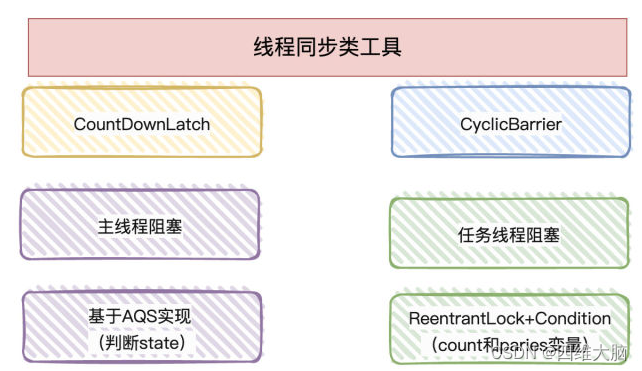
多线程进阶学习11------CountDownLatch、CyclicBarrier、Semaphore详解
CountDownLatch ①. CountDownLatch主要有两个方法,当一个或多个线程调用await方法时,这些线程会阻塞 ②. 其它线程调用countDown方法会将计数器减1(调用countDown方法的线程不会阻塞) ③. 计数器的值变为0时,因await方法阻塞的线程会被唤醒,继续执行 public static void m…...

华为OD机试用java实现 -【RSA 加密算法】
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本篇题解:RSA 加密算法 题目 RSA 加密…...

LLM Notebooks:从零构建RAG问答系统的实践指南
1. 项目概述:一个面向大语言模型实践的“笔记本”仓库最近在GitHub上闲逛,发现了一个挺有意思的仓库,叫qianniuspace/llm_notebooks。光看名字,llm_notebooks,大语言模型笔记本,这指向性就非常明确了。这大…...

如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南
如何为《欧洲卡车模拟2》实现完整智能驾驶体验?ETS2LA自动驾驶插件终极指南 【免费下载链接】Euro-Truck-Simulator-2-Lane-Assist Plugin based interface program for ETS2/ATS. 项目地址: https://gitcode.com/gh_mirrors/eur/Euro-Truck-Simulator-2-Lane-Ass…...

LearningX:构建结构化开发者知识体系,从基础到架构的实践指南
1. 项目概述:一个面向开发者的系统性学习仓库最近在GitHub上看到一个挺有意思的项目,叫“LearningX”。光看名字,你可能会觉得这又是一个普通的“Awesome-XXX”列表,或者是一堆学习资料的简单堆砌。但当我点进去,花了一…...

手把手教你用三菱FX3U PLC的RS指令和RS2指令与电脑串口调试助手‘对话’
三菱FX3U PLC串口通信实战:从零搭建RS485数据收发系统 第一次接触工业控制系统的串口通信时,我被那些密密麻麻的接线和晦涩的协议参数弄得晕头转向。直到在自动化生产线上亲眼看到PLC通过两根电线与十几台设备稳定通信,才意识到串口技术的精妙…...

如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南
如何快速掌握openpilot:从零到精通的自动驾驶系统终极指南 【免费下载链接】openpilot openpilot is an operating system for robotics. Currently, it upgrades the driver assistance system on 300 supported cars. 项目地址: https://gitcode.com/GitHub_Tre…...

如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南
如何在Mac上完美读写NTFS硬盘:Free NTFS for Mac终极指南 【免费下载链接】Free-NTFS-for-Mac Nigate: An open-source NTFS utility for Mac. It supports all Mac models (Intel and Apple Silicon), providing full read-write access, mounting, and management…...

Token工厂:从“卖流量”到“卖Token”:中国移动砸百亿建Token生态,三大运营商的AI战争升级,阿里,百度,华为,字节跟进
5月9日,2026移动云大会上,中国移动市场经营部总经理邱宝华扔出一个新概念——"Token运营体系"。未来3-5年,中国移动将投入百亿级Token生态资源,建设千亿级算力基础设施,携手共创万亿级AI产业价值。"百亿…...
,全程复制粘贴即可)
从0到1:手把手教你搭建VSCode(附避坑指南,拒绝报错),全程复制粘贴即可
🔥个人主页:北极的代码(欢迎来访) 🎬作者简介:java后端学习者 ❄️个人专栏:苍穹外卖日记,SSM框架深入,JavaWeb ✨命运的结局尽可永在,不屈的挑战却不可须臾或…...

2026生鲜店收银软件特点功能对比
每天傍晚高峰期,生鲜店门口排起的长队总是让店主心头一紧。顾客手里拿着刚挑好的蔬菜水果,眼神里透着急切,而收银台前的店员却还在手忙脚乱地查找商品代码、手动输入重量,甚至因为系统卡顿导致支付失败。这种场景不仅流失了潜在客…...

基于MCP协议构建AI金融数据可视化服务器:从原理到实战部署
1. 项目概述:一个为AI智能体提供实时金融数据可视化的MCP服务器最近在折腾AI智能体(Agent)的生态,发现一个挺有意思的痛点:当你想让AI帮你分析股票、基金或者加密货币时,它往往只能给你干巴巴的数字和文字描…...