知识图谱入门——7:阶段案例:使用 Protégé、Jupyter Notebook 中的 spaCy 和 Neo4j Desktop 搭建知识图谱
在 Windows 环境中结合使用 Protégé、Jupyter Notebook 中的 spaCy 和 Neo4j Desktop,可以高效地实现从自然语言处理(NLP)到知识图谱构建的全过程。本案例将详细论述环境配置、步骤实现以及一些扩展和不足之处。
文章目录
- 1. 环境准备
- 1.1 Neo4j Desktop 安装和配置
- 1.2 安装并启动 Protégé
- 1.3 配置 spaCy 环境(Jupyter Notebook)
- 1.3.1 安装 spaCy
- 1.3.2 安装 Jupyter 和 ipykernel
- 1.4 启动 Jupyter Notebook
- 2. 案例实现步骤
- 2.1 数据示例
- 2.2 使用 spaCy 进行实体识别和关系抽取
- 2.3 将抽取的实体和关系导入 Neo4j
- 2.4 在 Neo4j Desktop 中查看数据
- 3. Neo4j导出数据
- 3.1 在 Neo4j 中准备数据
- 3.2. 导出 Neo4j 数据
- 3.2.1 导出实体(如运动员和地点)
- 3.2.2 导出关系(如 BORN_IN)
- 4. 转换为 OWL 格式
- 4.1 使用 Python 编程库
- a. **`owlready2`**
- b. **`RDFLib`**
- 环境准备
- 案例代码
- 代码解释
- 注意事项
- 选择合适的方法
- 4.2 其他
- 5. 在 Protégé 中加载 OWL 文件和处理
- 4.1 打开 Protégé
- 4.2 创建或打开本体
- 4.3 导入 OWL 文件
- 4.4 验证数据
- 4.5 后续步骤
- 5. 案例总结
- 6. 不足与补充
- 相关阅读
1. 环境准备
1.1 Neo4j Desktop 安装和配置
- 安装 Neo4j Desktop:访问 Neo4j 官网 下载并安装 Neo4j Desktop。
- 启动本地数据库:创建一个新的数据库,并确保 Bolt 协议(默认端口:
7687)和 REST API(默认端口:7474)启用。
前置博客:
知识图谱入门——5:Neo4j Desktop安装和使用手册(小白向:Cypher 查询语言:逐步教程!Neo4j 优缺点分析)
1.2 安装并启动 Protégé
- 下载和安装 Protégé:访问 Protégé 官网 下载并安装最新版本。
- 启动 Protégé:运行应用程序并创建或打开本体项目。
前置博客:
知识图谱入门——4:Protégé 5.6.4安装和主要功能介绍、常用插件(2024年10月2日):知识图谱构建的利器
1.3 配置 spaCy 环境(Jupyter Notebook)
使用以下步骤在 Python 环境中配置 spaCy。
1.3.1 安装 spaCy
运行以下命令创建虚拟环境并安装 spaCy 和中文模型(因为有库冲突,建议新建环境):
# 创建虚拟环境
python -m venv spacy_env# 激活虚拟环境
spacy_env\Scripts\activate # Windows# 安装 spaCy
pip install spacy
python -m spacy download zh_core_web_sm # 中文模型
1.3.2 安装 Jupyter 和 ipykernel
确保可以在 Jupyter Notebook 中使用 spaCy 虚拟环境:
pip install jupyter ipykernel
python -m ipykernel install --name spacy_env --display-name "spacy_env"
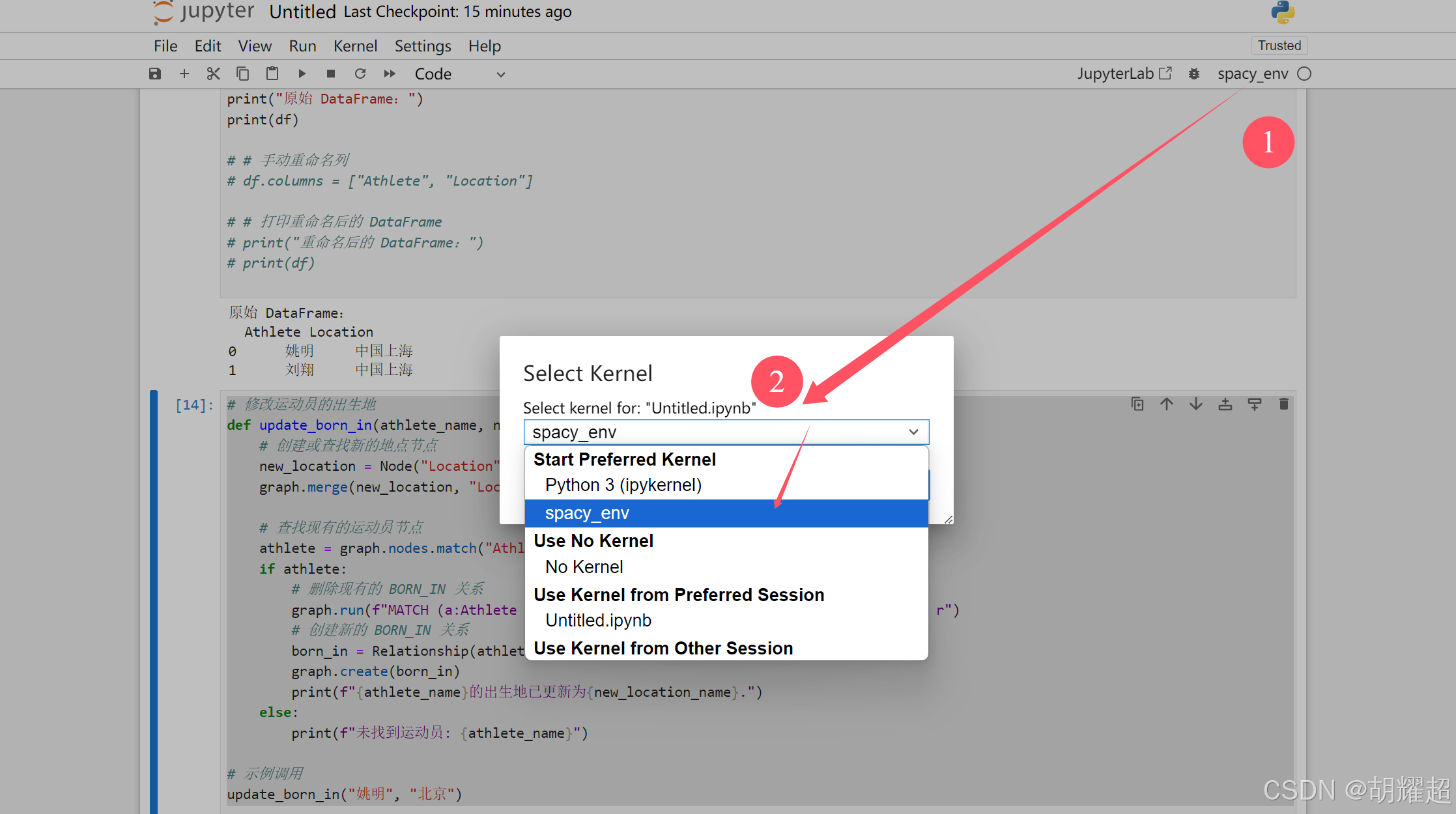
1.4 启动 Jupyter Notebook
在虚拟环境中运行 Jupyter Notebook:
jupyter notebook
在新建的笔记本中选择内核为 “spaCy Environment”。
2. 案例实现步骤
2.1 数据示例
假设我们有如下文本数据,描述了一些运动员的信息:
姚明,出生于中国上海,前中国篮球运动员,曾效力于NBA休斯顿火箭队。
刘翔,出生于中国上海,前中国田径运动员,曾获得奥运会110米栏冠军。
2.2 使用 spaCy 进行实体识别和关系抽取
在 Jupyter Notebook 中,使用 spaCy 进行命名实体识别(NER):
import spacy# 加载中文模型
nlp = spacy.load("zh_core_web_sm")# 示例文本
texts = ["姚明,出生于中国上海,前中国篮球运动员,曾效力于NBA休斯顿火箭队。","刘翔,出生于中国上海,前中国田径运动员,曾获得奥运会110米栏冠军。"
]# 处理文本
for text in texts:doc = nlp(text)print(f"Processing text: {text}")for ent in doc.ents:print(f"Entity: {ent.text}, Label: {ent.label_}")

2.3 将抽取的实体和关系导入 Neo4j
我们使用 py2neo 将抽取的实体和关系导入到 Neo4j(使用前要启动!):
from py2neo import Graph, Node, Relationship# 连接到 Neo4j 本地数据库
graph = Graph("bolt://localhost:7687", auth=("neo4j", "password(12345678)"))# 创建节点和关系
for text in texts:doc = nlp(text)entities = [ent.text for ent in doc.ents]if len(entities) >= 2:athlete = Node("Athlete", name=entities[0])location = Node("Location", name=entities[1])# 创建节点graph.merge(athlete, "Athlete", "name")graph.merge(location, "Location", "name")# 创建关系born_in = Relationship(athlete, "BORN_IN", location)graph.merge(born_in)# 打印插入信息print(f"Added {entities[0]} born in {entities[1]} to Neo4j")


2.4 在 Neo4j Desktop 中查看数据
使用 Neo4j 的 Cypher 查询语言检查插入的数据:
MATCH (a:Athlete)-[r:BORN_IN]->(l:Location)
RETURN a, r, l
都可以点击*和查询语言:

3. Neo4j导出数据
将 Neo4j 中的数据加载到 Protégé 进行本体管理,通常通过导出 Neo4j 的数据并转换为 OWL(Web Ontology Language)格式,再在 Protégé 中导入。以下是详细步骤:
3.1 在 Neo4j 中准备数据
确保 Neo4j 数据库中包含所有希望导入到 Protégé 的实体和关系。使用 Cypher 查询检查数据,例如:
MATCH (a:Athlete)-[r:BORN_IN]->(l:Location)
RETURN a, r, l
整体导出:

效果如:

3.2. 导出 Neo4j 数据
利用 Neo4j 提供的工具或 Cypher 查询将数据导出为 CSV 格式,步骤如下:
3.2.1 导出实体(如运动员和地点)
使用以下 Cypher 查询导出 Athlete 和 Location 节点为 CSV 文件(导出同上,不在截图):
// 导出运动员数据
MATCH (a:Athlete)
RETURN a.name AS Name
// 导出地点数据
MATCH (l:Location)
RETURN l.name AS Name
在 Neo4j 浏览器中,点击结果表格右上角的导出按钮,选择 “CSV” 格式。
3.2.2 导出关系(如 BORN_IN)
使用以下查询导出运动员与出生地之间的关系:
// 导出关系数据
MATCH (a:Athlete)-[r:BORN_IN]->(l:Location)
RETURN a.name AS Athlete, l.name AS Location
同样,将结果导出为 CSV 文件。
4. 转换为 OWL 格式
下面是几种常用的方法,将数据转换为 OWL 格式的综述,包括编程库、图形化工具和在线服务:
4.1 使用 Python 编程库
a. owlready2
- 功能: 提供一个简单的 API 来创建和管理 OWL 本体。
- 优点: 灵活、强大,适合需要编程的用户。
- 示例代码:
import pandas as pd from owlready2 import *# 创建 OWL 本体 onto = get_ontology("http://example.com/ontology.owl")# 定义类和属性 with onto:class Athlete(Thing): passclass Location(Thing): passclass BORN_IN(ObjectProperty):domain = [Athlete]range = [Location]# 读取 CSV 数据并转换 data_df = pd.read_csv('data.csv') for _, row in data_df.iterrows():athlete_instance = Athlete(row['a'].split("{name: ")[1].rstrip("}").strip('"'))location_instance = Location(row['l'].split("{name: ")[1].rstrip("}").strip('"'))athlete_instance.BORN_IN.append(location_instance)# 保存为 OWL 文件 onto.save("output.owl")
b. RDFLib
- 功能: 一个用于处理 RDF 数据的 Python 库,支持多种数据格式的转换。
- 优点: 灵活,可用于批量处理和自动化任务。
- 操作示例:
- 读取 CSV 文件并构建 RDF 图,然后使用 RDFLib 保存为 OWL 格式。
以下是一个使用 RDFLib 的简单案例,演示如何使用 Python 创建一个 RDF 图,添加一些三元组,并将其导出为 OWL 格式。
- 读取 CSV 文件并构建 RDF 图,然后使用 RDFLib 保存为 OWL 格式。
环境准备
确保你已经安装了 RDFLib。如果还没有安装,可以使用 pip 安装:
pip install rdflib
案例代码
以下代码示例演示了如何创建一个简单的 RDF 图,添加一些数据,然后将其导出为 OWL 文件。
from rdflib import Graph, URIRef, Literal, RDF, RDFS# 创建一个 RDF 图
g = Graph()# 定义命名空间
EX = URIRef("http://example.com/")# 添加类
g.add((EX.Athlete, RDF.type, RDFS.Class))
g.add((EX.Location, RDF.type, RDFS.Class))# 添加属性
g.add((EX.BORN_IN, RDF.type, RDF.Property))
g.add((EX.BORN_IN, RDFS.domain, EX.Athlete))
g.add((EX.BORN_IN, RDFS.range, EX.Location))# 添加个体
g.add((EX.LiuXiang, RDF.type, EX.Athlete))
g.add((EX.LiuXiang, RDFS.label, Literal("刘翔")))
g.add((EX.YaoMing, RDF.type, EX.Athlete))
g.add((EX.YaoMing, RDFS.label, Literal("姚明")))g.add((EX.LiuXiang, EX.BORN_IN, EX.ChinaShanghai))
g.add((EX.ChinaShanghai, RDF.type, EX.Location))
g.add((EX.ChinaShanghai, RDFS.label, Literal("中国上海")))g.add((EX.YaoMing, EX.BORN_IN, EX.Beijing))
g.add((EX.Beijing, RDF.type, EX.Location))
g.add((EX.Beijing, RDFS.label, Literal("北京")))# 保存为 OWL 文件
g.serialize(destination="output.owl", format="xml")print("RDF 图已保存为 output.owl 文件。")
代码解释
- 创建图:首先,我们创建一个新的 RDF 图。
- 定义命名空间:使用
URIRef定义一个基础的命名空间,方便后续引用。 - 添加类和属性:通过
g.add()方法添加Athlete和Location类,以及BORN_IN属性。 - 添加个体:为每个运动员和地点创建个体,并定义其标签和类型。
- 导出为 OWL:最后,将构建好的 RDF 图导出为 OWL 格式的 XML 文件。
注意事项
- 确保 RDFLib 已正确安装,并与 Python 版本兼容。
- 如果需要自定义更多复杂的关系和属性,可以在此基础上扩展代码。
选择合适的方法
- 编程用户: 使用
owlready2或RDFLib,适合需要自定义处理逻辑的场景。 - 非编程用户: 使用 Protégé 或在线工具,适合需要直观操作的用户。
- 临时处理: 在线工具提供快速解决方案,但功能可能有限。
根据你的具体需求和技术背景,可以选择最适合的方法来完成数据到 OWL 格式的转换。
4.2 其他
- Protégé插件:在 Protégé 中导入 CSV 数据通常需要使用插件,因为 Protégé 默认并不直接支持 CSV
格式的导入。这里就不在介绍。 - 使用在线工具:查找网站
5. 在 Protégé 中加载 OWL 文件和处理
4.1 打开 Protégé
启动 Protégé 应用程序。
4.2 创建或打开本体
- 新项目:点击 “File” > “New Project” 创建新本体。
- 现有项目:点击 “File” > “Open Project” 打开已有本体。

4.3 导入 OWL 文件
- 在 Protégé 菜单中,选择 File > Import…。
- 选择刚创建的 OWL 文件并点击 Next。
- 根据需要选择“完全导入”或“部分导入”。
- 点击 Finish 完成导入。
4.4 验证数据
在 Protégé 中浏览导入的类、个体和关系,确保数据正确显示并可管理。
4.5 后续步骤
- 在 Protégé 中进一步修改本体结构、添加注释、定义属性等。
- 根据需求设计新关系和类,增强本体语义。
通过这些步骤,你可以将 Neo4j 中的数据成功加载到 Protégé 中进行本体管理。
5. 案例总结
通过以上步骤,我们成功将 spaCy、Neo4j 和 Protégé 结合起来,构建了一个从文本处理到知识图谱的完整工作流。这种方法不仅提高了知识图谱构建的效率,还能够通过 Protégé 进行更加灵活的本体管理。
6. 不足与补充
- 数据质量:依赖于输入文本的质量,错误或模糊的信息可能导致不准确的实体识别。
- 扩展性:在处理复杂关系时,可能需要定义更多的关系和属性。
- 性能:在大规模数据集上运行可能会影响性能,需优化数据处理逻辑。
| 问题 | 解决方案 |
|---|---|
| 实体识别错误 | 提高模型训练数据的质量 |
| 关系定义不足 | 增加更多的关系定义和处理逻辑 |
| 性能问题 | 使用异步处理或批量操作 |
这种集成流程为从自然语言处理到知识图谱构建提供了高效的工具链,使得信息的存储和检索变得更加方便。随着项目的发展,你可以根据实际需求扩展这个流程,处理更多复杂的数据和关系。
相关阅读
- 专栏:知识图谱:从0到 ∞
- 知识图谱入门——1:基本概念、为什么要用?核心步骤、常用工具与技术、应用场景
- 知识图谱入门——2:技术体系基本概念:知识表示与建模、知识抽取与挖掘、知识存储与融合、知识推理与检索
- 知识图谱入门——3:工具分类与对比(知识建模工具:Protégé、 知识抽取工具:DeepDive、知识存储工具:Neo4j)
- 知识图谱入门——6:Cypher 查询语言高级组合用法(查询链式操作、复杂路径匹配、条件逻辑、动态模式创建,以及通过事务控制和性能优化处理大规模数据。
相关文章:
知识图谱入门——7:阶段案例:使用 Protégé、Jupyter Notebook 中的 spaCy 和 Neo4j Desktop 搭建知识图谱
在 Windows 环境中结合使用 Protg、Jupyter Notebook 中的 spaCy 和 Neo4j Desktop,可以高效地实现从自然语言处理(NLP)到知识图谱构建的全过程。本案例将详细论述环境配置、步骤实现以及一些扩展和不足之处。 文章目录 1. 环境准备1.1 Neo4j…...

【AIGC】VoiceControl for ChatGPT指南:轻松开启ChatGPT语音对话模式
博客主页: [小ᶻZ࿆] 本文专栏: AIGC | ChatGPT 文章目录 💯前言💯安装VoiceControl for ChatGPT插件💯如何使用VoiceControl for ChatGPT进行语音输入VoiceControl for ChatGPT快捷键注意点 💯VoiceControl for C…...

基于SpringCloud的微服务架构下安全开发运维准则
为什么要进行安全设计 微服务架构进行安全设计的原因主要包括以下几点: 提高数据保护:微服务架构中,服务间通信频繁,涉及到大量敏感数据的交换。安全设计可以确保数据在传输和存储过程中的安全性,防止数据泄露和篡改。…...

vue的图片显示
通过参数 调用方法 进行显示图片 方法一: 方法二:...

深度学习06:线性回归模型
线性回归:从理论到实现 1. 什么是线性回归? 线性回归是一种用于预测因变量(目标值)和自变量(特征值)之间关系的基本模型。它假设目标值(y)是特征值(x)的线性…...

Angular ng-state script 元素的生成机制介绍
ng-state 的生成过程是在 Angular SSR 中非常关键的部分。为了让客户端能够接管服务器渲染的页面状态,Angular 在服务器端需要将应用的当前状态保存下来,并将其嵌入到返回的 HTML 中。这样,客户端在接管时就可以直接使用这些状态,…...

小程序-全局数据共享
目录 1.什么是全局数据共享 2. 小程序中的全局数据共享方案 MboX 1. 安装 MobX 相关的包 2. 创建 MobX 的 Store 实例 3. 将 Store 中的成员绑定到页面中 4. 在页面上使用 Store 中的成员 5. 将 Store 中的成员绑定到组件中 6. 在组件中使用 Store 中的成员 1.什么是全…...

vSAN01:vSAN简介、安装、磁盘组、内部架构与调用关系
目录 传统的共享存储vSAN存储OSA的系统要求vSAN安装vSAN集群vSAN skyline healthvSAN与HA磁盘组混合磁盘架构全闪磁盘架构 vSAN对象vSAN内部架构 传统的共享存储 通过隔离的存储网络使得不同的ESXi主机访问独立的存储设备。需要前期投入较高的资金单独采购存储、网络可以单独规…...

Apache NiFi最全面试题及参考答案
目录 解释什么是Apache NiFi以及它的主要用途。 NiFi 的数据处理流程是怎样的? NiFi 的架构包括哪些组件? 解释 NiFi 的 “FlowFile” 概念及其组成部分。 NiFi 的 “Processor” 是什么?有哪些类型? 如何在 NiFi 中创建一个新的数据流? NiFi 的 “Connection” 有…...

基于Docker部署最新版本SkyWalking【10.1.0版本】
文章目录 前言前置条件一、创建Docker 网络二、部署 SkyWalking OAP 服务器三 部署 SkyWalking UI四 查看日志4.1. 查看 SkyWalking OAP 日志4.2. 查看 SkyWalking UI 日志 五 停止并删除容器结论 前言 由于本地的 JDK 版本与 SkyWalking 对应的 JDK 版本不一致,为…...

如何在 Ubuntu 18.04 上使用 LEMP 安装 WordPress
前些天发现了一个巨牛的人工智能学习网站,通俗易懂,风趣幽默,忍不住分享一下给大家。点击跳转到网站。 简介 WordPress 是互联网上最流行的 CMS(内容管理系统)。它允许您在 MySQL 后端和 PHP 处理的基础上轻松设置灵…...
)
shadcn-vue 快速入门(2)
components.json 关于项目配置 components.json 文件保存了项目的配置信息。 我们使用该文件了解项目的基本设定,并生成定制化的组件以适应项目需求。 注意:components.json 文件是可选的,仅在使用 CLI 向项目添加组件时才需要。如果使用复…...

Oracle数据恢复—异常断电导致Oracle数据库报错的数据恢复案例
Oracle数据库故障: 机房异常断电后,Oracle数据库启库报错:“system01.dbf需要更多的恢复来保持一致性,数据库无法打开”。数据库没有备份,归档日志不连续。用户方提供了Oracle数据库的在线文件,需要恢复zxf…...

数据结构-4.1.特殊矩阵的压缩存储
一.一维数组的存储结构: 1.知道一维数组的起始地址,就可以求出任意下标对应的元素所在的地址; 2.注:如果数组下标从1开始,上述公式的i就要改为i-1; 3.数组里的元素类型相同,因此所占空间也相同…...
)
Hive数仓操作(十四)
一、Hive的DDL语句 在 Hive 中,DDL(数据定义语言)语句用于数据库和表的创建、修改、删除等操作。以下是一些重要的 DDL 语句: 1. 创建数据库和表 创建数据库 CREATE DATABASE IF NOT EXISTS database_name;创建表 CREATE TABLE …...

SpringBoot技术:实现古典舞在线交流平台的秘诀
摘 要 随着互联网技术的发展,各类网站应运而生,网站具有新颖、展现全面的特点。因此,为了满足用户古典舞在线交流的需求,特开发了本古典舞在线交流平台。 本古典舞在线交流平台应用Java技术,MYSQL数据库存储数据&#…...

自动驾驶系列—全面解析自动驾驶线控制动技术:智能驾驶的关键执行器
🌟🌟 欢迎来到我的技术小筑,一个专为技术探索者打造的交流空间。在这里,我们不仅分享代码的智慧,还探讨技术的深度与广度。无论您是资深开发者还是技术新手,这里都有一片属于您的天空。让我们在知识的海洋中…...

YOLO11改进|卷积篇|引入可变核卷积AKConv
目录 一、AKConv卷积1.1AKConv卷积介绍1.2AKConv核心代码 五、添加MLCA注意力机制5.1STEP15.2STEP25.3STEP35.4STEP4 六、yaml文件与运行6.1yaml文件6.2运行成功截图 一、AKConv卷积 1.1AKConv卷积介绍 AKConv允许卷积参数的数量以线性方式增加或减少,而不是传统的…...

推荐 uniapp 相对好用的海报生成插件
插件地址:自定义canvas样式海报 - DCloud 插件市场 兼容性也是不错的:...
)
MySQL表操作(进阶)
一、数据库约束 1、约束类型 NOT NULL - 指示某列不能存储 NULL 值 UNIQUE - 保证某列的每行必须有唯一的值 DEFAULT - 规定没有给列赋值时的默认值 PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标 识ÿ…...

告别手动肝船!碧蓝航线自动化脚本Alas终极使用指南
告别手动肝船!碧蓝航线自动化脚本Alas终极使用指南 【免费下载链接】AzurLaneAutoScript Azur Lane bot (CN/EN/JP/TW) 碧蓝航线脚本 | 无缝委托科研,全自动大世界 项目地址: https://gitcode.com/gh_mirrors/az/AzurLaneAutoScript 还在为碧蓝航…...

Leetcode 思路-105.从前序与中序序列构造二叉树
105.从前序与中序序列构造二叉树给定两个整数数组 preorder 和 inorder ,其中 preorder 是二叉树的先序遍历, inorder 是同一棵树的中序遍历,请构造二叉树并返回其根节点。1.简单思路根据先序遍历根节点在前的特点,取到根节点后&a…...

法学论文降AI工具免费推荐:2026年法学毕业论文知网AIGC超标4.8元一次过完整方案
法学论文降AI工具免费推荐:2026年法学毕业论文知网AIGC超标4.8元一次过完整方案 论文AI率超标这件事,选错工具比不选工具更耽误事。 综合试用和口碑,法学论文降AI我主推嘎嘎降AI(www.aigcleaner.com),4.8…...
)
高性价比AI编程神器Claude Code+deepseek v4 pro+vscode——详细安装指南(2026最新版)
一.简介 这套组合性价比极高。关于Claude Code:它由Anthropic公司打造,是直接运行在终端中的AI编程助手,让你不用离开命令行就能完成代码生成、调试、重构、甚至Git提交等各种开发任务。本文将带你完成安装与配置。众所周知Claude 模型集强大…...
)
告别手动!用Windows批处理脚本批量重命名MKV音轨(MkvToolnix v73实战)
告别手动!用Windows批处理脚本批量重命名MKV音轨(MkvToolnix v73实战) 每次整理下载的剧集资源时,最让人头疼的莫过于音轨信息错乱——明明视频是国语配音,音轨标签却显示为日语。手动修改不仅效率低下,还容…...
)
从‘打包’到‘压缩’:一文理清Linux tar命令的-z、-j、-J参数该怎么选(附性能对比)
从‘打包’到‘压缩’:一文理清Linux tar命令的-z、-j、-J参数该怎么选(附性能对比) 在Linux系统管理中,文件归档与压缩是每位开发者绕不开的基础操作。当你面对几十GB的日志文件需要备份,或是需要将数百张高分辨率图片…...

GD32 RISC-V BSP框架设计:从硬件抽象到跨平台移植实战
1. 项目概述:为什么我们需要一个专属的BSP框架?如果你正在使用GD32的RISC-V内核MCU,比如GD32VF103系列,并且是从STM32或者其他ARM Cortex-M平台转过来的,那你大概率踩过这样的坑:官方提供的固件库ÿ…...

手把手教你用YOLOv5/PyTorch在DOTA V1.5数据集上训练自己的航拍目标检测模型
从零构建航拍目标检测模型:YOLOv5DOTA V1.5实战指南 当无人机镜头掠过城市上空,传回的40004000像素高清图像中,棒球场、港口集装箱、高速公路立交桥等目标如何被精准识别?本文将带您用YOLOv5框架,在包含18.8万实例的DO…...

给AI模型选‘口粮’:MIT-BIH、CPSC、PTB-XL,哪个ECG数据集更适合你的项目?
给AI模型选‘口粮’:三大ECG数据集深度评测与实战指南 当心电图(ECG)分析遇上人工智能,数据质量直接决定模型性能天花板。PhysioNet作为全球最大的生物医学信号开放平台,其收录的MIT-BIH、CPSC-2018和PTB-XL三大经典EC…...
一键Root)
保姆级教程:红米K70澎湃OS解锁BL后,如何用Delta面具(德尔塔面具)一键Root
红米K70澎湃OS深度Root指南:Delta面具全流程实战解析 在安卓玩机圈里,Root始终是释放设备潜力的终极钥匙。对于手持红米K70并已解锁Bootloader的进阶用户而言,Delta面具(Magisk Delta)无疑是当前最安全、最稳定的Root解…...