YOLO11改进|卷积篇|引入可变核卷积AKConv

目录
- 一、AKConv卷积
- 1.1AKConv卷积介绍
- 1.2AKConv核心代码
- 五、添加MLCA注意力机制
- 5.1STEP1
- 5.2STEP2
- 5.3STEP3
- 5.4STEP4
- 六、yaml文件与运行
- 6.1yaml文件
- 6.2运行成功截图
一、AKConv卷积
1.1AKConv卷积介绍

AKConv允许卷积参数的数量以线性方式增加或减少,而不是传统的平方增长趋势。这种特性对于硬件环境非常有益,因为它可以根据实际需求动态调整参数数量,从而实现更高效的资源利用。在资源有限的情况下,AKConv能够帮助网络模型在保持性能的同时,减少参数数量和计算开销,这对于轻量级模型的设计尤为重要。
其次,AKConv为网络性能的提升提供了更多的选择。在资源充足的情况下,使用大核卷积时,AKConv能够利用更多的选项来优化网络性能。由于其采样形状的灵活性和可调整性,AKConv能够更好地适应不同目标形状的变化,从而提高网络的识别能力和泛化性能。
此外,AKConv的思想还可以扩展到特定领域。根据先验知识,可以创建特定的采样形状用于卷积操作,并通过偏移量动态、自动地适应目标形状的变化。这种灵活性使得AKConv能够更好地适应各种复杂场景和任务需求。
AKConv的结构与工作流程如下所示
-
输入
输入的数据为 (C,H,W) 的特征图,表示通道数为 C,高度为 H,宽度为 W。 -
卷积层生成偏移量
首先,通过一个标准的卷积操作(Conv2d)来生成偏移量(offset)。该偏移量的输出维度为 (2𝑁,𝐻,𝑊),其中 N 是卷积核的大小,比如 3×3 的卷积核则 𝑁=9,2 表示偏移量包含 𝑥 和 𝑦 方向上的坐标变化。
偏移量解释:偏移量是用于调整采样位置的。普通卷积在固定的规则网格上进行采样,而加入偏移量后,采样点可以在原来固定的位置上根据偏移量进行微调,从而能够更好地捕捉几何变化。 -
计算新的采样坐标
原始卷积的采样点是规则排列的坐标集,比如 3×3
的卷积核对应固定的9个采样点坐标。现在,将这些原始采样点加上通过卷积生成的偏移量,得到新的采样点坐标。
公式:新的坐标 = 原始坐标 + 偏移量
这样可以在原始特征图中动态选择采样点,以更好地适应特征的几何变形和空间分布。 -
重采样(Resample)
接下来,根据计算得到的新采样坐标,对原始输入的特征图进行重采样操作。这一步类似于根据新的坐标在原始特征图上重新采集局部特征。
通过偏移量调整后的采样形状和采样点可以更灵活地捕捉到特征的局部变化。 -
合并特征通道对于每个通道 (𝐶,𝑘𝑠,𝑘𝑠)
的特征,经过采样后形成新的特征块。这些重采样后的特征块被合并在一起,得到一个新的特征图 (𝐶×𝑠,𝐻,𝑊),其中 𝑠 是卷积核的数量,如 𝑠=5。 -
后处理(Reshape, Conv, Norm, SiLU)
经过重采样后的特征图经过一系列标准的后处理步骤:
Reshape:调整特征图的维度,使其适合后续的卷积操作。
Conv:标准的卷积操作进一步处理融合后的特征。
Norm:归一化层,用于稳定网络训练。
SiLU:激活函数,增强非线性表达能力。 -
输出
最后,经过处理的特征图输出结果,其尺寸仍为 (𝐶,𝐻,𝑊)
,但这些特征包含了经过动态调整采样位置后的增强特征。

1.2AKConv核心代码
import torch
import torch.nn as nn
import math
from einops import rearrangeclass AKConv(nn.Module):def __init__(self, inc, outc, num_param, stride=1, bias=None):super(AKConv, self).__init__()self.num_param = num_paramself.stride = strideself.conv = nn.Sequential(nn.Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias),nn.BatchNorm2d(outc),nn.SiLU()) # the conv adds the BN and SiLU to compare original Conv in YOLOv5.self.p_conv = nn.Conv2d(inc, 2 * num_param, kernel_size=3, padding=1, stride=stride)nn.init.constant_(self.p_conv.weight, 0)self.p_conv.register_full_backward_hook(self._set_lr)@staticmethoddef _set_lr(module, grad_input, grad_output):grad_input = (grad_input[i] * 0.1 for i in range(len(grad_input)))grad_output = (grad_output[i] * 0.1 for i in range(len(grad_output)))def forward(self, x):# N is num_param.offset = self.p_conv(x)dtype = offset.data.type()N = offset.size(1) // 2# (b, 2N, h, w)p = self._get_p(offset, dtype)# (b, h, w, 2N)p = p.contiguous().permute(0, 2, 3, 1)q_lt = p.detach().floor()q_rb = q_lt + 1q_lt = torch.cat([torch.clamp(q_lt[..., :N], 0, x.size(2) - 1), torch.clamp(q_lt[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_rb = torch.cat([torch.clamp(q_rb[..., :N], 0, x.size(2) - 1), torch.clamp(q_rb[..., N:], 0, x.size(3) - 1)],dim=-1).long()q_lb = torch.cat([q_lt[..., :N], q_rb[..., N:]], dim=-1)q_rt = torch.cat([q_rb[..., :N], q_lt[..., N:]], dim=-1)# clip pp = torch.cat([torch.clamp(p[..., :N], 0, x.size(2) - 1), torch.clamp(p[..., N:], 0, x.size(3) - 1)], dim=-1)# bilinear kernel (b, h, w, N)g_lt = (1 + (q_lt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_lt[..., N:].type_as(p) - p[..., N:]))g_rb = (1 - (q_rb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_rb[..., N:].type_as(p) - p[..., N:]))g_lb = (1 + (q_lb[..., :N].type_as(p) - p[..., :N])) * (1 - (q_lb[..., N:].type_as(p) - p[..., N:]))g_rt = (1 - (q_rt[..., :N].type_as(p) - p[..., :N])) * (1 + (q_rt[..., N:].type_as(p) - p[..., N:]))# resampling the features based on the modified coordinates.x_q_lt = self._get_x_q(x, q_lt, N)x_q_rb = self._get_x_q(x, q_rb, N)x_q_lb = self._get_x_q(x, q_lb, N)x_q_rt = self._get_x_q(x, q_rt, N)# bilinearx_offset = g_lt.unsqueeze(dim=1) * x_q_lt + \g_rb.unsqueeze(dim=1) * x_q_rb + \g_lb.unsqueeze(dim=1) * x_q_lb + \g_rt.unsqueeze(dim=1) * x_q_rtx_offset = self._reshape_x_offset(x_offset, self.num_param)out = self.conv(x_offset)return out# generating the inital sampled shapes for the AKConv with different sizes.def _get_p_n(self, N, dtype):base_int = round(math.sqrt(self.num_param))row_number = self.num_param // base_intmod_number = self.num_param % base_intp_n_x,p_n_y = torch.meshgrid(torch.arange(0, row_number),torch.arange(0,base_int))p_n_x = torch.flatten(p_n_x)p_n_y = torch.flatten(p_n_y)if mod_number > 0:mod_p_n_x,mod_p_n_y = torch.meshgrid(torch.arange(row_number,row_number+1),torch.arange(0,mod_number))mod_p_n_x = torch.flatten(mod_p_n_x)mod_p_n_y = torch.flatten(mod_p_n_y)p_n_x,p_n_y = torch.cat((p_n_x,mod_p_n_x)),torch.cat((p_n_y,mod_p_n_y))p_n = torch.cat([p_n_x,p_n_y], 0)p_n = p_n.view(1, 2 * N, 1, 1).type(dtype)return p_n# no zero-paddingdef _get_p_0(self, h, w, N, dtype):p_0_x, p_0_y = torch.meshgrid(torch.arange(0, h * self.stride, self.stride),torch.arange(0, w * self.stride, self.stride))p_0_x = torch.flatten(p_0_x).view(1, 1, h, w).repeat(1, N, 1, 1)p_0_y = torch.flatten(p_0_y).view(1, 1, h, w).repeat(1, N, 1, 1)p_0 = torch.cat([p_0_x, p_0_y], 1).type(dtype)return p_0def _get_p(self, offset, dtype):N, h, w = offset.size(1) // 2, offset.size(2), offset.size(3)# (1, 2N, 1, 1)p_n = self._get_p_n(N, dtype)# (1, 2N, h, w)p_0 = self._get_p_0(h, w, N, dtype)p = p_0 + p_n + offsetreturn pdef _get_x_q(self, x, q, N):b, h, w, _ = q.size()padded_w = x.size(3)c = x.size(1)# (b, c, h*w)x = x.contiguous().view(b, c, -1)# (b, h, w, N)index = q[..., :N] * padded_w + q[..., N:] # offset_x*w + offset_y# (b, c, h*w*N)index = index.contiguous().unsqueeze(dim=1).expand(-1, c, -1, -1, -1).contiguous().view(b, c, -1)x_offset = x.gather(dim=-1, index=index).contiguous().view(b, c, h, w, N)return x_offset# Stacking resampled features in the row direction.@staticmethoddef _reshape_x_offset(x_offset, num_param):b, c, h, w, n = x_offset.size()# using Conv3d# x_offset = x_offset.permute(0,1,4,2,3), then Conv3d(c,c_out, kernel_size =(num_param,1,1),stride=(num_param,1,1),bias= False)# using 1 × 1 Conv# x_offset = x_offset.permute(0,1,4,2,3), then, x_offset.view(b,c×num_param,h,w) finally, Conv2d(c×num_param,c_out, kernel_size =1,stride=1,bias= False)# using the column conv as follow, then, Conv2d(inc, outc, kernel_size=(num_param, 1), stride=(num_param, 1), bias=bias)x_offset = rearrange(x_offset, 'b c h w n -> b c (h n) w')return x_offset五、添加MLCA注意力机制
5.1STEP1
首先找到ultralytics/nn文件路径下新建一个Add-module的python文件包【这里注意一定是python文件包,新建后会自动生成_init_.py】,如果已经跟着我的教程建立过一次了可以省略此步骤,随后新建一个AKConv.py文件并将上文中提到的注意力机制的代码全部粘贴到此文件中,如下图所示

5.2STEP2
在STEP1中新建的_init_.py文件中导入增加改进模块的代码包如下图所示

5.3STEP3
找到ultralytics/nn文件夹中的task.py文件,在其中按照下图添加,同样的如果已经跟我的教程走过一遍了这部分可以省略

5.4STEP4
定位到ultralytics/nn文件夹中的task.py文件中的def parse_model(d, ch, verbose=True): # model_dict, input_channels(3)函数添加如图代码,【如果不好定位可以直接ctrl+f搜索定位】

六、yaml文件与运行
6.1yaml文件
以下是在yolo11.yaml中添加AKConv卷积的yaml文件,大家可以注释自行调节,效果以自己的数据集结果为准
# Ultralytics YOLO 🚀, AGPL-3.0 license
# YOLO11 object detection model with P3-P5 outputs. For Usage examples see https://docs.ultralytics.com/tasks/detect# Parameters
nc: 80 # number of classes
scales: # model compound scaling constants, i.e. 'model=yolo11n.yaml' will call yolo11.yaml with scale 'n'# [depth, width, max_channels]n: [0.50, 0.25, 1024] # summary: 319 layers, 2624080 parameters, 2624064 gradients, 6.6 GFLOPss: [0.50, 0.50, 1024] # summary: 319 layers, 9458752 parameters, 9458736 gradients, 21.7 GFLOPsm: [0.50, 1.00, 512] # summary: 409 layers, 20114688 parameters, 20114672 gradients, 68.5 GFLOPsl: [1.00, 1.00, 512] # summary: 631 layers, 25372160 parameters, 25372144 gradients, 87.6 GFLOPsx: [1.00, 1.50, 512] # summary: 631 layers, 56966176 parameters, 56966160 gradients, 196.0 GFLOPs# YOLO11n backbone
backbone:# [from, repeats, module, args]- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2- [-1, 1, AKConv, [128, 3, 2]] # 1-P2/4- [-1, 2, C3k2, [256, False, 0.25]]- [-1, 1, AKConv, [256, 3, 2]] # 3-P3/8- [-1, 2, C3k2, [512, False, 0.25]]- [-1, 1, AKConv, [512, 3, 2]] # 5-P4/16- [-1, 2, C3k2, [512, True]]- [-1, 1, AKConv, [1024, 3, 2]] # 7-P5/32- [-1, 2, C3k2, [1024, True]]- [-1, 1, SPPF, [1024, 5]] # 9- [-1, 2, C2PSA, [1024]] # 10# YOLO11n head
head:- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 6], 1, Concat, [1]] # cat backbone P4- [-1, 2, C3k2, [512, False]] # 13- [-1, 1, nn.Upsample, [None, 2, "nearest"]]- [[-1, 4], 1, Concat, [1]] # cat backbone P3- [-1, 2, C3k2, [256, False]] # 16 (P3/8-small)- [-1, 1, AKConv, [256, 3, 2]]- [[-1, 13], 1, Concat, [1]] # cat head P4- [-1, 2, C3k2, [512, False]] # 19 (P4/16-medium)- [-1, 1, AKConv, [512, 3, 2]]- [[-1, 10], 1, Concat, [1]] # cat head P5- [-1, 2, C3k2, [1024, True]] # 22 (P5/32-large)- [[16, 19, 22], 1, Detect, [nc]] # Detect(P3, P4, P5)以上添加位置仅供参考,具体添加位置以及模块效果以自己的数据集结果为准 ,同时根据我的实验,使用这个模块训练我的数据集map有点奇怪,大家也可以实验一下
6.2运行成功截图

OK 以上就是添加AKConv卷积的全部过程了,后续将持续更新尽情期待

相关文章:
YOLO11改进|卷积篇|引入可变核卷积AKConv
目录 一、AKConv卷积1.1AKConv卷积介绍1.2AKConv核心代码 五、添加MLCA注意力机制5.1STEP15.2STEP25.3STEP35.4STEP4 六、yaml文件与运行6.1yaml文件6.2运行成功截图 一、AKConv卷积 1.1AKConv卷积介绍 AKConv允许卷积参数的数量以线性方式增加或减少,而不是传统的…...

推荐 uniapp 相对好用的海报生成插件
插件地址:自定义canvas样式海报 - DCloud 插件市场 兼容性也是不错的:...
)
MySQL表操作(进阶)
一、数据库约束 1、约束类型 NOT NULL - 指示某列不能存储 NULL 值 UNIQUE - 保证某列的每行必须有唯一的值 DEFAULT - 规定没有给列赋值时的默认值 PRIMARY KEY - NOT NULL 和 UNIQUE 的结合。确保某列(或两个列多个列的结合)有唯一标 识ÿ…...

【设计模式】软件设计原则——接口隔离迪米特
接口隔离原则引出 接口隔离原则 定义:用多个专门的接口,不使用单一的总接口,客户端不应该依赖它不需要的接口; 一个类对另一个类的依赖,应该建立在最小接口上;如果有一个大接口,里面有很多方法,如果使用一个类实现该接口,所有的类都要实现,导致代码冗余;…...

【C++】——list的介绍和模拟实现
P. S.:以下代码均在VS2019环境下测试,不代表所有编译器均可通过。 P. S.:测试代码均未展示头文件stdio.h的声明,使用时请自行添加。 博主主页:Yan. yan. …...

B树系列解析
我最近开了几个专栏,诚信互三! > |||《算法专栏》::刷题教程来自网站《代码随想录》。||| > |||《C专栏》::记录我学习C的经历,看完你一定会有收获。||| > |||《Linux专栏》࿱…...

docker 部署 WEB IDE
简介 问题描述:GitCode 的 Web IDE 不满足个人使用需求 如何解决:在本机或云服务器部署 Web IDE 如何解决 拉取容器镜像 docker pull coder/code-server 运行 docker run -d --name vscode -p 8080:8080 -p 8443:8443 -e PASSWORD"123456&quo…...

【Android】数据存储
本章介绍Android五种主要存储方式的用法,包括共享参数SharedPreferences、数据库SQLite、SD卡文件、App的全局内存,另外介绍重要组件之一的应用Application的基本概念与常见用法,以及四大组件之一的内容提供器ContentProvider的基本概念与常见…...

个人网络安全的几个重点与防御
1 浏览器 firefox 这是第一选择 如果你真的不明白可以找找各个浏览器漏洞 mail 的危险的 来自与代理和漏洞 浏览器溢出漏洞 实时注意更新就可以 2 防火墙 大家都用windows 只需在 gpedit.msc 设置 但有什么未知漏洞就不得而知了 因为美国的计划问题 网络端口溢出漏洞 但…...

python爬虫 - 初识爬虫
🌈个人主页:https://blog.csdn.net/2401_86688088?typeblog 🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html 目录 前言 一、爬虫的关键概念 (一)HTTP请求与响应 ࿰…...

tomcat版本升级导致的umask问题
文章目录 1、问题背景2、问题分析3、深入研究4、umask4.1、umask的工作原理4.2、umask的计算方式4.3、示例4.4、如何设置umask4.5、注意事项 1、问题背景 我们的java服务是打成war包放在tomcat容器里运行的,有一天我像往常一样去查看服务的日志文件,却提…...

Golang | Leetcode Golang题解之第455题分发饼干
题目: 题解: func findContentChildren(g []int, s []int) (ans int) {sort.Ints(g)sort.Ints(s)m, n : len(g), len(s)for i, j : 0, 0; i < m && j < n; i {for j < n && g[i] > s[j] {j}if j < n {ansj}}return }...
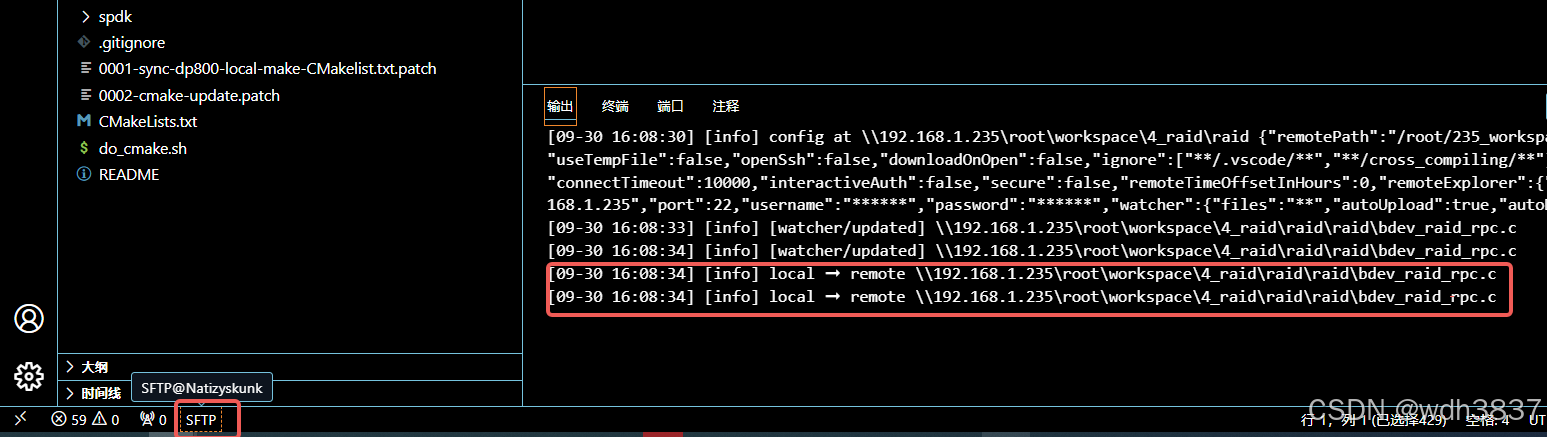
vscode+stfp插件,实现远程自动同步文件代码
概述 远程同步代码,将本地代码实时保存到同一局域网内的另一台电脑(linux系统),这里的本地代码也可以是远程服务上的代码,即从一个远程ip同步到另一台远程ip服务器。 工具 vscode,SFTP插件 安装 vscod…...

python 实现djb2哈希算法
djb2哈希算法介绍 DJB2哈希算法是一种简单且快速的哈希算法,由Daniel J. Bernstein设计。这种算法的实现非常简单,适用于短键值的哈希表,也常被用于嵌入式设备和资源受限的系统。 基本原理 DJB2算法的原理是将输入的字符串视为一个字节数组…...

文件夹作为普通文件而非子模块管理
relaxed_ik_ros2 文件夹下存在 .gitmodules 文件和 .gitignore 文件。这说明该目录已经被 Git 识别为子模块。 要将这个文件夹作为普通文件而非子模块管理,你可以按以下步骤操作: 1. 删除子模块配置 首先删除 .gitmodules 文件中的子模块配置。你可以…...

7c结构体
文章目录 一、结构体的设计二、结构体变量的初始化2.1结构体在内存表示;**2.2**结构体类型声明和 结构体变量的定义和初始化只声明结构体类型声明类型的同时定义变量p1用已有结构体类型定义结构体变量p2*定义变量的同时赋初值。*匿名声明结构体类型 2.3 结构体嵌套及…...

浅聊前后端分离开发和前后端不分离开发模式
1.先聊聊Web开发的开发框架Spring MVC 首先要知道,Spring MVC是Web开发领域的一个知名框架,可以开发基于请求-响应模式的Web应用。而Web开发的本质是遵循HTTP(Hyper Text Transfer Protocol: 超文本传输协议)协议【发请求…...
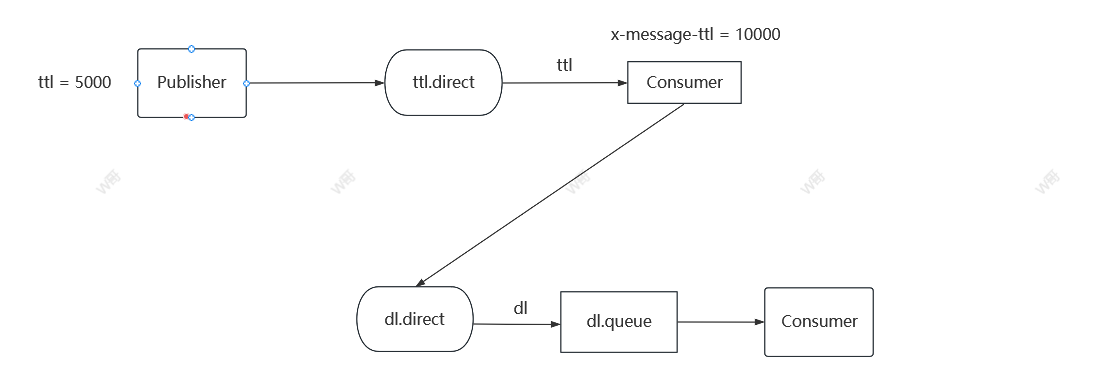
RabbitMQ篇(死信交换机)
目录 一、简介 二、TTL过期时间 三、应用场景 一、简介 当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter) 消费者使用basic.reject或者basic.nack声明消费失败,并且消息的requeue参数设置为false消息是一个过…...

HBase 的 MemStore 详解
一、MemStore 概述 MemStore 是 HBase 的内存存储区域,它是一个负责缓存数据写入操作的组件。每当有写操作(如 Put 或 Delete)发生时,数据会首先被写入到 MemStore 中,而不是直接写入磁盘。MemStore 类似于数据库中的缓…...

【嵌入式软件-数据结构与算法】01-数据结构
摘录于老师的教学课程~~(*๓╰╯๓)~~内含链表、队列、栈、循环队列等详细介绍~~ 基础知识系列 有空再继续更~~~ 目录 【链表】 一、单链表 1、存储结构:带头结点的单链表 2、单链表结点类型的定义 3、创建单链表 1)头插法 2)尾插法 …...

Aspia代码架构解析:从基础库到完整应用的开发思路
Aspia代码架构解析:从基础库到完整应用的开发思路 【免费下载链接】aspia Remote desktop and file transfer tool. 项目地址: https://gitcode.com/gh_mirrors/as/aspia Aspia是一款功能强大的开源远程桌面和文件传输工具,支持Windows、Linux和m…...

VSCodium终极指南:零监控的VS Code开源替代方案
VSCodium终极指南:零监控的VS Code开源替代方案 【免费下载链接】vscodium binary releases of VS Code without MS branding/telemetry/licensing 项目地址: https://gitcode.com/gh_mirrors/vs/vscodium VSCodium是一款基于Visual Studio Code源代码构建的…...

深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透
深入解析TRC-20代币:从技术原理到生态布局,一篇文章讲透 引言 在波场(TRON)生态中,TRC-20 代币标准扮演着至关重要的角色,它不仅是承载如USDT等巨量稳定币的基石,更是连接DeFi、GameFi和NFT等…...

Halcon实战:告别调参玄学,用dyn_threshold和var_threshold搞定复杂光照下的缺陷检测
Halcon实战:告别调参玄学,用dyn_threshold和var_threshold搞定复杂光照下的缺陷检测 在工业视觉检测中,光照不均和背景纹理干扰是最令人头疼的问题之一。想象一下这样的场景:金属表面反光导致划痕时隐时现,印刷品上的油…...

贪吃蛇游戏设计-7.完整系统
7.完整系统 完整系统Snake代码太多,另有源码。 一个基于 HarmonyOS ArkTS 开发的经典贪吃蛇游戏,适合作为 ArkTS 开发的学习项目。 功能特性 🎮 经典贪吃蛇玩法 📊 实时分数显示 🏆 最高分记录 📝 玩家姓名输入与成绩保存 📋 排行榜展示 🗑️ 排行榜滑动删除功…...

如何免费突破网盘限速?8大平台直链下载终极指南
如何免费突破网盘限速?8大平台直链下载终极指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / 天翼云盘 /…...

美团/京东/淘宝闪购外卖红包天天领取口令推荐最新发布今日实测有效的外卖红包每天免费领取入口
今日实测有效可领取外卖红包口令是:淘宝APP在闪购外卖下搜索外卖红包领取口令【 188288 】、美团APP搜索外卖红包领取口令是【 188288 】、词令直达美团/京东/淘宝闪购外卖红包领取口令是【 188288 】。作为天天点外卖的上班族,每天下单前先通过推荐的外…...

深入Linux内存管理:从虚拟内存到OOM Killer的完整解析
1. 从物理到虚拟:内存管理的演进与核心挑战干了这么多年系统开发和性能调优,内存问题始终是那个最让人头疼,但又不得不面对的“老朋友”。无论是半夜被报警叫醒处理线上服务的OOM(Out of Memory)崩溃,还是为…...

Amphenol DRPC11A009040线束解析
随着服务器、高速通信设备以及工业控制系统对高速传输性能要求不断提升,越来越多工程师开始关注高可靠性线束组件的选型问题。其中,来自 Amphenol ICC 的 DRPC11A009040 线束组件,近年来在高速连接领域中被广泛关注。 作为国际连接器品牌的重…...

不知道怎么挖漏洞?吐血整理40个网络安全漏洞挖掘姿势,看完不信你还挖不到
各位靓仔,搞网络安全,就像在雷区蹦迪,一不小心就BoomShakalaka!Web漏洞这玩意儿,说白了就是信任危机 验证掉链子。开发者们啊,总是对用户输入、权限边界和系统交互爱的太深,结果翻车了…...