python爬虫 - 初识爬虫
🌈个人主页:https://blog.csdn.net/2401_86688088?type=blog
🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html
目录
前言
一、爬虫的关键概念
(一)HTTP请求与响应
(二)HTML解析
(三)XPath和CSS选择器
(四)Robots.txt 协议
(五)反爬虫机制
(六)数据清洗
(七)数据存储
(八)多线程与异步
(九)合法性与道德问题
二、爬虫的流程
(一)明确目标与规划
(二)发送请求
(三)解析网页
(四)数据提取
(五)处理与清洗数据
(六)存储数据
(七)处理反爬机制
(八)迭代与调试
(九)数据分析与应用
(十)爬虫流程总结
三、HTTP与HTTPS协议
(一)HTTP 协议
(二)HTTPS 协议
(三)HTTP 与 HTTPS 的区别
(四)总结
四、总结
前言
Python 爬虫是一种通过编写程序自动化访问网页并从中提取信息的技术,通常用于从互联网上收集数据。它能够模拟用户浏览器行为,自动加载网页、抓取数据,并将所需信息存储在数据库或文件中,供后续分析使用。Python 是进行爬虫开发的常用语言,因为它拥有丰富的第三方库和简单易懂的语法,能够快速开发高效的爬虫。
一、爬虫的关键概念
(一)HTTP请求与响应
爬虫通过模拟浏览器发送 HTTP 请求获取网页内容,了解 HTTP 请求的结构是编写爬虫的基础。主要的 HTTP 请求类型有:
-
GET:从服务器获取资源,通常用于爬虫访问网页。
-
POST:向服务器发送数据,常用于提交表单或登录操作。 爬虫收到服务器的响应后,会处理响应中的 HTML、JSON 或其他格式的数据。
(二)HTML解析
网页的内容主要以 HTML 格式呈现,解析 HTML 是提取所需信息的关键。HTML 文档的结构为树形结构,包括标签、属性和文本内容。爬虫通过解析 HTML DOM 树,可以获取特定的标签、属性和内容。常用工具:
-
BeautifulSoup:简化 HTML 文档的解析和导航。
-
lxml:高效的 HTML 解析库,支持 XPath 查询
(三)XPath和CSS选择器
用于从 HTML 文档中精准定位和提取内容的两种常用方法:
-
XPath:XML 路径语言,可以通过路径表达式在 HTML 树中查找节点,非常强大且灵活。
-
CSS 选择器:一种更简洁的选择方式,类似于网页设计中使用的 CSS 样式选择器,适合处理简单的抓取任务。
(四)Robots.txt 协议
Robots.txt 是网站用来控制和限制爬虫行为的协议文件。爬虫应首先检查目标网站是否允许爬取特定内容或页面。Robots.txt 文件位于网站的根目录,常见指令包括:
-
User-agent:指定该规则适用于哪些爬虫。
-
Disallow:不允许爬虫访问的页面或目录。
-
Allow:允许爬虫访问的特定页面或目录。
(五)反爬虫机制
许多网站会采取措施来防止爬虫频繁访问或抓取大量内容,这些措施被称为反爬虫机制。常见的反爬手段包括:
-
IP 限制:通过检测频繁访问的 IP 地址,限制该 IP 的访问。
-
请求频率限制:网站可能通过检测请求间隔过短来判断是否为爬虫行为。
-
验证码:要求用户完成验证码以验证是否为真实用户。
-
动态内容加载:使用 JavaScript 动态加载部分内容,增加爬虫抓取的难度。
应对反爬虫机制的方法:
-
使用代理 IP:通过不断切换代理 IP,模拟不同用户的访问。
-
设置请求间隔:避免频繁请求,降低爬虫被检测到的几率。
-
模拟浏览器行为:通过设置合适的请求头(如 User-Agent)或使用 Selenium 等工具模拟用户点击、滚动等操作。
(六)数据清洗
抓取的数据往往包含许多不需要的内容,例如广告、无用的 HTML 标签等。因此,数据清洗是爬虫后处理阶段的重要任务。通过清洗可以去除冗余信息,确保抓取的数据更加干净和结构化,以便后续的分析。
(七)数据存储
爬虫获取的数据可以以多种形式存储,常见方式包括:
-
文本文件:如 CSV、JSON 格式,方便快速存储和处理。
-
数据库:如 MySQL、MongoDB,可以存储大规模、结构化的数据,适合长期管理和使用。
(八)多线程与异步
为了加快爬取速度,爬虫可以使用多线程或异步技术:
-
多线程爬虫:通过同时运行多个线程,减少等待时间,提高爬取效率。
-
异步爬虫:通过事件驱动机制,避免线程阻塞,特别适合大量 I/O 操作的场景。常用的异步库包括
aiohttp和Twisted。
(九)合法性与道德问题
使用爬虫时,必须遵守相关法律法规和道德规范。未经许可地抓取大量数据或绕过反爬虫机制可能涉及侵犯隐私或违反服务条款,甚至可能引发法律纠纷。因此,确保爬虫行为的合法性和网站许可是爬虫开发的重要前提。
二、爬虫的流程
Python 爬虫的流程通常可以分为以下几个步骤:
(一)明确目标与规划
在开始编写爬虫之前,首先需要明确目标,确定要抓取的网站和数据内容。例如,确定需要抓取的网页、数据格式以及存储方式。
(二)发送请求
爬虫通过发送 HTTP 请求来获取网页的内容。常见的请求方式包括 GET 和 POST。Python 中的 requests 库是处理 HTTP 请求的常用工具。
import requests
url = 'http://example.com'
response = requests.get(url)
在这一步骤中,爬虫向目标网站发送请求,并接收到服务器返回的 HTML 文档。
(三)解析网页
获取网页后,接下来需要解析网页,提取出所需的数据。HTML 文档通常需要通过解析工具进行结构化处理。常用的解析工具包括:
-
BeautifulSoup:通过解析 HTML,能够提取特定标签、文本和属性。
-
lxml:支持 XPath,可以更加精确地定位内容。
-
正则表达式:用于匹配特定格式的文本。
例如,使用 BeautifulSoup 提取网页标题:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, 'html.parser')
title = soup.title.string
print(title)
(四)数据提取
解析 HTML 后,需要提取具体的数据。这可以通过标签选择器、XPath 或正则表达式等技术来完成。爬虫根据目标网页的结构,提取想要的内容,如文本、链接、图片等。
举例,提取网页中的所有链接:
links = soup.find_all('a')
for link in links:print(link.get('href'))
(五)处理与清洗数据
抓取到的数据可能包含不需要的冗余信息,因此需要进行数据清洗。例如去除 HTML 标签、空格、换行符等,确保数据符合分析要求。
可以使用 Python 的内置函数或正则表达式来清理数据:
clean_data = raw_data.strip() # 去除多余的空格
(六)存储数据
数据清洗完成后,需要将数据保存以便后续处理。常见的存储方式包括:
-
文件存储:如 CSV、JSON、TXT 文件,适合小规模数据存储。
-
数据库:如 MySQL、MongoDB,适合处理大规模、结构化数据。
import csv
with open('data.csv', 'w') as file:writer = csv.writer(file)writer.writerow(['column1', 'column2']) # 写入表头writer.writerows(data_list) # 写入数据
(七)处理反爬机制
在抓取过程中,网站可能会有反爬虫机制来防止过于频繁的请求。为了应对这些反爬机制,爬虫开发者可以采取以下措施:
-
使用代理 IP:通过更换 IP 地址来避免被封禁。
-
增加请求间隔:通过设置合理的时间间隔,避免过度访问。
-
模拟用户行为:如使用
User-Agent伪装成浏览器请求。
例如,设置 User-Agent 来伪装爬虫请求:
headers = {'User-Agent': 'Mozilla/5.0'}
response = requests.get(url, headers=headers)
(八)迭代与调试
在开发和运行爬虫时,可能会遇到各种问题,比如请求失败、数据结构变化、反爬虫机制升级等。此时,需要不断调试和优化爬虫,确保其能够稳定、高效地工作。
-
多线程或异步:对于大规模爬取任务,可以使用多线程或异步编程来提高爬取效率。
-
异常处理:添加异常处理代码,确保在发生错误时,程序不会终止并且能够继续抓取其他页面。
(九)数据分析与应用
最后,爬取的数据可以用于各种分析任务,如文本分析、市场研究、情感分析等。爬虫抓取的数据往往是原始数据,需要经过进一步的处理和分析才能产生有价值的结果。
(十)爬虫流程总结
整个爬虫流程包括从请求网页、解析数据到数据清洗、存储和反爬机制的处理。流程的每一步都可以根据实际需求进行调整和优化。以下是常见的爬虫流程图示:
-
明确抓取目标
-
发送 HTTP 请求
-
解析网页
-
数据提取
-
数据清洗
-
存储数据
-
处理反爬虫
-
调试优化
三、HTTP与HTTPS协议
HTTP(HyperText Transfer Protocol,超文本传输协议)和 HTTPS(HyperText Transfer Protocol Secure,安全超文本传输协议)是两种用于在客户端(如浏览器)和服务器之间传输数据的网络协议。它们的主要区别在于安全性和数据传输方式。
(一)HTTP 协议
HTTP 是一种无状态、基于请求-响应模式的通信协议,用于在客户端和服务器之间传输数据。它的主要特点如下:
HTTP 特点:
-
明文传输:HTTP 以明文的形式传输数据,数据在传输过程中没有任何加密,这意味着第三方可以轻易拦截并读取通信内容。
-
无状态:HTTP 是无状态协议,每个请求都是独立的,服务器不会记录前后请求的状态,因此每次请求都需要传递必要的信息,比如身份验证信息。
-
简单快速:HTTP 协议设计相对简单,易于实现,通信效率高。
HTTP 工作过程:
-
客户端发送 HTTP 请求到服务器。
-
服务器接收请求后处理,并将相应的资源返回给客户端。
-
客户端解析服务器响应,显示网页或执行相关操作。
HTTP 请求示例:
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: text/html
HTTP 的不足:
-
安全性低:由于 HTTP 使用明文传输,任何中间人(如黑客)都可以拦截并读取传输的数据,容易发生数据泄露、篡改等安全问题。
-
无法验证服务器身份:用户无法通过 HTTP 验证自己连接到的服务器是否是合法的,可能会遭遇钓鱼网站。
(二)HTTPS 协议
HTTPS 是 HTTP 的安全版本,它通过 SSL(Secure Sockets Layer)/TLS(Transport Layer Security) 协议在客户端和服务器之间建立加密连接,确保数据的安全传输。HTTPS 的基本原理是在 HTTP 之上添加了一层加密协议来保护数据的完整性和隐私性。
HTTPS 特点:
-
加密传输:HTTPS 使用 SSL/TLS 协议对数据进行加密处理,确保数据在传输过程中不会被第三方窃取或篡改。即使中间人截获了数据,由于加密,内容也是无法解读的。
-
数据完整性:HTTPS 可以通过加密算法和数字签名确保数据传输的完整性,避免数据在传输过程中被修改。
-
身份验证:HTTPS 使用 SSL/TLS 证书来验证服务器的身份,确保客户端连接的是可信的服务器。这避免了钓鱼网站等问题。
HTTPS 工作过程:
-
客户端向服务器发送请求,并要求建立 SSL/TLS 加密连接。
-
服务器返回数字证书,客户端验证该证书是否可信。
-
如果证书有效,客户端与服务器之间通过 SSL/TLS 协议协商,生成对称密钥用于加密数据。
-
后续的通信数据通过加密通道传输。
HTTPS 请求示例:
GET /index.html HTTP/1.1
Host: www.example.com
User-Agent: Mozilla/5.0
Accept: text/html
与 HTTP 的请求格式相同,但底层使用加密通道进行数据传输。
HTTPS 的优势:
-
安全性高:由于加密传输和身份验证,HTTPS 保护了数据的隐私性和完整性,防止信息泄露、篡改。
-
身份验证:通过 SSL/TLS 证书,客户端可以验证服务器身份,防止钓鱼攻击。
-
搜索排名优化:搜索引擎(如 Google)偏向于对 HTTPS 网站给予更高的排名。
HTTPS 的不足:
-
性能开销:建立 HTTPS 连接需要 SSL/TLS 握手过程,相比 HTTP 增加了一些额外的开销,影响性能。
-
证书费用:为了使用 HTTPS,网站需要申请 SSL/TLS 证书,部分证书需要费用。
(三)HTTP 与 HTTPS 的区别
| 区别点 | HTTP | HTTPS |
|---|---|---|
| 安全性 | 明文传输,数据易被拦截 | 加密传输,数据安全 |
| 端口 | 默认使用端口 80 | 默认使用端口 443 |
| 证书 | 不需要证书 | 需要 SSL/TLS 证书 |
| 数据完整性 | 无法确保数据完整性,可能被篡改 | 通过加密确保数据不会被篡改 |
| 性能 | 由于无加密,性能较好 | 需要加密和解密过程,性能稍逊 |
| 身份验证 | 不进行服务器身份验证,易受中间人攻击 | 服务器通过证书进行验证,防止钓鱼网站 |
(四)总结
-
HTTP 是一种基础的通信协议,使用明文传输数据,适合对安全性要求不高的场景。
-
HTTPS 则在 HTTP 的基础上加入了 SSL/TLS 加密,提供了更高的安全性,适合任何需要保护用户隐私和数据安全的网站。
四、总结
Python 爬虫通过模拟浏览器行为自动化抓取网络数据,涉及 HTTP 请求、HTML 解析、数据清洗、存储等多个环节。开发爬虫时需要应对反爬虫机制,并遵守相关法律法规,确保抓取行为的合法性和道德性。
相关文章:

python爬虫 - 初识爬虫
🌈个人主页:https://blog.csdn.net/2401_86688088?typeblog 🔥 系列专栏:https://blog.csdn.net/2401_86688088/category_12797772.html 目录 前言 一、爬虫的关键概念 (一)HTTP请求与响应 ࿰…...

tomcat版本升级导致的umask问题
文章目录 1、问题背景2、问题分析3、深入研究4、umask4.1、umask的工作原理4.2、umask的计算方式4.3、示例4.4、如何设置umask4.5、注意事项 1、问题背景 我们的java服务是打成war包放在tomcat容器里运行的,有一天我像往常一样去查看服务的日志文件,却提…...

Golang | Leetcode Golang题解之第455题分发饼干
题目: 题解: func findContentChildren(g []int, s []int) (ans int) {sort.Ints(g)sort.Ints(s)m, n : len(g), len(s)for i, j : 0, 0; i < m && j < n; i {for j < n && g[i] > s[j] {j}if j < n {ansj}}return }...
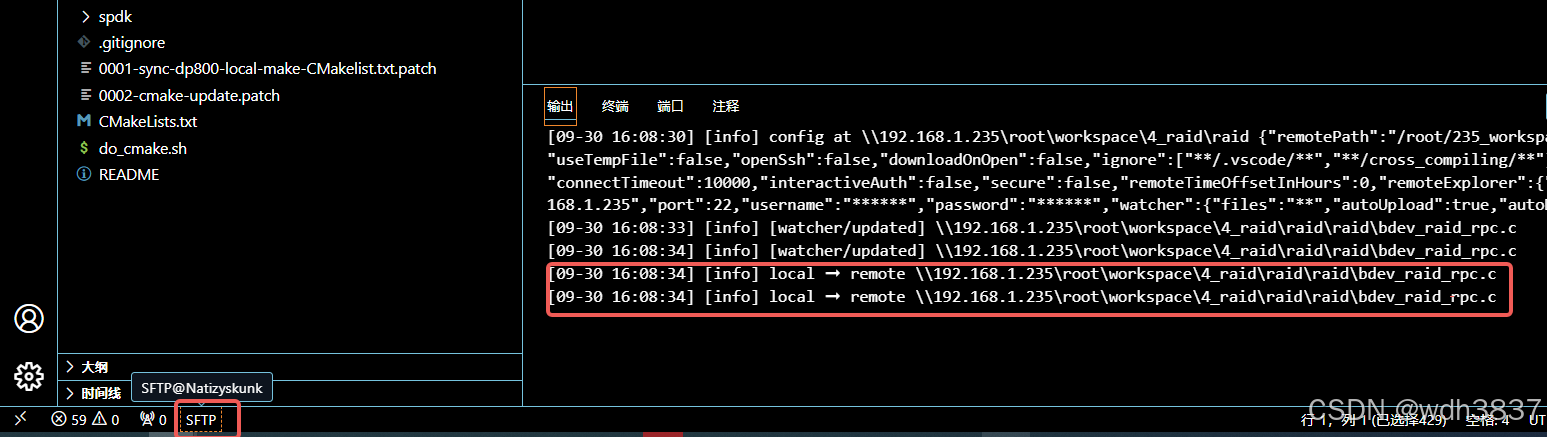
vscode+stfp插件,实现远程自动同步文件代码
概述 远程同步代码,将本地代码实时保存到同一局域网内的另一台电脑(linux系统),这里的本地代码也可以是远程服务上的代码,即从一个远程ip同步到另一台远程ip服务器。 工具 vscode,SFTP插件 安装 vscod…...

python 实现djb2哈希算法
djb2哈希算法介绍 DJB2哈希算法是一种简单且快速的哈希算法,由Daniel J. Bernstein设计。这种算法的实现非常简单,适用于短键值的哈希表,也常被用于嵌入式设备和资源受限的系统。 基本原理 DJB2算法的原理是将输入的字符串视为一个字节数组…...

文件夹作为普通文件而非子模块管理
relaxed_ik_ros2 文件夹下存在 .gitmodules 文件和 .gitignore 文件。这说明该目录已经被 Git 识别为子模块。 要将这个文件夹作为普通文件而非子模块管理,你可以按以下步骤操作: 1. 删除子模块配置 首先删除 .gitmodules 文件中的子模块配置。你可以…...

7c结构体
文章目录 一、结构体的设计二、结构体变量的初始化2.1结构体在内存表示;**2.2**结构体类型声明和 结构体变量的定义和初始化只声明结构体类型声明类型的同时定义变量p1用已有结构体类型定义结构体变量p2*定义变量的同时赋初值。*匿名声明结构体类型 2.3 结构体嵌套及…...

浅聊前后端分离开发和前后端不分离开发模式
1.先聊聊Web开发的开发框架Spring MVC 首先要知道,Spring MVC是Web开发领域的一个知名框架,可以开发基于请求-响应模式的Web应用。而Web开发的本质是遵循HTTP(Hyper Text Transfer Protocol: 超文本传输协议)协议【发请求…...
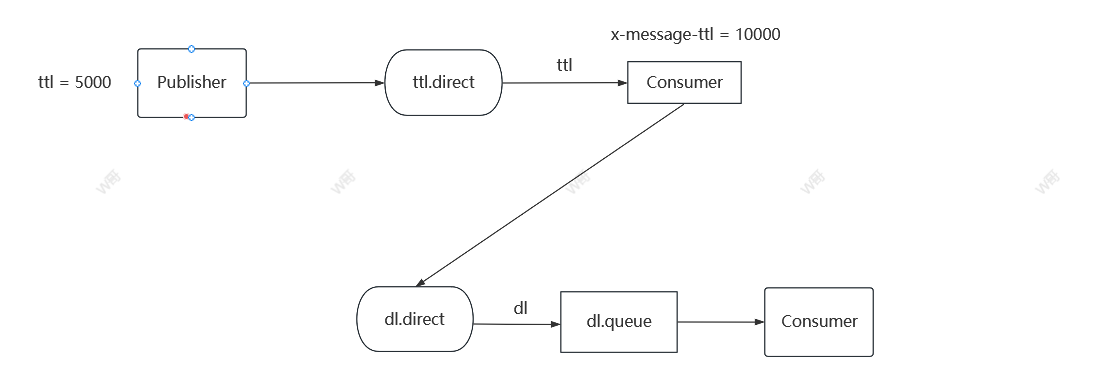
RabbitMQ篇(死信交换机)
目录 一、简介 二、TTL过期时间 三、应用场景 一、简介 当一个队列中的消息满足下列情况之一时,可以成为死信(dead letter) 消费者使用basic.reject或者basic.nack声明消费失败,并且消息的requeue参数设置为false消息是一个过…...

HBase 的 MemStore 详解
一、MemStore 概述 MemStore 是 HBase 的内存存储区域,它是一个负责缓存数据写入操作的组件。每当有写操作(如 Put 或 Delete)发生时,数据会首先被写入到 MemStore 中,而不是直接写入磁盘。MemStore 类似于数据库中的缓…...

【嵌入式软件-数据结构与算法】01-数据结构
摘录于老师的教学课程~~(*๓╰╯๓)~~内含链表、队列、栈、循环队列等详细介绍~~ 基础知识系列 有空再继续更~~~ 目录 【链表】 一、单链表 1、存储结构:带头结点的单链表 2、单链表结点类型的定义 3、创建单链表 1)头插法 2)尾插法 …...

Windows应用开发-解析AVI视频文件
本Windows应用解析AVI视频文件,以表格的方式显示AVI文件结构。并可以将结果保存到bmp图片。下面是,使用该应用解析一部AVI电影获得的图片。 应用开发信息 定义一个INFO结构,包含两个字符串对象,一个ULONGLONG变量,和…...

探索TCP协议的奥秘:Python中的网络通信
引言 在网络通信的世界里,TCP协议(传输控制协议)就如同一座桥梁,连接着数据的发送方和接收方。作为一名拥有20年实战经验的编码专家,我深知TCP协议在构建稳定、可靠的网络应用中的重要性。今天,我将带领大…...

每日学习一个数据结构-树
文章目录 树的相关概念一、树的定义二、树的基本术语三、树的分类四、特殊类型的树五、树的遍历六、树的应用场景 树的遍历一、前序遍历二、中序遍历三、后序遍历使用java代码实现遍历总结 树的相关概念 树是一种重要的非线性数据结构,在计算机科学中有着广泛的应用…...
)
简单PCL库读文件(linux vscode编译)
#include <pcl/io/pcd_io.h> #include <pcl/point_types.h> #include <pcl/common/common.h> #include <iostream>int main(int argc, char** argv) {if (argc ! 2) {std::cerr << "请指定 PCD 文件路径" << std::endl;return -…...

【自动驾驶】最近计划看的论文
将对应的论文链接贴出来,当作监督自己。 方向:端到端自动驾驶 方法论文代码UniADhttps://arxiv.org/pdf/2212.10156https://github.com/OpenDriveLab/UniADVADhttps://arxiv.org/pdf/2303.12077https://github.com/hustvl/VADUADhttps://arxiv.org/pdf…...

vue3学习:axios输入城市名称查询该城市天气
说来惭愧,接触前端也有很长一段时间了,最近才学习axios与后端的交互。今天学习了一个查询城市天气的案例,只需输入城市名称,点击“查询”按钮便可以进行查询。运行效果如下: 案例只实现了基本的查询功能,没…...

影刀RPA实战:Excel拆分与合并工作表
1.影刀操作excel的优势 Excel,大家都不陌生,它是微软公司推出的一款电子表格软件,它是 Microsoft Office 套件的一部分。Excel 以其强大的数据处理、分析和可视化功能而闻名,广泛应用于商业、教育、科研等领域。可以说࿰…...

STM32三种启动模式:【详细讲解】
STM32在上电后,从那里启动是由BOOT0和BOOT1引脚的电平决定的,如下表: BOOT模式选引脚启动模式BOOT0BOOT1X0主Flash启动01系统存储器启动11内置SRAM启动 BOOT 引脚的值在重置后 SYSCLK 的第四个上升沿时被锁定。在重置后,由用户决定是如何设…...

Ray_Tracing_The_Next_Week
1动态模糊 动态模糊在摄影中就是快门的速度慢,捕捉光的时间长,物体运动时进行捕捉成像,拍出来的结果是这个运动过程每一帧的平均值 我们的思路是: 每一条光线都拥有自己存在的一个时间点。随着时间变化随机生成光线,一般来说我…...

比特币钱包密码恢复神器:如何用btcrecover找回遗忘的数字资产密码
比特币钱包密码恢复神器:如何用btcrecover找回遗忘的数字资产密码 【免费下载链接】btcrecover An open source Bitcoin wallet password and seed recovery tool designed for the case where you already know most of your password/seed, but need assistance i…...

CANN/asc-devkit bfloat16精度转换函数
__float22bfloat162_rd 【免费下载链接】asc-devkit 本项目是CANN 推出的昇腾AI处理器专用的算子程序开发语言,原生支持C和C标准规范,主要由类库和语言扩展层构成,提供多层级API,满足多维场景算子开发诉求。 项目地址: https://…...

告别复杂命令:3步搞定M3U8视频下载的终极指南
告别复杂命令:3步搞定M3U8视频下载的终极指南 【免费下载链接】N_m3u8DL-CLI-SimpleG N_m3u8DL-CLIs simple GUI 项目地址: https://gitcode.com/gh_mirrors/nm3/N_m3u8DL-CLI-SimpleG 你是否曾经遇到过这样的困扰?在网上找到了心仪的视频教程或精…...

Triton Ascend 代码生成 Skill
【免费下载链接】cannbot-skills CANNBot 是面向 CANN 开发的用于提升开发效率的系列智能体,本仓库为其提供可复用的 Skills 模块。 项目地址: https://gitcode.com/cann/cannbot-skills name: triton-op-coding description: > Triton Ascend 算子代码生…...

别再死记硬背公式了!用Python实战SCS模型,5分钟搞定城市降雨径流估算
用Python实战SCS模型:5分钟自动化城市降雨径流分析 水文工程师们是否厌倦了手动查表计算CN值?环境分析师是否还在为重复的径流公式推导头疼?今天我们将用Python彻底改变传统工作流——无需记忆复杂公式,只需5行核心代码即可完成从…...

终极指南:3分钟解决微信网页版无法访问的难题
终极指南:3分钟解决微信网页版无法访问的难题 【免费下载链接】wechat-need-web 让微信网页版可用 / Allow the use of WeChat via webpage access 项目地址: https://gitcode.com/gh_mirrors/we/wechat-need-web 还在为微信网页版无法访问而烦恼吗ÿ…...

别再死磕论文了!用PyTorch复现StyleGAN,从代码层面理解风格混合与解耦
从零构建StyleGAN:用PyTorch代码揭示风格混合的奥秘 当你在浏览社交媒体时,是否曾被那些由AI生成的逼真虚拟人脸所震撼?这些图像背后往往隐藏着一个强大的生成对抗网络——StyleGAN。与传统的GAN不同,StyleGAN能够精确控制生成图像…...

Option ‘importsNotUsedAsValues‘ has been removed. Please remove it from your configuration
1、背景 在前端项目中的tsconfig.json中 compilerOptions 报红,鼠标放上去,会显示如下内容: Option importsNotUsedAsValues has been removed. Please remove it from your configuration. Use verbatimModuleSyntax instead.ts Option p…...

从SE到Dual-Attention:手把手教你为YOLOv8或ResNet模型‘加装’注意力模块提升指标
从SE到Dual-Attention:手把手教你为YOLOv8或ResNet模型‘加装’注意力模块提升指标 在计算机视觉领域,注意力机制已成为提升模型性能的"秘密武器"。不同于完全重构网络架构,注意力模块的魅力在于其即插即用的特性——就像为汽车加装…...

基于Sakura实验板的STM32流水灯项目实战:从GPIO控制到模式切换
1. 项目概述:从零到一,点亮你的第一串“流水”如果你刚拿到一块单片机开发板,面对一堆引脚和代码感到无从下手,那么“流水灯”几乎就是所有嵌入式开发者的“Hello World”。它简单、直观,却能让你快速理解GPIO…...