深度学习Day-35:One-hot独热编码
🍨 本文为:[🔗365天深度学习训练营] 中的学习记录博客
🍖 原作者:[K同学啊 | 接辅导、项目定制]
一、 独热编码原理
独热编码(One-Hot Encoding)是一种将分类数据转换为二进制向量的方法,其中每个类别对应一个唯一的二进制向量。在独热编码中,每个类别都由一个长度为n的向量表示,其中n是所有可能类别的数量。向量中的每个位置对应一个可能的类别,该位置上的值是1或0,表示该实例是否属于该类别。
例如,假设我们有四个类别:A、B、C和D。使用独热编码,我们可以将它们表示为:
- A: [1, 0, 0, 0]
- B: [0, 1, 0, 0]
- C: [0, 0, 1, 0]
- D: [0, 0, 0, 1]
独热编码的优点包括:
处理分类数据:独热编码允许分类数据被模型处理,因为许多机器学习算法和神经网络都要求输入是数字。
无序性:独热编码假设类别之间没有顺序关系,每个类别都是相互独立的。
稀疏性:独热编码产生的向量通常是稀疏的,这意味着大多数位置的值都是0,只有少数几个位置的值是1。这种稀疏性在某些情况下可以减少模型复杂性。
兼容性:独热编码可以与多种机器学习算法兼容,包括逻辑回归、支持向量机、决策树、随机森林、神经网络等。
在Python中,可以使用多种库来实现独热编码,例如pandas的get_dummies函数或scikit-learn的OneHotEncoder类。
这样的表示方式有助于模型更好地理解文本含义。在深度学习中,神经网络的输入层通常使用one-hot编码来表示分类变量。这种编码方式不仅能够避免不必要的关系假设,还能够提供清晰的输入表示,有助于模型的学习和泛化。
例如:
John likes to watch movies. Mary likes too
John also likes to watch football games.
以上两句可以构造一个词典:
{"John": 1, "likes": 2, "to": 3, "watch": 4, "movies": 5, "also": 6, "football": 7, "games": 8, "Mary": 9, "too": 10}
One-hot可表示为:
John: [1, 0, 0, 0, 0, 0, 0, 0, 0, 0]
likes: [0, 1, 0, 0, 0, 0, 0, 0, 0, 0]其余类推。
二、 案例
2.1 英文案例
import torch
import torch.nn.functional as F# 示例文本
texts = ['Hello, how are you?', 'I am doing well, thank you!', 'Goodbye.']# 构建词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set(" ".join(texts).split())):word_index[word] = iindex_word[i] = word# 将文本转化为整数序列
sequences = [[word_index[word] for word in text.split()] for text in texts]# 获取词汇表大小
vocab_size = len(word_index)# 将整数序列转化为one-hot编码
one_hot_results = torch.zeros(len(texts), vocab_size)
for i, seq in enumerate(sequences):one_hot_results[i, seq] = 1# 打印结果
print("词汇表:")
print(word_index)
print("\n文本:")
print(texts)
print("\n文本序列:")
print(sequences)
print("\nOne-Hot编码:")
print(one_hot_results)
输出结果为:
词汇表:
{'doing': 0, 'well,': 1, 'I': 2, 'how': 3, 'thank': 4, 'you!': 5, 'am': 6, 'Hello,': 7, 'are': 8, 'you?': 9, 'Goodbye.': 10}文本:
['Hello, how are you?', 'I am doing well, thank you!', 'Goodbye.']文本序列:
[[7, 3, 8, 9], [2, 6, 0, 1, 4, 5], [10]]One-Hot编码:
tensor([[0., 0., 0., 1., 0., 0., 0., 1., 1., 1., 0.],[1., 1., 1., 0., 1., 1., 1., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])Process finished with exit code 0
2.2 中文案例
import torch
import torch.nn.functional as F# 示例中文文本
texts = ['你好,最近怎么样?', '我过得很好,谢谢!', 'K同学啊']# 构建词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set("".join(texts))):word_index[word] = iindex_word[i] = word# 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in texts]# 获取词汇表大小
vocab_size = len(word_index)# 将整数序列转化为one-hot编码
one_hot_results = torch.zeros(len(texts), vocab_size)
for i, seq in enumerate(sequences):one_hot_results[i, seq] = 1# 打印结果
print("词汇表:")
print(word_index)
print("\n文本:")
print(texts)
print("\n文本序列:")
print(sequences)
print("\nOne-Hot编码:")
print(one_hot_results)
输出结果为:
词汇表:
{'!': 0, '谢': 1, '你': 2, '怎': 3, '好': 4, '学': 5, '近': 6, '么': 7, '同': 8, '最': 9, '样': 10, '很': 11, '我': 12, ',': 13, '得': 14, '过': 15, 'K': 16, '啊': 17, '?': 18}文本:
['你好,最近怎么样?', '我过得很好,谢谢!', 'K同学啊']文本序列:
[[2, 4, 13, 9, 6, 3, 7, 10, 18], [12, 15, 14, 11, 4, 13, 1, 1, 0], [16, 8, 5, 17]]One-Hot编码:
tensor([[0., 0., 1., 1., 1., 0., 1., 1., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0.,1.],[1., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 1., 1., 1., 1., 0., 0.,0.],[0., 0., 0., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 1.,0.]])Process finished with exit code 0
可以注意到上面的案例是以字为基本单位的,但词语被拆分开后,显然会失去原有的意思。在下面的案例中,我们使用jieba分词工具对句子进行划分。
使用结巴分词(jieba)进行中文文本的分词处理,然后将分词后的结果转化为one-hot编码。首先,确保你已经安装了结巴分词库。
pip install jieba接着,运行下述代码:
import torch
import torch.nn.functional as F
import jieba# 示例中文文本
texts = ['你好,最近怎么样?', '我过得很好,谢谢!', '再见。']# 使用结巴分词进行分词
tokenized_texts = [list(jieba.cut(text)) for text in texts]# 构建词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set([word for text in tokenized_texts for word in text])):word_index[word] = iindex_word[i] = word# 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in tokenized_texts]# 获取词汇表大小
vocab_size = len(word_index)# 将整数序列转化为one-hot编码
one_hot_results = torch.zeros(len(texts), vocab_size)
for i, seq in enumerate(sequences):one_hot_results[i, seq] = 1# 打印结果
print("词汇表:")
print(word_index)
print("\n文本:")
print(texts)
print("\n分词结果")
print(tokenized_texts)
print("\n文本序列:")
print(sequences)
print("\nOne-Hot编码:")
print(one_hot_results)
输出结果为:
词汇表:
{',': 0, '再见': 1, '?': 2, '!': 3, '得': 4, '你好': 5, '。': 6, '很': 7, '最近': 8, '谢谢': 9, '我过': 10, '怎么样': 11, '好': 12}文本:
['你好,最近怎么样?', '我过得很好,谢谢!', '再见。']分词结果
[['你好', ',', '最近', '怎么样', '?'], ['我过', '得', '很', '好', ',', '谢谢', '!'], ['再见', '。']]文本序列:
[[5, 0, 8, 11, 2], [10, 4, 7, 12, 0, 9, 3], [1, 6]]One-Hot编码:
tensor([[1., 0., 1., 0., 0., 1., 0., 0., 1., 0., 0., 1., 0.],[1., 0., 0., 1., 1., 0., 0., 1., 0., 1., 1., 0., 1.],[0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.]])Process finished with exit code 0
在ACGAN中,判别器的整体结构包括两部分:一个是用于判断样本真伪的主分类器,另一个是用于预测条件类别的辅助分类器。以下是判别器的整体结构:
共享的特征提取层:判别器的主分类器和辅助分类器通常共享相同的特征提取层。这意味着它们使用相同的网络层来提取输入样本的特征。
主分类器分支:特征提取层的输出被送入主分类器分支,这个分支通常是一个或几个全连接层,用于预测样本是真(来自真实数据分布)还是假(来自生成器)。
辅助分类器分支:同时,特征提取层的输出也被送入辅助分类器分支,用于预测样本的条件类别。
损失函数和优化:判别器的总损失是主分类器损失和辅助分类器损失的加权组合。在训练过程中,优化器会同时最小化这两个损失,以更新判别器的权重。
通过这种方式,ACGAN的判别器不仅能够区分真实和生成的样本,还能够准确预测样本的类别,从而为生成器提供了更具体的指导,使其能够生成具有特定条件属性的数据。
三、任务
运行代码:
import torch
import jieba#打开txt文件的方式
texts = open('任务.txt', 'r',encoding='utf-8').read().split('\n')
print(texts)# 使用结巴分词进行分词
tokenized_texts = [list(jieba.cut(text)) for text in texts]# 构建词汇表
word_index = {}
index_word = {}
for i, word in enumerate(set([word for text in tokenized_texts for word in text])):word_index[word] = iindex_word[i] = word# 将文本转化为整数序列
sequences = [[word_index[word] for word in text] for text in tokenized_texts]# 获取词汇表大小
vocab_size = len(word_index)# 将整数序列转化为one-hot编码
one_hot_results = torch.zeros(len(texts), vocab_size)
for i, seq in enumerate(sequences):one_hot_results[i, seq] = 1# 打印结果
print("词汇表:")
print(word_index)
print("\n文本:")
print(texts)
print("\n分词结果")
print(tokenized_texts)
print("\n文本序列:")
print(sequences)
print("\nOne-Hot编码:")
print(one_hot_results)
输出结果:
['比较直观的编码方式是采用上面提到的字典序列。', '例如,对于一个有三个类别的问题,可以用1、2和3分别表示这三个类别。', '但是,这种编码方式存在一个问题,就是模型可能会错误地认为不同类别之间存在一些顺序或距离关系', '而实际上这些关系可能是不存在的或者不具有实际意义的,为了避免这种问题,引入了one-hot编码(也称独热编码)。', 'one-hot编码的基本思想是将每个类别映射到一个向量,其中只有一个元素的值为1,其余元素的值为0。', '这样,每个类别之间就是相互独立的,不存在顺序或距离关系。', '例如,对于三个类别的情况,可以使用如下的one-hot编码:', '这是K同学啊的“365天深度学习训练营”教案内容']
词汇表:
{'提到': 0, '是': 1, '而': 2, '顺序': 3, '称': 4, '训练营': 5, '字典': 6, '内容': 7, '不同': 8, '问题': 9, '编码': 10, '每个': 11, '独热': 12, 'K': 13, '这是': 14, '例如': 15, '映射': 16, '3': 17, '情况': 18, '教案': 19, '表示': 20, '基本': 21, '向量': 22, '对于': 23, '可以': 24, '存在': 25, '将': 26, ',': 27, '了': 28, '到': 29, '元素': 30, '地': 31, '采用': 32, '值': 33, '为了': 34, '啊': 35, '或': 36, '或者': 37, '“': 38, '认为': 39, '避免': 40, '这些': 41, '编码方式': 42, '为': 43, '一个': 44, '分别': 45, '。': 46, '就是': 47, '一些': 48, '之间': 49, '不': 50, '具有': 51, '使用': 52, '深度': 53, '学习': 54, '和': 55, '比较': 56, 'hot': 57, '模型': 58, '实际上': 59, '1': 60, '可能': 61, '错误': 62, '其余': 63, ':': 64, '(': 65, '距离': 66, '会': 67, '-': 68, '这样': 69, '相互': 70, '关系': 71, '直观': 72, '思想': 73, '序列': 74, '如下': 75, '其中': 76, '实际意义': 77, '”': 78, '独立': 79, '有': 80, '365': 81, '天': 82, '三个': 83, '也': 84, '用': 85, '这': 86, '但是': 87, '引入': 88, 'one': 89, '这种': 90, '的': 91, '0': 92, '、': 93, '2': 94, '上面': 95, '只有': 96, '同学': 97, ')': 98, '类别': 99}文本:
['比较直观的编码方式是采用上面提到的字典序列。', '例如,对于一个有三个类别的问题,可以用1、2和3分别表示这三个类别。', '但是,这种编码方式存在一个问题,就是模型可能会错误地认为不同类别之间存在一些顺序或距离关系', '而实际上这些关系可能是不存在的或者不具有实际意义的,为了避免这种问题,引入了one-hot编码(也称独热编码)。', 'one-hot编码的基本思想是将每个类别映射到一个向量,其中只有一个元素的值为1,其余元素的值为0。', '这样,每个类别之间就是相互独立的,不存在顺序或距离关系。', '例如,对于三个类别的情况,可以使用如下的one-hot编码:', '这是K同学啊的“365天深度学习训练营”教案内容']分词结果
[['比较', '直观', '的', '编码方式', '是', '采用', '上面', '提到', '的', '字典', '序列', '。'], ['例如', ',', '对于', '一个', '有', '三个', '类别', '的', '问题', ',', '可以', '用', '1', '、', '2', '和', '3', '分别', '表示', '这', '三个', '类别', '。'], ['但是', ',', '这种', '编码方式', '存在', '一个', '问题', ',', '就是', '模型', '可能', '会', '错误', '地', '认为', '不同', '类别', '之间', '存在', '一些', '顺序', '或', '距离', '关系'], ['而', '实际上', '这些', '关系', '可能', '是', '不', '存在', '的', '或者', '不', '具有', '实际意义', '的', ',', '为了', '避免', '这种', '问题', ',', '引入', '了', 'one', '-', 'hot', '编码', '(', '也', '称', '独热', '编码', ')', '。'], ['one', '-', 'hot', '编码', '的', '基本', '思想', '是', '将', '每个', '类别', '映射', '到', '一个', '向量', ',', '其中', '只有', '一个', '元素', '的', '值', '为', '1', ',', '其余', '元素', '的', '值', '为', '0', '。'], ['这样', ',', '每个', '类别', '之间', '就是', '相互', '独立', '的', ',', '不', '存在', '顺序', '或', '距离', '关系', '。'], ['例如', ',', '对于', '三个', '类别', '的', '情况', ',', '可以', '使用', '如下', '的', 'one', '-', 'hot', '编码', ':'], ['这是', 'K', '同学', '啊', '的', '“', '365', '天', '深度', '学习', '训练营', '”', '教案', '内容']]文本序列:
[[56, 72, 91, 42, 1, 32, 95, 0, 91, 6, 74, 46], [15, 27, 23, 44, 80, 83, 99, 91, 9, 27, 24, 85, 60, 93, 94, 55, 17, 45, 20, 86, 83, 99, 46], [87, 27, 90, 42, 25, 44, 9, 27, 47, 58, 61, 67, 62, 31, 39, 8, 99, 49, 25, 48, 3, 36, 66, 71], [2, 59, 41, 71, 61, 1, 50, 25, 91, 37, 50, 51, 77, 91, 27, 34, 40, 90, 9, 27, 88, 28, 89, 68, 57, 10, 65, 84, 4, 12, 10, 98, 46], [89, 68, 57, 10, 91, 21, 73, 1, 26, 11, 99, 16, 29, 44, 22, 27, 76, 96, 44, 30, 91, 33, 43, 60, 27, 63, 30, 91, 33, 43, 92, 46], [69, 27, 11, 99, 49, 47, 70, 79, 91, 27, 50, 25, 3, 36, 66, 71, 46], [15, 27, 23, 83, 99, 91, 18, 27, 24, 52, 75, 91, 89, 68, 57, 10, 64], [14, 13, 97, 35, 91, 38, 81, 82, 53, 54, 5, 78, 19, 7]]One-Hot编码:
tensor([[1., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0.,0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 1., 0., 0., 0., 1., 0., 0., 0., 0.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1., 0., 1.,0., 0., 1., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 1., 0., 0., 0., 0., 0., 0., 0.,0., 1., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 1., 0., 1., 1., 0., 0., 0.,0., 1., 0., 1., 1., 0., 0., 0., 0., 1.],[0., 0., 0., 1., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 1., 0., 0., 0., 0.,1., 0., 0., 1., 0., 0., 1., 0., 1., 0., 0., 1., 1., 1., 0., 0., 0., 0.,0., 0., 0., 0., 1., 0., 0., 1., 1., 0., 0., 0., 1., 1., 0., 0., 0., 1.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0.,1., 0., 0., 0., 0., 0., 0., 0., 0., 1.],[0., 1., 1., 0., 1., 0., 0., 0., 0., 1., 1., 0., 1., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 1., 0., 0., 0., 0., 0., 1., 0.,0., 1., 0., 0., 1., 1., 0., 0., 0., 0., 1., 0., 0., 0., 1., 1., 0., 0.,0., 0., 0., 1., 0., 1., 0., 1., 0., 0., 0., 1., 0., 0., 1., 0., 0., 1.,0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 1.,1., 1., 0., 0., 0., 0., 0., 0., 1., 0.],[0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0., 0., 1., 0.,0., 0., 0., 1., 1., 0., 0., 0., 1., 1., 0., 1., 1., 0., 0., 1., 0., 0.,0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 1., 0., 0., 1., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0., 0.,0., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,0., 1., 1., 0., 0., 0., 1., 0., 0., 1.],[0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 1., 0., 1., 1., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 1., 1., 1.,0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 1., 0., 0., 0., 0., 0., 0., 0., 1.],[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 1., 0., 0.,1., 0., 0., 0., 0., 1., 1., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0.,0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 1., 0., 0., 0.,0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 1.,0., 1., 0., 0., 0., 0., 0., 0., 0., 1.],[0., 0., 0., 0., 0., 1., 0., 1., 0., 0., 0., 0., 0., 1., 1., 0., 0., 0.,0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,0., 0., 1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1.,1., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.,0., 0., 0., 0., 0., 0., 1., 0., 0., 1., 1., 0., 0., 0., 0., 0., 0., 0.,0., 1., 0., 0., 0., 0., 0., 1., 0., 0.]])Process finished with exit code 0
四、总结
本周任务较为简单,不做多余总结
相关文章:

深度学习Day-35:One-hot独热编码
🍨 本文为:[🔗365天深度学习训练营] 中的学习记录博客 🍖 原作者:[K同学啊 | 接辅导、项目定制] 一、 独热编码原理 独热编码(One-Hot Encoding)是一种将分类数据转换为二进制向量的方法&#…...

Streamlit 实现登录注册验证
在开发基于 Streamlit 的应用时,用户认证功能是一个常见需求。本文将介绍如何通过两种方式来实现登录注册功能:手动实现 和 使用 Streamlit-Authenticator 库。手动实现虽然灵活,但需要自行处理密码加密、验证等细节;而 Streamlit…...

ASP.NET Zero 多租户介绍
ASP.NET Zero 是一个基于 ASP.NET Core 的应用程序框架,它提供了多租户支持,以下是关于 ASP.NET Zero 多租户的介绍: 一、多租户概念 多租户是一种软件架构模式,允许多个客户(租户)共享同一套软件应用程序…...

【60天备战2024年11月软考高级系统架构设计师——第29天:微服务架构——微服务的优缺点】
微服务架构通过将大型单体应用拆分为多个独立的小型服务,使系统具备灵活性、可扩展性和独立部署的优势。但与此相伴的是复杂的运维和开发管理挑战。因此,在选择微服务架构时,架构师需仔细权衡其优势与劣势。 微服务架构的优点 独立部署&…...

读论文、学习时 零碎知识点记录01
1.入侵检测技术 2.深度学习、机器学习相关的概念 ❶注意力机制 ❷池化 ❸全连接层 ❹Dropout层 ❺全局平均池化 3.神经网络中常见的层...

图解C#高级教程(一):委托
什么是委托 可以认为委托是持有一个或多个方法的对象。但它与对象不同,因为委托可以被执行。当执行委托时,委托会执行它所“持有”的方法。先看一个完整的使用示例。 // See https://aka.ms/new-console-template for more informationdelegate void M…...

CMSIS-RTOS V2封装层专题视频,一期视频将常用配置和用法梳理清楚,适用于RTX5和FreeRTOS(2024-09-28)
【前言】 本期视频就一个任务,通过ARM官方的CMSIS RTOS文档,将常用配置和用法给大家梳理清楚。 对于初次使用CMSIS-RTOS的用户来说,通过梳理官方文档,可以系统的了解各种用法,方便大家再进一步的自学或者应用&#x…...

渗透测试入门学习——使用python脚本自动识别图片验证码,OCR技术初体验
写在前面 由于验证码在服务端生成后存储在服务器的session中,而标用于标识用户身份的sessionid存在于用户cookie中 所以本次识别验证码时需要用requests.session()创建会话对象,模拟真实的浏览器行为,保持与服务器的会话才能获取登录时服务…...

docker环境下配置cerbot获取免费ssl证书并自动续期
文章目录 实践场景了解certbot查看nginx的映射情况操作目标配置nginx配置的ssl证书设置自动续签 实践场景 本人使用docker部署了一个nginx容器,通过容器卷,实现本地html,ssl,conf和ngiinx容器映射的, 经常需要手动部署…...

Studying-多线程学习Part1-线程库的基本使用、线程函数中的数据未定义错误、互斥量解决多线程数据共享问题
来源:多线程编程 线程库的基本使用 两个概念: 进程是运行中的程序线程是进程中的进程 串行运行:一次只能取得一个任务并执行这一个任务 并行运行:可以同时通过多进程/多线程的方式取得多个任务,并以多进程或多线程…...
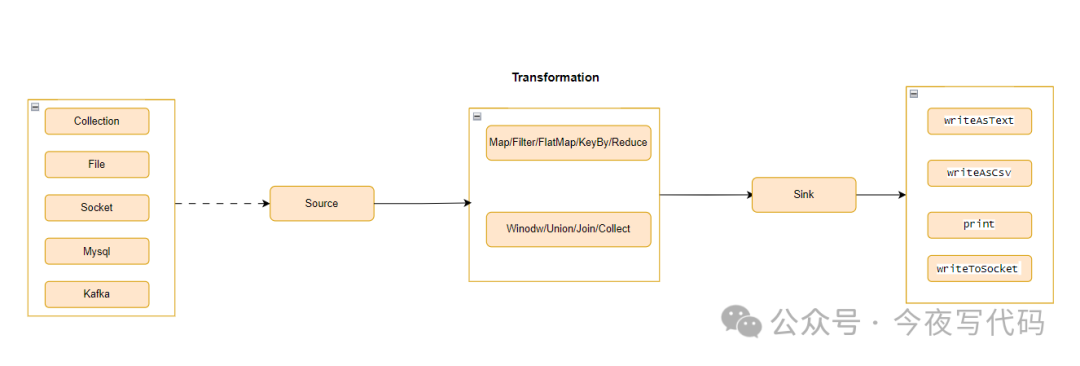
Flink 03 | 数据流基本操作
Flink数据流结构 DataStream 转换 通常我们需要分析的业务数据可能存在如下问题: 数据中包含一些我们不需要的数据 数据格式不方面分析 因此我们需要对原始数据流进行加工,比如过滤、转换等操作才可以进行数据分析。 “ Flink DataStream 转换主要作…...

在 TS 的 class 中,如何防止外部实例化
在 TypeScript(TS)中,如果你想要防止一个类被外部实例化,你可以采取以下几种策略: 将构造函数设为私有(Private Constructor): 通过将类的构造函数设为私有,你可以阻止外…...

HTML详解
HTML 基础HTML 标题HTML 段落HTML 链接HTML 图片HTML 元素HTML 注释HTML 属性HTML 文本格式化HTML 头部HTML cssHTML 表格HTML 列表HTML 自定义列表HTML 区块HTML 表单HTML 框架HTML 颜色HTML 脚本HTML 事件HTML 实体HTML urlHTML5 新元素 新元素 新元素 新元素 新元素 新元素 …...

记录|Modbus-TCP产品使用记录【德克威尔】
目录 前言一、德克威尔1.1 实验图1.2 DECOWELL IO Tester 软件1.3 读写设置1.4 C#进行Modbus-TCP读写 更新时间 前言 参考文章: 使用的第二款Modbus-TCP产品。 一、德克威尔 1.1 实验图 1.2 DECOWELL IO Tester 软件 这也是自带模块配置软件的。下图就是德克威尔的…...

基于深度学习的视频生成
基于深度学习的视频生成是一项极具前景的技术,旨在通过神经网络模型生成逼真的动态视频内容。随着生成对抗网络(GANs)、自回归模型、变分自编码器(VAEs)等深度学习模型的发展,视频生成技术已经取得了显著进…...

TB6612电机驱动模块(STM32)
目录 一、介绍 二、模块原理 1.原理图 2.电机驱动原理 三、程序设计 main.c文件 Motor.h文件 Motor.c文件 四、实验效果 五、资料获取 项目分享 一、介绍 TB6612FNG 是东芝半导体公司生产的一款直流电机驱动器件,它具有大电流 MOSFET-H 桥结构ÿ…...

webpack信息泄露
先看看webpack中文网给出的解释 webpack 是一个模块打包器。它的主要目标是将 JavaScript 文件打包在一起,打包后的文件用于在浏览器中使用,但它也能够胜任转换、打包或包裹任何资源。 如果未正确配置,会生成一个.map文件,它包含了原始JavaScript代码的映…...

启动服务并登录MySQL9数据库
【图书推荐】《MySQL 9从入门到性能优化(视频教学版)》-CSDN博客 《MySQL 9从入门到性能优化(视频教学版)(数据库技术丛书)》(王英英)【摘要 书评 试读】- 京东图书 (jd.com) Windows平台下安装与配置MyS…...

微服务_3.微服务保护
文章目录 一、微服务雪崩及解决方法1.1、超时处理1.2、仓壁模式1.3、断路器1.4、限流 二、Sentinel2.1、流量控制2.1.1、普通限流2.1.2、热点参数限流 2.2、线程隔离2.3、熔断降级2.3.1、断路器状态机2.3.2、断路器熔断策略2.3.2.1、慢调用2.3.2.2、异常比例,异常数…...

【设计模式】软件设计原则——依赖倒置合成复用
依赖倒置引出 依赖倒置 定义:高层模块不应该依赖低层模块,二者都应该依赖抽象;抽象不应该依赖细节,细节应该依赖抽象。面向接口编程而不是面向实现编程。 通过抽象使用抽象类、接口让各个类or模块之间独立不影响,实现…...

汽车跑偏吃胎?警惕四轮定位
开车上路,你是否遇到过这些情况:明明双手握紧方向盘,车子却总是不自觉地往一边跑;在高速上行驶,方向盘开始轻微抖动;轮胎用了没几年,一侧就磨得光秃秃,而另一侧花纹却很深……很多老…...
)
保姆级教程:用S32K344的FlexCAN模块实现CAN FD通信(附代码解析)
从零构建S32K344的CAN FD通信系统:硬件连接、寄存器配置与实战代码解析 在汽车电子和工业控制领域,CAN FD协议正逐步取代传统CAN成为主流总线标准。NXP S32K344微控制器内置的FlexCAN模块完美支持CAN FD协议,其最高8Mbps的数据传输速率和64字…...

时间序列预测损失函数全解析:从MSE到分位数损失的选择指南
1. 项目概述:为什么时间序列预测的损失函数值得深究?做时间序列预测,无论是金融市场的股价波动、电商平台的销量起伏,还是工业设备的传感器读数,我们最终都要面对一个核心问题:如何衡量模型预测得好不好&am…...

如何为 OpenClaw 配置 Taotoken 以实现高效的 Agent 工作流
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 如何为 OpenClaw 配置 Taotoken 以实现高效的 Agent 工作流 基础教程类,面向使用 OpenClaw 框架构建 AI Agent 的开发者…...

一文读懂:文档解析、RAG、知识库及文档Agent
AI会取代人类工作吗?斯坦福大学教授、AI领域顶尖学者吴恩达近日明确表示:不会有AI就业末日。在他看来,AI会影响岗位、改变技能要求、替代部分任务,但将其描绘成大规模失业灾难,“是在制造不必要的恐惧,也是…...

为Claude Code配置Taotoken备用通道防止服务中断
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为Claude Code配置Taotoken备用通道防止服务中断 对于依赖Claude Code进行日常编程辅助的开发者而言,服务稳定性直接影…...

Ubuntu20.04下Mapviz插件生态与多源数据融合实战
1. Mapviz简介与核心价值 Mapviz是ROS生态中一款专注于2D数据可视化的神器,它的独特之处在于模块化插件架构。不同于Rviz主要处理3D数据,Mapviz更擅长处理地理空间信息的可视化,比如我在做农业机器人项目时,需要同时监控GPS轨迹、…...
)
Perplexity数据验证功能全链路解析(98.7%准确率背后的4层校验架构)
更多请点击: https://kaifayun.com 第一章:Perplexity数据验证功能全链路解析(98.7%准确率背后的4层校验架构) Perplexity 的数据验证并非单一规则匹配,而是融合语义一致性、来源可信度、时效性约束与逻辑闭环性的四维…...

RTSP拉流播放器开发实战:用FFmpeg和SDL2解析H264 RTP流
RTSP拉流播放器开发实战:用FFmpeg和SDL2解析H264 RTP流 在实时视频监控、在线直播等场景中,RTSP协议因其低延迟和可靠性成为主流选择。本文将深入探讨如何从零构建一个RTSP客户端播放器,重点解决H264 RTP流的接收、解析与渲染难题。不同于简单…...

GIFT高级技巧:图像组合、并行处理和性能优化的终极指南
GIFT高级技巧:图像组合、并行处理和性能优化的终极指南 【免费下载链接】gift Go Image Filtering Toolkit 项目地址: https://gitcode.com/gh_mirrors/gi/gift GIFT(Go Image Filtering Toolkit)是一个强大的Go语言图像处理库&#x…...