强化学习笔记之【Q-learning算法和DQN算法】
强化学习笔记(一)——Q-learning和DQN算法核心公式
文章目录
- 强化学习笔记(一)——Q-learning和DQN算法核心公式
- 前言:
- Q-learning算法
- DQN算法
前言:
强化学习领域,繁冗复杂的大段代码里面,核心的数学公式往往只有20~40行,剩下的代码都是为了应用这些数学公式而服务的
这可比遥感图像难太多了,乱七八糟的数学公式看得头大

本文初编辑于2024.10.5
CSDN主页:https://blog.csdn.net/rvdgdsva
博客园主页:https://www.cnblogs.com/hassle
博客园本文链接:
Q-learning算法
需要先看:
Deep Reinforcement Learning (DRL) 算法在 PyTorch 中的实现与应用【Q-learning部分】
7个最流行的强化学习算法实战案例(附 Python 代码)【Q-learning部分】【不要看这个的DQN部分,里面用的是单网络】
q [ c u r r e n t ‾ s t a t e , a c t i o n ] = q [ c u r r e n t ‾ s t a t e , a c t i o n ] + l e a r n i n g ‾ r a t e × ( r e w a r d + g a m m a × m a x ( q [ n e x t ‾ s t a t e ] ) − q [ c u r r e n t ‾ s t a t e , a c t i o n ] ) q[current\underline{~}state, action] = \\q[current\underline{~}state, action] + learning\underline{~}rate \times (reward + gamma\times max(q[next\underline{~}state]) - q[current\underline{~}state, action]) q[current state,action]=q[current state,action]+learning rate×(reward+gamma×max(q[next state])−q[current state,action])
- 上述公式为Q-learning算法中的Q值更新公式
- Q-learning算法中的Q值更新公式参数解释:
-
Q[CurrentState, Action]: 这是在当前状态(CurrentState)下,采取特定动作(Action)所对应的Q值。Q值代表了在给定状态下采取该动作的预期累积回报。
-
LearningRate (α): 学习率是一个介于0和1之间的参数,用来控制新信息(即当前的经验和估计的未来回报)对Q值更新的影响。较高的学习率会使得新经验更快速地影响Q值,而较低的学习率则会使得Q值更新更加平滑,减小波动。
-
reward: 这是在执行动作(Action)后获得的即时奖励。它用于衡量该动作的好坏,与环境的反馈直接相关。
-
gamma (γ): 折扣因子是一个介于0和1之间的参数,用于确定未来奖励的重要性。γ越接近1,智能体越重视未来的奖励;γ越接近0,智能体则更关注眼前的即时奖励。
-
max(Q[NextState]): 这是在下一个状态(NextState)中所有可能动作的Q值中的最大值。它表示在下一个状态下预计能获得的最大未来回报。
A c t i o n = a r g m a x ( Q [ C u r r e n t S t a t e ] ) Action = argmax(Q[CurrentState]) Action=argmax(Q[CurrentState])
- 通过上述公式进行Action的选择
个人理解:Q-learning是off-policy算法。reward是现在的行为可见的确定的收益,**gamma*max(Q[NextState])**是预计的未来的总收益(不包括现在,即reward),**Q[CurrentState, Action]**是预计的现在的总收益(包括现在,即reward),此点参考【强化学习】 时序差分TD error的通俗理解,方程的右侧表示Q值的更新。它使用了目前的Q值,加上基于当前获得的奖励和预计的未来奖励的调整。这个调整部分是基于时序差分(即 TD-errors)学习的原则。
DQN算法
需要先看:
Deep Reinforcement Learning (DRL) 算法在 PyTorch 中的实现与应用【DQN部分】【代码中有take_action函数】
【深度强化学习】(1) DQN 模型解析,附Pytorch完整代码【代码实现部分】【代码中DQN网络缺少take_action函数,结合上文看吧】
q ‾ v a l u e s = q ‾ n e t w o r k ( s t a t e ) n e x t ‾ q v a l u e s = t a r g e t ‾ n e t w o r k ( n e x t ‾ s t a t e ) q ‾ t a r g e t = r e w a r d + ( 1 − d o n e ) × g a m m a × n e x t ‾ q v a l u e s . m a x ( ) l o s s = M S E L o s s ( q ‾ v a l u e s , q ‾ t a r g e t ) q\underline{~}values = q\underline{~}network(state)\\ next\underline{~}qvalues= target\underline{~}network(next\underline{~}state)\\q\underline{~}target = reward + (1 - done) \times gamma \times next\underline{~}qvalues.max()\\loss = MSELoss(q\underline{~}values, q\underline{~}target) q values=q network(state)next qvalues=target network(next state)q target=reward+(1−done)×gamma×next qvalues.max()loss=MSELoss(q values,q target)
- 上述公式为深度 Q 网络(DQN)算法中的Q值更新公式
q ‾ v a l u e s = q ‾ n e t w o r k ( s t a t e ) q\underline{~}values = q\underline{~}network(state) q values=q network(state)
- 通过上述公式进行Action的选择,注意这里用的是q_network而不是target_network
大白话解释:
state和action为经验池里面提取的batch,不是某一时刻的state和action
DQN实例化为q_network,输入state对应输出q_values,action也是这个网络给出的
DQN实例化为target_network,输入next_state对应输出next_q_values
next_q_values实例化为q_targets
q_values和q_targets进行q_network的参数更新
- 深度 Q 网络(DQN)算法中的Q值更新公式参数解释:
- target[action]: 这是当前状态下,执行特定动作
action的目标 Q 值。我们希望通过更新这个 Q 值来使其更接近真实的 Q 值。 - reward: 这是在当前状态下执行
action所得到的即时奖励。 - done: 这是一个布尔值,表示当前状态是否是终止状态。如果
done为 1(或 True),表示已经到达终止状态,那么后续不再有奖励;如果为 0(或 False),则表示还有后续状态和奖励。 - self.gamma: 这是折扣因子(通常在 0 到 1 之间),用于控制未来奖励对当前决策的影响。较高的折扣因子意味着更关注未来的奖励。
- next_q_values.max(): 这是在下一个状态中所有可能动作的 Q 值的最大值,表示在下一个状态下能获得的最佳期望奖励。
个人理解:DQN采用双网络,是off-policy算法。一个训练网络仅使用当前数据,对一种state采取最优的action,需要频繁更新。一个目标网络使用历史数据,采取总体最优action,不需要频繁更新。相较于Q-learning,使用Q函数代替了Q矩阵的作用,在状态很多时Q矩阵难以处理,Q函数擅长对复杂情况进行建模。
相关文章:
强化学习笔记之【Q-learning算法和DQN算法】
强化学习笔记(一)——Q-learning和DQN算法核心公式 文章目录 强化学习笔记(一)——Q-learning和DQN算法核心公式前言:Q-learning算法DQN算法 前言: 强化学习领域,繁冗复杂的大段代码里面&#…...

面试经验02
嵌入式简历制作指南与秋招求职建议 引言 秋招季即将到来,许多同学开始准备求职简历。无论你是考研失利准备就业,还是即将毕业寻找实习,一份优秀的简历都是求职的敲门砖。今天,我们将讨论如何制作嵌入式领域的求职简历࿰…...

分层图 的尝试学习 1.0
分层图: 分层图的最短路: 又叫做 扩点最短路。不把实际位置看做是图上的点,而是把实际位置及其状态的组合,(一个点有若干的状态,所以一个点会扩充出来若干点)看做是图上的点,然后搜索…...

第 31 章 javascript 之 XPath
第 31 章 XPath 1.IE 中的 XPath 2.W3C 中的 XPath 3.XPath 跨浏览器兼容 XPath 是一种节点查找手段,对比之前使用标准 DOM 去查找 XML 中的节点方式,大大降低了查找难度,方便开发者使用。但是,DOM3 级以前的标准并没有就 XPa…...

JavaScript中的高阶函数
高阶函数 所谓高阶函数,就是操作函数的函数,它接收一个或多个函数作为参数,并返回一个新函数: 来看一个mapper()函数,将一个数组映射到另一个使用这个函数的数组上: 更常见的例子,它接收两个函…...
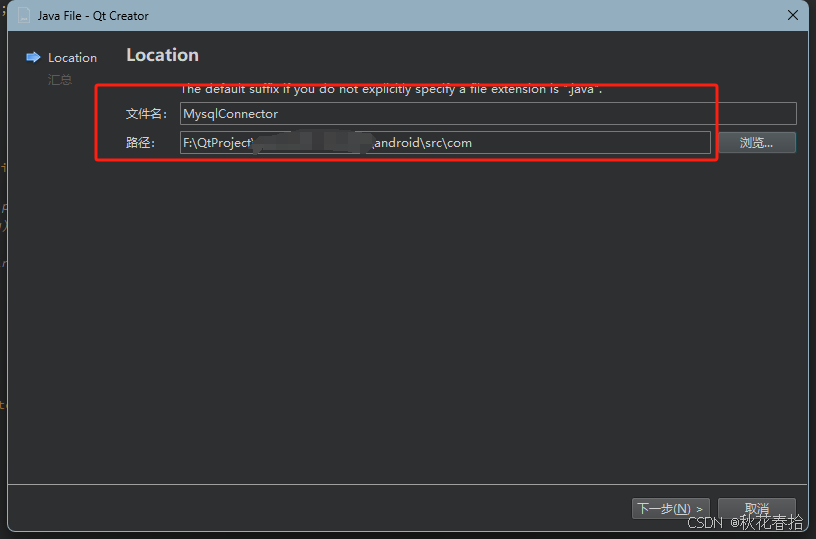
Qt6.7开发安卓程序间接连接到MySQL的方法
本文主要描述一种通过间接的方法,使得Qt开发的安卓程序可以直连到Mysql数据库的方法。本文章的方案是通过JAVA代码去连接MySQL数据库,然后C代码去调用JAVA的方法,从而实现QT开发的安卓程序去直连到MySQL数据库。 本文使用 JDBC 结合 JNI&…...

ROW_NUMBER
How to rewrite a query which uses the ROW_NUMBER() window function in versions 5.7 or earlier before window functions were supported e.g., SELECT ROW_NUMBER() OVER (PARTITION BY fieldA) AS rownum, myTable.* FROM myTable; index 用不上的 Solution Assuming…...

Docker技术
目录 Docker的基本概念 Docker的核心原理 Docker的使用场景 Docker的优点 Docker的挑战 为什么使用 环境一致性 快速启动和部署 资源利用率高 支持微服务架构 持续集成与持续交付(CI/CD) 依赖管理 简化部署流程 高效资源管理 生态系统丰富…...

中小企业做网站需要考虑哪些因素?
中小企业在建设网站时,需要考虑的因素有很多。以下是一些主要考虑因素的介绍: 明确建站目的:中小企业需要明确自己建立网站的目的。是为了展示企业形象、推广产品,还是提供客户服务?不同的目的将决定网站的设计和功能…...
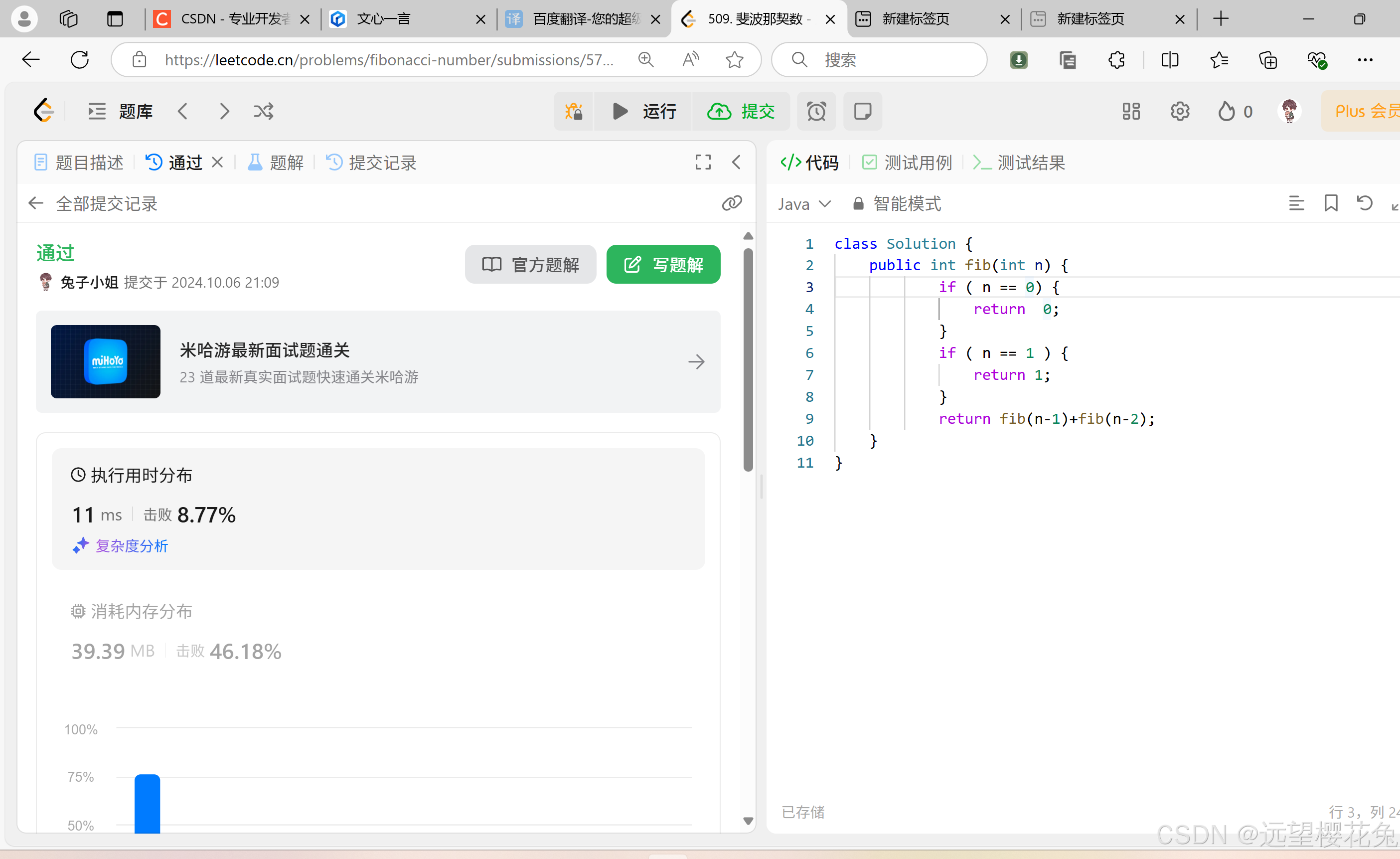
【d60】【Java】【力扣】509. 斐波那契数
思路 要做的问题:求F(n), F(n)就等于F(n-1)F(n-2),要把这个F(n-1)F(n-2)当作常量,已经得到的值, 结束条件:如果是第1 第2 个数字的时候,没有n-1和n-2,所以…...

项目-坦克大战学习-游戏结束
当boos受到伤害时游戏结束,游戏结束时我们需要将窗体全部绘制从别的画面,这样我们可以在游戏运行类中的update设置条件,在游戏运行类thread创建一个枚举类型定义是否游戏结束 public enum Game { play, over };//定义现在游戏运行状态 如果…...

MySQL基础之约束
MySQL基础之约束 概述 概念:约束是作用在字段的规则,限制表中数据 演示 # 多个约束之间不需要加逗号 # auto_increment 自增 create table user(id int primary key auto_increment comment 主键,name varchar(10) not null unique comment 姓名,age i…...

2024新版IDEA创建JSP项目
1. 创建项目 依次点击file->new->Project 配置如下信息并点击create创建项目 2. 配置Web项目 点击file->Project Structure 在点击Project Settings->Module右键右边模块名称->ADD->Web 点击Create Artifact 出现如下界面就表示配置完毕,…...

Conda创建,打包,删除环境相关及配置cuda
conda创建新环境Anaconda删除虚拟环境conda删除环境conda环境打包迁移及部署Python | Conda pack 进行环境打包Anaconda创建环境、删除环境、激活环境、退出环境Anaconda环境离线迁移_CondaPackError处理Anaconda环境离线迁移移植Anaconda-用conda创建python虚拟环境anaconda 配…...
Linux和指令初识
前言 Linux是我们在服务器中常用的操作系统,我们有必要对这个操作系统有足够的认识,并且能够使相关的指令操作。今天我们就来简单的认识一下这个操作的前世今生,并且介绍一些基础的指令操作 Linux的前世今生 要说Linux,还得从U…...

Vortex GPGPU的github流程跑通与功能模块波形探索(二)
文章目录 前言一、环境配置和debugging.md文档1.1 调试 Vortex GPU1.1.1测试 RTL 或模拟器 GPU 驱动的更改1.1.2 SimX 调试1.1.3 RTL 调试1.1.4 FPGA 调试1.1.5 分析 Vortex 跟踪日志 二、跑出波形文件和日志文件总结 前言 昨天另辟蹊径地去探索了子模块的波形仿真,…...

【X线源】微焦点X射线源的基本原理
【X线源】微焦点X射线源的基本原理 1.背景2.原理 1.背景 1895年11月8日,德国物理学家威廉伦琴在研究阴极射线时偶然发现了X射线。当时,他注意到阴极射线管附近的荧光屏发出了光,即使它被纸板遮挡住。经过进一步实验,他意识到这种…...
)
LeetCode hot100---栈专题(C++语言)
1、有效的括号 (1)题目描述以及输入输出 (1)题目描述: 给定一个只包括 (,),{,},[,] 的字符串 s ,判断字符串是否有效。(2)输入输出描述: 输入:s "()&…...

STM32-MPU6050+DAM库源码(江协笔记)
目录 1、MPU6050简介 2、MPU6050参数 3、MPU6050硬件电路 4、MPU6050结构 5、MPU6000和MPU6050的区别 6、MPU6050应用场景 7、MPU6050电气参数 8、MPU6050时钟源选择 9、MPU6050中断源 10、MPU6050的I2C读写操作 11、DMP库移植 1、MPU6050简介 10轴传感器࿱…...
)
Ruby 数组(Array)
Ruby 数组(Array) 引言 Ruby,作为一种高级编程语言,以其简洁明了的语法和强大的功能而闻名。在Ruby中,数组(Array)是一种基本的数据结构,用于存储一系列有序的元素。本文将深入探讨…...

高效跨平台网盘直链解析工具:LinkSwift技术实现与部署指南
高效跨平台网盘直链解析工具:LinkSwift技术实现与部署指南 【免费下载链接】Online-disk-direct-link-download-assistant 一个基于 JavaScript 的网盘文件下载地址获取工具。基于【网盘直链下载助手】修改 ,支持 百度网盘 / 阿里云盘 / 中国移动云盘 / …...

打造便携式Kali Linux安全评估工具:OpenClaw USB定制全攻略
1. 项目概述:一个便携式安全评估工具的诞生 在安全研究、渗透测试或者应急响应的现场,你经常会遇到一个经典困境:目标环境可能是一台物理隔离的机器,或者是一台你无法安装任何软件的“干净”主机。你需要一个功能强大、即插即用的…...

OSINT自动化平台ClawShield:模块化架构与安全运营实战解析
1. 项目概述:一个面向安全运营的公开情报收集与分析平台最近在整理自己的开源项目收藏夹,发现一个挺有意思的仓库,叫SleuthCo/clawshield-public。乍一看这个名字,“ClawShield”,爪子与盾牌,就透着一股子攻…...

为开源项目OpenClaw配置Taotoken作为后端模型供应商
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 为开源项目OpenClaw配置Taotoken作为后端模型供应商 OpenClaw是一个功能强大的开源智能体(Agent)框架&…...

如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案
如何在3分钟内为Photoshop安装AVIF插件:让你的图片体积减半的终极方案 【免费下载链接】avif-format An AV1 Image (AVIF) file format plug-in for Adobe Photoshop 项目地址: https://gitcode.com/gh_mirrors/avi/avif-format 还在为网站图片加载缓慢而烦恼…...
)
【稀缺首发】Midjourney达达主义风格提示工程白皮书:含89组对比实验数据+12个独家种子编号(限前500名下载)
更多请点击: https://intelliparadigm.com 第一章:达达主义在AI图像生成中的哲学解构 达达主义并非技术流派,而是一场对逻辑、秩序与意义权威的激进质疑——这一精神正悄然渗透至当代AI图像生成的核心机制中。当Stable Diffusion接收“一只会…...

终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧
终极qmcdump指南:5分钟掌握QQ音乐加密格式解密技巧 【免费下载链接】qmcdump 一个简单的QQ音乐解码(qmcflac/qmc0/qmc3 转 flac/mp3),仅为个人学习参考用。 项目地址: https://gitcode.com/gh_mirrors/qm/qmcdump qmcdump是…...

Redis增强工具包:封装分布式锁、缓存模板与监控的最佳实践
1. 项目概述:一个Redis开发者的“瑞士军刀”在分布式系统和高并发场景下,Redis几乎成了标配。但用久了你会发现,官方客户端虽然稳定,但在日常开发、调试、运维中,总有些“不够顺手”的地方。比如,想批量按模…...

为AI编程助手构建安全防线:Cursor自定义规则实战指南
1. 项目概述:为AI编程助手装上“安全护栏” 如果你和我一样,深度使用Cursor这类AI编程助手,那你一定体验过它带来的效率革命。它能帮你生成代码、重构函数、甚至解释复杂的逻辑,就像一个不知疲倦的编程伙伴。但硬币总有另一面——…...

Oracle数据库触发器概述
Oracle数据库触发器概述触发器介绍数据库触发器是一个 已编译的存储程序单元 ,使用 PL/SQL 或 Java 编写。 触发器是模式对象,类似于子程序;但其调用方法不同。 子程序由用户、应用程序、或触发器显式运行。而触发器是在触发的事件发生时由 数…...