提升集群吞吐量与稳定性的秘诀: Dubbo 自适应负载均衡与限流策略实现解析
作者:刘泉禄
整体介绍
本文所说的“柔性服务”主要是指 consumer 端的负载均衡和 provider 端的限流两个功能。在之前的 Dubbo 版本中,负载均衡部分更多的考虑的是公平性原则,即 consumer 端尽可能平等的从 provider 中作出选择,在某些情况下表现并不够理想。而限流部分只提供了静态的限流方案,需要用户对 provider 端设置静态的最大并发值,然而该值的合理选取对用户来讲并不容易。我们针对这些存在的问题进行了改进。
负载均衡
在原本的 Dubbo 版本中,有五种负载均衡的方案供选择,他们分别是 “Random” , “ShortestResponse” , “RoundRobin”,“LeastActive” 和 “ConsistentHash”。
其中除 “ShortestResponse” 和 “LeastActive” 外,其他的几种方案主要是考虑选择时的公平性和稳定性。对于 “ShortestResponse” 来说,其设计目的是从所有备选的 provider 中选择 response 时间最短的以提高系统整体的吞吐量。然而存在两个问题:
-
在大多数的场景下,不同 provider 的 response 时长没有非常明显的区别,此时该算法会退化为随机选择。
-
response 的时间长短有时也并不能代表机器的吞吐能力。对于 “LeastActive” 来说,其认为应该将流量尽可能分配到当前并发处理任务较少的机器上。但是其同样存在和 “ShortestResponse” 类似的问题,即这并不能单独代表机器的吞吐能力。
基于以上分析,我们提出了两种新的负载均衡算法。一种是同样基于公平性考虑的单纯 “P2C” 算法,另一种是基于自适应的方法 “adaptive”,其试图自适应的衡量 provider 端机器的吞吐能力,然后将流量尽可能分配到吞吐能力高的机器上,以提高系统整体的性能。
效果介绍
对于负载均衡部分的有效性实验在两个不同的情况下进行的,分别是提供端机器配置比较均衡和提供端机器配置差距较大的情况。
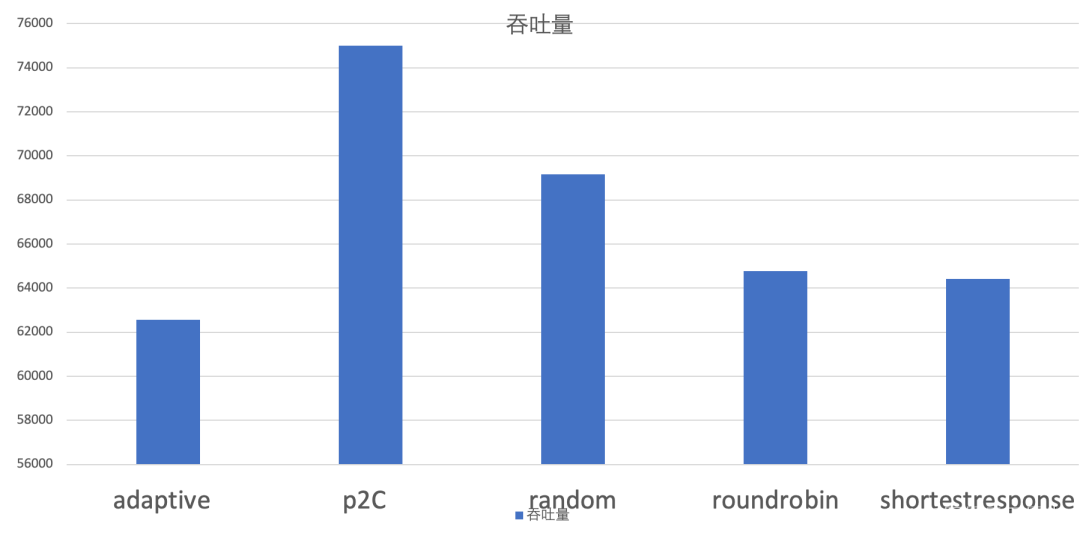
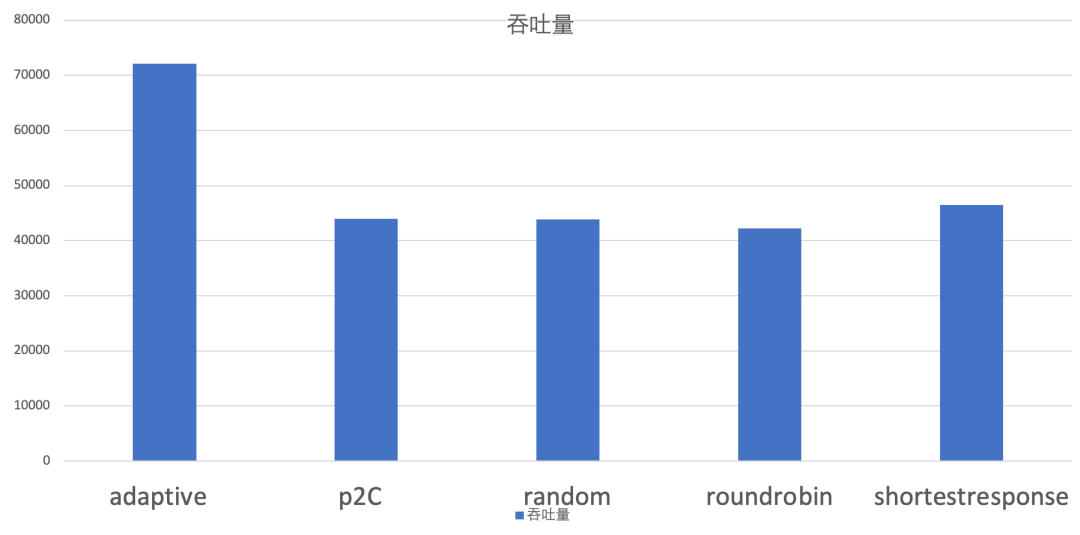
使用方法
使用方法与原本的负载均衡方法相同。只需要在 consumer 端将 “loadbalance” 设置为 “p2c” 或者 “adaptive” 即可。
代码结构
负载均衡部分的算法实现只需要在原本负载均衡框架内继承 LoadBalance 接口即可。
原理介绍
P2C 算法
Power of Two Choice 算法简单但是经典,主要思路如下:
-
对于每次调用,从可用的 provider 列表中做两次随机选择,选出两个节点 providerA 和 providerB。
-
比较 providerA 和 providerB 两个节点,选择其“当前正在处理的连接数”较小的那个节点。
adaptive 算法
代码的 github 地址 [ 1]
相关指标
- cpuLoad
cpuLoad = cpu一分钟平均负载 * 100 / 可用cpu数量。该指标在 provider 端机器获得,并通过 invocation 的 attachment 传递给 consumer 端。
- rt
rt 为一次 rpc 调用所用的时间,单位为毫秒。
- timeout
timeout 为本次 rpc 调用超时剩余的时间,单位为毫秒。
- weight
weight 是设置的服务权重。
- currentProviderTime
provider 端在计算 cpuLoad 时的时间,单位是毫秒
- currentTime
currentTime 为最后一次计算 load 时的时间,初始化为 currentProviderTime,单位是毫秒。
- multiple
multiple=(当前时间 - currentTime)/timeout + 1
- lastLatency

- beta
平滑参数,默认为0.5
- ewma
lastLatency 的平滑值
lastLatency=beta*lastLatency+(1 - beta)*lastLatency
- inflight
inflight 为 consumer 端还未返回的请求的数量。
inflight=consumerReq - consumerSuccess - errorReq
- load
对于备选后端机器x来说,若距离上次被调用的时间大于 2*timeout,则其 load 值为 0。
否则
load=CpuLoad*(sqrt(ewma) + 1)*(inflight + 1)/(((consumerSuccess / (consumerReq +1) )*weight)+1)
算法实现
依然是基于 P2C 算法。
-
从备选列表中做两次随机选择,得到 providerA 和 providerB
-
比较 providerA 和 providerB 的 load 值,选择较小的那个。
自适应限流
与负载均衡运行在 consumer 端不同的是,限流功能运行在 provider 端。其作用是限制 provider 端处理并发任务时的最大数量。从理论上讲,服务端机器的处理能力是存在上限的,对于一台服务端机器,当短时间内出现大量的请求调用时,会导致处理不及时的请求积压,使机器过载。在这种情况下可能导致两个问题:
1.由于请求积压,最终所有的请求都必须等待较长时间才能被处理,从而使整个服务瘫痪。
2.服务端机器长时间的过载可能有宕机的风险。因此,在可能存在过载风险时,拒绝掉一部分请求反而是更好的选择。在之前的 Dubbo 版本中,限流是通过在 provider 端设置静态的最大并发值实现的。但是在服务数量多,拓扑复杂且处理能力会动态变化的局面下,该值难以通过计算静态设置。
基于以上原因,我们需要一种自适应的算法,其可以动态调整服务端机器的最大并发值,使其可以在保证机器不过载的前提下,尽可能多的处理接收到的请求。
因此,我们参考部分业界方案实现基础上,在 Dubbo 的框架内实现了两种自适应限流算法,分别是基于启发式平滑的 “HeuristicSmoothingFlowControl” 和基于窗口的 “AutoConcurrencyLimier”。
代码的 github 地址 [ 2]
效果介绍
自适应限流部分的有效性实验我们在提供端机器配置尽可能大的情况下进行,并且为了凸显效果,在实验中我们将单次请求的复杂度提高,将超时时间尽可能设置的大,并且开启消费端的重试功能。
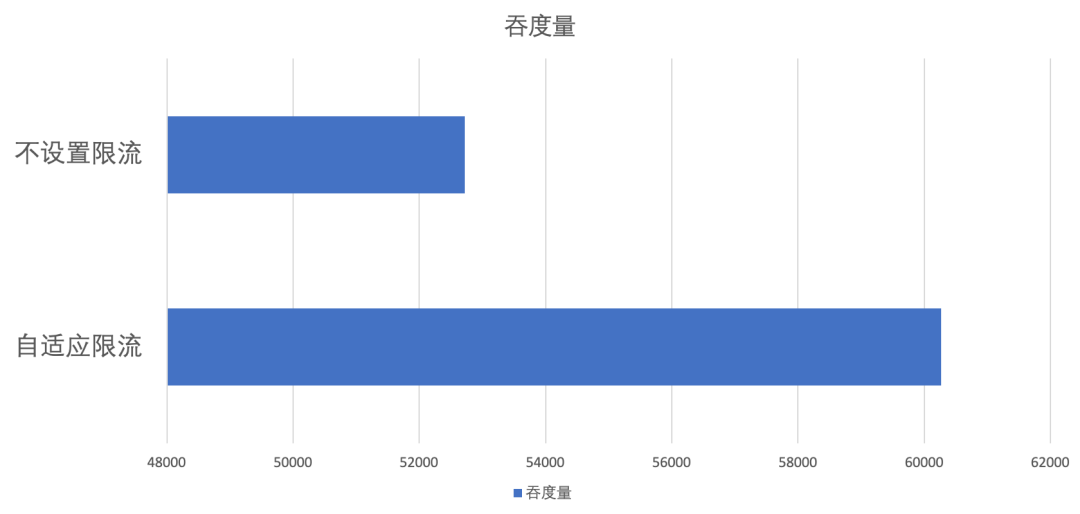
使用方法
要确保服务端存在多个节点,并且消费端开启重试策略的前提下,限流功能才能更好的发挥作用。设置方法与静态的最大并发值设置类似,只需在 provider 端将 “flowcontrol” 设置为 “autoConcurrencyLimier” 或者 “heuristicSmoothingFlowControl” 即可。
代码结构
-
FlowControlFilter:在 provider 端的 filter 负责根据限流算法的结果来对 provider 端进行限流功能。
-
FlowControl:根据 Dubbo 的 spi 实现的限流算法的接口。限流的具体实现算法需要继承自该接口并可以通过 Dubbo 的 spi 方式使用。
-
CpuUsage:周期性获取 cpu 的相关指标
-
HardwareMetricsCollector:获取硬件指标的相关方法
-
ServerMetricsCollector:基于滑动窗口的获取限流需要的指标的相关方法。比如 qps 等。
-
AutoConcurrencyLimier:自适应限流的具体实现算法。
-
HeuristicSmoothingFlowControl:自适应限流的具体实现方法。
原理介绍
HeuristicSmoothingFlowControl
相关指标
- alpha
alpha 为可接受的延时的上升幅度,默认为 0.3
- minLatency
在一个时间窗口内的最小的 Latency 值。
- noLoadLatency
noLoadLatency 是单纯处理任务的延时,不包括排队时间。这是服务端机器的固有属性,但是并不是一成不变的。在 HeuristicSmoothingFlowControl 算法中,我们根据机器CPU的使用率来确定机器当前的 noLoadLatency。当机器的 CPU 使用率较低时,我们认为 minLatency 便是 noLoadLatency。当 CPU 使用率适中时,我们平滑的用 minLatency 来更新 noLoadLatency 的值。当 CPU 使用率较高时,noLoadLatency 的值不再改变。
- maxQPS
一个时间窗口周期内的 QPS 的最大值。
- avgLatency
一个时间窗口周期内的 Latency 的平均值,单位为毫秒。
- maxConcurrency
计算得到的当前服务提供端的最大并发值。
maxConcurrency=ceil(maxQPS*((2 + alpha)*noLoadLatency - avgLatency))
算法实现
当服务端收到一个请求时,首先判断 CPU 的使用率是否超过 50%。如果没有超过 50%,则接受这个请求进行处理。如果超过 50%,说明当前的负载较高,便从 HeuristicSmoothingFlowControl 算法中获得当前的 maxConcurrency 值。如果当前正在处理的请求数量超过了 maxConcurrency,则拒绝该请求。
AutoConcurrencyLimier
相关指标
- MaxExploreRatio
默认设置为 0.3
- MinExploreRatio
默认设置为 0.06
- SampleWindowSizeMs
采样窗口的时长。默认为 1000 毫秒。
- MinSampleCount
采样窗口的最小请求数量。默认为 40。
- MaxSampleCount
采样窗口的最大请求数量。默认为 500。
- emaFactor
平滑处理参数。默认为 0.1。
- exploreRatio
探索率。初始设置为 MaxExploreRatio。若 avgLatency<=noLoadLatency*(1.0 + MinExploreRatio) 或者 qps>=maxQPS*(1.0 + MinExploreRatio)则 exploreRatio=min(MaxExploreRatio,exploreRatio+0.02)
否则
exploreRatio=max(MinExploreRatio,exploreRatio-0.02)
- maxQPS
窗口周期内 QPS 的最大值。
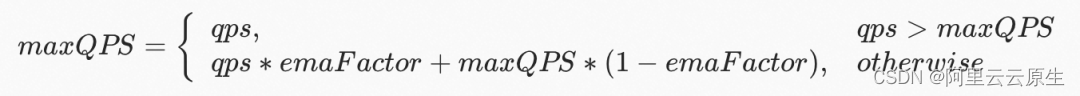
- noLoadLatency

- halfSampleIntervalMs
半采样区间。默认为 25000 毫秒。
- resetLatencyUs
下一次重置所有值的时间戳,这里的重置包括窗口内值和 noLoadLatency。单位是微秒。初始为 0.

- remeasureStartUs
下一次重置窗口的开始时间。
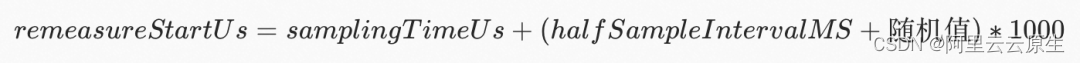
- startSampleTimeUs
开始采样的时间。单位为微秒。
- sampleCount
当前采样窗口内请求的数量。
- totalSampleUs
采样窗口内所有请求的 latency 的和。单位为微秒。
- totalReqCount
采样窗口时间内所有请求的数量和。注意区别 sampleCount。
- samplingTimeUs
采样当前请求的时间戳。单位为微秒。
- latency
当前请求的 latency。
- qps
在该时间窗口内的 qps 值。
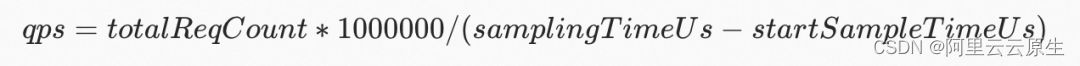
- avgLatency
窗口内的平均 latency。
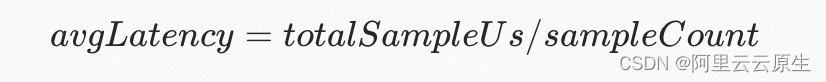
- maxConcurrency
上一个窗口计算得到当前周期的最大并发值。
- nextMaxConcurrency
当前窗口计算出的下一个周期的最大并发值。

Little’s Law
当服务处于稳定状态时:concurrency=latency*qps。这是自适应限流理论的基础。当请求没有导致机器超载时,latency 基本稳定,qps 和 concurrency 处于线性关系。当短时间内请求数量过多,导致服务超载的时候,concurrency 会和latency一起上升,qps则会趋于稳定。
算法实现
AutoConcurrencyLimier 的算法使用过程和 HeuristicSmoothingFlowControl 类似。
实现与 HeuristicSmoothingFlowControl 的最大区别是 AutoConcurrencyLimier 是基于窗口的。每当窗口内积累了一定量的采样数据时,才利用窗口内的数据来更新得到 maxConcurrency。
其次,利用 exploreRatio 来对剩余的容量进行探索。
另外,每隔一段时间都会自动缩小 max_concurrency 并持续一段时间,以处理 noLoadLatency 上涨的情况。因为估计 noLoadLatency 时必须先让服务处于低负载的状态,因此对 maxConcurrency 的缩小是难以避免的。
由于 max_concurrency
Dubbo 于上周上线了新版官网与文档,涵盖 Dubbo3 核心功能及特性,关于自适应负载均衡、自适应限流及更多方案的详细讲解,请访问:https://dubbo.apache.org
相关链接
[1] 代码的 github 地址
https://github.com/apache/dubbo/pull/10745
[2] 代码的 github 地址
https://github.com/apache/dubbo/pull/10642
相关文章:
提升集群吞吐量与稳定性的秘诀: Dubbo 自适应负载均衡与限流策略实现解析
作者:刘泉禄 整体介绍 本文所说的“柔性服务”主要是指 consumer 端的负载均衡和 provider 端的限流两个功能。在之前的 Dubbo 版本中,负载均衡部分更多的考虑的是公平性原则,即 consumer 端尽可能平等的从 provider 中作出选择,…...

大数据分析工具Power BI(十七):制作过程分析和原因分析图表
制作过程分析和原因分析图表 一、过程分析 过程分析主要分析业务流程中每一步骤的变化情况,用于分析业务流程指标数据变化、拆分业务流程、拆分关键业务指标等等。可以使用漏斗图、瀑布图来展示过程分析数据。 1、漏斗图 漏斗图常用来展示业务过程的线性变化,分析业务流程的转…...

公司“007”式工作的卷王测试员,被辞退了…
上周,公司传出同事小王被开除的消息,震惊了一办公室的人。要知道,小王在办公室素有卷王之称,不仅从没见他6点准点下班过,早上也都第一个到。平时的周报,也都洋洋洒洒的写了5K字之多,他的存在一度…...
)
C++ Primer第五版_第七章习题答案(1~10)
文章目录练习7.1练习7.2练习7.3练习7.4练习7.5练习7.6练习7.7练习7.8练习7.9练习7.10练习7.1 使用2.6.1节定义的Sales_data类为1.6节的交易处理程序编写一个新版本。 #include <iostream> #include <string> using std::cin; using std::cout; using std::endl; us…...

2023年全国最新保安员精选真题及答案42
百分百题库提供保安员考试试题、保安职业资格考试预测题、保安员考试真题、保安职业资格证考试题库等,提供在线做题刷题,在线模拟考试,助你考试轻松过关。 421.根据《保安服务管理条例》规定,取得《保安员证》的身体条件是&#x…...
通过 DVT 和 dbt 测试监控Airbyte数据管道
为数据复制或数据迁移构建 ELT 数据管道的一个重要部分是能够在出现错误时进行监视并获得通知。如果您不知道错误,您的数据将包含不一致之处,并且您的报告将不准确。由于使用的工具数量众多,大多数管道的复杂性使得设置监视和警报系统更具挑战…...
BootStrap4:组件
一、按钮 1.1、普通按钮 Bootstrap包括多个预定义的按钮样式,每个样式都有自己的语义目的,另外还有一些额外的功能可以用于更多的控制。 样式效果: 源代码: <body class"container"><button type"bu…...
菜鸟也能在10分钟内开发出3D数字化城市,这份干货教程请收好!
朋友被老板要求在2周内负责一个监控用的的3D全景地图项目,他每天能盯着程序员加班加点的干,可按照进度仍然赶不上ddl。我听了他的诉求,联想到之前参加过的一个宣讲会里提到的新软件,把东西推荐给他后,他让同事跑了一下…...

【区块链技术开发】十个比较流行的以太坊智能合约开发框架
专栏:【区块链技术开发】 前期文章: 【区块链技术开发】剖析区块链Ganache模拟器工具及其智能合约部署区块链的查询方式 【区块链技术开发】基于Web3.js以太坊网络上的智能合约的交互及其应用 【区块链技术开发】OpenZeppelin智能合约库:提高智能合约的安全性和可靠性,加速…...

Linux三剑客之grep命令详解
1、概述 Linux三剑客:grep、sed、awk。grep主打查找功能,sed主要是编辑行,awk主要是分割列处理。本篇文章我们详细介绍grep命令。 grep (global search regular expression(RE) and print out the line,全面搜索正则…...

【Python】【进阶篇】二、Python爬虫的User-Agent用户代理
目录二、Python爬虫的User-Agent用户代理2.1 常见的 User-Agent 请求头2.2 爬虫程序UA信息2.3 重构爬虫UA信息二、Python爬虫的User-Agent用户代理 User-Agent 即用户代理,简称“UA”,它是一个特殊字符串头。网站服务器通过识别 “UA”来确定用户所使用…...
ORBSLAM3 --- 双目惯导执行ORBSLAM3(一):Stereo_intertail_euroc.cc文件解析
1.执行双目例程的参数 在Clion中,我们输入以下参数: /home/liuhongwei/Desktop/slam/ORB_SLAM3_detailed_comments-master/Vocabulary/ORBvoc.txt /home/liuhongwei/Desktop/slam/ORB_SLAM3_detailed_comments-master/Examples_old/Stereo-Inertial/EuRo…...

五 MySQL 存储过程
五、企业级开发技术 5.1 存储过程 关于存储过程我只能说请看下图,这是阿里巴巴发布的《阿里巴巴Java开发手册(终极版)v1.3版本》在 MySQL 第七条中强制指出禁止使用存储过程 所以对于存储过程不必深究,做到会写能看懂即可 [外链…...
【指针函数和函数指针】
指针函数和函数指针1. 概述2. 案例分析指针函数函数指针1. 概述 函数指针和指针函数是两个不同的概念。 函数指针是指一个指针变量,该指针变量存储了一个函数的地址。通过函数指针可以实现动态调用函数,根据需要在程序运行时指定要调用的函数。函数指针的…...

实现卡片高度增加时的缓动动画效果
在开发中,我们可能会遇到需要让卡片高度由内容撑起(即不能手动设置height),并且在高度增加时增加缓动动画的需求。本文将介绍几种实现方式。 文章目录方法1:使用CSS的max-height属性和:hover伪类特定例子:鼠…...

什么是HRMS?哪些工作需要使用HRMS?
当今企业的发展离不开技术支持,同样,在管理方面也需要与时俱进,进行数字化转型。人力资源技术的运用是企业管理数字化转型的重要表现之一。在企业选择一款HR软件之前,应该先认识到,什么是人力资源管理软件——即HRMS。…...
【C语言蓝桥杯每日一题】—— 饮料换购
【C语言蓝桥杯每日一题】—— 饮料换购😎前言🙌饮料换购🙌喝汽水问题🙌饮料换购解题源码分享 😊总结撒花💞😎博客昵称:博客小梦 😊最喜欢的座右铭:全神贯注的…...

PMP适合哪些人考?
其实很多小白在最开始了解PMP考试的时候都会有同一个问题,那就是: “我适不适合考PMP?” 如果想做管理,那么一定要考PMP证书。PMP证书是国际认证,在国内的认可度也很高,可以说是管理岗位的入门认证。注意…...
)
中华好诗词大学季第二季(二)
第四期 1,宋代林升的《题临安邸》是一首著名的墙头诗,请问这里的”邸“指的是什么?旅店 2,宋代林升的《题临安邸》的“临安”是指那个城市?杭州 3,“申黜褒女进,班去赵姬升”具体写到了历史上那四个女人 申皇后,褒…...

【Linux】时间日期指令、查找指令、压缩和解压指令
目录1 时间日期类1.1 date指令-显示当前日期1.2 date指令-设置日期1.3 cal指令2 搜索查找类2.1 find指令2.2 locate指令2.3 grep指令和管道符号 |3 压缩和解压类3.1 gzip/gunzip 指令3.2 zip/unzip 指令1 时间日期类 1.1 date指令-显示当前日期 基本语法 date (功能描述:显示…...

Linux重定向与管道:从文件描述符到高效命令行工作流
1. 项目概述:为什么重定向是命令行的效率倍增器?如果你在Linux命令行里混过一段时间,肯定遇到过这样的场景:想看看一个命令的输出,结果屏幕刷地一下滚过去几百行,关键信息一闪而过;或者想把一个…...

WechatSogou:基于搜狗微信搜索的公众号数据采集解决方案实战指南
WechatSogou:基于搜狗微信搜索的公众号数据采集解决方案实战指南 【免费下载链接】WechatSogou 基于搜狗微信搜索的微信公众号爬虫接口 项目地址: https://gitcode.com/gh_mirrors/we/WechatSogou 在微信公众号生态日益繁荣的今天,如何高效、稳定…...

对比直接购买,使用 Taotoken 的 Token Plan 带来的成本优势感知
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 对比直接购买,使用 Taotoken 的 Token Plan 带来的成本优势感知 1. 从按需付费到套餐规划的成本视角转变 在直接使用各…...

OBS多路RTMP推流插件:一站式解决多平台同步直播难题
OBS多路RTMP推流插件:一站式解决多平台同步直播难题 【免费下载链接】obs-multi-rtmp OBS複数サイト同時配信プラグイン 项目地址: https://gitcode.com/gh_mirrors/ob/obs-multi-rtmp 还在为每次直播需要在不同平台间手动切换而烦恼吗?obs-multi…...

3D模型格式转换终极方案:用stltostp轻松实现STL到STEP的专业转换
3D模型格式转换终极方案:用stltostp轻松实现STL到STEP的专业转换 【免费下载链接】stltostp Convert stl files to STEP brep files 项目地址: https://gitcode.com/gh_mirrors/st/stltostp 你是否曾遇到这样的困境:3D打印的STL模型无法在专业CAD…...

NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的700+高级设置
NVIDIA Profile Inspector终极指南:解锁显卡隐藏性能的700高级设置 【免费下载链接】nvidiaProfileInspector 项目地址: https://gitcode.com/gh_mirrors/nv/nvidiaProfileInspector 作为一款开源显卡配置工具,NVIDIA Profile Inspector提供了直…...

项目烂尾的魔咒:为什么你的物联网系统总是“上线即落后”?
在物联网行业有一个令人沮丧的“3-6-12”现象:3个月调研,6个月开发,12个月后项目烂尾或重构。 为什么投入巨资打造的智慧园区或工业互联系统,往往在验收通过的那一刻,就已经开始走向僵化?问题往往不出在硬…...

UE5项目版本控制终极指南:ue5-gitignore让你的团队协作效率翻倍
UE5项目版本控制终极指南:ue5-gitignore让你的团队协作效率翻倍 【免费下载链接】ue5-gitignore A git setup example with git-lfs for Unreal Engine 5 (and 4) projects. 项目地址: https://gitcode.com/gh_mirrors/ue/ue5-gitignore 在Unreal Engine 5游…...

Silk-v3-decoder:打破即时通讯音频格式壁垒的专业解码方案
Silk-v3-decoder:打破即时通讯音频格式壁垒的专业解码方案 【免费下载链接】silk-v3-decoder [Skype Silk Codec SDK]Decode silk v3 audio files (like wechat amr, aud files, qq slk files) and convert to other format (like mp3). Batch conversion support. …...
)
保姆级教程:用斐讯N1盒子刷Armbian 5.77,打造你的专属Debian服务器(附解决负载过高问题)
斐讯N1盒子改造指南:从电视盒子到高性能家庭服务器的蜕变 在智能家居和个性化网络需求日益增长的今天,拥有一台24小时运行的家庭服务器成为许多技术爱好者的刚需。而斐讯N1盒子凭借其出色的硬件配置和极低的功耗,成为了DIY玩家眼中的"宝…...