于BERT的中文问答系统12
主要改进点
日志配置:
确保日志文件按日期和时间生成,便于追踪不同运行的记录。
数据处理:
增加了对数据加载过程中错误的捕获和日志记录,确保程序能够跳过无效数据并继续运行。
模型训练:
增加了重新训练模型的功能,用户可以选择重新训练现有模型或从头开始训练。
用户交互:
增加了输入验证,确保用户输入的问题不为空。
增加了模糊匹配功能,支持部分输入问题的匹配。
错误处理:
在关键步骤增加了异常捕获和日志记录,提高了程序的健壮性。
import os
import json
import jsonlines
import torch
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from transformers import BertModel, BertTokenizer
import tkinter as tk
from tkinter import filedialog, messagebox
import logging
from difflib import SequenceMatcher
from datetime import datetime# 配置日志
LOGS_DIR = os.path.join(PROJECT_ROOT, 'logs')
os.makedirs(LOGS_DIR, exist_ok=True)def setup_logging():log_file = os.path.join(LOGS_DIR, datetime.now().strftime('%Y-%m-%d/%H-%M-%S/羲和.txt'))os.makedirs(os.path.dirname(log_file), exist_ok=True)logging.basicConfig(level=logging.INFO,format='%(asctime)s - %(levelname)s - %(message)s',handlers=[logging.FileHandler(log_file),logging.StreamHandler()])# 获取项目根目录
PROJECT_ROOT = os.path.dirname(os.path.abspath(__file__))
setup_logging()# 数据集类
class XihuaDataset(Dataset):def __init__(self, file_path, tokenizer, max_length=128):self.tokenizer = tokenizerself.max_length = max_lengthself.data = self.load_data(file_path)def load_data(self, file_path):data = []if file_path.endswith('.jsonl'):with jsonlines.open(file_path) as reader:for i, item in enumerate(reader):try:data.append(item)except jsonlines.jsonlines.InvalidLineError as e:logging.warning(f"跳过无效行 {i + 1}: {e}")elif file_path.endswith('.json'):with open(file_path, 'r') as f:try:data = json.load(f)except json.JSONDecodeError as e:logging.warning(f"跳过无效文件 {file_path}: {e}")return datadef __len__(self):return len(self.data)def __getitem__(self, idx):item = self.data[idx]question = item['question']human_answer = item['human_answers'][0]chatgpt_answer = item['chatgpt_answers'][0]try:inputs = self.tokenizer(question, return_tensors='pt', padding='max_length', truncation=True, max_length=self.max_length)human_inputs = self.tokenizer(human_answer, return_tensors='pt', padding='max_length', truncation=True, max_length=self.max_length)chatgpt_inputs = self.tokenizer(chatgpt_answer, return_tensors='pt', padding='max_length', truncation=True, max_length=self.max_length)except Exception as e:logging.warning(f"跳过无效项 {idx}: {e}")return self.__getitem__((idx + 1) % len(self.data))return {'input_ids': inputs['input_ids'].squeeze(),'attention_mask': inputs['attention_mask'].squeeze(),'human_input_ids': human_inputs['input_ids'].squeeze(),'human_attention_mask': human_inputs['attention_mask'].squeeze(),'chatgpt_input_ids': chatgpt_inputs['input_ids'].squeeze(),'chatgpt_attention_mask': chatgpt_inputs['attention_mask'].squeeze(),'human_answer': human_answer,'chatgpt_answer': chatgpt_answer}# 获取数据加载器
def get_data_loader(file_path, tokenizer, batch_size=8, max_length=128):dataset = XihuaDataset(file_path, tokenizer, max_length)return DataLoader(dataset, batch_size=batch_size, shuffle=True)# 模型定义
class XihuaModel(torch.nn.Module):def __init__(self, pretrained_model_name='F:/models/bert-base-chinese'):super(XihuaModel, self).__init__()self.bert = BertModel.from_pretrained(pretrained_model_name)self.classifier = torch.nn.Linear(self.bert.config.hidden_size, 1)def forward(self, input_ids, attention_mask):outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask)pooled_output = outputs.pooler_outputlogits = self.classifier(pooled_output)return logits# 训练函数
def train(model, data_loader, optimizer, criterion, device):model.train()total_loss = 0.0for batch in data_loader:try:input_ids = batch['input_ids'].to(device)attention_mask = batch['attention_mask'].to(device)human_input_ids = batch['human_input_ids'].to(device)human_attention_mask = batch['human_attention_mask'].to(device)chatgpt_input_ids = batch['chatgpt_input_ids'].to(device)chatgpt_attention_mask = batch['chatgpt_attention_mask'].to(device)optimizer.zero_grad()human_logits = model(human_input_ids, human_attention_mask)chatgpt_logits = model(chatgpt_input_ids, chatgpt_attention_mask)human_labels = torch.ones(human_logits.size(0), 1).to(device)chatgpt_labels = torch.zeros(chatgpt_logits.size(0), 1).to(device)loss = criterion(human_logits, human_labels) + criterion(chatgpt_logits, chatgpt_labels)loss.backward()optimizer.step()total_loss += loss.item()except Exception as e:logging.warning(f"跳过无效批次: {e}")return total_loss / len(data_loader)# 主训练函数
def main_train(retrain=False):device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')logging.info(f'Using device: {device}')tokenizer = BertTokenizer.from_pretrained('F:/models/bert-base-chinese')model = XihuaModel(pretrained_model_name='F:/models/bert-base-chinese').to(device)if retrain:model.load_state_dict(torch.load(os.path.join(PROJECT_ROOT, 'models/xihua_model.pth'), map_location=device, weights_only=True))optimizer = optim.Adam(model.parameters(), lr=1e-5)criterion = torch.nn.BCEWithLogitsLoss()train_data_loader = get_data_loader(os.path.join(PROJECT_ROOT, 'data/train_data.jsonl'), tokenizer, batch_size=8, max_length=128)num_epochs = 5for epoch in range(num_epochs):train_loss = train(model, train_data_loader, optimizer, criterion, device)logging.info(f'Epoch [{epoch+1}/{num_epochs}], Loss: {train_loss:.4f}')torch.save(model.state_dict(), os.path.join(PROJECT_ROOT, 'models/xihua_model.pth'))logging.info("模型训练完成并保存")# GUI界面
class XihuaChatbotGUI:def __init__(self, root):self.root = rootself.root.title("羲和聊天机器人")self.tokenizer = BertTokenizer.from_pretrained('F:/models/bert-base-chinese')self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')self.model = XihuaModel(pretrained_model_name='F:/models/bert-base-chinese').to(self.device)self.load_model()self.model.eval()# 加载训练数据集以便在获取答案时使用self.data = self.load_data(os.path.join(PROJECT_ROOT, 'data/train_data.jsonl'))self.create_widgets()def create_widgets(self):self.question_label = tk.Label(self.root, text="问题:")self.question_label.pack()self.question_entry = tk.Entry(self.root, width=50)self.question_entry.pack()self.answer_button = tk.Button(self.root, text="获取回答", command=self.get_answer)self.answer_button.pack()self.answer_label = tk.Label(self.root, text="回答:")self.answer_label.pack()self.answer_text = tk.Text(self.root, height=10, width=50)self.answer_text.pack()self.train_button = tk.Button(self.root, text="训练模型", command=self.train_model)self.train_button.pack()self.retrain_button = tk.Button(self.root, text="重新训练模型", command=lambda: self.train_model(retrain=True))self.retrain_button.pack()def get_answer(self):question = self.question_entry.get()if not question:messagebox.showwarning("输入错误", "请输入问题")returninputs = self.tokenizer(question, return_tensors='pt', padding='max_length', truncation=True, max_length=128)with torch.no_grad():input_ids = inputs['input_ids'].to(self.device)attention_mask = inputs['attention_mask'].to(self.device)logits = self.model(input_ids, attention_mask)if logits.item() > 0:answer_type = "人类回答"else:answer_type = "ChatGPT回答"specific_answer = self.get_specific_answer(question, answer_type)self.answer_text.delete(1.0, tk.END)self.answer_text.insert(tk.END, f"{answer_type}\n{specific_answer}")def get_specific_answer(self, question, answer_type):# 使用模糊匹配查找最相似的问题best_match = Nonebest_ratio = 0.0for item in self.data:ratio = SequenceMatcher(None, question, item['question']).ratio()if ratio > best_ratio:best_ratio = ratiobest_match = itemif best_match:if answer_type == "人类回答":return best_match['human_answers'][0]else:return best_match['chatgpt_answers'][0]return "未找到具体答案"def load_data(self, file_path):data = []if file_path.endswith('.jsonl'):with jsonlines.open(file_path) as reader:for i, item in enumerate(reader):try:data.append(item)except jsonlines.jsonlines.InvalidLineError as e:logging.warning(f"跳过无效行 {i + 1}: {e}")elif file_path.endswith('.json'):with open(file_path, 'r') as f:try:data = json.load(f)except json.JSONDecodeError as e:logging.warning(f"跳过无效文件 {file_path}: {e}")return datadef load_model(self):model_path = os.path.join(PROJECT_ROOT, 'models/xihua_model.pth')if os.path.exists(model_path):self.model.load_state_dict(torch.load(model_path, map_location=self.device, weights_only=True))logging.info("加载现有模型")else:logging.info("没有找到现有模型,将使用预训练模型")def train_model(self, retrain=False):file_path = filedialog.askopenfilename(filetypes=[("JSONL files", "*.jsonl"), ("JSON files", "*.json")])if not file_path:messagebox.showwarning("文件选择错误", "请选择一个有效的数据文件")returntry:dataset = XihuaDataset(file_path, self.tokenizer)data_loader = DataLoader(dataset, batch_size=8, shuffle=True)# 加载已训练的模型权重if retrain:self.model.load_state_dict(torch.load(os.path.join(PROJECT_ROOT, 'models/xihua_model.pth'), map_location=self.device, weights_only=True))self.model.to(self.device)self.model.train()optimizer = torch.optim.Adam(self.model.parameters(), lr=1e-5)criterion = torch.nn.BCEWithLogitsLoss()num_epochs = 5for epoch in range(num_epochs):train_loss = train(self.model, data_loader, optimizer, criterion, self.device)logging.info(f'Epoch [{epoch+1}/{num_epochs}], Loss: {train_loss:.4f}')torch.save(self.model.state_dict(), os.path.join(PROJECT_ROOT, 'models/xihua_model.pth'))logging.info("模型训练完成并保存")messagebox.showinfo("训练完成", "模型训练完成并保存")except Exception as e:logging.error(f"模型训练失败: {e}")messagebox.showerror("训练失败", f"模型训练失败: {e}")# 主函数
if __name__ == "__main__":# 启动GUIroot = tk.Tk()app = XihuaChatbotGUI(root)root.mainloop()
相关文章:

于BERT的中文问答系统12
主要改进点 日志配置: 确保日志文件按日期和时间生成,便于追踪不同运行的记录。 数据处理: 增加了对数据加载过程中错误的捕获和日志记录,确保程序能够跳过无效数据并继续运行。 模型训练: 增加了重新训练模型的功…...

基于SpringBoot“花开富贵”花园管理系统【附源码】
效果如下: 系统注册页面 系统首页界面 植物信息详细页面 后台登录界面 管理员主界面 植物分类管理界面 植物信息管理界面 园艺记录管理界面 研究背景 随着城市化进程的加快和人们生活质量的提升,越来越多的人开始追求与自然和谐共生的生活方式…...

MySQL连接查询:自连接
先看我的表结构 emp表 自连接也就是把一个表看作是两个作用的表就好,也就是说我把emp看作员工表,也看做领导表 自连接 基本语法 select 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件;例子1:查询员工 及其 所属领导的名字 select a.n…...

Prometheus+Grafana备忘
Grafana安装 官网 https://grafana.com/grafana/download 官网提供了几种安装方式,我用最简单的 yum install -y https://dl.grafana.com/enterprise/release/grafana-enterprise-11.2.2-1.x86_64.rpm启动 //如果需要在系统启动时自动启动Grafana,可以…...
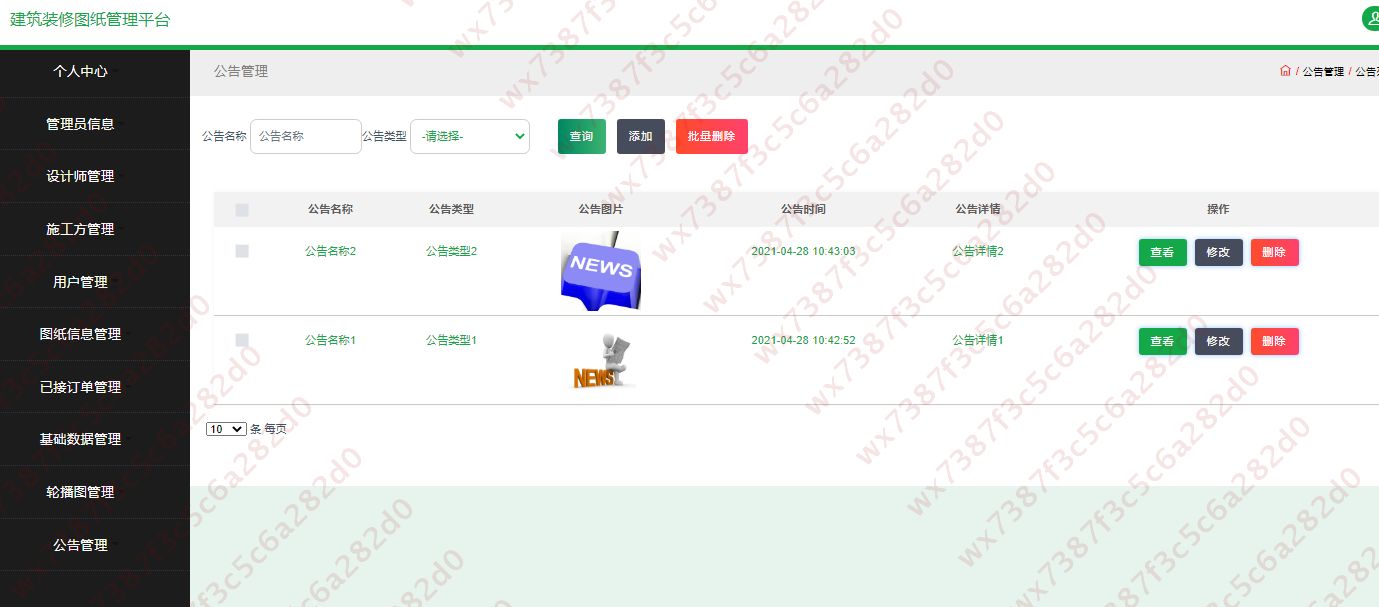
基于ssm实现的建筑装修图纸管理平台(源码+文档)
项目简介 基于ssm实现的建筑装修图纸管理平台,主要功能如下: 技术栈 后端框框:spring/springmvc/mybatis 前端框架:html/JavaScript/Css/vue/elementui 运行环境:JDK1.8/MySQL5.7/idea(可选)…...

计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-07
计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-07 目录 文章目录 计算机前沿技术-人工智能算法-大语言模型-最新研究进展-2024-10-07目录1. Evaluation of Large Language Models for Summarization Tasks in the Medical Domain: A Narrative Review摘要研究…...

Mahalanobis distance 马哈拉诺比斯距离
马哈拉诺比斯距离(Mahalanobis Distance)是一种衡量点与分布之间距离的度量,尤其适用于多维数据。与欧几里得距离不同,马哈拉诺比斯距离考虑了数据的协方差结构,因此在统计分析和异常值检测中非常有用。 定义 给定一…...

R语言绘制直方图
直方图是一种统计图表。它将数据分成若干区间,统计每个区间内数据的数量或频率,用矩形条高度表示。能直观展现数据分布特征,如集中趋势、离散程度等。在数据分析、质量控制、市场调研等领域广泛应用,可帮助人们快速了解数据整体形…...

论文阅读笔记-LogME: Practical Assessment of Pre-trained Models for Transfer Learning
前言 在NLP领域,预训练模型(准确的说应该是预训练语言模型)似乎已经成为各大任务必备的模块了,经常有看到文章称后BERT时代或后XXX时代,分析对比了许多主流模型的优缺点,这些相对而言有些停留在理论层面,可是有时候对于手上正在解决的任务,要用到预训练语言模型时,面…...

求二叉树的带权路径长度
二叉树的带权路径长度(WPL)是二叉树中所有叶结点的带权路径长度之和。给定一棵二叉树T,采用二叉链表存储。结点结构为: 其中叶结点的weight域保存该结点的非负权值。设root为指向T的根结点的指针,请设计求T的WPL的算法…...
)
Hive数仓操作(十五)
Hive 开窗函数 Hive窗口函数是一种特殊的函数,允许用户在查询中对一组行进行计算,而不仅仅是单独的行。窗口函数可以在 SQL 查询中进行聚合、排名、累积计算等。这使得窗口函数在数据分析和报告生成中非常有用。 窗口函数的基本组成部分 函数类型&…...

No.12 笔记 | 网络基础:ARP DNS TCP/IP与OSI模型
一、计算机网络:安全的基石 1. 网络的本质:数字世界的神经系统 定义:计算机的互联互通,实现资源共享和信息交换组成要素:发送者、接收者、介质、数据、协议(五大要素) 2. 网络架构࿱…...

OpenHarmony(鸿蒙南向开发)——轻量系统STM32F407芯片移植案例
往期知识点记录: 鸿蒙(HarmonyOS)应用层开发(北向)知识点汇总 鸿蒙(OpenHarmony)南向开发保姆级知识点汇总~ 持续更新中…… 介绍基于STM32F407IGT6芯片在拓维信息 Niobe407 开发板上移植OpenH…...

简单易懂的springboot整合Camunda 7工作流入门教程
简单易懂的Spring Boot整合Camunda7入门教程 因为关于Spring Boot结合Camunda7的教程在网上比较少,而且很多都写得有点乱,很多概念写得太散乱,讲解不清晰,导致看不懂,本人通过研究学习之后就写出了这篇教学文档。 介…...
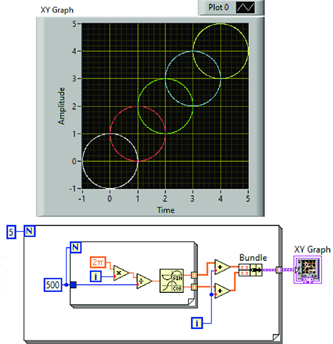
LabVIEW提高开发效率技巧----点阵图(XY Graph)
在LabVIEW开发中,点阵图(XY Graph) 是一种强大的工具,尤其适用于需要实时展示大量数据的场景。通过使用点阵图,开发人员能够将实时数据可视化,帮助用户更直观地分析数据变化。 1. 点阵图的优势 点阵图&…...

C++-匿名空间
匿名命名空间(anonymous namespace)是 C 中的一种特性,用于将符号(如变量、函数或类)限制在定义它们的源文件的作用域内。这意味着在该源文件外部,这些符号不可见,从而避免了命名冲突。 1. 定义…...

jdk的安装和环境变量配置
1.将从官网下载好的jdk放在自己想要放的位置,这里的位置是:E:\develop 2.新建一个文件夹用来放安装的jdk,将jdk安装的此目录,这里的位置是:E:\develop\jdk17 3.jdk安装好之后,点击jdk17目录,点…...

继承、Lambda、Objective-C和Swift
继承 东风系列导弹是镇国神器。东风41不是突然就造出来的,之前有很多种东风xx导弹,每种导弹都有自己的独特之处,相同之处都具备导弹基本特点。很多工厂有量产磨具的生产线,盖房子就图纸,建筑设计建设都有参考ÿ…...

设置服务器走本地代理
勾选: 然后: git clone https://github.com/rofl0r/proxychains-ng.git./configure --prefix/home/wangguisen/usr --sysconfdir/home/wangguisen/etcmakemake install# 在最后配置成本地代理地址 vim /home/wangguisen/etc/proxychains.confsocks4 17…...

刷题 -哈希
面试面试经典 150 题 - 哈希 383. 赎金信 - 一个哈希表搞定 class Solution { public:bool canConstruct(string ransomNote, string magazine) {int hash[26] {0};for (auto& ch : magazine) {hash[ch - a];}for (auto& ch : ransomNote) {if (--hash[ch - a] < …...

利用 Taotoken 多模型聚合能力优化内容生成流水线的实践
🚀 告别海外账号与网络限制!稳定直连全球优质大模型,限时半价接入中。 👉 点击领取海量免费额度 利用 Taotoken 多模型聚合能力优化内容生成流水线的实践 对于内容创作团队而言,不同题材和创作阶段往往需要不同特长的…...

OpenClaw Windows 端快速部署教程 小白实操指南
OpenClaw 一键安装包|一键部署,轻松搞定环境配置 适配系统:Windows10/11 64 核心优势:全程可视化操作,无需命令行、无需手动配置 Python/Node.js,内置所有运行依赖,5 分钟即可完成部署&#x…...

用STM32CubeMX和HAL库,5分钟搞定Nooploop TOFSense激光测距模块的串口通信
基于STM32CubeMX与HAL库的TOFSense激光测距快速开发指南 激光测距技术在工业自动化、机器人导航等领域应用广泛,而Nooploop的TOFSense模块凭借其高精度和小型化特点,成为许多嵌入式开发者的首选。本文将手把手带你使用STM32CubeMX和HAL库,在5…...

小红书内容采集神器:XHS-Downloader免费开源工具完全指南
小红书内容采集神器:XHS-Downloader免费开源工具完全指南 【免费下载链接】XHS-Downloader 小红书(XiaoHongShu、RedNote)链接提取/作品采集工具:提取账号发布、收藏、点赞、专辑作品链接;提取搜索结果作品、用户链接&…...
)
SAP ECC6 2027年停服倒计时:手把手教你评估四大迁移路径与成本(含第三方支持避坑指南)
SAP ECC6 2027年停服倒计时:企业迁移决策全景指南 当2027年的钟声敲响时,全球仍在运行SAP ECC6系统的企业将面临一个关键转折点。这不是简单的技术升级,而是一次关乎企业数字化未来的战略抉择。作为经历过三次SAP重大版本迁移的顾问ÿ…...

DeepSeek-Coder-V2开源部署实战:打破闭源模型垄断的代码智能解决方案
DeepSeek-Coder-V2开源部署实战:打破闭源模型垄断的代码智能解决方案 【免费下载链接】DeepSeek-Coder-V2 DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence 项目地址: https://gitcode.com/GitHub_Trending/de/DeepSeek-C…...

ThinkPad T480黑苹果终极方案:从硬件兼容到系统优化的完全手册
ThinkPad T480黑苹果终极方案:从硬件兼容到系统优化的完全手册 【免费下载链接】t480-oc 💻 Lenovo ThinkPad T480 / T580 / X280 Hackintosh (macOS Monterey 12.x - Sequoia 15.x) - OpenCore 项目地址: https://gitcode.com/gh_mirrors/t4/t480-oc …...

5分钟掌握Sketch Measure:设计师必备的设计标注神器完整指南
5分钟掌握Sketch Measure:设计师必备的设计标注神器完整指南 【免费下载链接】sketch-measure Make it a fun to create spec for developers and teammates 项目地址: https://gitcode.com/gh_mirrors/sk/sketch-measure 还在为设计稿标注而烦恼吗ÿ…...

STM32CubeMX实战:5分钟搞定MAX31865 PT100测温,从SPI配置到温度读取全流程
STM32CubeMX实战:5分钟搞定MAX31865 PT100测温,从SPI配置到温度读取全流程 在工业测温领域,PT100凭借其优异的线性度和稳定性成为温度测量的黄金标准。而MAX31865作为专为RTD传感器设计的信号调理器,极大简化了前端电路设计。本文…...

知识竞赛代表队分组方法详解
🎲 知识竞赛代表队分组方法详解公平 均衡 策略 让每一支队伍都在合适的起点🎯 引言知识竞赛中,代表队的合理分组是赛事公平与精彩的基础。无论是学校比赛、企业活动还是大型公开赛,组织者都需要根据队伍数量和赛制选择合适的分…...