GPU Puzzles讲解(一)
GPU-Puzzles项目可以让你学习到GPU编程和cuda核心并行编程的概念,通过一个个小问题让你理解cuda的编程和调用,创建共享显存空间,实现卷积和矩阵乘法等,通过每个小问题之后还会奖励一个狗狗小视频😁
下面是项目的仓库:https://github.com/srush/GPU-Puzzles![]() https://github.com/srush/GPU-Puzzles
https://github.com/srush/GPU-Puzzles
我本人也是做完了所有的puzzles,特地做一份讲解供大家参考
Puzzle 1: Map
Implement a "kernel" (GPU function) that adds 10 to each position of vector a and stores it in vector out. You have 1 thread per position.
题目的目的是让out输出为a中所有元素+10
def map_spec(a):return a + 10def map_test(cuda):def call(out, a) -> None:local_i = cuda.threadIdx.x# FILL ME IN (roughly 1 lines)out[local_i] = a[local_i] + 10return callSIZE = 4
out = np.zeros((SIZE,))
a = np.arange(SIZE)
problem = CudaProblem("Map", map_test, [a], out, threadsperblock=Coord(SIZE, 1), spec=map_spec
)
problem.show()这里不能完全用Python代码的思想去阅读,函数每次调用cuda.threadId.x的时候都会取一个新的核心,实现并行的效果,下面是可视化运行效果
# MapScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 1 | 1 | 0 | 0 |

Puzzle 2 - Zip
Implement a kernel that adds together each position of a and b and stores it in out. You have 1 thread per position.
在out中每个元素是a,b向量中对应位置元素和,这里不需要什么额外操作,直接local_i作为对应位置的索引即可
def zip_spec(a, b):return a + bdef zip_test(cuda):def call(out, a, b) -> None:local_i = cuda.threadIdx.x# FILL ME IN (roughly 1 lines)out[local_i] = a[local_i] + b[local_i]return callSIZE = 4
out = np.zeros((SIZE,))
a = np.arange(SIZE)
b = np.arange(SIZE)
problem = CudaProblem("Zip", zip_test, [a, b], out, threadsperblock=Coord(SIZE, 1), spec=zip_spec
)
problem.show()可视化效果
# ZipScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 2 | 1 | 0 | 0 | 
Puzzle 3 - Guards
Implement a kernel that adds 10 to each position of a and stores it in out. You have more threads than positions.
这里是Map的升级版,我们拥有更多的cuda线程,但是这不影响,利用if判断使local_i索引有效即可
def map_guard_test(cuda):def call(out, a, size) -> None:local_i = cuda.threadIdx.x# FILL ME IN (roughly 2 lines)if (local_i < size):out[local_i] = a[local_i] + 10return callSIZE = 4
out = np.zeros((SIZE,))
a = np.arange(SIZE)
problem = CudaProblem("Guard",map_guard_test,[a],out,[SIZE],threadsperblock=Coord(8, 1),spec=map_spec,
)
problem.show()可视化效果
# GuardScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 1 | 1 | 0 | 0 | 
Puzzle 4 - Map 2D
Implement a kernel that adds 10 to each position of a and stores it in out. Input a is 2D and square. You have more threads than positions.
这里更进了一步,教我们cuda可以创建二维的线程,我们创建了多余的线程,需要更多边界判断
def map_2D_test(cuda):def call(out, a, size) -> None:local_i = cuda.threadIdx.xlocal_j = cuda.threadIdx.y# FILL ME IN (roughly 2 lines)if local_i < size and local_j < size:out[local_i, local_j] = a[local_i, local_j]+1return callSIZE = 2
out = np.zeros((SIZE, SIZE))
a = np.arange(SIZE * SIZE).reshape((SIZE, SIZE))
problem = CudaProblem("Map 2D", map_2D_test, [a], out, [SIZE], threadsperblock=Coord(3, 3), spec=map_spec
)
problem.show()可视化效果
# Map 2DScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 1 | 1 | 0 | 0 | 
Puzzle 5 - Broadcast
Implement a kernel that adds a and b and stores it in out. Inputs a and b are vectors. You have more threads than positions.
其实就是前面zip的二维版本,对行向量和列向量相同索引位置相加,线程比实际矩阵大,要注意边界
def broadcast_test(cuda):def call(out, a, b, size) -> None:local_i = cuda.threadIdx.xlocal_j = cuda.threadIdx.y# FILL ME IN (roughly 2 lines)if local_i < size and local_j < size:out[local_i, local_j] = a[local_i, 0] + b[0, local_j]return callSIZE = 2
out = np.zeros((SIZE, SIZE))
a = np.arange(SIZE).reshape(SIZE, 1)
b = np.arange(SIZE).reshape(1, SIZE)
problem = CudaProblem("Broadcast",broadcast_test,[a, b],out,[SIZE],threadsperblock=Coord(3, 3),spec=zip_spec,
)
problem.show()可视化效果
# BroadcastScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 2 | 1 | 0 | 0 | 
Puzzle 6 - Blocks
Implement a kernel that adds 10 to each position of a and stores it in out. You have fewer threads per block than the size of a.
这里和前面不同,每一块中线程数比矩阵要小,但是这也不影响,因为把块是把线程分组了,每个块有一定数量的线程,程序会循环遍历取出一个个线程块,判断好边界条件即可
def map_block_test(cuda):def call(out, a, size) -> None:i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x# FILL ME IN (roughly 2 lines)if i < size:out[i] = a[i] + 10return callSIZE = 9
out = np.zeros((SIZE,))
a = np.arange(SIZE)
problem = CudaProblem("Blocks",map_block_test,[a],out,[SIZE],threadsperblock=Coord(4, 1),blockspergrid=Coord(3, 1),spec=map_spec,
)
problem.show()可视化效果
# BlocksScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 1 | 1 | 0 | 0 | 
Puzzle 7 - Blocks 2D
Implement the same kernel in 2D. You have fewer threads per block than the size of a in both directions.
这里线程矩阵比实际的矩阵大小要小,但是没关系,设置好边界条件直接遍历即可
def map_block2D_test(cuda):def call(out, a, size) -> None:i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x# FILL ME IN (roughly 4 lines)j = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.yif i < size and j < size:out[i, j] = a[i, j] + 10return callSIZE = 5
out = np.zeros((SIZE, SIZE))
a = np.ones((SIZE, SIZE))problem = CudaProblem("Blocks 2D",map_block2D_test,[a],out,[SIZE],threadsperblock=Coord(3, 3),blockspergrid=Coord(2, 2),spec=map_spec,
)
problem.show()可视化效果
# Blocks 2DScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 1 | 1 | 0 | 0 | 
Puzzle 8 - Shared
Implement a kernel that adds 10 to each position of a and stores it in out. You have fewer threads per block than the size of a.
这里是利用共享内存的教学,cuda申请共享内存只能用静态变量
TPB = 4
def shared_test(cuda):def call(out, a, size) -> None:shared = cuda.shared.array(TPB, numba.float32)i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.xlocal_i = cuda.threadIdx.xif i < size:shared[local_i] = a[i]cuda.syncthreads()# FILL ME IN (roughly 2 lines)if I < size:out[i] = shared[local_i] + 10return callSIZE = 8
out = np.zeros(SIZE)
a = np.ones(SIZE)
problem = CudaProblem("Shared",shared_test,[a],out,[SIZE],threadsperblock=Coord(TPB, 1),blockspergrid=Coord(2, 1),spec=map_spec,
)
problem.show()可视化效果
# SharedScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 1 | 1 | 1 | 1 | 
Puzzle 9 - Pooling
Implement a kernel that sums together the last 3 position of a and stores it in out. You have 1 thread per position. You only need 1 global read and 1 global write per thread.
这里教会我们要控制全局读写次数,如果把需要重复读的内容移动到共享内存,可以提升效率
def pool_spec(a):out = np.zeros(*a.shape)for i in range(a.shape[0]):out[i] = a[max(i - 2, 0) : i + 1].sum()return outTPB = 8
def pool_test(cuda):def call(out, a, size) -> None:shared = cuda.shared.array(TPB, numba.float32)i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.xlocal_i = cuda.threadIdx.x# FILL ME IN (roughly 8 lines)if i < size:shared[local_i] = a[i]cuda.syncthreads()if i == 0:out[i] = shared[local_i]elif i == 1:out[i] = shared[local_i] + shared[local_i - 1]else:out[i] = shared[local_i] + shared[local_i - 1] + shared[local_i - 2]return callSIZE = 8
out = np.zeros(SIZE)
a = np.arange(SIZE)
problem = CudaProblem("Pooling",pool_test,[a],out,[SIZE],threadsperblock=Coord(TPB, 1),blockspergrid=Coord(1, 1),spec=pool_spec,
)
problem.show()可视化效果
# PoolingScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 1 | 1 | 3 | 1 | 
Puzzle 10 - Dot Product
Implement a kernel that computes the dot-product of a and b and stores it in out. You have 1 thread per position. You only need 2 global reads and 1 global write per thread.
这里是手动实现向量点乘,我们可以先把结果暂存到一个共享内存中,然后最后用一个线程统一计算共享内存的数据并输出到结果,这样可以控制全局读写次数
def dot_spec(a, b):return a @ bTPB = 8
def dot_test(cuda):def call(out, a, b, size) -> None:shared = cuda.shared.array(TPB, numba.float32)i = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.xlocal_i = cuda.threadIdx.x# FILL ME IN (roughly 9 lines)if i < size:shared[local_i] = a[i] * b[i]cuda.syncthreads()if local_i == 0:total = 0.0for j in range(TPB):total += shared[j]out[0] = totalreturn callSIZE = 8
out = np.zeros(1)
a = np.arange(SIZE)
b = np.arange(SIZE)
problem = CudaProblem("Dot",dot_test,[a, b],out,[SIZE],threadsperblock=Coord(SIZE, 1),blockspergrid=Coord(1, 1),spec=dot_spec,
)
problem.show()可视化效果
# DotScore (Max Per Thread):| Global Reads | Global Writes | Shared Reads | Shared Writes || 2 | 1 | 8 | 1 | 
后面还有puzzle11-14,因为难度比较大,思路较为复杂,留在下一篇文章做讲解
👉🏻GPU Puzzles讲解(二)-CSDN博客
相关文章:
GPU Puzzles讲解(一)
GPU-Puzzles项目可以让你学习到GPU编程和cuda核心并行编程的概念,通过一个个小问题让你理解cuda的编程和调用,创建共享显存空间,实现卷积和矩阵乘法等,通过每个小问题之后还会奖励一个狗狗小视频😁 下面是项目的仓库&…...

滚雪球学Oracle[1.3讲]:内存与进程架构
全文目录: 前言一、SGA的深度解析1.1 SGA的作用与构成SGA的大小与调整 1.2 数据库缓冲区缓存(DB Cache)DB Cache的工作原理案例演示:调整DB Cache的大小 1.3 共享池(Shared Pool)的构成与调优共享池的组成部…...

Nginx的正向与反向代理
一、Nginx简介 1. 什么是Nginx Nginx(发音为“engine-x”)是一个高性能的HTTP和反向代理服务器,同时也是一个IMAP/POP3/SMTP代理服务器。Nginx是由俄罗斯的Igor Sysoev(伊戈尔赛索耶夫)为解决C10k问题(即…...

esp8266 at指令链接wifi时一直connect disconnest
那是你的连接wifi的名字密码有误或者热点有问题,看看热点是不是把设备拉入黑名单或者设置为5G或者连了校园网或者设置了最多链接设备...

基于SpringBoot博物馆游客预约系统【附源码】
基于SpringBoot博物馆游客预约系统 效果如下: 主页面 注册界面 展品信息界面 论坛交流界面 后台登陆界面 后台主界面 参观预约界面 留言板界面 研究背景 随着现代社会的快速发展和人们生活水平的提高,文化生活需求也在日益增加。博物馆作为传承文化、…...
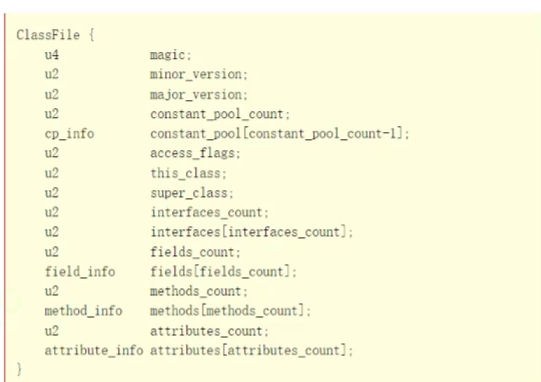
【JVM】内存区域划分,类加载的过程,.class文件的格式
一个java写的程序,跑起来就得到了一个java进程,而java进程=JVM上面运行的字节码指令 JVM是「java虚拟机」,负责解释执行java的指令 【JVM内存区域划分】 1.程序计数器(比较小的空间) 作用:保存了下一条…...
)
esp32-camera入门(基于ESP-IDF)
主要参考资料: ESP32-S2 Kaluga camera lcd 示例入门: https://blog.csdn.net/Marchtwentytwo/article/details/121121028 摄像头应用方案常见问题汇总: https://docs.espressif.com/projects/esp-faq/zh_CN/latest/application-solution/camera-application.html …...

react中类式组件与函数式组件的区别
在React中,类式组件(Class Components)与函数式组件(Functional Components)是两种不同的组件定义方式,它们各有特点,适用于不同的场景。以下是它们之间的主要区别: 一、定义与语法…...

【D3.js in Action 3 精译_030】3.5 给 D3 条形图加注图表标签(下):Krisztina Szűcs 人物专访 + 3.6 本章小结
当前内容所在位置(可进入专栏查看其他译好的章节内容) 第一部分 D3.js 基础知识 第一章 D3.js 简介(已完结) 1.1 何为 D3.js?1.2 D3 生态系统——入门须知1.3 数据可视化最佳实践(上)1.3 数据可…...

【重学 MySQL】五十六、位类型
【重学 MySQL】五十六、位类型 定义赋值与使用注意事项应用场景 在MySQL数据库中,位类型(BIT类型)是一种用于存储位字段值的数据类型。 定义 BIT(n)表示n个位字段值,其中n是一个范围从1到64的整数。这意味着你可以存储从1位到64…...

Centos7 NTP客户端
目录 1. NTP客户端1.1 安装1.2 启动1.3 同步状态异常1.4 更改/etc/chrony.conf配置文件1.5 同步状态正常 1. NTP客户端 1.1 安装 如果chrony没有安装,可以使用以下命令安装 sudo yum install chrony1.2 启动 启动并设置开机自启 sudo systemctl start chronyd …...

手机号归属地查询-手机号归属地-手机号归属地-运营商归属地查询-手机号码归属地查询手机号归属地-运营商归属地
手机号归属地查询API接口是一种网络服务接口,允许开发者通过编程方式查询手机号码的注册地信息。关于快证签API接口提供的手机号归属地查询服务,以下是一些关键信息: 一、快证签API接口简介 快证签API接口可能是一个提供多种验证和查询服务…...
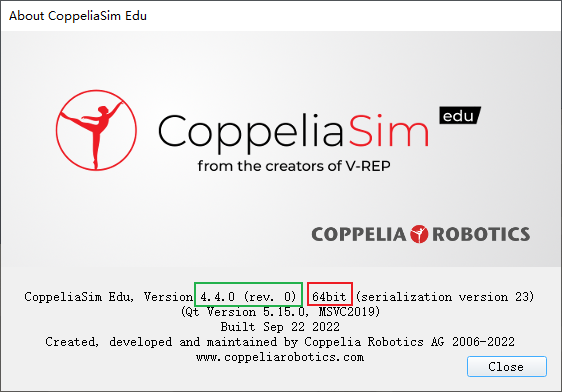
CoppeliaSim和Matlab建立远程连接教程
CoppeliaSim和Matlab建立远程连接教程 Matlab通过调用CoppeliaSim的远程API和库函数实现远程连接,为实现Matlab和CoppeliaSim的联合仿真做准备。 一、获取并查看版本信息 点击 Help 查看版本信息 使用的CoppeliaSim Edu版本为:4.4.0 位数:64bit 二、拷贝API函数和库文件…...

使用STS以及签名URL临时授权访问OSS资源
本文介绍JAVA如何使用STS以及签名URL临时授权访问OSS资源。 注意事项 由于STS临时账号以及签名URL均需设置有效时长,当您使用STS临时账号生成签名URL执行相关操作(例如上传、下载文件)时,以最小的有效时长为准。例如您的STS临时账…...

Next.js 14 使用 react-md-editor 编辑器 并更改背景颜色
1.简介 react-md-editor是一款markdown编辑器,本文介绍如何在Next.js中使用它。 2.安装 安装命令: npm install uiw/react-md-editor3.MD编辑器 markdown编辑器的使用: "use client" import MDEditor from uiw/react-md-edi…...
)
【Iceberg分析】Spark与Iceberg集成落地实践(一)
Spark与Iceberg集成落地实践(一) 文章目录 Spark与Iceberg集成落地实践(一)清理快照与元数据配置表维度自动清理元数据文件属性手动清理 清理孤岛文件合并数据文件 清理快照与元数据 配置表维度自动清理元数据文件属性 每一次写…...

【Verilog学习日常】—牛客网刷题—Verilog进阶挑战—VL45
异步FIFO 描述 请根据题目中给出的双口RAM代码和接口描述,实现异步FIFO,要求FIFO位宽和深度参数化可配置。 电路的接口如下图所示。 双口RAM端口说明: 端口名 I/O 描述 wclk input 写数据时钟 wenc input 写使能 waddr input 写…...

【强训笔记】day27
NO.1 代码实现: #include<iostream>using namespace std;int n,m; int main() {cin>>n>>m;long long retn;for(int i0;i<m-1;i)retret*(n-1)%109;cout<<ret<<endl;return 0; }NO.2 思路:bfs遍历实现,dis…...
Nginx06-静态资源部署
零、文章目录 Nginx06-静态资源部署 1、静态资源概述 静态资源:是在Web开发中不经常改变的文件,比如图片、CSS样式表、JavaScript脚本文件等。这些资源通常是预先编译好的,不需要服务器端的动态处理。动态资源:是在Web开发中需…...

MySQL数据库专栏(二)SQL语句基础操作
目录 数据库操作 创建数据库 查看数据库 选择数据库 删除数据库 数据表操作 数据表数据类型 数据表列约束 数据表索引 创建表 查看表 查看表结构 删除表 数据表的增删改操作 …...

深兰科技签约乌兹别克斯坦智慧城市项目,推动中国AI出海规模化
2026年5月11日,深兰人工智能科技(上海)股份有限公司与乌兹别克斯坦合作方在上海张江总部举行签约仪式。双方将围绕乌兹别克斯坦新塔什干新城(Yangi Toshkent)智慧城市建设展开合作,深兰科技通过控股乌兹别克项目公司,围绕智慧城市、智慧住宅、…...
CircuitPython驱动NeoPixel与DotStar:从原理到炫彩动画实战
1. 项目概述与核心价值在嵌入式开发和物联网项目中,灯光不仅仅是简单的“亮”与“灭”,它更是设备与用户沟通的语言,是项目灵魂的直观体现。无论是智能家居的氛围灯带、可穿戴设备的动态提示,还是艺术装置的视觉表达,可…...

米尔RK3576开发板评测:工业AI与边缘计算的性能甜点方案
1. 项目概述:当RK3576遇上米尔开发板,工业AI的新选择最近在嵌入式圈子里,瑞芯微的RK3576这颗SoC讨论热度挺高。作为一枚常年混迹在工控、边缘计算和AIoT项目里的老工程师,我对这类新平台的发布总是格外敏感。米尔电子作为国内老牌…...

终极指南:如何使用webSpoon快速构建企业级数据集成平台
终极指南:如何使用webSpoon快速构建企业级数据集成平台 【免费下载链接】pentaho-kettle webSpoon is a web-based graphical designer for Pentaho Data Integration with the same look & feel as Spoon 项目地址: https://gitcode.com/gh_mirrors/pen/pent…...

终极文档下载神器:30+平台一键免费保存,告别繁琐下载流程
终极文档下载神器:30平台一键免费保存,告别繁琐下载流程 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该…...

FanControl深度技术解析:构建精准智能的风扇控制体系
FanControl深度技术解析:构建精准智能的风扇控制体系 【免费下载链接】FanControl.Releases This is the release repository for Fan Control, a highly customizable fan controlling software for Windows. 项目地址: https://gitcode.com/GitHub_Trending/fa/…...

ARM PMU性能监控单元原理与编程实践
1. ARM PMU性能监控基础架构解析 性能监控单元(Performance Monitoring Unit, PMU)是现代处理器微架构中的关键组件,它通过硬件计数器实现对处理器运行时行为的精确测量。在ARMv8/v9架构中,PMU的设计遵循了高度模块化和可扩展的原则,能够支持…...
预处理小工具)
告别手动处理!用MATLAB App Designer打造你的专属数据(图片/表格)预处理小工具
告别手动处理!用MATLAB App Designer打造你的专属数据预处理小工具 在数据分析与科研工作中,我们常常陷入重复性劳动的泥潭:每次收到新数据集都要用不同软件打开图片查看尺寸、用Excel检查表格结构、用统计工具计算基础指标。这种碎片化操作不…...

技能管理框架skill-mix:用YAML与声明式配置构建可量化技能体系
1. 项目概述与核心价值最近在梳理团队的知识库和技能树时,我又一次深刻体会到,一个清晰、可量化、可追踪的技能管理体系对个人成长和团队效能有多重要。无论是作为技术负责人评估团队战斗力,还是作为一线开发者规划自己的学习路径,…...
)
ArcGIS实战:手把手教你拼接与裁剪全国10米建筑高度栅格数据(以武汉为例)
ArcGIS实战:全国10米建筑高度栅格数据的精准处理与武汉应用 引言:高精度建筑数据的价值与挑战 城市规划师李明最近在武汉某旧城改造项目中遇到了棘手问题——传统30米分辨率的建筑高度数据无法准确反映老城区复杂的建筑形态差异。当他尝试获取更高精度的…...