数据结构(二叉树)
1. 树相关术语

- 父结点/双亲结点:如果一个结点有子结点那么它就是父结点或者双亲结点;例如A是BCDEFG的父结点,J是PQ的父结点等等;
- 子结点:一个结点含有的子树的根节点称为该结点的子结点;如上图的H是D的子结点,BCDEFG是A的子结点;
- 结点的度:一个结点有几个子结点那他就有多少度,例如A的度为6,他的子结点是BCDEFG,例如D的度为1,他的子结点为H;
- 树的度:树的度就是最大结点的度,上图A的度最大为6所以上面那棵树的度为6;
- 叶子结点:度为0的结点称为叶子结点,也就是没有子结点的结点;
- 分支结点:度不为0的结点称为分支结点,例如DEFGJ都是;
- 兄弟结点:具有相同父结点的结点称为兄弟结点,例如BCDEFG都是兄弟结点,因为他们有是A的子结点;
- 结点的层次:从根开始定义起,根为第 1 层,根的⼦结点为第 2 层,以此类推;
- 树的高度:就是结点的最大层次,也就是4,其实就是看跟结点到最底部的结点有多少层,就是树的高度;
- 结点的祖先:从根到该结点所经分⽀上的所有结点;如上图: A 是所有结点的祖先
- 森林:由 m ( m>0 ) 棵互不相交的树的集合称为森林;
2. 树的表示方法
孩子兄弟表示法:就是说一个结点里,有一个data值存储数据,一个指向从左边开始的第一个子结点还有一个指向右边的兄弟结点;如下图和代码所示
struct TreeNode
{struct Node* child; // 左边开始的第⼀个孩⼦结点struct Node* brother; // 指向其右边的下⼀个兄弟结点int data; // 结点中的数据域
};3. 二叉树
顾名思义就是开叉的树,一个根节点右左子树和右子树组成;如下图所示:
- 二叉树不存在度大于2的结点;
- 二叉树的子树有左右之分,次序不能颠倒所以二叉树是有序的树;
3.1 满二叉树
满二叉树就是除了最后一层以外其他每一层的结点都为最大值,也就是2,则成为满二叉树;如果二叉树的层数为k, 则结点的总个数为2的k次方-1;
3.2 完全二叉树
除了最后一层外,其余每一层的结点个数都必须有2的k-1次方个,且最后一层的每一个子结点都必须是从左到右依次排放;满二叉树是完全二叉树但完全二叉树不一定是满二叉树

二叉树的性质:
1)若规定根结点的层数为 1 ,则⼀棵⾮空⼆叉树的第i层上最多有 2 的i次方 −1 个结点
2)若规定根结点的层数为 1 ,则深度为 h 的⼆叉树的最⼤结点数是 2 的h次方 − 1
3)若规定根结点的层数为 1 ,具有 n 个结点的满⼆叉树的深度 h = log 2 ( n + 1) ( log以2为底, n+1 为对数)
4. 二叉树的存储结构
4.1 顺序结构
顺序结构的底层存储方式是数组,但一般只适合完全二叉树,如果不是满二叉树的话会有空间的浪费,完全二叉树更适合使用顺序结构进行存储;

而我们把完全二叉树的顺序存储称为堆;这里的堆和操作系统的堆不一样。
4.2 顺序结构二叉树
4.2.1 堆分为小根堆和大根堆
顾名思义,小根堆的根是最小的,大根堆的根是最大的值;如下图可知:
- 小堆的某个结点的值不得小于其父节点的值;
- 大堆的某个结点的值不得大于其父节点的值;
- 堆一般都是一棵完全二叉树;
4.2.2 堆的性质
4.2.3 堆的实现
由于堆的底层就是数组,那么堆的结构和顺序表就大差不差了;如下代码所示.h文件也就是准备要实现堆的每个功能的声明:
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
#include<string>//定义堆的结构---数组
typedef int HPDataType;
typedef struct Heap
{HPDataType* arr;int size;//有效的数据个数int capacity;//空间大小
}HP;//交换
void Swap(int* x, int* y);//堆的初始化
void HPInit(HP* php);//堆的销毁
void HPDestroy(HP* php);//堆的插入数据
void HPPush(HP* php, HPDataType x);//堆的删除数据
void HPPop(HP* php);//取堆顶数据
HPDataType HPTop(HP* php);// 判空
bool HPEmpty(HP* php);//向上调整
void AdjustUp(HPDataType* arr, int child);//向下调整
void AdjustDown(HPDataType* arr, int parent, int n);- 堆的初始化:
void HPInit(HP* php)
{assert(php);php->arr = NULL;php->capacity = 0;php->size = 0;
}- 堆的删除:
void HPDestroy(HP* php)
{assert(php);if (php->arr){free(php->arr);}php->arr = NULL;php->capacity = 0;php->size = 0;
}- Swap:
void Swap(int* x, int* y)
{int temp = *x;*x = *y;*y = temp;
}- 向上调整:就是说如果插入的数据不符合小堆或者大堆的性质的话就需要往上调整,如下图所示:
 这个就不是小堆,因为43比6大,父结点大于子结点,所以我们需要向上移动,如下动图和代码所示:
这个就不是小堆,因为43比6大,父结点大于子结点,所以我们需要向上移动,如下动图和代码所示:
void AdjustUp(HPDataType* arr, int child)
{int parent = (child - 1) / 2;while (child > 0){if (arr[parent] > arr[child]){Swap(&arr[parent], &arr[child]);child = parent;parent = (child - 1) / 2;}else{break; }}
}- 插入数据:插入数据就是在尾部插入一个数据,需要判断空间是否充足,因为底层是顺序表,插入数据后还要向上调整一下,如果说符合小堆或大堆特性则不动,如果不符合则往上调整;如下代码所示:
void HPPush(HP* php, HPDataType x)
{//push就是尾插assert(php);//进行插入的时候我们要判断空间是否充足if (php->size == php->capacity){int Newcapacity = php->capacity == 0 ? 4 : 2 * php->capacity;HPDataType* temp = (HPDataType*)realloc(php->arr, Newcapacity * sizeof(HPDataType));//漏了sizeof(HPDataType)if (temp == NULL){perror("realloc fail!");exit(1);}//增容成功php->arr = temp;php->capacity = Newcapacity;}php->arr[php->size] = x;AdjustUp(php->arr, php->size);++php->size;
}- 堆的向下调整:传入一个父结点,判断该父结点和子结点是否符合小堆或大堆的性质,和向上调整不一样,向上调整是传入子结点判断子结点和父结点;如果说在小堆里父结点大于子结点的话就需要向下调整;如下图和代码所示:

void AdjustDown(HPDataType* arr, int parent, int n)
{int child = parent * 2 + 1;while (child < n){if (child + 1 < n && arr[child] > arr[child + 1]){child++;}if (arr[child] < arr[parent]){Swap(&arr[child], &arr[parent]);parent = child;child = parent * 2 + 1;}else{break;}}
}- 堆的头删操作:如果说我们直接删除头结点的话就会出现错误,因为本身头结点就是根节点,如果说我们直接删掉的话那就出问题了,树没有根了,所以我们需要交换根节点和最后一个结点,然后--size,删除掉最后一个结点其实也就是根节点,然后再向下调整即可;


void HPPop(HP* php)
{assert(php);assert(php->size); //这个就是树要有结点Swap(&php->arr[0], &php->arr[php->size - 1]);--php->size;AdjustDown(php->arr, 0, php->size);}判空操作:直接就是看size是否为0,因为size是计算堆中数据的个数的;如下代码所示:
bool HPEmpty(HP* php)
{assert(php);return php->size == 0;
}取堆顶元素:取堆顶元素就是直接取下标为0的元素即可;如下代码所示:
HPDataType HPTop(HP* php)
{assert(php && php->size);return php->arr[0];
}4.2.4 堆排序
小堆排序,首位交换,小的到最下面了然后再对堆顶元素进行向下调整,然后--end,再首位交换,一直循环到end<=0的时候,小数据就全部在后面,大数据就全部在前面得到一个降序的数组;如果想得到一个升序的则用大堆排序;如下代码所示:
void HeapSort(int* arr, int n)
{//建堆//升序--大堆//降序--小堆向上建堆//for (int i = 0; i < n; i++)//{// AdjustUp(arr, i);//}//向下建堆得从最下面开始建起//因为向下调整必须他下面就是一个堆//那么就从传入的数据开始,传入的i就是childfor (int i = (n - 1 - 1) / 2; i >= 0; i--){//i就是最后一个孩子的父母AdjustDown(arr, i, n);}//建完堆后int end = n - 1;while (end > 0){Swap(&arr[0], &arr[end]);AdjustDown(arr, 0, end);end--;}
}int main()
{int arr[] = { 17,20,10,13,19,15 };HeapSort(arr, 6);for (int i = 0; i < 6; i++){printf("%d ", arr[i]);}return 0;
}👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇
运行结果为:
4.3 链式结构实现
用链表来实现一棵二叉树,一个结点有三个域组成,一个data存储数据,一个指向左孩子,还有一个指向右孩子;
#pragma once
#include<iostream>
#include<assert.h>
#include<stdlib.h>
using namespace std;//定义一个链表树
typedef int BTNodeType;
typedef struct BinaryTree
{BTNodeType data;struct BinaryTree* LeftNode;struct BinaryTree* RightNode;}BTNode;在这里不实现二叉树的插入和删除,就先手动创建几个结点;如下代码所示:
#include"Tree.h"
BTNode* Buynode(BTNodeType x)
{BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));if (newnode == NULL){perror("malloc fail!");exit(1);}newnode->data = x;newnode->LeftNode = newnode->RightNode = NULL;return newnode;
}void createTree()
{BTNode* node1 = Buynode(1);BTNode* node2 = Buynode(2);BTNode* node3 = Buynode(3);BTNode* node4 = Buynode(4);node1->LeftNode = node2;node1->RightNode = node3;node2->LeftNode = node4;}👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇 👇
调试结果为:

4.3.1 前中后序遍历
二叉树有三种方式遍历:前序遍历、中序遍历、后序遍历。而这三种遍历都需要使用递归来实现:
1)前序遍历(Preorder):先访问根结点、然后左子树、最后右子树;总结:根左右。
2)中序遍历(Inorder):先访问左子树、然后根结点、最后访问右子树;总结:左根右
3)后序遍历(Posorder):先访问左子树、然后右子树、最后根结点;总结:左右根

代码实现如下:
//根左右
void PreOrder(BTNode* root)
{if (root == NULL){return;}printf("%d", root->data);PreOrder(root->LeftNode);PreOrder(root->RightNode);
}//左根右
void InOrder(BTNode* root)
{if (root == NULL){return;}InOrder(root->LeftNode);printf("%d", root->data);InOrder(root->RightNode);
}//左右根
void PosOrder(BTNode* root)
{if (root == NULL){return;}PosOrder(root->LeftNode);PosOrder(root->RightNode);printf("%d", root->data);
}4.3.2 计算Tree的结点个数
首先我们要知道,链式结构的二叉树遍历都是需要递归的,递归会产生多个函数栈帧,如果说我们想创建局部变量来存储的话则无法返回值,因为局部变量出了作用域自动被销毁,而创建全局变量的话则会出现比如说tree的结点有4个,我们调用了两次计算结点个数的函数的话那在第二次打印结点个数的时候会显示8;所以一般做叠加计算的话都是通过返回值进行处理;如下代码所示:
int BinaryTreeSize(BTNode* root)
{if (root == NULL){return 0;}return 1 + BinaryTreeSize(root->LeftNode) + BinaryTreeSize(root->RightNode);
}
4.3.3 计算Tree的叶子结点的个数
计算叶子结点的话,也是通过递归进行,那我们就要先想清楚递归停止的条件,如果不想清楚则会无限陷入递归里面;同样也是像上面那样通过返回值进行递归,当递归到空节点的时候则要返回0,如果说该结点的左右孩子都为NULL的话则说明这是一个叶子结点就返回1;如下代码所示:
// ⼆叉树叶⼦结点个数
int BinaryTreeLeafSize(BTNode* root)
{if (root == NULL){return 0;}if (root->LeftNode == NULL && root->RightNode == NULL){return 1;}return BinaryTreeLeafSize(root->LeftNode) + BinaryTreeLeafSize(root->RightNode);
}
4.3.4 计算二叉树第k层结点个数
计算第k层结点的个数,假如传入的层数k = 2, 根节点位于第一层,遍历到第二层的话就可以通过k-1来实现,当k等于1的时候为第二层;加入传入的层数k = 3的话,那就每次递归-1,当k等于1的时候就为第三层了;
// ⼆叉树第k层结点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{if (root == NULL){return 0;}if (k == 1){return 1;}return BinaryTreeLevelKSize(root->LeftNode, k - 1) + BinaryTreeLevelKSize(root->RightNode, k - 1);
}
4.3.5 计算二叉树的深度/高度
递归到NULL的时候返回0,如果不是NULL则返回1,然后还要比较左右子树的大小,我们只要最大的,所以用个三目运算符进行判断;
//⼆叉树的深度/⾼度
int BinaryTreeDepth(BTNode* root)
{if (root == NULL){return 0;}int left = BinaryTreeDepth(root->LeftNode);int right = BinaryTreeDepth(root->RightNode);return left > right ? left + 1 : right + 1;
}4.3.6 二叉树查找值为x的结点
当找到的时候返回当前结点的地址,没找到则返回NULL,如果遍历到空的时候返回NULL;
// ⼆叉树查找值为x的结点
BTNode* BinaryTreeFind(BTNode* root, BTNodeType x)
{if (root == NULL){return NULL;}if (root->data == x){return root;}BTNode* left = BinaryTreeFind(root->LeftNode,x);if (left)return left;BTNode* right = BinaryTreeFind(root->RightNode,x);if (right)return right;return NULL;
}4.3.7 二叉树销毁
销毁操作就不同上面的了,如果说遍历到空结点的时候则让他直接跳出该次循环直接进入下一条语句,当遍历完LeftNode结点和RightNode结点的时候再free掉当前结点,但有一个要注意的是,需要改变实参,那就要进行传址操作,而这里就需要用到二级指针;如下代码所示:
// ⼆叉树销毁
void BinaryTreeDestory(BTNode** root)
{if ((*root) == NULL){return;}BinaryTreeDestory(&((*root)->LeftNode));BinaryTreeDestory(&((*root)->RightNode));free(*root);*root = NULL;
}4.3.8 层序遍历
层序遍历则需要用到队列,这里不需要递归,只需要进行入队列,打印,出队列,然后判断左右结点是否为空,不为空则插入左结点和右结点
一直循环直到队列为空的时候结束循环。如下代码所示:
//层序遍历
void LevelOrder(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);while (!(QueueEmpty(&q))){BTNode* front = QueueFront(&q);printf("%d ", front->data);QueuePop(&q);if(front->LeftNode)QueuePush(&q, front->LeftNode);if(front->RightNode)QueuePush(&q, front->RightNode);}QueueDestroy(&q);
}4.3.9 判断是否为完全二叉树
这就是完全二叉树

如果不是完全二叉树则会出现打印空之后还有值;如下图所示:
如下代码所示:
//判断二叉树是否为完全二叉树
bool BinaryTreeComplete(BTNode* root)
{Queue q;QueueInit(&q);QueuePush(&q, root);while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front == NULL){break;}QueuePush(&q,root->LeftNode);QueuePush(&q, root->RightNode);}while (!QueueEmpty(&q)){BTNode* front = QueueFront(&q);QueuePop(&q);if (front != NULL){QueueDestroy(&q);return false;}}QueueDestroy(&q);return true;
}END!
相关文章:
数据结构(二叉树)
1. 树相关术语 父结点/双亲结点:如果一个结点有子结点那么它就是父结点或者双亲结点;例如A是BCDEFG的父结点,J是PQ的父结点等等;子结点:一个结点含有的子树的根节点称为该结点的子结点;如上图的H是D的子结点…...
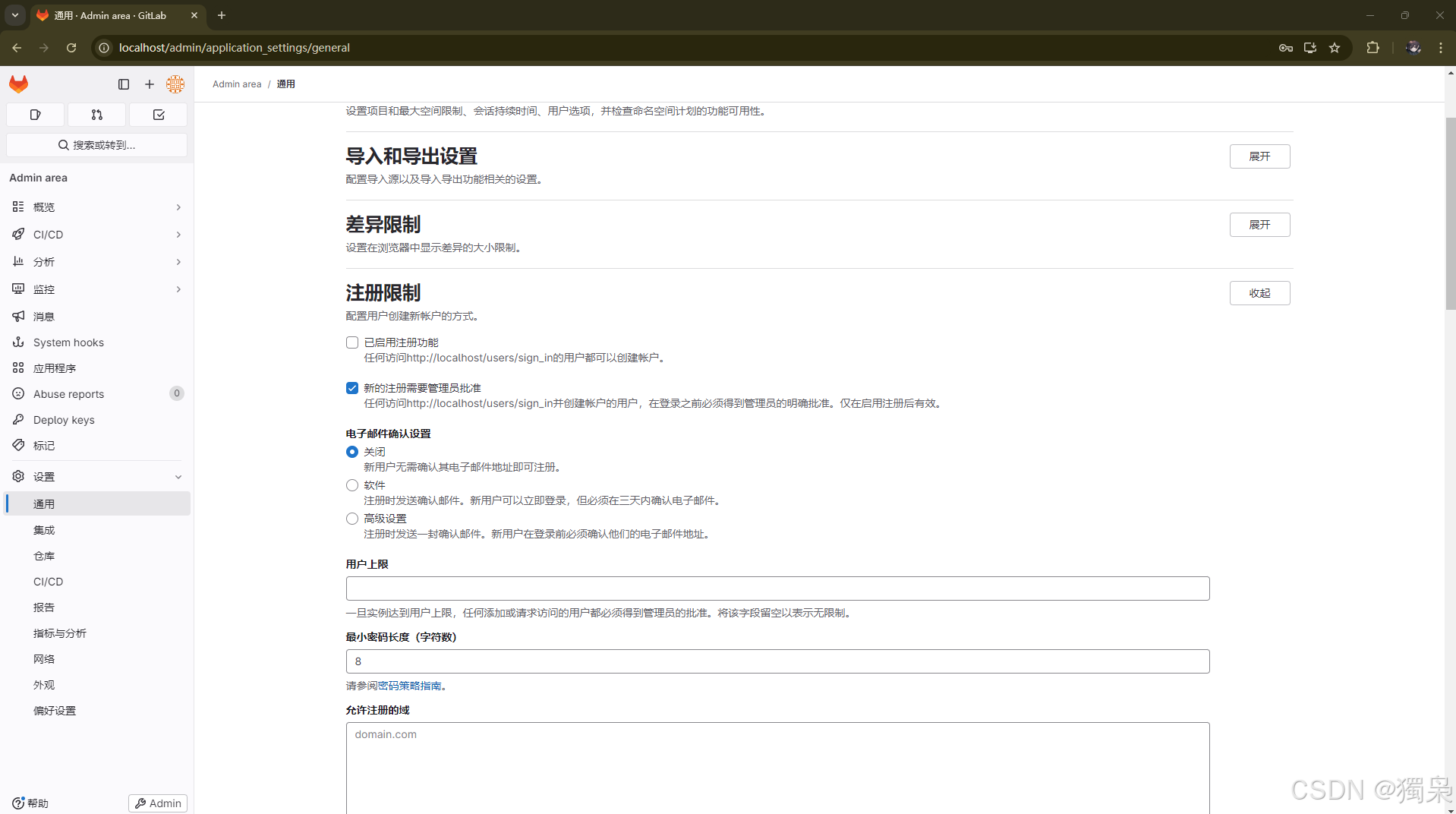
Windows 通过 Docker 安装 GitLab
1. 安装 Docker Desktop 下载网站:Windows | Docker Docs 2. 拉取 GitLab Docker 镜像 打开 PowerShell 或 命令提示符,拉取 GitLab 镜像: docker pull gitlab/gitlab-ee:latest或则使用社区版: docker pull gitlab/gitlab-ce…...

SQL专项练习第六天
Hive 在处理不同数据需求时的灵活性和强大功能,包括间隔连续问题的处理、行列转换、交易数据查询、用户登录统计以及专利数据分析等方面。本文将介绍五个 Hive 数据处理问题的解决方案,并通过实际案例进行演示。 先在home文件夹下建一个hivedata文件夹&a…...

CSS——属性值计算
CSS——属性值计算 今天来详细讲解一下 CSS的属性值计算过程,这是 CSS 的核心之一(另一个是视觉可视化模型,个人理解,这个相对复杂,以后再讲)。 基本概念 层叠样式表:Cascade Style Sheet&am…...

408算法题leetcode--第26天
496. 下一个更大元素 I 题目地址:496. 下一个更大元素 I - 力扣(LeetCode) 题解思路:单调栈,如注释 时间复杂度:O(n m) 空间复杂度:O(n) 代码: class Solution { public:vector<int&g…...

JavaScript 与浏览器存储
JavaScript提供了两种存储数据的方式:LocalStorage和SessionStorage。这两种方式都是浏览器提供的客户端存储解决方案,可以将数据保存在用户的浏览器中,供网站使用。 LocalStorage和SessionStorage的区别在于数据的作用域和生命周期。 Loca…...

Chromium 如何查找已经定义好的mojom函数实现c++
进程通信定义通常都是用.mojom文件或者idl文件格式 以content\common\frame.mojom里面的BeginNavigation函数为例。 一、如何查找BeginNavigation函数定义,在vscode里面直接搜索BeginNavigation,过滤条件 *.idl,*.mojom,*.cc 效果: 这样…...

图文深入理解Oracle DB Scheduler(续)-调度的创建
List item 今天是国庆假期最后一天。窗外,秋雨淅淅沥沥淅淅下个不停。继续深宅家中,闲来无事,就多写几篇博文。 本篇承接前一篇,继续图文深入介绍Oracle DB Scheduler。本篇主要介绍调度的创建。 1. 创建基于时间的作业 • 可以…...

基于Springboot的宠物咖啡馆平台的设计与实现(源码+定制+参考)
博主介绍: ✌我是阿龙,一名专注于Java技术领域的程序员,全网拥有10W粉丝。作为CSDN特邀作者、博客专家、新星计划导师,我在计算机毕业设计开发方面积累了丰富的经验。同时,我也是掘金、华为云、阿里云、InfoQ等平台…...
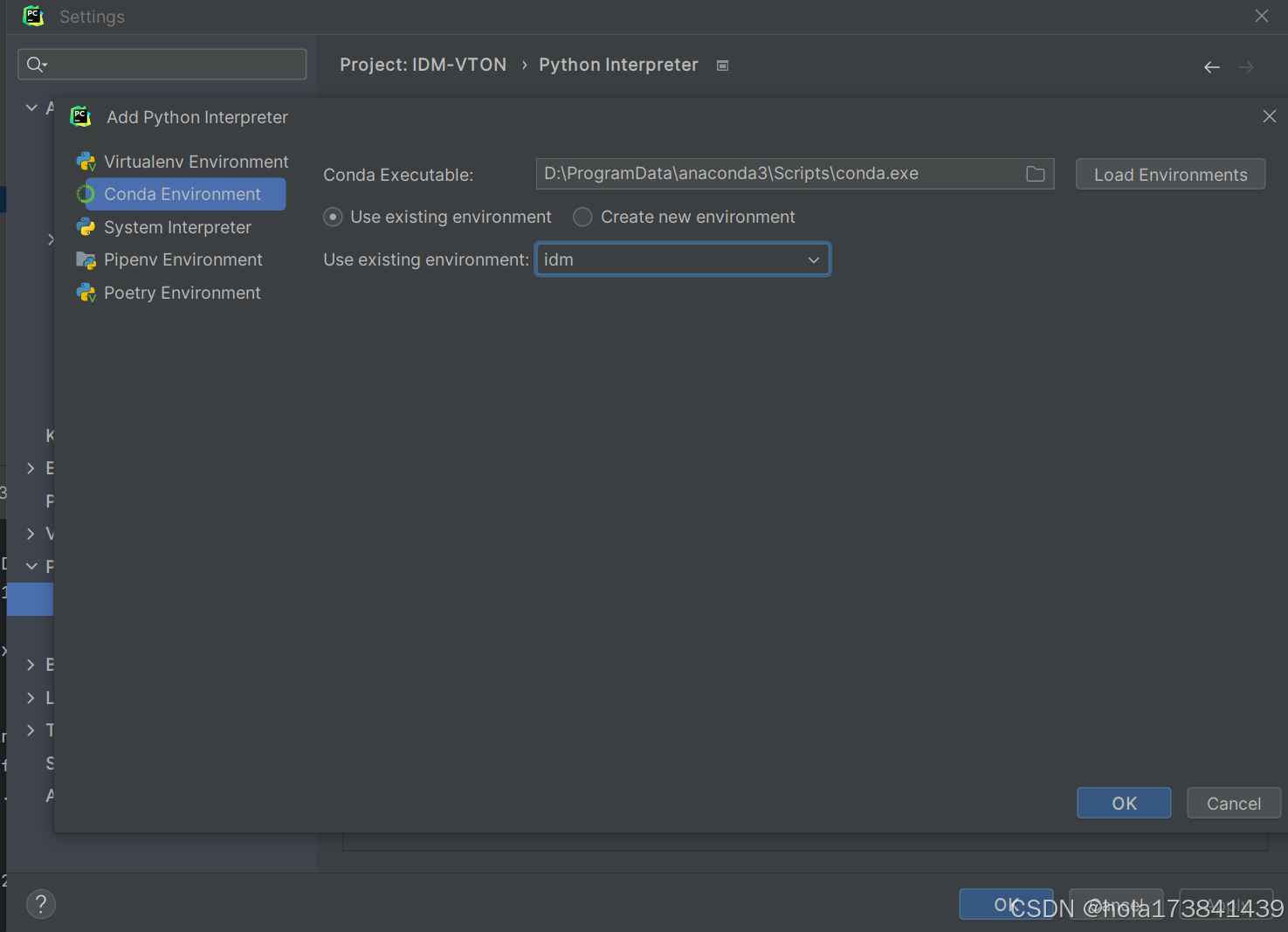
Conda答疑
文章目录 优雅的使用Conda管理python环境1. conda info -e 和conda env list区别2.conda创建环境 创建的新环境在哪个文件夹下3. 自定义路径4. anaconda 新建环境 包是来自哪里4.1. 默认 Anaconda 仓库4.2. Conda-Forge4.3. 镜像源4.4. 自定义频道4.5. 总结 5. conda config --…...

Python 工具库每日推荐【PyPDF2】
文章目录 引言Python PDF 处理库的重要性今日推荐:PyPDF2 工具库主要功能:使用场景:安装与配置快速上手示例代码代码解释实际应用案例案例:PDF文件合并案例分析高级特性加密和解密PDF添加水印扩展阅读与资源优缺点分析优点:缺点:总结【 已更新完 TypeScript 设计模式 专栏…...

Nacos的应用
什么是nacos? Nacos是一个开源的动态服务发现,配置管理和服务治理平台。主要用于构建原生应用和微服务架构。它是阿里巴巴开源的项目,整合了配置管理,服务管理,服务发现的功能,核心价值在于帮助用户在云平…...

CSS圆角
在制作网页的过程中,有时我们可能需要实现圆角的效果,以前的做法是通过切图(将设计稿切成便于制作成页面的图片),使用多个背景图像来实现圆角。在 CSS3 出现之后就不需要这么麻烦了,CSS3 中提供了一系列属性…...

信息安全工程师(37)防火墙概述
前言 防火墙是一种网络安全系统,旨在监控和控制网络流量,根据预定义的安全规则决定是否允许数据包的传输。 一、定义与功能 定义:防火墙是网络安全的第一道防线,由硬件设备和软件系统共同构成,位于外网与内网之间、公共…...

多元化网络团队应对复杂威胁
GenAI、ML 和 IoT 等技术为威胁者提供了新的工具,使他们更容易针对消费者和组织发起攻击。 从诱骗受害者陷入投资骗局的Savvy Seahorse ,到使用 ChatGPT 之类的程序感染计算机并阅读电子邮件的自我复制 AI 蠕虫,新的网络威胁几乎每天都在出现…...
)
Observer(观察者模式)
1. 意图 定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都得到通知并被自动更新。 在观察者模式中,有两类对象:被观察者(Subject)和观察者(Observer…...

Python深度学习进阶与前沿应用:注意力机制、Transformer模型、生成式模型、目标检测算法、图神经网络、强化学习等
近年来,伴随着以卷积神经网络(CNN)为代表的深度学习的快速发展,人工智能迈入了第三次发展浪潮,AI技术在各个领域中的应用越来越广泛。为了帮助广大学员更加深入地学习人工智能领域最近3-5年的新理论与新技术࿰…...

24.1 prometheus-exporter管理
本节重点介绍 : exporter 流派 必须和探测对象部署在一起的1对多的远端探针模式 exporter管控的难点 1对1 的exporter 需要依托诸如 ansible等节点管理工具 ,所以应该尽量的少 1对1的exporter改造成探针型的通用思路 exporter 流派 必须和探测对象部署在一起的…...

【Arduino IDE安装】Arduino IDE的简介和安装详情
目录 🌞1. Arduino IDE概述 🌞2. Arduino IDE安装详情 🌍2.1 获取安装包 🌍2.2 安装详情 🌍2.3 配置中文 🌍2.4 其他配置 🌞1. Arduino IDE概述 Arduino IDE(Integrated Deve…...

『网络游戏』自适应制作登录UI【01】
首先创建项目 修改场景名字为SceneLogin 创建一个Plane面板 - 将摄像机照射Plane 新建游戏启动场景GameRoot 新建空节点重命名为GameRoot 在子级下创建Canvas 拖拽EventSystem至子级 在Canvas子级下创建空节点重命名为LoginWnd - 即登录窗口 创建公告按钮 创建字体文本 创建输入…...

TI毫米波雷达IWR/AWR1642 L3 RAM内存优化实战:从原理到配置
1. 项目概述:为何要动L3 RAM这块“蛋糕”?如果你正在基于TI的IWR1642或AWR1642毫米波雷达芯片进行开发,尤其是当你的应用代码量越来越大,或者数据处理任务越来越重时,你可能会遇到一个瓶颈:内存不够用了。不…...
Translumo终极指南:5步掌握实时屏幕翻译与OCR识别技术
Translumo终极指南:5步掌握实时屏幕翻译与OCR识别技术 【免费下载链接】Translumo Advanced real-time screen translator for games, hardcoded subtitles in videos, static text and etc. 项目地址: https://gitcode.com/gh_mirrors/tr/Translumo 你是否曾…...

Android Studio中文界面解决方案:从语言障碍到开发效率提升
Android Studio中文界面解决方案:从语言障碍到开发效率提升 【免费下载链接】AndroidStudioChineseLanguagePack AndroidStudio中文插件(官方修改版本) 项目地址: https://gitcode.com/gh_mirrors/an/AndroidStudioChineseLanguagePack 当你在And…...

8款投屏软件亲测对比:哪款才是真正的“良心之选”?
市面上的投屏软件多如牛毛,但真正好用的没几个。为了帮大家避坑,我亲自下载、安装、使用了8款常见的投屏工具,从是否收费、有无广告、功能丰富度、兼容性、实际体验五个维度做了深度测试。下面是我的真实使用感受,希望对你有帮助。…...

PowerPoint插件latex-ptt安装踩坑全记录:从‘无法下载’到‘点击报错’的保姆级排雷指南
LaTeX公式输入神器latex-ppt插件安装与排雷全攻略 在学术报告、技术分享或教学演示中,数学公式的呈现质量直接影响专业形象。虽然PowerPoint作为主流演示工具广受欢迎,但其原生公式编辑器功能有限,无法满足科研工作者对LaTeX公式排版的需求。…...

ARM架构ID_ISAR4寄存器详解与应用
1. ARM架构中的ID_ISAR4寄存器概述在ARMv8架构体系中,系统寄存器扮演着处理器功能特性的关键角色。作为指令集属性寄存器家族的重要成员,ID_ISAR4(Instruction Set Attribute Register 4)专门用于描述处理器在AArch32执行状态下支…...

WinGet安装工具:PowerShell自动化部署的架构解析与实践指南
WinGet安装工具:PowerShell自动化部署的架构解析与实践指南 【免费下载链接】winget-install Install WinGet using PowerShell! Prerequisites automatically installed. Works on Windows 10/11 and Server 2019/2022. 项目地址: https://gitcode.com/gh_mirror…...

5分钟快速上手:OpenRGB跨平台RGB灯光控制神器终极指南
5分钟快速上手:OpenRGB跨平台RGB灯光控制神器终极指南 【免费下载链接】OpenRGB Open source RGB lighting control that doesnt depend on manufacturer software. Supports Windows, Linux, MacOS. Mirror of https://gitlab.com/CalcProgrammer1/OpenRGB. Releas…...

为什么你的v8出图突然“高级感崩塌”?3分钟定位色彩语义锚点失效+实时修复模板
更多请点击: https://intelliparadigm.com 第一章:为什么你的v8出图突然“高级感崩塌”? V8 引擎本身并不直接“出图”——这一表述实为开发者对前端渲染链路中某环节异常的戏谑指代。真正崩塌的,往往是基于 V8 驱动的 Canvas/We…...

Lacinia错误处理最佳实践:构建健壮GraphQL API的10个技巧
Lacinia错误处理最佳实践:构建健壮GraphQL API的10个技巧 【免费下载链接】lacinia GraphQL implementation in pure Clojure 项目地址: https://gitcode.com/gh_mirrors/la/lacinia Lacinia作为纯Clojure实现的GraphQL库,为开发者提供了构建高效…...