Diffusion models(扩散模型) 是怎么工作的
前言
给一个提示词, Midjourney, Stable Diffusion 和 DALL-E 可以生成很好看的图片,那么它们是怎么工作的呢?它们都用了 Diffusion models(扩散模型) 这项技术。
Diffusion models 正在成为生命科学等领域的一项尖端技术,例如, Diffusion models 可以生成分子用于药物发现。
这篇文章,我们会谈到当前扩散模型的发展状态和能力。
我们将从理解sampling process(采样过程)开始,从纯噪声开始并逐步改进它以获得最终的好看的图像。我们将
建立必要的编程技能来有效地训练扩散模型。我们将学习如何构建能够预测图像中噪声的神经网络。我们将向模型添加上下文,以便可以控制它生成的位置。最后,通过实施高级算法,你将学习如何通过10倍的因数加速采样过程。
对扩散模型直观的理解
首先我们将讨论扩散模型的目标,然后我们将讨论你拥有的不同精灵的训练数据如何对这些模型有用,然后我们将讨论如何在这些数据上训练模型本身。
扩散模型的目标是什么?你有很多训练数据,比如你看到的这些精灵图像,这些是你的训练数据集。你想要的是你想要更多的这些精灵,它们没有在你的训练数据集中表示出来。你可以使用一个神经网络,它可以为你生成更多的这些精灵,遵循扩散模型的过程。
那么,我们如何使这些图像对神经网络有用呢?好吧,你希望神经网络能够普遍地学习精灵的概念,它是什么。这可能是更细致的细节,比如精灵的头发颜色,或者它腰带上的扣子。但它也可能是一般的轮廓,像它的头和身体,以及其中的一切。做到这一点的一种方式,强调更细致的细节或一般轮廓的方式,实际上是添加不同级别的噪声。所以这只是向图像中添加噪声,它被称为“增噪过程”。
这是受到物理学启发的。你可以想象一滴墨水滴入一杯水中。最初,你确切地知道墨水滴在哪里落下。但随着时间的推移,你实际上会看到它扩散到水中,直到它消失。这里的想法是一样的,你从“鲍勃精灵”开始,当你添加噪声时,它会逐渐消失,直到你不知道它实际上是哪个精灵。那么当你逐渐向图像中添加更多噪声时,神经网络究竟应该在每一个噪声级别上想些什么呢?当它是“鲍勃精灵”时,你希望神经网络会说,“是的,那是鲍勃精灵”。保持鲍勃的样子,就是一个精灵。如果可能是鲍勃,那么你可能希望神经网络会说,“你知道,这儿有些噪声。”。提出一些建议的细节,使其看起来像“鲍勃精灵”。如果现在它只是一个精灵的轮廓,那么你只能感觉到这可能是一个精灵人物,但它可能是鲍勃或者弗雷德,甚至可能是南希,那么你想要为可能的精灵提出更一般的细节。所以或许你会根据这个为鲍勃提出一些建议的细节,或者你会为弗雷德提出一些细节。最后,如果你一无所知,如果它看起来完全像什么都没有,你仍然希望它看起来更像一个精灵。你仍然希望神经网络会说,“你知道吗,我还是要把这个完全噪声的图像变成某种稍微像精灵的东西,通过提出一个精灵可能看起来的轮廓。”
那么现在开始训练那个神经网络吧。它要学会处理不同的噪声图像并将它们转换回精灵图像。这就是你的目标。 它是如何做到这一点的呢?它学会了去除你添加的噪声。 从“毫无头绪”级别开始,那里只有纯粹的噪声, 然后开始让它看起来好像可能有一个人在那里,变得像弗雷德一样,最终成为一个看起来像弗雷德的精灵。“毫无头绪”级别的噪声非常重要,因为它是正态分布的。 我的意思是,这些像素中的每一个都是从一个正态分布中抽样得到的,也就是所谓的 “高斯分布”或“钟形曲线”。所以当你想要请求神经网络生成一个新的精灵,比如这里的弗雷德,你可以从那个正态分布中抽样噪声, 然后你可以通过神经网络逐渐去除那些噪声,得到一个全新的精灵。现在你已经达到了你的目标。你甚至可以得到更多的精灵,超出了你所训练过的所有精灵。



采样(推理)
现在我们讨论采样。我们将深入了解其细节以及它是如何在多次迭代中工作的。 在我们讨论如何训练这个神经网络之前,让我们谈谈采样,或者我们在训练完成后在推理时如何使用神经网络。 所以发生的事情是你有了那个噪声样本。 你将其通过你的训练有素的神经网络 它已经理解了精灵的样子 它所做的是预测噪声。它预测噪声 而不是精灵,然后我们从噪声样本中减去 预测出的噪声,以得到更像精灵的东西。 现实情况是,这只是噪声的预测 它并没有完全去除所有噪声,所以你需要 多个步骤来获得高质量样本。经过 500次迭代后,我们能够得到看起来 非常像精灵的东西。所以现在让我们从算法上逐步了解这个过程。
首先,你可以采样一个随机噪声 样本,现在我们从最初的 噪声开始。 然后你想要逆着时间走,实际上你是 从最后一次迭代,500次,那时是完全噪声状态,一直 回到第一次。只需想象你的墨水滴。你实际上是 在时间上倒退。它最初是完全扩散的 然后你正在回到 最初墨水滴入水中的那一刻。
你实际上将原始噪声,那个样本,再次传回你的神经网络, 然后你会得到一些预测噪声。这个预测噪声是经过训练的神经网络想要从原始噪声中减去的,以得到看起来更像 精灵的东西。 最后,有一个叫做“DDPM”的采样算法,意为 去噪扩散概率模型, 一篇由 Jonathan Ho, Ajay Jain 和 Pieter Abbeel 所写的论文(https://arxiv.org/abs/2006.11239)。 这个采样算法本质上能够 得到一些用于缩放的数字。这不是特别重要,但重要的是 这是你实际上从 原始噪声样本中减去预测噪声的地方。而且你又添加那一点额外的噪声回去。
好的,现在我们讨论那额外的噪声。现在你的神经网络在预测你原始噪声样本中的噪声。你将它减去,得到更像精灵的东西。但这个神经网络期望输入的是正态分布的噪声样本。去噪后,样本的分布就不再是这样了。因此,你需要在每一步之后和下一步之前,添加根据当前时间步骤缩放的额外噪声,作为下一次迭代的输入。实际上,这有助于稳定神经网络,防止它仅产生接近数据集平均值的结果。如果我们不把噪声加回去,神经网络只会产生这些平均的精灵团块;而当我们加回噪声时,它才能够创造出美丽的精灵图像。


神经网络架构 UNet
接下来我们将讨论神经网络、其架构以及我们如何将额外信息整合到其中。我们用于扩散模型的神经网络架构是一个UNet。你需要知道的最重要的事情是,UNet以这张图片作为输入,并输出一个与该图片大小相同的东西,但这里它预测的是噪声。UNet已经存在很长时间了,自2015年起就有了,并且它首次被用于图像分割。它最初是用来将图像准确分割成行人或汽车的,因此它在自动驾驶汽车研究中被广泛使用。但UNet特别之处在于其输入和输出是同样的大小。它所做的首先是将关于这个输入的信息进行嵌入,通过许多卷积层来下采样,将所有信息压缩到一小块空间中。然后它通过同样数量的上采样块将输出重新上采样完成它的任务。在这个案例中,任务是预测被应用到这张图片上的噪声。而这个预测的噪声与原始输入图像的尺寸相同,是16x16x3的维度。关于这个UNet的另一个优点是它可以接收额外的信息。所以它压缩了图像以理解发生了什么,但它也可以接收更多信息。那么我们想要包含哪些信息呢?嗯,对于这些模型来说一个非常重要的事情是时间嵌入。所以这是一个告诉模型时间步长的嵌入,因此知道我们需要什么样的噪声水平。而你所需要做的关于这个时间嵌入就是将它嵌入到某种向量中,并且你可以将它添加到这些上采样块中。
另一条有用的信息是上下文嵌入。上下文嵌入所做的就是帮助你控制模型生成的内容。例如,一个文本描述,就像你真的希望它是Bob,或者某种因素,比如它需要是特定的颜色。在上采样块中,你将上下文嵌入与上采样块相乘,然后添加时间嵌入。我们稍后会更多地讨论这个问题。


训练神经网络
现在,我们将讨论如何训练这个UNet神经网络并让它预测噪声。因此,神经网络的目标是预测噪声,并且它确实学习了图像上噪声的分布,但也学习了什么不是噪声,什么是精灵的相似性。我们做这个的方法是,我们从我们的训练数据中取一个精灵,并实际向其添加噪声。我们给它添加噪声,然后交给神经网络,并要求神经网络预测那个噪声。然后我们比较预测的噪声和添加到那个图像上的实际噪声,这就是我们如何计算损失的。
然后通过神经网络进行反向传播,于是神经网络就学会更好地预测那个噪声。那么你怎么确定这里的噪声是什么呢?你可以通过时间采样并给予不同的噪声水平。但实际上,在训练中,我们不希望神经网络一直看同一个精灵。如果它在一个epoch中观察不同的精灵,它会更稳定,而且更加均匀。所以实际上我们所做的是我们随机采样这个时间步骤可能是什么。然后我们获得适合那个时间步骤的噪声水平。我们将它添加到这个图像上,然后让神经网络预测它。我们取我们训练数据中的下一个精灵图像。我们再次随机采样一个时间步骤。它可能和你在这里看到的完全不同。然后我们将它添加到这个精灵图像上,并再次让神经网络预测添加的噪声。这样就产生了一个更稳定的训练方案。那么实际的训练是什么样子的呢?这里是一个巫师帽精灵,这里是噪声输入看起来的样子。
当你首次在第0个epoch将它放入神经网络时,神经网络还没有真正学会什么是精灵。所以预测的噪声并没有真正改变输入的样子,而当它被减去后,它实际上就变成了这个样子,看起来差不多。但到了第31个epoch,神经网络对这个精灵的样子有了更好的理解。然后它预测噪声,然后从这个输入中减去这个噪声,生成了类似这个巫师帽精灵的东西。
很酷,所以那是一个样本。这是针对多个不同的样本,多种不同的精灵,在许多个时期中,看起来是什么样的。正如你可以在这个第一个epoch中看到的,它与精灵相去甚远,但是到了这里的第32个epoch甚至在那之前,它看起来很像小型视频游戏角色。




控制模型的生成内容
下面,你将学习如何控制模型和它生成的内容。 对许多人来说,这是最令人兴奋的部分,因为你可以告诉模型你想要的内容,然后它可以为你想象出来。 当谈到控制这些模型时,我们实际上想要使用嵌入(embeddings)。嵌入是什么呢?我们在前面已经稍微了解了一下时间嵌入和上下文嵌入,嵌入就是向量,它们是能够捕获含义的数字。这里它捕获了这个句子或者这个笑话的含义,也许是通过扩散模型。"布朗运动体经常碰撞到彼此"。所以它将这个含义编码成嵌入,即这一组向量中的数字。 嵌入特别的地方在于它们能够捕获语义含义,因此内容相似的文本将具有相似的向量。而嵌入神奇的一点是你几乎可以用它进行向量算术。例如“巴黎 - 法国 + 英格兰 = 伦敦嵌入”。好的,那这些嵌入是如何在训练期间真正成为模型上下文的呢?这里,你有一个鳄梨的图片,你希望神经网络去学习,你也为它提供了一个标题,一个成熟的鳄梨。你实际上可以通过这个过程,得到一个嵌入,并将其输入神经网络,然后预测添加到这个鳄梨图片上的噪声,接着计算损失并做之前相同的事情。
你可以在许多不同的带有标题的图片上应用这个方法。这里有一个舒适的扶手椅。你可以将其通过一个嵌入,传入模型,并作为训练的一部分。 现在,这个部分的魔力在于,虽然你能从互联网上抓取带有这些标题的鳄梨和扶手椅的图片,但在推理时,你能生成模型之前从未见过的东西。那可能是一个“鳄梨扶手椅”。这一切之所以神奇,是因为你可以将“鳄梨扶手椅”这些词嵌入到包含了一些鳄梨和一些扶手椅的嵌入中,将其通过神经网络,让它预测噪声,然后去除这些噪声,你看,就出现了一个“鳄梨扶手椅”。 更广泛来说,上下文是一个可以控制生成的向量。正如我们现在所见,上下文可以是那个“鳄梨扶手椅”的文本嵌入,那是很长的。但是上下文不必非要那么长。上下文还可以是五个不同类别的长度,你知道的,五个不同维度,比如设定为英雄或非英雄,就像这些火球和蘑菇这样的对象。它可以是食物项目,你知道的,苹果、橙子、西瓜。它可以是像这个弓箭或者这个蜡烛这样的咒语和武器。最后,它可能是这些精灵是侧面还是正面。



加速采样方法
下面我们将了解到一种新的采样方法,它比我们迄今为止使用的DDPM高效10倍以上。这种新方法被称为DDIM。
您的目标是希望获得更多的图片,并且希望快速获得。但是到目前为止,采样过程一直很慢,因为一来,涉及许多时间步骤,您知道的,有500个,有时甚至更多,以获得一个好的样本,每一个时间步骤还依赖于前一个步骤。它遵循马尔可夫链过程。
不过值得庆幸的是,现在有许多新的采样器来解决这个问题,因为这一直是扩散模型的一个长期问题。问题在于您可以训练它们,它们能创造出既多样又逼真的美丽图像,但是从它们那里得到结果却非常缓慢。而这些采样器中一个非常受欢迎的叫做DDIM,或者叫去噪扩散隐式模型(Denoising Diffusion Implicit Models)。
这篇论文是由Jiaming Song、Chenlin Meng和Stefano Ermon撰写的。DDIM之所以更快,是因为它能跳过时间步骤。所以它不是从时间步骤500到499再到498,而是能跳过所有这些时间步骤。它能跳过相当多,因为它打破了马尔可夫假设。
马尔可夫链只用于概率过程。但DDIM实际上从这个采样过程中移除了所有的随机性,因此它是确定性的。它本质上所做的就是预测最终输出的粗略草图,然后用去噪过程进行细化。
现在有了这种更快的采样方法(DDIM),你不会总是得到跟运行DDPM一样的质量水平。但这些实际上看起来相当不错。
从经验上看,人们发现,例如,对于一个在这500步骤上训练的模型,如果你采样500步,DDPM会表现得更好。但对于任何小于500步的数字,DDIM会做得更好。

总结
到此我们学习了扩散模型的基础知识。 现在,把所有内容汇总起来,你能够训练一个扩散模型来预测噪声,并且迭代地从纯噪声中减去预测噪声,以获得一幅好的图像。 你能够从那个训练过的神经网络中快速采样图像,而且还用了一个更高效的采样器,叫做DDIM。 你了解了模型架构,一个UNet。 你向模型中添加了上下文,这样你就能决定你是想要食物、魔法还是英雄精灵,或者介于两者之间的某种古怪的东西。扩散模型也不仅限于图像,那只是它们最受欢迎的领域。还有用于音乐的扩散模型,你可以给它任何提示并得到音乐,用于提出新分子以加速药物发现。 你还可以尝试一个更大的数据集,尝试一个新的采样器。 实际上有很多采样器比DDIM更快更好。 你能够用这些模型做更多事情,比如内画法,即让扩散模型在你已有的图片周围绘制一些东西,以及文本反演,它使模型能够只用几个样本图像捕捉一个全新的文本概念。 你在这里了解了基础知识,基础原理。 在这个领域还有其他重要的发展。 例如,稳定扩散使用了一种叫做潜在扩散的方法,它直接在图像嵌入上操作,而不是直接在图像上,使得过程更加高效。其他值得一提的酷炫方法包括交叉关注、文本条件化和无分类器引导。
研究社区仍在努力研究更快的采样方法,因为在推断时间上它仍然比其他生成模型慢。总而言之,这对扩散模型来说是一个极其激动人心的时期,因为它们作为一个整体生成模型,它们的应用变得越来越广泛。
参考资料和更多学习参考网页
文中图片来自于课程 https://learn.deeplearning.ai/courses/diffusion-models ,内容也来自于对该课程的学习。
关于扩散模型,更多学习可以参考下面网页:
https://huggingface.co/docs/diffusers/v0.17.0/en/api/schedulers/ddpm
https://huggingface.co/docs/diffusers/v0.17.0/en/index
What is Stable Diffusion? - Stable Diffusion AI Explained - AWS
相关文章:
Diffusion models(扩散模型) 是怎么工作的
前言 给一个提示词, Midjourney, Stable Diffusion 和 DALL-E 可以生成很好看的图片,那么它们是怎么工作的呢?它们都用了 Diffusion models(扩散模型) 这项技术。 Diffusion models 正在成为生命科学等领域的一项尖端技术&…...

查找回收站里隐藏的文件
在Windows里,每个磁盘分区都有一个隐藏的回收站Recycle, 回收站里保存着用户删除的文件、图片、视频等数据,比如,C盘的回收站为C:\RECYCLE.BIN\,D盘的的回收站为D:\RECYCLE.BIN\,E盘的的回收站为E:\RECYCLE…...

[运维]2.elasticsearch-svc连接问题
Serverless 与容器决战在即?有了弹性伸缩就不一样了 - 阿里云云原生 - 博客园 当我部署好elasticsearch的服务后,由于个人习惯,一般服务会在name里带上svc,所以我elasticsearch服务的名字是elasticsearch-svc: [root…...
Ajax面试题:(第一天)
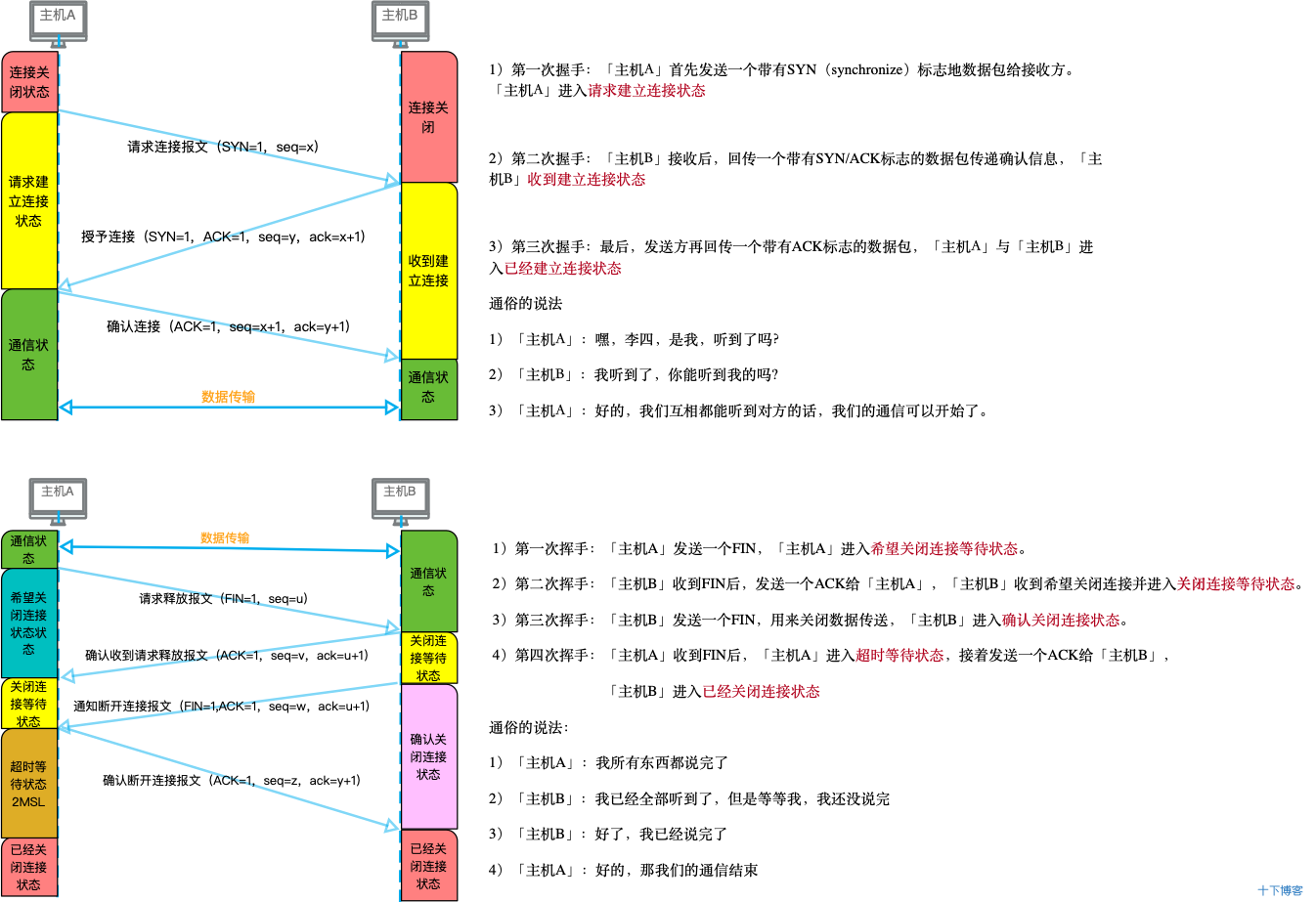
目录 1.说一下网络模型 2.在浏览器地址栏键入URL,按下回车之后会经历以下流程: 3.什么是三次握手和四次挥手? 4.http协议和https协议的区别 1.说一下网络模型 注:各层含义按自己理解即可 2.在浏览器地址栏键入URL,…...

数据仓库拉链表
数仓拉链表是数据仓库中常用的一种数据结构,用于记录维度表中某个属性的历史变化情况。在实际应用中,数仓拉链表可以帮助企业更好地进行数据分析和决策。 数仓拉链表(Slowly Changing Dimension, SCD)是一种用于处理维表中数据变化…...

【JVM】实战篇
1、内存调优 1.1 内存溢出和内存泄漏 内存泄漏(memory leak):在Java中如果不再使用一个对象,但是该对象依然在GC ROOT的引用链上,这个对象就不会被垃圾回收器回收,这种情况就称之为内存泄漏。 内存泄漏绝…...
)
2024年9月30日--10月6日(ue5肉鸽结束)
按照月计划,本周把ue肉鸽游戏完成,然后进行ue5太阳系 , 剩余14节,218分钟,如果按照10分钟的视频教程1小时进行完的话,则需要22小时,分布在10月2日-10月6日之间,每天44分钟的视频教程…...

【Python游戏开发】贪吃蛇游戏demo
准备步骤 项目开发使用【Mu 编辑器】 1.新建项目,并导入游戏图片 游戏编写 1.创建场景 SIZE 15 # 每个格子的大小 WIDTH SIZE * 30 # 游戏场景总宽度 HEIGHT SIZE * 30 # 游戏场景总高度def draw():screen…...

pytorch张量基础
引言张量的基础知识 张量的概念张量的属性张量的创建张量的操作 基本运算索引和切片形状变换自动微分 基本概念停止梯度传播张量的设备管理 检查和移动张量CUDA 张量高级操作 张量的视图广播机制分块和拼接张量的复制内存优化和管理 稀疏张量内存释放应用实例 线性回归神经网络…...

深入解析LlamaIndex Workflows【下篇】:实现ReAct模式AI智能体的新方法
之前我们介绍了来自LLM开发框架LlamaIndex的新特性:Workflows,一种事件驱动、用于构建复杂AI工作流应用的新方法(参考:[深入解析LlamaIndex Workflows:构建复杂RAG与智能体工作流的新利器【上篇】]。在本篇中ÿ…...

要在 Git Bash 中使用 `tree` 命令,下载并手动安装 `tree`。
0、git bash 安装 git(安装,常用命令,分支操作,gitee,IDEA集成git,IDEA集成gitee,IDEA集成github,远程仓库操作) 1、下载并手动安装 tree 下载 tree.exe 从 tree for Windows 官方站点 下载 tree 的 Windows 可执行文件。tree for Window:https://gnuwin32.source…...

Linux的基本指令(1)
前提: a:博主是在云服务器上进行操作的 b:windows上普通文件在Linux中也叫作普通文件,但是windows上的文件夹,在Linux中叫作目录 c:文件 文件内容 文件属性(创建时间,修改时间,…...

JavaEE之多线程进阶-面试问题
一.常见的锁策略 锁策略不是指某一个具体的锁,所有的锁都可以往这些锁策略中套 1.悲观锁与乐观锁 预测所冲突的概率是否高,悲观锁为预测锁冲突的概率较高,乐观锁为预测锁冲突的概率更低。 2.重量级锁和轻量级锁 从加锁的开销角度判断&am…...

费曼学习法没有输出对象怎么办?
费曼学习法并不需要输出对象。费曼学习法的核心在于通过将所学知识以简明易懂的方式解释给自己听,从而加深对知识的理解和记忆。这种方法强调的是理解和反思的过程,而不是简单地通过输出(如向他人解释)来检验学习效果。费曼学…...
)
Hive优化操作(二)
Hive 数据倾斜优化 在使用 Hive 进行大数据处理时,数据倾斜是一个常见的问题。本文将详细介绍数据倾斜的概念、表现、常见场景及其解决方案。 1. 什么是数据倾斜? 数据倾斜是指由于数据分布不均匀,导致大量数据集中到某个节点或任务中&…...

销冠的至高艺术:让自己不像销售
若想在销售领域脱颖而出,首先是让自己超越传统销售的框架,成为客户心中不可多得的行业顾问与信赖源泉。这不仅是身份的蜕变,更是影响力与信任度质的飞跃。 销冠对客户只吸引不骚扰,不讲自己卖什么,只讲自己能解决什么…...
)
Hive数仓操作(十一)
一、Hive 日期函数 在日常的数据处理工作中,日期和时间的处理是非常常见的操作。Hive 提供了丰富的日期函数,能够帮助我们方便地进行日期和时间的计算。本文将详细介绍 Hive 中常用的日期函数,并通过具体的示例展示其用法和结果。 1. 获取当…...

C语言初步介绍(初学者,大学生)【上】
1.C语⾔是什么? ⼈和⼈交流使⽤的是⾃然语⾔,如:汉语、英语、⽇语 那⼈和计算机是怎么交流的呢?使⽤ 计算机语⾔ 。 ⽬前已知已经有上千种计算机语⾔,⼈们是通过计算机语⾔写的程序,给计算机下达指令&am…...

陈文自媒体:现在的房价,已经跌到7年前!
今年的国庆北上广深都放开了政策,很多人都放弃旅游去看房了,现在的全民都有一个基本意识,现在的房子已经到了谷底,从各大政策就可以看出来,稍微有点钱的可以出手买房了。 昨天我哥跟我说,现在xx地方的房子…...

基于STM32的智能水族箱控制系统设计
引言 本项目基于STM32微控制器设计一个智能水族箱控制系统。该系统能够通过传感器监测水温、照明和水位,并自动控制加热器、LED灯和水泵,确保水族箱内的环境适宜鱼类生长。该项目展示了STM32在环境监测、设备控制和智能反馈系统中的应用。 环境准备 1…...

别再手动配置时钟树了!用STM32CubeMX 6.10 + Keil MDK 5分钟搞定LED闪烁工程
5分钟极速开发:STM32CubeMX图形化工具颠覆传统嵌入式开发模式 第一次接触STM32开发时,面对密密麻麻的寄存器手册和复杂的时钟树配置,我花了整整三天才让一个LED灯闪烁起来。直到发现STM32CubeMX这个神器——它彻底改变了嵌入式开发的入门门槛…...

如何用茉莉花插件实现Zotero中文文献元数据一键抓取:终极解决方案
如何用茉莉花插件实现Zotero中文文献元数据一键抓取:终极解决方案 【免费下载链接】jasminum A Zotero add-on to retrive CNKI meta data. 一个简单的Zotero 插件,用于识别中文元数据 项目地址: https://gitcode.com/gh_mirrors/ja/jasminum 还在…...

FakeLocation:安卓应用级位置模拟终极解决方案
FakeLocation:安卓应用级位置模拟终极解决方案 【免费下载链接】FakeLocation Xposed module to mock locations per app. 项目地址: https://gitcode.com/gh_mirrors/fak/FakeLocation 在数字时代,位置隐私已成为每个Android用户必须面对的重要问…...

企业出海聘用海外员工该怎么挑选靠谱名义雇主服务商?
很多企业出海初期,都会卡在海外员工聘用这一步:没有海外实体,没法合法签合同、缴社保,想找名义雇主服务商,又怕选到不靠谱的,踩坑又不合规。结合我这几年帮出海企业对接服务商的经验,今天不玩虚…...
)
别再只会显示字符了!用51单片机和OLED做个简易电子时钟(IIC协议详解)
从零构建51单片机OLED电子时钟:IIC协议深度解析与项目实战 在嵌入式开发领域,51单片机因其稳定性和易用性始终占据一席之地。当基础的点亮OLED屏幕、显示静态文字已经无法满足你的求知欲时,一个融合硬件协议、实时时钟和UI设计的电子时钟项目…...

从ASCII到机器码:深入解析HEX文件的结构与校验机制
1. HEX文件的前世今生:从ASCII到机器码的桥梁 第一次接触HEX文件时,我也被那一串串看似毫无规律的十六进制字符搞得一头雾水。直到后来在嵌入式开发中频繁使用HEX文件进行固件升级,才真正理解了这个"翻译官"的重要性。HEX文件本质上…...

自行车轮POV显示:基于视觉暂留与微控制器的DIY空中光绘
1. 项目概述:在车轮上“画”出光之画卷几年前,我第一次在夜间的公园里看到一辆飞驰而过的自行车,它的轮辐间竟然清晰地显示着一行发光的文字和图案,那种瞬间的震撼感至今难忘。那不是魔法,而是视觉暂留原理与微控制器精…...
)
告别adb命令行:用C++和libusb手撸一个USB调试工具(附完整源码)
告别adb命令行:用C和libusb手撸一个USB调试工具(附完整源码) 你是否厌倦了反复敲击adb命令,却对背后的USB通信机制充满好奇?本文将带你深入Android调试桥(ADB)的底层世界,用C和libus…...

5分钟快速上手Ketcher:免费开源的Web分子绘图神器
5分钟快速上手Ketcher:免费开源的Web分子绘图神器 【免费下载链接】ketcher Web-based molecule sketcher 项目地址: https://gitcode.com/gh_mirrors/ke/ketcher Ketcher是一款功能强大的开源化学绘图工具,专为化学家、生物学家和研究人员设计。…...
)
终极指南:如何快速将AIO Sandbox与主流AI框架集成(LangChain、OpenAI Assistant等)
终极指南:如何快速将AIO Sandbox与主流AI框架集成(LangChain、OpenAI Assistant等) 【免费下载链接】sandbox All-in-One Sandbox for AI Agents that combines Browser, Shell, File, MCP and VSCode Server in a single Docker container. …...