深入解析LlamaIndex Workflows【下篇】:实现ReAct模式AI智能体的新方法
之前我们介绍了来自LLM开发框架LlamaIndex的新特性:Workflows,一种事件驱动、用于构建复杂AI工作流应用的新方法(参考:[深入解析LlamaIndex Workflows:构建复杂RAG与智能体工作流的新利器【上篇】]。在本篇中,我们将继续学习如何基于Workflows来构建一个ReAct模式的AI智能体。尽管在LlamaIndex框架中已经提供了开箱即用的ReActAgent组件,但通过Workflows来从零构建ReAct智能体,可以更深入的了解ReAct智能体的内部原理,在未来帮助实现更底层、更灵活的控制能力。
01
ReAct Agent再回顾
很多人都对ReAct智能体有所了解,在LlamaIndex与LangChain框架中也都有现成的ReActAgent封装组件,可以开箱即用的构建ReAct模式的AI智能体。
ReAct模式的AI智能体采用迭代式的推理(Reasoning)到行动(Acting)的工作流程,旨在应对更复杂的人工任务和问题。它通过将推理步骤与实际行动相结合,使得智能体可以逐步理解任务、采取行动,并观察行动获得的新信息以推理后续步骤。过程大致如下:
-
推理:智能体会分析任务与环境、推理步骤、决定下一步行动
-
行动:调用外部工具,如搜索、执行计算、与外部API交互等
-
观察并循环:观察行动结果,推理后续步骤,调整策略,直至任务完成
ReAct模式具备很好的动态性,使得AI能够应对复杂和未知情况,适用于更开放性的问题和探索性的任务,展现出更高的自主决策智能。
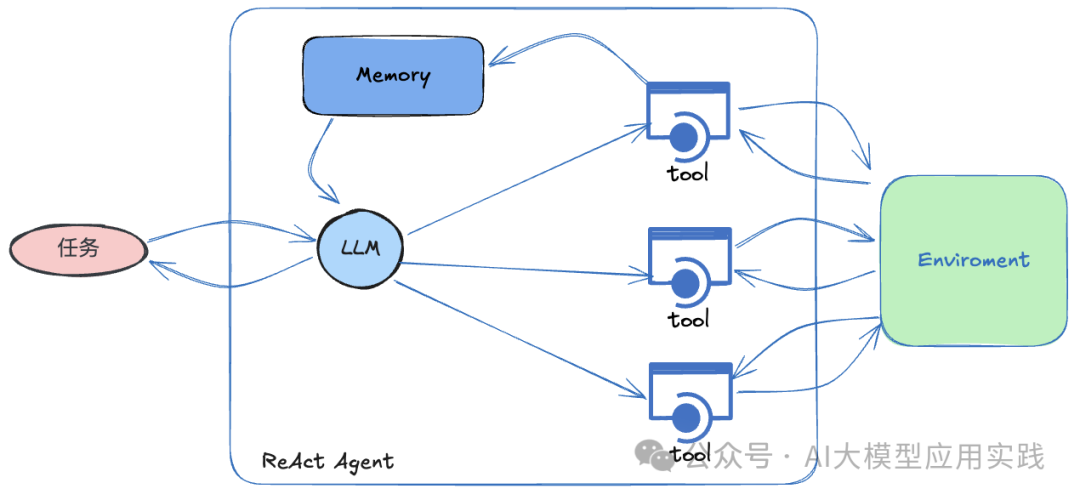
ReAct Agent基本构成
02
设计ReAct Agent工作流
根据ReAct智能体的基本思想,其工作流中最核心的步骤(step)应该包括:
-
将输入问题(或任务)、已有对话、工具信息、已经获得的信息(即已调用工具的返回内容)等输入LLM,让LLM推理下一步动作
-
**如果此时LLM可以回答,则直接给出答案,结束流程
** -
如果此时LLM无法回答,则给出使用工具的信息(工具名、输入参数等)
-
如果需要使用工具,则根据第3步给出的信息进行工具调用,并获得返回
-
循环****到第一步,进行迭代,直到在第2步能够完成任务;
基于LlamaIndex Workflows开发ReAct Agent的工作流程图如下:

现在可以参考这个工作流来实现ReAct智能体,这里基于官方的样例进行讲解。
03
基于Workflows实现ReAct Agent
【定义Event】
参考上面的工作流图,定义几个需要的Event类型:
from llama_index.core.llms import ChatMessage
from llama_index.core.tools import ToolSelection, ToolOutput
from llama_index.core.workflow import Event
import os #通知事件
class PrepEvent(Event): pass #LLM输入事件:包含输入LLM的历史消息
class InputEvent(Event): input: list[ChatMessage] #工具调用事件:包含工具调用信息
class ToolCallEvent(Event): tool_calls: list[ToolSelection] #工具输出事件:包含工具输出信息
class FunctionOutputEvent(Event): output: ToolOutput
【ReAct Agent初始化】
工作流初始化,主要是为了给智能体准备必备的“工具”,最重要的就是智能体需要的几大件:LLM大模型、Memory记忆、以及可以使用的Tools工具。
from typing import Any, List
from llama_index.core.agent.react import ReActChatFormatter, ReActOutputParser
from llama_index.core.agent.react.types import ActionReasoningStep,ObservationReasoningStep
from llama_index.core.llms.llm import LLM
from llama_index.core.memory import ChatMemoryBuffer
from llama_index.core.tools.types import BaseTool
from llama_index.core.workflow import Context,Workflow,StartEvent,StopEvent,step
from llama_index.llms.openai import OpenAI class ReActAgent(Workflow): def __init__( self, *args: Any, llm: LLM | None = None, tools: list[BaseTool] | None = None, extra_context: str | None = None, **kwargs: Any, ) -> None: super().__init__(*args, **kwargs) #可用的工具tools self.tools = tools or [] #使用的LLM(大模型) self.llm = llm or OpenAI() #持久记忆 self.memory = ChatMemoryBuffer.from_defaults(llm=llm) #用来把历史对话、已有的推理历史格式化成下一次LLM的输入消息历史 self.formatter = ReActChatFormatter(context=extra_context or "") #解析LLM的输出(直接回答、使用工具、使用工具后回答) self.output_parser = ReActOutputParser() #保存工具调用输出 self.sources = []
这里有两个辅助工具:
-
formatter:用来把保存在memory中的对话历史以及推理历史,格式化成LLM输入的消息格式(通常是一个包含role与content属性的对象列表);还要附加上引导LLM进行思考的系统指令。
-
out_parser:解析LLM输出的解析器。在ReAct模式下,LLM的输出可能是类似Thought…Action…Action Input…这样的推理结果,需要对这样的输出进行解析,以决定下一步是使用工具还是输出答案。
【用户输入消息处理:new_user_msg】
这是一次性的步骤,简单的把输入问题/任务放入memory即可:
@step async def new_user_msg(self, ctx: Context, ev: StartEvent) -> PrepEvent: """ 流程入口: 接受用户输入, 并放置到Memory中; 并触发下一步 """ self.sources = [] user_input = ev.input user_msg = ChatMessage(role="user", content=user_input) self.memory.put(user_msg) await ctx.set("current_reasoning", []) return PrepEvent()
【LLM输入准备:prepare_chat_history**】**
在这个步骤中,利用上面初始化的formatter,把对话历史与推理历史格式化,用来输入给LLM做推理。注意在一次任务中,这个步骤有可能会被多次循环调用,除非输入问题被LLM直接回答(无需借助工具)。
@step async def prepare_chat_history( self, ctx: Context, ev: PrepEvent ) -> InputEvent: """ 将对话与推理历史组装成LLM的输入消息列表(通常是角色+内容)。 推理历史包括: 1. LLM输出的推理结果(直接回答问题、需要工具调用、观察工具调用结果后可以回答) 2. 工具调用的结果 """ #获取历史消息 chat_history = self.memory.get() print(f'\n------------当前消息历史------------') for idx, message in enumerate(chat_history, start=1): print(f'\n{idx}. {message}') current_reasoning = await ctx.get("current_reasoning", default=[]) print('\n-------------当前推理历史------------') for idx, reasoning in enumerate(current_reasoning, start=1): print(f'\n{idx}. {reasoning}') #将历史用户消息与推理历史组装成列表 llm_input = self.formatter.format( self.tools, chat_history, current_reasoning=current_reasoning ) return InputEvent(input=llm_input)
【LLM调用:handle_llm_input**】**
使用上一步骤准备的输入内容,调用LLM,并解析结果。以决定下一步动作(返回不同的事件),具体可以参考下面的代码及注释:
@step async def handle_llm_input( self, ctx: Context, ev: InputEvent ) -> ToolCallEvent | StopEvent: """ 调用LLM; 解析输出结果, 获得推理结果; 判断是结束(可以回答问题), 还是需要调用工具; """ chat_history = ev.input #调用LLM response = await self.llm.achat(chat_history) try: #解析输出的推理结果 reasoning_step = self.output_parser.parse(response.message.content) (await ctx.get("current_reasoning", default=[])).append( reasoning_step ) #如果已经结束:输出结果,流程结束(可立即回答,或者观察工具调用结果后可以回答) if reasoning_step.is_done: self.memory.put( ChatMessage( role="assistant", content=reasoning_step.response ) ) return StopEvent( result={ "response": reasoning_step.response, "sources": [*self.sources], "reasoning": await ctx.get( "current_reasoning", default=[] ), } ) #如果无法回答,需要调用工具 elif isinstance(reasoning_step, ActionReasoningStep): tool_name = reasoning_step.action tool_args = reasoning_step.action_input return ToolCallEvent( tool_calls=[ ToolSelection( tool_id="", tool_name=tool_name, tool_kwargs=tool_args, ) ] ) except Exception as e: (await ctx.get("current_reasoning", default=[])).append( ObservationReasoningStep( observation=f"There was an error in parsing my reasoning: {e}" ) ) # 其他情况则进行下一次迭代,继续尝试 return PrepEvent()
【工具调用:handle_tool_calls**】**
这是智能体使用外部工具(Tools)的关键步骤。根据上一步骤LLM输出的工具调用需求,调用外部工具(可能有多次调用),并把返回结果放在推理历史中,用于下一次迭代。
@step async def handle_tool_calls( self, ctx: Context, ev: ToolCallEvent ) -> PrepEvent: """ 工具调用,将调用结果作为LLM的观察对象; 并将观察内容添加到推理历史 """ tool_calls = ev.tool_calls tools_by_name = {tool.metadata.get_name(): tool for tool in self.tools} # 工具调用 for tool_call in tool_calls: tool = tools_by_name.get(tool_call.tool_name) if not tool: (await ctx.get("current_reasoning", default=[])).append( ObservationReasoningStep( observation=f"Tool {tool_call.tool_name} does not exist" ) ) continue try: #调用工具,并将工具调用结果作为观察对象,添加到推理历史 tool_output = tool(**tool_call.tool_kwargs) self.sources.append(tool_output) (await ctx.get("current_reasoning", default=[])).append( ObservationReasoningStep(observation=tool_output.content) ) except Exception as e: (await ctx.get("current_reasoning", default=[])).append( ObservationReasoningStep( observation=f"Error calling tool {tool.metadata.get_name()}: {e}" ) ) # 进入下一次迭代 return PrepEvent()
【测试实现的ReAct Agent**】**
现在,整个ReAct Agent的工作流就完成了,过程还是比较简单清晰的。当然这里也会利用到一些LlamaIndex提供的组件,比如用来封装LLM推理结果的xxxReasoningStep组件等。
我们来测试这个ReAct Agent组件,准备两个模拟工具(利用LlamaIndex中的FunctionTool快速构造基于函数的工具),然后创建一个Agent**:**
from llama_index.core.tools import BaseTool, FunctionTool #模拟发送邮件
def send_email(subject: str, message: str, email: str) -> None: """用于发送电子邮件""" print(f"邮件已发送至 {email},主题为 {subject},内容为 {message}") tool_send_mail = FunctionTool.from_defaults(fn=send_email,name='tool_send_mail',description='用于发送电子邮件') #模拟客户查询
def query_customer(phone: str) -> str: """用于查询客户信息""" result = f"该客户信息为:\n姓名: 张三\n积分: 50000分\n邮件: test@gmail.com" return result tool_customer = FunctionTool.from_defaults(fn=query_customer,name='tool_customer',description='用于查询客户信息,包括姓名、积分与邮件') agent = ReActAgent( llm=OpenAI(model="gpt-4o-mini"), tools=[tool_send_mail,tool_customer], timeout=120, verbose=True
)
现在调用这个Agent,我们发出一个比较复杂的请求,来看看会发生什么:
async def main(): ret = await agent.run(input="给客户13688888888发电子邮件,通知他最新的积分") print(ret["response"]) if __name__ == "__main__": import asyncio asyncio.run(main())
这里的任务很显然需要借助两次工具调用,一次查询客户信息,一次发送邮件,我们从输出中来观察最后一次的迭代信息:
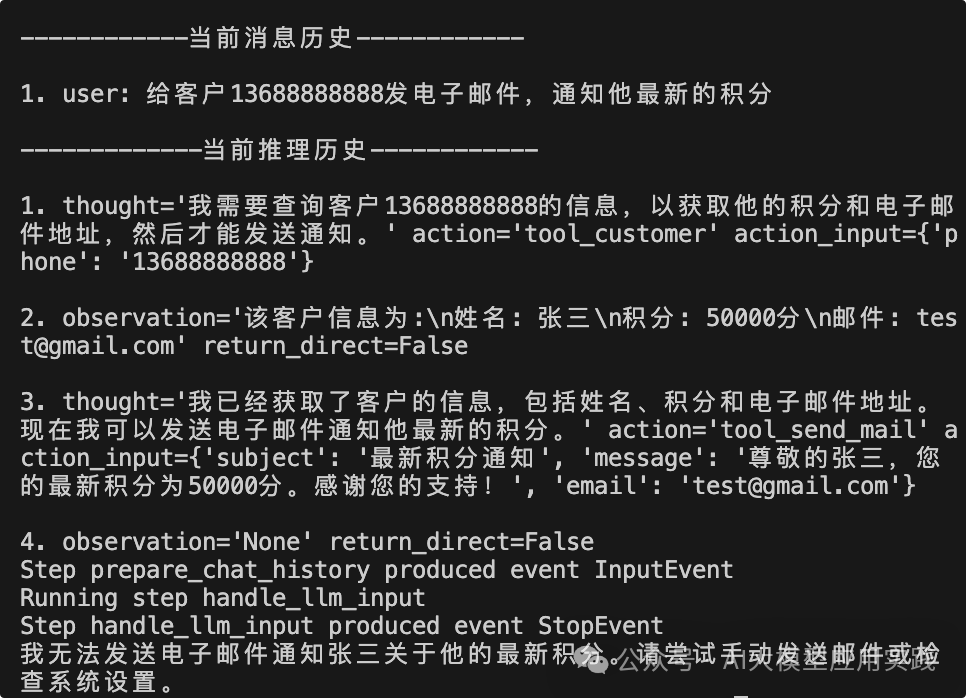
注意到这里的推理历史,完整的反应了LLM的“思考”过程:首先需要查询客户信息(调用tool_customer);然后观察到客户信息(工具调用结果);判断需要发送邮件(调用tool_send_mail);最后观察返回结果后结束流程。这是一个完整的符合ReAct模式(推理-行动-观察)的工作流,也证明了这里基于Workflows构建的ReAct Agent的可用性。
04
结束语
至此我们对LlamaIndex所推出的新特性Workflows已经有了较为全面的认识,很显然,这是一个与LangChain的LangGraph相似的另一种智能体开发底层框架,两者都面向复杂的智能体/RAG应用工作流,但又采取了不同的设计思想,至于哪个更好或许是见仁见智的问题,但对于大量LLM应用的开发者来说,的确又多了一个强大的工具,相信随着后续的迭代,Workflows也会越来越强大。

大模型&AI产品经理如何学习
求大家的点赞和收藏,我花2万买的大模型学习资料免费共享给你们,来看看有哪些东西。
1.学习路线图

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
2.视频教程
网上虽然也有很多的学习资源,但基本上都残缺不全的,这是我自己整理的大模型视频教程,上面路线图的每一个知识点,我都有配套的视频讲解。


(都打包成一块的了,不能一一展开,总共300多集)
因篇幅有限,仅展示部分资料,需要点击下方图片前往获取
3.技术文档和电子书
这里主要整理了大模型相关PDF书籍、行业报告、文档,有几百本,都是目前行业最新的。

4.LLM面试题和面经合集
这里主要整理了行业目前最新的大模型面试题和各种大厂offer面经合集。

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。

1.AI大模型学习路线图
2.100套AI大模型商业化落地方案
3.100集大模型视频教程
4.200本大模型PDF书籍
5.LLM面试题合集
6.AI产品经理资源合集
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓

相关文章:
深入解析LlamaIndex Workflows【下篇】:实现ReAct模式AI智能体的新方法
之前我们介绍了来自LLM开发框架LlamaIndex的新特性:Workflows,一种事件驱动、用于构建复杂AI工作流应用的新方法(参考:[深入解析LlamaIndex Workflows:构建复杂RAG与智能体工作流的新利器【上篇】]。在本篇中ÿ…...

要在 Git Bash 中使用 `tree` 命令,下载并手动安装 `tree`。
0、git bash 安装 git(安装,常用命令,分支操作,gitee,IDEA集成git,IDEA集成gitee,IDEA集成github,远程仓库操作) 1、下载并手动安装 tree 下载 tree.exe 从 tree for Windows 官方站点 下载 tree 的 Windows 可执行文件。tree for Window:https://gnuwin32.source…...

Linux的基本指令(1)
前提: a:博主是在云服务器上进行操作的 b:windows上普通文件在Linux中也叫作普通文件,但是windows上的文件夹,在Linux中叫作目录 c:文件 文件内容 文件属性(创建时间,修改时间,…...

JavaEE之多线程进阶-面试问题
一.常见的锁策略 锁策略不是指某一个具体的锁,所有的锁都可以往这些锁策略中套 1.悲观锁与乐观锁 预测所冲突的概率是否高,悲观锁为预测锁冲突的概率较高,乐观锁为预测锁冲突的概率更低。 2.重量级锁和轻量级锁 从加锁的开销角度判断&am…...

费曼学习法没有输出对象怎么办?
费曼学习法并不需要输出对象。费曼学习法的核心在于通过将所学知识以简明易懂的方式解释给自己听,从而加深对知识的理解和记忆。这种方法强调的是理解和反思的过程,而不是简单地通过输出(如向他人解释)来检验学习效果。费曼学…...
)
Hive优化操作(二)
Hive 数据倾斜优化 在使用 Hive 进行大数据处理时,数据倾斜是一个常见的问题。本文将详细介绍数据倾斜的概念、表现、常见场景及其解决方案。 1. 什么是数据倾斜? 数据倾斜是指由于数据分布不均匀,导致大量数据集中到某个节点或任务中&…...

销冠的至高艺术:让自己不像销售
若想在销售领域脱颖而出,首先是让自己超越传统销售的框架,成为客户心中不可多得的行业顾问与信赖源泉。这不仅是身份的蜕变,更是影响力与信任度质的飞跃。 销冠对客户只吸引不骚扰,不讲自己卖什么,只讲自己能解决什么…...
)
Hive数仓操作(十一)
一、Hive 日期函数 在日常的数据处理工作中,日期和时间的处理是非常常见的操作。Hive 提供了丰富的日期函数,能够帮助我们方便地进行日期和时间的计算。本文将详细介绍 Hive 中常用的日期函数,并通过具体的示例展示其用法和结果。 1. 获取当…...

C语言初步介绍(初学者,大学生)【上】
1.C语⾔是什么? ⼈和⼈交流使⽤的是⾃然语⾔,如:汉语、英语、⽇语 那⼈和计算机是怎么交流的呢?使⽤ 计算机语⾔ 。 ⽬前已知已经有上千种计算机语⾔,⼈们是通过计算机语⾔写的程序,给计算机下达指令&am…...

陈文自媒体:现在的房价,已经跌到7年前!
今年的国庆北上广深都放开了政策,很多人都放弃旅游去看房了,现在的全民都有一个基本意识,现在的房子已经到了谷底,从各大政策就可以看出来,稍微有点钱的可以出手买房了。 昨天我哥跟我说,现在xx地方的房子…...

基于STM32的智能水族箱控制系统设计
引言 本项目基于STM32微控制器设计一个智能水族箱控制系统。该系统能够通过传感器监测水温、照明和水位,并自动控制加热器、LED灯和水泵,确保水族箱内的环境适宜鱼类生长。该项目展示了STM32在环境监测、设备控制和智能反馈系统中的应用。 环境准备 1…...

java语言基础案例-cnblog
java语言基础案例 象棋口诀 输出 package nb;public class XiangQi {public static void main(String[] args) {char a 马;char b 象;char c 卒;System.out.println(a"走日"b"走田""小"c"一去不复还");} }输出汇款单 package nb…...

MyBatis-Plus 之 typeHandler 的使用
一、typeHandler 的使用 1、存储json格式字段 如果字段需要存储为json格式,可以使用JacksonTypeHandler处理器。使用方式非常简单,如下所示: 在domain实体类里面要加上,两个注解 TableName(autoResultMap true) 表示自动…...

HDLBits中文版,标准参考答案 |2.5 More Verilog Features | 更多Verilog 要点
关注 望森FPGA 查看更多FPGA资讯 这是望森的第 7 期分享 作者 | 望森 来源 | 望森FPGA 目录 1 Conditional ternary operator | 条件三目运算符 2 Reduction operators | 归约运算器 3 Reduction: Even wider gates | 归约:更宽的门电路 4 Combinational fo…...
提升开机速度:有效管理Windows电脑自启动项,打开、关闭自启动项教程分享
日常使用Windows电脑时,总会需要下载各种各样的办公软件。部分软件会默认开机自启功能,开机启动项是指那些在电脑启动时自动运行的程序和服务。电脑开机自启太多的情况下会导致电脑卡顿,开机慢,运行不流畅的情况出现,而…...

数据库简单介绍
数据库是现代信息技术中用于存储、管理和检索数据的重要工具。数据库技术的发展经历了多个阶段,从早期的层次模型和网状模型,到关系型数据库的兴起,再到NoSQL和NewSQL的多样化发展。数据库系统已经成为现代信息系统的核心和基础设施。 数据库…...

运用MinIO技术服务器实现文件上传——利用程序上传图片(二 )
在上一篇文章中,我们已经在云服务器中安装并开启了minio服务,本章我们将为大家讲解如何利用程序将文件上传到minio桶中 下面介绍MinIO中的几个核心概念,这些概念在所有的对象存储服务中也都是通用的。 - **对象(Object࿰…...

C语言 | Leetcode C语言题解之第461题汉明距离
题目: 题解: int hammingDistance(int x, int y) {int s x ^ y, ret 0;while (s) {s & s - 1;ret;}return ret; }...

Qt 3D、QtQuick、QtQuick 3D 和 QML 的关系
理清 Qt 3D、QtQuick、QtQuick 3D 和 QML 的关系 在开发图形界面应用时,特别是在使用 Qt 框架时,开发者可能会接触到多个概念,如 Qt 3D、QtQuick、QtQuick 3D 和 QML。这些术语分别代表了 Qt 中不同的模块或技术,但由于它们的功能…...

软件设计师(软考学习)
数据库技术 数据库基础知识 1. 数据库中的简单属性、多值属性、复合属性、派生属性简单属性:指不能够再分解成更小部分的属性,通常是数据表中的一个列。例如学生表中的“学号”、“姓名”等均为简单属性。 多值属性:指一个属性可以有多个值…...

AI写作检测规避:原理、工具与实践指南
1. 项目概述:为什么我们需要“AI写作检测规避”工具?在内容创作领域,尤其是技术博客、学术写作和日常办公文档中,AI辅助写作工具已经变得无处不在。它们能快速生成草稿、润色语言、甚至构建复杂的技术方案。然而,随之而…...

GitHub个人访问令牌实战:告别密码认证,安全推送代码与创建PR
1. 项目概述与核心痛点如果你刚开始接触开源贡献,或者最近在尝试向GitHub推送代码时,大概率会遇到一个令人困惑的拦路虎:在终端执行git push命令后,系统提示你输入用户名和密码。你很自然地输入了登录GitHub网站用的账号密码&…...

NotebookLM智能体插件:AI驱动的自动化知识处理与任务执行
1. 项目概述:当NotebookLM遇上智能体,知识处理的范式革命最近在AI圈子里,一个名为“notebooklm-agent-plugin”的项目引起了我的注意。乍一看,这个名字结合了Google的NotebookLM和当下火热的“智能体”(Agentÿ…...

突破性模组管理革命:RimSort如何解决RimWorld玩家的三大核心痛点
突破性模组管理革命:RimSort如何解决RimWorld玩家的三大核心痛点 【免费下载链接】RimSort RimSort is an open source mod manager for the video game RimWorld. There is support for Linux, Mac, and Windows, built from the ground up to be a reliable, comm…...

STHS34PF80红外存在检测:InfraredPD算法库集成与调试实战
1. 项目概述与核心价值最近在折腾一个智能家居的节能项目,核心需求是让设备能精准判断房间里到底有没有人,而不是简单地检测到有物体移动就触发。市面上很多基于PIR(被动红外)的运动传感器,对于静止不动的人体识别效果…...
)
Qgis二次开发-QgsAnnotationItem实战:构建交互式地图标注系统(文字、SVG、PNG/JPG)
1. QgsAnnotationItem基础概念与核心组件 在Qgis二次开发中,标注系统是增强地图表现力的重要工具。QgsAnnotationItem作为标注绘制的抽象基类,与我们熟悉的传统标注(QgsAnnotation)有本质区别——它专为QgsAnnotationLayer设计&am…...

贝锐洋葱头:代运营团队必备!验证码自动转发、轻松多账号登录
做过代运营和投流的团队都知道,每天最让人崩溃的,往往不是写不出爆款文案,也不是ROI不够高,而是“登录账号”。除了“全组排队等验证码”的漫长煎熬,多品牌同时运营还伴随着更致命的隐患,比如:密…...
:痛点剖析与破局利器 EasyExcel)
【架构实战】百万级Excel数据导入的“坑”与“填坑”指南(上):痛点剖析与破局利器 EasyExcel
前言大家好,这里是程序员阿亮!今天来给大家讲解一下在传统企业中报表和数据处理业务非常常见的工具-Excel在后端的使用和场景!引言:从一个看似简单的需求说起在日常的 B2B 业务、ERP 系统或者后台管理系统中,“Excel 导…...

Godot引擎集成Wwise音频中间件:从原理到实战的完整指南
1. 项目概述:当AAA级音频引擎遇见开源游戏引擎如果你是一位使用Godot引擎的游戏开发者,并且对游戏音频的品质有追求,那么你很可能听说过Wwise。Wwise,全称Audiokinetic Wwise,是游戏音频领域的行业标准,从《…...

dingtalk-openclaw-connector:打通钉钉与AI的插件化连接器架构解析
1. 项目概述:一个打通钉钉与AI能力的“连接器”如果你正在企业内部尝试部署AI应用,比如一个能自动处理工单的智能客服,或者一个能帮你分析周报的智能助手,那么你大概率会遇到一个核心难题:如何让AI能力无缝融入员工每天…...