【MySQL 08】复合查询
目录
1.准备工作
2.多表查询
笛卡尔积
多表查询案例
3. 自连接
4.子查询
1.单行子查询
2.多行子查询
3.多列子查询
4.在from子句中使用子查询
5.合并查询
1.union
2.union all
1.准备工作
如下三个表,将作为示例,理解复合查询
- EMP员工表
- DEPT部门表
- SALGRADE工资等级表






2.多表查询
实际开发中往往数据来自不同的表,所以需要多表查询。本节我们用一个简单的公司管理系统,有三张表EMP,DEPT,SALGRADE来演示如何进行多表查询。进行多表查询时,表与表就会进行笛卡尔积。
笛卡尔积
什么是笛卡尔积:
数学上,有两个集合A={a,b},B={1,2,3},则两个集合的笛卡尔积={{a,1}, {a,2}, {a,3}, {b,1}, {b,2}, {b,3}} 列出所有情况,一共是2*3=6条记录;在数据库中,笛卡尔积是多表查询没有连接条件时返回的表结果。
笛卡尔积的元素是元组,关系A和关系B的笛卡尔积可以记为(AXB),如果A表a条,B表为b条,那么A和B的笛卡尔积为(a+b)列数,有(a*b)行的元素集合。检索出来的条目是将第一个表中的行数乘以第二个表中的行数。
避免全笛卡尔积 :在 where 加入有效的连接条件;
消除笛卡尔积:使用等值连接和非等值连接;
例子:
显示雇员名、雇员工资以及所在部门的名字因为上面的数据来自EMP和DEPT表,因此要联合查询
对部分结果截取,由于两张表进行了笛卡尔积,任意一种可能都是存在的,我们可以看到SMITH时20部门的,但是给他拼接了其它部门的信息,这显然是没有意义的,所以我们在进行笛卡尔积的时候是要加过滤条件的。
我们需要通过员工的部门号与对应的部门做关联,这才是正确的。这其实就有点像员工表中的外键,与部门表中的主键做关联。现在两张表就有效的合成了一张表,这张表的信息肯定是准确无误的,我们可以对这张大表多增删查改。
多表查询案例
1.显示雇员名、雇员工资以及所在部门的名字
雇员名、雇员工资是存在于emp表中的,二所在部门存在于dept表中的,因此我们要同时对emp表和dept进行查询。
select emp.ename, emp.sal, dept.dname: 这部分指定了查询的结果应该包含哪些列。from emp, dept: 这部分指定了查询将要使用的表。在这个例子中,它指定了两个表:emp和dept。注意,这里使用的是表的直接连接(也称为笛卡尔积),但实际的连接条件在WHERE子句中给出。where emp.deptno = dept.deptno: 这是查询的关键部分,它指定了两个表之间的连接条件。这里,它要求emp表中的deptno字段(雇员所属的部门编号)必须与dept表中的deptno字段(部门编号)相匹配。
2.显示部门号为10的部门名,员工名和工资
在上一题的基础上多给个条件就行了。
3.显示各个员工的姓名,工资,及工资级别
姓名和薪资属于emp表,而工资级别属于salgrade表,所以要对两表做笛卡尔积,但薪资要在薪资对应等级的范围内,不然就是错误关系。






3. 自连接
自连接是指在同一张表连接查询,即自己与自己做笛卡尔积。在自连接中要,要取别名才可以。
自连接在处理需要比较表中记录之间的关系时非常有用。例如,你可能有一个包含员工信息的表,并希望找到每个员工的直接上级或下级。例子:
显示员工 FORD 的上级领导的编号和姓名
第一步先筛选出,在自连接表中与FORD有关的信息。
select * from emp e1,emp e2 where e1.ename='FORD';
第二步,我们知道要的不是FORD的信息,而是需要看到它领导的信息。因此我们可以用FORD领导的编号找到它领导的信息。
select * from emp e1,emp e2 where e1.ename='FORD' and e1.mgr=e2.empno;
第三步,我们只需要领导的编号和姓名,那么我们在第二步的基础上,选出我们需要的信息就好了



4.子查询
子查询是指嵌入在其他sql语句中的select语句,也叫嵌套查询
1.单行子查询
该子查询返回的是单行单列的数据,即一个格子
例子:显示SMITH同一部门的员工
那么首先我们就要找出SMITH的部门号,返回的是一个格子。
然后就用SMITH返回的部门号查找同一部门的员工
2.多行子查询
该子查询返回的是多行但是单列的数据
例子:
1.查询和10号部门的工作岗位相同的雇员的名字,岗位,工资,部门号,但是不包含10自己的
先找出10号部门的工作岗位,这里对工作岗位一般会用到去重操作
然后我们将此作为子查询条件,这里会用到in关键字,只要是上面三种岗位其中一个的就符合筛选条件,当然除10号部门以外的员工。
2.显示工资比部门30的所有员工的工资高的员工的姓名、工资和部门号
这里我们子查询条件就是30号部门所有的工资,可以对该结果去重。
然后,我们要用到all关键字,工资大于30号部门所有工资的员工,就筛选出来。(当然也可以用大于30号最高工资的方法进行筛选,而不是用all关键字)
3.显示工资比部门30的任意员工的工资高的员工的姓名、工资和部门号(包含自己部门
的员工)
这里把all关键字换成any关键字就可以了(当然也可以用大于30号最低工资的方法进行筛选,而不是用any关键字)
3.多列子查询
该子查询返回的是多列但是单行的数据
例子:
查询和SMITH的部门和岗位完全相同的所有雇员,不含SMITH本人
那么首先就要查询SMITH的部门和岗位
然后,只要筛选出deptno和job,与SMITH完全一样的就可以了。
4.在from子句中使用子查询
你可以在
FROM子句中使用子查询来创建一个临时表或派生表。这个临时表在查询的执行期间存在,并且你可以像对待普通表一样对它进行操作,包括选择列、应用过滤条件以及与其他表进行笛卡尔积。这也就是MySQL中一切皆表的思想,只不过在from中使用子查询,所得的临时表要取别名使用。
例子:
1.显示每个高于自己部门平均工资的员工的姓名、部门、工资、平均工资
首先获取各个部门的平均工资,将其看作临时表我们需要部门的平均工资和部门号,我们不存在这种表,因此只能构建临时表。然后通过此表,与员工表做笛卡尔积,筛选出我们需要的数据就可以了。
2.显示每个部门的信息(部门名,编号,地址)和人员数量
使用多表查询方法:统计每个部门的人数,并同时返回部门的名称(
dname)、部门编号(deptno)和位置(loc)。这个查询使用了EMP(员工)表和DEPT(部门)表。并通过
EMP.deptno=DEPT.deptno条件将它们连接起来。然后,它按部门编号、部门名称和部门位置进行分组,并使用count(*)函数来计算每个组中的记录数(即每个部门的人数)。
使用子查询方法:
先查询出每个部门人员数量、部门编号。
一上面查询结果作为临时表,与部门表做笛卡尔积,筛选出符合条件的情况。














5.合并查询
在实际应用中,为了合并多个select的执行结果,可以使用集合操作符 union,union all
union操作符用于取得两个结果集的并集。当使用该操作符时,会自动去掉结果集中的重复行。union all操作符用于取得两个结果集的并集。当使用该操作符时,不会去掉结果集中的重复行。1.union
案例:将工资大于25000或职位是MANAGER的人找出来
这里一共有七行数据
使用union进行合并(这里对结果做了去重)
2.union all
接上面例子,发现是没有对结果去重的


相关文章:

【MySQL 08】复合查询
目录 1.准备工作 2.多表查询 笛卡尔积 多表查询案例 3. 自连接 4.子查询 1.单行子查询 2.多行子查询 3.多列子查询 4.在from子句中使用子查询 5.合并查询 1.union 2.union all 1.准备工作 如下三个表,将作为示例,理解复合查询 EMP员工表…...

求1000以内的完数
题目:一个数如果恰好等于他的因子之和(包括1,但不包括这个数),这个数就是完数。编写算法找出1000之内的所有完数,并按下面格式输出其因子:28 its factors are 1,2,4,7,14 代码如下:…...

sqli-labs less-16 post提交dnslog注入
post提交DNSlog注入 第十六关和和十五关大差不大,可以使用布尔注入,时间盲注等,只不过闭合方式不一样,但是用布尔和时间盲太过于消耗时间,本次测试我将使用dnslog注入。 使用在线平台http://www.dnslog.cn/ 闭合方式…...

nginx报错|xquic|xqc_engine_create: fail|
一.问题描述 nginx使用xquic协议一切安装正常,nginx -s reload也正常,但就是访问不了网页 [emerg] 12342#0: |xquic|xqc_engine_create: fail| [emerg] 12342#0: |xquic|ngx_xquic_process_init|engine_init fail| [emerg] 12341#0: |xquic|xqc_engine_create: fai…...

Java虚拟机(JVM)
目录 内存区域划分堆(Heap)方法区(Method Area)程序计数器(Program Counter Register)虚拟机栈(VM Stack)本地方法栈(Native Method Stack) 类加载的过程类加…...

MQ 架构设计原理与消息中间件详解(三)
RabbitMQ实战解决方案 RabbitMQ死信队列 死信队列产生的背景 RabbitMQ死信队列俗称,备胎队列;消息中间件因为某种原因拒收该消息后,可以转移到死信队列中存放,死信队列也可以有交换机和路由key等。 产生死信队列的原因 消息投…...

大数据新视界 --大数据大厂之 Alluxio 数据缓存系统在大数据中的应用与配置
💖💖💖亲爱的朋友们,热烈欢迎你们来到 青云交的博客!能与你们在此邂逅,我满心欢喜,深感无比荣幸。在这个瞬息万变的时代,我们每个人都在苦苦追寻一处能让心灵安然栖息的港湾。而 我的…...

PHP基本语法总结
目录 输出语句 注释 数据类型(变量) 局部和全局作用域 类型比较(松散比较与严格比较) 常量 运算符 并置运算符 不等于 逻辑运算符 条件语句 数组 关联数组 数组排序 一般数组 关联数组 循环 函数 变量函数 魔…...

尚硅谷rabbitmq 2024第30-33节 死信队列 答疑
Virtual host: Type: Name: Durabiity: Arguments: Default for virtual host w ququt.normal.video Durable x-dead-letter-exchange x-dead-1etter-routing-xey x-mAx-1ength X-m在88点0也-6E1 exchange.dead.letter.vide zouting.key.dead.ietter.v 10 String String Number…...

解锁空间距离计算的多种方式-含前端、空间数据库、后端
目录 前言 一、空间数据库求解 1、PostGIS实现 二、GIS前端组件求解 1、Leaflet.js距离测算 2、Turf.js前端计算 三、后台距离计算生成 1、欧式距离 2、Haversice球面距离 3、GeoTools距离计算 4、Gdal距离生成 5、geodesy距离计算 四、成果与生成对比 1、Java不…...

Windows 开发工具使用技巧 QT使用安装和使用技巧 QT快捷键
一、QT配置 1. 安装 Qt 开发框架 1、下载 1、进入下载地址 下载地址1 (官方, 需注册账号): https://www.qt.io/download下载地址2(推荐): http://download.qt.io/http://download.qt.io/archive/qt/ (或更直接的…...

【实战教程】SpringBoot全面指南:快速上手到项目实战(SpringBoot)
文章目录 【实战教程】SpringBoot全面指南:快速上手到项目实战(SpringBoot)1. SpringBoot介绍1.1 SpringBoot简介1.2系统要求1.3 SpringBoot和SpringMVC区别1.4 SpringBoot和SpringCloud区别 2.快速入门3. Web开发3.1 静态资源访问3.2 渲染Web页面3.3 YML与Properti…...

LeetCode讲解篇之1043. 分隔数组以得到最大和
文章目录 题目描述题解思路题解代码题目链接 题目描述 题解思路 对于这题我们这么考虑,我们选择以数字的第i个元素做为分隔子数组的右边界,我们需要计算当前分隔子数组的长度为多少时能让数组[0, i]进行分隔数组的和最大 我们用数组f表示[0, i)区间内的…...

Python知识点:结合Python工具,如何使用TfidfVectorizer进行文本特征提取
开篇,先说一个好消息,截止到2025年1月1日前,翻到文末找到我,赠送定制版的开题报告和任务书,先到先得!过期不候! 如何使用Python的TfidfVectorizer进行文本特征提取 在自然语言处理(…...

Diffusion models(扩散模型) 是怎么工作的
前言 给一个提示词, Midjourney, Stable Diffusion 和 DALL-E 可以生成很好看的图片,那么它们是怎么工作的呢?它们都用了 Diffusion models(扩散模型) 这项技术。 Diffusion models 正在成为生命科学等领域的一项尖端技术&…...

查找回收站里隐藏的文件
在Windows里,每个磁盘分区都有一个隐藏的回收站Recycle, 回收站里保存着用户删除的文件、图片、视频等数据,比如,C盘的回收站为C:\RECYCLE.BIN\,D盘的的回收站为D:\RECYCLE.BIN\,E盘的的回收站为E:\RECYCLE…...

[运维]2.elasticsearch-svc连接问题
Serverless 与容器决战在即?有了弹性伸缩就不一样了 - 阿里云云原生 - 博客园 当我部署好elasticsearch的服务后,由于个人习惯,一般服务会在name里带上svc,所以我elasticsearch服务的名字是elasticsearch-svc: [root…...
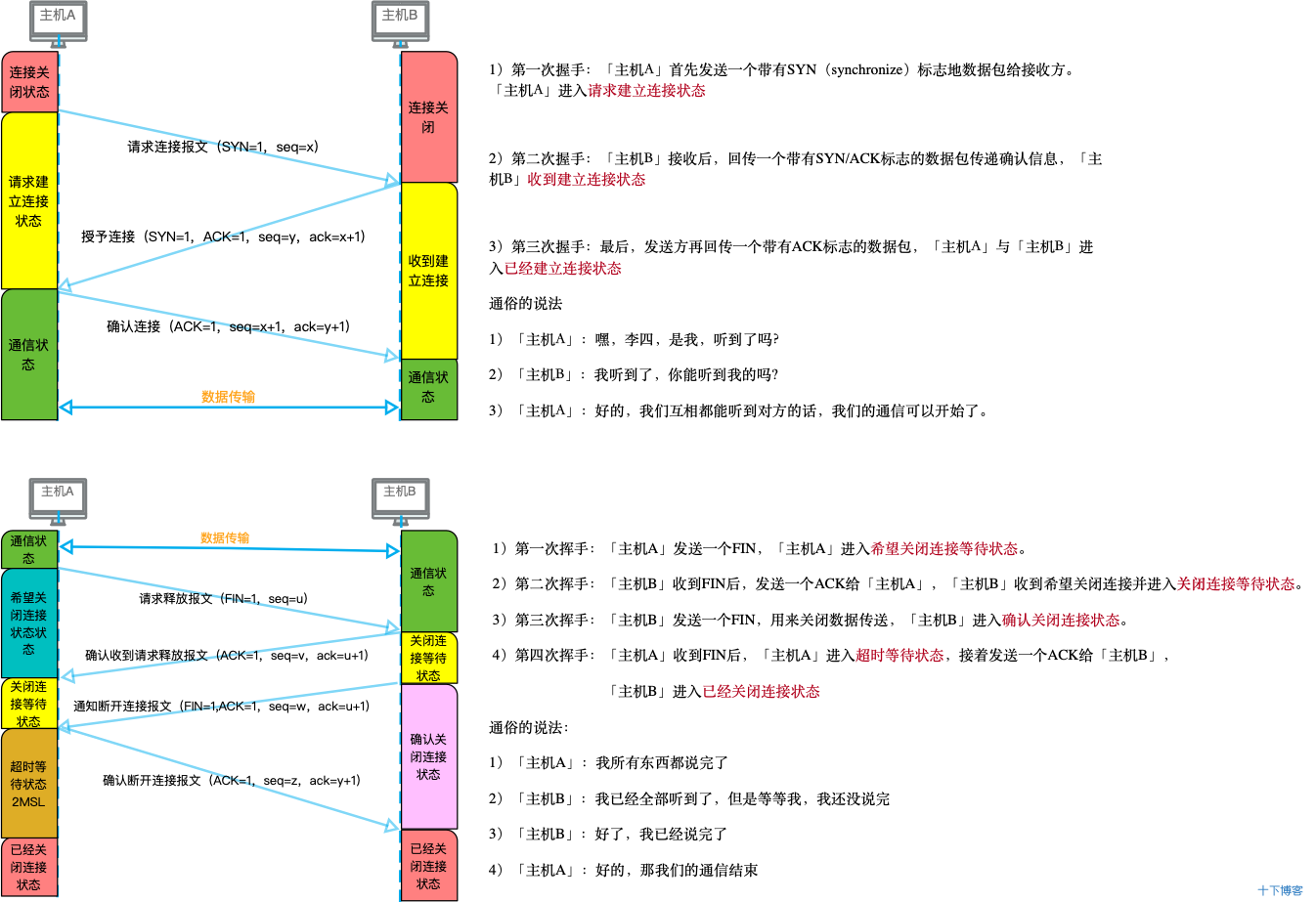
Ajax面试题:(第一天)
目录 1.说一下网络模型 2.在浏览器地址栏键入URL,按下回车之后会经历以下流程: 3.什么是三次握手和四次挥手? 4.http协议和https协议的区别 1.说一下网络模型 注:各层含义按自己理解即可 2.在浏览器地址栏键入URL,…...

数据仓库拉链表
数仓拉链表是数据仓库中常用的一种数据结构,用于记录维度表中某个属性的历史变化情况。在实际应用中,数仓拉链表可以帮助企业更好地进行数据分析和决策。 数仓拉链表(Slowly Changing Dimension, SCD)是一种用于处理维表中数据变化…...

【JVM】实战篇
1、内存调优 1.1 内存溢出和内存泄漏 内存泄漏(memory leak):在Java中如果不再使用一个对象,但是该对象依然在GC ROOT的引用链上,这个对象就不会被垃圾回收器回收,这种情况就称之为内存泄漏。 内存泄漏绝…...

别再手动改路由了!用Ant Design Vue的Menu组件动态生成“顶一左多”级导航菜单
基于Ant Design Vue的声明式导航菜单架构设计 在复杂后台管理系统开发中,导航菜单的动态生成与权限控制一直是架构设计的难点。传统方案往往需要在多个组件中硬编码菜单结构,导致维护成本高、权限同步困难。本文将介绍如何利用Ant Design Vue的Menu组件与…...

文档下载革命:kill-doc浏览器脚本让你的学习资料一键保存
文档下载革命:kill-doc浏览器脚本让你的学习资料一键保存 【免费下载链接】kill-doc 看到经常有小伙伴们需要下载一些免费文档,但是相关网站浏览体验不好各种广告,各种登录验证,需要很多步骤才能下载文档,该脚本就是为…...

技术干货!!DeepSeek API 实战:从零到生产级的 Python 调用指南 — 流式、Function Calling、多轮对话、成本优化全覆盖
DeepSeek V3 的 API 性价比在 2026 年依然没有对手——同等能力价格只有 GPT-5.5 的 1/5。但翻了一圈中文技术社区,发现大多数「教程」只讲到第一段 chat.completions.create 就停了。生产环境真正需要的东西——流式输出怎么接、Function Calling 踩了什么坑、高并…...

Go代码片段管理工具gocode:提升开发效率的CLI利器
1. 项目概述:一个为Go开发者量身定制的代码片段管理工具如果你和我一样,是个长期和Go语言打交道的开发者,那你肯定遇到过这样的场景:在多个项目间来回切换时,总有一些常用的代码片段——比如一个优雅的错误处理包装函数…...

构建AI智能体安全护栏:AgentGuard多层防护架构与工程实践
1. 项目概述:构建AI应用的安全护栏最近在部署和调试一些基于大语言模型(LLM)的智能体(Agent)应用时,我遇到了一个挺头疼的问题:这些应用在自由发挥时,偶尔会“说错话”或者“做错事”…...

从计数器到计时器:使用Spectator构建可观测性系统的实践指南
1. 项目概述:从“观众”到“观察者”的视角转变在软件开发,尤其是后端服务开发中,我们常常需要一种机制来观察和度量系统的内部状态。这种观察不是简单的日志打印,而是系统化、结构化地收集运行时指标,比如接口的调用次…...

极简静态站点生成器Minima:从核心原理到工程实践
1. 项目概述:一个极简静态站点的构建哲学 最近在整理个人博客和项目文档时,我又一次把目光投向了静态站点生成器。市面上选择很多,从功能庞大的Hugo、Jekyll,到追求速度的Zola、11ty,各有拥趸。但当我需要一个纯粹、轻…...

Go语言实现轻量级双向文件同步工具clawsync配置与实战
1. 项目概述:一个轻量级的文件同步利器在数据备份、多设备协同或者项目部署的场景里,文件同步是个绕不开的活儿。你可能用过rsync,功能强大但命令参数复杂;也可能试过syncthing,全平台覆盖但需要常驻后台服务。如果你在…...

Play Integrity API Checker:5分钟快速掌握Android设备安全检测终极指南
Play Integrity API Checker:5分钟快速掌握Android设备安全检测终极指南 【免费下载链接】play-integrity-checker-app Get info about your Device Integrity through the Play Intergrity API 项目地址: https://gitcode.com/gh_mirrors/pl/play-integrity-chec…...

抠图怎么制作?2026年最全工具对比指南,一键搞定透明背景
五一假期,我被朋友们的"抠图需求"整崩溃了。换证件照底色、制作商品图、去掉背景重新合成……各种场景都来了一遍。索性我决定把这几年用过的抠图工具都总结一下,给大家写篇真实体验文章。说实话,抠图这件事看似简单,但…...