李宏毅深度学习-梯度下降和Batch Normalization批量归一化
Gradient Descent梯度下降

▽ -> 梯度gradient -> vector向量 -> 下图中的红色箭头(loss等高线的法线方向)

Tip1: Tuning your learning rates

Adaptive Learning Rates自适应lr

通常lr会越来越小
Adaptive Learning Rates中每个参数都给它不同的lr
Adagrad
Adagrad也是Adaptive Learning Rates,因此每个参数都给它不同的lr



Tip2: Stochastic Gradient Descent随机梯度下降


左边走一步,右边已经二十步
天下武功唯快不破
Tip3: Feature Scaling特征缩放
为什么要做归一化处理

如果要predict宝可梦进化以后CP值,有两个input feature:x1是进化前CP值,x2是它的生命值
如果x1和x2分布的range很不一样,建议把它们做scaling,也就是把它们的range分布变成是一样的
希望不同的feature,它们的scale是一样的

左边这种情况下会发现,w1的变化对y的变化而言是比较小的,而w2的变化对y的变化而言是比较大的
如果画error surface会是长椭圆形状的:因此,w1对loss是有比较小的微分的,因此w1方向上比较平滑。此时,在不同方向上,就会需要非常不同的lr,除非Adagrad等adaptive lr否则很难搞定它,很难update参数
正圆形update参数就比较容易,而且注意到梯度方向就是指向最低点的,效率就比较高,而椭圆形开始时不是指向最低点
常见的Feature Scaling方式:
深度学习中典型的特征归一化代表就是Batch Normalization批归一化,具体的计算方法也是较简单即计算批中均值和方差,通过均值和方差对原数据进行归一化操作:

看上图绿色框框圈起来的地方,我们称作它是“第i个dimension”。然后在第i个dimension当中再取出其中一个element出来看(就是红色框框的地方)。
每一个元素减掉同一个dimension的所有elements平均值再除以standard deviation后再放回原位,然后每一个elements都经过一次这样的计算,就完成了feature normalization
那做完Normalization后有什么好处?
所有dimension的mean会被限制是0,而variance变成全部是1。呈现一个统计上的常态分布,这样就可以制造出一个较好(较smooth)的error surface。
再做梯度下降可以收敛地更快更好
此外,在 Deep Learning 中,还要考虑 hidden layer (中间层)的输出。如下图所示的 z i z^i zi它同时是下一层的输入,因此也需要做 Normalization。

看上图,最左边的三个x tilde已经做feature normalization(x变成x tilde: tilde就是波浪符号的意思),但他们还会因为要经过下一层的hidden layer,经过下一层的hidden layer,代表必须再做一次feature normalization的动作.可以在z的那层做或是在a的那层做feature normalization都可以; 事实上在实作上, 在activation前或后做feature normalization不会有太大的变化,所以其实都可以。
在什么位置做 Normalization 呢?
一般来说,在 activation function 之前(对 z i z^i zi做)或之后(对 a i a^i ai做)都可以。不过,如果 activation function 是 Sigmoid,因为 Sigmoid function 在取值范围 [0,1] 的 gradient 较大,因此对 z i z^i zi做normalization 更好。
我们接下来对z层做feature normalization。先算出 μ \mu μ和 σ \sigma σ

再对每一个element做feature normalization,得到z-tilde

对 z i z^i zi做了 normalization 之后,有一个有趣的现象:本来各条数据(各个 sample )之间是互不影响的。例如 z 1 z^1 z1的变化只影响 a 1 a^1 a1 。但是做 normalization 要在全部数据 (samples) 上求均值和方差,如下图所示, z 1 z^1 z1的变化会通过 μ \mu μ, σ \sigma σ影响KaTeX parse error: Expected group after '_' at position 2: z_̲^2,KaTeX parse error: Expected group after '_' at position 2: z_̲^3,进而影响到 a 2 a^2 a2, a 3 a^3 a3

也就是说,以前是一次只需要考虑一个 sample ,输入到 deep neural network 得到一个 output。做 Normalization 会使得 samples 之间互相有影响,因此现在一次需要考虑一批 samples,输入一个大的 deep neural network,得到一批 outputs。
但我们经过feature normalization关联化之后,那我们下一层必须把被关联化的所有input都包在一起做计算。这也是为什么这个演算法叫做Batch的原因。所以请记住一个关键: Batch的原因就是input已经在feature normalization的时候就"被关联"起来了。也可以看做,不是一个network处理一个example,而是变成一个巨大的network处理一大把example然后output出另一大把example.
然而,这边又有一个问题,我们资料要是有好几百万笔的话,我们在实作的时候或许会受限于硬体效能状况下会跑很久,那这时候我们就可以只取Batch做计算。
但另一个问题是,若我们只取Batch,这个Batch也必须要够大,大到足以表示整个data corpus的分布。这个时候就可以把原本要对整个corpus做feature normalization变成只需要对一个batch做feature normalization,做为整个data corpus的概估值。
所以这样大大减少计算量且减小了”Internal Covariate Shift”带来的负面效应。
把输入 samples 的各个维度都调整成均值为 0,方差为 1的分布,有时可能不好解决问题,此时可以做一点改变。如下图右上角的公式所示。注意: γ \gamma γ 和 β \beta β 的值通过学习得到,也就是根据模型和数据的情况调整。 γ \gamma γ 初始设为全 1 向量, β \beta β 初始设为全 0 向量。

Testing Performance
刚刚说的都是training的状况,接下来看一下testing时怎么做:
Batch Normalization 虽好,但是在 testing 时就遇到了问题。testing 或者实际部署时,数据都是实时处理,不可能每次等到满一个 batch 才处理。
怎么办呢?
训练时,每处理一个 batch,就按下图中所示公式,更新均值 μ \mu μ 的 moving average μ ‾ \overline\mu μ , σ \sigma σ 也是类似操作。训练结束后,把得到的 μ ‾ \overline\mu μ和 σ ‾ \overline\sigma σ 用作 testing data 的均值和方差。


为什么说 Batch Normalization 对优化参数有帮助?
“Experimental results (and theoretically analysis) support batch normalization change the landscape of error surface.”
实验结果和理论分析验证了 Batch Normalization 可以通过改变 error surface,让 optimization 更顺利。
Batch Normalization的表现

所以BN实际上有一些对抗过拟合的效果
看到一个方法时要考虑是对training performance有用还是对testing performance有用。BN是对两个stage都有用,主要的作用还是在training不好的时候帮助比较大;如果是training已经很好但testing不好,还有很多其他方法可用

BN归一化的表现没有说特别突出,因为Normalization不仅仅只有BN,还有其他Layer Normalization,Instance Normalization等等,但是BN所使用最为广泛,并且如图实验数据可以看出BN的加入能够使得模型收敛速度更快并且随着batch的增大表现出更大的优势,特别是在使用sigmoid的时候,由于sigmoid函数曲线的特殊性,使得BN后输入sigmoid激活函数中能够表现出更好的梯度。要有BN,sigmoid才train的起来
Gradient Descent Theory

update参数后,loss不一定会下降
此时,人物往前和往右都会变低,因此会往右前方走,但是却变高了
相关文章:
李宏毅深度学习-梯度下降和Batch Normalization批量归一化
Gradient Descent梯度下降 ▽ -> 梯度gradient -> vector向量 -> 下图中的红色箭头(loss等高线的法线方向) Tip1: Tuning your learning rates Adaptive Learning Rates自适应lr 通常lr会越来越小 Adaptive Learning Rates中每个参数都给它不…...

java集合框架都有哪些
Java集合框架(Java Collections Framework)是Java提供的一套设计良好的支持对一组对象进行操作的接口和类。这些接口和类定义了如何添加、删除、遍历和搜索集合中的元素。Java集合框架主要包括以下几个部分: 接口: Collection&…...
线程与进程)
笔记整理—linux进程部分(8)线程与进程
前面用了高级IO去实现鼠标和键盘的读取,也说过要用多进程方式进行该操作: int mian(void) {int ret-1;int fd-1;char bug[100]{0};retfork();if(0ret){//子进程,读鼠标}if(0<ret){//父进程,读键盘}else{perror("fork&quo…...

使用 Python 实现遗传算法进行无人机路径规划
目录 使用 Python 实现遗传算法进行无人机路径规划引言1. 遗传算法概述1.1 定义1.2 基本步骤1.3 遗传算法的特点 2. 使用 Python 实现遗传算法2.1 安装必要的库2.2 定义类2.2.1 无人机模型类2.2.2 遗传算法类 2.3 示例程序 3. 遗传算法的优缺点3.1 优点3.2 缺点 4. 改进方向5. …...

JAVA基础: synchronized 和 lock的区别、synchronized锁机制与升级
1 synchronized 和 lock的区别 synchronized是一个关键字, lock是一个接口,实际使用的是实现类 synchronized通过触发的是系统级别的锁机制, lock是API级别的锁机制 synchronized自动获得锁,自动释放锁。 lock需要通过方法获得锁…...

自动驾驶 车道检测实用算法
自动驾驶 | 车道检测实用算法 车道识别是自动驾驶领域的一个重要问题,今天介绍一个利用摄像头图像进行车道识别的实用算法。该算法利用了OpenCV库和Udacity自动驾驶汽车数据库的相关内容。 该算法包含以下步骤: 摄像头校准,以移除镜头畸变&…...

22.第二阶段x86游戏实战2-背包遍历REP指令详解
免责声明:内容仅供学习参考,请合法利用知识,禁止进行违法犯罪活动! 本次游戏没法给 内容参考于:微尘网络安全 本人写的内容纯属胡编乱造,全都是合成造假,仅仅只是为了娱乐,请不要…...

java 的三种IO模型(BIO、NIO、AIO)
java 的三种IO模型(BIO、NIO、AIO) 一、BIO 阻塞式 IO(Blocking IO)1.1、BIO 工作机制1.2、BIO 实现单发单收1.3、BIO 实现多发多收1.4、BIO 实现客户端服务端多对一1.5、BIO 模式下的端口转发思想 二、NIO 同步非阻塞式 IO&#…...

低级语言和高级语言、大小写敏感、静态语言和动态语言、链接
低级语言和高级语言 一般而言,更接近硬件的语言被称为低级语言,反之,更远离硬件被称为高级语言。C语言既有低级语言的特点,又有高级语言的特点,又被称为系统语言。Java/Python一般被称为高级语言。 大小写敏感 DOS/Win…...

P3197 [HNOI2008] 越狱
题目传送门 题面 [HNOI2008] 越狱 题目描述 监狱有 n n n 个房间,每个房间关押一个犯人,有 m m m 种宗教,每个犯人会信仰其中一种。如果相邻房间的犯人的宗教相同,就可能发生越狱,求有多少种状态可能发生越狱。 …...
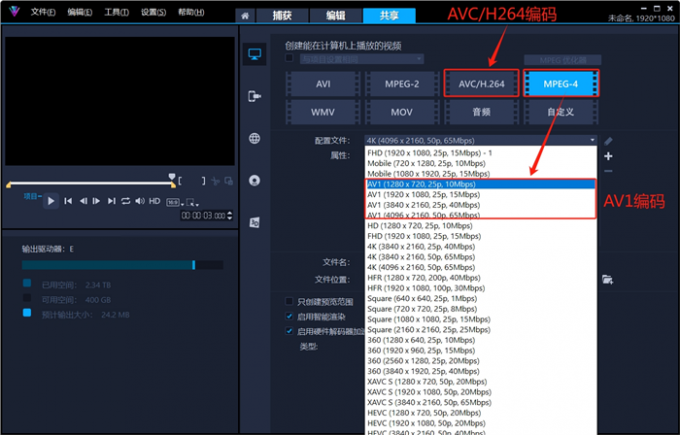
会声会影导出视频mp4格式哪个最高清,会声会影输出格式哪个清晰
调高分辨率后,mp4视频还是不清晰。哪怕全部使用4K级素材,仍然剪不出理想中的高画质作品。不是你的操作有问题,而是剪辑软件没选对。Corel公司拥有全球顶尖的图像处理技术,该公司研发的会声会影视频剪辑软件,在过去的20…...

Linux:进程调度算法和进程地址空间
✨✨✨学习的道路很枯燥,希望我们能并肩走下来! 文章目录 目录 文章目录 前言 一 进程调度算法 1.1 进程队列数据结构 1.2 优先级 编辑 1.3 活动队列 编辑 1.4 过期队列 1.5 active指针和expired指针 1.6 进程连接 二 进程地址空间 2.1 …...

TCP ---滑动窗口以及拥塞窗口
序言 在上一篇文章中我们介绍了 TCP 中的协议段格式,以及保证其可靠传输的重传机制,着重介绍了三次握手建立连接,四次挥手断开连接的过程(👉点击查看)。 这只是 TCP 保证通信可信策略的一部分,现在让我们继续深入吧&…...

第十二章--- fixed 和 setprecision 函数、round 函数、进制转换及底层逻辑
1. 保留几位小数 在C中,如果你想要控制输出的小数点后的位数,可以使用<iomanip>头文件提供的fixed和setprecision函数。这里的fixed用于设置浮点数的输出格式为定点表示法,而setprecision(n)则用来指定小数点后保留的位数。具体用法如…...

ASP.NetCore---I18n(internationalization)多语言版本的应用
文章目录 0.实现的效果如下1.创建新项目I18nBaseDemo2.添加页面中的下拉框3.在HomeController中添加ChangeLanguage方法4.在Progress.cs 文件中添加如下代码:5. 在progress.cs中添加code6.添加Resource资源文件7.在页面中引用i18n的变量8. 重启项目,应该…...

vue3 环境配置vue-i8n国际化
一.依赖和插件的安装 主要是vue-i18n和 vscode的自动化插件i18n Ally https://vue-i18n.intlify.dev/ npm install vue-i18n10 pnpm add vue-i18n10 yarn add vue-i18n10 vscode在应用商城中搜索i18n Ally:如图 二.实操 安装完以后在对应项目中的跟package.jso…...

2024 uniapp入门教程 01:含有vue3基础 我的第一个uniapp页面
uni-app官网uni-app,uniCloud,serverless,快速体验,看视频,10分钟了解uni-app,为什么要选择uni-app?,功能框架图,一套代码,运行到多个平台https://uniapp.dcloud.net.cn/ 准备工作:HBuilder X 软件 HBuilder X 官网下载…...

CentOS 7文件系统
从centos7开始,默认的文件系统从ext4变成了XFS。随着虚拟化的应用越来越广泛,作为虚拟化磁盘来源的大文件(单个文件几GB级别)越来越常见。 1.XFS组成部分: XFS文件系统在数据的分布上主要划分为三部分:数据…...
)
vue源码解析(源码解析学习大纲)
文章目录 Vue源码解析入手方向大纲1.核心概念1-1.响应式系统1-2. 组件1-3. 虚拟DOM1-4. 指令1-5. 生命周期钩子 2.虚拟DOM2-1. 概念2-2. 工作流程2-3. 示例2-4.总结 3.组件系统3-1. 组件的定义3-2. 组件的创建3-3. 组件的模板3-4. 生命周期3-5. 事件处理3-6. 插槽(S…...

工行企业网银U盾展期后有两个证书问题的解决方法
工行企业网银U盾证书快到期后,可以自助展期,流程可以根据企业网银提示页面操作。操作后,可能存在两个新旧两个证书并存的情况,致使网银转账等操作失败,如图: 其原因是新证书生成后,旧证书没有删…...

别再乱收CAN报文了!STM32F407的HAL库CAN过滤器配置保姆级避坑指南
STM32F407 HAL库CAN过滤器配置:从原理到实战的深度解析 在嵌入式系统开发中,CAN总线因其高可靠性和实时性被广泛应用于汽车电子、工业控制等领域。然而,许多开发者在STM32F407上使用HAL库配置CAN过滤器时,常常陷入"能接收数据…...

700MHz 5G网络DTMB干扰实战:从测量到规避的完整解决方案
1. 项目概述:直面700MHz网络中的DTMB干扰挑战在5G网络的深度覆盖战役中,700MHz频段因其卓越的穿透能力和广阔的覆盖范围,被寄予厚望,成为解决偏远地区和室内深度覆盖难题的“黄金频段”。然而,理想很丰满,现…...

正交设计实战指南:从理论到最优方案验证
1. 正交设计入门:从概念到实战价值 第一次接触正交设计是在五年前的一个电机工艺优化项目上。当时面对12个关键参数、每个参数4-5个水平的选择困境,如果做全面实验需要3125组数据,而项目周期只允许做50组实验。正是正交设计让我们用36组实验…...

深入PEX8796:从Serdes到Virtual Switch,图解PCIe交换芯片的三种工作模式
深入解析PEX8796:PCIe交换芯片的架构设计与模式创新 在高速数据传输领域,PCIe交换芯片如同交通枢纽般连接着计算系统的各个组件。作为PLX公司(现已被博通收购)的经典之作,PEX8796凭借其灵活的架构设计和多样化的操作模…...

命令行控制中心:提升开发效率的聚合与自动化工具
1. 项目概述:一个面向开发者的命令行控制中心最近在GitHub上看到一个挺有意思的项目,叫jendrypto/command-center。光看名字,你可能会联想到科幻电影里那种布满屏幕、控制一切的舰桥。但在开发者的世界里,它其实是一个更接地气、更…...

去人类中心化研究引擎:AI如何突破学科壁垒驱动科研创新
1. 项目概述:一个“去人类中心化”的研究引擎最近在GitHub上看到一个挺有意思的项目,叫“De-Anthropocentric-Research-Engine”,直译过来就是“去人类中心化研究引擎”。第一眼看到这个标题,你可能和我一样,脑子里会冒…...

方法论:什么是横向纵向分析法?
文章目录前言什么是横纵分析法?规划类: 空间和时间价值链:投入和产出考察类: 广度和深度调研类:竞品和历史机型对比问题跟进类:正面和侧面问题解决类:预防和治愈前言 由于事情往往有两面性&…...

Boss-Key终极指南:Windows窗口隐藏与隐私保护完整解决方案
Boss-Key终极指南:Windows窗口隐藏与隐私保护完整解决方案 【免费下载链接】Boss-Key 老板来了?快用Boss-Key老板键一键隐藏静音当前窗口!上班摸鱼必备神器 项目地址: https://gitcode.com/gh_mirrors/bo/Boss-Key 在数字化办公环境中…...

Arm架构在中国市场的潜力与挑战:从技术选型到实践落地
1. 项目概述:从一次技术选型引发的深度思考最近在为一个边缘计算项目做硬件选型,团队里关于采用x86还是Arm架构的服务器争论了好几天。这让我想起,这几年在国内的云计算、数据中心、甚至个人消费电子领域,Arm架构的声音是越来越响…...

Void-Memory:内存与持久化的平衡术,构建高性能本地缓存与状态存储
1. 项目概述与核心价值最近在折腾一个挺有意思的开源项目,叫G3sparky/void-memory。乍一看这个标题,可能会让人有点摸不着头脑——“虚空记忆”?这听起来更像是一个哲学概念或者游戏里的技能名。但作为一个在技术圈摸爬滚打多年的老手&#x…...