头歌实践教学平台 大数据编程 实训答案(二)
第三阶段 Spark算子综合案例
Spark算子综合案例 - JAVA篇
第1关:WordCount - 词频统计
任务描述
本关任务:使用 Spark Core 知识编写一个词频统计程序。
相关知识
略
编程要求
请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,具体任务如下:
对文本文件内的每个单词都统计出其出现的次数;
按照每个单词出现次数的数量,降序排序。
package net.educoder;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.Arrays;/*** 1、对文本文件内的每个单词都统计出其出现的次数。* 2、按照每个单词出现次数的数量,降序排序。*/
public class Step1 {private static SparkConf conf;private static JavaSparkContext sc;static {conf = new SparkConf().setAppName("step1").setMaster("local");sc = new JavaSparkContext(conf);}/**** @return JavaRDD<Tuple2>*/public static JavaRDD<Tuple2> fun1() {JavaRDD<String> rdd = sc.textFile("/root/wordcount.txt");/**-----------------------------------begin----------------------------------------------**/JavaRDD<String> rdd1 = rdd.flatMap(x -> Arrays.asList(x.split(" ")).iterator());JavaPairRDD<String, Integer> rdd2 = rdd1.mapToPair(x -> new Tuple2<>(x, 1));JavaPairRDD<String, Integer> rdd3 = rdd2.reduceByKey((x, y) -> x + y);JavaRDD<Tuple2> rdd4 = rdd3.map(x -> new Tuple2(x._2(), x._1()));JavaRDD<Tuple2> rdd5 = rdd4.sortBy(x -> x._1(), false, 1);JavaRDD<Tuple2> rdd6 = rdd5.map(x -> new Tuple2(x._2(), x._1()));return rdd6;/**-----------------------------------end----------------------------------------------**/}
}第2关:Friend Recommendation - 好友推荐
任务描述
本关任务:使用 Spark Core 知识完成 " 好友推荐 " 的程序。
相关知识
直接好友与间接好友
参照数据如下:
hello hadoop cat
world hadoop hello hive
cat tom hive
...
...
数据说明(第二行为例):
这个人叫 world ,他有三个好友,分别是:hadoop、hello 和 hive。hadoop、hello 和 hive 之间就是间接好友。word 与 hadoop 、 hello 、hive 属于直接好友。
package net.educoder;import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;import java.util.ArrayList;
import java.util.List;public class Step2 {private static SparkConf conf;private static JavaSparkContext sc;static {conf = new SparkConf().setAppName("step2").setMaster("local");sc = new JavaSparkContext(conf);}/**** @return JavaPairRDD<String, Integer>*/public static JavaPairRDD<String, Integer> fun2() {JavaRDD<String> rdd = sc.textFile("/root/friend.txt");/**-------------------------------beign-----------------------------------**/JavaPairRDD<String,Integer> rdd1 = rdd.flatMapToPair(line->{List<Tuple2<String,Integer>> list = new ArrayList<Tuple2<String,Integer>>();String[] split = line.split(" ");String me = split[0];for (int i = 1;i < split.length;i++){String s = me.hashCode() > split[i].hashCode() ? me +"_"+split[i]:split[i] + "_" + me;list.add(new Tuple2<>(s,0));for(int j=i+1;j<split.length;j++){String ss = split[j].hashCode() > split[i].hashCode() ? split[j] + "_" + split[i]:split[i] + "_" +split[j];list.add(new Tuple2<>(ss,1));}}return list.iterator();});JavaPairRDD<String,Iterable<Integer>> rdd2 = rdd1.groupByKey();JavaPairRDD<String,Integer> javaPairRDD = rdd2.mapToPair(x ->{boolean bool = false;int count = 0;Iterable<Integer> flags = x._2();String name = x._1();for(Integer flag:flags){if(flag == 0){bool = true;}count++;}if(bool == false){return new Tuple2<String,Integer>(name,count);}else{return new Tuple2<String,Integer>("直接好友",0);}});JavaPairRDD<String,Integer> filter = javaPairRDD.filter(x -> x._2()!=0?true : false);return filter;/**-------------------------------end-----------------------------------**/}
}
第四阶段 SparkSQL
Spark SQL 自定义函数(Scala)
第1关:Spark SQL 自定义函数
任务描述
本关任务:根据编程要求,创建自定义函数,实现功能。
相关知识
为了完成本关任务,你需要掌握:
自定义函数分类;
自定义函数的实现方式;
弱类型的 UDAF 与 强类型的 UDAF 区分;
实现弱类型的 UDAF 与 强类型的 UDAF。
import org.apache.spark.sql.api.java.UDF1
import org.apache.spark.sql.types.StringType
import org.apache.spark.sql.{DataFrame,SparkSession}object First_Question {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("First_Question").master("local[*]").getOrCreate()/******************* Begin *******************/ val dataFrame: DataFrame = spark.read.text("file:///data/bigfiles/test.txt")dataFrame.createTempView("data")spark.sql("""select value[0] as name,value[1] as chinese, value[2] as math,value[3] as english from(select split(value,' ')value from data)""".stripMargin).createOrReplaceTempView("clean_data")spark.udf.register("nameToUp",(x:String)=>x.toUpperCase)spark.udf.register("add",(chinese:Integer,math:Integer,english:Integer)=>chinese + math+english)spark.sql("""select nameToUp(name) as name,add(chinese,math,english) as total from clean_data order by total desc""".stripMargin).show()/******************* End *******************/spark.stop()}
}
Spark SQL 多数据源操作(Scala)
第1关:加载与保存操作
任务描述
本关任务:根据编程要求,编写 Spark 程序读取指定数据源,完成任务。
相关知识
为了完成本关任务,你需要掌握:
数据加载;
SQL 语句加载数据;
文件保存;
保存模式;
持久化存储到 Hive;
分区与排序。
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object First_Question {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("First_Question").master("local[*]").getOrCreate()/******************* Begin *******************/ val dataFrame = spark.read.json("file:///data/bigfiles/demo.json");dataFrame.orderBy(dataFrame.col("age").desc).show();/******************* End *******************/spark.stop()}
}
第2关:Parquet 格式文件
任务描述
本关任务:根据编程要求,编写 Spark 程序读取指定数据源,完成 Parquet 分区任务。
相关知识
为了完成本关任务,你需要掌握:
什么是 Parquet 文件;
Parquet 分区自动识别;
Parquet 模式合并;
Hive Metastore Parquet 表转换;
元数据刷新。
什么是 Parquet 文件?
Apache Parquet 是面向分析型业务的列式存储格式,由 Twitter 和 Cloudera 合作开发,Parquet 是一种与语言无关的列式存储文件类型,可以适配多种计算框架。在 Spark SQL 中提供了对 Parquet 文件的读写支持,读取 Parquet 文件时会自动保留原始数据的结构。需要注意的一点,我们在编写 Parquet 文件时,出于兼容性原因,所有列都将自动转换为 NULL 类型。
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object Second_Question {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("Second_Question").master("local[*]").getOrCreate()/******************* Begin *******************/ spark.read.json("file:///data/bigfiles/demo.json").write.parquet("file:///result/student=1")spark.read.json("file:///data/bigfiles/demo2.json").write.parquet("file:///result/student=2")/******************* End *******************/spark.stop()}
}
第3关:ORC 格式文件
任务描述
本关任务:根据编程要求,完善程序,实现 Spark SQL 读取 ORC 格式的 Hive 数据表。
相关知识
为了完成本关任务,你需要掌握:
什么是 ORC 文件?
ORC 组成
读取 ORC 文件数据流程
Spark SQL 读取 ORC 格式的 Hive 数据表
什么是 ORC 文件?
ORC 全称 Optimized Row Columnar,是一种为 Hadoop 工作负载设计的自描述类型感知列文件格式。它针对大型流式读取进行了优化,但集成了对快速查找所需行的支持。以列格式存储数据使读者可以仅读取、解压缩和处理当前查询所需的值。因为 ORC 文件是类型感知的,所以编写者为该类型选择最合适的编码,并在写入文件时建立一个内部索引。谓词下推使用这些索引来确定需要为特定查询读取文件中的哪些条带,并且行索引可以将搜索范围缩小到 10,000 行的特定集合。ORC 支持 Hive 中的完整类型集,包括复杂类型:结构、列表、映射和联合。
命令行窗口
# 启动 Hadoop
start-all.sh
# 启动 Hive 元数据服务
nohup hive --service metastore &
# 进入 Hive
hive
# 创建 ORC 格式的 Hive 数据表
create table student(id int,name string,age int,class string
)stored as orc;
# 插入数据
insert into table student values(1001,"王刚",19,"大数据一班");
insert into table student values(1002,"李虹",18,"大数据一班");
insert into table student values(1003,"张子萱",20,"大数据一班");
insert into table student values(1004,"赵云",18,"大数据一班");
insert into table student values(1005,"李晓玲",19,"大数据一班");
insert into table student values(1006,"张惠",18,"大数据二班");
insert into table student values(1007,"秦散",19,"大数据二班");
insert into table student values(1008,"王丽",18,"大数据二班");
insert into table student values(1009,"田忌",20,"大数据二班");
insert into table student values(1010,"张花",18,"大数据二班");代码文件窗口
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object Third_Question {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("Third_Question").master("local[*]").enableHiveSupport().getOrCreate()/******************* Begin *******************/ spark.sql("select * from student").orderBy("id").show()/******************* End *******************/spark.stop()}
}第4关:JSON 格式文件
任务描述
本关任务:根据编程要求,读取 JSON 文件,完成任务。
相关知识
为了完成本关任务,你需要掌握:
什么是 JSON 格式;
JSON 的标准格式;
JSON 与 Spark SQL。
什么是 JSON 格式?
JSON(JavaScript Object Notation, JS 对象简谱)是一种轻量级的数据交换格式。它基于 ECMAScript(European Computer Manufacturers Association, 欧洲计算机协会制定的 js 规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。 易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object Forth_Question {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("Forth_Question").master("local[*]").getOrCreate()/******************* Begin *******************/ val dataFrame:DataFrame = spark.read.json("file:///data/bigfiles/test.json")dataFrame.createOrReplaceTempView("data")spark.sql("select id,name,age,class from data").orderBy("id").show()/******************* End *******************/spark.stop()}
}
第5关:JDBC 操作数据库
任务描述
本关任务:根据编程要求,读取本地文件,将数据使用 JDBC 方式进行保存。
相关知识
为了完成本关任务,你需要掌握:
JDBC 的定义;
Spark SQL 与 JDBC;
Spark SQL 加载 JDBC 数据;
Spark SQL 写入 JDBC 数据。
JDBC 的定义
Java 数据库连接(Java Database Connectivity,简称 JDBC)是 Java 语言中用来规范客户端程序如何来访问数据库的应用程序接口,提供了诸如查询和更新数据库中数据的方法。JDBC 也是 Sun Microsystems 的商标。我们通常说的 JDBC 是面向关系型数据库的。
import org.apache.spark.sql.{DataFrame, SaveMode, SparkSession}object Fifth_Question {def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("Fifth_Question").master("local[*]").getOrCreate()/******************* Begin *******************/ val dataFrame:DataFrame = spark.read.option("header","true").csv("file:///data/bigfiles/job58_data.csv")dataFrame.write.format("jdbc").option("url", "jdbc:mysql://localhost:3306/work?useSSL=false").option("driver", "com.mysql.jdbc.Driver").option("user", "root").option("password", "123123").option("dbtable", "job_data").mode(SaveMode.Overwrite) .save()/******************* End *******************/spark.stop()}
}
第6关:Hive 表操作
任务描述
本关任务:根据编程要求,创建 Hive 数据表,完成读取操作。
相关知识
为了完成本关任务,你需要掌握:
什么是 Hive;
Spark on Hive;
Spark SQL 与 Hive;
Spark SQL 加载 Hive 数据;
Spark SQL 保存数据到 Hive。
什么是 Hive?
Hive 是基于 Hadoop 的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 数据仓库工具能将结构化的数据文件映射为一张数据库表,并提供 SQL 查询功能,能将 SQL 语句转变成 MapReduce 任务来执行。Hive 的优点是学习成本低,可以通过类似 SQL 语句实现快速 MapReduce 统计,使 MapReduce 变得更加简单,而不必开发专门的 MapReduce 应用程序。
命令行窗口
# 启动 Hadoop
start-all.sh
# 启动 Hive 元数据服务
nohup hive --service metastore &
# 进入 Hive
hive
# 创建 Hive 数据表
create table employee(eid string,ename string,age int,part string
);
# 插入数据
insert into table employee values("A568952","王晓",25,"财务部");
insert into table employee values("B256412","张天",28,"人事部");
insert into table employee values("C125754","田笑笑",23,"销售部");
insert into table employee values("D265412","赵云",24,"研发部");
insert into table employee values("F256875","李姿姿",26,"后勤部");代码文件窗口
import org.apache.spark.sql.{DataFrame, SparkSession}
object Sixth_Question {def main(args: Array[String]): Unit = {/******************* Begin *******************/ val spark: SparkSession = SparkSession.builder().appName("Sixth_Question").master("local[*]").enableHiveSupport().getOrCreate()val dataFrame : DataFrame = spark.sql("select * from employee order by eid")dataFrame.show()spark.stop()/******************* End *******************/}
}RDD、DataSet 与 DataFrame 的转换(Scala)
第1关:RDD、DataSet 与 DataFrame 的相互转换
任务描述
本关任务:完成 RDD、DataSet 与 DataFrame 之间的相互转换。
相关知识
为了完成本关任务,你需要掌握:
熟悉基础的 Scala 代码编写;
创建 RDD、DataSet、DataFrame 数据集。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame,SparkSession}object First_Question {case class Employee(id:Int,e_name:String,e_part:String,salary:Int)def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("First_Question").master("local[*]").getOrCreate()val rdd: RDD[(Int, String, String, Int)] = spark.sparkContext.parallelize(List((1001, "李晓", "运营部", 6000), (1002, "张花", "美术部", 6000), (1003, "李强", "研发部", 8000), (1004,"田美", "营销部", 5000), (1005, "王菲", "后勤部", 4000)))/******************* Begin *******************/ import spark.implicits._val df:DataFrame=rdd.map(line=>{Employee(line._1,line._2,line._3,line._4)}).toDF()df.as[Employee].show()/******************* End *******************/spark.stop()}
}
DataFrame 基础操作(Scala)
第1关:DataFrame 基础操作
任务描述
本关任务:根据编程要求,完成对指定 DataFrame 数据集的基础操作。
相关知识
为了完成本关任务,你需要掌握:
熟悉基础的 Scala 代码编写;
DataFrame 的基础操作。
下面让我来带领大家一起来学习 DataFrame 中丰富的方法,首先创建 DataFrame,做为下面各个方法中的示例数据。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame,SparkSession}object First_Question {case class Student(name:String,age:String,sex:String)def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("First_Question").master("local[*]").getOrCreate()val rdd: RDD[String] = spark.sparkContext.parallelize(List("张三,20,男", "李四,22,男", "李婷,23,女","赵六,21,男"))val temp: RDD[Student] = rdd.map(s => {val split_rdd: Array[String] = s.split(",")Student(split_rdd(0), split_rdd(1), split_rdd(2))})import spark.implicits._// DataFrame 源数据val dataFrame: DataFrame = temp.toDF()/******************* Begin *******************/ dataFrame.where("age>=18 and age<25").groupBy("sex").count().show()/******************* End *******************/spark.stop()}
}
DataFrame 创建(Scala)
第1关:DataFrame 创建
任务描述
本关任务:了解什么是 DataFrame 以及创建 DataFrame 的方式。
相关知识
为了完成本关任务,你需要掌握:
熟悉基础的 Scala 代码编写;
创建 DataFrame 数据集。
什么是 DataFrame?
DataFrame 的前身是 SchemaRDD, 从 Spark 1.3.0 开始 SchemaRDD 更名为 DataFrame。与 SchemaRDD 的主要区别是: DataFrame 不再直接继承自 RDD, 而是自己实现了 RDD 的绝大多数功能。但仍旧可以在 DataFrame 上调用 RDD 方法将其转换为一个 RDD。DataFrame 是一种以 RDD 为基础的分布式数据集, 类似于传统数据库的二维表格, DataFrame 带有 Schema 元信息, 即 DataFrame 所表示的二维表数据集的每一列都带有名称和类型, 但底层做了更多的优化。DataFrame 可以从很多数据源构建, 比如: 已存在的 RDD, 结构化文件, 外部数据库, Hive 表等。
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame,SparkSession}object First_Question {/******************* Begin *******************/ case class Student(name:String,age:String,sex:String)/******************* End *******************/ def main(args: Array[String]): Unit = {val spark: SparkSession = SparkSession.builder().appName("First_Question").master("local[*]").getOrCreate()val rdd: RDD[String] = spark.sparkContext.parallelize(List("张三,20,男", "李四,22,男", "李婷,23,女","赵六,21,男"))/******************* Begin *******************/ val result: RDD[Student] = rdd.map(s => {val split_rdd: Array[String] = s.split(",")Student(split_rdd(0), split_rdd(1), split_rdd(2))})import spark.implicits._result.toDF().show()/******************* End *******************/spark.stop()}
}
SparkSQL数据源
第1关:SparkSQL加载和保存
任务描述
本关任务:编写一个SparkSQL程序,完成加载和保存数据。
相关知识
为了完成本关任务,你需要掌握:
加载数据
直接在文件上运行SQL
保存到路径
保存模式介绍
保存到持久表
存储和排序或分区
package com.educoder.bigData.sparksql2;import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;public class Test1 {public static void main(String[] args) throws AnalysisException {SparkSession spark = SparkSession .builder().appName("test1").master("local").getOrCreate();/********* Begin *********/spark.read().format("json").load("people.json").write().mode(SaveMode.Append).save("people");spark.read().format("json").load("people1.json").write().mode(SaveMode.Append).save("people");spark.read().load("people").show(); /********* End *********/}}
第2关:Parquet文件介绍
任务描述
本关任务:编写Parquet分区文件,并输出表格内容
相关知识
为了完成本关任务,你需要掌握:
编程方式加载Parquet文件
Parquet分区
结构合并
元数据刷新
Parquet参数配置
package com.educoder.bigData.sparksql2;import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.SparkSession;public class Test2 {public static void main(String[] args) throws AnalysisException {SparkSession spark = SparkSession .builder().appName("test1").master("local").getOrCreate();/********* Begin *********/spark.read().json("people.json").write().parquet("people/id=1");spark.read().json("people1.json").write().parquet("people/id=2");spark.read().load("people").show(); /********* End *********/}}
第3关:json文件介绍
任务描述
本关任务:编写一个sparksql程序,统计平均薪水。
相关知识
为了完成本关任务,你需要掌握json文件介绍及使用。
json文件介绍
Spark SQL可以自动推断JSON数据集的模式并将其加载为Dataset<Row>。可以使用SparkSession.read().json()。
请注意,作为json文件提供的文件不是典型的JSON文件。每行必须包含一个单独的,自包含的有效JSON对象。有关更多信息,请参阅JSON Lines文本格式,也称为换行符分隔的JSON。
package com.educoder.bigData.sparksql2;import org.apache.spark.sql.AnalysisException;
import org.apache.spark.sql.SparkSession;public class Test3 {public static void main(String[] args) throws AnalysisException {SparkSession spark = SparkSession .builder().appName("test1").master("local").getOrCreate();/********* Begin *********/spark.read().format("json").load("people.json").createOrReplaceTempView("people"); spark.read().format("json").load("people1.json").createOrReplaceTempView("people1");spark.sql("select avg(salary) from ( select salary from people union all select salary from people1) a").show();/********* End *********/}}
第4关:JDBC读取数据源
任务描述
本关任务:编写sparksql程序,保存文件信息到mysql,并从mysql进行读取。
相关知识
为了完成本关任务,你需要掌握如何使用JDBC读取数据源。
使用JDBC如何读取数据源
Spark SQL 还包括一个可以使用JDBC从其他数据库读取数据的数据源,与使用JdbcRDD相比,此功能应该更受欢迎。这是因为结果作为DataSet返回,可以在Spark SQL中轻松处理,也可以与其他数据源连接。
JDBC数据源也更易于使用Java或Python,因为它不需要用户提供 ClassTag。(请注意,这与Spark SQL JDBC服务器不同,后者允许其他应用程序使用Spark SQL运行查询)。
package com.educoder.bigData.sparksql2;import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SaveMode;
import org.apache.spark.sql.SparkSession;public class Test4 {public static void case4(SparkSession spark) {/********* Begin *********///people.json保存至mysql的peopleDataset<Row> load = spark相关文章:
)
头歌实践教学平台 大数据编程 实训答案(二)
第三阶段 Spark算子综合案例 Spark算子综合案例 - JAVA篇 第1关:WordCount - 词频统计 任务描述 本关任务:使用 Spark Core 知识编写一个词频统计程序。 相关知识 略 编程要求 请仔细阅读右侧代码,根据方法内的提示,在Begin - End区域内进行代码补充,具体任务如下: …...
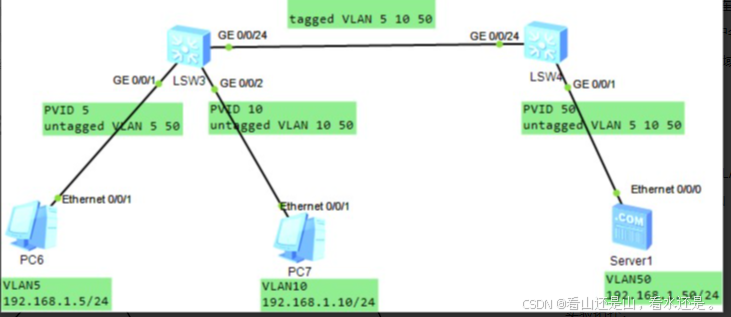
路由交换实验指南
案例 01:部署使用 eNSP 平台实验需求: 安装华为 eNSP 网络模拟平台打开 eNSP 平台,新建拓扑并绘制网络能够成功启动交换机、计算机设备 实验步骤: 安装华为 eNSP 网络模拟平台启动安装程序 配置安装内容 防护墙允许 eNSP 程序的…...

了解网页 blob 链接
blob 链接 自从 HTML5 提供了 video 标签,在网页中播放视频变得非常简单,只要在代码中插入一个 video 标签,再将 video 标签的 src 属性设置为视频的链接就可以了。由于 src 指向的是视频文件真实的地址,所以当我们通过浏览器的调…...
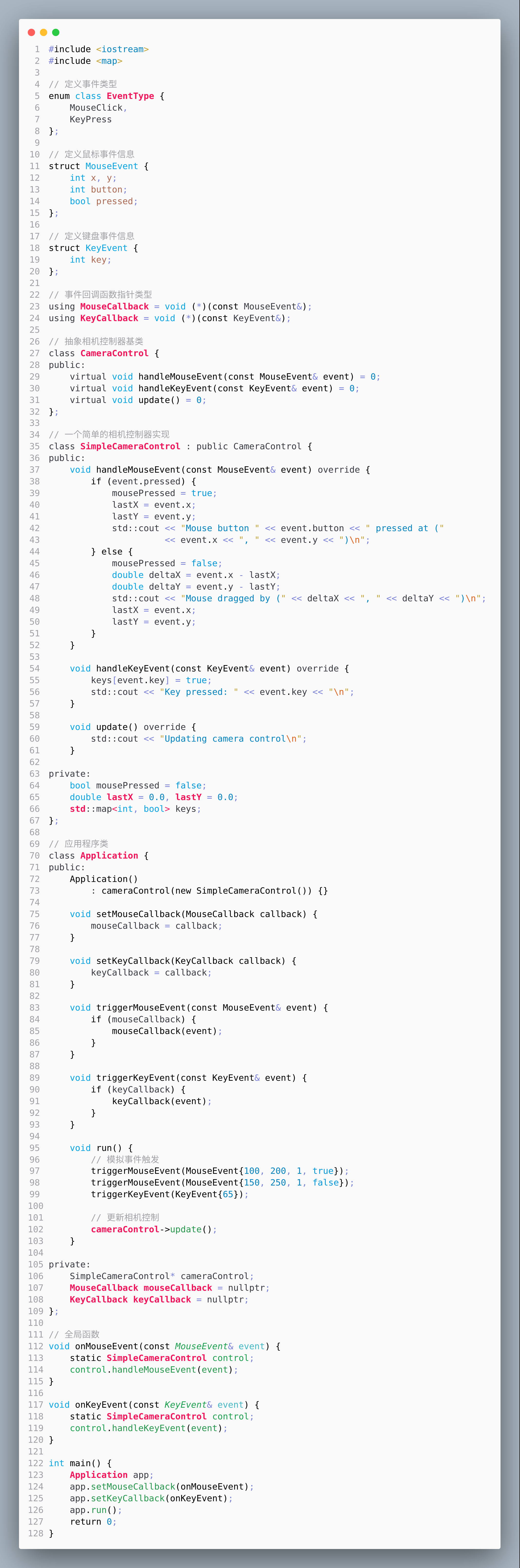
OpenGL笔记之事件驱动设计将相机控制类和应用程序类分离
OpenGL笔记之事件驱动设计将相机控制类和应用程序类分离 —— 2024-10-02 下午 bilibili赵新政老师的教程看后笔记 code review! 文章目录 OpenGL笔记之事件驱动设计将相机控制类和应用程序类分离1.代码图片2.分析3.UML4.代码 1.代码图片 运行 Mouse button 1 pressed at (1…...

低代码时代的企业信息化:规范与标准化的重要性
在当今数字化转型的浪潮中,企业的信息化建设正逐步向低代码平台倾斜。低代码不仅仅是简化开发过程,更是对企业内部流程、规范和标准化的深刻理解与应用。本文将探讨低代码在企业信息化中的重要性,特别是在运维和开发流程中的标准化࿰…...

理解无监督学习、无监督图像分割
系列文章目录 文章目录 系列文章目录一、无监督学习如何学习 能不能举一个非常具体的例子,带着运算过程的例子总结 二、在图像分割中呢,具体怎样实现无监督示例:使用自编码器和k-means进行无监督图像分割1. **数据准备**2. **构建自编码器**3…...

C语言— exec系列函数
exec系列函数 在C语言编程中,exec 系列函数用于在当前进程中执行一个新程序,从而替换当前进程的映像。这些函数不会返回,除非发生错误。exec 系列函数有多个变体,其中最常用的包括 execl, execle, execlp, execv, execve, execvp…...
命名管道Linux
管道是 毫不相关的进程进程间通信::命名管道 管道 首先自己要用用户层缓冲区,还得把用户层缓冲区拷贝到管道里,(从键盘里输入数据到用户层缓冲区里面),然后用户层缓冲区通过系统调用(write)写…...
【ios】---swift开发从入门到放弃
swift开发从入门到放弃 环境swift入门变量与常量类型安全和类型推断print函数字符串整数双精度布尔运算符数组集合set字典区间元祖可选类型循环语句条件语句switch语句函数枚举类型闭包数组方法结构体 环境 1.在App Store下载Xcode 2.新建项目(可以先使用这个&…...
【AUTOSAR 基础软件】PduR模块详解(通信路由)
文章包含了AUTOSAR基础软件(BSW)中PduR模块相关的内容详解。本文从AUTOSAR规范解析,ISOLAR-AB配置以及模块相关代码分析三个维度来帮读者清晰的认识和了解PduR这一基础软件模块。文中涉及的ISOLAR-AB配置以及模块相关代码都是依托于ETAS提供的…...

[控制理论]—差分变换法与双线性变换法的基本原理和代码实现
差分变换法与双线性变换法的基本原理和代码实现 1.差分变换法 差分变换法就是把微分方程中的导数用有限差分来近似等效,得到一个与原微分方程逼近的差分方程。 差分变换法包括后向差分与前向差分。 1.1 后向差分法 差分变换如下: d e ( t ) d t e…...
【JavaEE】——多线程常用类
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 引入: 一:Callable和FutureTask类 1:对比Runnable 2:…...
Cilium-Multi Networking-多网络)
Cilium-实战系列-(二)Cilium-Multi Networking-多网络
一、Cilium必要开启的功能 1、enable-multi-network 2、ipam模式选择:multi-pool 二、涉及的CRD资源 1、 ciliumpodippools.cilium.io *通过Cilium管理节点上的pod cidr.网络分为主网络和第二网络。 *主网络的 ciliumpodippools.cilium.io default根据配置文件默认生成的。 …...
springboot自动配置
自动配置的核心就在SpringBootApplication注解上,SpringBootApplication这个注解 底层包含了3个注解,分别是: SpringBootConfiguration ComponentScan EnableAutoConfiguration EnableAutoConfiguration这个注解才是自动配置的核心,它 封…...

mock数据,不使用springboot的单元测试
业务代码 package com.haier.configure.service.impl;import com.baomidou.mybatisplus.core.toolkit.Wrappers; import com.baomidou.mybatisplus.extension.service.impl.ServiceImpl; import com.haier.common.util.RequestUtil; import com.haier.configure.entity.Langua…...
【pytorch】pytorch入门5:最大池化层(Pooling layers )
文章目录 前言一、定义概念 缩写二、参数三、最大池化操作四、使用步骤总结参考文献 前言 使用 B站小土堆课程 一、定义概念 缩写 池化(Pooling)是深度学习中常用的一种操作,用于降低卷积神经网络(CNN)或循环神经网…...

职场上的人情世故,你知多少?这五点一定要了解
职场是一个由人组成的复杂社交网络,人情世故在其中起着至关重要的作用。良好的人际关系可以帮助我们更好地融入团队,提升工作效率,甚至影响职业发展。在职场中,我们需要了解一些关键要素,以更好地处理人际关系…...

Python | Leetcode Python题解之第456题132模式
题目: 题解: class Solution:def find132pattern(self, nums: List[int]) -> bool:candidate_i, candidate_j [-nums[0]], [-nums[0]]for v in nums[1:]:idx_i bisect.bisect_right(candidate_i, -v)idx_j bisect.bisect_left(candidate_j, -v)if…...

【重学 MySQL】五十四、整型数据类型
【重学 MySQL】五十四、整型数据类型 整型类型TINYINTSMALLINTMEDIUMINTINT(或INTEGER)BIGINT 可选属性UNSIGNEDZEROFILL显示宽度(M)AUTO_INCREMENT注意事项 适合场景TINYINTSMALLINTMEDIUMINTINT(或INTEGER࿰…...

查看 Git 对象存储中的内容
查看 Git 对象存储中的内容 ls -C .git/objects/<dir>ls: 列出目录内容的命令。-C: 以列的形式显示内容。.git/objects/<dir>: .git 是存储仓库信息的 Git 目录,objects 是其中存储对象的子目录。<dir> 是对象存储目录下的一个特定的子目录。 此…...

这五家软件许可优化的公司,我直接说结论。
你要是搞工程设计软件的(CAD、SolidWorks、CATIA这些),在国内,闭眼找。 你要是啥软件都有一大堆,不差钱人也多,上OptiCore(优化内核)。 你要是全在云上跑、主用微软全家桶…...

PowerBI主题模板终极指南:35款专业模板一键美化数据报表
PowerBI主题模板终极指南:35款专业模板一键美化数据报表 【免费下载链接】PowerBI-ThemeTemplates Snippets for assembling Power BI Themes 项目地址: https://gitcode.com/gh_mirrors/po/PowerBI-ThemeTemplates 还在为PowerBI报表的单调外观而烦恼吗&…...

Cursor Pro破解工具完整指南:三步实现永久免费使用AI编程助手
Cursor Pro破解工具完整指南:三步实现永久免费使用AI编程助手 【免费下载链接】cursor-free-vip [Support 0.45](Multi Language 多语言)自动注册 Cursor Ai ,自动重置机器ID , 免费升级使用Pro 功能: Youve reached y…...

ComfyUI InstantID终极指南:3步实现人脸完美保留的AI图像生成
ComfyUI InstantID终极指南:3步实现人脸完美保留的AI图像生成 【免费下载链接】ComfyUI_InstantID 项目地址: https://gitcode.com/gh_mirrors/co/ComfyUI_InstantID 你是否曾经尝试过用AI生成图像,却发现生成的人物完全不像你想要的参考对象&am…...

从零实现一个电商图片下载器:技术方案与核心代码
引言如果你想自己开发一款电商图片下载工具,本文提供完整的技术方案和核心代码参考。一、技术选型组件推荐方案备选方案浏览器内核CEFElectron下载库libcurlrequests界面框架QtElectron跨平台CEF QtElectron二、核心代码实现2.1 浏览器初始化cppCefRefPtr<CefBr…...

深拷贝和浅拷贝深入讲解
What? 浅拷贝和深拷贝发生在对象和对象之间,假设你需要将一个对象的值赋予给另一个对象,这个过程就叫做拷贝。那么拷贝的过程中,对象的属性中可能既有普通变量也有对象,能够复制后副本对象的引用指向新地址的就是深拷贝ÿ…...

抖音直播数据采集:如何用Golang构建实时弹幕监控系统
抖音直播数据采集:如何用Golang构建实时弹幕监控系统 【免费下载链接】douyin-live-go 抖音(web) 弹幕爬虫 golang 实现 项目地址: https://gitcode.com/gh_mirrors/do/douyin-live-go 在直播电商和内容创作日益火爆的今天,数据驱动的运营决策变得…...

技术驱动财税革新,用友小畅 AI 以大模型重构行业生态
人工智能技术的快速发展,正在深刻改变各个行业的面貌,财税行业也不例外。大模型技术的应用,让财务软件从传统的工具型产品向智能型产品转变,彻底重构了传统的财税工作流。作为行业龙头,用友集团率先将大模型技术应用于…...

Vue SSR实战:如何用Express + Webpack-dev-middleware实现开发环境热更新与内存编译?
Vue SSR开发环境优化:Express与Webpack-dev-middleware深度整合指南 1. 为什么需要开发环境热更新? 在传统Vue SSR项目开发中,每次代码修改后都需要手动重启服务并刷新浏览器,这种开发体验对于中型以上项目来说效率极低。想象一…...

ComfyUI Manager 架构设计与性能优化:从插件管理到系统集成的完整解决方案
ComfyUI Manager 架构设计与性能优化:从插件管理到系统集成的完整解决方案 【免费下载链接】ComfyUI-Manager ComfyUI-Manager is an extension designed to enhance the usability of ComfyUI. It offers management functions to install, remove, disable, and e…...