LSTM模型变种
LSTM模型变种
一、GRU
1.什么是GRU
GRU(Gated Recurrent Unit)是一种循环神经网络(RNN)的变体,它被设计用来解决传统RNN在处理长序列时可能遇到的梯度消失或梯度爆炸问题。GRU通过引入门控机制来控制信息的流动,使得模型能够更好地捕捉长时间依赖关系。
GRU的主要特点在于它的结构比LSTM(Long Short-Term Memory)更简单,因为它只有一个隐藏状态,而没有像LSTM那样的细胞状态。尽管如此,GRU仍然能够有效地学习长期依赖,并且通常计算效率更高。
2.GRU的基本结构
一个GRU单元包含两个主要的门:重置门(Reset Gate)和更新门(Update Gate)。这些门的作用是决定如何将新输入的信息与先前的记忆相结合。
- 重置门( r t r_t rt)决定了前一时刻的状态 h t − 1 h_{t−1} ht−1 有多少信息会被用于当前时刻的候选激活 $\tilde{h}_t $的计算。
- 更新门( z t z_t zt)决定了前一时刻的状态 h t − 1 h_{t−1} ht−1 和当前时刻的候选激活 h ~ t \tilde{h}_t h~t 如何结合以产生当前时刻的状态 h t h_t ht。
3.模型结构
模型图:

内部结构:



4.代码实现
原理实现
import numpy as npclass GRU:def __init__(self, input_size, hidden_size):self.input_size = input_sizeself.hidden_size = hidden_size# 初始化参数和偏置# 更新门self.W_z = np.random.randn(hidden_size, hidden_size+input_size)self.b_z = np.zeros(hidden_size)# 重置门self.W_r = np.random.randn(hidden_size, hidden_size + input_size)self.b_r = np.zeros(hidden_size)# 候选隐藏状态self.W_h = np.random.randn(hidden_size, hidden_size + input_size)self.b_h = np.zeros(hidden_size)def tanh(self, x):return np.tanh(x)def sigmoid(self, x):return 1 / (1 + np.exp(-x))def forward(self, x):# 初始化隐藏状态h_prev = np.zeros((self.hidden_size, ))concat_input = np.concatenate([x, h_prev], axis=0)z_t = self.sigmoid(np.dot(self.W_z, concat_input) + self.b_z)r_t = self.sigmoid(np.dot(self.W_r, concat_input) + self.b_r)concat_reset_input = np.concatenate([x, r_t*h_prev], axis=0)h_hat_t = self.tanh(np.dot(self.W_h, concat_reset_input) + self.b_h)h_t = (1 - z_t) * h_prev + z_t * h_hat_treturn h_t# 测试数据
input_size = 3
hidden_size = 2
seq_len = 4x = np.random.randn(seq_len, input_size)
gru = GRU(input_size, hidden_size)all_h = []
for t in range(seq_len):h_t = gru.forward(x[t, :])all_h.append(h_t)print(np.array(all_h).shape)nn.GRUCell
import torch.nn as nn
import torchclass GRUCell(nn.Module):def __init__(self, input_size, hidden_size):super(GRUCell, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.gru_cell = nn.GRUCell(input_size, hidden_size)def forward(self, x):h_t = self.gru_cell(x)return h_t# 测试数据
input_size = 3
hidden_size = 2
seq_len = 4gru_model = GRUCell(input_size, hidden_size)x = torch.randn(seq_len, input_size)all_h = []
for t in range(seq_len):h_t = gru_model(x[t])all_h.append(h_t)print(all_h)nn.GRU
import torch.nn as nn
import torchclass GRU(nn.Module):def __init__(self, input_size, hidden_size):super(GRU, self).__init__()self.input_size = input_sizeself.hidden_size = hidden_sizeself.gru = nn.GRU(input_size, hidden_size)def forward(self, x):out = self.gru(x)return out# 测试数据
input_size = 3
hidden_size = 2
seq_len = 4
batch_size = 5x = torch.randn(seq_len, batch_size, input_size)gru_model = GRU(input_size, hidden_size)out = gru_model(x)print(out)二、BiLSTM
1.什么是BiLSTM
BiLSTM(Bidirectional Long Short-Term Memory)是LSTM的一种扩展,它通过同时考虑序列的前向和后向信息来增强模型对序列数据的理解。传统的LSTM只能从过去到未来单方向处理序列,而BiLSTM则能够同时捕捉到序列中每个时间点上的前后文信息,从而提高模型在许多任务中的表现。
2.BiLSTM的工作原理
在BiLSTM中,对于每个时间步t,模型包含两个独立的LSTM层:
- 前向LSTM:按照正常的时间顺序处理输入序列,即从第一个时间步到最后一个时间步。
- 后向LSTM:以相反的时间顺序处理输入序列,即从最后一个时间步到第一个时间步。
这两个LSTM层分别输出一个隐藏状态,然后将这两个隐藏状态拼接起来形成最终的隐藏状态。这个拼接后的隐藏状态可以用来做进一步的预测或计算。

优点:
- 上下文感知:BiLSTM可以利用整个序列的信息,因此对于需要理解上下文的任务特别有效。
- 更好的性能:由于它可以捕捉更丰富的序列信息,通常在诸如命名实体识别、情感分析等自然语言处理任务上表现出色。
3.标注集
BMES标注:汉字作为词语开始Begin,结束End,中间Middle,单字Single,这四种情况就可以囊括所有的分词情况。比如“参观了北京天安门”这句话的标注结果就是BESBEBME
词性标注
4.代码实现
原理实现
import numpy as np
import torchclass BILSTM:def __init__(self, input_size, hidden_size, output_size):# 参数:词向量大小,隐藏层大小, 输出类别self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size# 正向self.lstm_forward = LSTM(input_size, hidden_size, output_size)# 反向self.lstm_backward = LSTM(input_size, hidden_size, output_size)def forward(self, x):# 正向LSTMoutput, _, _ = self.lstm_forward.forward(x)# 反向LSTM,np.flip是将数组进行翻转output_backward, _, _ = self.lstm_backward.forward(np.flip(x))# 合并两层的隐藏状态combine_output = [np.concatenate((x, y), axis=0) for x, y in zip(output, output_backward)]return combine_outputclass LSTM:def __init__(self, input_size, hidden_size, output_size):# 参数:词向量大小,隐藏层大小, 输出类别self.input_size = input_sizeself.hidden_size = hidden_sizeself.output_size = output_size# 初始化权重,偏置,把结构的W,U拼接在一起self.W_f = np.random.rand(hidden_size, input_size+hidden_size)self.b_f = np.random.rand(hidden_size)self.W_i = np.random.rand(hidden_size, input_size + hidden_size)self.b_i = np.random.rand(hidden_size)self.W_c = np.random.rand(hidden_size, input_size + hidden_size)self.b_c = np.random.rand(hidden_size)self.W_o = np.random.rand(hidden_size, input_size + hidden_size)self.b_o = np.random.rand(hidden_size)# 输出层self.W_y = np.random.rand(output_size, hidden_size)self.b_y = np.random.rand(output_size)def tanh(self, x):return np.tanh(x)def sigmoid(self, x):return 1/(1+np.exp(-x))def forward(self, x):# 初始化隐藏状态h_t = np.zeros((self.hidden_size,))# 初始化细胞状态c_t = np.zeros((self.hidden_size,))h_states = [] # 存储每一个时间步的隐藏状态c_states = [] # 存储每一个时间步的细胞状态for t in range(x.shape[0]):x_t = x[t] # 获取当前时间步的输入(一个词向量)# 将x_t和h_t进行垂直方向拼接x_t = np.concatenate([x_t, h_t])# 遗忘门 "dot"迷茫中,这里是点积的效果,(5,7)点积(7,)得到的是(5,)f_t = self.sigmoid(np.dot(self.W_f, x_t) + self.b_f)# 输出门i_t = self.sigmoid(np.dot(self.W_i, x_t) + self.b_i)# 候选细胞状态c_hat_t = self.tanh(np.dot(self.W_c, x_t) + self.b_c)# 更新细胞状态, "*"对应位置直接相乘c_t = f_t * c_t + i_t * c_hat_t# 输出门o_t = self.sigmoid(np.dot(self.W_o, x_t) + self.b_o)# 更新隐藏状态h_t = o_t * self.tanh(c_t)# 保存时间步的隐藏状态和细胞状态h_states.append(h_t)c_states.append(c_t)# 输出层,分类类别y_t = np.dot(self.W_y, h_t) + self.b_youtput = torch.softmax(torch.tensor(y_t), dim=0)return np.array(h_states), np.array(c_states), output# 测试数据
input_size = 3
hidden_size = 2
seq_len = 4x = np.random.randn(seq_len, input_size)
bilstm = BILSTM(input_size, hidden_size, 5)
out = bilstm.forward(x)print(out)
print(np.array(out).shape)API的使用
import torch
import torch.nn as nn
import numpy as npclass BiLstm(nn.Module):def __init__(self, input_size, hidden_size, output_size):super(BiLstm, self).__init__()# 定义双向LSTMself.lstm = nn.LSTM(input_size, hidden_size, bidirectional=True)# 因为双向的,所以第一个参数是隐藏层的的二倍self.linear = nn.Linear(hidden_size*2, output_size)def forward(self, x):out, _ = self.lstm(x)out = self.linear(out)return out# 测试数据
input_size = 3
hidden_size = 8
seq_len = 4
output_size = 5
batch_size = 6x = torch.randn(seq_len, batch_size, input_size)bilstm = BiLstm(input_size, hidden_size, output_size)output = bilstm(x)print(output.shape)相关文章:
LSTM模型变种
LSTM模型变种 一、GRU 1.什么是GRU GRU(Gated Recurrent Unit)是一种循环神经网络(RNN)的变体,它被设计用来解决传统RNN在处理长序列时可能遇到的梯度消失或梯度爆炸问题。GRU通过引入门控机制来控制信息的流动&…...
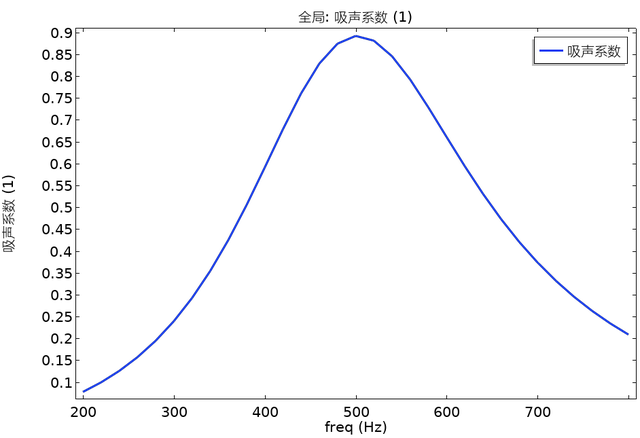
基于comsol模拟微穿孔板和卷曲通道的混合吸声器低频吸声
研究背景: 具有深亚波长厚度(5cm)的吸收器对低频声音(<500Hz)的衰减在噪声控制工程中引起了极大的兴趣。然而,由于低频声音的强穿透性和普通材料的弱固有分散性,这是一项具有挑战性的任务。…...

Ajax ( 是什么、URL、axios、HTTP、快速收集表单 )Day01
AJAX 一、Ajax是什么1.1名词解释1.1.1 服务器1.1.2 同步与异步1. 同步(Synchronous)2. 异步(Asynchronous)3. 异步 vs 同步 场景4. 异步在 Web 开发中的常见应用: 1.2 URL 统一资源定位符1.2.1 URL - 查询参数1.2.2 ax…...

【Java 循环控制实例详解【While do... while】】
Java 循环控制详解【While & do… while】 在 Java 中,循环控制是程序设计中非常重要的部分,主要包括 while 循环和 do...while 循环。本文将详细介绍这两种循环的基本语法、执行流程及相关示例。 1. while 循环控制 基本语法 循环变量初始化; wh…...

10.2 Linux_进程_进程相关函数
创建子进程 函数声明如下: pid_t fork(void); 返回值:失败返回-1,成功返回两次,子进程获得0(系统分配),父进程获得子进程的pid 注意:fork创建子进程,实际上就是将父进程复制一遍作为子进程&…...

栈与队列面试题(Java数据结构)
前言: 这里举两个典型的例子,实际上该类型的面试题是不确定的! 用栈实现队列: 232. 用栈实现队列 - 力扣(LeetCode) 方法一:双栈 思路 将一个栈当作输入栈,用于压入 push 传入的数…...

手撕数据结构 —— 顺序表(C语言讲解)
目录 1.顺序表简介 什么是顺序表 顺序表的分类 2.顺序表的实现 SeqList.h中接口总览 具体实现 顺序表的定义 顺序表的初始化 顺序表的销毁 打印顺序表 编辑 检查顺序表的容量 尾插 尾删 编辑 头插 头删 查找 在pos位置插入元素 删除pos位置的值 …...

女友学习前端第二天-笔记
2024/10/8笔记 表格 table 表格 tr 行 td 单元格内容 th 表头 第一行相当于h1 alignleft /center /right 对齐方式 应在table边上 比如<table alignleft> border 代表边框 也应在table边上 比如<table alignleft border"1"> cellpadding 单元外框与…...

电脑手机下载小米xiaomi redmi刷机包太慢 解决办法
文章目录 修改前下载速度修改后下载速度修改方法(修改host) 修改前下载速度 一开始笔者以为是迅雷没开会员的问题,在淘宝上买了一个临时会员后下载速度依然最高才100KB/s 修改后下载速度 修改方法(修改host) host文…...

Python中的策略模式:解锁编程的新维度
引言 策略模式是一种行为型设计模式,允许算法独立于使用它的客户端而变化。这使得我们可以根据不同的情况选择不同的算法或策略来解决问题,从而增强系统的灵活性。在日常开发中,策略模式常用于处理多种算法或行为之间的切换,比如…...
的概念和使用方法)
ara::core::Future::then()的概念和使用方法
1. 概念 在ara::core::Future的上下文中,then()是一种用于处理异步操作结果的机制。一个Future代表一个尚未完成的异步计算,它最终会产生一个结果或者一个错误。then()方法允许你在Future完成时注册一个回调函数(或者说后续操作)…...

九、5 USART串口数据包
数据包作用:把一个个单独的数据给打包起来,将同一批的数据进行打包和分割,方便接收方进行识别,方便我们进行多字节的数据通信。 1、串口收发HEX数据包 (1)数据包的格式是个人规定的,如以FF为包…...

SQL第12课——联结表
三点:什么是联结?为什么使用联结?如何编写使用联结的select语句 12.1 联结 SQL最强大的功能之一就是能在数据查询的执行中联结(join)表。联结是利用SQL的select能执行的最重要的操作。 在使用联结前,需要了解关系表…...

CentOS7 虚拟机操作系统安装及相关配置教程
1、安装虚拟机 在VMware《主页》界面中点击《创建新的虚拟机》按钮: 选择你准备好的ISO文件,点击下一步: 然后填写虚拟机的名称以及虚拟机将来保存的位置: 再次下一步,填写虚拟机磁盘大小: 继续下一步&…...

『网络游戏』窗口基类【06】
创建脚本:WindowRoot.cs 编写脚本: 修改脚本:LoginWnd.cs 修改脚本:LoadingWnd.cs 修改脚本:ResSvc.cs 修改脚本:LoginSys.cs 运行项目 - 功能不变 本章结束...

04_23 种设计模式之《单例模式》
文章目录 一、单例模式基础知识单例模式有 3 个特点: 单例模式(Singleton Pattern)是一种创建型设计模式,它确保一个类只有一个实例,并提供一个全局访问点来获取这个实例。这种模式通常用于管理共享资源,如…...
视频加字幕用什么软件最快?12款工具快速添加字幕!
对于大多数同学来讲,剪辑中比较头疼的就是如何给视频加字幕和唱词啦,特别是用Pr或者FCXP等专业剪辑软件,加字幕也是特别费时的,哪怕是有批量添加的功能orz... 虽然关于这方面的内容已经很多啦,但是真正全面的内容还特…...

C++:string (用法篇)
文章目录 前言一、string 是什么?二、C语法补充1. auto2. 范围for 三、string类对象的常见构造1. Construct string object2. String destructor3. operator 四、string迭代器相关1. begin与end1)begin2)end3)使用 2. rbegin 与 r…...

力扣随机题
最接近原点的K个点 题目 973. 最接近原点的 K 个点 - 力扣(LeetCode) 思路 这就是一道排序题,直接根据公式排序,然后返回对应范围的数组就行了 代码 public int[][] kClosest(int[][] points, int k) {Arrays.sort(points, n…...

CSS样式基础样式选择器(案例+代码实现+效果图)
目录 1.css样式的规则 2.引入css样式的方式 1)行内式 2)内嵌式 3)外链式 1-link导入 2-import导入 4)总 3.css基础选择器 1)标签选择器 案例:使用标签选择器编写一个圆 1.代码 2.效果 2)类选择器 案例:使用类选择器为div添加背景色 1.代码 2.效果 3)id…...

杰理之人声消除会有杂音问题修改方法【篇】
原因:消人声应该以立体声的音频数据来参考处理,由于DAC输出选择了左右差分方式,会在消人声的数据流节点前加了一个节点将右边声道进行反相处理,导致消原音的数据不是立体声数据,消除效果不好。...

终极游戏光标解决方案:YoloMouse让你的鼠标在游戏中清晰可见
终极游戏光标解决方案:YoloMouse让你的鼠标在游戏中清晰可见 【免费下载链接】YoloMouse Game Cursor Changer 项目地址: https://gitcode.com/gh_mirrors/yo/YoloMouse 你是否曾在激烈的游戏战斗中迷失了鼠标光标?当屏幕上特效绚烂、技能乱飞时&…...

深度解析 SGLang 框架 Wan2.1 视频生成加速技术:从 49 分钟到 1 分钟的极致优化
Wan2.1 作为当前开源视频生成模型的标杆,其 14B 参数版本在生成质量上已经达到了商业级水准,但原生推理速度却令人望而却步:单卡 A800 生成一段 5 秒 720P 视频需要近 50 分钟。 本文基于真实生产环境的运行日志和 SGLang 源码深度分析&…...

强烈推荐!这款顶伯 工具拯救了我的日更视频账号
强烈推荐!这款顶伯 TTS 工具拯救了我的日更视频账号做日更视频账号最痛苦的是什么?是配音。 以前我每天花两小时录音、降噪、剪辑,嗓子还经常哑。直到用了顶伯文字转语音工具,一切都变了。它基于微软 TTS 技术,音质自然…...

避坑指南:全志T113-S3连接EC200A模块,搞定RNDIS驱动与自动拨号的那些坑
全志T113-S3与EC200A模块深度调优:从RNDIS驱动到稳定联网的完整实战 在物联网设备开发中,4G模块的集成往往是项目成败的关键节点之一。全志T113-S3作为一款高性能嵌入式处理器,与移远EC200A 4G模块的组合在工业控制、智能终端等领域应用广泛。…...

智慧养殖与猪行为实例分割数据集 动物行为分析数据集 生猪进食数据集 生猪睡觉站立姿态识别数据集 yolo格式数据集
猪行为实例分割数据集核心信息 类别 Tags 标签 Instance Segmentation 实例分割 Model 模型Classes (4) 类别(4) Eating 进食 Lying 躺着 Sitting 坐着 Standing 站立数据集关键信息表信息类别具体内容数据集类别猪行为实例分割数据集,聚焦猪…...

AutoCAD字体管理终极指南:如何彻底解决字体缺失问题
AutoCAD字体管理终极指南:如何彻底解决字体缺失问题 【免费下载链接】FontCenter AutoCAD自动管理字体插件 项目地址: https://gitcode.com/gh_mirrors/fo/FontCenter 还在为AutoCAD字体缺失问题而烦恼吗?FontCenter是您的专业字体管理解决方案&a…...
)
SAP ABAP SM30表维护:手把手教你实现‘运费类型’重复描述校验(附完整代码与避坑指南)
SAP ABAP SM30表维护实战:运费类型唯一性校验的深度解析 在物流管理系统中,运费类型的定义往往需要遵循严格的业务规则。一个常见的需求是确保"运输类型运费代码"与"运费描述"的组合具有唯一性,避免因描述重复导致的操作…...

如何快速上手Orbit:新手入门10个技巧 [特殊字符]
如何快速上手Orbit:新手入门10个技巧 🚀 【免费下载链接】orbit Experimental spaced repetition platform for exploring ideas in memory augmentation and programmable attention 项目地址: https://gitcode.com/gh_mirrors/orbit1/orbit Orb…...

手把手教你用复旦微FM7Z045芯片在线调试DDR:JTAG与QSPI模式切换避坑指南
复旦微FM7Z045芯片DDR调试实战:模式切换与JTAG连接深度解析 第一次拿到复旦微FM7Z045开发板时,许多工程师都会遇到一个令人困惑的问题——明明按照手册步骤操作,DDR调试却总是失败。这往往不是代码问题,而是模式选择不当导致的。本…...