TinyAgent: 从零开始构建最小化Agent系统
引言
随着大模型(LLM)的崛起,特别是ChatGPT等大模型的广泛应用,基于LLM的系统越来越受欢迎。然而,尽管大模型具备强大的生成能力和推理能力,它们在处理某些专有领域或实时问题时仍然存在局限性。因此,结合工具和Agent的概念,增强大模型的实时交互能力,成为解决问题的关键方法。
本文将从零开始,手动构建一个基于React方式的最小化Agent结构,我们称之为TinyAgent。本文会展示如何通过结合LLM与外部工具的方式,赋予大模型实时处理问题的能力。
实现细节
Step 1: 构建大模型
首先,我们需要加载一个大模型作为核心,这里我们选择InternLM2模型。InternLM2是一个Decoder-Only的对话大模型,具备较强的生成能力。我们可以使用transformers库来加载并运行该模型。
首先,我们定义一个通用的大模型基类BaseModel,该类用于加载模型和处理输入输出。
class BaseModel:def __init__(self, path: str = '') -> None:self.path = pathdef chat(self, prompt: str, history: List[dict]):passdef load_model(self):pass
然后,我们实现一个继承自BaseModel的类InternLM2Chat,这个类实现了具体的模型加载和与模型对话的方法。
class InternLM2Chat(BaseModel):def __init__(self, path: str = '') -> None:super().__init__(path)self.load_model()def load_model(self):print('================ Loading model ================')self.tokenizer = AutoTokenizer.from_pretrained(self.path, trust_remote_code=True)self.model = AutoModelForCausalLM.from_pretrained(self.path, torch_dtype=torch.float16, trust_remote_code=True).cuda().eval()print('================ Model loaded ================')def chat(self, prompt: str, history: List[dict], meta_instruction: str = '') -> str:response, history = self.model.chat(self.tokenizer, prompt, history, temperature=0.1, meta_instruction=meta_instruction)return response, history
Step 2: 构造工具
接下来,我们定义工具类,支持外部功能的调用,比如Google搜索。通过这些工具,可以扩展大模型的能力,从而处理实时或专有领域的任务。
我们首先定义工具的描述信息,并在类Tools中实现具体的工具操作。
class Tools:def __init__(self) -> None:self.toolConfig = self._tools()def _tools(self):tools = [{'name_for_human': '谷歌搜索','name_for_model': 'google_search','description_for_model': '谷歌搜索是一个通用搜索引擎,可用于访问互联网、查询百科知识、了解时事新闻等。','parameters': [{'name': 'search_query','description': '搜索关键词或短语','required': True,'schema': {'type': 'string'},}],}]return toolsdef google_search(self, search_query: str):url = "https://google.serper.dev/search"payload = json.dumps({"q": search_query})headers = {'X-API-KEY': '你的API_KEY','Content-Type': 'application/json'}response = requests.request("POST", url, headers=headers, data=payload).json()return response['organic'][0]['snippet']
Step 3: 构建Agent
接下来,我们创建一个Agent类,实现ReAct(Reasoning and Acting)范式的Agent。这个Agent可以通过LLM处理输入,并在需要时调用工具。
我们需要构造system_prompt,让模型了解可以使用哪些工具,以及如何调用这些工具。
class Agent:def __init__(self, path: str = '') -> None:self.path = pathself.tool = Tools()self.system_prompt = self.build_system_input()self.model = InternLM2Chat(path)def build_system_input(self):tool_descs, tool_names = [], []for tool in self.tool.toolConfig:tool_descs.append(TOOL_DESC.format(**tool))tool_names.append(tool['name_for_model'])tool_descs = '\n\n'.join(tool_descs)tool_names = ','.join(tool_names)sys_prompt = REACT_PROMPT.format(tool_descs=tool_descs, tool_names=tool_names)return sys_prompt
通过system_prompt,我们告知模型可以使用哪些工具,以及如何格式化输入输出。
然后,我们实现一个解析工具调用的逻辑,模型通过解析用户输入决定何时调用工具,并将结果返回。
def parse_latest_plugin_call(self, text):plugin_name, plugin_args = '', ''i = text.rfind('\nAction:')j = text.rfind('\nAction Input:')k = text.rfind('\nObservation:')if 0 <= i < j: # 如果包含Action和Action Inputif k < j: # 且没有Observationtext = text.rstrip() + '\nObservation:' # 添加Observationk = text.rfind('\nObservation:')plugin_name = text[i + len('\nAction:') : j].strip()plugin_args = text[j + len('\nAction Input:') : k].strip()text = text[:k]return plugin_name, plugin_args, text
最后,整合工具调用和LLM的生成过程。
def text_completion(self, text, history=[]):text = "\nQuestion:" + textresponse, his = self.model.chat(text, history, self.system_prompt)print(response)plugin_name, plugin_args, response = self.parse_latest_plugin_call(response)if plugin_name:response += self.call_plugin(plugin_name, plugin_args)response, his = self.model.chat(response, history, self.system_prompt)return response, his
Step 4: 运行Agent
最后,运行我们的Agent,测试其功能。
if __name__ == '__main__':agent = Agent('/root/share/model_repos/internlm2-chat-7b')response, _ = agent.text_completion(text='周杰伦是哪一年出生的?', history=[])print(response)response, _ = agent.text_completion(text='周杰伦是谁?', history=[])print(response)
结语
通过本文的讲解,我们从零开始构建了一个最小化的Agent系统。我们一步一步地实现了如何结合大语言模型(LLM)与外部工具来增强大模型的实际应用能力。尽管大语言模型在很多任务中展现出了惊人的能力,但在面对特定领域的专有任务或实时性要求较高的场景时,单靠语言模型可能会表现不足。Agent系统的核心理念就是让大模型能够借助外部工具(如搜索引擎、数据库等)来完成更加复杂和个性化的任务。
在本项目中,我们基于React范式设计了一个简单的Agent,通过提供工具描述与交互模板,让模型可以理解如何合理调用外部工具。在我们的示例中,模型能够调用Google搜索引擎来获取实时信息,从而补充大模型在某些领域的知识盲点。这种方式大大拓展了大模型的应用边界,不再仅仅依赖于模型参数内的知识,而是能够动态连接外部信息资源。
Agent系统的意义
- 增强信息获取能力:通过工具接口,模型可以即时获取最新信息或查询外部资源,从而突破模型知识更新滞后的局限性。
- 提高任务处理效率:Agent能够通过合理地调用外部工具,更加快速、准确地完成复杂任务。
- 灵活扩展性:我们构建的系统框架具备高度的扩展性,后续可以通过简单的工具插件接口,轻松接入其他任务场景,如金融数据分析、地理信息查询等。
- 实现智能决策:通过多次推理和工具调用,Agent能够像人类一样通过多步推理,获得更符合问题背景的答案,而不是单一的响应。
通过手搓这个TinyAgent,我们不仅熟悉了ReAct范式的原理与实现,还学习了如何通过系统提示与多次推理循环,让大模型具备更强的推理与行动能力。在未来,我们可以进一步优化该框架,将其应用到更广泛的场景中,如智能客服、实时金融预测、医疗信息查询等。
最后,构建Agent系统为大模型的应用开辟了新的可能性,它不仅提升了大模型的智能化水平,也为探索更复杂的任务提供了技术基础。希望本文的讲解能够帮助你深入理解Agent的运作机制,并激发更多关于大模型与工具结合的创新思路。
如果你觉得这篇博文对你有帮助,请点赞、收藏、关注我,并且可以打赏支持我!
欢迎关注我的后续博文,我将分享更多关于人工智能、自然语言处理和计算机视觉的精彩内容。
谢谢大家的支持!
相关文章:

TinyAgent: 从零开始构建最小化Agent系统
引言 随着大模型(LLM)的崛起,特别是ChatGPT等大模型的广泛应用,基于LLM的系统越来越受欢迎。然而,尽管大模型具备强大的生成能力和推理能力,它们在处理某些专有领域或实时问题时仍然存在局限性。因此&#…...
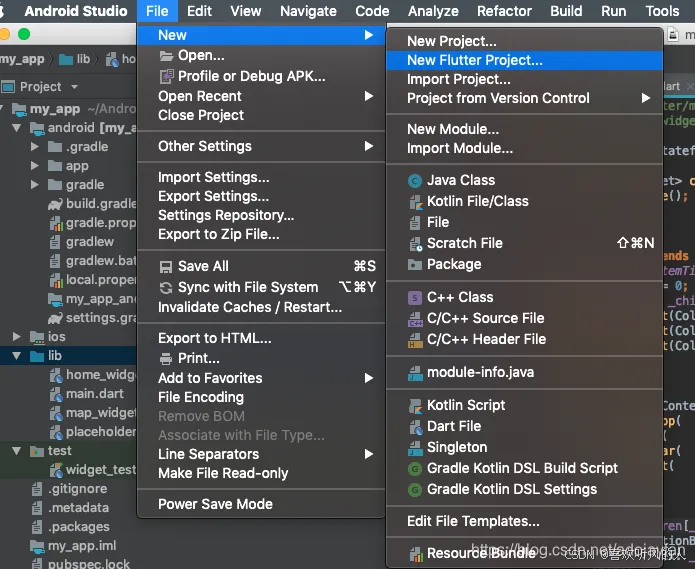
Android Studio New里面没有New Flutter Project
跟着Flutter中文网的配置教程,安装好了flutter,在Android studio里面也安装了dart和flutter的插件。重启后还是在FIle->New里面没有显示New Flutter Project。 反复卸载重装dart和flutter插件好几次,依然没有效果。 原来是没有把Android APK Suppor…...
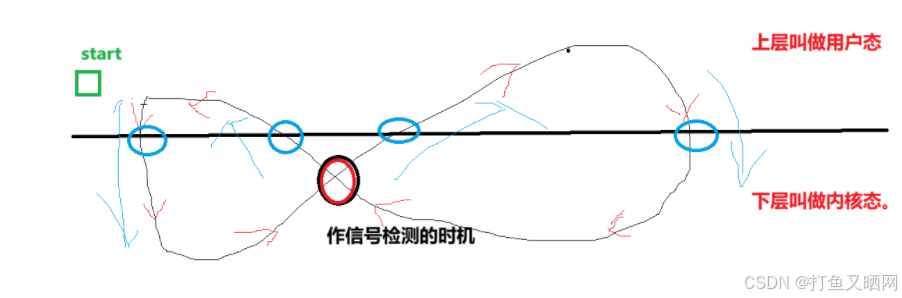
linux信号 | 学习信号四步走 | 透析信号是如何被处理的?
前言:本节内容讲述linux信号的捕捉。 我们通过前面的学习, 已经学习了信号的概念, 信号的产生, 信号的保存。 只剩下信号的处理。 而信号的处理我们应该着重注意的是第三种处理方式——信号的捕捉。 也就是说, 这篇文章…...
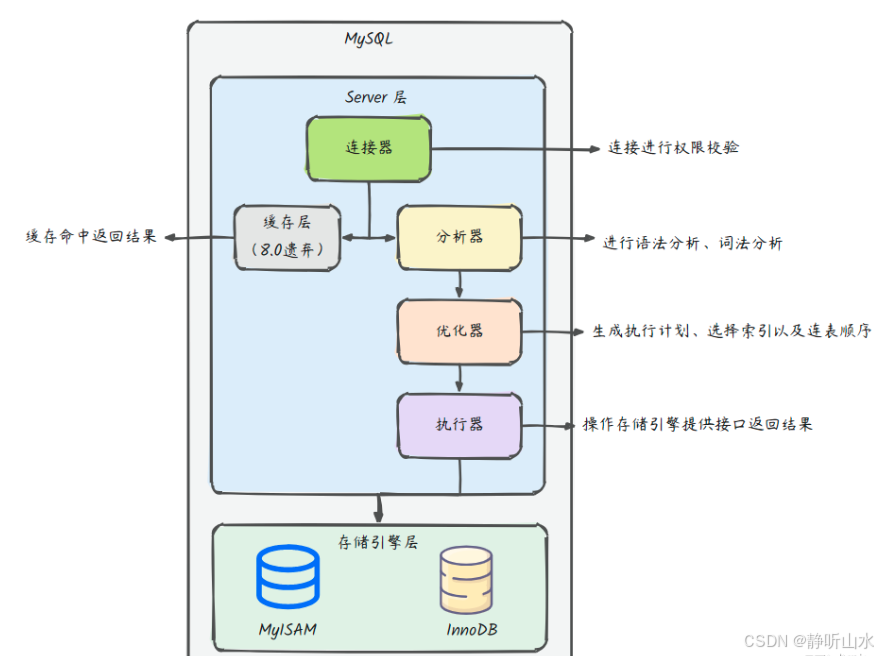
mysql语句执行过程
具体流程如下: 1】当客户端的SOL发送到MySQL时,首先是到达服务器层的连接器,连接器会对你此次发起的连接进行权限校验,以此来获取你这个账号拥有的权限。当你的账号或密码不正确时,会报用户错误。连接成功如果后续没有任何操作&am…...
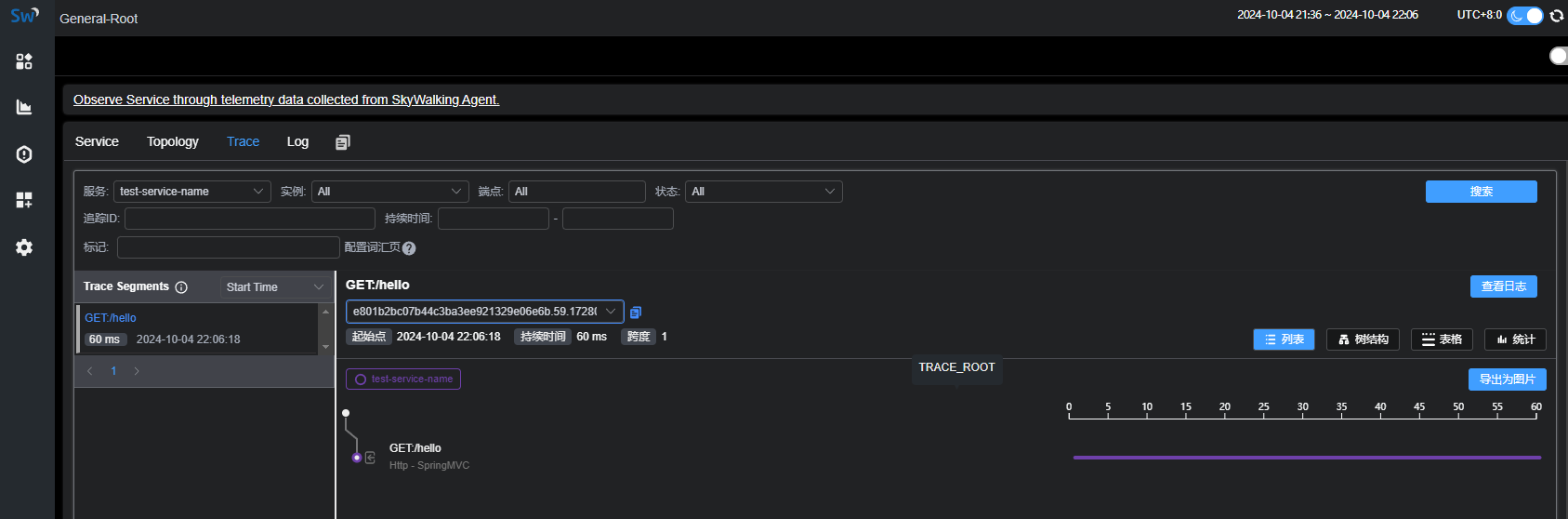
最新版本SkyWalking【10.1.0】部署
这里写目录标题 前言前置条件启动Skywalking下载解压启动说明 集成Skywalking Agent下载Agent在IDEA中添加agent启动应用并访问SpringBoot接口 说明 前言 基于当前最新版10.1.0搭建skywalking 前置条件 装有JDK11版本的环境了解SpringBoot相关知识 启动Skywalking 下载 地…...

WSL2 中配置桥接模式、虚拟交换机及固定 IP
WSL2 中配置桥接模式、虚拟交换机及固定 IP 一、创建虚拟交换机1.1 使用 Hyper-V 管理器创建虚拟交换机1.2 使用 PowerShell 创建虚拟交换机 二、更新 WSL 配置三、设置 WSL2 中的静态 IP、网关和 DNS3.1 编辑网络配置文件3.2 应用网络配置3.3 测试网络连接 四、重启 WSL 在使用…...

Unite Shanghai 2024 团结引擎专场 | 团结引擎 OpenHarmony 工程剖析
在 2024 年 7 月 24 日的 Unite Shanghai 2024 团结引擎专场演讲中,Unity中国 OpenHarmony 技术负责人刘伟贤对团结引擎导出的 OpenHarmony 工程进行了细节剖析,详细讲解 XComponent 如何与引擎结合,UI 线程和引擎线程的关联以及 ts/ets 的代…...
计算机毕业设计 基于Hadoop的智慧校园数据共享平台的设计与实现 Python毕业设计 Python毕业设计选题 Spark 大数据【附源码+安装调试】
博主介绍:✌从事软件开发10年之余,专注于Java技术领域、Python人工智能及数据挖掘、小程序项目开发和Android项目开发等。CSDN、掘金、华为云、InfoQ、阿里云等平台优质作者✌ 🍅文末获取源码联系🍅 👇🏻 精…...
)
2022CCPC绵阳站VP题解报告(CGHMAE六题)
文章目录 2022CCPC绵阳站VP题解报告前言[Problem - C ](https://codeforces.com/gym/104065/problem/C) (签到思维)[H (codeforces.com)](https://codeforces.com/gym/104065/problem/H) (签到构造)[Problem - G ](https://codefo…...

代码随想录day23:贪心part1
455. 分发饼干 class Solution {public int findContentChildren(int[] g, int[] s) {Arrays.sort(g);Arrays.sort(s);int res 0;int index s.length - 1;for(int i g.length - 1; i > 0; i--){if(index > 0 && s[index] > g[i]){res;index--;}}return r…...

通过网页设置参数,submit还是json
在通过网页设置参数并发送到服务器时,选择使用submit(通常是通过HTML表单的提交)还是直接发送JSON数据(通常是通过AJAX请求,如使用fetch API)取决于几个因素,包括你的服务器端如何处理这些请求、…...

C语言 | Leetcode C语言题解之第463题岛屿的周长
题目: 题解: const int dx[4] {0, 1, 0, -1}; const int dy[4] {1, 0, -1, 0};int dfs(int x, int y, int** grid, int n, int m) {if (x < 0 || x > n || y < 0 || y > m || grid[x][y] 0) {return 1;}if (grid[x][y] 2) {return 0;}g…...

逼近理论及应用精解【12】
文章目录 卷积卷积层与滤波层定义数学原理与公式定理架构例子例题 卷积层和滤波层概念的详细解释卷积层滤波层 滤波层和卷积层在卷积神经网络(CNN)中区别滤波层卷积层总结卷积层的数学原理滤波层的数学原理 参考文献 卷积 卷积层与滤波层 定义 卷积层…...

LIN总线学习大全(基于CANoe和CAPL)
🍅 我是蚂蚁小兵,专注于车载诊断领域,尤其擅长于对CANoe工具的使用🍅 寻找组织 ,答疑解惑,摸鱼聊天,博客源码,点击加入👉【相亲相爱一家人】🍅 玩转CANoe&…...
国庆作业
day1 1.开发环境 Linux系统GCCFDBmakefilesqlite3 2.功能描述 项目功能: 服务器:处理客户端的请求,并将数据存入数据库中,客户端请求的数据从数据库进行获取,服务器转发给客户端。 用户客户端:实现账号的注册、登…...
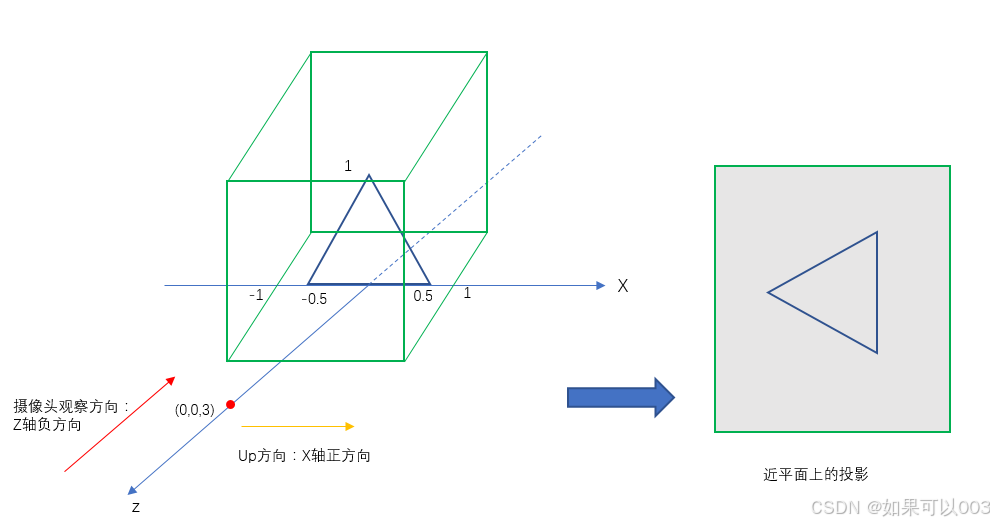
Android OpenGLES2.0开发(四):矩阵变换和相机投影
事物的本质是事物本身所固有的、深藏于现象背后并决定或支配现象的方面。 还记得我们上一篇绘制的三角形吗,我们确实能够顺利用OpenGL ES绘制出图形了,这是一个好的开始,但这还远远不够。我们定义的坐标是正三角形,但是绘制出…...
快递查询软件:实现单号识别与批量物流查询的高效工具
随着网络购物的普及,快递物流行业迎来了前所未有的发展机遇,同时也面临着巨大的挑战。跟踪物流信息成为一个难题,因此,快递查询软件的核心功能之一便是单号识别。传统的快递单号输入方式繁琐且易出错在此背景下,快递查…...
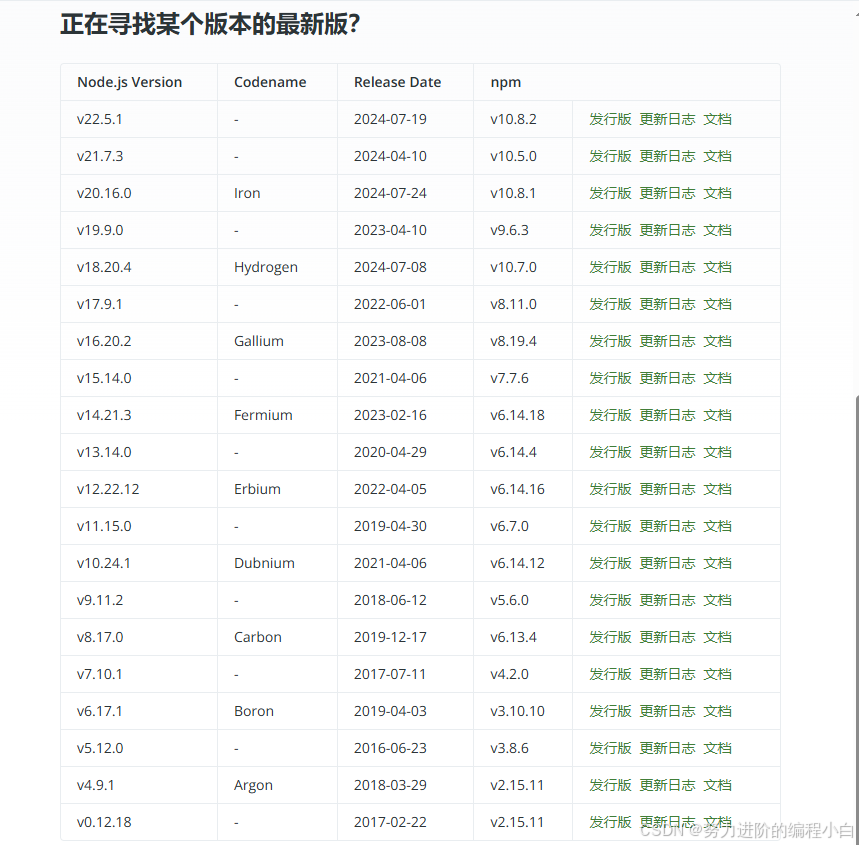
nodejs与npm版本对应表
Node.js — Node.js 版本 (nodejs.org)...

Spring Boot 项目中如何使用异步任务
前置知识: 同步任务: 同步任务是在单线程中按顺序执行,每次只有一个任务在执行,不会引发线程安全和数据一致性等并发问题 同步任务需要等待任务执行完成后才能执行下一个任务,无法同时处理多个任务,响应慢…...

Scrum实战中遇到的问题与解决方法
在当今快速变化的技术环境中,IT企业面临着持续的市场压力和竞争,传统的瀑布式开发模式已经难以满足现代企业的需要。瀑布模型过于僵化,缺乏灵活性,导致项目经常延期,成本增加,最终可能无法达到预期效果。为…...
变成了真实漏洞挖掘指南)
别只当题做!我把CTFshow Web信息搜集题(11-20)变成了真实漏洞挖掘指南
从CTF到实战:Web信息泄露漏洞的企业级攻防指南 当CTF技巧遇上真实世界 深夜两点,某电商平台的安全工程师收到告警——核心数据库正在被异常下载。溯源发现,攻击者竟是通过一个被遗忘的测试接口获取了服务器目录遍历权限。这个场景与CTFshow W…...

ARM嵌入式项目存储选型指南:从eMMC到SD卡,如何平衡性能、可靠性与成本
1. 项目概述:为什么存储选型是ARM嵌入式项目的“命门”?干了十几年嵌入式开发,从早期的ARM7、ARM9到现在的Cortex-A系列,经手的项目少说也有上百个。我发现一个很有意思的现象:很多工程师在选型时,CPU主频、…...

甲级钢制隔热平开防火窗:技术参数、结构工艺与工程应用解析
一、产品概述甲级钢制隔热平开防火窗严格依照国家消防标准制造,采用加厚冷轧镀锌钢板打造框架,搭配防火填充材料、隔热防火玻璃与专用密封配件,防火隔热、密闭性强,耐用抗腐蚀。相较于低等级防火窗,本品耐火隔热性能更…...

AI人才缺口500万:2026年最值得入局的10个职业方向
人社部最新披露的数据让人心惊:我国人工智能相关人才缺口已突破500万,平均10个岗位在抢1个人。 2026年春天,一边是考公大军挤破脑袋,另一边是大厂拿着月薪6万的支票本愁得睡不着觉。智能体开发岗位需求暴涨455%,就连零…...

载肌红蛋白的钆纳米Texaphyrin用于氧协同和成像引导的放射增敏治疗
北京大学王凡教授、中国科学院生物物理研究所史继云研究员和多伦多大学郑钢教授团队在《Nature Communications》(IF16.6)上发表题为“Myoglobin-loaded gadolinium nanotexaphyrins for oxygen synergy and imaging-guided radiosensitization therapy”…...

编写同城公益捐书物资登记流转程序,统计闲置书籍物资,对接公益捐赠渠道。
一个完全去营销化、偏工程与社会创新视角的 Python 示例项目,定位为创新与创业实验课程原型,不绑定任何公益平台、不引导捐赠渠道、不涉及任何机构背书,仅作为物资登记与流转建模工具。 同城公益捐书物资登记流转程序 ——基于物资生命周期管…...

3分钟掌握FlicFlac:高效音频格式转换工具完全指南
3分钟掌握FlicFlac:高效音频格式转换工具完全指南 【免费下载链接】FlicFlac Tiny portable audio converter for Windows (WAV FLAC MP3 OGG APE M4A AAC) 项目地址: https://gitcode.com/gh_mirrors/fl/FlicFlac 在数字音频处理领域,格式兼容性…...

用NE555和立创EDA做个会‘叮咚’的门铃:从原理图到PCB打板的完整DIY记录
从零打造NE555叮咚门铃:立创EDA全流程实战指南 当电子爱好者第一次尝试将电路图转化为实物时,往往会面临软件操作、元件选型和生产对接的多重挑战。本文将以经典NE555叮咚门铃为例,手把手演示如何用立创EDA完成从原理图设计到PCB打板的完整流…...

BUUCTF [ZJCTF 2019]NiZhuanSiWei 通关详解:从PHP伪协议到反序列化的三层渗透
1. 题目初探与源码分析 第一次看到这道题的时候,我盯着屏幕上的PHP源码看了足足五分钟。题目给出了一个简单的PHP文件,要求我们通过三个参数来获取flag。这种层层递进的题目设计在CTF中很常见,但每一步都需要仔细思考。 源码的核心逻辑是这样…...
)
给Hadoop初学者的环境搭建备忘录:为什么你的JDK配置总在重启后‘消失’?(Linux基础解惑)
Hadoop环境搭建中的Linux系统原理:为什么你的配置总在重启后"消失"? 很多Hadoop初学者在搭建开发环境时,都会遇到一个令人困惑的问题:明明按照教程一步步配置好了JDK和Hadoop,为什么重启后环境变量就"消…...