分享:数据库存储与索引技术(一)存储模型与索引结构演变
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/
本文来自OceanBase社区分享,仅限交流探讨。原作者马伟,长期从事互联网广告检索系统的研发,对数据库,编译器等领域也有浓厚兴趣。
文章目录
- 综述
- 传统单机数据库存储与索引技术
- 存储模型介绍
- 数据文件组织方式
- 堆文件
- 索引组织表
- 索引
- B+树基本性质
- B+树基本操作
- 查找
- 插入
- 删除
- B+树并发策略
- 读操作(查找)
- 写操作(插入或删除)
- 数据库扩展技术
- Sharding
- Share-Storage
- Share-Nothing
- 参考文献
综述
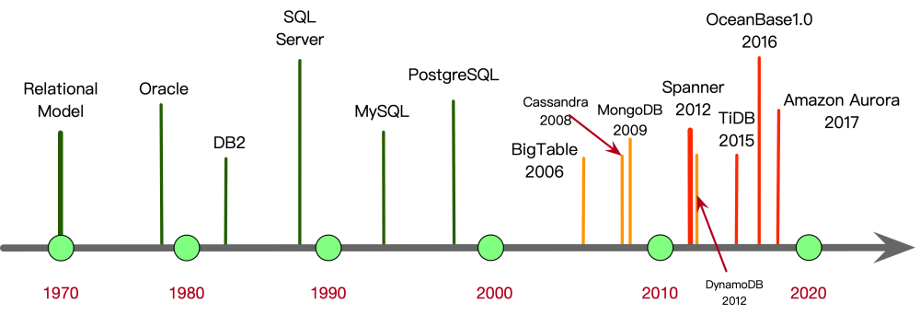
随着1970年代关系模型被提出,数据库进入了一个飞速发展的时期。整个80年代和90年代,各类关系数据库层出不穷,这些产品到现在依然占据着数据库市场的主流。然而到了2000年以后,互联网产业的崛起,使得传统的关系数据库在面对海量请求和数据的时候有些力不从心。在这一时期,解决可扩展问题的主流方案是拆分数据库(分库分表),诞生了众多的数据库中间层(中间件);同时,业界也诞生了众多的K-V数据库,如BigTable,MongoDB,Cassandra等,解决了半结构化数据的计算和存储的可扩展问题,然而业界对于可扩展的关系数据库的诉求一直存在。
2012年Google的论文《Spanner: Google’s Globally-Distributed Database》为业界提供了一个分布式数据库的非常好的参考,此后,各类参考Spanner架构的分布式数据库系统层出不穷。其中国内厂商在自身用户数,以及去IOE动力的驱使下,诞生了包括OceanBase和TiDB在内的几款非常优秀的分布式数据库,在技术上的差距和国外巨头已经拉平,但是市场开拓上还需要继续努力。
同时,众多的云计算厂商基于自身的云基础设施为其客户提供的数据库解决方案也为数据库的扩展性提供了新的思路。代表性的产品是亚马逊的Aurora,其上层100%兼容开源数据库(MySQL, PostgreSQL),下层依托自身云厂商存储技术设施,计算与存储分离的架构,成为了众多云厂商参考的对象。
数据库是一个庞大而复杂的系统,其各个子系统,如SQL,事务,存储,日志等,每一个都是既有一定的理论理解门槛,又有非常高的实现难度,分布式数据库还会涉及更多晦涩的理论,如CAP理论,2/3阶段提交协议,Paxos协议,Raft协议等。本系列通过三篇文章尝试从存储和索引的角度和大家共同学习和了解数据库在存储领域的一些技术,希望这样浮光掠影的文章能给大家留下些许印象,拓宽一些思路,在以后的工作中能有所帮助(注:本系列参考的资料均系本人搜集自互联网公开的论文和博客文章,以及开源的代码和文档等,并经本人理解和整理。文章中的一些技术观点仅代表个人观点,如有描述偏差烦请指正)。
传统单机数据库存储与索引技术
存储模型介绍
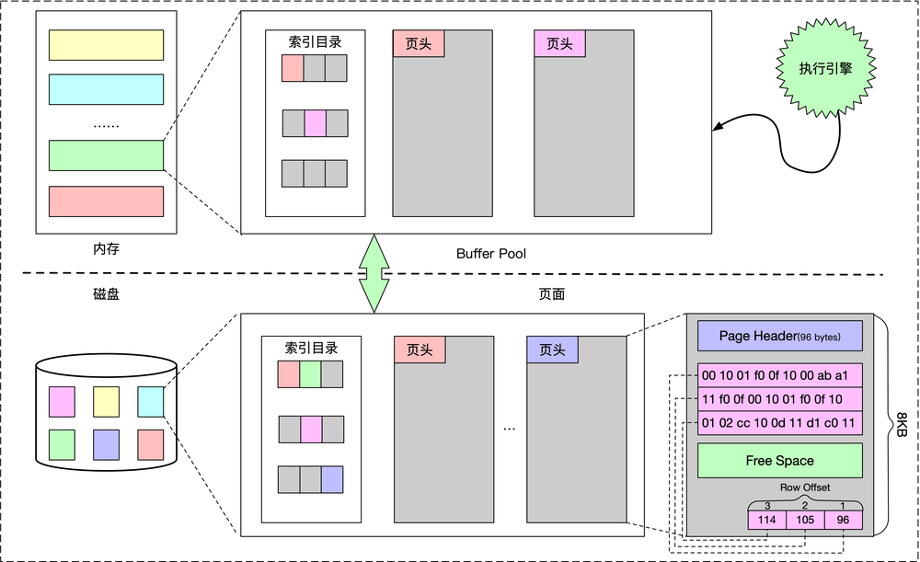
为了保证在系统发生故障时的数据持久化,数据库使用非易失的磁盘作为主存储介质。传统数据库的在磁盘上的数据组织方式为页面行存,即数据库将磁盘空间划分为多个页面,每个页面的大小一般是4K的整数倍,数据在页面内以行为单位存储在一起。数据库读写IO的基本单位都是页面。
由于系统不能直接操作磁盘上的数据,因此还需使用内存作为缓存。通常数据库在内存中会维护一个Buffer Pool的数据结构,用于缓存从磁盘中读取的页面。数据库上层子系统对于数据的读写,都经过Buffer Pool进行。数据库在进行事务操作时,先将redo log顺序写入日志文件,然后再将修改应用到Buffer Pool中的目标页面。通常这一过程只有一次日志文件的顺序IO操作,没有磁盘的随机IO。Buffer Pool会在系统空闲或者内存到达一定阈值的时候异步将某些页面回刷到磁盘并回收内存。Buffer Pool页面回刷会产生随机IO,页面的替换策略也会影响系统整体的缓存命中率,因此页面回刷策略也是很多研究的热点。
数据库的数据存储在页面上,通常以行为单位存储。页面一般会有一个固定大小的页头(Page Header),用于存储页面的一些meta信息,如页面类型,记录条数,同一张表下一个页面的地址等。如果页面存储的行记录是定长的,那么从Page Header开始依次存储记录就行了。如果是变长记录,即每一行数据的大小都可能不一样,一般的做法是从Page Header后开始存储数据,再从页面的末尾开始反向分配也目录(Row Offset)空间,Row Offset记录行在页面内的偏移。这样可以在不确定一个页面可以存储多少行数据的情况下,尽量提高页面空间的利用率。
数据文件组织方式
前面我们讲到数据表的存储方式是以页面为单位进行存储的,但是页面与页面之间如何组织,也由不同的方式。常见的方式有两种。一种叫做堆文件(Heap File),另外一种叫做索引组织表(IOT,Index Organized Table)。
堆文件
堆文件是数据库中最简单,最基本的文件结构,新数据插入优先使用文件末尾的空闲页面,每行数据都会被分配一个rowid作为行的唯一标识。rowid通常包含其所在的文件ID,页面ID,以及页面内的行序号ID。
堆文件有以下一些使用场景:
- 数据量很小的表, 如数据只有几个页面,此时通过索引访问和直接进行全表扫描相比没太大差别。
- 数据表有一次性的大量数据插入的场景, 如数据迁移。此时,使用对文件进行数据插入,效率会比通过索引组织表的方式插入会高非常多。
- 在堆文件上建立索引后,也可以用于数据量大的场景。
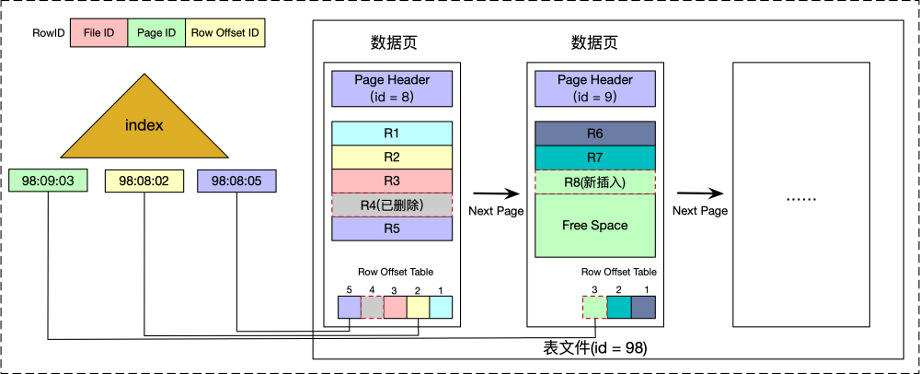
堆文件的各种操作如下如下。
- 插入: 插入优先使用文件末尾的空闲页面空间,只有当空闲空间不足时,才考虑复用被删除的记录的空间。
- 删除: 删除数据需要将页面上的物理记录标记为删除,并删除索引中对rowid的引用。
- 查询: 根据索引(B+Tree)进行点查询或者范围查询,查询索引得到rowid之后,再通过rowid得到对应的数据。如果没有建立索引的话,无论点查询或者范围查询,都需要全表扫描。
索引组织表
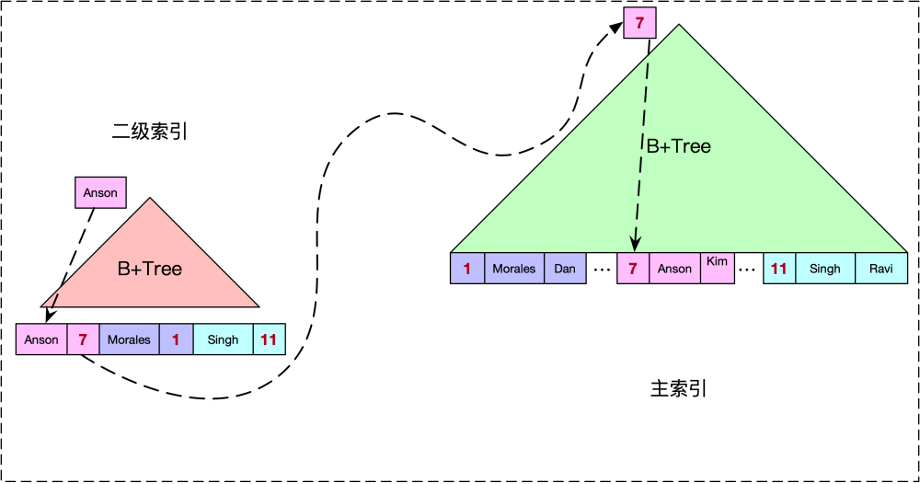
我们可以看到,堆文件的索引只能索引到对应的rowid,如果需要获取数据的话,还需要一次间接引用(如果页面不在内存中,则是一次额外的IO)才能获取到数据。如果一张表主要的查询场景都是通过主键进行查询的话,我们可以选择另外一种索引文件的组织方式,即索引组织表。 索引组织表最大的特点就是,通过在主键上建立索引(B+Tree),并在索引叶子页面上直接存储数据,而非rowid,融主键索引和表数据为一体。 索引组织表支持其他二级索引(Secondary Index),只不过与堆文件不同的是,二级索引中存储的不是rowid,而是行的主键。二级索引通过查询到记录的主键之后再访问主索引获取行记录。
索引组织表的各项操作均通过主索引进行,查询或者插入数据均需要从B+树的根节点开始,一直到叶节点的数据页面上,然后再进行对应的操作。
索引
我们常见的内存索引有很多种,如HashTable, SkipList, BinaryTree, B+Tree等,但是在传统数据库领域,基本上只有B+树一种,B+树可以说是页面为单位组织数据的数据库架构的基石。究其原因,主要还是因为B+树各项操作的均衡性,无论是点查询,范围查询,还是插入,删除等,B+树均能在可接受的IO代价内完成。
与之相比,以HashTable为例,HashTable支持很高效的点查询,但是对范围查询则只能全表扫描;对插入操作来说,HashTable最大的问题是,Hash桶难以动态扩张。当插入数据量大的时候,如果对Hash桶的设置不合适,则将导致读取操作IO数急剧增加;如果进行rehash,则代价巨大,难以接受。
B+树基本性质
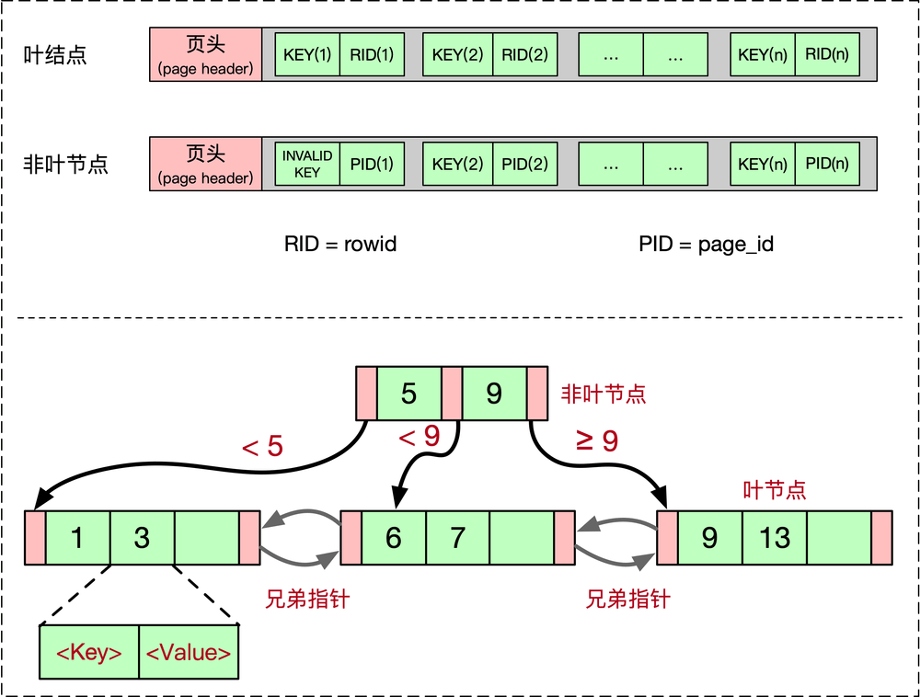
B+树由叶结点和非叶节点组成。数据库中使用到的B+树,叶结点和非叶节点一般都是以一页为单位,二者结构类似,只不过存放的信息略微有所不同。
对于非叶节点,一个页面大小的空间中,会存放一些控制信息,通常放在Page Header中,剩下则是Payload信息。Payload信息中存放着K个KEY和K+1个子节点的指针(PID, page_id)。有些实现为了方便,会额外增加一个INVALID_KEY,这样非叶节点的KEY和指针个数可以一一对应。
对于叶结点,其Page Header中除了一些控制信息之外,还会存放其左右兄弟的指针,这样整个B+树的叶结点可以通过左右兄弟指针进行遍历。如果该B+树是我们前文讲的索引组织表的话,那么叶结点中存放的是真实的行数据。如果是Secondary Index的话,存放的是索引的KEY和表的主键值(如果是Heap File的索引的话,是rowid)。
B+树的KEY可以是一行的某一列,也可以是多个列。B+树要求所有节点中存放的KEY都必须是有序的。对于非叶节点中的某个,其左子树的任一KEY为,右子树的任一KEY为,那么满足:
B+树基本操作
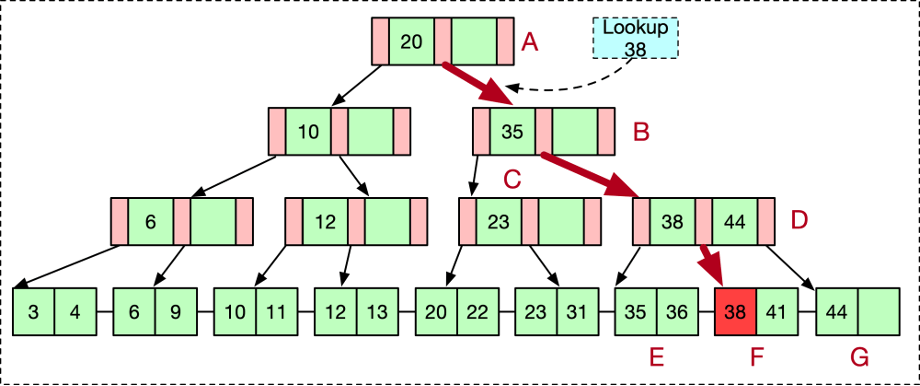
查找
B+树的查找从根节点开始,逐层往下查找直到叶结点。根据每一层的KEY都是有序的特点,可以选择进行二分查找(KEY较少的情况下也可以直接遍历)。找到第一个大于查找元素的KEY,其左子树即是下一层要搜索的节点。
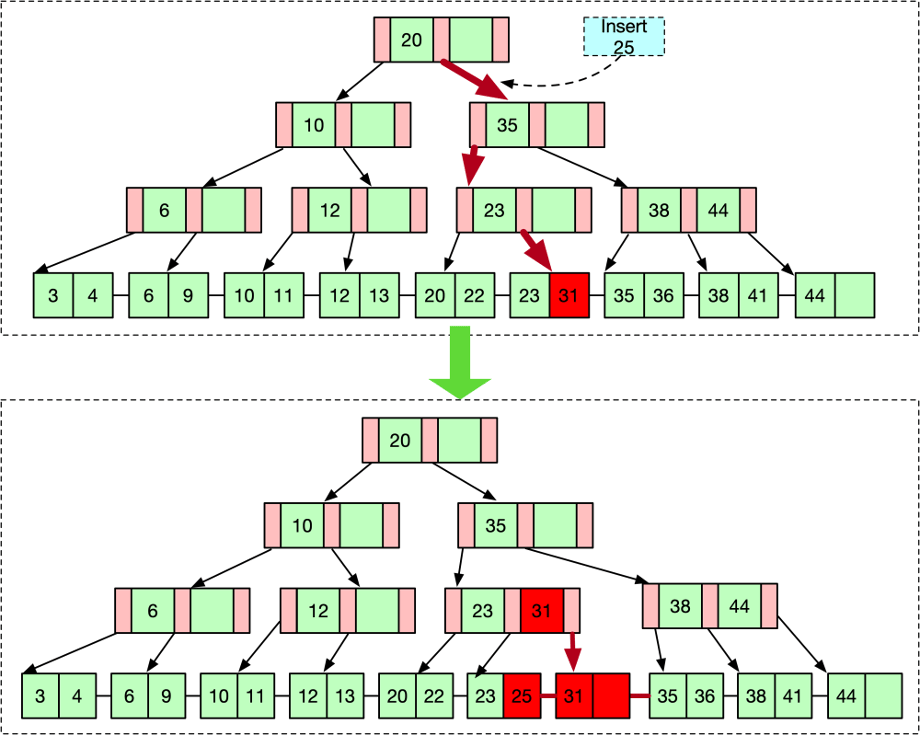
插入
B+树的插入也需要先通过查找找到元素需要被插入的叶结点。如下图,我们插入25,通过逐层二分查找之后,找到31这个值的为位置。如果叶结点有空闲空间可以插入,那么只需要把插入元素放进合适插入位置就行了。如果叶节点已经满了的话,需要对该节点进行分裂。
分裂方法是将当前已满的叶结点一分为二,然后在合适的位置放置待插入的元素。最后像父节点插入新分裂出来的叶结点的第一个KEY。如果父节点也是满的,那么需要递归对父节点进行分裂,这一过程有可能持续到根节点也被分裂,此时B+树的高度被升高了一级。
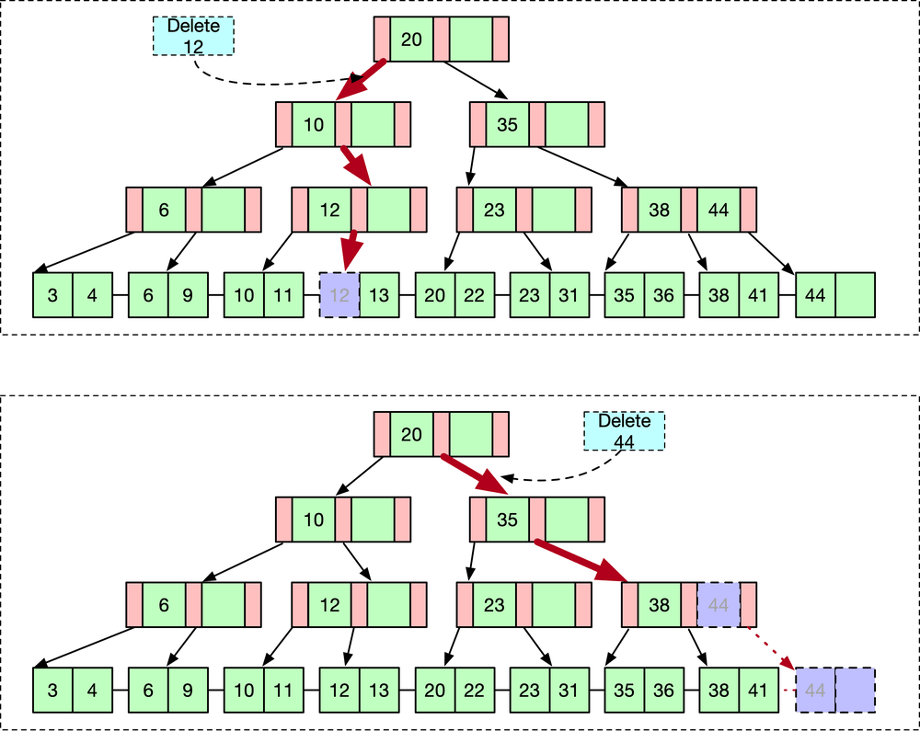
删除
B+树的删除操作一样也需要先通过查找找到待删除元素所在的叶结点,然后进行删除操作。如果待删除元素不是叶结点中唯一的元素,那么直接删除待删除元素即可。
如果待删除元素是该叶结点中的唯一元素,则需要将该叶结点也删除掉,回收空间用于后续再次利用。此时我们需要将该元素的父节点对应的KEY也删除掉。对父节点的删除也可能引发对父节点的删除操作,这一过程可能递归一直到根节点。如果根节点调整后只剩下一个子节点,那么我们可以将根节点也摘除掉,并将根节点的唯一子节点提升为根节点。此时B+树的高度被降低了一级。
B+树并发策略
我们前面讲B+树的基本操作都是在没有考虑并发的情况下,在真实的数据库实现中,B+树往往是被并发读取的。一张表会被多个请求同时读写,对应数据库中多个线程同时在并发读取整棵B+树。无论读还是写操作,我们都需要适当的加锁(latch)才能保证并发读写的安全。
最直接的想法当然是对整棵树加读写锁,读加读锁(RL),写加写锁(WL)。这种做法读写虽然都安全了,但是并发都太低,性能不好,我们需要更细致的枷锁方案以得到更好的并发。
我们来分析B+树的写操作(插入和删除):
大多数情况下,写操作不引发分裂或者节点摘除的情况下,只需要操作目标元素所在的叶结点即可,此时我们只需要对该叶结点加写锁就可以了。
随机情况下,一个叶结点平均插入或者删除N次,才会引发一次分裂或者摘除。此时我们需要对当前叶结点的父节点也进行写操作,此时我们需要对父节点也加写锁。即父节点被加写锁的概率是子节点的1/N。
有了上述观察,我们来看常用的B+树并发策略(Crabbing协议)。
读操作(查找)
读操作从根节点开始,逐个节点进行加读锁,进行元素查找,获取子节点读锁,然后释放读锁的过程。如一开始获取根节点读锁,查找到KEY出现的子节点,然后获取子节点的读锁,再释放根节点的读锁。
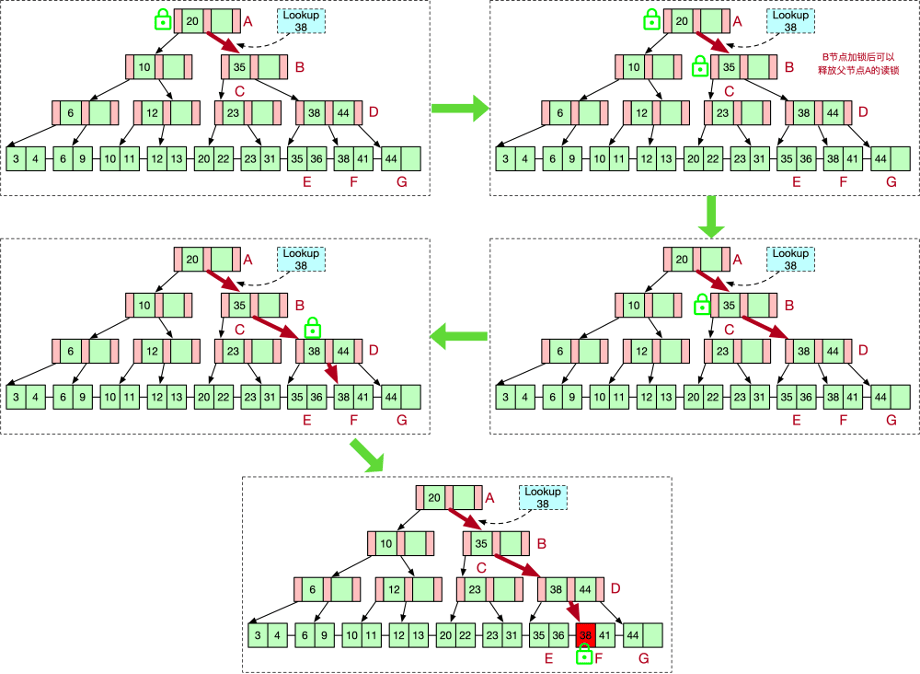
写操作(插入或删除)
对于写操作,也是从根节点开始,先获取根节点的写锁,进行元素查找,找到子节点后获取子节点写锁。获取到子节点写锁之后,需要检查父节点是否安全,如果安全则可以释放所有父节点的写锁。所谓安全,即子节点的操作是否会引起父节点的写入。如某个节点X可以容纳的最大元素(叶结点为KEY个数,非叶节点为子节点个数)是N,当前元素个数为K, 1 < K + 1 < N,那么我们知道,无论X的子节点如何分裂或者摘除,X的父节点都不会受影响,因此我们可以安全的释放X的所有父节点的写锁。

数据库扩展技术
随着互联网时代数据量的增大以及对并发读写事务需求量的增加,传统的单机数据库已经难以满足互联网时代应用对数据库的需求。底层数据库的瓶颈可能来自存储,即单机无法存储下应用所需要的数据量;也可能来自计算,即大量的读或者写QPS,让数据库难以负担。由此产生了各类数据库扩展技术,在不同程度上部分解决了以上两个问题。
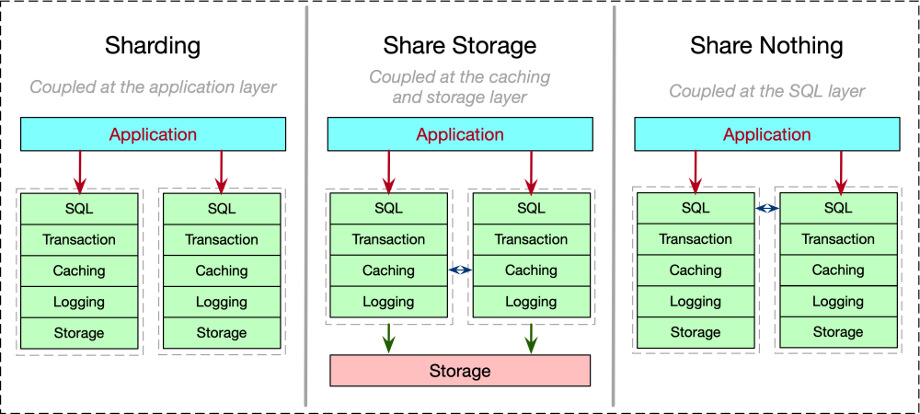
Sharding
Sharding技术在PC互联网时代使用较多,常见的各类数据库中间件,如淘宝的TDDL等,就采用的这种方案。这种方案本质是由应用层去感知底层数据库的分库分表信息,然后在应用层确定查询的路由,并合并查询的结果。写入数据时也由应用层自己来保证涉及到多个分库时的事务的成功。Sharding方案一定程度上解决了数据库存储的瓶颈,但是对于数据计算的瓶颈,仍然未能解决。
Share-Storage
目前这种方案几乎是有自研数据库(微软/Google)的云服务厂商之外的其他厂商的标配,典型代表有Amazon Aurora,腾讯云TDSQL-C,以及阿里云的PolarDB-1.0。这种方案的特点是一写多读,多个计算层实例共享底层存储服务,且由底层存储服务来解决数据的一致性,从而简化计算层的逻辑。以已公开论文的Aurora为例,其实现有如下特点:
-
充分利用云服务厂商的基础设施,共享存储层几乎都是建立在云服务厂商提供的云存储之上。
-
充分利用开源代码,云服务厂商可以将开源数据库(MySQL,PostgreSQL)代码与自己研发的存储层充分结合。在一套存储层基础设施的基础上,通过替换MySQL, PostgreSQL的存储层,从而可以在一套存储上支持多种数据库,且能做到100%兼容。
-
由于对SQL和事务层代码未做大调整,这种方案都只支持单节点写入。通过底层存储服务解决数据存储的可靠性和可扩展的问题,通过增加多个只读副本来解决读QPS可扩展的问题。写入节点与只读节点之间,写入节点与存储层之间,通过事务的原始redo log进行同步,效率比MySQL多副本之间通过bin log进行同步高了非常多。
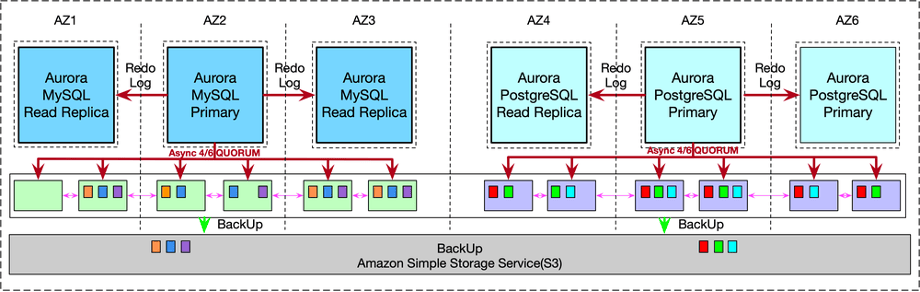
Share Storage的方案解决了存储和读的可扩展,但依然存在单点写入瓶颈。云服务厂商采用这种方案有着自己非常现实的考虑:
-
这种方案可以复用开源数据库大部分代码,且能做到100%兼容(不仅SQL兼容,行为也兼容),充分降低了开发难度,属于一个非常合适的折中。
-
100%兼容多种开源数据库,对于以MySQL, PostgreSQL等为主的互联网中小企业而言,几乎可以做到无感迁移。
-
对存储和读请求做了充分的扩展,单点写入,也是考虑到实现难度,兼容性,以及客户特性的折中。使用云服务的多数都是互联网中小客户,相对写入扩展,对读和存储扩展的需求更大一些。
Share-Nothing
目前主流的分布式数据库,即所谓"NewSQL"数据库的实现,多采用了Share Nothing的架构。这类架构数据库实例之间不共享存储,自己管理自己分区的数据。这是一种完全不同于过去的全新的关系数据库架构,需要从SQL,事务,存储等各个子系统都考虑到扩展性。这类系统的第一个实现是Google的Spanner(Spanner2012),但Spanner支持的存储模型并不是关系模型,因此Google F1(F12013)又在Spanner的基础上实现了对SQL的支持,成为了一个完整的分布式关系数据库。
受此启发,国内互联网企业受制于传统数据库Oracle的限制,也纷纷开始了自己的研发计划。目前国内已经商用的分布式数据库主要有三个实现,即阿里系蚂蚁集团的OceanBase和阿里云的PloarDB-X(即PolarDB-2.0),以及独立数据库开发商PingCAP的TiDB。
这类分布式数据库都采用了LSM树用于构建底层的存储系统,上层通过Paxos或者Raft协议来保证多个副本之间的一致性,通过自动的数据分区(可类比MySQL的分表)来解决不同分区数据的并行写入,同时通过两阶段提交协议来支持跨分区的多机事务。
这类实现对存储和读写请求的扩展都有了非常好的支持,可以说从根本上解决了数据库可扩展的问题。以TPCC Benchmark的结果看,排在榜单第一的OceanBase的的事务(写操作)处理能力,已经是传统数据库Oracle的20倍。
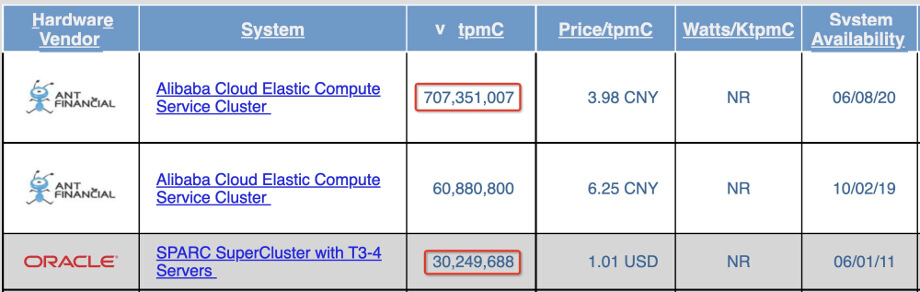
OceanBase能取的这样的TPCC榜单成绩,正是得益于分布式数据库的可扩展能力。整个系统的事务处理能力可以随着部署实例的增加线性扩展,而传统的数据库则做不到这一点。
但这类数据库研发门槛高,同时,LSM树自身的Compaction机制,会导致在Compaction时,会占用非常大的CPU和IO,因此这类数据库需要对Compaction的时机和策略有非常细致的设计,否则会显著影响到系统的稳定性。
关于LSM树的原理及各类操作,会在本系列的第二篇文章《数据库存储与索引技术(二) 分布式数据库基石——LSM树》中进行详细介绍。
参考文献
- 传统数据库
《数据库管理系统实现基础讲义》:https://github.com/oceanbase/oceanbase/blob/master/docs/docs/lectures/index.md
PostgreSQL物理存储介绍:http://rachbelaid.com/introduction-to-postgres-physical-storage/
《MySQL技术内幕》:https://book.douban.com/subject/24708143/
《MySQL B+树并发控制机制前世今生》:http://mysql.taobao.org/monthly/2018/09/01/
《Coarse-Gr Coarse-Grained, Fine-Gr ained, Fine-Grained, and Lock-F ained, and Lock-Free Concurr ee Concurrency Approaches for Self-Balancing B-Tree》 : https://digitalscholarship.unlv.edu/cgi/viewcontent.cgi?article=4733&context=thesesdissertations
- Share Disk架构
Aurora原始论文:https://www.allthingsdistributed.com/files/p1041-verbitski.pdf
Amazon Aurora解读:https://dbaplus.cn/news-160-1748-1.html
Amazon Aurora解读2: https://blog.acolyer.org/2019/03/25/amazon-aurora-design-considerations-for-high-throughput-cloud-native-relational-databases/
腾讯云TDSQL-C架构解析:https://www.modb.pro/db/53642
3. OceanBase TPCC测试
OceanBase TPCC结果:http://tpc.org/tpcc/results/tpcc_results5.asp?print=false&orderby=tpm&sortby=desc
OceanBase TPCC测试细节:https://developer.aliyun.com/article/761887
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/
相关文章:
分享:数据库存储与索引技术(一)存储模型与索引结构演变
欢迎访问 OceanBase 官网获取更多信息:https://www.oceanbase.com/ 本文来自OceanBase社区分享,仅限交流探讨。原作者马伟,长期从事互联网广告检索系统的研发,对数据库,编译器等领域也有浓厚兴趣。 文章目录综述传统单…...

ZeusAutoCode代码生成工具(开源)
ZeusAutoCode代码生成工具 一、简介 Zeus代码生成器是一款自动代码生成工具,旨在快速生成基础的CRUD代码,在此基础上也提供了一些高级功能,做到灵活配置,生成可扩展性强的代码。 后端是基于springboot、freemarker、mybatisplu…...
算法题记录
力扣的算法题:1154 给你一个字符串 date ,按 YYYY-MM-DD 格式表示一个 现行公元纪年法 日期。返回该日期是当年的第几天。 示例 1: 输入:date “2019-01-09” 输出:9 解释:给定日期是2019年的第九天。 示例…...

章节2 行走数据江湖,只需一行代码
目录6. 函数填充,计算列6.1 excel操作6.2 pandas操作16.3 pandas操作28. 数据筛选、过滤,[绘图前的必备功课]8.1 excel操作8.2 Python操作http://sa.mentorx.net 蔓藤教育6. 函数填充,计算列 书的编号、书的名字、标价、折扣、最终价钱 最终…...
springboot集成xx-job;
概念理解: xx-job是一个分布式任务调度平台。比如你有AB两个项目。 AB的定时任务就要在xx-job上个注册。同时AB要配置对应的依赖。 所以集成xx-job要分2步骤:第一步:先搭建xx-job服务 第二步,在A项目中导包并引用。 第一步&am…...

35岁,失业6个月终于接到降薪offer:有面就面,薪酬不限,随机应变说瞎话,对奇葩面试官保持礼貌克制,为拿offer什么都能忍...
被裁后为了生存,人需要做出什么改变?一位35岁网友在失业6个月后终于拿到offer,虽然降薪到四年前的水平,但能继续养家糊口,楼主已经很满意了,并分享了自己的个人经验:1.挖掘历史项目经验…...

如何有效管理项目进度 都有哪些解决方法
项目进度管理是确保项目按时完成的关键因素之一。如果一个项目不能按时完成,那么它可能会导致成本超支、客户不满意和失去信誉等问题。因此,有效的项目进度管理至关重要。在本文中,我们将探讨如何有效管理项目进度以及可以采取哪些解决方法。…...
 光纤与电路交换)
互联网随想(三) 光纤与电路交换
光纤的 “纤”,读 xian(先),第一声,而不是 qian(千)。 光纤之于通信,就像半导体之于计算机。光纤突破了通信的电子瓶颈,就像半导体集成电路突破了计算机的电子管瓶颈一样。 但本文不是赞美光纤的,本文为反…...
electron之旅(二)react使用
首先使用react模板 我们这里使用的是vite和yarn yarn create vite #创建vite的react-js模板初始化依赖 yarn添加依赖 state(状态管理) yarn add redux react-reduxroutes(react路由) yarn add react-router-domelectron依赖 yarn add electron vite-plugin-electron cross-env…...

ChatGPT基础知识系列之Prompt
ChatGPT基础知识系列之Prompt 在 ChatGPT 中,用户可以输入任何问题或者话题,如天气、体育、新闻等等。系统将这个输入作为一个“提示”(prompt)输入到 GPT 模型中进行处理。GPT 模型会基于其学习到的语言规律和上下文知识,生成一个自然语言回答,并返回给用户。 例如,当…...

SpringBoot3 - Spring Security 6.0 Migration
Spring Security 6.0 Migration https://docs.spring.io/spring-security/reference/5.8/migration/servlet/config.html 最近在做SpringBoot2.x到3.0的升级。其中最主要的一部分是javax -> jakartapackageName的变更,另外一部分是对一些废弃/删除的类进行替换。…...

【新2023Q2模拟题JAVA】华为OD机试 - 最少停车数
最近更新的博客 华为od 2023 | 什么是华为od,od 薪资待遇,od机试题清单华为OD机试真题大全,用 Python 解华为机试题 | 机试宝典【华为OD机试】全流程解析+经验分享,题型分享,防作弊指南华为od机试,独家整理 已参加机试人员的实战技巧本篇题解:最少停车数 题目 特定大小的…...

《代码实例前端Vue》Security查询用户列表,用户新增
login.html <!DOCTYPE html> <html lang"en"> <head><meta charset"UTF-8"><title>系统登录-超市订单管理系统</title><link rel"stylesheet" href"../css/style.css"><script type&qu…...
--- README翻译)
CANopenNode学习笔记(一)--- README翻译
CANopenNode学习笔记 文章目录CANopenNode学习笔记特性CANopen其他CANopenNode 流程图文件结构对象字典编辑器CANopenNode 是免费开源的CANopen协议栈。 CANopen是建立在CAN基础上的用于嵌入式控制系统的国际标准化(EN 50325-4) (CiA301)高层协议。有关CANopen的更多信息&#…...

关于Android 11、12和13服务保活问题
物联网环境,为了解决不同厂商、不同设备、不同网络情况下使用顺畅,同时也考虑到节约成本,缩小应用体积的好处,我们需要一个服务应用一直存在系统中,保活它以提供服务给其他客户端调用。 开机自启动,通过广播…...
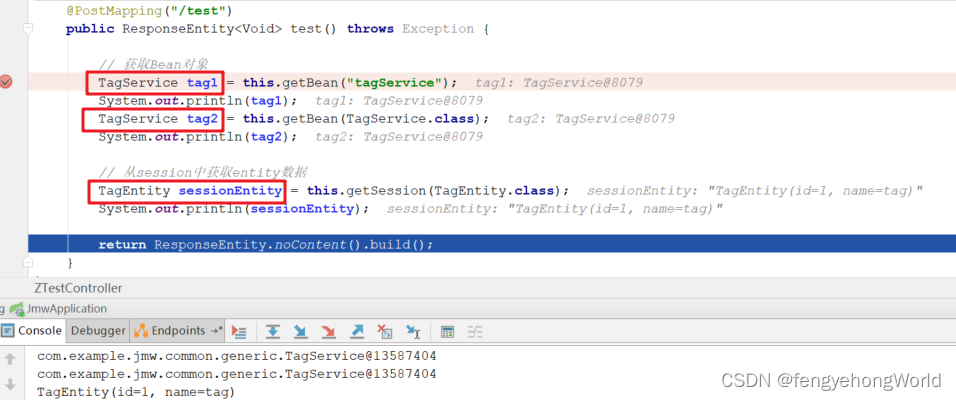
Java 泛型 使用案例
参考资料 Java 基础 - 泛型机制详解路人甲-Java泛型专题 目录一. 通用Mapper1.1 实体类1.2 Mapper基类1.3 自定义接口1.4 抽象基类Service1.5 调用二. session和bean的获取一. 通用Mapper 1.1 实体类 ⏹ Accessors(chain true): 允许链式调用 import lombok.Data; import …...

进程与线程
文章目录什么是线程线程与进程的关系线程与进程的区别什么是线程 上一篇文章中我们介绍了什么进程,我们把进程比作一个工厂,那么线程就是工厂中的流水线。引入进程的目的就是为了实现多个任务并发执行,但是如果频繁的创建销毁进程࿰…...

骑友,怎么挑选适合自己的赛事
骑友,怎么挑选适合自己的赛事一、从场地、路况、天气,各个方面了解赛事的要求。二、看完赛事,要知道自己适合参加什么样的比赛。三、通过比赛成绩,对比自己的实力。四、综合考虑自己的经济能力,根据自己的经济能力选择…...

【Java 数据结构与算法】-遍历Map和Set的方式
作者:学Java的冬瓜 博客主页:☀冬瓜的主页🌙 专栏:【Java 数据结构与算法】 文章目录一、遍历Map法一 先获取Map集合的全部key的set集合,遍历map的key的Set集合法二 把map的key和value打包成Set的key后的这个Set集合法…...
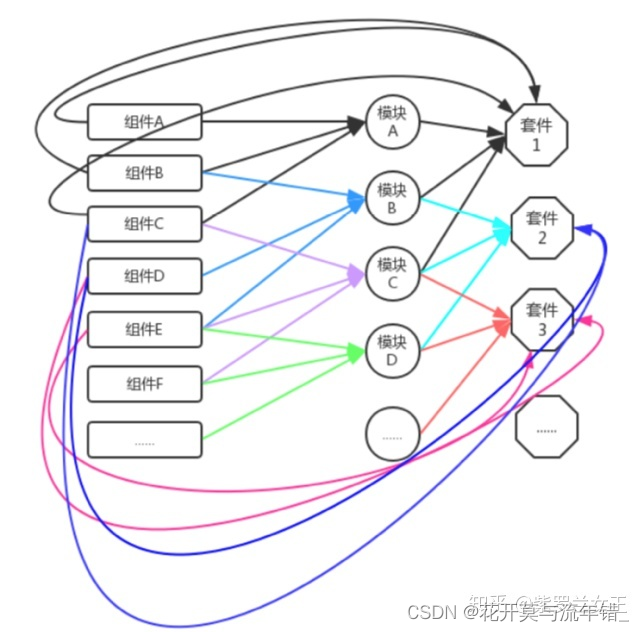
组件、套件、 中间件、插件
组件、套件、 中间件、插件 组件 位于框架最底层,是由重复的代码提取出来合并而成。组件的本质,是一件产品,独立性很强,组件的核心,是复用,与其它功能又有强依赖关系。 模块 在中台产品和非中台产品中&…...

显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理?
显卡驱动清理终极指南:为什么你的系统需要Display Driver Uninstaller深度清理? 【免费下载链接】display-drivers-uninstaller Display Driver Uninstaller (DDU) a driver removal utility / cleaner utility 项目地址: https://gitcode.com/gh_mirr…...

知识图谱与推荐系统实战
一、传统推荐系统的“天花板”协同过滤的困境你刷电商、看视频时,推荐系统总在猜你喜欢什么。最经典的协同过滤思路是“物以类聚、人以群分”:你买过A,那么买过A的人也常买B,于是把B推给你。这套方法简单有效,但也有硬…...

DLSS版本管理器:5分钟掌握游戏性能优化终极指南
DLSS版本管理器:5分钟掌握游戏性能优化终极指南 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 你是否曾因游戏帧数不稳定而烦恼?是否想体验最新DLSS技术带来的性能提升却不知从何入手ÿ…...

避坑指南:STM32F407的DAC输出Buffer为啥会导致0V?ADC连续转换模式与DMA配置的细节解析
STM32F407模拟信号处理实战:DAC输出与ADC采样的深度避坑指南 1. 从异常现象到原理剖析:DAC输出Buffer的隐藏陷阱 调试STM32F407的DAC外设时,不少开发者都遇到过这样的困惑:明明配置了正确的数值,输出电压却始终为0V。…...

java篇12-Java中的异常
java中的异常是一个类,处理异常就是创建一个异常类对象并抛出这个对象,java处理异常的机制是中断,异常不是语法错了,语法错了编译不通过,不会产生字节码文件,不会运行,而异常是在运行过程中导致…...

uView 2.0组件源码深度剖析:理解核心实现原理与设计思想
uView 2.0组件源码深度剖析:理解核心实现原理与设计思想 【免费下载链接】uView2.0 uView UI,是全面兼容nvue的uni-app生态框架,全面的组件和便捷的工具会让您信手拈来,如鱼得水 项目地址: https://gitcode.com/gh_mirrors/uv/u…...

如何将GIMP秒变Photoshop?GimpPs主题插件完整配置指南
如何将GIMP秒变Photoshop?GimpPs主题插件完整配置指南 【免费下载链接】GimpPs Gimp Theme to be more photoshop like 项目地址: https://gitcode.com/gh_mirrors/gi/GimpPs 如果你正在寻找一款能让GIMP拥有Photoshop般专业界面的主题插件,GimpP…...

中兴光猫工厂模式终极解锁工具:zteOnu完整指南
中兴光猫工厂模式终极解锁工具:zteOnu完整指南 【免费下载链接】zteOnu A tool that can open ZTE onu device factory mode 项目地址: https://gitcode.com/gh_mirrors/zt/zteOnu 你是否曾经因为中兴光猫的限制而感到束手无策?想要进行高级配置却…...

Windows Defender移除终极指南:如何彻底禁用微软安全组件提升系统性能30%
Windows Defender移除终极指南:如何彻底禁用微软安全组件提升系统性能30% 【免费下载链接】windows-defender-remover A tool which is uses to remove Windows Defender in Windows 8.x, Windows 10 (every version) and Windows 11. 项目地址: https://gitcode.…...

如何三步完成QQ音乐加密音频的免费解密:解决音乐格式兼容性难题
如何三步完成QQ音乐加密音频的免费解密:解决音乐格式兼容性难题 【免费下载链接】QMCDecode QQ音乐QMC格式转换为普通格式(qmcflac转flac,qmc0,qmc3转mp3, mflac,mflac0等转flac),仅支持macOS,可自动识别到QQ音乐下载目录…...