多模态大语言模型(MLLM)-InstructBlip深度解读
前言
InstructBlip可以理解为Blip2的升级版,重点加强了图文对话的能力。
模型结构和Blip2没差别,主要在数据集收集、数据集配比、指令微调等方面下文章。
创新点
- 数据集收集: 将26个公开数据集转换为指令微调格式,并将它们归类到11个任务类别中。使用了其中13个数据集来进行指令微调,另外13个数据集用于zero-shot评估。
- 数据集配比:提出了一种平衡采样策略,以同步不同数据集间的学习进度。
- 模型改进:提出了指令感知的视觉特征提取,能够根据输入文本,提取特定的图像特征。说白了,就是文本不仅输入到LLM,也输入到Q-Former,Q-Former的输出再又给到LLM。
- 评估并开源了一系列InstructBLIP模型,使用了两类大型语言模型:1) FlanT5,一种基于T5 微调得到的encoder-decoder模型;2) Vicuna,一种基于LLaMA微调得到的decoder模型。InstructBLIP模型在广泛的视觉-语言任务上实现了最先进的零样本性能。
具体细节
数据集收集
总共收集了11个任务类别(例如image captioning、visual reasoning等),26个数据集,如下:
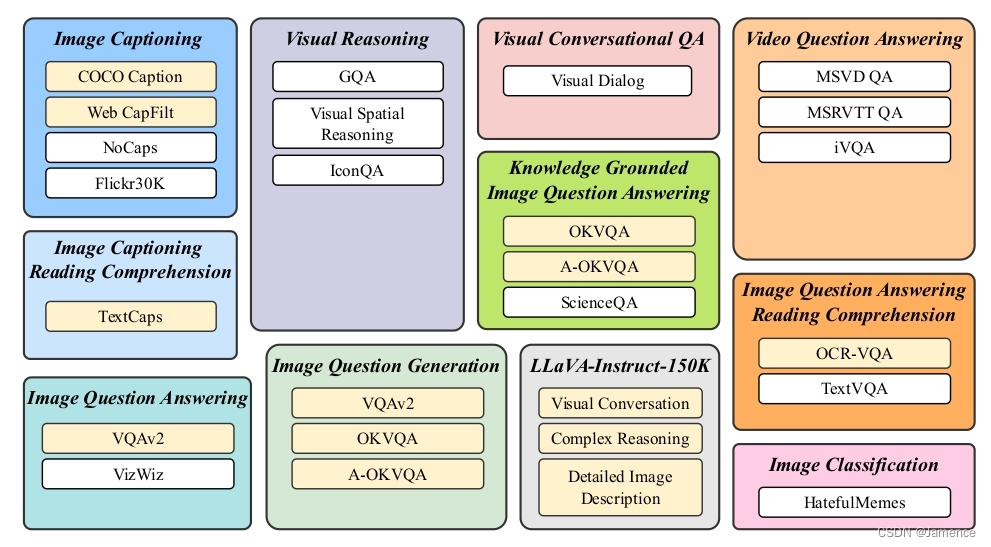
数据集需要转化为图文指令微调的形式,用于多模态大语言模型的训练。
举个例子,在image classification任务中,图片A的类别是狗,数据的组织形式要转换成
问题:图片A,请问图片的类别是什么
回答:类别是狗
针对不同的任务类型,有多样化模板来进行数据的形式转换,如下:

训练测试数据划分
26个数据集中,13个用于训练,另外13个用于测试
按照对zero-shot影响深浅,评测集分为两类
- 训练集有同一任务的其他数据集
- 训练集无同一任务的其他数据集
数据集配比
因数据集较多,直接均匀分布可能会导致模型对小数据集过拟合,而对大数据集欠拟合。
为了解决这个问题,提出了一种采样策略,即按照数据集大小(或训练样本数)的平方根成比例的概率来选择数据集。
给定D个数据集,其大小分别为{S1, S2, …, SD},从数据集d中选取一个训练样本的概率

模型优化
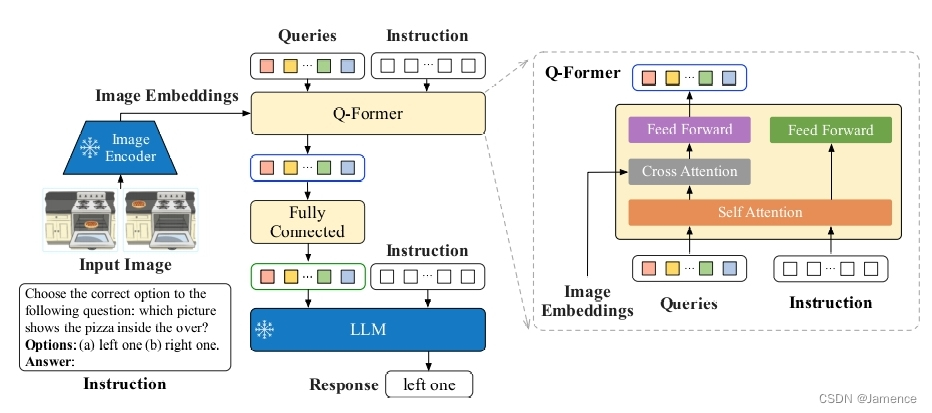
从模型结构上看,和Blip2一模一样。。。
Instruction指用户的问题,有两个输入位置:
- Q-Former:上一篇博客说到,左列输入图像,右列输入文本(Instruction),提取的是多模态特征,相较于Blip2仅输入图像效果肯定是更好的
- LLM:Q-Former的输出、Instruction在embedding层面融合,输入到LLM中
class BertEmbeddings(nn.Module):"""Construct the embeddings from word and position embeddings."""def __init__(self, config):super().__init__()self.word_embeddings = nn.Embedding(config.vocab_size, config.hidden_size, padding_idx=config.pad_token_id)self.position_embeddings = nn.Embedding(config.max_position_embeddings, config.hidden_size)# self.LayerNorm is not snake-cased to stick with TensorFlow model variable name and be able to load# any TensorFlow checkpoint fileself.LayerNorm = nn.LayerNorm(config.hidden_size, eps=config.layer_norm_eps)self.dropout = nn.Dropout(config.hidden_dropout_prob)# position_ids (1, len position emb) is contiguous in memory and exported when serializedself.register_buffer("position_ids", torch.arange(config.max_position_embeddings).expand((1, -1)))self.position_embedding_type = getattr(config, "position_embedding_type", "absolute")self.config = configdef forward(self,input_ids=None,position_ids=None,query_embeds=None,past_key_values_length=0,):if input_ids is not None:seq_length = input_ids.size()[1]else:seq_length = 0if position_ids is None:position_ids = self.position_ids[:, past_key_values_length : seq_length + past_key_values_length].clone()if input_ids is not None:embeddings = self.word_embeddings(input_ids)if self.position_embedding_type == "absolute":position_embeddings = self.position_embeddings(position_ids)embeddings = embeddings + position_embeddingsif query_embeds is not None:embeddings = torch.cat((query_embeds, embeddings), dim=1)else:embeddings = query_embedsembeddings = self.LayerNorm(embeddings)embeddings = self.dropout(embeddings)return embeddings
可以看到
if query_embeds is not None:embeddings = torch.cat((query_embeds, embeddings), dim=1)
作者重写了bert embedding层的代码,将query_embeds(可理解为Q-Former的输出)和embeddings(可理解为Instruction的文本embedding) concat起来
推理策略
对于不同的任务类别,采用不同的推理策略
- 对于绝大部分任务,例如image captioning以及开放域VQA任务,采用传统的transformer解码方式生成回答
- 对于classification或multi-choice VQA这种回复内容受限的任务,生成时限制解码的词表,保证回复范围不超过规定范围。(例如多选任务里,回答只能约束在A B C D四个选项)
实验结果
zero-shot对比
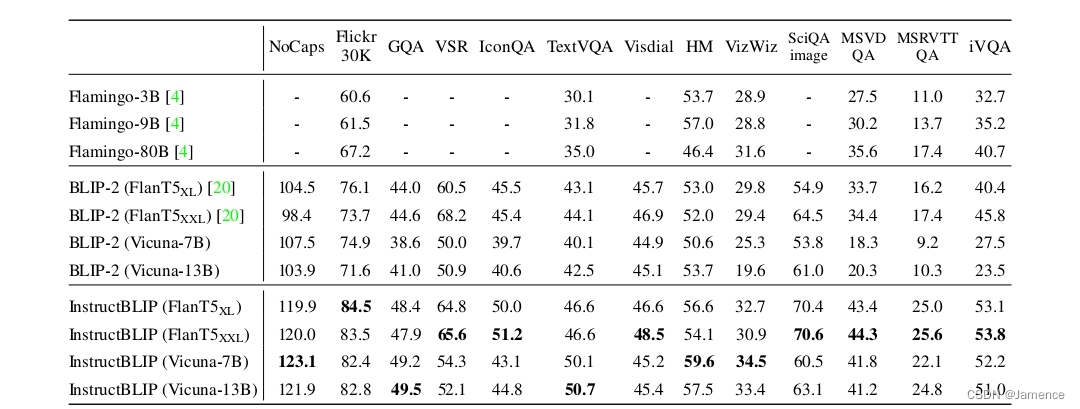
从图标上看,效果确实比Blip2,flamingo要好。不过InstructBlip在Blip2的基础上加了这么多数据训练,效果没道理差。
消融实验
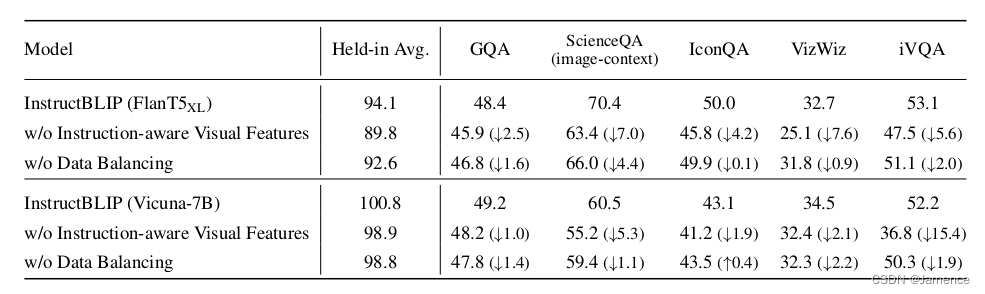
不把instruction送到Q-Former,效果确实差了很多
同时,不做数据配比,效果也差了一些
指令微调 VS 多任务学习
指令微调在实现的时候,利用了13个数据集来训练。一个比较类似的算法是多任务学习,也能够实现多个数据集的学习。
为比较效果,做了如下多任务学习实验:
- 训练用原任务input-output数据,测试用InstructBlip指令
- 训练在input前添加数据集名称,测试用InstructBlip指令
- 训练在input前添加数据集名称,测试在input前添加数据集名称
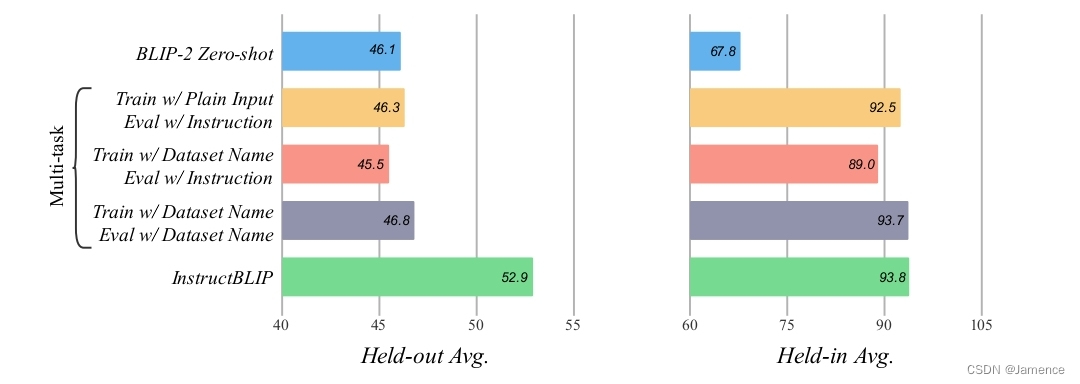
有两个观察 - 多任务学习和InstructBlip在held-in 数据集上,效果差不多。held-in数据可以理解为训练和测试均来自同一数据集,说明
- InstructBlip在held-out数据集上远优于多任务学习,held-out数据集指模型在训练时没见过这个数据集,直接跨数据集。
笔者会持续关注多模态大语言模型(MLLM),对底层原理、经典论文、开源代码都会进行详细解读,欢迎交流学习。
相关文章:
多模态大语言模型(MLLM)-InstructBlip深度解读
前言 InstructBlip可以理解为Blip2的升级版,重点加强了图文对话的能力。 模型结构和Blip2没差别,主要在数据集收集、数据集配比、指令微调等方面下文章。 创新点 数据集收集: 将26个公开数据集转换为指令微调格式,并将它们归类…...
:字符串)
网页前端开发之Javascript入门篇(7/9):字符串
Javascript字符串 什么是字符串? 答:其概念跟 Python教程 介绍的一样,只是语法上有所变化。 在 Javascript 中,一个字符串变量可以看做是其内置类String的一个实例(Javascript会自动包装)。 因此它拥有一…...

双登股份再战IPO:数据打架,实控人杨善基千万元股权激励儿子
撰稿|行星 来源|贝多财经 近日,双登集团股份有限公司(下称“双登股份”)递交招股书,准备在港交所主板上市,中金公司、建银国际、华泰国际为其联席保荐人。 贝多财经了解到,这并非双登股份首次向资本市场…...
)
4.Python 函数(函数的定义、函数的传入参数、函数的返回值、None 类型、函数说明文档、变量的作用域)
一、函数快速入门 1、函数概述 函数是组织好的,可重复使用的,用来实现特定功能的代码段 name "Hello World" name_length len(name)print(f"{name} 的长度为 {name_length}") # Hello World 的长度为 11len() 是Python 内置的函…...

【JavaEE】——文件IO
阿华代码,不是逆风,就是我疯 你们的点赞收藏是我前进最大的动力!! 希望本文内容能够帮助到你!! 目录 一:认识文件 1:文件的概念 2:文件的结构 3:文件路径…...

Python的pandas库基本操作(数据分析)
一、安装,导入 1、安装 使用包管理器安装: pip3 install pandas 2、导入 import pandas as pd as是为了方便引用起的别名 二、DateFrame 在Pandas库中,DataFrame 是一种非常重要的数据结构,它提供了一种灵活的方式来存储和…...
)
软件测试(平铺版本)
目录 黑盒测试: 定义: 示例:登录功能的黑盒测试 适合使用黑盒测试的情况 几种常见的黑盒测试方法: 1. 等价类划分(Equivalence Partitioning) 2. 边界值分析(Boundary Value Analysis) …...

树控件QTreeWidget
树控件跟表格控件类似,也可以有多列,也可以只有1列,可以有多行,只不过每一行都是一个QTreeWidgetItem,每一行都是一个可以展开的树 常用属性和方法 显示和隐藏标题栏 树控件只有水平标题栏 //获取和设置标题栏的显…...

Python酷库之旅-第三方库Pandas(139)
目录 一、用法精讲 626、pandas.plotting.scatter_matrix方法 626-1、语法 626-2、参数 626-3、功能 626-4、返回值 626-5、说明 626-6、用法 626-6-1、数据准备 626-6-2、代码示例 626-6-3、结果输出 627、pandas.plotting.table方法 627-1、语法 627-2、参数 …...

昇思学习打卡营学习记录:CycleGAN壁画修复
按照提示,运行实训代码 进入实训平台:https://xihe.mindspore.cn/projects 选择“jupyter 在线编辑器” 启动“Ascend开发环境” :Ascend开发环境需要申请,大家可以申请试试看 启动开发环境后,在左边的文件夹中&am…...

南京大学《软件分析》李越, 谭添——1. 导论
导论 主要概念: soundcompletePL领域概述 动手学习 本节无 文章目录 导论1. PL(Programming Language) 程序设计语言1.1 程序设计语言的三大研究方向1.2 与静态分析相关方向的介绍与对比静态程序分析动态软件测试形式化(formal)语义验证(verification) 2. 静态分析:2.1莱斯…...

使用seata管理分布式事务
做应用开发时,要保证数据的一致性我们要对方法添加事务管理,最简单的处理方案是在方法上添加 Transactional 注解或者通过编程方式管理事务。但这种方案只适用于单数据源的关系型数据库,如果项目配置了多个数据源或者多个微服务的rpc调用&…...
浏览器指纹
引言 先看下 官网 给的定义。 WebAssembly (abbreviatedWasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server …...

W外链平台有什么优势?
W外链作为一种短网址服务,具备多项功能和技术优势,适用于多种场景,以下是其主要特点和优势: 短域名与高级设置:W外链提供了非常短的域名,这有助于提高用户体验,使其在社交媒体分享时更加便捷。…...

深入理解Spring Cache:加速应用性能的秘钥
一、什么是Spring Cache? Spring Cache是Spring框架中的一部分,它为应用提供了一种统一的缓存抽象,可以轻松集成各种缓存提供者(如Ehcache、Redis、Caffeine等)。通过使用Spring Cache,开发者可以在方法上…...
:完成旅途的最少时间(C语言版))
C语言入门基础题(力扣):完成旅途的最少时间(C语言版)
1.题目: 给你一个数组 time ,其中 time[i] 表示第 i 辆公交车完成 一趟旅途 所需要花费的时间。 每辆公交车可以 连续 完成多趟旅途,也就是说,一辆公交车当前旅途完成后,可以 立马开始 下一趟旅途。每辆公交车 独立 …...

基于LORA的一主多从监测系统_0.96OLED
关联:0.96OLED hal硬件I2C LORA 在本项目中每个节点都使用oled来显示采集到的数据以及节点状态,OLED使用I2C接口与STM32连接,这个屏幕内部驱动IC为SSD1306,SSD1306作为从机地址为0x78 发送数据:起始…...

C#系统学习路线
分享一个C#程序员的成长学习路线规划,希望能够帮助到想从事C#开发的你。 我一直在想,初学者刚开始学习编程时应该学些什么?学习到什么程度才能找到工作?才能在项目中发现和解决Bug? 我不知道每位初学者在学习编程时是…...

UI开发:从实践到探索
UI开发:从实践到探索 参考博客文章:https://blog.jim-nielsen.com/2024/sanding-ui/ 在现代web开发中,用户界面(UI)的重要性不言而喻。一个优秀的UI不仅能提升用户体验,还能直接影响产品的成功。 UI开发…...
操作系统 | 学习笔记 | 王道 | 3.1 内存管理概念
3 内存管理 3.1 内存管理概念 3.1.1 内存管理的基本原理和要求 内存可以存放数据,程序执行前需要先放到内存中才能被CPU处理—缓和cpu和磁盘之间的速度矛盾 内存管理的概念 虽然计算机技术飞速发展,内存容量也在不断扩大,但仍然不可能将所有…...

从Overleaf回归本地:为什么我最终选择了Windows下的MiKTeX和VS Code组合?
从Overleaf回归本地:为什么我最终选择了Windows下的MiKTeX和VS Code组合? 作为一名长期依赖Overleaf的科研工作者,我曾在云端LaTeX编辑器的便利性中如鱼得水——直到开始撰写我的博士学位论文。当文档规模超过200页、包含数百个交叉引用和复杂…...
)
解密冰蝎和蚁剑:在CTF流量分析中如何识别和还原WebShell攻击(含AES/Base64解密实操)
解密冰蝎与蚁剑:CTF流量分析中的WebShell识别与解密实战 在CTF竞赛和安全分析领域,WebShell流量分析一直是让许多选手头疼的高阶挑战。特别是当面对冰蝎(Behinder)、蚁剑(AntSword)这类采用强加密通信的Web…...

从仿真到现实:用Unity+ROS2搭建激光雷达小车,为实体机器人开发做预演
从仿真到现实:用UnityROS2搭建激光雷达小车,为实体机器人开发做预演 在机器人开发领域,仿真环境正逐渐成为不可或缺的工具。想象一下,你可以在不购买任何硬件的情况下,验证复杂的导航算法;或者在投入大量资…...

Univer开源项目部署完整指南:从零到生产环境
Univer开源项目部署完整指南:从零到生产环境 【免费下载链接】univer Build AI-native spreadsheets. Univer is a full-stack framework for creating and editing spreadsheets on both web and server. With Univer Platform, Univer Spreadsheets is driven dir…...

二维码坏了别着急扔!3步教你用QRazyBox免费修复损坏的二维码
二维码坏了别着急扔!3步教你用QRazyBox免费修复损坏的二维码 【免费下载链接】qrazybox QR Code Analysis and Recovery Toolkit 项目地址: https://gitcode.com/gh_mirrors/qr/qrazybox 你有没有遇到过这样的情况?打印出来的二维码被水弄湿了&am…...

避开HAL库:STM32F103寄存器级PWM移相全桥配置避坑指南
STM32F103寄存器级PWM移相全桥实战:从原理到避坑指南 在嵌入式开发领域,许多工程师习惯使用HAL库或标准库进行STM32开发,这确实能提高开发效率。但当项目对时序精度、资源占用或性能有极致要求时,直接操作寄存器往往能带来更优的效…...
)
别再到处搜了!高德、百度、ArcGIS地图瓦片URL,我帮你整理好了(附Leaflet加载代码)
地图瓦片集成实战:从URL解析到Leaflet高效加载 1. 地图瓦片服务的选择与评估 在WebGIS开发中,选择合适的瓦片地图服务是项目成功的第一步。主流服务商提供的地图瓦片各有特点,开发者需要根据项目需求进行综合评估。 高德地图瓦片以其丰富的图…...

三分钟搞定B站缓存视频:m4s转MP4的傻瓜式完整教程
三分钟搞定B站缓存视频:m4s转MP4的傻瓜式完整教程 【免费下载链接】m4s-converter 一个跨平台小工具,将bilibili缓存的m4s格式音视频文件合并成mp4 项目地址: https://gitcode.com/gh_mirrors/m4/m4s-converter 你是不是也遇到过这样的烦恼&#…...
)
告别点灯:用STM32+FPGA+FSMC做个数据吞吐测试仪(附Quartus与标准库工程)
STM32与FPGA联袂打造:高性能数据吞吐测试仪实战指南 在嵌入式系统开发中,总线通信性能往往是决定整体系统响应速度的关键瓶颈。对于硬件爱好者、电子工程师和学生群体而言,如何直观测量和优化总线传输效率,是一个既具挑战性又充满…...

RuoYi-Vue-Plus多租户实现原理:数据隔离与权限控制的终极指南 [特殊字符]
RuoYi-Vue-Plus多租户实现原理:数据隔离与权限控制的终极指南 🏢 【免费下载链接】RuoYi-Vue-Plus 基于RuoYi-Vue集成 LombokMybatis-PlusUndertowknife4jHutoolFeign 重写所有原生业务 定期与RuoYi-Vue同步 项目地址: https://gitcode.com/GitHub_Tre…...