Python的pandas库基本操作(数据分析)
一、安装,导入
1、安装
使用包管理器安装:
pip3 install pandas2、导入
import pandas as pdas是为了方便引用起的别名
二、DateFrame
在Pandas库中,DataFrame 是一种非常重要的数据结构,它提供了一种灵活的方式来存储和操作结构化数据。DataFrame 类似于Excel中的表格,具有行和列,其中每列可以是不同的数据类型(数值、字符串、布尔值等)。
1、创建DateFrame
import pandas as pd # 从字典创建 DataFrame
data = {'Name': ['Alice', 'Bob', 'Charlie'], 'Age': [25, 30, 35], 'City': ['New York', 'Los Angeles', 'Chicago']}
df = pd.DataFrame(data) # 从列表的字典创建 DataFrame
data_list = [{'Name': 'Alice', 'Age': 25, 'City': 'New York'}, {'Name': 'Bob', 'Age': 30, 'City': 'Los Angeles'}, {'Name': 'Charlie', 'Age': 35, 'City': 'Chicago'}]
df_list = pd.DataFrame(data_list)两个对象存储情况:
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
Name Age City
0 Alice 25 New York
1 Bob 30 Los Angeles
2 Charlie 35 Chicago
2、查看 DateFrame
# 查看前几行
print(df.head()) # 查看后几行
print(df.tail()) # 查看数据的基本信息
print(df.info()) # 查看数值列的统计信息
print(df.describe())head和tail括号内都可以写数值指定要前几行。默认是5行。
3、选择数据
你可以通过列名、行标签(索引)或条件来选择数据。
# 选择单列
print(df['Name']) # 选择多列
print(df[['Name', 'Age']]) # 通过行标签选择(假设设置了索引)
# df.set_index('Name', inplace=True)
# print(df.loc['Alice']) # 通过条件选择
print(df[df['Age'] > 30])当你使用 inplace=True 参数时,这个操作会直接在原DataFrame上进行,而不会返回一个新的DataFrame。之后,你可以使用 .loc[] 索引器来根据新的索引值选择数据。
可以通过设置index属性自定义输出的顺序。
app=data['apples']
#自定义输出序列下标顺序
app=pd.Series(app,index=[0,2,1,3])执行后,会根据索引值的0213顺序赋值给app.
4、添加或删除数据
# 添加新列
df = df.assign(Salary=pd.Series([50000, 60000, 70000])) # 删除列
df = df.drop(columns=['City']) # 删除行(通过索引或条件)
# df = df.drop(index=0) # 删除第一行
# df = df[df['Age'] != 30] # 删除 Age 为 30 的行5、数据处理
Pandas 提供了丰富的数据处理功能,如分组(groupby)、聚合(aggregate)、合并(merge)、连接(join)等。
# 分组和聚合
grouped = df.groupby('City').agg({'Age': 'mean', 'Salary': 'sum'}) # 合并两个 DataFrame
df1 = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'], 'A': ['A0', 'A1', 'A2', 'A3']})
df2 = pd.DataFrame({'Key': ['K0', 'K1', 'K2', 'K3'], 'B': ['B0', 'B1', 'B2', 'B3']})
merged = pd.merge(df1, df2, on='Key')6、导出数据
你可以将 DataFrame 导出为CSV、Excel等格式的文件。
# 导出为CSV文件
df.to_csv('output.csv', index=False) # 导出为Excel文件
df.to_excel('output.xlsx', index=False)将index设置为false可以去掉下标。
7、其他操作
(1)转置
print(date.T)使用DateFrame对象打点调用T可以将矩阵进行转置,也就是将行转为列,列转为行。
(2)排序
#根据内容排序,ascending=False是降序,默认升序
print(date.sort_values(by='A',ascending=False))也可以根据索引排序,就是使用date.sort_values。
三、时间序列和Resample函数
时间序列数据在Pandas中通常存储为DataFrame或Series对象,其中时间戳作为索引。这种结构使得Pandas能够轻松地对数据进行时间相关的操作,如按时间筛选、滚动窗口计算、时间差计算等。
resample()函数是Pandas时间序列对象(DataFrame或Series)的一个方法,它允许用户按照指定的频率对数据进行重新采样。重新采样的过程通常包括两个步骤:首先,根据新的频率对数据进行分组;其次,对每个分组应用聚合函数(如求和、平均、最大值、最小值等)来计算新的值。
# 假设df是一个时间序列DataFrame,时间戳作为索引
# 对数据进行按月重新采样,并计算每个月的平均值
monthly_mean = df.resample('M').mean()参数:
rule:字符串或数字,指定新的采样频率。on:可选参数,指定用于重新采样的列名(如果DataFrame的索引不是时间戳)。closed:可选参数,指定区间的开闭性,'left'、'right'或None(默认为'right')。label:可选参数,指定标签的位置,'left'、'right'或'both'(默认为'right'),或者是一个时间戳数组。convention:可选参数,指定'start'、'end'或'e'(默认为'end'),用于确定在区间边界上的值的归属。loffset:可选参数,用于调整标签的位置。base:可选参数,用于指定时间间隔的起始点(0到23之间的整数)。how或aggregate:可选参数,指定应用于每个分组的聚合函数(如'mean'、'sum'等)。在较新版本的Pandas中,建议使用aggregate参数。
常用的resample聚合函数
-
mean():计算每个分组的平均值。这是时间序列数据分析中最常用的聚合函数之一,用于获取数据的平均水平。
-
sum():计算每个分组的总和。这个函数可以用于计算某个时间段内的累积值。
-
count():计算每个分组中非空(非NA/null)值的数量。这个函数可以用于检查数据的完整性或缺失情况。
-
first():获取每个分组的第一个值。这个函数可以用于提取时间序列数据中的起始点。
-
last():获取每个分组的最后一个值。这个函数可以用于提取时间序列数据中的结束点。
-
min():计算每个分组的最小值。这个函数可以用于识别数据中的最低点或阈值。
-
max():计算每个分组的最大值。这个函数可以用于识别数据中的最高点或峰值。
-
ohlc():计算每个分组的开盘价(first)、最高价(max)、最低价(min)和收盘价(last)。这个函数通常用于金融时间序列数据的分析。
-
prod():计算每个分组的乘积。这个函数可以用于计算某个时间段内数据的累积效应。
-
std():计算每个分组的标准差。这个函数用于衡量数据的离散程度或波动性。
-
var():计算每个分组的方差。方差是标准差的平方,同样用于衡量数据的离散程度。
-
median():计算每个分组的中位数。中位数是一种位置平均数,对于偏态分布的数据具有较好的代表性。
-
quantile():计算每个分组的指定分位数。这个函数允许用户指定一个介于0和1之间的数值作为分位数,以获取数据的不同分位点。
-
apply():应用一个自定义的函数到每个分组。这个函数提供了极大的灵活性,允许用户根据自己的需求编写复杂的聚合逻辑。
四、plot快速可视化
plot可视化需要安装一个matplotlib包
使用包管理器安装matplotlib
pip3 install matplotlib案例:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
#单样本
df=np.random.rand(1000)
df=pd.DataFrame(df,index=pd.date_range('20210101',periods=1000))
print(df)
df.plot()
plt.show()df是一个新的DataFrame,然后设置一个新的索引,这个索引是一个日期范围,从'20210101'开始,包含1000个日期。plot 方法实际上是Pandas对Matplotlib绘图库的封装,为用户提供了一个简洁的接口来快速生成图表。plt.show是展示出来。
展示图表:

五、读取与存储(pandas)
读取是pandas打点调用‘’read_格式‘’函数,读什么格式的文件就用什么格式。
案例:
读取csv的文件:
pd.read_csv('txt.csv')以下是一些Pandas可读取的主要文件类型:
- CSV(Comma-Separated Values)文件:
- CSV是一种常见的文本文件格式,用于存储表格数据。
- 每行表示一条记录,字段之间用逗号分隔。
- Pandas使用
read_csv函数读取CSV文件。
- Excel文件:
- Excel是一种常见的电子表格文件格式,通常包含多个工作表。
- Pandas使用
read_excel函数读取Excel文件,并可以指定要读取的工作表名称或索引。
- JSON(JavaScript Object Notation)文件:
- JSON是一种轻量级的数据交换格式,易于阅读和编写。
- Pandas使用
read_json函数读取JSON文件。
- SQL数据库:
- Pandas支持从SQL数据库中读取数据,需要使用SQLAlchemy库来创建数据库连接。
- 使用
read_sql或read_sql_table函数从SQL数据库中读取数据。
- Parquet文件:
- Parquet是一种高效的列式存储格式,适用于大规模数据集。
- Pandas使用
read_parquet函数读取Parquet文件。
- HDF5文件:
- HDF5是一种用于存储大量数据的文件格式,支持分层数据存储。
- Pandas使用
read_hdf函数读取HDF5文件,需要指定数据集的键(key)。
- Feather文件:
- Feather是一种轻量级的二进制文件格式,适用于快速读写。
- Pandas使用
read_feather函数读取Feather文件。
- Pickle文件:
- Pickle是Python的一种序列化格式,用于存储Python对象。
- Pandas使用
read_pickle函数读取Pickle文件。
- HTML文件:
- Pandas可以读取HTML文件中的表格数据。
- 使用
read_html函数读取HTML文件,该函数返回一个DataFrame列表,其中每个DataFrame对应HTML文件中的一个表格。
- TXT文件:
- 虽然Pandas没有专门为TXT文件设计的读取函数,但可以使用
read_csv函数通过指定适当的分隔符来读取TXT文件。如果TXT文件的字段是用制表符(\t)分隔的,可以使用sep='\t'参数。
- 虽然Pandas没有专门为TXT文件设计的读取函数,但可以使用
案例2:
向Excel写入:
data.to_excel('excel.xlsx',sheet_name='a')上述代码实现了创建sheet页:a,并向excel.xlsx文件输入data数据。若想追加sheet页:
with pd.ExcelWriter('writerExcel.xlsx',mode='a',engine='openpyxl') as writer:data.to_excel(writer,sheet_name='d')需要在打开文件时设置属性mode值为:a表示追加
engine参数用于指定用于写入Excel文件的底层引擎。Pandas支持多种引擎来处理Excel文件,但最常用的引擎是openpyxl(用于.xlsx文件)和xlsxwriter。这两个引擎都提供了丰富的功能来创建和修改Excel文件。
-
openpyxl:这是一个用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。它支持对Excel文件的读取和写入,包括公式、图表、图像等复杂元素。 -
xlsxwriter:这是一个Python库,用于创建Excel.xlsx文件。它提供了丰富的功能来格式化单元格、添加图表、创建工作表等。
同时添加多个sheet页:
with pd.ExcelWriter('writerExcel.xlsx') as writer:data.to_excel(writer,sheet_name='a')data.to_excel(writer, sheet_name='b')data.to_excel(writer, sheet_name='c')相关文章:
Python的pandas库基本操作(数据分析)
一、安装,导入 1、安装 使用包管理器安装: pip3 install pandas 2、导入 import pandas as pd as是为了方便引用起的别名 二、DateFrame 在Pandas库中,DataFrame 是一种非常重要的数据结构,它提供了一种灵活的方式来存储和…...
)
软件测试(平铺版本)
目录 黑盒测试: 定义: 示例:登录功能的黑盒测试 适合使用黑盒测试的情况 几种常见的黑盒测试方法: 1. 等价类划分(Equivalence Partitioning) 2. 边界值分析(Boundary Value Analysis) …...

树控件QTreeWidget
树控件跟表格控件类似,也可以有多列,也可以只有1列,可以有多行,只不过每一行都是一个QTreeWidgetItem,每一行都是一个可以展开的树 常用属性和方法 显示和隐藏标题栏 树控件只有水平标题栏 //获取和设置标题栏的显…...

Python酷库之旅-第三方库Pandas(139)
目录 一、用法精讲 626、pandas.plotting.scatter_matrix方法 626-1、语法 626-2、参数 626-3、功能 626-4、返回值 626-5、说明 626-6、用法 626-6-1、数据准备 626-6-2、代码示例 626-6-3、结果输出 627、pandas.plotting.table方法 627-1、语法 627-2、参数 …...

昇思学习打卡营学习记录:CycleGAN壁画修复
按照提示,运行实训代码 进入实训平台:https://xihe.mindspore.cn/projects 选择“jupyter 在线编辑器” 启动“Ascend开发环境” :Ascend开发环境需要申请,大家可以申请试试看 启动开发环境后,在左边的文件夹中&am…...

南京大学《软件分析》李越, 谭添——1. 导论
导论 主要概念: soundcompletePL领域概述 动手学习 本节无 文章目录 导论1. PL(Programming Language) 程序设计语言1.1 程序设计语言的三大研究方向1.2 与静态分析相关方向的介绍与对比静态程序分析动态软件测试形式化(formal)语义验证(verification) 2. 静态分析:2.1莱斯…...

使用seata管理分布式事务
做应用开发时,要保证数据的一致性我们要对方法添加事务管理,最简单的处理方案是在方法上添加 Transactional 注解或者通过编程方式管理事务。但这种方案只适用于单数据源的关系型数据库,如果项目配置了多个数据源或者多个微服务的rpc调用&…...
浏览器指纹
引言 先看下 官网 给的定义。 WebAssembly (abbreviatedWasm) is a binary instruction format for a stack-based virtual machine. Wasm is designed as a portable compilation target for programming languages, enabling deployment on the web for client and server …...

W外链平台有什么优势?
W外链作为一种短网址服务,具备多项功能和技术优势,适用于多种场景,以下是其主要特点和优势: 短域名与高级设置:W外链提供了非常短的域名,这有助于提高用户体验,使其在社交媒体分享时更加便捷。…...

深入理解Spring Cache:加速应用性能的秘钥
一、什么是Spring Cache? Spring Cache是Spring框架中的一部分,它为应用提供了一种统一的缓存抽象,可以轻松集成各种缓存提供者(如Ehcache、Redis、Caffeine等)。通过使用Spring Cache,开发者可以在方法上…...
:完成旅途的最少时间(C语言版))
C语言入门基础题(力扣):完成旅途的最少时间(C语言版)
1.题目: 给你一个数组 time ,其中 time[i] 表示第 i 辆公交车完成 一趟旅途 所需要花费的时间。 每辆公交车可以 连续 完成多趟旅途,也就是说,一辆公交车当前旅途完成后,可以 立马开始 下一趟旅途。每辆公交车 独立 …...

基于LORA的一主多从监测系统_0.96OLED
关联:0.96OLED hal硬件I2C LORA 在本项目中每个节点都使用oled来显示采集到的数据以及节点状态,OLED使用I2C接口与STM32连接,这个屏幕内部驱动IC为SSD1306,SSD1306作为从机地址为0x78 发送数据:起始…...

C#系统学习路线
分享一个C#程序员的成长学习路线规划,希望能够帮助到想从事C#开发的你。 我一直在想,初学者刚开始学习编程时应该学些什么?学习到什么程度才能找到工作?才能在项目中发现和解决Bug? 我不知道每位初学者在学习编程时是…...

UI开发:从实践到探索
UI开发:从实践到探索 参考博客文章:https://blog.jim-nielsen.com/2024/sanding-ui/ 在现代web开发中,用户界面(UI)的重要性不言而喻。一个优秀的UI不仅能提升用户体验,还能直接影响产品的成功。 UI开发…...
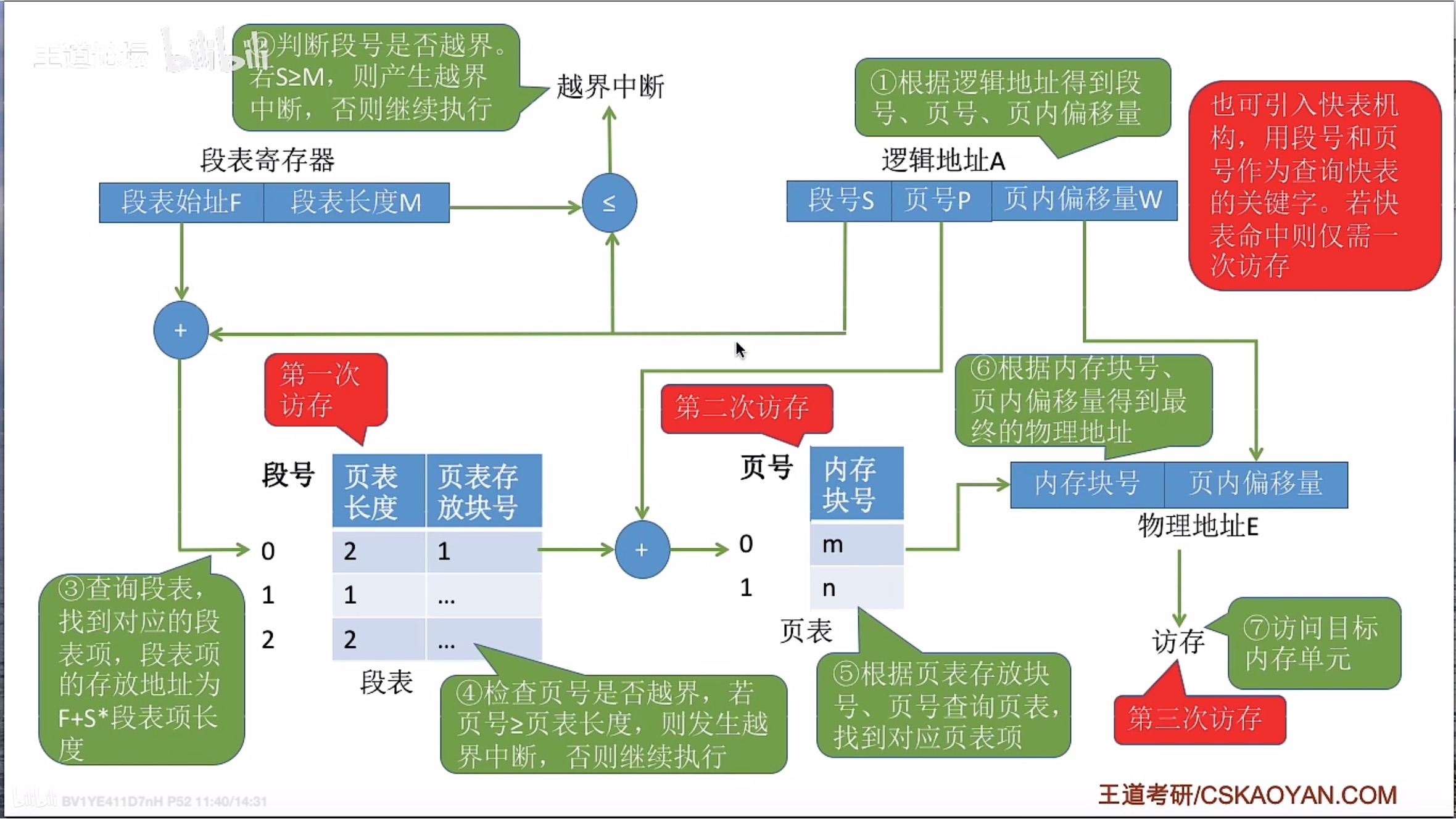
操作系统 | 学习笔记 | 王道 | 3.1 内存管理概念
3 内存管理 3.1 内存管理概念 3.1.1 内存管理的基本原理和要求 内存可以存放数据,程序执行前需要先放到内存中才能被CPU处理—缓和cpu和磁盘之间的速度矛盾 内存管理的概念 虽然计算机技术飞速发展,内存容量也在不断扩大,但仍然不可能将所有…...

Unity射线之拾取物体
实现效果: 可以移动场景内物品放置到某个位置。通过射线检测,点击鼠标左键,移动物体,再点击左键放下物体。 效果: 移动物体 实现思路: 通过射线检测,将检测到的物体吸附到摄像机前的一个空物…...
)
Python的numpy库矩阵计算(数据分析)
一、创建矩阵 import numpy as np#创建矩阵anp.arange(15).reshape(3,5) bnp.arange(15,30).reshape(3,5) 使用arrange和reshape创建的二维数组就可以看成矩阵。 此时a和b存储的是: [[ 0 1 2 3 4] [ 5 6 7 8 9] [10 11 12 13 14]] [[15 16 17 18 19]…...

R语言的基本语句及基本规则
0x01 赋值语句 使用 “<-” 或 “” 进行赋值。例如: x <- 5 # 将数值 5 赋值给变量 x y 10 # 另一种赋值方式0x02 输出语句 使用 print() 函数输出内容。例如: print("Hello, R!") print(x)0x03 注释语句 任何在 #之后的内容在…...

网络受限情况下安装openpyxl模块提示缺少Jdcal,et_xmlfile
1.工作需要处理关于Excel文件内容的东西 2.用公司提供的openpyxl模块总是提示缺少jdcal文件,因为网络管控,又没办法直接使用命令下载,所以网上找了资源,下载好后上传到个人资源里了 资源路径 openpyxl jdcal et_xmlfile 以上模块来源于:Py…...
)
【算法】- 查找 - 散列表查询(哈希表)
文章目录 前言一、哈希表的思想二、哈希表总结 前言 散列技术:在记录的存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key) 哈希表:采用散列技术将记录存储在一块连续的存储空间中,这块连…...

Synopsys ICC 2016环境变量配置详解:从.bashrc编辑到license启动的保姆级步骤
Synopsys ICC 2016环境变量配置全流程实战指南 当你第一次打开Synopsys ICC 2016却遭遇"Command not found"时,90%的问题都源于环境变量配置不当。作为芯片设计领域的工业级工具链,正确的环境配置不仅是运行的先决条件,更是后续所有…...

HEIF Utility:当跨平台技术遇上真实世界的照片困境
HEIF Utility:当跨平台技术遇上真实世界的照片困境 【免费下载链接】HEIF-Utility HEIF Utility - View/Convert Apple HEIF images on Windows. 项目地址: https://gitcode.com/gh_mirrors/he/HEIF-Utility 你是否曾经历过这样的场景?用iPhone记…...

云英谷开启招股:拟募资11亿港元 5月27日上市 小米华为红杉是股东
雷递网 雷建平 5月18日云英谷科技股份有限公司(简称:“云英谷”,股票代码:“03310”)日前开启招股,准备2026年5月27日在港交所上市。云英谷发行价为20.81港元,发行5285.92万股,募资总…...

三星固件下载神器Bifrost:三分钟学会跨平台官方固件下载与解密
三星固件下载神器Bifrost:三分钟学会跨平台官方固件下载与解密 【免费下载链接】Bifrost Cross-platform tool for downloading Samsung mobile device firmware. 项目地址: https://gitcode.com/gh_mirrors/sa/Bifrost 还在为找不到三星官方固件而烦恼吗&am…...

Windows热键冲突终结者:3步精准定位占用进程的智能方案
Windows热键冲突终结者:3步精准定位占用进程的智能方案 【免费下载链接】hotkey-detective A small program for investigating stolen key combinations under Windows 7 and later. 项目地址: https://gitcode.com/gh_mirrors/ho/hotkey-detective 你是否曾…...

cube studio开源一站式云原生机器学习平台--pytorch分布式训练
全栈工程师开发手册 (作者:栾鹏) 一站式云原生机器学习平台 前言 开源地址:https://github.com/data-infra/cube-studio cube studio 开源的国内最热门的一站式机器学习mlops/大模型训练平台,支持多租户,…...

Linux应用配置分层实战指南
Linux应用配置分层实战指南本文面向具备一定 Linux 基础的技术人员,围绕应用配置分层展开,重点讨论默认配置、环境覆盖和敏感参数隔离。在中级运维和系统管理工作中,这类主题常常与配置变更、资源状态、权限边界、自动化任务和业务影响交织在…...

英雄联盟个人信息修改终极指南:3分钟学会LeaguePrank完整使用教程
英雄联盟个人信息修改终极指南:3分钟学会LeaguePrank完整使用教程 【免费下载链接】LeaguePrank 项目地址: https://gitcode.com/gh_mirrors/le/LeaguePrank 你是否厌倦了英雄联盟中千篇一律的个人资料显示?想向好友展示一个与众不同的游戏身份吗…...

猫抓浏览器扩展终极指南:高效捕获网页视频与流媒体资源的专业解决方案
猫抓浏览器扩展终极指南:高效捕获网页视频与流媒体资源的专业解决方案 【免费下载链接】cat-catch 猫抓 浏览器资源嗅探扩展 / cat-catch Browser Resource Sniffing Extension 项目地址: https://gitcode.com/GitHub_Trending/ca/cat-catch 猫抓(…...
)
NotebookLM文档召回率骤降73%?(内部实验报告首次公开:BM25+SBERT混合排序实战框架)
更多请点击: https://intelliparadigm.com 第一章:NotebookLM相似文档推荐 NotebookLM 是 Google 推出的基于用户上传文档构建个性化 AI 助手的实验性工具,其核心能力之一是“相似文档推荐”——即在用户提问时,自动从已导入的文…...