Python cachetools常用缓存算法汇总
文章目录
- cachetools介绍
- 缓存操作
- 设置数据生存时间(TTL)
- 自定义缓存策略
- 缓存装饰器
- 缓存清理
- cachetools 超过缓存数量maxsize
- cachetools 使用示例
cachetools介绍
-
cachetools: 是一个Python第三方库,提供了多种缓存算法的实现。缓存是一种用于临时存储计算结果的技术,以避免在后续计算中重复执行相同的计算。使用缓存可以提高应用程序的性能和响应速度。 -
多种缓存策略
cachetools提供了以下常见的缓存策略:-
LRUCache(Least Recently Used Cache):基于最近使用的原则,删除最久未使用的缓存项。当缓存达到最大容量时,将删除最久未使用的缓存项。 -
LFUCache(Least Frequently Used Cache):基于最近使用频率的原则,删除使用频率最低的缓存项。当缓存达到最大容量时,将删除使用频率最低的缓存项。 -
FIFOCache(First In, First Out Cache):按照缓存项的插入顺序进行删除,最先插入的缓存项将首先被删除。 -
RRCache(Random Replacement Cache):随机删除缓存项,没有特定的策略。
-
这些缓存策略都可以在 Cachetools 中使用,并可以通过设置缓存的最大容量来控制缓存的大小。
python3.10版本的cachetools缓存策略
import cachetools# 创建 LRU 缓存
lru_cache = cachetools.LRUCache(maxsize=100)# 创建 MRU 缓存
mru_cache = cachetools.MRUCache(maxsize=100)# 创建 RR 缓存
rr_cache = cachetools.RRCache(maxsize=100)# 创建 FIFO 缓存
fifo_cache = cachetools.FIFOCache(maxsize=100)
maxsize参数代表的是缓存中可以存储的最大条目数量,而不是字符数。
缓存操作
缓存对象支持类似字典的操作,例如:添加、获取、删除和更新缓存项。
# 类似于字典操作# 添加缓存项
lru_cache["key"] = "value"# 获取缓存项
value = lru_cache.get("key", "default_value")
print(lru_cache)
# 删除缓存项
if "key" in lru_cache:del lru_cache["key"]# 更新缓存项
lru_cache["key"] = "new_value"
print(lru_cache)
LRUCache({'key': 'value'}, maxsize=100, currsize=1)
LRUCache({'key': 'new_value'}, maxsize=100, currsize=1)
设置数据生存时间(TTL)
cachetools 还支持为缓存项设置生存时间(TTL)。当缓存项的生存时间到期后,该项将被自动移除。
import cachetools
import time# 创建一个带 TTL 的缓存对象
ttl_cache = cachetools.TTLCache(maxsize=100, ttl=60)# 添加缓存项
ttl_cache["key"] = "value"
print(ttl_cache)# 等待一段时间,让缓存项过期
time.sleep(61)# 此时缓存项已过期,尝试获取时将返回默认值
value = ttl_cache.get("key", "default_value")
print(value)
当为ttl_cache添加缓存项之后,可以看到 TTLCache类型缓存添加成功,当过去61s之后,缓存项已过期,尝试获取时返回的是默认值default_value。
TTLCache({'key': 'value'}, maxsize=100, currsize=1)
default_value
自定义缓存策略
cachetools允许自定义缓存策略。要实现一个自定义的缓存策略,需要继承 cachetools.Cache 类,并实现相应的方法。例如,实现一个简单的大小有限制的缓存:
import cachetoolsclass SizeLimitedCache(cachetools.Cache):def __init__(self, maxsize):super().__init__(maxsize=maxsize)def __getitem__(self, key, cache_getitem=dict.__getitem__):return cache_getitem(self, key)def __setitem__(self, key, value, cache_setitem=dict.__setitem__):if len(self) >= self.maxsize:self.popitem(last=False) # 删除第一个缓存项cache_setitem(self, key, value)# 使用自定义缓存策略
custom_cache = SizeLimitedCache(maxsize=100)
custom_cacheSizeLimitedCache({}, maxsize=100, currsize=0)
缓存装饰器
cachetools还提供了一些缓存装饰器,可以方便地将缓存应用于函数或方法。
import cachetools
import cachetools.func
import requests # 使用 LRU 缓存装饰函数
@cachetools.func.ttl_cache(maxsize=100, ttl=60)
def get_data_from_api(api_url, params):response = requests.get(api_url, params=params)response.raise_for_status()data = response.json()return data# 使用缓存的函数
data = get_data_from_api("https://api.example.com/data", {"param1": "value1", "param2": "value2"})
缓存清理
cachetools提供了一些方法,可以手动清理缓存
import cachetools# 创建 LRU 缓存
lru_cache = cachetools.LRUCache(maxsize=100)
lru_cache["name"] = "Abel"
lru_cache["age"] = 33
lru_cache["job"] = "student"
print(lru_cache)# 移除最近最少使用的缓存项
lru_cache.popitem()
print(lru_cache)# 手动清空缓存
lru_cache.clear()
print(lru_cache)
lru_cache创建缓存之后依次添加了3个缓存项,当使用popitem()函数移除最近最少使用的一条缓存项之后,lru_cache只剩余其他两个缓存项,最后使用clear()函数清空缓存之后,lru_cache显示为空。
LRUCache({'name': 'Abel', 'age': 33, 'job': 'student'}, maxsize=100, currsize=3)
LRUCache({'age': 33, 'job': 'student'}, maxsize=100, currsize=2)
LRUCache({}, maxsize=100, currsize=0)
import cachetools# 创建 LRU 缓存
lru_cache = cachetools.LRUCache(maxsize=100)# 向lru_cache添加缓存项
lru_cache["name"] = "Abel"
lru_cache["age"] = 33
lru_cache["job"] = "student"
print(lru_cache)# 查看缓存项
print(lru_cache.get("name"))# 移除最近最少使用的缓存项
lru_cache.popitem()
print(lru_cache)# 手动清空缓存
lru_cache.clear()
print(lru_cache)
在添加3条缓存项之后,如果查看第一条缓存项,则这条缓存项被使用过,在调用popitem()函数进行移除时,会从下一条未被使用过的缓存项开始,找到最近的一条进行删除。
LRUCache({'name': 'Abel', 'age': 33, 'job': 'student'}, maxsize=100, currsize=3)
Abel
LRUCache({'name': 'Abel', 'job': 'student'}, maxsize=100, currsize=2)
LRUCache({}, maxsize=100, currsize=0)
cachetools 超过缓存数量maxsize
设置缓存量为10,添加11个缓存项,对LRUCache缓存策略,则会删除最近未被使用的一条。
import cachetools# 创建 LRU 缓存
lru_cache = cachetools.LRUCache(maxsize=10)for index in range(11):lru_cache[index] = 'cache'+str(index)print(lru_cache)
LRUCache({'key': 'value'}, maxsize=100, currsize=1)
LRUCache({'key': 'new_value'}, maxsize=100, currsize=1)
TTLCache({'key': 'value'}, maxsize=100, currsize=1)
default_value
SizeLimitedCache({}, maxsize=100, currsize=0)
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[11], line 1411 return data13 # 使用缓存的函数
---> 14 data = get_data_from_api("https://api.example.com/data", {"param1": "value1", "param2": "value2"})File e:\python3.10\lib\site-packages\cachetools\__init__.py:696, in cached.<locals>.decorator.<locals>.wrapper(*args, **kwargs)694 try:695 with lock:
--> 696 result = cache[k]697 hits += 1698 return resultFile e:\python3.10\lib\site-packages\cachetools\__init__.py:410, in TTLCache.__getitem__(self, key, cache_getitem)408 def __getitem__(self, key, cache_getitem=Cache.__getitem__):409 try:
--> 410 link = self.__getlink(key)411 except KeyError:412 expired = FalseFile e:\python3.10\lib\site-packages\cachetools\__init__.py:497, in TTLCache.__getlink(self, key)496 def __getlink(self, key):
--> 497 value = self.__links[key]498 self.__links.move_to_end(key)
...18 if hashvalue is None:
---> 19 self.__hashvalue = hashvalue = hash(self)20 return hashvalueTypeError: unhashable type: 'dict'
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
LRUCache({'name': 'Abel', 'age': 33, 'job': 'student'}, maxsize=100, currsize=3)
Abel
LRUCache({'name': 'Abel', 'job': 'student'}, maxsize=100, currsize=2)
LRUCache({}, maxsize=100, currsize=0)
---------------------------------------------------------------------------
gaierror Traceback (most recent call last)
File e:\python3.10\lib\site-packages\urllib3\connection.py:174, in HTTPConnection._new_conn(self)173 try:
--> 174 conn = connection.create_connection(175 (self._dns_host, self.port), self.timeout, **extra_kw176 )178 except SocketTimeout:File e:\python3.10\lib\site-packages\urllib3\util\connection.py:72, in create_connection(address, timeout, source_address, socket_options)68 return six.raise_from(69 LocationParseError(u"'%s', label empty or too long" % host), None70 )
---> 72 for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):73 af, socktype, proto, canonname, sa = resFile e:\python3.10\lib\socket.py:955, in getaddrinfo(host, port, family, type, proto, flags)954 addrlist = []
--> 955 for res in _socket.getaddrinfo(host, port, family, type, proto, flags):956 af, socktype, proto, canonname, sa = resgaierror: [Errno 11001] getaddrinfo failedDuring handling of the above exception, another exception occurred:
...
--> 519 raise ConnectionError(e, request=request)521 except ClosedPoolError as e:522 raise ConnectionError(e, request=request)ConnectionError: HTTPSConnectionPool(host='api.example.com', port=443): Max retries exceeded with url: /data (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0000015BB5EBEFB0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
---------------------------------------------------------------------------
gaierror Traceback (most recent call last)
File e:\python3.10\lib\site-packages\urllib3\connection.py:174, in HTTPConnection._new_conn(self)173 try:
--> 174 conn = connection.create_connection(175 (self._dns_host, self.port), self.timeout, **extra_kw176 )178 except SocketTimeout:File e:\python3.10\lib\site-packages\urllib3\util\connection.py:72, in create_connection(address, timeout, source_address, socket_options)68 return six.raise_from(69 LocationParseError(u"'%s', label empty or too long" % host), None70 )
---> 72 for res in socket.getaddrinfo(host, port, family, socket.SOCK_STREAM):73 af, socktype, proto, canonname, sa = resFile e:\python3.10\lib\socket.py:955, in getaddrinfo(host, port, family, type, proto, flags)954 addrlist = []
--> 955 for res in _socket.getaddrinfo(host, port, family, type, proto, flags):956 af, socktype, proto, canonname, sa = resgaierror: [Errno 11001] getaddrinfo failedDuring handling of the above exception, another exception occurred:
...
--> 519 raise ConnectionError(e, request=request)521 except ClosedPoolError as e:522 raise ConnectionError(e, request=request)ConnectionError: HTTPSConnectionPool(host='api.example.com', port=443): Max retries exceeded with url: /data?param1=value1¶m2=value2 (Caused by NewConnectionError('<urllib3.connection.HTTPSConnection object at 0x0000015BB65BDED0>: Failed to establish a new connection: [Errno 11001] getaddrinfo failed'))
Output is truncated. View as a scrollable element or open in a text editor. Adjust cell output settings...
LRUCache({0: 'cache0'}, maxsize=10, currsize=1)
LRUCache({0: 'cache0', 1: 'cache1'}, maxsize=10, currsize=2)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2'}, maxsize=10, currsize=3)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3'}, maxsize=10, currsize=4)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4'}, maxsize=10, currsize=5)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5'}, maxsize=10, currsize=6)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6'}, maxsize=10, currsize=7)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7'}, maxsize=10, currsize=8)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8'}, maxsize=10, currsize=9)
LRUCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8', 9: 'cache9'}, maxsize=10, currsize=10)
LRUCache({1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8', 9: 'cache9', 10: 'cache10'}, maxsize=10, currsize=10)
Random 缓存会随机删除一条记录。
import cachetools# 创建 RR 缓存
rr_cache = cachetools.RRCache(maxsize=10)for index in range(11):rr_cache[index] = 'cache'+str(index)print(rr_cache)
RRCache({0: 'cache0'}, maxsize=10, currsize=1)
RRCache({0: 'cache0', 1: 'cache1'}, maxsize=10, currsize=2)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2'}, maxsize=10, currsize=3)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3'}, maxsize=10, currsize=4)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4'}, maxsize=10, currsize=5)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5'}, maxsize=10, currsize=6)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6'}, maxsize=10, currsize=7)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7'}, maxsize=10, currsize=8)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8'}, maxsize=10, currsize=9)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8', 9: 'cache9'}, maxsize=10, currsize=10)
RRCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8', 9: 'cache9', 10: 'cache10'}, maxsize=10, currsize=10)
FIFO缓存会删除第一条存入的缓存项。
import cachetools# 创建 FIFO 缓存
fifo_cache = cachetools.FIFOCache(maxsize=10)for index in range(11):fifo_cache[index] = 'cache'+str(index)print(fifo_cache)
FIFOCache({0: 'cache0'}, maxsize=10, currsize=1)
FIFOCache({0: 'cache0', 1: 'cache1'}, maxsize=10, currsize=2)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2'}, maxsize=10, currsize=3)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3'}, maxsize=10, currsize=4)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4'}, maxsize=10, currsize=5)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5'}, maxsize=10, currsize=6)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6'}, maxsize=10, currsize=7)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7'}, maxsize=10, currsize=8)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8'}, maxsize=10, currsize=9)
FIFOCache({0: 'cache0', 1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8', 9: 'cache9'}, maxsize=10, currsize=10)
FIFOCache({1: 'cache1', 2: 'cache2', 3: 'cache3', 4: 'cache4', 5: 'cache5', 6: 'cache6', 7: 'cache7', 8: 'cache8', 9: 'cache9', 10: 'cache10'}, maxsize=10, currsize=10)
cachetools 使用示例
在这个示例中,我们使用 cachetools.LRUCache 创建一个 LRU 缓存。当我们调用 get_data_from_api() 函数时,会先检查缓存中是否有数据。如果缓存中有数据,就直接返回缓存的数据,避免了重复请求接口,提高了程序性能。
import requests
import cachetools# 创建一个 LRU 缓存,最大容量为 100
cache = cachetools.LRUCache(maxsize=100)def get_data_from_api(url):if url in cache:return cache[url] # 如果数据已经在缓存中,直接返回缓存的数据response = requests.get(url)response.raise_for_status()data = response.json()cache[url] = data # 将数据存储在缓存中return data# 使用缓存的函数
data = get_data_from_api("https://api.example.com/data")相关文章:

Python cachetools常用缓存算法汇总
文章目录 cachetools介绍缓存操作设置数据生存时间(TTL)自定义缓存策略缓存装饰器缓存清理cachetools 超过缓存数量maxsize cachetools 使用示例 cachetools介绍 cachetools : 是一个Python第三方库,提供了多种缓存算法的实现。缓存是一种用于…...
java类和对象_成员变量方法修饰符局部变量this关键字-cnblog
java类和对象 成员变量 权限修饰符 变量类型 变量名; 成员变量可以是任意类型,整个类是成员变量的作用范围 成员变量 成员方法 权限修饰符 返回值类型 方法名() 成员方法可以有参数,也可以有返回值,用return声明 权限修饰符 private 只能在本类…...

海信和TCL雷鸟及各大品牌智能电视测评
买了型号为32E2F(9008)的海信智能的电视有一段时间了,要使用这个智能电视还真能考验你的智商。海信电视有很多优点,它的屏幕比较靓丽,色彩好看,遥控器不用对着屏幕就能操作。但也有不少缺点。 1. 海信智能电视会强迫自动更新操作…...
)
Linux 基本系统命令及其使用详解手册(六)
指令:mesg 使用权限:所有使用者 使用方式:mesg [y|n] 说明 : 决定是否允许其他人传讯息到自己的终端机介面 把计 : y:允许讯息传到终端机介面上。 n:不允许讯息传到终端机介面上 。 如果没有设定,则讯息传递与否则由终端机界…...

Oracle架构之段管理和区管理
文章目录 1 段1.1 简介1.1.1 定义1.1.2 分类 1.2 段空间的管理模式1.2.1 手工段空间管理(Manual Segment Space Management)1.2.2 自动段空间管理(Auto Segment Space Management) 1.3 段空间的手工管理(Manual Segmen…...

mybatis-plus转换数据库json类型数据为java对象
JacksonTypeHandler JacksonTypeHandler 可以实现把json字符串转换为java对象。同一类型的handler有: Fastjson2TypeHandlerFastjsonTypeHandlerGsonTypeHandlerJacksonTypeHandler 至于需要哪一个选一个用就好了 使用方式 在实体类中加入注解 TableName(value "table_…...

Java | Leetcode Java题解之第467题环绕字符串中唯一的子字符串
题目: 题解: class Solution {public int findSubstringInWraproundString(String p) {int[] dp new int[26];int k 0;for (int i 0; i < p.length(); i) {if (i > 0 && (p.charAt(i) - p.charAt(i - 1) 26) % 26 1) { // 字符之差为…...

诺贝尔物理奖与化学奖彰显AI力量,探索智能新边界
在今年的诺贝尔物理学奖和化学奖的颁奖典礼上,人工智能(AI)再次成为耀眼的明星。两位物理学奖得主约翰J霍普菲尔德和杰弗里E辛顿因在人工神经网络和机器学习领域的开创性工作而获奖,而化学奖则颁给了在蛋白质结构设计和预测方面做…...

基于京东:HotKey实现自动缓存热点Key!!!
一.引言 某些热点数据,我们提前如果能够预判到的话,可以提前人工给数据加缓存,也就是缓存预热,将其缓存在本地或者Redis中,提高访问性能同时,减低数据库压力,也减轻后端服务的压力。但是&#…...

★ 算法OJ题 ★ 二分查找算法
Ciallo~(∠・ω< )⌒☆ ~ 今天,塞尔达将和大家一起做几道二分查找算法算法题 ~ ❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️❄️ 澄岚主页:椎名澄嵐-CSDN博客 算法专栏:★ 优选算法100天 ★_椎名澄嵐的博客-CSDN博客…...

RTSP RTP RTCP SDP基础知识
理论 流(Streaming ) 是近年在 Internet 上出现的新概念,其定义非常广泛,主要是指通过网络传输多媒体数据的技术总称。 流式传输分为两种 顺序流式传输 (Progressive Streaming) 实时流式传输 (Real time Streaming) …...

静态变量、变量作用域、命名空间
静态变量 静态变量一般位于程序全局data区,只是编程语言根据它所在的scope做语言级别访问限制。 静态变量和全局变量 可以在C语言一个函数中定义static变量,并比较和全局变量的地址差异。 C系语言使用static关键字标示静态变量。 PHP使用大写的STATIC关键…...

Android笔记(二十四)基于Compose组件的MVVM模式和MVI模式的实现
仔细研究了一下MVI(Model-View-Intent)模式,发现它和MVVM模式非常的相识。在采用Android JetPack Compose组件下,MVI模式的实现和MVVM模式的实现非常的类似,都需要借助ViewModel实现业务逻辑和视图数据和状态的传递。在这篇文章中,…...

MySQL 是否支持 XML
MySQL 是否支持 XML:概述与应用 虽然 MySQL 主要以处理关系型数据为主,但它也提供了对 XML 数据的支持。XML(可扩展标记语言)是一种用于数据传输和存储的通用格式。在许多应用场景中,XML 被广泛用于数据交换、配置文件…...
)
pikachu靶场总结(四)
九、越权漏洞 1.概述 如果使用A用户的权限去操作B用户的数据,A的权限小于B的权限,如果能够成功操作,则称之为越权操作。 越权漏洞形成的原因是后台使用了 不合理的权限校验规则导致的。 一般越权漏洞容易出现在权限页面(需要登…...
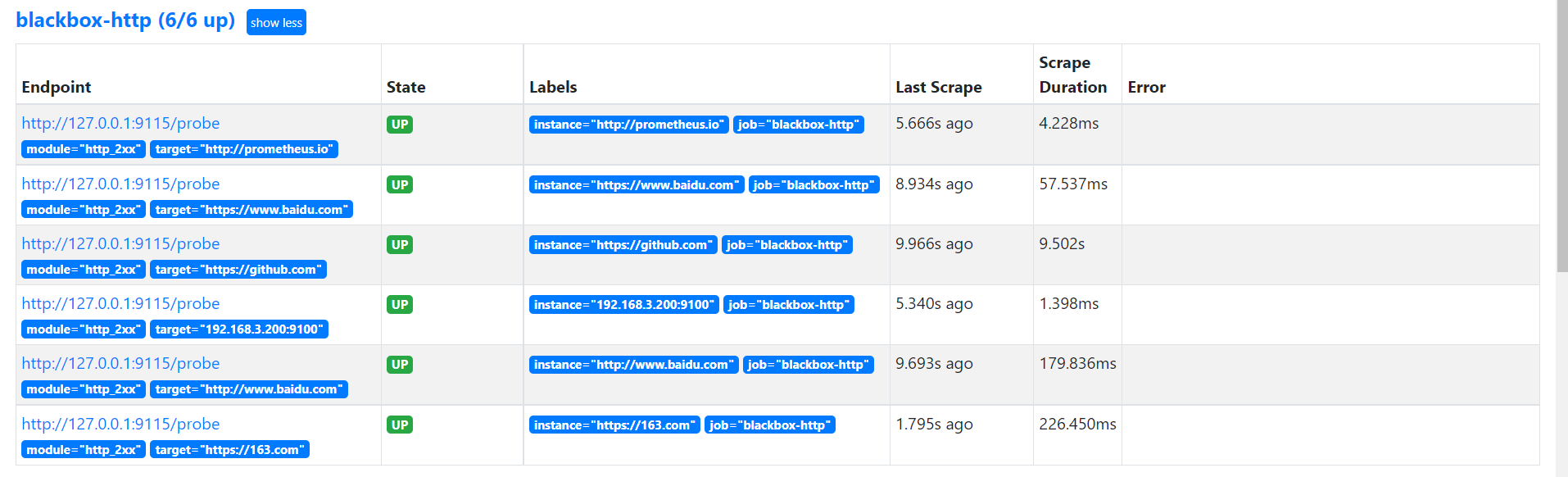
24.3 基于文件的服务发现模式
本节重点介绍 : 基于文件的服务发现提供了一种配置静态目标的更通用的方法可以摆脱对特定服务发现源的依赖通常的做法是调用内部CMDB的接口获取target数据,打上标签,生成json文件发给prometheus采集 基于文件的服务发现模式 解决的问题 之前手动配置…...

【Java】面向UDP接口的网络编程
【Java】面向UDP接口的网络编程 一. 基本通信模型二. APIDatagramSocketDatagramPacket 三. 回显服务器/客户端示例服务器客户端总结 一. 基本通信模型 UDP协议是面向数据报的,因此此处要构建数据报(Datagram)在进行发送。 二. API DatagramSocket DatagramSocke…...

SRS服务器搭建
1、配置 listen 1935; max_connections 1000; #srs_log_tank file; #srs_log_file ./objs/srs.log; daemon on; http_api { enabled on; listen 1985; } http_server { enabled on; listen 808…...
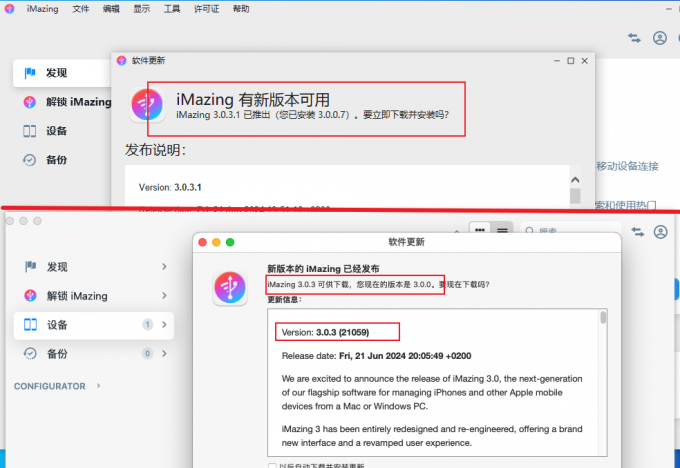
iMazing只能苹果电脑吗 Win和Mac上的iMazing功能有区别吗
在当今数字时代,管理和备份手机数据变得越来越重要。无论是转移照片、备份短信,还是管理应用程序,一个强大的工具可以大大简化这些操作。iMazing作为一款备受好评的iOS设备管理软件,已经成为许多用户的选择。但是,许多…...

ChatGPT可以分析股票吗?
结合国庆前大A股市的小波牛市以及今天的股市表现,我从多个角度为你提供一些分析和建议: 一、国庆前的小波牛市分析 国庆前,大A股市出现了一波小幅上涨,市场呈现出一些积极的信号: 政策面利好:政府出台了…...

智能体AI前景光明但挑战重重,企业级系统构建要素有哪些?
智能体AI:现状与挑战 在多智能体企业系统中,哪些技术、设计、标准、开发方法和安全实践正蓬勃发展?为此咨询了专家。智能体AI已成为软件行业新宠,其自主性不断增强,有望提升企业效率。Shopify应用机器学习主管Andrew M…...

real-anime-z开源可部署优势:离线环境稳定运行保障项目交付周期
real-anime-z开源可部署优势:离线环境稳定运行保障项目交付周期 1. 项目概述 real-anime-z是一款基于Z-Image基础镜像构建的LoRA模型,专注于生成高质量的真实动画风格图片。该项目采用Xinference框架进行模型服务部署,并通过Gradio提供用户…...
)
别再只用默认主题了!手把手教你为Obsidian换上5款高颜值社区主题(附CSS文件下载)
Obsidian视觉升级指南:5款高颜值主题深度评测与实战安装 第一次打开Obsidian时,那种极简的界面确实让人眼前一亮——直到你看到第100篇笔记依然保持着相同的黑白配色。作为一款以Markdown为核心的笔记工具,Obsidian的默认主题确实足够专注&am…...
)
Elasticsearch 实战:使用 boost 参数提高字段相关性得分(全文检索权重优化)
Elasticsearch 实战:使用 boost 参数提高字段相关性得分(全文检索权重优化)前言Elasticsearch boost 参数:提高字段相关性权重完整实战一、核心概念:boost 参数是什么?1.1 定义1.2 作用1.3 boost 工作流程图…...

期货交易系统部署三 — 交易
期货交易系统核心服务部署方案,覆盖期货交易、交易风控、日志监控全套流程,适配国内期货(CTP)国际期货(GPS、直达)。交易服务功能CTP 交易前置连接限价单、市价单、撤单账户、持仓、委托、成交查询风控&…...

22岁天才小伙破解“AI黑箱“:融合DeepSeek思路,参数效率翻倍!
本报讯 人工智能领域近日传来震动性消息:一位年仅22岁的年轻创业者,仅凭公开资料和对"第一性原理"的深刻理解,竟成功推导出了Anthropic公司号称"捂得最严实"的Claude Mythos大模型核心架构,并将完整代码开源至…...
为数学建模论文提供高效复现与智能排版的一体化解决方案)
爱毕业(aibiye)为数学建模论文提供高效复现与智能排版的一体化解决方案
还在为论文写作头痛?特别是数学建模的优秀论文复现与排版,时间紧、任务重,AI工具能帮上大忙吗?今天,我们评测10款热门AI论文写作工具,帮你精准筛选最适合的助手。 aibiye:专注于语法润色与结构…...

2025届学术党必备的六大降AI率方案实测分析
Ai论文网站排名(开题报告、文献综述、降aigc率、降重综合对比) TOP1. 千笔AI TOP2. aipasspaper TOP3. 清北论文 TOP4. 豆包 TOP5. kimi TOP6. deepseek 基于自然语言处理跟深度学习算法构建了AI论文查重系统,它会对文本语义展开细致分…...

TI DP83822I的Strap Pin配置避坑指南:如何根据RMII模式与LED需求精准计算电阻值
DP83822I Strap Pin配置实战:从模式选择到电阻计算的完整设计指南 在以太网硬件设计中,PHY芯片的strap pin配置往往是决定系统稳定性的关键细节。以TI的DP83822I为例,其strap pin不仅决定了RMII/RGMII等工作模式,还影响着LED行为、…...

避坑指南:不是所有MATLAB程序都适合用GPU加速,这4类情况要小心
GPU加速MATLAB的四大陷阱:如何避免性能反降? 最近在帮同事优化一个图像处理项目时,遇到了典型的GPU加速困境——原本期待3-5倍的性能提升,实际测试却只快了不到20%,某些参数下甚至比CPU版本更慢。这让我意识到…...