大模型1-本地部署实现交互问答
任务
在本地部署大模型,调用大模型进行对话。
添加库:
1、Transformer
Transformers 是由 Hugging Face 开发的一个开源库,广泛应用于自然语言处理(NLP)任务。其主要功能是简化了对大型预训练语言模型的加载和使用。它提供了数百种预训练的模型,涵盖了多种 NLP 任务。Transformers 支持多种不同类型的 Transformer 模型架构,涵盖了近年来最先进的 NLP 模型。以下是一些知名模型架构:
- BERT (Bidirectional Encoder Representations from Transformers):双向编码器,用于生成上下文的词向量。
- GPT (Generative Pretrained Transformer):生成型预训练模型,擅长生成流畅的文本。
- T5 (Text-To-Text Transfer Transformer):将所有任务转换为文本生成问题,支持多任务学习。
- RoBERTa:BERT 的改进版本,通过更多的数据和计算资源训练,性能更好。
- DistilBERT:BERT 的简化版,参数更少、速度更快,但仍能保持高性能。
- XLNet:结合了自回归和自编码器的优点,擅长生成任务。
- Bart:适合文本生成、摘要等任务,双向编码、左到右生成。
2、streamlit
Streamlit 是一个开源的 Python 库,专为快速构建和分享数据应用(data apps)而设计。通过 Streamlit,开发者可以使用非常简洁的 Python 代码将数据分析或机器学习模型可视化,并创建交互式的 Web 应用程序。Streamlit 的主要目标是降低开发和部署数据应用的复杂性,使得数据科学家和工程师可以专注于业务逻辑,而不需要深度了解前端开发。
简而言之就是提供了一个用户交互页面,不需要前端代码。
Streamlit 提供了许多用于构建用户界面的组件,使用户能够与数据进行交互。以下是一些常用的组件:
st.write(): 通用的输出函数,支持文字、数据框、图表等的输出。st.title(): 用于创建应用的标题。st.text()和st.markdown(): 显示文本,支持 Markdown 格式。st.image(): 显示图片。st.button(): 创建一个按钮,用户点击后触发事件。st.slider(): 滑块,允许用户选择数值范围。st.selectbox(): 下拉选择框。st.file_uploader(): 文件上传组件,支持用户上传文件。st.form(): 用于处理表单输入,用户可以提交多个字段。
主要添加的库如下:
from transformers import AutoTokenizer, AutoModelForCausalLM # 大模型加载必要的函数
import torch
import streamlit as st
# 源大模型下载
from modelscope import snapshot_download # 阿里的魔塔涵盖了很多大模型,下载速度超级快,而且qwen系列模型也挺好用的,算是国内数一数二的开源模型了
注意:
1、运行使用命令:streamlit run xxx.py
2、可能需要下载的包:einops、sentencepiece
3、使用魔塔modelscope下载模型,模型可以去魔塔社区寻找。
from modelscope import snapshot_download
model_dir = snapshot_download('模型ID', cache_dir='您希望的下载路径', revision='版本号')
加载大模型
大模型加载最重要的就是tokenizer和model,
1. Tokenizer(分词器)
Tokenizer 是将自然语言文本转换为模型可理解的数字化表示的工具。它负责将输入的文本转化为词(或子词)ID,然后传递给模型。具体来说,Tokenizer 的作用包括:
- 分词:将文本拆分成词或子词(这取决于模型的分词方式,比如 BERT 使用的 WordPiece,GPT 使用的 Byte-Pair Encoding (BPE))。
- 编码:将分词后的文本转换为词汇表中的唯一标识(IDs)。
- 填充与截断:确保输入的长度符合模型的要求(通常是固定长度),通过在短于要求的序列后添加填充(padding),或者截断超长的序列。
- 特殊标记处理:如开始标记 (
[CLS])、结束标记 ([SEP]) 等,这些标记通常在处理输入序列时是必须的,尤其是在任务如分类和生成中。
示例
from transformers import AutoTokenizer
# 加载 Tokenizer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
# 将文本转换为输入 ID
inputs = tokenizer("Hello, how are you?", return_tensors="pt")
2. Model(模型)
Model 是预训练的大型神经网络模型,通常是 Transformer 架构,用于执行特定的任务(如语言建模、文本生成、问答、翻译等)。模型的任务可以包括:
- 生成文本(如 GPT 模型)
- 进行分类(如 BERT 在情感分析、分类任务中)
- 生成摘要(如 T5 或 Bart 模型)
- 回答问题(如 BERT 在问答系统中)
示例
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载 tokenizer 和 model
tokenizer = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2").cuda()
# 编码输入文本,将字符转为ID
inputs = tokenizer("Hello, how are you?", return_tensors="pt").to('cuda')
# 模型生成文本
outputs = model.generate(inputs['input_ids'], max_length=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))注意:
1、generate() 是 transformers 库中用于文本生成的函数。它会根据输入的 token ID(即 inputs['input_ids'])生成一段新的文本。
2、inputs['input_ids']:这是模型输入的 token ID 序列,来自于上一步 tokenizer 处理后的结果。模型会根据这些 token 来生成下一个 token。
3、tokenizer.decode(outputs[0], skip_special_tokens=True):
outputs[0]:outputs是一个 batch,其中outputs[0]是我们关心的第一条生成结果。tokenizer.decode():将模型生成的 token ID 序列转换回人类可读的文本字符串。skip_special_tokens=True:告诉tokenizer在解码时忽略特殊的 token,比如[CLS]、[SEP]等。某些模型在处理过程中会加入这些特殊的 token,但它们通常不需要出现在最终的输出文本中。
4、AutoTokenizer负责加载预训练的分词器, AutoModelForCausalLM负责加载语言模型。AutoTokenizer.from_pretrained函数的相关参数可参考AutoTokenizer.from_pretrained参数说明,AutoModelForCausalLM.from_pretrained函数的相关参数可参考AutoModelForCausalLM.from_pretrained参数说明
示例
1、Yuan2-2B-Mars-hf模型
源2.0 是浪潮信息发布的新一代基础语言大模型。我们开源了全部的3个模型源2.0-102B,源2.0-51B和源2.0-2B。并且我们提供了预训练,微调,推理服务的相关脚本,以供研发人员做进一步的开发。源2.0是在源1.0的基础上,利用更多样的高质量预训练数据和指令微调数据集,令模型在语义、数学、推理、代码、知识等不同方面具备更强的理解能力。
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st# 创建一个标题和一个副标题
st.title("AI助手")# 源大模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('IEITYuan/Yuan2-2B-Mars-hf', cache_dir='./')# 定义模型路径
path = './IEITYuan/Yuan2-2B-Mars-hf'# 定义模型数据类型
torch_dtype = torch.bfloat16 # A10
# torch_dtype = torch.float16 # P100# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():print("Creat tokenizer...")tokenizer = AutoTokenizer.from_pretrained(path, add_eos_token=False, add_bos_token=False, eos_token='<eod>')tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>'], special_tokens=True)print("Creat model...")model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch_dtype, trust_remote_code=True).cuda()print("Done.")return tokenizer, model# 加载model和tokenizer
tokenizer, model = get_model()# 初次运行时,session_state中没有"messages",需要创建一个空列表
if "messages" not in st.session_state:st.session_state["messages"] = []# 每次对话时,都需要遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:st.chat_message(msg["role"]).write(msg["content"])# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():# 将用户的输入添加到session_state中的messages列表中st.session_state.messages.append({"role": "user", "content": prompt})# 在聊天界面上显示用户的输入st.chat_message("user").write(prompt)# 调用模型prompt = "<n>".join(msg["content"] for msg in st.session_state.messages) + "<sep>" # 拼接对话历史inputs = tokenizer(prompt, return_tensors="pt")["input_ids"].cuda()outputs = model.generate(inputs, do_sample=False, max_length=1024) # 设置解码方式和最大生成长度output = tokenizer.decode(outputs[0])response = output.split("<sep>")[-1].replace("<eod>", '')# 将模型的输出添加到session_state中的messages列表中st.session_state.messages.append({"role": "assistant", "content": response})# 在聊天界面上显示模型的输出st.chat_message("assistant").write(response)
运行结果:

显存占用情况:

2、qwen2-1.5b-instruct模型
Qwen2 是 Qwen 大型语言模型系列的新篇章。对于 Qwen2,我们发布了从 0.5 到 720 亿参数不等的基础语言模型与指令调优语言模型,其中包括混合专家(Mixture-of-Experts)模型。本仓库包含了 1.5B 参数的 Qwen2 指令调优模型。
用原来的的代码运行会出问题,运行结果如下:

猜测是因为不同模型的运行规则有所不同,因此按照qwen文档说明修改代码:
# 导入所需的库
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
import streamlit as st
# 源大模型下载
from modelscope import snapshot_download
model_dir = snapshot_download('qwen/Qwen2-1.5B-Instruct', cache_dir='./')
# 创建一个标题和一个副标题
st.title("AI助手")# 定义模型路径
path = './qwen/Qwen2-1___5B-Instruct'
# path = './IEITYuan/Yuan2-2B-Mars-hf'
# 定义一个函数,用于获取模型和tokenizer
@st.cache_resource
def get_model():print("Creat tokenizer...")tokenizer = AutoTokenizer.from_pretrained(path, add_eos_token=False, add_bos_token=False, eos_token='<eod>')tokenizer.add_tokens(['<sep>', '<pad>', '<mask>', '<predict>', '<FIM_SUFFIX>', '<FIM_PREFIX>', '<FIM_MIDDLE>','<commit_before>','<commit_msg>','<commit_after>','<jupyter_start>','<jupyter_text>','<jupyter_code>','<jupyter_output>','<empty_output>','<|im_end|>'], special_tokens=True)print("Creat model...")model = AutoModelForCausalLM.from_pretrained(path, torch_dtype=torch.bfloat16, trust_remote_code=True).cuda()print("Done.")return tokenizer, model# 加载model和tokenizer
tokenizer, model = get_model()# 初次运行时,session_state中没有"messages",需要创建一个空列表
if "messages" not in st.session_state:st.session_state["messages"] = []# 每次对话时,都需要遍历session_state中的所有消息,并显示在聊天界面上
for msg in st.session_state.messages:st.chat_message(msg["role"]).write(msg["content"])# 如果用户在聊天输入框中输入了内容,则执行以下操作
if prompt := st.chat_input():# 将用户的输入添加到session_state中的messages列表中st.session_state.messages.append({"role": "user", "content": prompt})# 在聊天界面上显示用户的输入st.chat_message("user").write(prompt)# 调用模型messages = [{"role": "system", "content": "You are Qwen, created by Alibaba Cloud. You are a helpful assistant."},]for msg in st.session_state.messages:messages.append(msg)print(messages)text = tokenizer.apply_chat_template(messages,tokenize=False,add_generation_prompt=True,)inputs = tokenizer([text], return_tensors="pt").to(model.device)outputs = model.generate(**inputs, max_length=1024) # 设置解码方式和最大生成长度generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(inputs.input_ids, outputs)]response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]# 将模型的输出添加到session_state中的messages列表中st.session_state.messages.append({"role": "assistant", "content": response})# 在聊天界面上显示模型的输出st.chat_message("assistant").write(response)输出结果如下:

这下没啥问题了,所以对不同模型,要根据对应文档编写使用程序。qwen2-1.5b-instruct显存占用如下:

参考文献:
1、Streamlit完全指南:交互式应用开发从入门到精通 - 知乎 (zhihu.com)
2、Task3:源大模型RAG实战 - 飞书云文档 (feishu.cn)
相关文章:
大模型1-本地部署实现交互问答
任务 在本地部署大模型,调用大模型进行对话。 添加库: 1、Transformer Transformers 是由 Hugging Face 开发的一个开源库,广泛应用于自然语言处理(NLP)任务。其主要功能是简化了对大型预训练语言模型的加载和使用…...

鸿蒙架构-系统架构师(七十八)
1信息加密是保证系统机密性的常用手段。使用哈希校验是保证数据完整性的常用方法。可用性保证合法用户对资源的正常访问,不会被不正当的拒绝。()就是破坏系统的可用性。 A 跨站脚本攻击XSS B 拒绝服务攻击DoS C 跨站请求伪造攻击CSRF D 缓…...
大数据存储计算平台EasyMR:多集群统一管理助力企业高效运维
随着全球企业进入数字化转型的快车道,数据已成为企业运营、决策和增长的核心驱动力。为了处理海量数据,同时应对数据处理的复杂性和确保系统的高可用性,企业往往选择部署多个Hadoop集群,这样的策略可以将生产环境、测试环境和灾备…...

代理IP的类型及其在爬虫中的应用
1 动态住宅代理 这些IP地址来自真实的住宅用户,因此具有很高的匿名性和隐私性,不易被别为代理IP。而增加了爬虫任务的安全性。这类代理有以下特点: 高安全性:使用这类代理可发起真实有效的请求,提高爬虫效率的同时&am…...
)
鸿蒙Swiper动态加载翻页数据(等同于安卓动态加载viewPager)
我这里是加载一个实体类列表 类似 List 的数据,那么首先写一个dataSource: export class MyDataSource implements IDataSource {private list: MyBean[] []constructor(list: MyBean[]) {this.list list}totalCount(): number {return this.list.len…...

嵌入式面试——FreeRTOS篇(八) Tickless低功耗
本篇为:FreeRTOS Tickless 低功耗模式篇 一、低功耗模式简介 1、低功耗介绍 答: 很多应用场合对于功耗的要求很严格,比如可穿戴低功耗产品、物联网低功耗产品等;一般MCU都有相应的低功耗模式,裸机开发时可以使用MCU的…...

基于facefusion的换脸
FaceFusion是一个引人注目的开源项目,它专注于利用深度学习技术实现视频或图片中的面部替换。作为下一代换脸器和增强器,FaceFusion在人脸识别和合成技术方面取得了革命性的突破,为用户提供了前所未有的视觉体验。 安装 安装基础软件 安装…...
)
Hive数仓操作(十三)
一、JSON 数据 JSON(JavaScript Object Notation)是一种轻量级的数据交换格式,在不同的编程语言之间进行数据传输时非常通用和常用。JSON 格式简单直观,易于阅读和编写,并且可以被大多数编程语言轻松解析和生成。 1.…...

MyBatis XML映射文件
XML映射文件 XML映射文件的名称与Mapper接口名称一致,并且将XML映射文件和Mapper接口放置在相同包下(同包同名)XML映射文件的namespace属性为Mapper接口全限定名一致XML映射文件中SQL语句的id与Mapper接口中的方法名一致,并保持返…...

「PYTHON」配置支持cuda计算的torch环境
本教程用于配置可支持cuda加速计算的torch环境 如果单纯使用命令行的pip安装torch,几乎都是cpu版本的,所以想要下载支持cuda的torch,我们只能通过手动下载安装包到本地,再使用pip从下载好的本地文件离线安装 而要想使用cuda加速…...
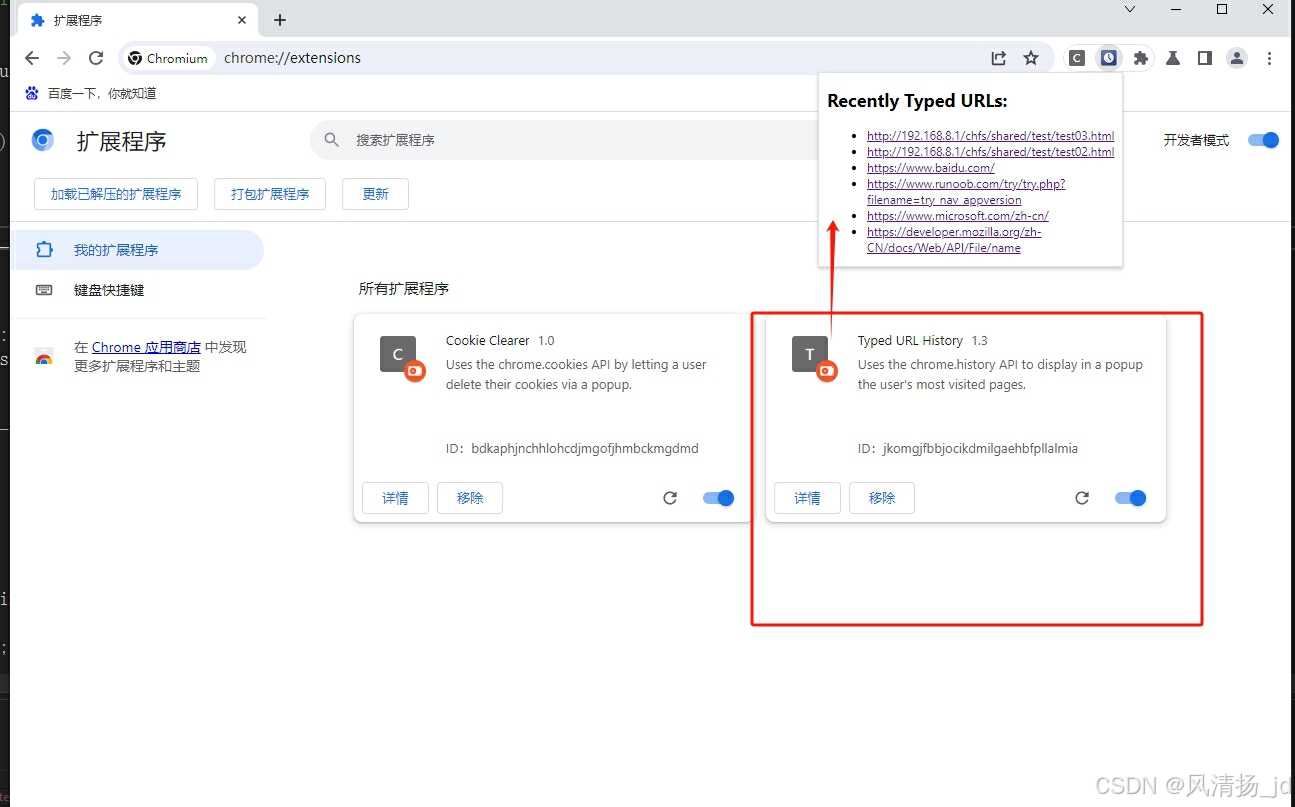
Chromium 中chrome.history扩展接口c++实现
一、前端 chrome.history定义 使用 chrome.history API 与浏览器的已访问网页的记录进行交互。您可以在浏览器的历史记录中添加、移除和查询网址。如需使用您自己的版本替换历史记录页面,请参阅覆盖网页。 更多参考:chrome.history | API | Chrome…...

(Linux和数据库)1.Linux操作系统和常用命令
了解Linux操作系统介绍 除了办公和玩游戏之外不用Linux,其他地方都要使用Linux(it相关) iOS的本质是unix(unix是付费版本的操作系统) unix和Linux之间很相似 Linux文件系统和目录 bin目录--放工具使用的 操作Linux远程…...

Linux——echo-tail-重定向符
echo命令 类似printf 输出 反引号 重定向符 > 和 >> > 覆盖 >> 追加 tail命令 查看文件尾部内容,追踪文件最新更改 tail -num 从尾部往上读num行,默认10行 tail -f 持续跟踪...
--配置)
GitHub Copilot 使用手册(一)--配置
一、 什么是GitHub Copilot GitHub Copilot 是GitHub和OpenAI合作开发的一个人工智能工具,在使用Visual Studio Code、Microsoft Visual Studio、Vim、Cursor或JetBrains等IDE时可以协助用户编写代码等工作,实现虚拟的结对编程。 二、 GitHub Copilot …...
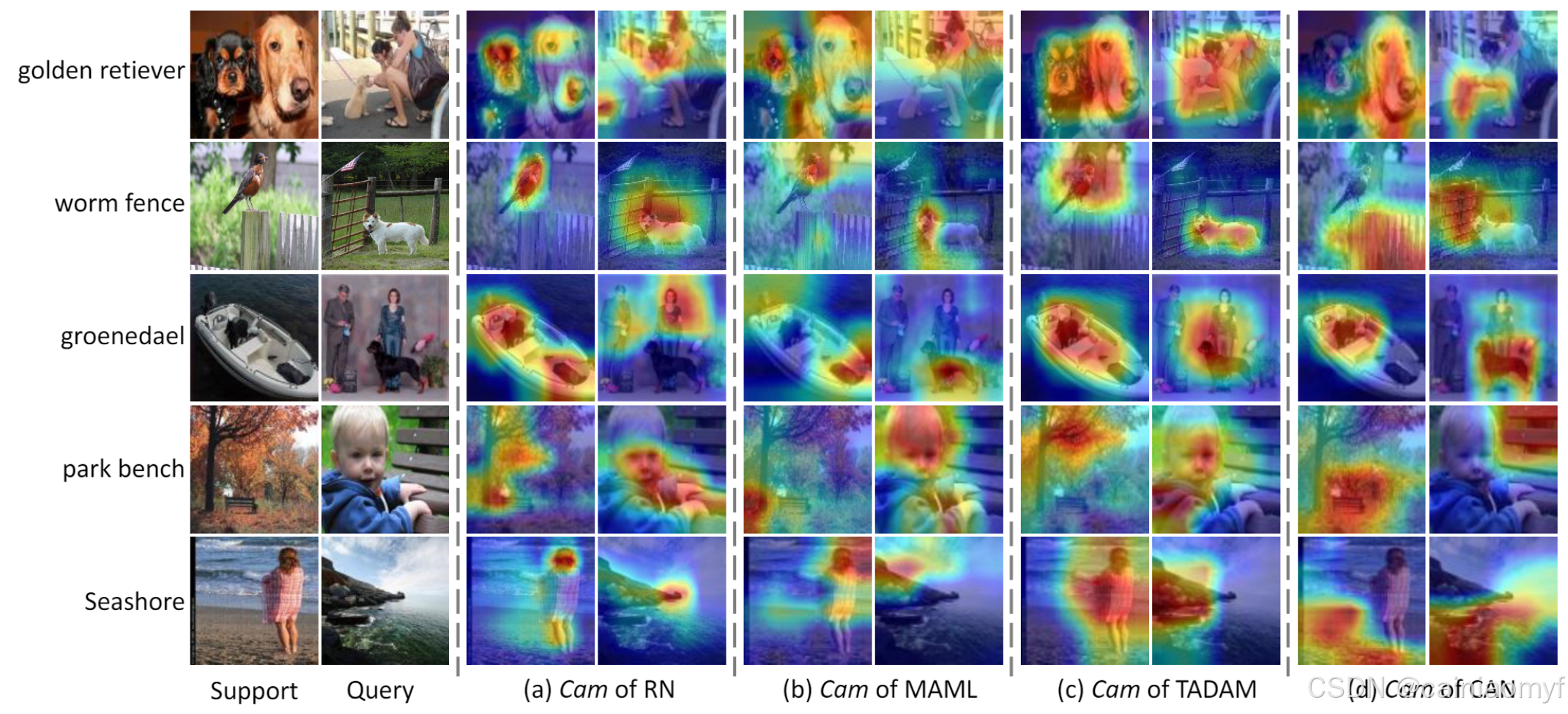
【论文阅读】Cross Attention Network for Few-shot Classification
用于小样本分类的交叉注意力网络 引用:Hou, Ruibing, et al. “Cross attention network for few-shot classification.” Advances in neural information processing systems 32 (2019). 论文地址:下载地址 论文代码:https://github.com/bl…...
CV图像处理小工具——json文件转P格式mask
CV图像处理小工具——json文件转P格式mask import cv2 import json import numpy as np import osdef func(file_path: str) -> np.ndarray:try:with open(file_path, moder, encoding"utf-8") as f:configs json.load(f)# 检查JSON是否包含必要的字段if "…...

Typora 快捷键操作大全
Typora 是一款简洁的 Markdown 编辑器,它提供了一些快捷键来帮助用户更高效地编辑文档。以下是一些常用的 Typora 快捷键,这些快捷键可能会根据操作系统有所不同(Windows 和 macOS): 常用格式化快捷键 加粗ÿ…...
<Project-8.1.1 pdf2tx-mm> Python 调用 ChatGPT API 翻译PDF内容 历程心得
原因 用ZhipuAI,测试用的PDF里,有国名西部省穆斯林,翻译结果返回 “系统检测到输入或生成内容可能包含不安全或敏感内容,请您避免输入易产生敏感内容的提 示语,感谢您的配合” 。想过先替换掉省名、民族名等ÿ…...

JDK1.1主要特性
JDK 1.1,也被称为Java Development Kit 1.1,是Java编程语言的第一个更新版本,由Sun Microsystems公司在1997年发布。JDK 1.1在JDK 1.0的基础上进行了许多重要的改进和扩展,进一步巩固了Java作为一种强大、安全的编程语言和平台的地…...

软件测试工作中-商城类项目所遇bug点
商城的 bug 1、跨设备同步问题 当用户在不同设备上使用同一个账户时,购物车数据无法正确同步这可能是由于购物车数据存储和同步机制不完善,导致购物车内容在设备之间无法实时更新。怎么解决:开发把同步机制代码修改了一下,就不会出现这个 bug 了。 2、数…...

ChatGPT资源宝库:从提示工程到项目实践的完整指南
1. 项目概述:一份关于ChatGPT的“Awesome”清单意味着什么?如果你最近在GitHub上搜索过任何与ChatGPT、AI或提示工程相关的内容,那么你大概率见过一个以“awesome-”开头的仓库。而sindresorhus/awesome-chatgpt无疑是这个领域里最知名、最常…...

从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会?
从《西部世界》到现实:AI智能体如何重塑游戏NPC与虚拟社会? 当《西部世界》中的NPC开始拥有记忆、情感和自主决策能力时,观众惊叹于科幻与现实的边界正在模糊。如今,大型语言模型(LLM)驱动的AI智能体正将这…...
)
告别迷茫!在嵌入式Linux上用libwebsockets v4.0实现WebSocket客户端(含SSL配置避坑)
嵌入式Linux实战:libwebsockets v4.0客户端开发与SSL避坑指南 当树莓派的GPIO引脚需要与云端实时同步数据时,WebSocket往往是嵌入式开发者的首选协议。但面对内存仅512MB的ARMv7开发板,选用一个既支持SSL加密又能兼容C99标准的轻量级库&#…...

【人生底稿 28】新疆出差终章:几番波折终汇报,尽兴踏归津门路
三日游玩尽数落幕,忙碌工作正式回归。轻松的闲暇时光悄然收尾,紧绷的工作状态再次上线。整趟新疆之行,在起伏辗转中迎来最终收尾。一、深夜复盘材料,彻夜待汇报游玩结束回到酒店,我没有松懈休息,静下心重新…...

AI智能体密钥安全管理:AgentVault架构解析与实战指南
1. 项目概述:一个为AI智能体打造的“保险箱”最近在折腾AI智能体(Agent)应用开发的朋友,估计都绕不开一个核心痛点:如何安全、可靠地管理智能体运行过程中需要用到的各种密钥、凭证和敏感数据?无论是调用Op…...

Windows平台QT BLE开发避坑指南:从环境搭建到稳定通信
1. Windows平台QT BLE开发环境搭建 在Windows平台上使用QT进行BLE开发,首先需要确保开发环境正确配置。我遇到过不少开发者因为环境问题卡在第一步,白白浪费好几天时间。这里分享几个关键点: 编译器选择是第一个坑。实测发现必须使用MSVC编译…...

【实战指南】STM32CubeMX UART配置进阶:从阻塞到中断+DMA的高效数据通信
1. UART通信模式选择指南 第一次接触STM32的UART通信时,很多人都会纠结该用哪种模式。我在实际项目中尝试过所有模式,总结下来就是:没有最好的模式,只有最适合当前场景的模式。先说说三种典型场景: 调试打印࿱…...

智慧树自动刷课终极指南:3分钟快速上手Autovisor免费工具
智慧树自动刷课终极指南:3分钟快速上手Autovisor免费工具 【免费下载链接】Autovisor 2025智慧树刷课脚本 基于Python Playwright的自动化程序 [有免安装版] 项目地址: https://gitcode.com/gh_mirrors/au/Autovisor 还在为智慧树网课的手动操作烦恼吗&#…...

通达信数据解析终极指南:mootdx让金融数据获取变得如此简单
通达信数据解析终极指南:mootdx让金融数据获取变得如此简单 【免费下载链接】mootdx 通达信数据读取的一个简便使用封装 项目地址: https://gitcode.com/GitHub_Trending/mo/mootdx 在金融数据分析和量化交易的世界里,获取准确、完整的市场数据是…...

终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析
终极游戏性能调优指南:DLSS Swapper智能管理工具深度解析 【免费下载链接】dlss-swapper 项目地址: https://gitcode.com/GitHub_Trending/dl/dlss-swapper 游戏体验痛点剖析:当DLSS版本成为性能瓶颈 你是否曾在畅玩《赛博朋克2077》时…...