Linux搭建Hadoop集群(详细步骤)
前言
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
说白了就是实现一个任务可以在多个电脑上计算的过程。
一:准备工具
1.1 VMware
1.2Linux服务器(两台,创建一个克隆一个即可)
1.3 hadoop-2.7.3.tar(Hadoop的安装文件)
1.4 jdk-8u65-linux-x64.t.gz(hadoop是基于java的,要有java的jdk)
1.5.SSH服务(远程连接工具)
1.6Xshell或者 winSCP(远程传输工具)
VMware的安装下载和Linux服务器的创建请参考这篇文章;
虚拟机开启SSH服务以及Xshell连接服务器请参考这篇文章。
两个安装文件,大家可以在网盘自行获取:
通过网盘分享的文件:jdk及Hadoop
链接: https://pan.baidu.com/s/1tnHohO3GHNFAuWZqiq51lg?pwd=2rxu 提取码: 2rxu
二:Linux服务器的配置
最好是一开始就切换到管理员模式(输入su,回车后输入登录密码),便于后续对文件的操作。
目前是两台服务器,你需要确定一台为主节点,另一台为子节点。这个待会我们会修改主机名称来区分两个节点,我这里一台命名为hadoop01,一台是hadoop02(这些是创建主机时设置的名字,随时都可以重命名)。
2.1 服务器IP的查看
刚创建的服务器的IP分配一般都是DHCP模式,这时可以查看到网卡中的IP信息,每个人的IP地址是不同的,你需要根据自己的IP地址进行配置。
在命令行输入
ifconfig


接下来需要进行静态IP的配置,并检查两台服务器是否可以上网,可以和本地机通信。最好是都配置成静态IP,防止重启时IP变化,出现无法连接的情况。
2.2静态IP的配置
刚才我们查看了IP地址,网关查看步骤点击VMware工作台左上角"编辑“——》虚拟网络编辑器——》NET设置——》网关IP(每个人的网关也不同)
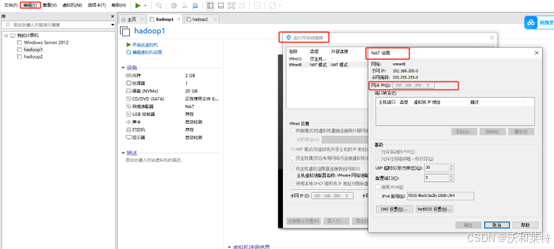
根据自己的IP和网关,可以提前在记事本上写上以下配置信息
#Hadoop01:
IPADDR=192.168.132.128
NETMASK=255.255.255.0
GATEWAY=192.168.132.2(网关可以在虚拟网络上设置上查看,一般都是xxx.xxx.xxx.2)
DNS1:8.8.8.8
#和hadoop01一样,我们配置hadoop02的网卡信息
Hadoop02:
IPADDR=192.168.132.129
NETMASK=255.255.255.0
GATEWAY=192.168.132.2
DNS1:8.8.8.8
然后进入一个文件夹,然后查看当前目录下是否有你的网卡文件,我们要进入网卡中修改IP地址信息
cd /etc/sysconfig/network-scripts
 我这边的网卡文件是ifcfg-ens160,进入这个文件中
我这边的网卡文件是ifcfg-ens160,进入这个文件中
vi ifcfg-ens160
我们看到原始的信息,接下来在需要修改我标注的地方(进入该文件中需要按“i”键盘,进入编辑模式,修改完成后按“ Esc”键,退出编辑模式,然后输入“ :wq”保存并退出)。
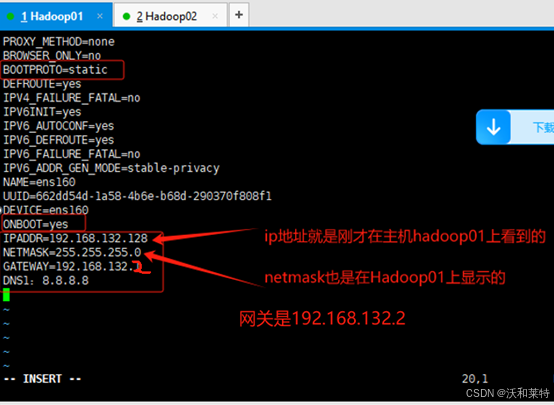
同样的操作,我们也把hadoop02的静态IP配置好。
修改完成后reboot重启,两台都要重启(当然你也可以按照接下来的步骤修改完主机映射后再重启)。
为了保证我们的主机都能上网,需要再在本地机的控制面板中修改VMnet8中配置IP地址和网关:控制面板——》网络和共享中心——》更改适配器设置——》双击VMnet8——》属性——》找到TCP/ipv4——》使用下面的IP地址。
更改完成后确定。
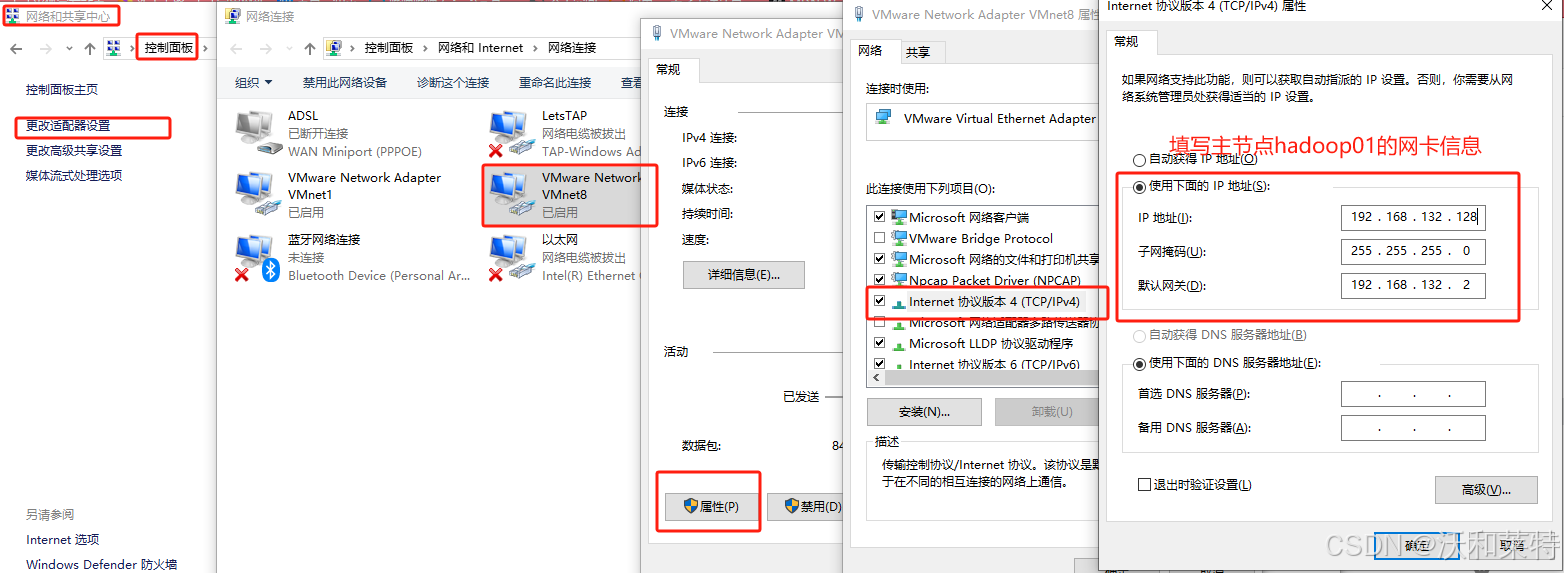
然后测试两台主机能否上网,直接ping百度。如果有问题的话,可以参考这篇文章,希望能有所帮助。


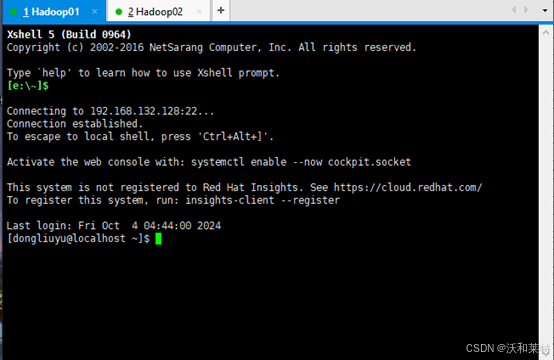
2.3Xshell连接服务器(接下来的操作均在Xshell上完成)
为了便于后续传输文件给服务器,我们使用远程传输工具Xshell(这个你可以自行选择,winSCP也可以),连接两台服务器。
2.4修改主机名
我这里时hadoop01为主节点,hadoop02是子节点。名字的修改是为了区分这两个节点
hostnamectl set-hostname(空格)主机名

2.5修改主机名称以及主机映射
由于后面的步骤我们会多次使用到IP地址,因此这里修改IP地址和主机名的映射会方便我们后续的操作。
vi /etc/hosts
i键进入编辑模式,输入以下信息后保存退出。
192.168.132.128 hadoop01
192.168.132.129 hadoop02
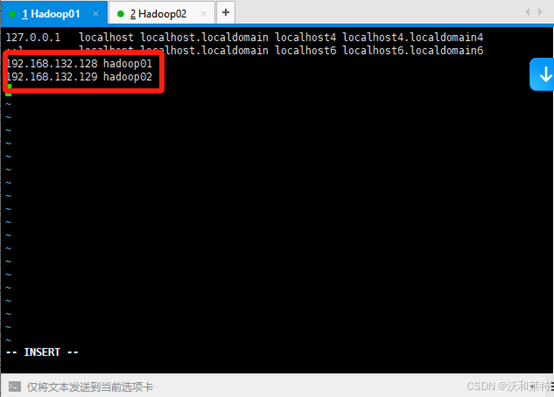
同样的,hadoop02也是这样的操作
操作完成之后重启主机
reboot
那么重启之后,我们会发现主机名称已经完成更改了,此时我们就可以直接ping 主机名,就可以测试通信了。

你也可以用本地机直接ping虚拟机服务器名

2.6配置免密登录
首先关闭防火墙
systemctl stop firewalld.service
回到根目录
cd /
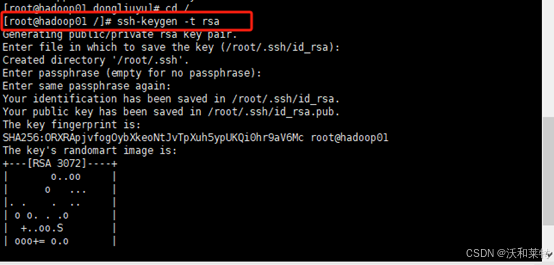
生成公钥和私钥(前提是你的主机已经安装了ssh服务,并且已经开此服务。如果没有安装ssh,请参考这篇文章)
执行命令,生成公钥私钥
ssh-keygen -t rsa
一直回车即可
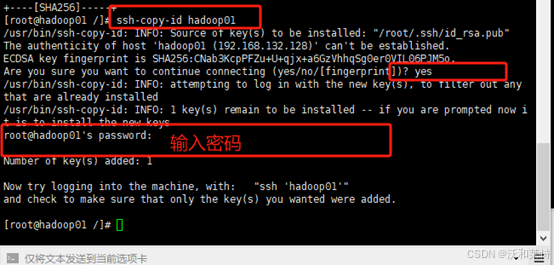
拷贝密钥到主节点
ssh-copy-id hadoop01
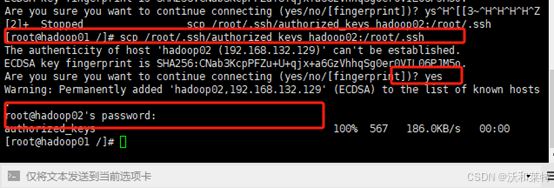
复制分发放置公钥的文件给其他虚拟机(hadoop02)
scp /root/.ssh/authorized_keys hadoop02:/root/.ssh
目前主机的配置工作就完成了,接下来我们就需要往主机上传一些安装包。
三:上传并配置jdk
(以下是两台主机都需要操作,有需要一台主机的我会标注)。在上传安装包之前,我们先在两台主机上创建几个文件夹,用来存放我们解压出的数据
3.1创建文件夹
Hadoop01和hadoop02都要创建
放置数据
mkdir -p /export/data
软件安装目录
mkdir -p /export/servers
放置软件包
mkdir -p /export/software

3.2 下载一个rz的插件,我们待会上传文件时需要用到
前提是你已经安装了yum源,才可以通过yum来下载安装rz插件
yum install lrzszcd -y
如果输入命令后报错,应该就是没有安装yum,可以参考以下操作。
yum的安装
直接使用wget下载(前提是你的虚拟机上中的服务器是可以正常联网的)
#进入系统YUM源的目录,查看该目录下有多少yum源
cd /etc/yum.repos.d我的只有一个之前安装过的yum源,但是很多软件都无法安装了,因此下载一个新的yum源

本文我们用的是阿里源,阿里源的网址是:https://mirrors.aliyun.com/repo/,你可以找到适合自己的版本进行下载,以下是下载命令,你只需要将后面的版本改成自己的而即可。
wget -O /etc/yum.repos.d/CentOS-Base.repo https://mirrors.aliyun.com/repo/Centos-vault-8.5.2111.repo
安装完成以后你可以查看当前目录下yum的个数

 然后你就可以使用yum安装工具啦
然后你就可以使用yum安装工具啦
比如你可以下载lrzsz插件,实现本地文件通过Xshell上传到虚拟机。
yum install lrzsz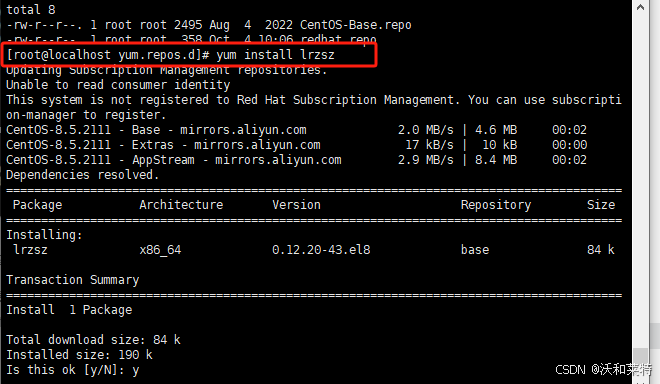
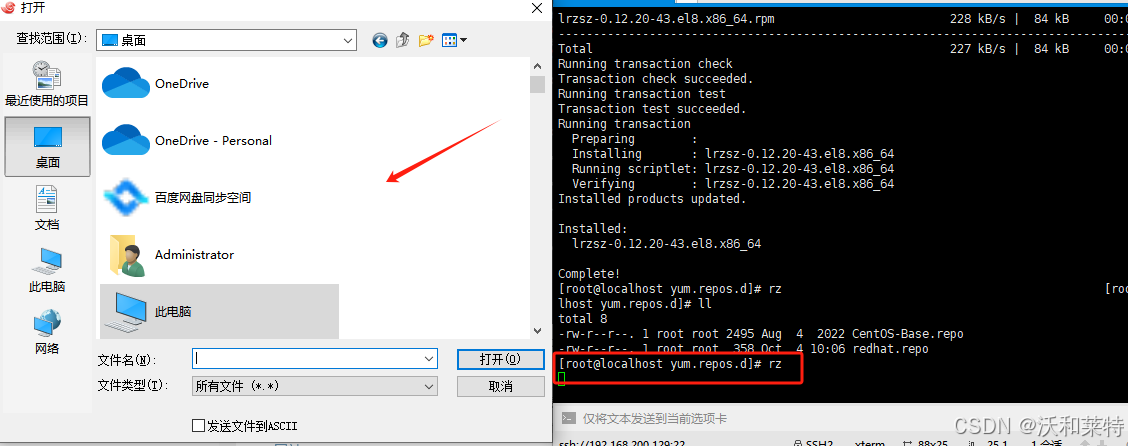
你在Xshell中输入rz,即可打开你的本地文件夹,你可以选取需要上传到服务器的文件。
3.3 查看主机上是否安装有jdk
java -version
搜索目前的jdk
rpm -qa | grep jdk
没有的话就不需要再卸载了

如果有的话,需要进行卸载
rpm -e –nodeps 搜索得到的jdk名
注意,这个是需要一条一条的卸载的。卸载完成可以执行搜索命令查看下有没有没卸载的。
3.4 安装jdk(以下操作主节点hadoop01配置即可)
先切换到我们刚才创建的software目录下
cd /export/software
然后输入rz命令,通过Xshell将jdk包传入

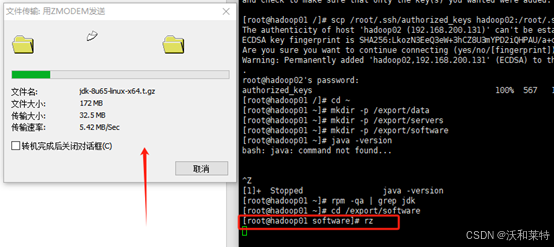
点击关闭即可

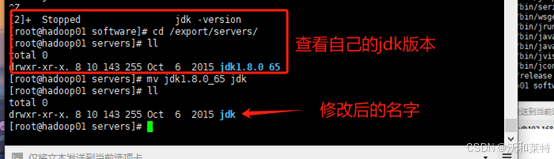
3.5解压jdk
解压到我们创建好的servers文件夹中
tar -zxvf jdk-8u65-linux-x64.t.gz -C /export/servers/
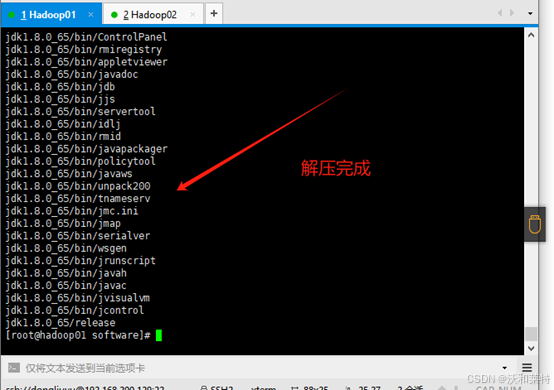
切换路径
cd /export/servers/
重命名为jdk
mv jdk1.8.0_65 jdk
3.6配置jdk变量
vi /etc/profile
添加以下内容,写的是你的jdk路径(注意等号的前后不要有空格,否则无法识别)
export JAVA_HOME=/export/servers/jdk
export PATH=$PATH:$JAVA_HOME/bin
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar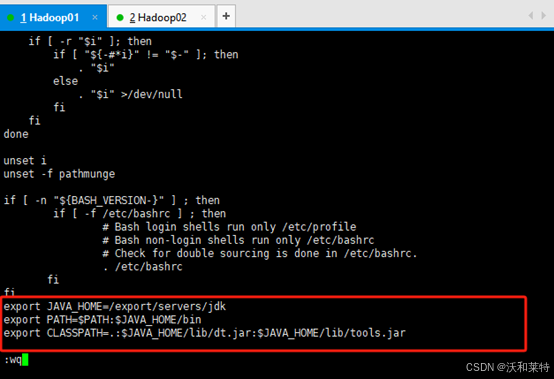
保存退出后我们重新加载一下环境变量
source /etc/profile
然后检查下Java版本
java -version
 如果是提示权限不够,可以输入以下命令增加权限
如果是提示权限不够,可以输入以下命令增加权限
chmod -R +x /export/servers/jdk/bin/java
3.7将主节点hadoop01配置完成的jdk文件分发给hadoop02节点
在当前目录下输入ll,查看jdk的路径以及名称
然后切换到jdk目录
cd jdk

然后输入命令查看当前完整路径
pwd
 然后切换到/export/servers/
然后切换到/export/servers/
cd /export/servers/
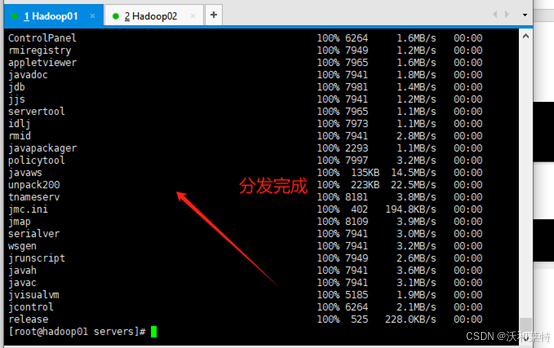
再将jdk文件给hadoop02节点
scp -r /export/servers/jdk hadoop02:$PWD
回车执行后可能需要输入密码,输入即可
3.8分发环境变量配置
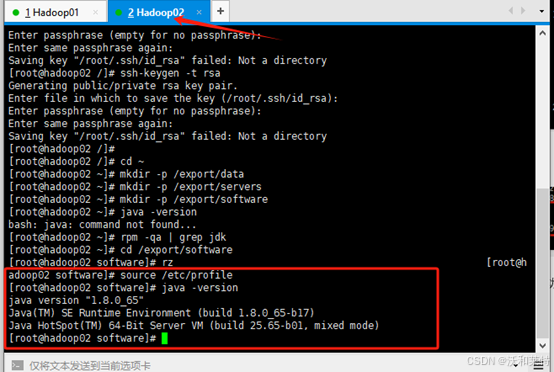
hadoop01
scp /etc/profile root@hadoop02:/etc/profile
将hadoop02切换到创建好的software目录,结合hadoop02加载环境变量,再用java -version验证是否成功
hadoop02
source /etc/profile
到此为止,两台主机的jdk文件及其环境变量配置完成,接下来安装Hadoop文件,并完成对其的文件和环境变量的配置。
四:Hadoop的安装和配置
4.1上传Hadoop安装包(以下操作主节点hadoop01配置即可)
进入下列目录
cd /export/software
然后rz上传Hadoop安装包

对安装包进行解压安装,解压路径为创建的servers目录
tar -zxvf hadoop-2.7.3.tar.gz -C /export/servers/
解压完成之后,切换目录
cd /export/servers/
给Hadoopjdk文件重命名
mv hadoop-2.7.3 hadoop

4.2配置Hadoop的系统环境变量
进入编辑模式
vi /etc/profile
添加以下内容
export HADOOP_HOME=/export/servers/hadoop
export PATH=:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
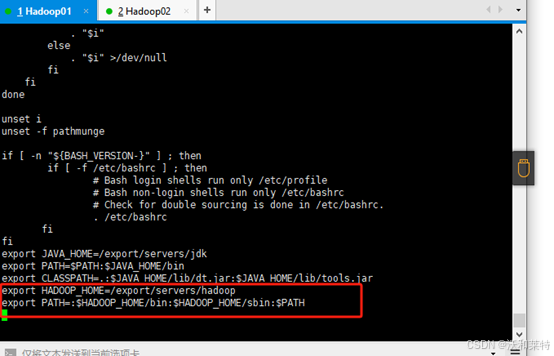
保存退出后,加载环境变量
source /etc/profile
检查是否安装成功
hadoop version
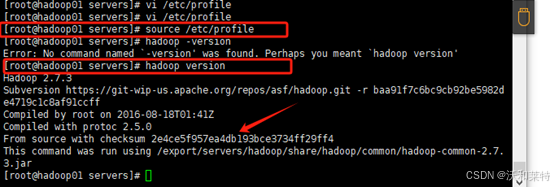
安装成功!
4.3 修改Hadoop配置文件
(1)hadoop-env.sh文件
切换目录
cd /export/servers/hadoop/etc/hadoop/
进入编辑模式
vi hadoop-env.sh
修改内容如下(将jdk的路径修改成自己的)
export JAVA_HOME=/export/servers/jdk
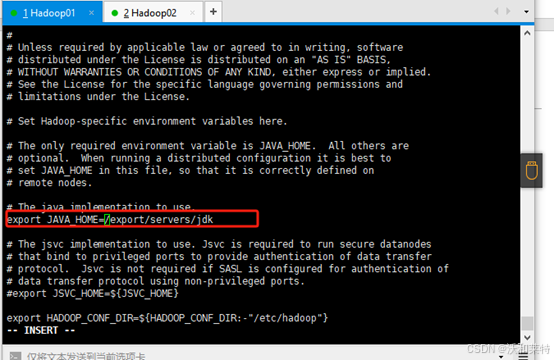
保存退出
(2)修改core-site.xml文件
进入编辑模式
vi core-site.xml
添加内容为:
<property><name>fs.defaultFS</name>#写成你的主节点主机名<value>hdfs://hadoop01:9000</value>
</property>
<property><name>hadoop.tmp.dir</name>#代表后面我们格式化文件的路径,如果是格式化多次,需要将该目录删掉<value>/export/servers/hadoop/tmp</value>
</property>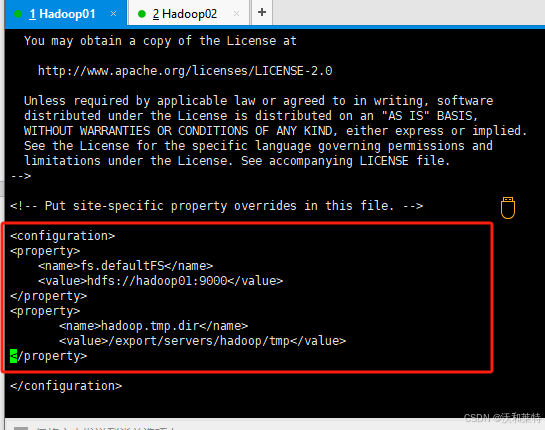
保存退出
(3)修改hdfs-site.xml 文件
进入编辑模式
vi hdfs-site.xml
添加以下内容
<property><name>dfs.replication</name>#代表你的子节点个数,也就是我这里的hadoop02<value>1</value>
</property>
<property><name>dfs.namenode.secondary.http.address</name>#子节点的主机名<value>hadoop02:50090</value>
</property>
 保存退出
保存退出
(4)修改mapred-site.xml文件
修改之前需要先拷贝一下mapred-site.xml.template文件,命名为mapred-site.xml
输入命令
cp mapred-site.xml.template mapred-site.xml
进入编辑
vi mapred-site.xml
输入以下命令
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
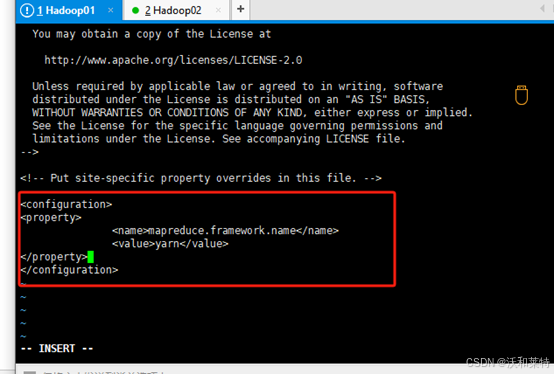
(5)修改yarn-site.xml文件
进入编辑模式
vi yarn-site.xml
添加以下命令
#将含端口的value标签中的节点名改成你自己的主节点名字
<property><name>yarn.resourcemanager.address</name><value>hadoop01:8032</value>
</property>
<property><name>yarn.resourcemanager.scheduler.address</name><value>hadoop01:8030</value>
</property>
<property><name>yarn.resourcemanager.resource-tracker.address</name><value>hadoop01:8031</value>
</property>
<property><name>yarn.resourcemanager.admin.address</name><value>hadoop01:8033</value>
</property>
<property><name>yarn.resourcemanager.webapp.address</name><value>hadoop01:8088</value>
</property>
<property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value>
</property>
<property><name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name><value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
(6)修改 slaves文件
该文件十分重要,因为启动Hadoop 的时候,系统总是根据当前 slaves 文件中 slave 节点名称列表启动集群,不在列表中的slave节点便不会被视为计算节点。
进入编辑模式
vi slaves
修改内容为两台虚拟机的主机名(也就是你的主节点和子节点的名字)
 保存退出
保存退出
4.4将配置好的环境分发给另一台主机
scp /etc/profile hadoop02:/etc/profile
scp -r /export/ hadoop02:/
由于hadoop中配置的文件较多,因此分发时比较慢

4.5 在hadoop02上重新加载下环境
source /etc/profile
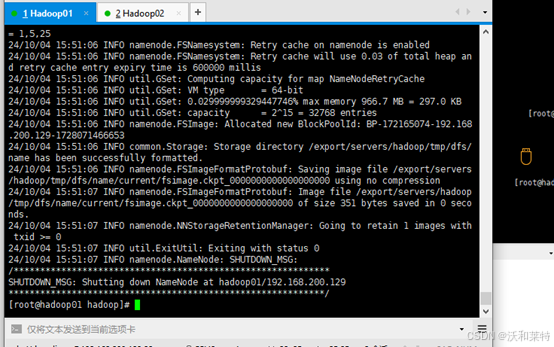
4.6格式化集群(hadoop01主节点完成)
本次格式化只需要第一次启动集群时进行
使用命令
hdfs namenode -format
4.7开启集群服务(hadoop01主节点完成)
先关闭防火墙(两台都要关闭)
systemctl stop firewalld
关闭防火墙开机自启
systemctl disable firewalld
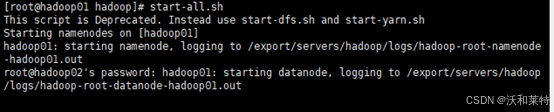
开启集群服务
start-dfs.sh 或 stop-dfs.sh
#一键开启集群服务
start-all.sh 或 stop-all.sh
查看jps,可以先将权限设为777
chmod 777 /export/servers/jdk/bin/jps
可以看到,目前主节点显示的是五个进程
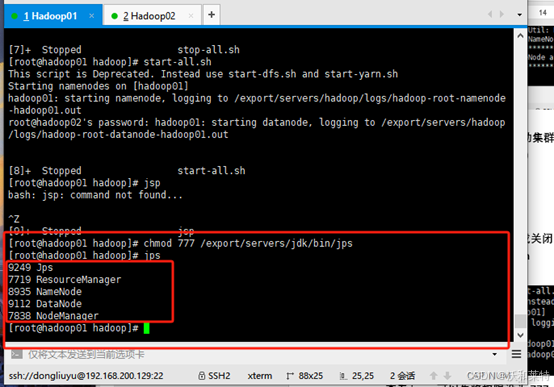
4.8查看子节点进程
子节点hadoop02的进程:

你也可以查看集群报告:
hdfs dfsadmin -report
停止集群报告
stop-all.sh
到此为止,Hadoop的集群环境已经配置完毕,接下来检测下能否在浏览器中正常访问端口。
五:验证Hadoop是否配置成功
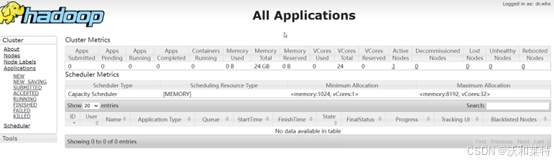
本地浏览器输入
hadoop01:50070
出现以下图片就说明你的Hadoop集群环境搭建成功啦!

你也可以访问8088端口
hadoop01:8088
以上就是Hadoop环境的搭建步骤,如有不足,感谢补充。
六:参考
从零开始Hadoop安装和配置,图文手把手教你,定位错误(已部署成功)
视频参考
相关文章:
Linux搭建Hadoop集群(详细步骤)
前言 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。 说白了就是实现一个任务可以在多个电脑上计算的过程。 一:准备工具 1.1 VMware 1.2L…...

MongoDB中如何实现相似度查询
在 MongoDB 中,进行相似度查询通常涉及文本搜索或基于特定字段的相似度计算。以下是几种常见的方法: 1. 使用文本索引和文本搜索 MongoDB 提供了文本索引功能,可以对字符串字段进行全文搜索。你可以使用 $text 操作符来执行文本搜索查询。 …...

F开头的词根词缀:ful
60.-ful (1)表形容词,“有…的” grateful a 感激的(grate感激) rueful a 后悔的(rue悔恨) willful a 任性的(will意志…任意办事) tactful a 圆滑的(tact手腕…...

【python开发笔记】-- python装饰器
装饰器: 不修改被装饰对象的源代码,也不修改调用方式的前提下,给被装饰对象添加新的功能 原则:开放封闭原则 开放:对扩展功能(增加功能开放),扩展功能的意思是在源代码不做任何改变…...

WEB攻防-python考点CTF与CMS-SSTI模板注入PYC反编译
知识点: 1、PYC(python编译后的文件)文件反编译; 2、Python-Web-SSTI; 3、SSTI模板注入利用分析; (Server-Side Template Injection) SSTI 就是服务器端模板注入 当前使用的一…...

Open3D实现点云数据的序列化与网络传输
转载自个人博客:Open3D实现点云数据的序列化与网络传输 在处理点云数据的时候,有时候需要实现点云数据的远程传输。当然可以利用传输文件的方法直接把点云数据序列化成数据流进行传输,但Open3D源码在实现RPC功能时就提供了一套序列化及传输的…...

【C++11】右值引用
前言: 在C11中引入的右值引用(rvalue references)是现代C的一个重要特性,它允许开发者以更高效的方式处理临时对象(右值),避免不必要的拷贝,提升性能。右值引用通常与C11的**移动语义…...

CSS元素显示类型
display 属性是 CSS 中最重要的属性之一,主要用来控制元素的布局,通过 display 属性您可以设置元素是否显示以及如何显示。 根据元素类型的不同,每个元素都有一个默认的 display 属性值,例如<div>默认的 display 属性值为 …...
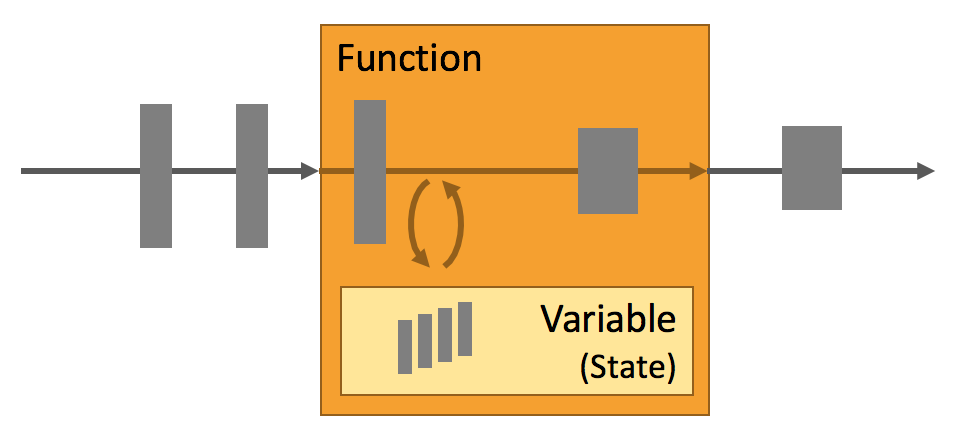
Flink 介绍(特性、概念、故障容错、运维部署、应用场景)
概述 特性 概念 数据流 状态 时间 savepoint 故障容错 运维部署 部署应用到任意地方 Flink能够更方便地升级、迁移、暂停、恢复应用服务 监控和控制应用服务 运行任意规模应用 应用场景 事件驱动型应用 什么是事件驱动型应用? 事件驱动型应用的优势 Flink如何…...

Python+Flask接口判断身份证省份、生日、性别、有效性验证+docker部署+Nginx代理运行
这里写目录标题 一、接口样式二、部署流程2.1 镜像打包2.1.1 准备工作2.1.2 build打包2.1.3 dokcer部署运行2.1.4 Nginx代理 三、代码及文件3.1 index.py3.2 areaCodes.json3.3 Dockerfile 一、接口样式 https://blog.henryplus.cn/idcardApi/idCard/query?idcard{idcard} 二、…...
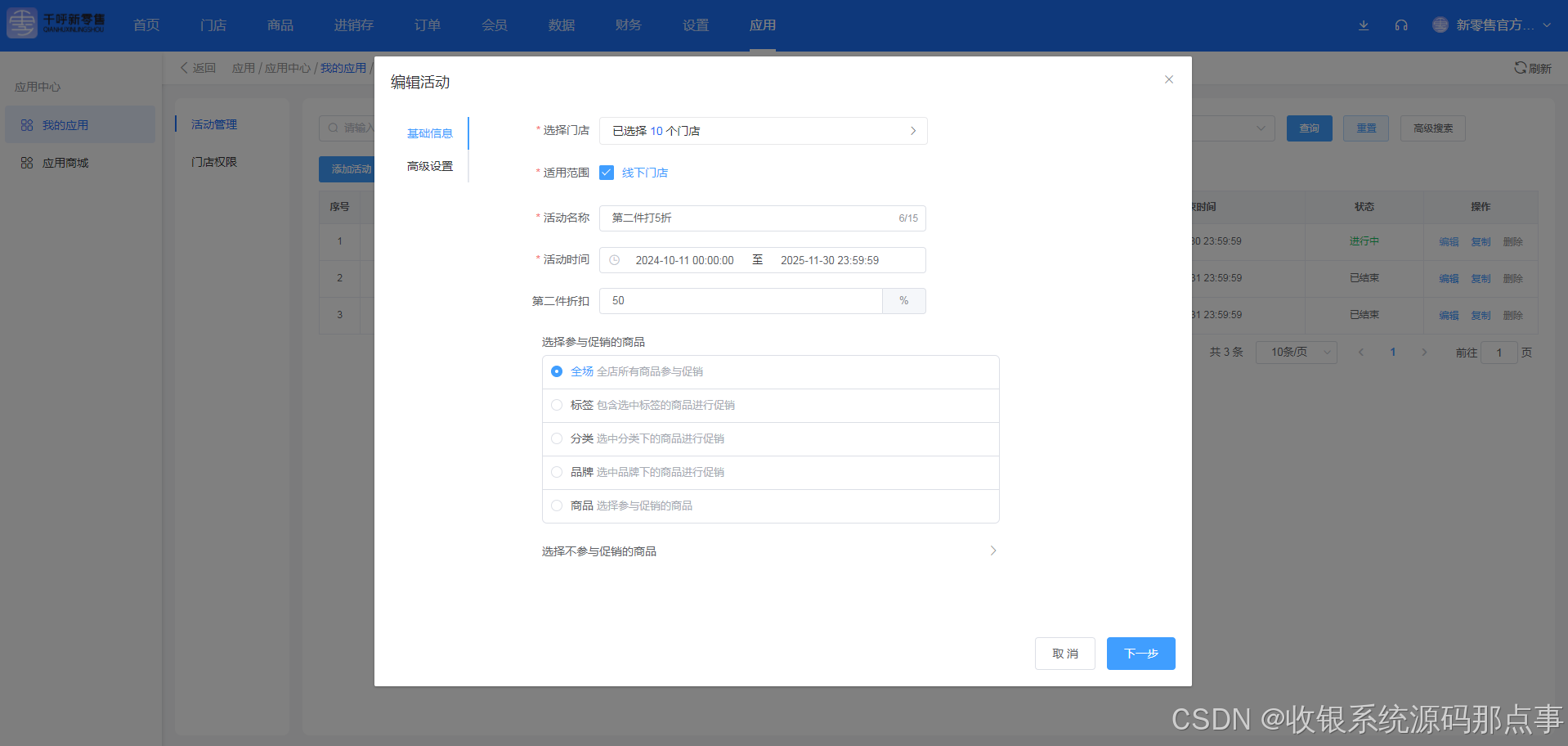
门店收银营销活动打折特价-收银系统源码
1.功能描述 功能描述:连锁店总部/门店可以将商品设置第二件打折,如保温杯第一件10元,第二件5折; 2.适用场景 ☑新店开业、门店周年庆、节假日等特定时间促销; ☑会员拉新,设置会员专享套餐; …...

QTabWidget的每个tab居中显示图标和文本
使用QTabWidget,给每个tab添加了图标之后,文字和图标之间有间距,没有完美居中显示。 遇到此问题,尝试了多种办法,均不理想,最终自定义QTabBar,重绘tab,完美解决。 #include <QT…...

Ubuntu20.04如何安装Microsoft Edge浏览器?
Microsoft Edge是由微软开发的一款网页浏览器,首次发布于2015年,作为Windows 10操作系统的默认浏览器,取代了之前的Internet Explorer。 基于Chromium内核:自2019年起,Microsoft Edge转向了使用开源的Chromium内核,这使得它与Google Chrome在性能和兼容性方面有很多相似之…...

美团Java一面
美团Java一面 9.24一面,已经寄了 收到的第一个面试,表现很不好 spring bean生命周期 作用域(忘完了) 为什么用redis缓存 redis和数据库的缓存一致性问题 redis集群下缓存更新不一致问题 aop说一下 arraylist和linkedlist 数据库的…...

C#中ref关键字和out关键字
值传递和引用传递 值传递和引用传递是编程中涉及数据传递的两种方式。它们的主要区别在于数据是如何在函数或方法之间传递的。 值传递 值传递意味着当你把一个变量传递给一个函数时,实际上传递的是这个变量的值的一个拷贝。也就是说,函数内部对这个参数…...

贴吧软件怎么切换ip
在网络使用中,有时我们需要切换IP地址来满足特定的需求,比如需要切换贴吧软件IP以进行不同的操作。本文将介绍几种贴吧切换IP地址的方法,帮助用户更好地管理自己的网络身份和访问权限。 1、更换网络环境 通过连接到不同的Wi-Fi网络或使用移…...

图像分割恢复方法
传统的图像分割方法主要依赖于图像的灰度值、纹理、颜色等特征,通过不同的算法将图像分割成多个区域。这些方法通常可以分为以下几类: 1.基于阈值的方法 2.基于边缘的方法 3.基于区域的方法 4.基于聚类的方法 下面详细介绍这些方法及其示例代码。 1. 基…...

Ultralytics:YOLO11使用教程
Ultralytics:YOLO11使用教程 前言相关介绍前提条件实验环境安装环境项目地址LinuxWindows YOLO11使用教程进行目标检测进行实例分割进行姿势估计进行旋转框检测进行图像分类 参考文献 前言 由于本人水平有限,难免出现错漏,敬请批评改正。更多…...

前缀和算法——优选算法
个人主页:敲上瘾-CSDN博客 个人专栏:游戏、数据结构、c语言基础、c学习、算法 一、什么是前缀和? 前缀和是指从数组的起始位置到某一位置(或矩阵的某个区域)的所有元素的和。这种算法通过预处理数组或矩阵,…...

YOLO11改进|注意力机制篇|引入HAT超分辨率重建模块
目录 一、HAttention注意力机制1.1HAttention注意力介绍1.2HAT核心代码 二、添加HAT注意力机制2.1STEP12.2STEP22.3STEP32.4STEP4 三、yaml文件与运行3.1yaml文件3.2运行成功截图 一、HAttention注意力机制 1.1HAttention注意力介绍 HAT模型 通过结合卷积特征提取与多尺度注意…...
)
保姆级教程:用Sen2Cor批量处理Sentinel-2 L1C到L2A(Win/Linux通用,附避坑清单)
遥感数据处理实战:Sen2Cor高效批量处理Sentinel-2 L1C至L2A全流程指南 当面对数百景Sentinel-2 L1C数据需要转换为L2A级别时,手动逐景处理不仅效率低下,还容易因操作失误导致数据不一致。本文将分享一套经过实际项目验证的批处理方案…...

AUTOSAR Ea模块深度剖析:从原理到实战的EEPROM抽象层配置与优化
1. 项目概述:为什么我们需要深入理解Ea模块?在AUTOSAR的软件架构里,NVRAM管理器(NvM)负责非易失性数据的抽象管理,而Ea(EEPROM Abstraction,EEPROM抽象)模块,…...

GEE实战:Landsat 8 TOA和SR数据去云处理,保姆级代码对比与避坑指南
GEE实战:Landsat 8 TOA与SR数据去云处理深度解析 当你在Google Earth Engine(GEE)平台上处理Landsat 8数据时,是否曾为选择TOA(大气层顶反射率)还是SR(地表反射率)而犹豫不决&#x…...

2026 AI 技术生态全景指南:从 LLM 到 Agent,从 MCP 到 A2A
AI 技术生态指南 整合 AI/ML/DL 核心概念、模型对比、基础设施与工具链的完整参考。 你是否也有这些困惑? 🤔 GPT、Claude、Gemini、DeepSeek、Qwen…20 模型到底怎么选? 🤔 MCP 和 A2A 这两个新协议有什么区别?谁提出…...

3分钟掌握OBS智能跟拍:告别手动调焦的直播神器
3分钟掌握OBS智能跟拍:告别手动调焦的直播神器 【免费下载链接】obs-face-tracker Face tracking plugin for OBS Studio 项目地址: https://gitcode.com/gh_mirrors/ob/obs-face-tracker 您是否曾因直播时频繁调整镜头位置而分心?是否希望有一个…...

轴承‘健康体检’新思路:不用复杂公式,5步教你用CNN从振动信号中‘看’出故障先兆
轴承健康监测:用CNN像AI医生一样"听诊"振动信号 想象一下,医生通过听诊器捕捉心跳的微妙变化,就能预判潜在的健康风险。在工业设备的"健康管理"中,轴承的振动信号就像它的"心跳",而卷积…...
)
告别Modelsim命令行!用Notepad++插件NppExec一键检查Verilog语法(附详细配置命令)
硬件工程师的效率革命:Notepad与Verilog语法检查的终极整合方案 在数字电路设计领域,Verilog作为主流硬件描述语言,其语法检查是每位工程师日常工作中不可或缺的环节。传统工作流程中,工程师们不得不在文本编辑器与EDA工具之间频繁…...

RK3568扩展模块实战:4G/Wi-Fi 6/多串口集成与Linux驱动适配
1. 项目概述:当“小”模块遇上“大”平台最近在折腾一块瑞芯微的RK3568开发板,这板子性能不错,四核A55加上独立的NPU,做边缘计算、多媒体网关或者轻量级服务器都挺合适。但在实际项目落地时,我遇到了一个几乎所有硬件开…...

5分钟掌握LXMusic音源配置:告别音乐资源匮乏的终极指南
5分钟掌握LXMusic音源配置:告别音乐资源匮乏的终极指南 【免费下载链接】LXMusic音源 lxmusic(洛雪音乐)全网最新最全音源 项目地址: https://gitcode.com/guoyue2010/lxmusic- 还在为找不到心仪歌曲而烦恼吗?你是否厌倦了…...

反向Shell隐藏技术深度解析:从进程伪装到网络隐匿的攻防实践
1. 项目概述:从“隐藏”到“隐匿”的攻防博弈在网络安全领域,反向Shell是一种经典且常见的远程控制手段。简单来说,它让被控端主动连接控制端,从而绕过防火墙等入站限制。然而,一个明晃晃的、持续存在的网络连接或进程…...