数据分析练习——学习一般分析步骤
目录
一、准备工作
二、导入库和数据
1、导入必要的库:
2、模拟数据
三、数据分析过程
1、读取数据:
2、数据概览和描述性统计:
2.1、查看数据概览:
2.2、查看描述性统计:
3、数据清洗:
3.1、处理缺失值:
3.2、处理异常值:
3.3、处理重复数据:
4、EDA(探索性数据分析):
4.1、相关性分析:查看数值型变量之间的相关性
4.2、分类数据分析:
4.3、数据分布分析:
4.4、双变量分析:分析两个变量之间的关系。例如,使用散点图查看 units_sold 和 price_per_unit 之间的关系
4.5、时间序列分析:如果数据包含时间信息,可以分析各个变量随时间的变化趋势。在我们的示例中,首先需要将 order_date 转换为 datetime 类型
4.6、多变量分析:分析多个变量之间的关系。例如,分析不同 product_category 的 units_sold 和 price_per_unit 之间的关系
4.7、箱线图分析
5、数据建模与分析
6、数据可视化
ps:据建模与分析、数据可视化显示结果的解释
7、结果解释和报告
四、学习过程中一些问题的回答
1、通过训练模型并对测试数据进行预测,预测了什么,为什么要预测?
2、”评估这种关系的存在程度以及模型的预测能力“,如何评估以及为什么要评估?
3、为什么要找与项目需求和数据最适合的模型?
在这个实践项目中,我们将使用Python和一些常用的数据分析库(如Pandas、Matplotlib和Seaborn)进行数据分析。假设我们的目标是分析一个虚构的电商平台的销售数据,以获取关于产品销售、客户行为等方面的见解。
一、准备工作
首先,确保已经安装了Python及相关的数据分析库。在你的Python环境中安装以下库(如果尚未安装):
pip install pandas
pip install matplotlib
pip install seaborn
pip install scikit-learn
二、导入库和数据
1、导入必要的库:
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
2、模拟数据
将以下CSV格式数据复制到名为"sales_data.csv"的文件中
order_id,product_id,product_category,user_id,order_date,units_sold,price_per_unit,sales_amount
10001,2001,A,3001,2023-01-02,5,100,500
10002,2002,B,3002,2023-01-03,2,150,300
10003,2003,C,3001,2023-01-04,7,200,1400
10004,2004,D,3003,2023-01-05,4,50,200
10005,2005,A,3004,2023-01-06,3,100,300
10006,2001,A,3005,2023-01-07,6,100,600
10007,2002,B,3006,2023-01-08,3,150,450
10008,2003,C,3001,2023-01-09,8,200,1600
10009,2004,D,3007,2023-01-10,2,50,100
10010,2005,A,3008,2023-01-11,4,100,400
10011,2001,A,3009,2023-01-12,5,100,500
10012,2002,B,3010,2023-01-13,1,150,150
10013,,C,3011,2023-01-14,3,200,600
10014,2004,D,3012,2023-01-15,6,50,300
10015,2005,A,3013,2023-01-16,4,100,400
10016,2001,A,3014,2023-01-17,7,100,700
10017,2002,B,3015,2023-01-18,1,150,150
10018,2003,C,3016,2023-01-19,5,200,1000
10019,2004,D,3017,2023-01-20,3,50,150
10020,2005,A,3018,2023-01-21,6,100,600
10021,2001,A,3019,2023-01-22,4,100,400
10022,2002,B,3020,2023-01-23,3,150,450
10023,2003,C,3021,2023-01-24,2,200,400
10024,2004,D,3022,2023-01-25,6,50,300
10025,2005,A,3023,2023-01-26,4,100,400
10026,2001,A,3024,2023-01-27,5,100,500
10027,2002,B,3025,2023-01-28,3,150,450
10028,2003,C,3026,2023-01-29,15,200,3000
10029,2004,D,3027,2023-01-30,2,5000,100
三、数据分析过程
1、读取数据:
data = pd.read_csv('sales_data.csv')
2、数据概览和描述性统计:
2.1、查看数据概览:
print(data.head())
print(data.info())
2.2、查看描述性统计:
print(data.describe())
3、数据清洗:
3.1、处理缺失值:
# 查看缺失值
print(data.isnull().sum())# 用众数填充 product_category 缺失值
data['product_category'].fillna(data['product_category'].mode()[0], inplace=True)# 删除 product_id 为空的行
data.dropna(subset=['product_id'], inplace=True)3.2、处理异常值:
# 分析 price_per_unit 异常值
sns.boxplot(x=data['price_per_unit'])
plt.show()# 用四分位法去除异常值
Q1 = data['price_per_unit'].quantile(0.25)
Q3 = data['price_per_unit'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQRdata = data[(data['price_per_unit'] > lower_bound) & (data['price_per_unit'] < upper_bound)]
3.3、处理重复数据:
# 检查重复行
print(data.duplicated().sum())# 删除重复行
data.drop_duplicates(inplace=True)
4、EDA(探索性数据分析):
4.1、相关性分析:查看数值型变量之间的相关性
corr_matrix = data.corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm')
plt.show()
4.2、分类数据分析:
# 分析 product_category 的销售数量
category_units_sold = data.groupby('product_category')['units_sold'].sum()
category_units_sold.plot(kind='bar')
plt.show()# 分析 product_category 的销售金额
category_sales_amount = data.groupby('product_category')['sales_amount'].sum()
category_sales_amount.plot(kind='bar')
plt.show()
4.3、数据分布分析:
# 分析 units_sold 数据分布
sns.histplot(data['units_sold'])
plt.show()# 分析 price_per_unit 数据分布
sns.histplot(data['price_per_unit'])
plt.show()# 分析 sales_amount 数据分布
sns.histplot(data['sales_amount'])
plt.show()
4.4、双变量分析:分析两个变量之间的关系。例如,使用散点图查看 units_sold 和 price_per_unit 之间的关系
sns.scatterplot(x='units_sold', y='price_per_unit', data=data)
plt.show()
4.5、时间序列分析:如果数据包含时间信息,可以分析各个变量随时间的变化趋势。在我们的示例中,首先需要将 order_date 转换为 datetime 类型
data['order_date'] = pd.to_datetime(data['order_date'])# 按日期对销售额进行分组并求和
daily_sales = data.groupby('order_date')['sales_amount'].sum()# 绘制销售额随时间变化的折线图
daily_sales.plot(kind='line')
plt.show()
4.6、多变量分析:分析多个变量之间的关系。例如,分析不同 product_category 的 units_sold 和 price_per_unit 之间的关系
sns.scatterplot(x='units_sold', y='price_per_unit', hue='product_category', data=data)
plt.show()
4.7、箱线图分析
# 分析 units_sold 箱线图
sns.boxplot(x=data['units_sold'])
plt.show()# 分析 price_per_unit 箱线图
sns.boxplot(x=data['price_per_unit'])
plt.show()# 分析 sales_amount 箱线图
sns.boxplot(x=data['sales_amount'])
plt.show()
5、数据建模与分析
还需要继续导入对应库:
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score以下示例将以一个简单的线性回归模型为例,对销售数据进行分析。
首先,我们假设 units_sold 受 price_per_unit 的影响。我们将使用 scikit-learn 库中的线性回归模型进行建模。
# 建立线性回归模型
X = data[['price_per_unit']]
y = data['units_sold']# 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)# 训练模型
reg = LinearRegression()
reg.fit(X_train, y_train)# 预测
y_pred = reg.predict(X_test)# 评估模型
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error: ", mse)
print("R2 Score: ", r2)6、数据可视化
# 数据可视化
plt.scatter(X_test, y_test, color='blue', label='Actual')
plt.scatter(X_test, y_pred, color='red', label='Predicted')
plt.xlabel('Price Per Unit')
plt.ylabel('Units Sold')
plt.legend()
plt.show()这个代码段包括了数据建模与分析、数据可视化的过程。我们首先使用 scikit-learn 库中的 train_test_split 函数将数据集划分为训练集和测试集。接着,我们使用 LinearRegression 类创建一个线性回归模型,使用训练集对模型进行训练。然后,我们使用训练好的模型对测试集进行预测,并计算均方误差 (MSE) 和决定系数 (R2) 来评估模型的性能。最后,我们将实际值与预测值进行可视化,以直观地观察模型的表现。
ps:据建模与分析、数据可视化显示结果的解释
在我们的示例中,我们通过线性回归模型探讨了 price_per_unit(商品单价)与 units_sold(销售数量)之间的关系。通过训练线性回归模型并对测试数据进行预测,我们可以评估这种关系的存在程度以及模型的预测能力。
在数据可视化部分,我们展示了一个散点图,其中蓝色点代表实际的数据点(测试集),红色点代表预测的数据点。这个图像可以帮助我们直观地了解模型的预测性能。横坐标表示商品单价,纵坐标表示销售数量。
如果红色预测点与蓝色实际点之间的距离较小,说明模型的预测性能较好,反之则表示预测性能较差。此外,我们还可以通过计算均方误差 (MSE) 和决定系数 (R2) 来量化模型的性能。
- 均方误差 (MSE):衡量预测值与实际值之间差异的平均平方和。MSE 越小,表示模型预测的误差越小,性能越好。
- 决定系数 (R2):衡量模型对数据的拟合程度。R2 的取值范围为 0 到 1,值越接近 1,表示模型拟合得越好,预测性能越好。
通过这些指标和可视化结果,您可以对线性回归模型的性能进行评估,并根据需要调整模型或尝试其他建模方法。在实际工作中,您可能需要尝试多种模型,并根据项目需求和数据特点选择最合适的模型。
7、结果解释和报告
在结果解释和报告阶段,您需要根据分析结果撰写一份报告,报告中应包括以下内容:
- 项目背景和目的:说明分析的背景、目的和应用场景。
- 数据来源和描述:简要介绍数据的来源、类型、结构和特点。
- 数据清洗和预处理:描述数据清洗和预处理过程中采取的方法和步骤,以及数据质量的改进情况。
- EDA 过程和结果:详细介绍 EDA 过程中使用的方法和技术
四、学习过程中一些问题的回答
1、通过训练模型并对测试数据进行预测,预测了什么,为什么要预测?
答:这次实例中通过训练线性回归模型并对测试数据进行预测,预测的是输出变量(也称为响应变量或因变量)的值,这些值可以是数字、类别或一些其他形式。预测的目的是根据已知的输入变量(也称为解释变量或自变量)的值来预测输出变量的值。例如,如果我们想预测房屋的销售价格,我们可以使用线性回归模型,其中输入变量可能包括房屋的大小、位置、年龄和卫生间数量等,输出变量是房屋的销售价格。这种预测有助于我们了解数据之间的关系,并提供有用的信息,例如房屋价格随着卫生间数量增加而增加等。
2、”评估这种关系的存在程度以及模型的预测能力“,如何评估以及为什么要评估?
答:要评估线性回归模型中变量之间的关系强度和预测能力,可以使用各种统计指标,例如R方值,均方误差(MSE),平均绝对误差(MAE)等。R方值衡量模型对数据的拟合程度,值介于0到1之间,越接近1表示模型拟合得越好。MSE和MAE衡量模型的预测误差,值越小表示模型预测得越准确。评估模型的目的是确定模型是否适合数据,以及它是否可以可靠地预测未来数据的值。
3、为什么要找与项目需求和数据最适合的模型?
答:选择最合适的模型是为了确保预测的准确性和可靠性。不同的模型适用于不同的数据类型和问题类型。例如,如果我们的数据包含二元分类问题(例如,区分垃圾邮件和正常邮件),则逻辑回归模型可能比线性回归模型更适合。在选择模型时,需要考虑数据的特点,例如数据的分布、是否存在非线性关系等。选择正确的模型可以帮助我们更好地理解数据,并提高预测的准确性和可靠性。
-----------------------------------------------------------------我是分割线--------------------------------------------------------------
看完了觉得不错就点个赞或者评论下吧,感谢!!!
如果本文哪里有误随时可以提出了,收到会尽快更正的
相关文章:

数据分析练习——学习一般分析步骤
目录 一、准备工作 二、导入库和数据 1、导入必要的库: 2、模拟数据 三、数据分析过程 1、读取数据: 2、数据概览和描述性统计: 2.1、查看数据概览: 2.2、查看描述性统计: 3、数据清洗: 3.1、处…...

Linux环境下挂载exfat格式U盘,以及安装exfat文件系统
目录Linux一般支持的文件系统有:1.安装exfat软件安装工具环境以及exfat件依赖的系统软件下载exfat源码包并安装2.挂载exfat格式U盘查看U盘在那个目录执行挂载命令Linux一般支持的文件系统有: 文件系统名称详情ext专门为Linux核心做的第一个文件系统&…...
网格布局grid
grid网格定义 css网格是一个用于web的二维(行和列的组合)布局,利用网格,你可以把内容按照行和列的格式进行排版,另外,可以轻松的实现复杂布局。 1.定义网格和fr单位 1.1定义网格 在父元素加上ÿ…...

《扬帆优配》环境更优!这类资金,迎利好!
近来,第一批主板注册制新股连续发动申购,网下询价中,组织出资者频繁现身打新商场,公募基金、社保基金、养老金、保险资金等中长时间资金,成为全面注册制下新股发行商场的重要参加者。 多位业内人士对此表明,…...
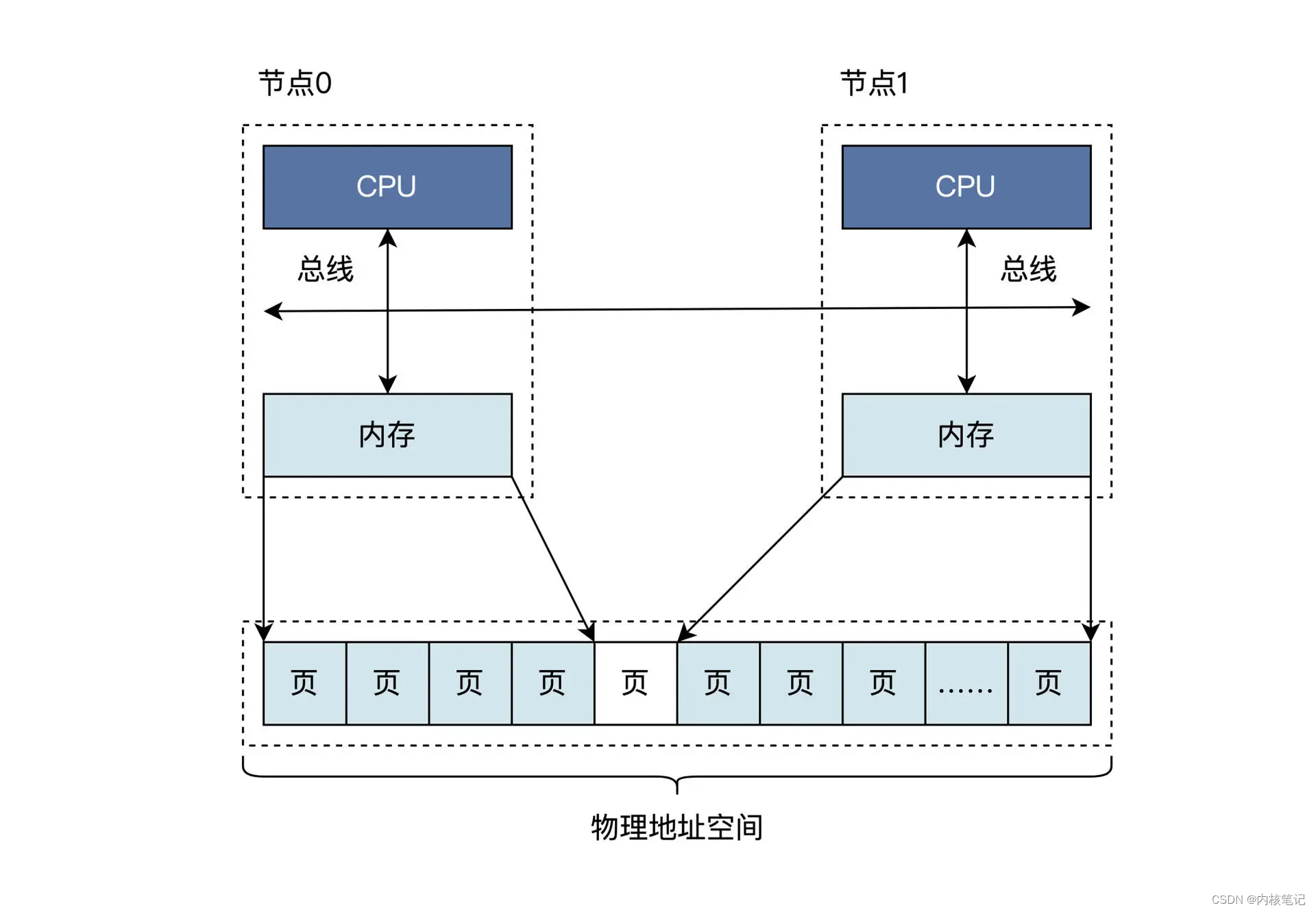
RK3568平台开发系列讲解(内存篇)内存管理的相关结构体
🚀返回专栏总目录 文章目录 一、硬件架构二、Linux 物理内存管理结构体沉淀、分享、成长,让自己和他人都能有所收获!😄 📢应用程序想要使用内存,必须得先找操作系统申请,我们有必要先了解一下 Linux 内核怎么来管理内存,这样再去分析应用程序的内存管理细节的时候,…...

如何理解二叉树与递归的关系
二叉树一般都是和递归有联系的,二叉树的遍历包括了前序,后序,中序,大部分题目只要考虑清楚应该用那种遍历顺序,然后特殊情况的条件,题目就会迎刃而解。 1. 先来说说二叉树的遍历方式 其实二叉树的遍历很简…...

CSS 高级技巧
目录 1.精灵图 1.1为什么需要精灵图 1.2 精灵图(sprites)的使用 2.字体图标 2.1字体图标的产生 2.2字体图标的优点 2.3字体图标的下载 2.4字体图标的引入 2.5字体图标的追加 1.精灵图 1.1为什么需要精灵图 一个网站往往回应用很多的小背景图像作…...

ToBeWritten之MIPS汇编基础铺垫
也许每个人出生的时候都以为这世界都是为他一个人而存在的,当他发现自己错的时候,他便开始长大 少走了弯路,也就错过了风景,无论如何,感谢经历 转移发布平台通知:将不再在CSDN博客发布新文章,敬…...

MySQL数据库对数据库表的创建和DML操作
1.创建表user,其中包含id、name、password,其中主键自增,name,唯一是可变长度,最大长度是30,密码,可变长度,最大长度为20,不为空。 以下是创建符合要求的user表的SQL语句…...

【PCB专题】PCB 阻焊层(solder mask)与助焊层(paste mask)有什么区别
一块标准的印刷电路板 (PCB) 通常需要两种不同类型的“罩层 (mask)”。其中阻焊层 (solder mask) 和助焊层 (paste mask) 都是“罩层”,但在 PCB 制造过程中,它们分别用于两个完全不同的部分,因此也存在很大的区别。 阻焊层定义 阻焊层定义了电路板外表面的保护材料涂抹范围…...
ThreeJS-纹理旋转、重复(十一)
旋转 文档:three.js docs 关键代码: //设置旋转中心,默认左下角 docColorLoader.center.set(0.5,0.5); //围绕旋转中心逆时针旋转45度 docColorLoader.rotation Math.PI/4; 完整代码: <template> <div id"three_div"></div>…...
CSDN——Markdown编辑器——官方指导
CSDN——Markdown编辑器——官方指导欢迎使用Markdown编辑器新的改变功能快捷键合理的创建标题,有助于目录的生成如何改变文本的样式插入链接与图片如何插入一段漂亮的代码片生成一个适合你的列表创建一个表格设定内容居中、居左、居右SmartyPants创建一个自定义列表…...
DN-DETR调试记录
博主在进行DINO实验过程中,发现在提取了3个类别的COCO数据集中,DINO-DETR对car,truck的检测性能并不理想,又通过实验自己的数据集,发现AP值相差不大且较为符合预期,因此便猜想是否是由于DINO中加入了负样本约束导致背景…...

ASP消防网上考试系统设计与实现
本文以ASP和Access数据库来开发服务器端,通过计算机网络技术实现了一个针对消防部队警官的网上考试系统。为了。提高消防部队的工作效率和信息化水平,体现消防部队信息化进程的特色,开发一个适合消防部队的计算机网上考试系统是非常必要的。鉴…...

MongoDB - 数据模型的设计模式
简介 官方文章的地址是 Building with Patterns: A Summary,其中汇总了 12 种设计模式及使用场景。 上述的图表列举了 12 种设计模式及应用场景,主要是以下这些: 近似值模式(Approximation Pattern)属性模式…...

3D格式转换工具助力Shapr3D公司产品实现了 “无障碍的用户体验”,可支持30多种格式转换!
今天主要介绍的是HOOPS Exchange——一款支持30多种CAD文件格式读取和写入的工具,为Shapr3D公司提供的重要帮助! Shapr3D是一家有着宏伟目标的公司:将CAD带入21世纪!该公司于2016年首次推出其同名应用程序,并将Shapr3D带到了macOS…...
虚拟环境-----virtualenv和pipenv的安装和应用
1.pip install virtualenv 2.pip安装虚拟环境管理包virtualenvwrapper-win 3.创建一个存放虚拟环境的目录(建议命名为.env或者.virtualenv) 4.配置环境变量(变量名:WORKON_HOME,值:上面创建的目录路径) …...

awd pwn——LIEF学习
文章目录1. 什么是LIEF2. 加载可执行文件3. 修改ELF的symbols4. ELF Hooking5. 修改got表6. 总结1. 什么是LIEF LIEF是一个能够用于对各种类型的可执行文件(包括Linux ELF文件、Windows exe文件、Android Dex文件等)进行转换、提取、修改的项目…...

亚商投资顾问 早餐FM/0330 6G发展持开放态度
01/亚商投资顾问 早间导读 1.工信部副部长:中国对6G发展持开放的态度已成立工作组推动关键技术研究 2.易纲、周小川最新发声 中国加快绿色低碳发展的决心坚定不移 3.中移动出手!450亿溢价包圆邮储银行定增股份 4.海南全面启动全岛封关运作准备 免税消…...

cookie和session的区别
文章目录cookie和session的区别1. 存储位置不同2. 生命周期不同3. 存储数据大小不同4. 数据类型不同5. 安全性不同cookie和session的区别 1. 存储位置不同 cookie:cookie数据保存在客户端。 session:session数据保存在服务器端。 2. 生命周期不同 s…...

关于我使用MinMix创建了一个Tailwindcss学习网站
一、语言特性:Java 26 与模式匹配进化 1.1 Java 26 语言级别支持 IDEA 2026.1 EAP 最引人注目的变化之一,就是新增 Java 26 语言级别支持。这意味着开发者可以提前体验和测试即将在 JDK 26 中正式发布的语言特性。 其中最重要的变化是对 JEP 530 的全…...

leetcode 1534. 统计好三元组 Count Good Triplets
Problem: 1534. 统计好三元组 Count Good Triplets 用变量存储数组中的值,防止多次访问IO Code class Solution { public:int countGoodTriplets(vector<int>& arr, int a, int b, int c) {int n arr.size(), a1, b1, c1, ans 0;for(int i 0; i <…...

nRF52832上电启动全解析:从MBR到Bootloader的跳转机制与寄存器配置
nRF52832上电启动全解析:从MBR到Bootloader的跳转机制与寄存器配置 当nRF52832芯片通电瞬间,一场精密的硬件芭蕾在微秒级时间内悄然上演。这颗蓝牙低功耗SoC的启动流程远非简单的"通电即运行",而是涉及存储器分区、寄存器配置和多重…...

OpenClaw+nanobot自动化测试:24小时监控网站可用性
OpenClawnanobot自动化测试:24小时监控网站可用性 1. 为什么需要自动化网站监控 作为个人站长,我经常遇到这样的困扰:半夜网站突然宕机,直到第二天收到用户反馈才发现问题。传统监控方案要么价格昂贵,要么配置复杂&a…...
)
Google Test进阶玩法:用测试夹具重构你的C++项目(CLion实战篇)
Google Test进阶实战:用测试夹具重构复杂C项目的工程化实践 当你的C项目从几百行扩展到几万行代码时,那些曾经简单的单元测试开始变得力不从心。测试用例之间出现隐蔽的状态依赖,setup代码重复率飙升,而每次运行测试套件的时间越来…...

Phaser游戏中的布料模拟:高级物理效果终极指南
Phaser游戏中的布料模拟:高级物理效果终极指南 【免费下载链接】phaser Phaser is a fun, free and fast 2D game framework for making HTML5 games for desktop and mobile web browsers, supporting Canvas and WebGL rendering. 项目地址: https://gitcode.co…...

CCMusic跨平台部署指南:Windows/Linux/macOS全适配
CCMusic跨平台部署指南:Windows/Linux/macOS全适配 音乐风格识别从未如此简单——无论你用哪种电脑系统 1. 开篇:为什么需要跨平台部署方案 还在为音乐风格分类工具的安装头疼吗?不同的操作系统、不同的环境配置、复杂的依赖关系...这些麻烦…...

StarVCenter单机版安装避坑指南:从BIOS设置到虚拟机创建的完整流程
StarVCenter单机版安装全流程实战:从硬件准备到虚拟机管理的深度解析 在当今企业IT基础设施快速迭代的背景下,虚拟化技术已成为资源整合与管理的核心解决方案。StarVCenter作为一款国产化虚拟化管理平台,其单机版部署方案特别适合中小型业务场…...

MySQL视图与子查询的那些事儿:从报错1349看数据库设计的最佳实践
MySQL视图与子查询深度解析:从报错1349看高效数据库设计 在数据库开发与维护过程中,视图(View)和子查询(Subquery)是两种极为常用的技术手段。它们能够简化复杂查询、提高代码复用性,并为数据安全提供额外保障。然而,当这两种技术…...

Empire渗透测试框架深度解析:如何构建无文件攻击链的实战指南
Empire渗透测试框架深度解析:如何构建无文件攻击链的实战指南 【免费下载链接】Empire EmpireProject/Empire: Empire 是一个开源的Post-Exploitation框架,主要用于渗透测试后的操作阶段,通过模块化的设计实现远程命令执行、持久化连接、凭证…...